
基于多模板模糊競爭的涉案財物關系抽取方法
2021-07-15 09:10:38李攀鋒蔣宗神
四川大學學報(自然科學版) 2021年4期
關鍵詞:方法
李攀鋒, 林 鋒, 蔣宗神
(四川大學計算機學院, 成都 610065)
1 引 言
關系抽取是知識工程領域的重要任務之一,也是知識圖譜構建的核心步驟.它的目的在于從無結構的自然語言文本中抽取出結構化的知識,得到文本內含的語義關系,進而用于知識庫的構建、智能問答、推薦系統等.
目前常見的關系抽取方法主要分為三種:(1) 基于模板匹配的方法[1];(2) 基于監督學習的方法[2];(3) 基于半監督或無監督的方法.
隨著機器學習和深度學習的發展,基于監督學習和半監督學習的關系抽取方法應用十分廣泛[3].Zeng等[4]在2014年首次提出采用卷積神經網絡來提取句子的語義特征,進而實現關系抽取;Zhang等[5]在2015年采用了雙向長短期記憶網絡并借助依存分析和命名實體識別來解決關系抽取問題;諶予恒等[6]在2020年采用了結合注意力機制與殘差網絡進行遠程監督關系抽取.這些方法大多用于處理如人物關系之類的關系抽取問題,因為在這種場景下,關系類別明確、訓練語料豐富[7].但本文提出的關系抽取方法是為了解決涉案財物知識庫構建的特定問題,即是立足于抽取“業務單位實體”與“財物實體”之間存在的“處置方式”關系.受限于涉案財物知識庫場景訓練語料少且單一以及識別準確率要求高的特點,機器學習的關系抽取方法在涉案財物領域并不適用,而采用基于模板匹配的方法更為合理.
本文提出的基于多模板模糊競爭的涉案財物關系抽取方法,根據涉案財物處置的實際場景需求,在常規三元組關系的基礎上擴充了“財物狀態”和“處置條件”兩個屬性元素,定義為五元組關系,以不同維度設計了三個關系抽取模板,從法律法規文本自動抽取五元組關系,并運用模糊邏輯計算各個模板抽取結果的置信度,使得三個模板間相互競爭,進一步提高抽取結果的準確度.
2 基本概念與任務描述
2.1 涉案財物知識庫
涉案財物知識庫指在根據現有法律法規自動完成刑事案件中涉案財物處置的相關知識融合,為司法實踐中公檢法等執法司法單位的辦案人員提供支持[8].核心的工作是從法律法規出發,抽取出“業務單位實體”與“財物實體”之間的處置關系.由于該領域的特殊性,在創建知識庫過程中完成關系抽取面臨著的挑戰如下:
(1) 訓練語料少且單一.涉案財物知識庫的構建目標是基于法律法條自動完成知識抽取,語料主要來源于正式實施的法律法規中與涉案財物處置相關的法條,這造成進行關系抽取時訓練語料不僅遠遠少于通用知識庫,也少于一般的法律知識庫.
(2) 識別準確率要求高.涉案財物知識庫的應用目標是為司法實踐中的一線辦案人員提供支持,這對知識庫中知識的準確性提出了極高的要求.為保證知識庫的正確性和減少后續工作,關系抽取算法的抽取準確率應盡可能提高.
上述問題使得涉案財物知識庫構建過程中的關系抽取區別于一般關系抽取,成為了一個獨特的、挑戰性的問題.
2.2 涉案財物關系概述
實體關系三元組是由頭實體、尾實體、實體間關系組成[9].在人物關系領域,即是形如[“姚明”,“葉莉”,“夫妻”]這樣的人物關系三元組,其中“姚明”為頭實體,“葉莉”為尾實體,“夫妻”為實體間關系[10].
