基于深度學習的結腸癌病理圖片分類研究*
2021-07-07 09:27:18廣州醫科大學公共衛生學院511436鐘碧霞周冠群許文琪
中國衛生統計 2021年3期
關鍵詞:模型
廣州醫科大學公共衛生學院(511436) 鐘碧霞 周冠群 許文琪 趙 倩
【提 要】 目的 本研究探討基于深度學習算法的結腸癌病理組織切片的診斷模型,對癌旁正常和腫瘤組織以及不同分化程度的腫瘤組織進行自動分類。方法 經公共數據庫TCGA收集117名結腸癌患者的全切片病理圖,分割成不重疊的4440張子圖片,按8∶1∶1的比例隨機劃分成訓練集、驗證集和測試集。基于Python語言的TensorFlow框架,采用Inception-v3模型和遷移學習算法構建模型。結果 對癌旁正常和腫瘤組織構建診斷模型,測試集的準確度為99.8%,靈敏度為99.7%,特異度為100%;對低分化和中分化腫瘤組織構建診斷模型,測試集的準確度為94.8%,靈敏度為94.4%,特異度為95.1%;對不同分化程度腫瘤組織構建三分類診斷模型,測試集中癌旁正常、中分化、低分化組織的準確度分別為100%、94.6%、95.2%。結論 利用Inception-v3模型和遷移學習算法對結腸癌病理組織切片構建診斷模型,具有較高準確度、查全率和查準率。
結直腸癌是嚴重危害人類健康的惡性腫瘤之一。據2018年全球癌癥統計報告,2018年全球結直腸癌新發病人數約180萬,占所有惡性腫瘤的10.2%;死亡人數約86.1萬,占所有腫瘤死亡人數的9.2%;其發病率在所有癌癥中排名第三位,死亡率為第二位[1]。2014年中國癌癥的統計數據顯示,結直腸癌新發病例約37萬,死亡例數約18萬,發病率在所有癌癥中排名第三位,死亡率為第五位[2]。結直腸癌的高發病率和高死亡率嚴重威脅著人類健康及生命安全。
相關研究顯示,結直腸癌患者若能早發現、早治療,其5年生存率可高達90%;若未能進行早期診斷,一旦癌細胞擴散到結直腸外,患者的5年生存率將下降為14%[3]。因此,患者早期診斷的準確性就顯得尤為重要。目前,活體組織病理檢查是結直腸癌診斷的金標準[4],由臨床病理醫生根據相關指導原則進行分類和分期。而人工閱片的準確性取決于臨床醫師的經驗,且工作量大、耗時長。構建具有較高準確性的病理圖片診斷模型,能輔助臨床醫生快速地診斷病理圖片,提高工作效率。
本文采用深度學習中的Inception v3模型[5]和遷移學習算法[6],對公共數據庫TCGA中經HE染色的結腸癌病理圖像構建診斷模型,對癌旁正常和腫瘤組織以及不同分化程度的腫瘤組織進行自動分類。
資料與方法
1.數據來源
本研究的數據來自于美國癌癥基因組圖譜信息中心(the cancer genome atlas,TCGA)[7]。該數據庫提供了患者基本信息和病理掃描圖片。病理標本經HE染色制片和顯微鏡拍照后上傳平臺,并按美國癌癥聯合委員會第六版或第七版分期手冊[8-9],對病理圖片進行分級和分期。患者基本信息主要為性別、年齡、病理圖片分化程度和分期。
