聯合總變率空間和時延神經網絡的說話人識別
2021-07-22 17:02:34瞿于荃邵玉斌杜慶治
計算機與生活 2021年7期
關鍵詞:模型
瞿于荃,龍 華,2+,段 熒,邵玉斌,2,杜慶治,2
1.昆明理工大學 信息工程與自動化學院,昆明 650000
2.昆明理工大學 云南省計算機國家重點實驗室,昆明 650000
說話人識別(speaker verification,SV)屬于生物認證領域的一種技術,是一項根據說話人語音中代表說話人生理和行為的特征參數,來判別說話人身份的技術。起初的短語音問題還沒能得到廣大信號處理界的重視,有些研究員們僅僅從側面提到了短語音問題[1],并未成為說話人識別的重點。由于說話人識別對樣本語音的時長非常敏感,短時語音的識別性能的好壞,是決定其能否商業化的關鍵一步。隨著說話人系統實際項目的落地,短語音問題開始被重視起來。由于實際生活環境的限制,收集目標用戶長時間的語音數據不易,而在短語音條件下獲得的有效信息較少,這樣就無法提取足夠的說話人身份信息,直接導致識別性能的降低。在21 世紀初期,高斯混合模型通用背景模型(Gaussian mixture model universal background model,GMM-UBM)[2]的提出解決了注冊說話人語料不足的問題,它的成功應用標志著說話人識別的興起。隨后,聯合因子分析(joint factor analysis,JFA)[3]則對說話人變率空間和信道變率空間分別建模,以其高性能引領了說話人識別進入一個新時代。繼而,基于總變率空間的身份向量(identity vector,i-vector)[4]成為了近十年來說話人識別研究的基線標準。直至深度學習流行的今日,身份向量仍占據一席之地。近來,針對短語音說話人識別的問題,大致思路分為兩方面。一是特征層面,增加特征有效維度是短語音的常用方法,它能有效提高識別率。然而,特征維數的增加,勢必加大計算的復雜度和維度災難的風險。文獻[5]將聲學特征進行特征融合后生成高維特征矩陣,再利用主成分分析(principal component analysis,PCA)降維;利用說話人特征信息在高頻區域更為突出的特點,文獻[6]提出使用線性頻率倒譜系數(linear frequency cepstral coefficients,LFCC)提取短語音說話人嵌入向量;針對Baum-Welch 統計量的不足,文獻[7]通過聯合通用背景模型中的參數信息,增加說話人的個人信息表達;文獻[8]利用神經網絡極強的特征提取能力,提出了使用時延神經網絡(time-delay neural networks,TDNN)提取語音的嵌入向量x-vector。針對x-vector 的不足,文獻[9]提出將語譜圖輸入進時延神經網絡代替傳統聲學特征,并在統計池化層使用注意力機制增強關鍵幀的信息。二是模型層面,對于傳統支持向量機模型,文獻[10]運用多個核函數的線性組合構造多核空間實現短語音下說話人識別。而深度學習的崛起,席卷整個語音處理界,人們開始嘗試不同模型應用在短語音說話人識別上。文獻[11]將話語視為圖像,將深度卷積架構直接應用于時頻語音表征,像人臉識別一樣學習短時說話人嵌入。文獻[12]提出使用生成式對抗網絡(generative adversarial networks,GAN)的i-vector 補償方法來代替概率線性判別模型(probabilistic linear discriminant analysis,PLDA)在短語音下所出現的估計偏差。文獻[13]使用圖像特征金字塔(feature pyramid network,FPN)對多尺度聚合(multi-scale aggregation,MSA)進行改進,提高處理變化時長下話語的魯棒性;然而,訓練深度神經網絡[14]需要大量的數據,而用于說話人識別的可用數據量通常非常小。這一直是使用深度學習構建端到端說話者識別系統的最大障礙之一。
本文從特征方法出發,提出使用典型聯合分析方法從總變率空間的i-vector 向量和TDNN 網絡的xvector 向量中學習線性關聯信息,再從投影矩陣中抽取相關向量組合成為新向量,以此增強說話人身份信息。在短注冊和短測試語音環境下,實驗結果證明,融合超向量在注冊和測試時長不匹配問題條件下均對說話人識別等誤差率有下降的作用。
1 總變率空間模型
說話人語音的長短不一,讓學者耗費大量的精力去尋求一種技術可以從變化長度的語音中獲得恒定長度表示說話人身份信息。i-vector 的出現為這種想法開創了先河,使得文本無關的說話人識別上升到了新高度。由聯合因子分析(JFA)理論獲得啟發[4],Dehak 提出從高斯混合模型的均值超向量中提取更加緊湊的身份向量,即i-vector。i-vector 模型利用因子分析來構造總變率空間(total variability space),對說話人差異和信道差異共同進行建模。假設說話人的一段語音,該語音的高斯均值超矢量可由下式表示:

其中,m為通用背景模型的高斯均值超矢量,T為總變率空間矩陣,ω為總變率空間因子,其后驗均值就是身份向量i-vector。身份向量模型的重點就是總變率空間矩陣的估計和身份向量的提取。
1.1 總變率空間矩陣的估計
總變率空間矩陣的估計[15]用最大期望算法,提取Baum-Welch 統計量,計算隱藏因子的后驗分布,更新模型參數,迭代多次直至停止,最后得到總變率空間矩陣。前提條件是已訓練好一個通用背景模型。
步驟1給定第s說話人第h句話,有若干幀{Y1,Y2,…}組成,對于每一個高斯分量c,計算零階、一階Baum-Welch 的統計量如下:

其中,mc為高斯分量所對應的均值矢量。對于t時刻,γt(c)是第t幀Yt相對每個高斯分量c的狀態占有率,換句話說,第t時刻落入狀態c的后驗概率,其值可以表示為:

步驟2計算總變率空間因子ω的后驗分布。對于第s個說話人的第h段語音總變率空間因子記為ωs,h,令l(s)=I+TTΣ-1Nh(s)T:

Σ為UBM 的各階協方差矩為對角塊的對角矩陣。
步驟3最大似然值重估更新模型參數矩陣T和最大化似然函數值,得到如下:

對于每一個高斯混合分量c=1,2,…,C和特征參數的每一維d=1,2,…,P,令i=(c-1)P+d,Ti表示T的第i行,Ωi表示Ω的第i行,則說話人總變率空間矩陣T的更新公式如下:

