敵手能力有限時基于生成對抗網(wǎng)絡的保密增強
2021-07-22 17:02:26李西明吳嘉潤吳少乾
計算機與生活 2021年7期
李西明,吳嘉潤,吳少乾
1.華南農(nóng)業(yè)大學 數(shù)學與信息學院,廣州 510000
2.暨南大學 計算機科學系,廣州 510632
保密增強是由Bennett 等人在文獻[1]中提出,文獻[2]加以推廣。保密增強是指通信雙方Alice 和Bob在共享一個部分保密的串S 且敵手Eve 只知道該串的部分信息的情況下,通過在公共信道上進行協(xié)商來提取一個更短的但是高度保密的串S′,使Eve關于S′的信息幾乎可以忽略。保密增強方面的研究在近年來也有一些進展,文獻[3]通過增大計算能力的差距,保證接收方與敵手接收到的信息量差距隨時間變大,實現(xiàn)了單信道加密通信;文獻[4]在無保護的持續(xù)信道下,重復地通過Merkle 謎題產(chǎn)生新的密鑰,并且使用上一次解開的密鑰對最新的謎題進行加密,從而實現(xiàn)防御多樣本的攻擊。
生成對抗網(wǎng)絡(generative adversarial networks,GANs)是由生成器與判別器所組成,其核心在于生成器和判別器之間的博弈。生成器生成虛假的數(shù)據(jù),而判別器負責辨別數(shù)據(jù)真?zhèn)巍烧咄ㄟ^博弈后生成器能夠生成以假亂真的數(shù)據(jù)。自Goodfellow 等人[5]提出后,GANs 被廣泛地應用于各個領域,并且取得了很好的效果。特別是在計算機視覺方面的應用,包括利用物體2D 圖片進行3D 重構[6]、利用人臉圖片生成年齡增長時各年齡段的人臉圖片[7]等。另外,在信息檢索[8]、文本生成[9]等領域中也取得了令人矚目的成果。
2016 年Google Brain 團隊Abadi 等人[10]利用生成對抗網(wǎng)絡進行了安全通信方面的研究。該通信模型由通信雙方Alice、Bob 以及竊聽方Eve 組成。Alice與Bob 的通信通過共同的密鑰對明文進行加密解密。竊聽方Eve 在沒有密鑰的情況下竊聽Alice 與Bob 之間的通信信息。在模型訓練的過程中,Alice與Bob 雙方要保證能夠通過相同密鑰進行正常通信的情況下,抵抗Eve 對通信內(nèi)容的竊聽。Eve 則需要通過訓練盡量準確地破解出Alice 與Bob 之間傳遞的明文。在對抗訓練后得到一個能夠抵抗竊聽的加密通信模型。李西明等人[11]基于Abadi等人的模型進行改進,利用生成對抗網(wǎng)絡的方法初步實現(xiàn)了對稱密鑰下的模糊密鑰加密通信方案,同時,他們對文獻[11]的模型繼續(xù)改進[12],實現(xiàn)了密鑰泄漏情況下的安全通信,發(fā)現(xiàn)了利用對抗網(wǎng)絡實現(xiàn)抗泄漏加密通信的可能性。Gomez 等人[13]以CycleGAN 思想為基礎,提出了CipherGAN 模型,對移位密碼[14]和維吉尼亞密碼[15]進行破譯,表明模型可用于推斷未成對明文和密文庫的底層密碼映射。
本文研究使用生成對抗網(wǎng)絡來解決在敵手通信能力或計算能力受限的情況下保密增強的問題。本文首先設計了基于生成對抗網(wǎng)絡的保密增強的基本架構,然后使用文獻[10]的Alice 和Eve 的基本模型,設置神經(jīng)網(wǎng)絡輸入為80 位的通信信息,輸出結果為16 位的密鑰。對通信雙方及敵手的神經(jīng)網(wǎng)絡模型進行增加全連接層、修改激活函數(shù)方面的改進,改進后的神經(jīng)網(wǎng)絡模型通過對抗訓練可實現(xiàn)保密增強的通信。本文貢獻主要有以下兩點:
(1)結合保密增強的概念,以神經(jīng)網(wǎng)絡的思路實現(xiàn)該概念,設計相應的網(wǎng)絡框架。
(2)利用生成對抗網(wǎng)絡的對抗學習機制模擬通信雙方與敵手的對抗關系,進行對抗訓練,最終利用通信雙方的密鑰一致性來體現(xiàn)出保密增強功能。
1 技術背景
GANs 由兩個獨立的部分組成:生成器G(z)和鑒別器D(x)。生成器的目標是基于隨機變量z~pz(z)生成真實的數(shù)據(jù)樣本,而鑒別器的任務是將真實的數(shù)據(jù)樣本x~pdata(x)與生成的樣本~pg(x)區(qū)分開來。這兩個模型以一種對抗的方式訓練,本質(zhì)上是玩一個兩人游戲,目標是收斂到納什均衡。同時,D和G的訓練可以表示為關于值函數(shù)V(G,D)的極小化極大的雙方博弈問題:

Abadi等人在其論文[10]中利用神經(jīng)網(wǎng)絡構建加密通信模型中的通信雙方Alice 與Bob 以及敵手Eve,使用GANs 的原理進行對抗訓練得到敵手存在時的加密通信模型。
其工作場景如圖1 所示。Alice 需要向Bob 發(fā)送一條信息,信息為明文P(Plaintext)。Alice 通過密鑰K(key)對明文P進行加密得到密文C(ciphertext)。密文C傳遞給Bob 的過程中,Eve 能夠準確地獲得密文C。Bob 通過密文C與密鑰K解密得到PBob,而Eve 通過密文C解密得到消息PEve。Alice 和Bob 組成的加密解密模型與Eve 敵手模型進行對抗訓練,兩者互相學習提升,最終使得PBob=P,而PEve與P存在盡可能大的差異。

Fig.1 Alice,Bob and Eve in symmetric encryption system圖1 對稱加密系統(tǒng)中的Alice、Bob 和Eve

Fig.2 Alice,Bob and Eve structures of neural network圖2 神經(jīng)網(wǎng)絡Alice、Bob 和Eve結構
Abadi 等人實驗所使用的Alice 與Bob 的神經(jīng)網(wǎng)絡模型相同,而Eve 比Alice 與Bob 多一層全連接神經(jīng)網(wǎng)絡,如圖2 所示。Alice 的輸入為明文P以及密鑰K,輸出為密文C。Bob 的輸入為密文C以及密鑰K,輸出為消息PBob。Eve 的輸入為密文C,輸出為消息PEve。