在涉案財物領域,關系三元組稍有不同.在法律法規文本中,財物實體和業務單位實體直接存在著某種處置關系,如[“公安機關”,“涉案財物”,“扣押”],其中“公安機關”為頭實體,“涉案財物”為尾實體,“扣押”關系同時作為一種處置方式,本質上是“公安機關”作為主語,對賓語“涉案財物”實施“扣押”動作.由此形成了包括“業務單位實體”、“處置方式”、“財物實體”的三元組關系模式,對應于司法實踐的具體任務,即是公安機關在辦理各類刑事案件以及檢察機關在職務犯罪案件偵查過程中,對與案件有關的物品、款項等依法進行扣押、查封、凍結等操作.
基于法律法規的涉案財物關系抽取即是從法律法規文本中抽取出涉案財物處置的規則信息.這種規則信息對于司法實踐中涉案財物的智能管理有著重要的意義.考慮到司法實踐的嚴謹性,單純的三元組信息并不能較好地反映業務單位執行涉案財物處置的具體情形.因此,本文在傳統三元組關系的基礎上,針對涉案財物處置實際場景,為“財物實體”增加了“財物狀態”屬性,為“處置方式”增加了“處置條件”屬性,形成了形如[“業務單位實體”,“處置方式”,“處置條件”,“財物實體”,“財物狀態”]的五元組關系模式.
2.3 涉案財物關系抽取任務
在與涉案財物處置相關的法律文件中,法條準確地描述了在何種情況下某個機構可以對某種財物實施特定的處置.涉案財物關系抽取任務即是從法條文本中自動抽取出這種處置規則.即是抽取出形如[“業務單位實體”,“處置方式”,“處置條件”,“財物實體”,“財物狀態”]的五元組關系.
在目前常規的關系抽取任務中,往往采用基于神經網絡的方法,本質上是將抽取問題轉化為了分類問題[11],在諸如人物關系這種關系類型確定的場景下效果較好,由于本文研究的涉案財物關系抽取任務特殊,難以轉化為分類問題,采用模板匹配的方法進行抽取,抽取的五元組示例如下.
對法條文本:“人民法院在必要的時候,可以采取保全措施,查封、扣押或者凍結被告人的財產.”內含如表1所示的五元組關系.

表1 五元組關系
在上述例子中,實體與關系之間的相對位置較為常規,且各元素成分相對獨立,抽取過程中干擾信息較少.
但對另一個法條文本:“對查封、扣押的財物、文件、郵件、電報或者凍結的存款、匯款、債券、股票、基金份額等財產,經查明確實與案件無關的,應當在三日以內解除查封、扣押、凍結,予以退還.”
該法條中語法結構有所不同,財物實體進行了前置,且財物狀態搭配復雜,抽取難度較大.
可見,在涉案財物關系抽取任務中,由于語言習慣的差異,單個模板難以較好地應對不同結構的法條,因此有必要從不同維度設計多個模板,以應對不同的語言現象.但由此產生了另一個問題,即多個模板抽取的結果如何整合的問題.本文為此提出了一種基于模糊邏輯的方法,以評判多個模板抽取結果的置信度,競爭得出質量較優的結果.
3 基于多模板模糊競爭的關系抽取
3.1 數據預處理
涉案財物關系抽取的初始數據是法律文件,但模板匹配的處理對象是單句法條,因此,需要對初始法律文件進行預處理,以適配模板匹配,處理流程如圖1所示.
首先,對輸入的法律文件進行段落解析,得到段落集A,對于每一個段落,判斷其是否是居中的標題,若是則忽略該段落,否則利用正則表達式提取法條序號及法條內容.通過以上步驟得到了帶有序號標記的法條集A′.后續根據涉案財物處置相關的特征詞過濾掉與涉案財物處置無關的法條,得到最終有效的法條集A″.

圖1 預處理流程圖Fig.1 Flow chart of preprocessing
3.2 模板設計
3.2.1 模板設計基礎說明 本文以不同的維度設計了三個抽取五元組關系的模板.下面就三個模板的公共部分做說明.
