基于深度學習的交通圖像識別的研究與應用
2021-07-20 11:54:36章康明曹新
軟件工程 2021年6期
關鍵詞:深度學習
章康明 曹新


摘 ?要:為了克服目標檢測算法在交通圖像識別領域對數據集利用不充分、對小物體檢測不敏感等問題,提出了一種基于SSD算法改進的檢測模型。選擇自動駕駛領域最重要的測試集作為模型訓練的數據集,通過對比實驗,選擇出訓練集、驗證集和測試集最合適的劃分比例。實驗結果顯示,合理的數據集劃分相較于其他的對照組對于檢測目標的準確率提升了13%,檢測時間縮短了15%,證明合理的數據集劃分能夠提升模型泛化能力和檢測效率。針對該算法對于小物體檢測不敏感這一問題,有針對性地調整了模型的結構及參數,并修改了模型輸入圖像的尺寸。實驗結果表明,在輸入相同圖片尺寸下,模型對于小物體的檢測能力顯著提升,整體檢測能力提升了14.5%,且保證了較高的檢測速率。以上均證明新算法的有效性。
關鍵詞:深度學習;計算機視覺;目標檢測;SSD
中圖分類號:TP311.5 ? ? 文獻標識碼:A
Abstract: Aiming at problems of insufficient utilization of datasets and insensitivity to small object detection in the field of traffic image recognition by target detection algorithm, this paper proposes an improved detection model based on SSD (Solid State Disk) algorithm. The most important test set in the field of autonomous driving is selected as the dataset for model training. Through comparative experiments, the most appropriate division ratio of training set, validation set and test set is selected. Experimental results show that compared with other control groups, reasonable dataset division has an increase of 13% in accuracy of detecting targets and a decrease of 15% ?in detection time, which proves that reasonable dataset division can improve model generalization and detection efficiency. Aiming at the problem that the algorithm is not sensitive to small object detection, structure and parameters of the model is adjusted and size of the input image of the model is modified. The experimental results show that under the same image input size, the detection capability of small objects is significantly improved, the overall detection capability is improved by 14.5%, and a higher detection rate is guaranteed. The above all prove the effectiveness of the new algorithm.