通過對抗訓練后,Alice 的加密能力得到增強,相應地Bob 的解密能力也得到提升,最后能夠保證PBob=P。同時Eve 解譯的消息PEve只有一半的內(nèi)容是與P吻合的,說明其解密結果與隨機生成數(shù)據(jù)的情況相似,并未獲得更多有用的信息。
2 保密增強的模型設計
保密增強的應用場景需要假設敵手在計算或通信這兩方面的某一方面弱于通信雙方,因此從兩個方向展開。首先設計出實驗采用的基礎模型,然后根據(jù)不同的應用場景修改基礎模型。
2.1 基礎模型設計
在一般的保密增強場景中,如圖3 所示,Alice 與Bob 進行公開信道上的通信,兩者之間所交流的信息Information 被Eve 所竊聽,即:對某個很小的ε>0,式H(S′|Z=z)≥lb|S′|-ε以很高的概率成立,其中Z代表Eve 所知道的關于S′的全部信息,z是Eve 所知道的Z的某個具體值[11-12]。Alice 與Bob 在交流一段時間后通過兩者交流的內(nèi)容各自提取一份保密的密鑰,且兩者提取的密鑰相同,同時需要保證Eve 無法準確通過竊聽的交流內(nèi)容合成密鑰。
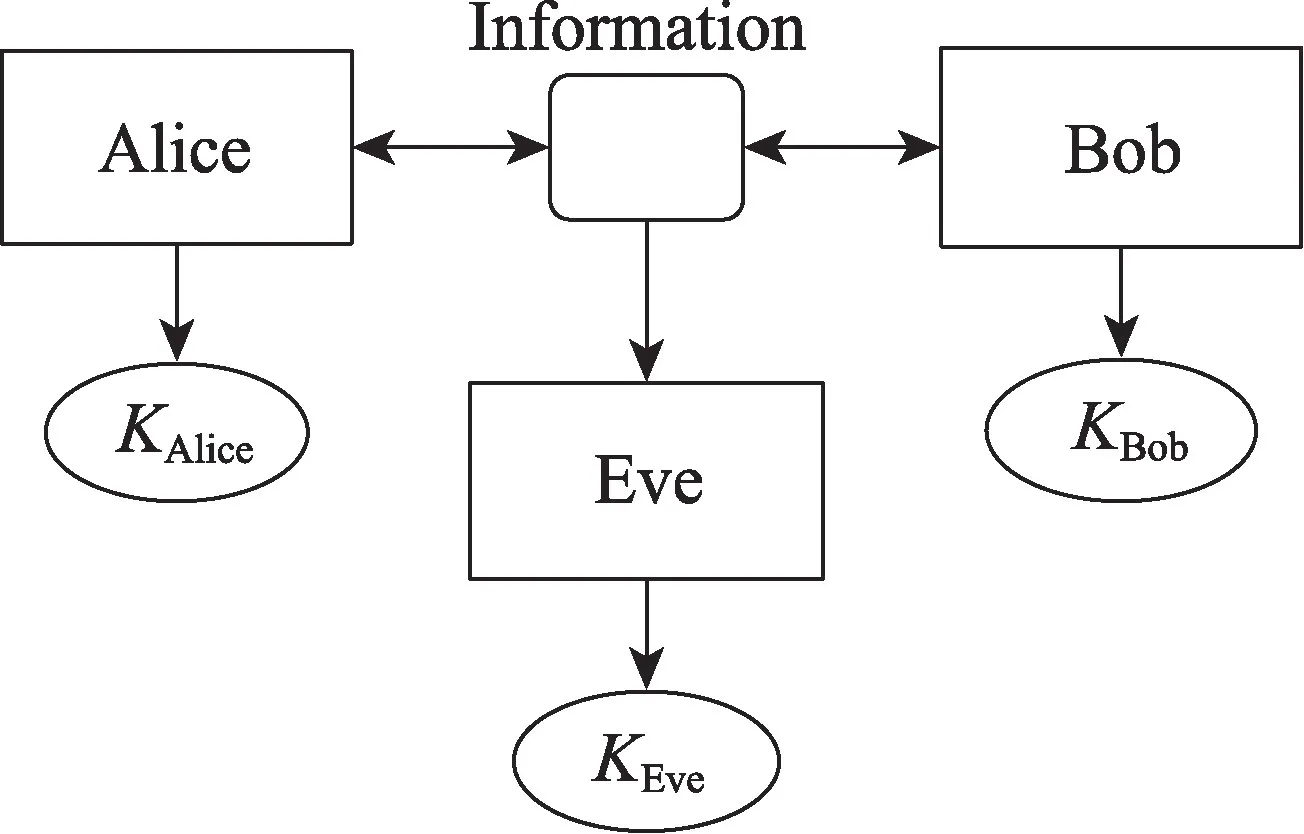
Fig.3 Security enhancement scenario diagram圖3 保密增強場景圖
本文受Abadi 等人啟發(fā),設計了保密增強模型。為了簡化模型,更利于模型訓練,在圖3 的場景圖基礎上進行了修改。剔除了Alice 與Bob 之間的交流過程,只保留密鑰生成的部分,提出了新的模型場景圖,如圖4 所示。