模板輸入輸出:1) 輸入:T、W1、W2、W3、W4、W5;2) 輸出:R.其中,T為輸入的法條文本;W1、W2、W3、W4、W5為人工整理的詞典[12](W1為財物實體詞典;W2為業務單位實體詞典;W3為觸發詞典;W4為處置方式詞典;W5為財物狀態詞典).R為輸出的5元組關系集合.
模板偽代碼中將用到的重要函數如表2.

表2 函數說明
3.2.2 模板1設計 模板1是以詞為單元進行匹配,首先確定財物實體的位置,以此為中心檢索其余4個元素.具體匹配規則如下.
輸入:T、W1、W2、W3、W4、W5
輸出:R
(1)W← cut_w(T)
(2)p← DTW(0,len(W),W,W1)
(3)t← DTW(0,len(W),W,W3)
(4)P← PTW(0,len(W),W,W1)
(5) ift≤pthenf← True
(6) end if
(7)C← {GCT(min(t,p),max(t,p),W)}
(8)S← PTW(p,0,W,W5)
(9) iffis not True then
(10)M← PTW(t,len(W),W,W4)
(11) else
(12)M← PTW(p,len(W),W,W4)
(13) ifM== ? then
(14)M← PTW(t,p,W,W4)
(15) end if
(16) end if
(17)G← PTW(t,0,W,W2)
(18)R←P×G×M×S×C
(19) returnR
3.2.3 模板2設計 模板2同樣是以詞為單元進行匹配,但首先確定的是業務單位實體的位置,以此為中心檢索其余4個元素.匹配規則如下.
輸入:T、W1、W2、W3、W4、W5
輸出:R
(1)W← cut_w(T)
(2)G← PTW(0,len(W),W,W2)
(3) ifG≠ ? then
(4)n1← DTW(0,len(W),W,W2),n2← 0
(5) elsen1← 0,n2← len(W)
(6) end if
(7)P← PTW(n1,n2,W,W1)
(8)t←DTW(0,len(W),W,W3)
(9)S← PTW(t,0,W,W5)
(10)M← PTW(t,len(W),W,W4)
(11)s← DTW(t,0,W,W5)
(12)C← {GCT(s,len(W),W)}
(13)R←P×G×M×S×C
(14) returnR
3.2.4 模板3設計 模板3是以子句為單元進行匹配.模板3中認為業務單位實體與處置方式應當同屬一個子句,財物實體與財物狀態屬性應當同屬一個子句,處置條件屬性單獨屬于一個子句.具體匹配規則如下.
輸入:T、W1、W2、W3、W4、W5
輸出:R
(1)Q← cut_c(T)
(2) selectqinQthat 包含業務單位實體或處置方式
(3)Q←Q- {q}
(4)W← cut_w(q)
(5)G← PTW(0,len(W),W,W2)
(6)M← PTW(0,len(W),W,W4)
(7) selectqinQthat 包含財物實體或財物狀態
(8)Q←Q- {q}
(9)W← cut_w(q)
(10)P← PTW(0,len(W),W,W1)
(11)S← PTW(0,len(W),W,W5)
(12) selectqinQthat 包含處置條件
(13)Q←Q- {q}
(14)W← cut_w(q)
(15)P← {GCT(0,len(W),W)}
(16)R←P×G×M×S×C
(17) returnR
3.3 模糊競爭
3.3.1 數值化 本文擬利用模糊邏輯對模板抽取出的五元組關系進行打分,進而實現多個模板間抽取結果的獎懲機制,綜合勝出置信度較高的五元組關系.鑒于模糊邏輯適用于數值計算[13],而五元組關系為文本數據,加之初始抽取的五元組關系存在空值干擾,因此,首先定義五元組各元素補全方法及數值化方法.
(1) 初始抽取數據如下所示.
(2) 補全過程:
1) 通過實驗數據確定三個模板初始置信度:w1,w2,w3;
2) 對于{a,b,c,d,e}中的每一種元素x:
(a) 篩選出x1,x2,x3中的非空元素,記作集合R;
(b) 選出集合R中對應模板置信度最大的元素r;
(c) 用r補全x1,x2,x3中的空值元素;
(d) 若R為空集,則x1,x2,x3置為“空”.
