
卷積神經網絡在微博反諷語句識別中的應用
2021-07-20 08:54:36霍瑞雪白曉雷
中國新通信 2021年9期
關鍵詞:機器學習
霍瑞雪 白曉雷


【摘要】 ? ?隨著互聯網信息發布平臺日益增多,網民發表情感的方式也逐漸多元化,其中反諷這一特殊修辭手法得到了廣泛使用,對其的識別也變得日益迫切。為了更好的識別微博語料中的反諷語句,研究了一種改進后卷積神經網絡模型。卷積神經網絡是人工智能領域的一個重要組成部分,應用范圍極其廣泛,也是目前人工智能領域的研究重點。卷積神經網絡憑借著特征自主學習的優勢在自然語言處理方面有著出色的表現。通過實驗,利用特征與詞向量雙輸入的卷積神經網絡模型對反諷識別準確率有了明顯提升。
【關鍵詞】 ? ?卷積神經網絡 ? ?機器學習 ? ?反諷識別
引言:
隨著互聯網信息發布平臺的逐漸增加,網民的發布內容也變得多樣化。其中反諷作為一種特殊的表達方式,也占有相當大的比例。反諷通常是以一種正面的文字表達不屑、嘲笑等反面的信息內容,為微博平臺自身管理帶來了一定的挑戰。本文基于卷積神經網絡模型對反諷語句的識別展開研究,為微博等互聯網信息發布平臺開展內容審核提供一種新的思路。
一、技術研究路線概述
本文的主要技術路線如圖1所示,首先是對實驗數據的收集。該部分主要是對微博的數據進行爬取,過濾,清洗、標注形成初步的實驗數據集。
其次對實驗數據進行特征提取。特征主要包含兩方面,一是通過人工提取的方式,找到反諷語句共通的特征。例如:很好又要加班了,該句中的“很好……又”,就可以作為一種特征。二是通過卷積神經網絡模型中獨特的卷積層和池化層,自主提取特征。
然后使用詞向量與特征共同融入至卷積神經網絡模型。實現反諷特征、詞向量的雙輸入,提高卷積神經網絡反諷識別的準確性。
最后將經過改善的卷積神經網絡模型與傳統機器模型進行對比,并通過人工方式驗證識別效果,并持續對模型進行優化,持續提高模型的反諷文本識別準確率。
二、數據集建立與特征選擇
2.1 實驗數據集建立
為了更好的進行卷積神經網絡模型的訓練,提高準確性,本研究明確了采用監督學習的方式。監督學習需要對訓練樣本進行標注,反諷的標注過程,主要是將反諷看做二分類,若為反諷則標注為1,否則標注為0。在標注的同時對不符合要求的數據進行清洗、擴充、去噪等處理。另外為了保證標注結果的準確性,減少人工判定的偏差。在標注完成后,又采用交叉檢驗的方式,最終得到標注后的反諷語句共2888條,為了防止實驗數據集類別傾斜,影響分類的性能,需要把數據類別平衡化,又從非反諷中任意抽取了2888條語料,使得中文反諷數據集最終由反諷與非反諷各2888條語料,共5776條語料構成了反諷平衡語料庫。
2.2 特征選擇
反諷語言特征的選擇好壞與最終識別結果有著緊密的聯系,為了提取最佳的語言特征,本研究利用在文本檢測方面有著較大優勢的卡方統計法。卡方統計法首先假設特征和類別之間是相互獨立的,主要通過計算偏差來判斷相關性。當卡方值較小時,說明二者相關性不大;當卡方統計值較大時,說明選取的特征和類別相關性較高,可以作為該類別的特征。
反諷特征詞匯的選擇:
通過計算卡方值,人工提取了緊密度較高的反諷詞匯,如絕了、果然、就這、極好、不愧、牛逼、真有你的、你敢信、真是高啊等。
三、融合反諷特征的卷積神經網絡
3.1 詞嵌入向量
詞向量技術是將自然語言中的詞語轉化為稠密的向量,相似的詞會有相似的向量表示,這樣的轉化方便挖掘文字中詞語和句子之間的特征。生成詞向量的方法從一開始基于統計學的方法到基于不同結構的神經網絡的語言模型方法。到現在為止已經有很多成熟的詞向量模型,本研究中采用的是TF-IDF模型來進行詞向量的訓練。