本研究共收集了117名結腸癌患者的病理全切片掃描圖和相關病理信息。所有患者的病理圖片只含有一種分級或一種分期,不含有混合型。其中低分化患者21人,中分化患者96人。21名患者的病理圖片包含癌旁正常組織(19個中分化,2個低分化)。對于癌旁正常組織的界定,分別由兩位具有5年以上臨床經驗的病理醫生劃分腫瘤邊界,確定癌旁正常組織的選取范圍。若兩名醫生意見不一致,則由討論后共同商定。
將117名患者的病理全切片圖分割成不重疊的512×512大小的高分辨率子圖片,共得到癌旁正常組織的圖片729張、中分化腫瘤組織2393張、低分化腫瘤組織1318張,并根據病理結果來制作圖片標簽。如圖1所示。從細胞形態學看,正常的結腸腺體排列整齊、大小均勻,癌變的腺體發生不同程度的畸變,排列紊亂,并且上皮細胞質消失。癌旁正常與腫瘤組織細胞形態學差異較大。
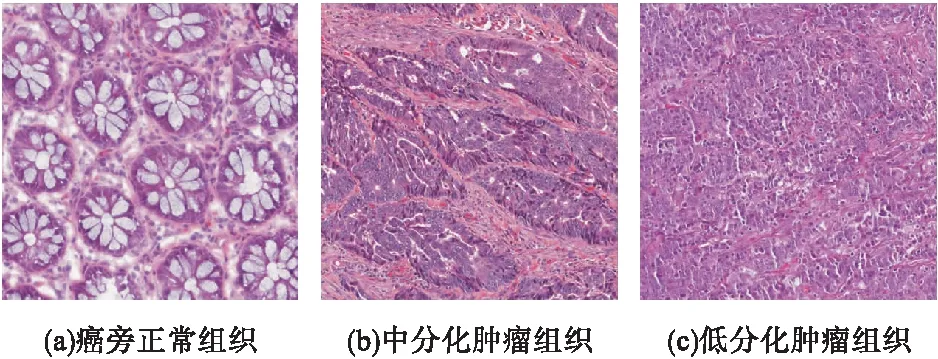
圖1 經HE染色結腸癌病理組織切片
2.模型的介紹
(1)Inception-v3模型
2014年Christian Szegedy提出一種全新的深度學習框架GoogLeNet[10],深度有22層,參數達到500萬。GoogLeNet最大的特點是具有Inception 模塊,通過對輸入圖像進行1×1、3×3 或 5×5 等不同的卷積運算與池化操作,獲取更好的圖像特征。Inception-v3模型是一種廣泛使用的圖片識別模型,在Inception-v1和Inception-v2的基礎上發展起來[5]。主要由11個Inception模塊組成,包括卷積層、平均池化層、最大池化層、連接層、丟包(dropout)層和全連接層。其中卷積層數約為100層,模型參數超過2500萬。Inception-v3模型通過分解卷積層可增加網絡的深度和非線性,降低參數數量,減輕過擬合問題。
(2)遷移學習
由于Inception-v3的模型參數數量較大,卷積層數較多,因而需要大規模的已標記樣本進行模型訓練,對于臨床數據而言通常難以實現。常采用遷移學習的方法來解決這一問題。遷移學習是通過對大規模已標記的數據集進行網絡訓練,將得到的網絡參數遷移到目標數據集上進行微調訓練[6],即對問題甲訓練好的網絡模型通過調整參數用于解決問題乙。通常選取ImageNet數據集的120余萬張標注圖片對1000多個目標進行網絡訓練[11],作為預訓練好的Inception模型。
本文采用Google提供的預訓練Inception-v3網絡模型,將底層的權重參數作為初始值來重新訓練,將訓練好瓶頸層遷移到本研究數據集上,替換最后一層全連接層。這樣可避免計算機內存不足,獲得更準確的權重參數,減少模型訓練的時間,提高模型的收斂速度和精度。
(3)模型訓練策略