(3) 補全后進行數值化,對于每一個元素xi,其數值化結果v計算公式如下.
x∈{a,b,c,d,e},i∈{1,2,3}
(1)
其中,sim為文本相似度計算函數,經實驗嘗試,摒棄了常規的基于詞袋的余弦相似度方法,實際采用的相似度方法如下.
輸入:s1,s2
輸出:t
(1)Q← {},P← {},m← 0
(2) foriins1do
(3)Q[i] ←Q.get(i,0) + 1
(4) end if
(5) forjins2do
(6) ifP.contains(j) then
(7)n←P[j]
(8) else
(9)n←Q.get(j,0)
(10) end if
(11)P[j] ←n-1
(12) ifn> 0 thenm←m+ 1
(13) end if
(14) end for
(15)t←2*[m/(len(s1) + len(s2))]
(16) returnt
3.3.2 模糊化 通過數值化處理后,每個模板抽取的五元組關系均如以下格式:[abcde] ,其中,各元素均為0到1之間的浮點數.
在模糊化階段,定義每個元素x均隸屬于P、A、G三個集合.其中,P集合和G集合采用梯形隸屬函數,A集合采用三角形隸屬函數[14].如圖2所示.
圖2中,橫軸為輸入的元素浮點數值,縱軸為對應的各集合的隸屬度.p1,p2,a,d,g1,g2為各隸屬度函數的參數.
通過隸屬函數模糊化后,得到五元組各元素隸屬于PAG三個集合的隸屬度,如圖3所示.

圖2 隸屬函數圖Fig.2 Image of membership functions

圖3 隸屬示意圖Fig.3 Diagram of affiliation
3.3.3 規則化 通過模糊化處理后,需要根據模糊規則和模糊邏輯的運算進行重新組合.五元組各元素均隸屬于PAG三個集合,五種元素不同隸屬集合組合情況共有35種,如下所示.
對于每一種組合,通過規則指定最終的隸屬集合以及相應的隸屬度.為減少模糊規則數量,本文簡化規則如下.
1) 定義.
w(Px)=0,w(Ax)=1,w(Gx)=2,
x∈{a,b,c,d,e}
(2)
2) 對于任意一種組合:
S=(Ya,Yb,Yc,Yd,Ye),Y∈{P,A,G},

(3)
3) 隸屬集合:
(4)
4) 隸屬度:
V(S)=min(Ya,Yb,Yc,Yd,Ye)
(5)
3.3.4 去模糊 通過規則化處理后,得到了各種組合情況下對應的隸屬集合以及隸屬度,借助去模糊化將其轉化為最終評判五元組關系質量的數值.
本文采用加權平均判決法.
(6)
其中,FSi為規則化階段得到的隸屬度;OWi為對應隸屬集合的權重系數.在本文中,取值如下.
(7)
其中,p2,a,g1為圖2中隸屬度函數參數.
3.3.5 模板競爭 三個模板抽取的五元組關系通過上述模糊計算,得到三個output值,最高值對應的模板勝出,本次抽取結果以該模板為準.同時更新三個模板置信度,更新規則如下.
(1) 勝出的模板:
wi=wi+(1-wi)*0.001
(8)
(2) 其余模板:
wj=wj-wj*0.0005
(9)
4 實驗與評估
4.1 實驗數據
本文的實驗數據來自“法律法規數據庫”,共選取了10個與涉案財物處置相關的法律文件,其中1~4號文件用于模板初值置信度確定,5~10號文件用于算法效果測試.
通過人工對上述法律文件進行整理,共標定五元組數據1 450條.數據格式:[文件名,法條序號,法條內容,五元組].
4.2 評價指標
本文使用正確率作為評價指標對關系抽取的效果進行評估.考慮到五元組關系的特殊性,定義:
有測試結果S=[s1,s2,…,si],標定數據K=[k1,k2,…,ki].若匹配度q>0.6,則認為抽取成功.
(10)
正確率的計算方法如下.