TF-IDF模型是一種統計方法,用來衡量字詞對于文本的重要程度。字詞的重要性隨著它在當前文本中出現的頻率成正比,隨著它在語料庫中其他文本中出現的頻率成反比,因此TD-IDF也經常被用來提取文本的特征。該模型的計算公式如下:
在實驗中只要設置合適語料,就可以訓練出高質量的詞向量。
3.2 融合反諷特征與詞向量技術的卷積神經網絡模型
為了更好的提高反諷的識別精度,本研究采用詞向量與反諷特征雙輸入的卷積神經網絡模型進行訓練。具體流程:首先輸入語料,使用特征對語料進行擴展,再統一進行分詞。之后使用詞向量模型對擴展分詞后的進行使用詞向量對融合特征的句子形成矩陣。最后將矩陣輸入至卷積神經網絡模型,經過卷積層、池化層自動提取特征向量,并在全連接層進行擬合,最后在輸出層分類器sigmoid分類器進行輸出。
3.2.1輸入層
由于我們要進行識別的是反諷語句,要想使用卷積層、池化層進行特征的進一步提取就需要把語句轉化為矩陣的形式。我們實驗集的語句經過詞向量的訓練后,已經形成矩陣。
首先使用分詞工具對句子進行分詞,假設一個句子為“醉了,當著這么多人也不臉紅,是真夠厲害的”使用分詞工具進行分詞后得到的為“醉 了 , 當著 這么 多人 也 不 臉紅 , 是 真夠 厲害 的”。
3.2.2卷積層
卷積層的作用主要是用于特征的提取。和之前的人工特征提取不同,此處的特征提取是模型隨著訓練次數的增多自主提取的。考慮到本課題是對文本的識別,卷積神經網絡的過濾器只能在矩陣的列上移動才能正確的識別出特征。
3.3 具體實驗過程與結果分析
為了進一步驗證融合特征與詞向量的卷積神經網絡在反諷識別上的優勢,采用keras 深度學習的框架,在GT740顯卡上展開了實驗。
3.3.1評價指標
本課題采用的是精確率、召回率、F值三個指標作為實驗結果的評判指標。其中主要是以準確率作為重要的整體評價指標。
3.3.2參數設置
本課題反諷語料庫中20%用來做測試集。實驗中卷積神經網絡的卷積層的過濾器設置大小為[3,4,5]訓練迭代次數為20次,batch size是32,dropout率設為0.5.
3.3.3實驗結果
按照約定的把反諷語料數據劃分成了4:1的形式。實驗主要過程是對比融合反諷特征以及詞向量后的卷積神經網絡與融合反諷特征以及詞向量后詞袋模型在反諷識別上的主要差別。其中詞袋模型采用支持向量機(svm),樸素貝葉斯(NB)和隨機森林(rf)三種方法。
融合反諷特征與沒有融合詞袋模型的訓練結果對比如下所示:
由此可見,融合了反諷特征后的,傳統的機器模型識別精確度都有所提升。可見融入反諷特征在對反諷識別上具有一定的積極作用。
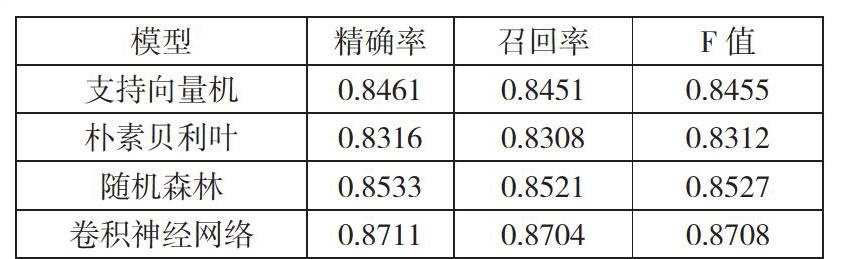
將融合反諷特征以及詞向量技術的卷積神經網絡與融合反諷特征以及詞向量技術的傳統模型進行對比,實驗結果如下:
由此可見卷積神經網絡在反諷識別上相比較傳統的機器學習模型的確優勢較為明顯。
四、結束語
針對微博反諷語句識別,本文提出了一種融合反諷特征的深度學習的模型。該方法首先對微博的反諷語料數據進行預處理,人工提取反諷語料中出現頻率較多的特征詞,之后采用分詞工具對語句、特征進行分詞,再用詞向量進行訓練,轉換成矩陣模塊,最后再采用與卷積神經網絡模型上進行訓練與對比,得到最終實驗結果相比較與傳統的分類器精確率有明顯提高,進一步驗證深度學習在反諷識別方面具有顯著優勢。
參 ?考 ?文 ?獻
[1]盧欣. 基于深度學習的中文反諷識別及其情感判別研究[D]. ?山西大學, 2019.
[2] 羅婷. ?社交網絡評論中的反語識別研究[D]. ?云南:云南財經大學, 2017.
[3] 羅觀柱. ?面向社交媒體的反諷識別[D]. ?哈爾濱工業大學, 2019.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