Keywords: deep learning; computer vision; target detection; SSD
1 ? 引言(Introduction)
近年來,隨著人工智能的蓬勃發展,深度學習在越多越多場景下應用,尤其是自動駕駛領域。根據IDC最新發布的《全球自動駕駛汽車預測報告(2020—2024)》數據顯示,2024年全球L1—L5級自動駕駛汽車出貨量預計將達到約5,425 萬輛,年均復合增長率達18.3%。在巨大的市場需求推動下,對自動駕駛技術的要求愈加嚴苛。駕駛環境復雜多變,對駕駛場景中的目標檢測算法模型的泛化能力有很高的要求,同時也需要保證模型的檢測速率。
目標檢測是在圖片中對可變數量的目標進行查找和分類,主要存在目標種類與數量問題、目標尺度問題以及外在環境干擾問題。目標檢測算法經過長時間的發展迭代,經過從傳統的目標檢測方法到深度學習方法的變遷。傳統的目標檢測算法主要基于傳統手工設計特征并結合滑動窗口的方式來進行目標檢測和定位,典型的代表有Viola-Jones[1]、HOG[2]、DPM[3]等。傳統目標檢測算法設計出的特征魯棒性較差,效率較低,且通過滑動窗口提取特征的方式流程煩瑣。因此在2008年DPM算法提出后,傳統目標檢測算法遇到了較大的瓶頸。
自2012年卷積神經網絡的興起,基于深度學習的目標檢測方法發展并成熟,在檢測效率和精度上有了巨大的飛躍,逐漸取代傳統機器視覺方法,成為目標檢測領域的主流算法。目前,基于深度學習的目標檢測算法分為One-Stage[4]和Two-Stage[5]。以R-CNN[6]、Faster R-CNN[7]為代表的Two-Stage檢測算法具有良好的檢測精度,但檢測速度相對較慢,無法滿足自動駕駛領域實時性需求。One-Stage采用直接回歸目標位置的方法,以YOLO[8]、SSD[9]為代表,在保證檢測精度的同時,提高了檢測速度,但不同模型也有各自的缺陷。
本文提出了一種基于深度學習的交通圖像識別算法,以SSD為目標檢測模型,使用合適的數據集劃分對模型進行訓練,并針對模型對小目標檢測性能的不足,修改模型相應的輸入尺寸,在保證多數目標檢測能力的同時,大大改善了模型對小目標的檢測能力,輔以快速的圖片檢測能力,能夠提升汽車行駛過程中的安全性,對于深度學習在交通圖片識別以及自動駕駛應用上具有參考意義。
2 ? SSD模型(SSD model)
2.1 ? 模型概述
SSD是一種One-Stage的目標檢測模型,移除了region proposals[10]步驟以及后續的像素采樣的步驟;借鑒了YOLO的回歸思想以及Faster R-CNN的anchor機制,精度可以和Faster R-CNN匹敵,速度上遠遠快于Faster R-CNN。回歸思想的引入降低了模型復雜度,提高了算法的檢測速度;anchor機制能夠檢測不同尺度的目標,提高算法檢測精度。
SSD網絡模型如圖1所示,由主干網絡和多尺度feature map預測兩部分組成。主干網絡由VGG-16組成,舍棄了FC6和FC7兩個全連接層,用于特征提取。同時在網絡后面添加八個卷積層作為多尺度feature map預測,這些卷積層在尺寸上逐漸減小,在多個尺度上對檢測結果進行預測。用于預測檢測的卷積模型對于每個特征層都是不同的。基于前饋卷積網絡,產生固定大小的邊界框集合,并對這些邊界框中存在的目標類別實例進行評分,通過非極大抑制來控制噪聲,確保網絡保留最有效地幾個預測,并產生最終的檢測結果。