采用Inception-v3遷移學習模型對結腸癌病理圖像進行建模,首先按照隨機化的原則對分割好的圖片按8∶1∶1 的比例分為訓練集、驗證集和測試集。其中,訓練集用于訓練模型,尋找損失函數最小的模型參數;驗證集用于確定模型超參數,選出最優模型;測試集用于對訓練好的最優模型進行性能評估。按隨機化的原則產生8∶1∶1數據集的步驟如下:隨機產生[0,99]的服從均勻分布的整數,每一張圖片對應一個隨機數;隨機數在[0,79]之間的圖片歸為訓練集,[80,89]為驗證集,[90,99]為測試集。癌旁正常組織、腫瘤組織、中分化腫瘤組織、低分化腫瘤組織分割好后的圖片,分別按照上述隨機化原則產生訓練集、驗證集和測試集。即:3711張腫瘤組織圖片隨機分成訓練集2975張、驗證集370張和測試集366張;2393張中分化圖片隨機分成訓練集1928張、驗證集242張和測試集223張;1318張低分化圖片隨機分成訓練集1073張、驗證集119張和測試集126張;729張癌旁正常圖片隨機分成訓練集596張,驗證集66張和測試集67張。如表1所示。

表1 模型1~3的訓練集、驗證集和測試集
選取隨機梯度下降(stochastic gradient descent,SGD)作為優化器[12],設置初始學習率為0.01,批尺寸(batch_size)為32,最大迭代次數為1000。基于Python的TensorFlow框架上完成模型構建,具體研究路線見圖2。
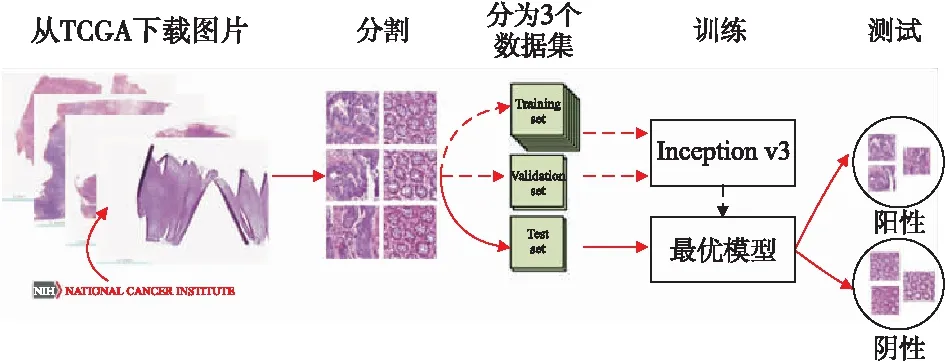
圖2 Inception-v3遷移學習模型路線圖
(4)模型的評價標準
本文采用準確度(Acc)、靈敏度(Sen)、特異度(Spe)、陽性預測值(PPV)、陰性預測值(NPV)、Youden指數(YI)、F1-score、ROC曲線、PRC曲線(precision recall curve)進行模型的性能評價。在機器學習中,靈敏度也稱為召回率(recall),陽性預測值也稱為精確率(precision)[13],F1-score是precision和recall的調和均數[13],PRC曲線描述precision隨recall變化關系[14-15]。
結 果
1.結腸癌患者的基本信息
本研究共納入117名結腸癌患者,男性59人,占50.4%。平均年齡為(69.3±12.7)歲,最小31歲,最大90歲。患者的腫瘤的分化、分期信息見表2。

表2 結腸癌患者的基本信息及腫瘤的分化、分期信息
2.Inception-v3遷移學習模型評價
模型1:癌旁正常和腫瘤組織的預測
對癌旁正常和腫瘤組織圖像進行建模,驗證集上的損失函數隨著訓練次數的增大而減少,最終收斂到0,見圖3中模型1。
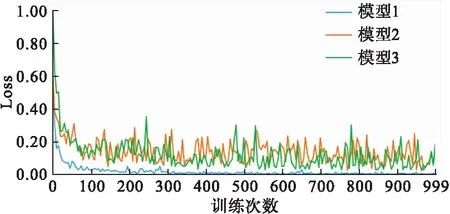
圖3 三個模型在驗證集上的損失函數隨訓練次數變化曲線