Fig.4 Experimental scene diagram圖4 實驗場景圖
Alice 和Bob 共享一份弱保密的信息,Eve 掌握了這份信息的一部分信息,而這份信息是Alice 與Bob交流過程中產(chǎn)生的數(shù)據(jù),利用這些數(shù)據(jù)經(jīng)過神經(jīng)網(wǎng)絡模型的訓練得到密鑰一致性,以此實現(xiàn)保密增強的功能。隨機生成Information 作為數(shù)據(jù)輸入,Alice、Bob 與Eve 分別產(chǎn)生密鑰KAlice、KBob和KEve,密鑰均由16 個數(shù)值的數(shù)組組成,Information 由80 個數(shù)的數(shù)組組成。為方便模型訓練,Information 的每一個位的數(shù)取為1 或-1,密鑰的每一個位的數(shù)取[-1,1]之間的值。
由于實驗中Alice 與Bob 均需保證生成的密鑰兩者之間相同,而且與Eve 的盡量有差異,Alice 與Bob可以是完全相同的兩個模型,最終實現(xiàn)中復制Alice模型作為Bob 模型,因而本文的實驗中只對Alice 和Eve進行訓練。
模型中采用Adam 優(yōu)化器進行優(yōu)化,進行20 輪的迭代訓練,每一輪中迭代訓練2 000 次,在每一次訓練中,生成器和判別器的MiniBatch-Size 的比例為1∶2,因此,假設n為迭代輪數(shù)的大小,m為每一輪的訓練次數(shù),經(jīng)分析可以得到實驗的時間復雜度為O(2nm)。Alice 通過訓練保證生成的密鑰與Eve生成的密鑰差異盡量得大,而Eve 在訓練的過程中盡力生成與Alice 更為接近的密鑰。兩者在此過程中不斷地進行對抗訓練,最終達到模型訓練的目標,即實現(xiàn)Alice 與Eve 生成的密鑰只有一半的內(nèi)容是相同的,即Eve 在生成密鑰的過程中純粹是猜測,無法從交流信息Information 中提取有效的信息。
實驗中的模型結構圖如圖5 所示,模型的輸入只有Information,而在Abadi等人設計的模型中Alice是有兩個輸入的,因此需要對Alice 的模型進行修改。把Alice 的輸入端修改成一個輸入,并且Eve 的模型采用與Alice 相同的結構,卷積層均采用了Same padding 方法進行填充,每一層的激活函數(shù)如圖5所示。
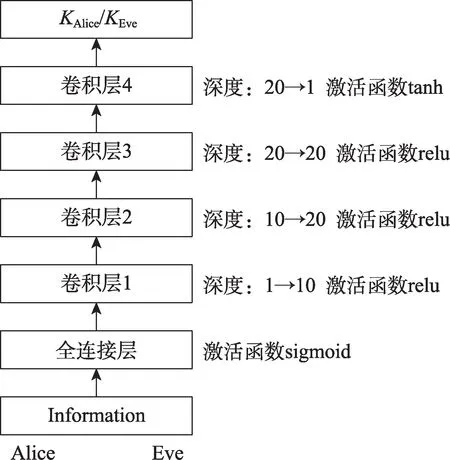
Fig.5 Structure of neural network Alice and Eve圖5 神經(jīng)網(wǎng)絡Alice與Eve的結構

為了對保密增強造成的解密損失進行評估,本文給出了Eve損失率計算公式,具體見式(1)。其中,N為密鑰K的長度。因為密鑰各位取值為1或-1,損失率衡量的是KEve與KAlice相同的位差的平均值,因此LEve的取值范圍為[0,2]。
以下為Alice損失計算的方法,見式(2)。

Alice 的損失是判別LEve是否接近于1,由于接近1 時代表著Eve 的密鑰正確率只有一半,說明Eve 處于隨機猜測狀態(tài),學習到的信息較少。因此Eve 學習到的信息越少,Alice的損失也就越小。
2.2 通信能力受限敵手
若要假設敵手的通信能力受限,可以假設敵手在獲取Information 時出現(xiàn)遺漏,敵手Eve 只能從部分的信息中解析密鑰。需要在2.1 節(jié)模型的基礎上修改Eve 的Information 輸入,使其能夠獲取原本信息的50%、70%和85%,并分別進行實驗。
2.3 計算能力受限敵手
若要假設敵手計算能力較差,通過增強Alice 的計算能力以此達到效果。因此在2.1 節(jié)模型(即圖5所示)的基礎上,增強Alice 模型的復雜度。將激活函數(shù)為tanh 的全連接神經(jīng)網(wǎng)絡添加到第一層中,同時修改前3 層卷積激活函數(shù)為Leaky relu,即模型結構由兩層全連接神經(jīng)網(wǎng)絡和4 層卷積神經(jīng)網(wǎng)絡組成。由于最后一層的激活函數(shù)會影響最終輸出結果的值域,因此不予以修改。
3 保密增強模型實驗
本文的實驗環(huán)境為64 位的Linux 系統(tǒng),3.40 GHz的Intel i7-6800K CPU 處理器,利用Python3 進行實現(xiàn)。本文作為概念驗證實驗,采用由1 和-1 組成的隨機生成串作為初始數(shù)據(jù),利用Tensorflow 的Adam 優(yōu)化器對訓練過程進行不斷的迭代優(yōu)化,模型的學習速率設為0.000 8。
3.1 通信能力受限敵手
根據(jù)2.2 節(jié)設計相應模型,然后進行通信能力受限敵手的保密增強實驗,最終實驗的結果如圖6所示。