2.2 ? 基本原理
2.2.1 ? 用于檢測的多尺度映射
多尺度特征映射主要為了提高檢測精度。基礎網絡后添加的一些卷積層主要用于檢測和分類。不同的特征層(Feature Layer)預測的邊界框(Bounding Box)是不一樣的,因此不同的特征層上的卷積模型也不一樣。多尺度的特征映射可以檢測不同尺度和大小的目標。
2.2.2 ? 卷積預測器
每一個添加的特征層用于一組卷積濾波產生固定的檢測預測集合。卷積預測器對這些默認框(Default Box)進行關于類別和位置的回歸,然后得出一個類別的得分及坐標偏移量。
2.2.3 ? 默認邊界框與長寬比
本文一系列默認的邊界框和各個不同的特征層聯系在一起,即每個被選中預測的特征層,在每個位置都關聯個默認框。在每個特征層的映射中,對于給定個邊界框中的每一個,本文計算個類別分數以及相對原始默認邊框的四個偏移量,并允許不同的默認邊界框,有效地離散出可能的輸出框。
2.2.4 ? NMS(非最大值抑制)
為了避免重復預測,過濾掉背景和得分不是很高的框,從而得到最終預測。
2.2.5 ? 匹配策略
在訓練過程中需要確定默認框和真值邊界框(Ground Truth Box)之間的聯系后訓練網絡。對于每一個真值邊界框,本文計算其與默認邊界框之間的杰卡德系數(Jaccard Overlap),也就是IOU,默認兩者之間的閾值大于0.5,即為正樣本。因此本文簡化了學習過程,允許網絡為多個重疊的默認邊框預測高分,而不只是挑選一個邊界框。
2.2.6 ? 損失函數
2.3 ? 網絡結構
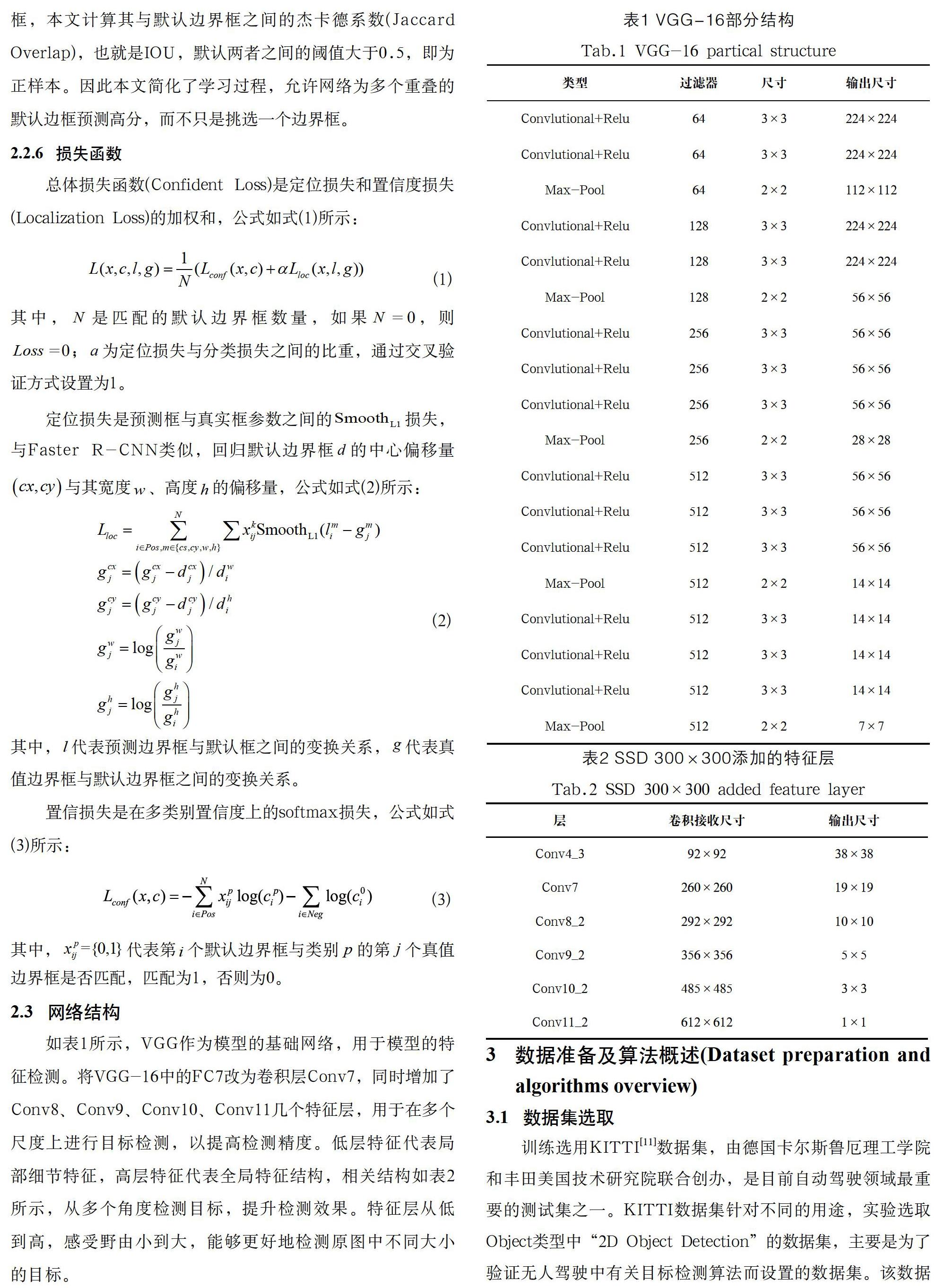
如表1所示,VGG作為模型的基礎網絡,用于模型的特征檢測。將VGG-16中的FC7改為卷積層Conv7,同時增加了Conv8、Conv9、Conv10、Conv11幾個特征層,用于在多個尺度上進行目標檢測,以提高檢測精度。低層特征代表局部細節特征,高層特征代表全局特征結構,相關結構如表2所示,從多個角度檢測目標,提升檢測效果。特征層從低到高,感受野由小到大,能夠更好地檢測原圖中不同大小的目標。
3 ? 數據準備及算法概述(Dataset preparation and algorithms overview)
3.1 ? 數據集選取
訓練選用KITTI[11]數據集,由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創辦,是目前自動駕駛領域最重要的測試集之一。KITTI數據集針對不同的用途,實驗選取Object類型中“2D Object Detection”的數據集,主要是為了驗證無人駕駛中有關目標檢測算法而設置的數據集。該數據集一共包含7,841 張訓練圖和7,518 張測試圖,包含80,256 個目標Label。所有圖像均為彩色并保存為png格式。
3.2 ? 數據集內容
KITTI數據集為攝像機視野內運動物體提供一個3D邊框標注(使用激光雷達的坐標系)。該數據集的標注一共分為八個類別:Car、Van、Truck、Pedestrian、Person、Cyclist、Tram和Misc或Don't Care。其中Don't Care標簽表示該區域沒有被標注,在訓練中可以被忽略。
3.3 ? 算法概述
3.3.1 ? 合適的數據集劃分
在數據集有限的條件下,高效利用訓練數據集能夠訓練出一個更優越的算法。將數據集按照訓練集、驗證集以及測試集進行劃分,比例分別為30∶20∶50、40∶10∶50、45∶5∶50三種;并使用相同的SSD網絡進行訓練,初始學習率為0.001,動量為0.9,權重衰減為0.0005,批處理數據大小為8,訓練次數均為80,000 次。對訓練結果進行評估,選擇最佳的數據集劃分。