在測試集上,模型預測的準確度為99.8%,靈敏度為99.7%,特異度為100%,陽性預測值為100%,陰性預測值為98.5%,Youden指數為0.997,F1-score為99.9%,僅有1例腫瘤組織誤判為正常,詳見表3。圖4(a)為對應ROC和PRC曲線,兩條曲線下的面積均為1。圖5(a)為被誤判成癌旁正常的腫瘤組織圖片。
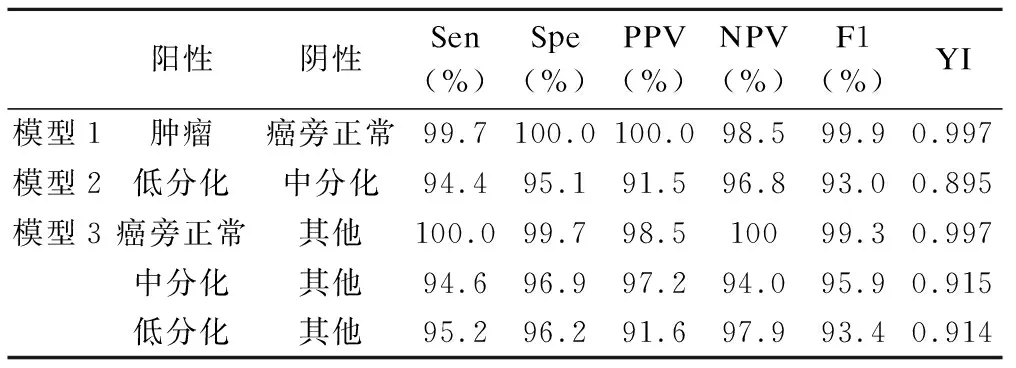
表3 三個模型在測試集上的性能評價

圖4 三個模型在測試集上的ROC和PRC曲線
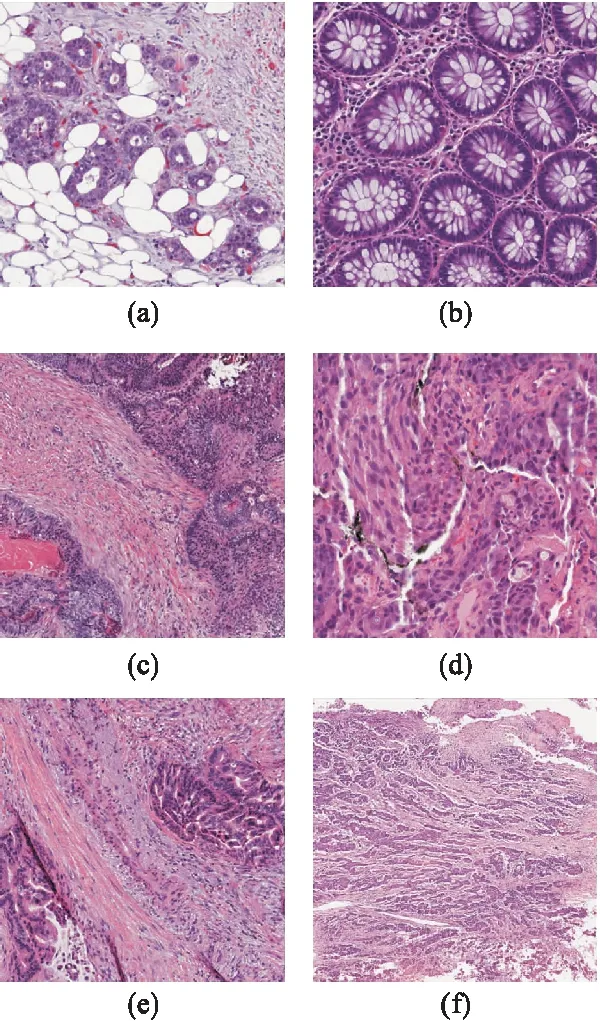
圖5 三個模型在測試集上分類錯誤的圖片(a)和(b)為模型1測試集中的圖片,(a)被誤判為正常的腫瘤組織圖片,(b)為癌旁正常組織的圖片;(c)和(d)為模型2測試集中的圖片,(c)為中分化腫瘤被誤判成低分化,(d)為低分化腫瘤被誤判中分化;(e)和(f)為模型3測試集中的圖片,(e)為中分化腫瘤被誤判成低分化,(d)為低分化腫瘤被誤判成中分化。
模型2:低分化、中分化腫瘤組織的預測
對中分化和低分化的腫瘤組織圖像進行建模,驗證集上的損失函數隨著訓練次數的增大而減少,但波動較大、變異增大,見圖3中模型2。
在測試集上,模型預測的準確度為94.8%,靈敏度為94.4%,特異度為95.1%,陽性預測值為91.5%,陰性預測值為96.8%,Youden 指數為0.895,F1-score為93.0%,詳見表3。圖4(b)為對應ROC和PRC曲線,AUC為0.99,PRC曲線下的面積(AUCPR)為0.98。圖5(c)為中分化腫瘤被誤判成低分化腫瘤,圖5(d)為低分化腫瘤被誤判成中分化腫瘤。
模型3:不同分化程度腫瘤組織的預測
對癌旁正常組織、中分化腫瘤組織和低分化腫瘤組織圖像進行三分類建模,驗證集上的損失函數隨著訓練次數的增大而減少,但波動較大、變異增大,與模型2的曲線較為接近,見圖3中模型3。
在測試集上,整體準確度為95.7%(398/416)。癌旁正常組織的準確度為100%(67/67),中分化腫瘤組織的準確度為94.6%(211/223),低分化腫瘤組織的準確度為95.2%(120/126)。分別對癌旁正常組織、中分化腫瘤組織和低分化腫瘤組織的預測結果,轉為二分類進行性能評價,見表3。圖4(c)為對應ROC和PRC曲線。其中,癌旁正常組織模型對應的AUC=1,AUCPR=1;中分化組織模型對應的AUC=0.992,AUCPR=0.993;低分化組織模型對應的AUC=0.991,AUCPR=0.978。在ROC曲線幾乎重合的情形下,中分化組織對應的PRC曲線略優于低分化組織對應的PRC曲線。圖5(e)為中分化腫瘤被誤判成低分化腫瘤,圖5(f)為低分化腫瘤被誤判成中分化腫瘤。
討 論
結腸癌嚴重危害人類的健康,采用深度學習算法對HE染色的結腸病理圖像進行輔助診斷具有重要的臨床意義。本文使用Inception-v3遷移學習模型,對TCGA數據庫中的癌旁正常組織和腫瘤組織,不同分化程度腫瘤組織的病理圖像進行診斷分類,具有較高的準確度、靈敏度和特異度。在本研究的測試集中,三個模型的靈敏度、特異度和準確度均達到94%以上,具有較好的區分度。