Fig.6 Loss when enemy Eve gains partial information圖6 敵手Eve獲得部分信息時的損失
實驗表明在Eve 獲得85%的信息時并不能保證通信雙方能協(xié)商出安全的密鑰,Eve 的損失是0.7 即Eve 能夠破解的信息可以達到65%,因此通信環(huán)境是不安全的。當Eve 獲取70%信息時,Eve 的損失可以提升到0.8,相比獲取85%信息時安全性有一定的提升。當Eve 獲得50%的信息時,能夠保證Eve 的損失維持在1,即能夠保證Eve 破解的信息僅有50%,因此Eve處于隨機猜測狀態(tài),并未解開密鑰。
雖然模型在Eve 獲得50%信息時運行的效果尚可,但是由前面的實驗圖可知模型的損失非常不穩(wěn)定,波動很大,甚至有從損失為1 瞬間降到0 的情況。
考慮到卷積網(wǎng)絡所使用的激活函數(shù)為relu 函數(shù),該函數(shù)容易出現(xiàn)神經(jīng)網(wǎng)絡神經(jīng)元死亡,而引發(fā)訓練停滯的情況,有可能是模型損失波動大的原因。因此把Alice 與Eve 的卷積網(wǎng)絡的relu 激活函數(shù)均改為Leaky relu。Leaky relu 能夠保證神經(jīng)網(wǎng)絡避免出現(xiàn)神經(jīng)元死亡的現(xiàn)象,而死亡神經(jīng)元出現(xiàn)原因在文獻[16]中已指出,損失圖如圖7 所示。

Fig.7 Loss diagram after using Leaky relu function圖7 使用Leaky relu 函數(shù)后的損失圖
實驗結果表明,在使用了Leaky relu 函數(shù)后整個模型的損失穩(wěn)定了下來,并沒有大幅度的波動而且能夠保證Eve 獲取70%的信息時仍能保證信息的安全。
前面的實驗使用的卷積網(wǎng)絡過濾器比較大,目的是希望過濾器提取特征時能夠同時考慮更多的數(shù)據(jù),但是缺點是提取特征時可能會把信息過度濃縮,因此嘗試把過濾器和卷積核大小減小。具體的網(wǎng)絡層信息如下所示:
卷積層1 過濾器大小為4×1,卷積核為2,步長為1,激活函數(shù)為relu 函數(shù);
卷積層2 過濾器大小為2×2,卷積核為4,步長為5,激活函數(shù)為relu 函數(shù);
卷積層3 過濾器大小為1×4,卷積核為4,步長為1,激活函數(shù)為relu 函數(shù);
卷積層4 過濾器大小為1×4,卷積核為1,步長為1,激活函數(shù)為tanh 函數(shù)。
調(diào)整參數(shù)后的實驗結果如圖8 所示。由圖可知,整體的效果都有很大的提升,基本上都能夠保證敵手的損失在0.8 以上。在所有情況下均能夠保證信息的安全。

Fig.8 Adjust convolutional network parameters圖8 調(diào)整卷積網(wǎng)絡參數(shù)
3.2 計算能力受限敵手
根據(jù)2.3 節(jié)設計相應的模型,然后進行計算能力受限敵手的保密增強實驗,分別對Alice 增加全連接層以及Alice 增加全連接層的同時修改激活函數(shù)的兩種情況進行了實驗,最終實驗的結果如圖9 所示。

Fig.9 Enhance Alice's computing power圖9 增強Alice計算能力
由實驗結果可知,在增強了Alice 模型的計算能力后,基本上能夠很穩(wěn)定地保證密鑰信息沒有泄漏給敵手Eve,Eve 的損失維持在1.0 附近。說明通過增強Alice 來保證密鑰信息安全是可行的,同時發(fā)現(xiàn)在修改激活函數(shù)后,模型能夠更快地達到最優(yōu)解的狀態(tài)。
4 結束語
本文利用生成對抗網(wǎng)絡解決了在敵手能力受限時的保密增強問題,分別給出了在敵手通信能力受限或者計算能力受限時的保密增強方案。基于Abadi等人提出的安全通信模型,經(jīng)過一系列對模型進行的修改,實現(xiàn)了在通信信息量為80 位的情況下,能夠保證在敵手獲知70%通信信息時,或者在敵手計算能力受限時信息傳遞的安全性。本文為保密增強提供了一個新的實現(xiàn)思路,設計出了新的模型架構,并且通過實驗證明了思路的可行性。但本文僅從增加神經(jīng)元、修改激活函數(shù)以及修改過濾器的角度進行優(yōu)化。對于保密增強的問題,還可以從敵手存儲能力受限、增加通信信息的位數(shù)、更強的加密能力的神經(jīng)網(wǎng)絡、為神經(jīng)網(wǎng)絡添加記憶單元等方面入手。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