3.3.2 ? 優化模型
對模型進行評估,發現模型對于較小目標檢測性能較差。因為KITTI原始數據集大小為375×1242,而原始模型輸入大小為300×300,對輸入圖片的壓縮導致檢測效果下降,因此將模型輸入的尺寸大小修改為384×1280,以提升模型的檢測精度。
4 ?實驗與結果分析(Experiments and results analysis)
4.1 ? 實驗環境
本文實驗所用的環境如下:
硬件環境:Intel(R) Core(TM) i5-6300HQ CPU @ 2.30 GHz、NVIDIA GTM965M。
軟件環境:Ubuntu 18.04 LTS、CUDA 10.0 cuDNN 7.4.2、TensorFlow 1.14.0-gpu、Python 3.6.9、conda 4.9.2。
4.2 ? 評價標準
4.2.1 ? FPS
4.2.2 ? 準確率和召回率
TP:正確劃分為正例的個數,即實際為正例且被分類器劃分為正例的實例數。
FN:錯誤劃分為正例的個數,即實際為負例但被分類器劃分為正例的實例數。
FP:被錯誤劃分為負例的個數,即實際為正例但被分類器劃分為負例的實例數。
TN:被正確劃分為負例的個數,即實際為負例且被分類器劃分為負例的實例數。
TP、FP、FN、TN可用來計算表示目標檢測模型精度的多個指標。
本文中的實驗使用mAP評價模型的精度。
4.3 ? 實驗結果
4.3.1 ? 改進數據集的劃分比例
按照3.3.1中的算法描述對模型進行訓練,初始學習率為0.001,動量為0.9,權重衰減為0.0005,每次批處理數據大小值設置為8,訓練次數均為80,000 次。訓練過程中部分loss圖像得到結果如表3所示。
4.4 ? 結果分析
根據4.3.1的實驗結果所示,充分利用數據集對模型進行訓練,能夠顯著提升模型的泛化能力。實驗結果顯示,合理的數據集劃分,相對于其他對照組對于檢測目標的mAP提升了13%,檢測時間縮短10%,證明本文提出的數據集劃分能夠有效提升模型的泛化能力和檢測速率,且在幾個重要的檢測目標上具有較高的AP,能夠勝任一般交通場景的目標檢測需求。
本文使用的KITTI數據集分辨率較高,而SSD本身對于小物體識別的準確率并不高,為了解決模型對小物體檢測不敏感這一問題,本文對模型進行修改,將模型的輸入尺寸提升為384×1280。根據4.3.2的實驗結果所示,Cyclist類別的AP從0.2311提升到了0.4179,Pedestrian類別的AP從0.0909提升到了0.3709,Car類別的AP從0.6754提升到0.6942等,整體的mAP提升了接近14%,證明使用本文提出的算法對小物體的檢測能力提升顯著,同時還微弱提升了其余物體的檢測能力,均證明了本文提出新算法的有效性。模型的部分檢測過程和檢測結果如圖2和圖3所示,本文實現的算法模型通過使用分辨率較大的KITTI數據集更真實地模擬現實場景,同時通過對模型的優化,在提升對小物體檢測精度的情況下,依舊保持較佳的檢測速率,大大提升了模型的整體檢測效率。
5 ? 結論(Conclusion)
為了進一步模擬真實駕駛場景下目標檢測的性能,本文提出一種基于SSD的深度學習交通檢測識別算法。實驗結果顯示,利用本文提出的算法檢測準確率和檢測效率明顯優于未經過本文算法優化的檢測算法。在KITTI數據集上的mAP達到0.47,FPS為26.76 fps,不影響其余檢測類型的前提下,提升了模型對小物體的檢測精度,同時保證了模型的檢測速率,滿足了目標檢測中對檢測速度和檢測精度的一般要求,證明本文提出的算法在交通圖像識別領域具有實用和參考價值。