傳統的機器學習方法如支持向量機、隨機森林、BP神經網絡也可用于結直腸癌的病理分類[16-19]。針對癌旁正常組織和腫瘤組織病理圖像的分類算法,其準確度為55.0%~100%[16-17],針對結直腸癌不同分化程度的分類算法,其準確度為44.6%~95.5%[17-19],準確度的變化范圍較大。出現這種現象的主要原因是,這些傳統方法的輸入通常為一個或多個一維的變量或特征,對于二維或三維的圖像數據,需要先提取圖像特征。如通過共生矩陣獲取圖像紋理信息、通過圖像的邊緣特點獲取其形態特征等。可見,如何選取有效的圖像特征、有區分性的高質量特征以及選取多少數量的特征,是傳統的機器學習方法能否具有較好的準確度的關鍵所在,存在一定主觀性。
深度學習方法不需要提取圖像的一維特征,而是直接把二維的圖像以矩陣的方式放入模型進行訓練,通過深度網絡的訓練和學習直接獲取圖像特征從而進行最優分類。深度學習方法讓模型自動從原始圖像中學習特征,避免了傳統算法中人工設計、特征提取的復雜性和局限性。本研究所構建的三個Inception-v3遷移學習模型的準確度(99.8%,94.8%,95.7%),也高于傳統機器學習的平均水平。
2015年Kainz等人[20]采用深度卷積神經網絡,對Warwick-QU 數據庫中165幅已標記的結腸正常組織和腫瘤組織的病理圖像進行分類,其準確性為95%。本研究在測試集上的準確性達到99.8%,比深度卷積神經網絡提高了4.8%。Inception-v3遷移學習模型具有更高的準確性和模型精度。
另一方面,Inception-v3遷移學習模型也存在一些不足。從圖5中的誤判圖片可看出,該模型對于形態特征非常相似的病理圖片難以分辨。當不同分化程度的腫瘤細胞的輪廓較為相似時,該模型容易出現誤判。此外,本課題組前期研究發現,該模型對不同T分期的病理圖片的分類準確度較低。
因此,Inception-v3遷移學習模型分類效果的好壞,完全取決于不同分類間的病理圖像差異或相似度的大小。如果差異大,如正常和腫瘤圖片,則分類效果好、準確度高。反之如果差異小,如不同T分期圖片,則準確率較低。這可能需要對卷積層或池化層進行重新設計,最大化放大不同類別之間的差異。這些問題仍需要進一步探討和研究。
由于患者的相關臨床信息較少,本文主要考慮單純依靠病理圖片信息,可提供多大的診斷效能[21]。下一步可考慮進行臨床試驗設計,收集患者的有效臨床信息,進一步考慮基于病理圖片和臨床信息的混合模型[22]。還可在深度學習模型中自適應地提取圖像特征[23-24],再采用傳統的支持向量機、隨機森林構建新的混合模型。此外,深度學習計算量較大,對樣本標記、樣本量和硬件的要求較高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