(11)
本文同時進行了3元組和5元組抽取效果的評估,在計算3元組正確率時,i=3,計算5元組正確率時,i=5.
4.3 實驗結果
本文利用選取的涉案財物處置相關的法律文件,對基于多模板模糊競爭(MTFC)的方法進行了實驗,同時將其與單模板抽取方法(模板1、模板2、模板3)、基于非空元素數量的投票方法(NONV)進行對比.
首先,我們運用三個模板分別對1~4號文件進行關系抽取,三元組抽取正確數目的比值約為33∶37∶30.因此,我們設定三個模板初始置信度:
w1=0.33;w2=0.37;w3=0.3.
在基于多模板模糊競爭方法的實驗中,共有如下8個參數:p1,p2,a,d,g1,g2(圖2隸屬度函數參數);k1,k2(式(4)模糊規則參數).
為降低參數選取難度,設定整數參數步距為1,浮點數參數步距為0.1,并將單輪實驗參數調整數量限制為2個.實驗表明,當p1=0.3,p2=0.5,a=0.5,d=0.2,g1=0.7,g2=0.9,k1=5,k2=8時,多模板模糊競爭方法有較優的效果.在5~10號法律文件上,各方法實驗結果如表3和表4所示.可以看出,在8號文件上,多模板模糊競爭方法的五元組正確率沒有明顯的提升,但在其他情況下,多模板模糊競爭方法的正確率較其余方法,均有顯著優勢.總體來看,如圖4所示,多模板模糊競爭方法對三元組及五元組關系抽取效果明顯.
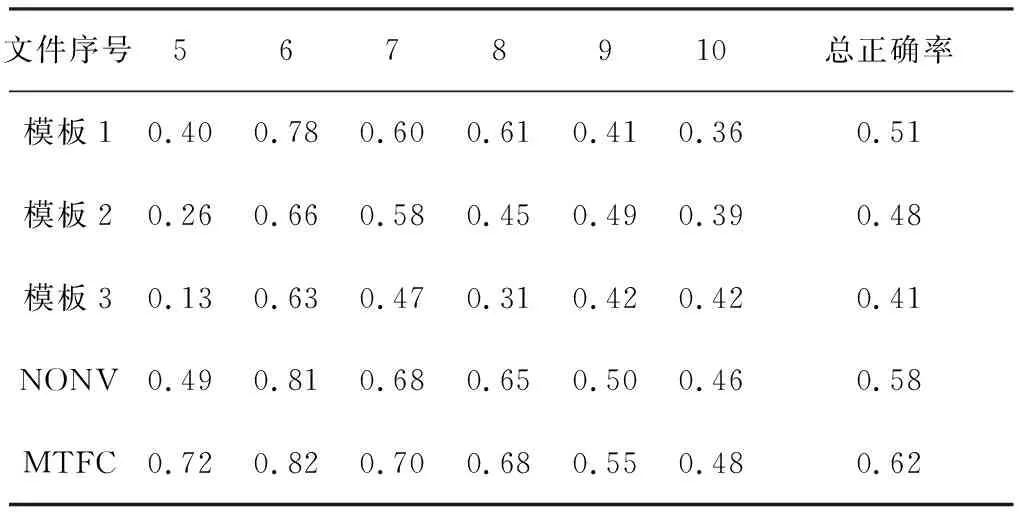
表3 三元組正確率

表4 五元組正確率

圖4 綜合正確率Fig.4 Comprehensive accuracy
5 結 論
本文提出了一種基于多模板模糊競爭的涉案財物關系抽取方法,從不同維度設計了三個涉案財物五元組關系抽取的模板,并借助模糊邏輯算法,競爭出較優的結果.實驗表明,在涉案財物關系抽取任務中,基于多模板模糊競爭的方法效果優于單模板,也優于基于非空元素數量的投票方法.因此,可以在涉案財物知識庫構建過程中引入該方法,以較好地適應其訓練語料少且單一以及識別準確率要求高的特點,為后續知識推理奠定基礎.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