參考文獻(References)
[1] WANG Y Q. An analysis of the Viola-Jones face detection algorithm[J]. Image Processing On Line, 2014, 104(4):128-148.
[2] TORRIONE P A, MORTON K D, RAYN S, et al. Histograms of oriented gradients for landmine detection in ground-penetrating radar data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2013, 52(3):1539-1550.
[3] OUYANG W, ZENG X, WANG X, et al. DeepID-Net: Object detection with deformable part based convolutional neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(7):1320-1334.
[4] CHEN L L, WEN L F, BIAN X, et al. Fast single shot multibox detector and its application on vehicle counting system[J]. IET Intelligent Transport Systems, 2018, 12(10):1406-1413.
[5] GE Z, JIE Z, HUANG X, et al. Delving deep into the imbalance of positive proposals in two-stage object detection[J]. Neurocomputing, 2021(425):107-116.
[6] HAN X F. Modified cascade RCNN based on contextual information for vehicle detection[J]. Sensing and Imaging, 2021, 22(1):1-10.
[7] 閆新慶,楊喻涵,陸桂.基于改進Faster-RCNN目標檢測算法研究[J].中國新通信,2021,23(01):46-48.
[8] 孫乾宇,張振東.基于YOLOv3增強模型融合的人流密度估? ? ?計[J].計算機系統應用,2021,30(04):271-276.
[9] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[J]. Computer Vision, 2016, 9905(12):21-37.
[10] 王冠,耿明洋,馬勃檀,等.基于孿生區域候選網絡的目標跟蹤模型[J].小型微型計算機系統,2021,42(04):755-760.
[11] GEIGER A, LENZS P, STILLER C, et al. Vision meets robotics: The KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11):1231-1237.
作者簡介:
章康明(1998-),男,本科生.研究領域:軟件開發,計算機視覺.
曹 ?新(1980-),女,碩士,教授.研究領域:車聯網,無線傳感器網絡.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