1.2 抽取身份向量
步驟2、步驟3 在設置一定的次數迭代更新,完成總變率空間矩陣訓練后,由式(6)得到每個說話人對應的身份向量i-vector。這里,目標說話人的模型訓練的過程和i-vector說話人向量抽取就到此結束。
短語音下的說話人識別的困難很大程度上可以歸結于注冊和測試時長語音數據的不匹配。雖然通用背景模型中的均值超向量可以通過每個人的總變率因子來共享一些統計信息,在一定程度上減輕短語音帶來的影響,但從式(2)~(4)看來,總變率空間的估計很大程度上依賴于Baum-Welch 統計量的計算,而語音數據量過少勢必造成統計量估計的偏差。對于GMM-UBM、i-vector 等基于語音概率分布的統計模型來說,短語音下的語音分布必然存在偏差,使得估計的說話人特征在統計上變得不那么可靠。
2 時延神經網絡模型
深度學習中的嵌入(embedding)是一項非常流行的技術,它的原理是取一個低維稠密的向量表示一個對象。“表示”代表著embedding 向量能夠表達相應對象的某些特性,同時兩個embedding 向量之間的距離反映了對象之間的相像性。比較典型的:graph embedding 中圖像為對象的deepwalk[16];word embedding 中文字為對象的word2vec[17];隨著深度學習在語音識別方面火熱進行,說話人識別深受影響。而xvector 是由Snyder 從時延神經網絡(TDNN)[18]中提取的voice embedding 特征,并像i-vector 一樣使用。時延神經網絡的結構如圖1 所示,由此看來,TDNN 更像是一個一維卷積的過程,這樣的架構更適合語音序列信息的處理。將分幀后的語音輸入進TDNN 網絡,網絡中的統計池化層會負責將幀級特征映射至話語級特征上,具體操作為計算幀級特征的均值和標準差。在統計池化層之后的全連接層用于抽取embedding 向量,網絡最后一層為softmax 層,輸出的神經元數量與訓練集中說話人個數保持一致。由于TDNN 是時延架構,利用其網絡結構的優點可以學習不同時長的特征,這也讓x-vector 在注冊測試不同時長語音上表現出更強的魯棒性。
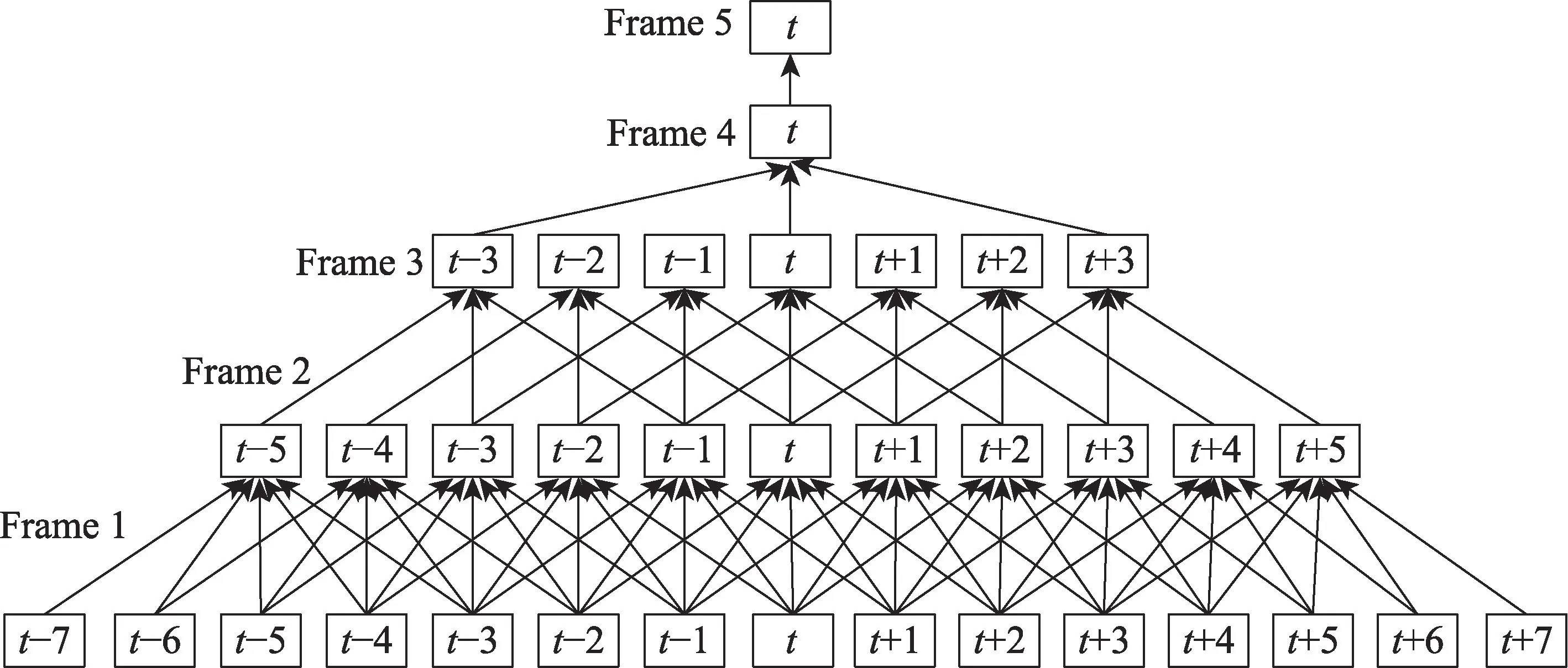
Fig.1 Time delay neural network structure圖1 時延神經網絡結構
傳統基線DNN(deep neural networks)網絡中,DNN 僅僅只對輸入層的語音特征做了前后若干幀的擴展,在輸入層擁有上下文信息,而TDNN 與DNN 不同之處在于TDNN 對其中的隱藏層也進行上下文的拓展,TDNN 會將隱層當前時刻的輸出與前后若干時刻的輸出組成在一起,以此作為當前時刻下一個隱藏層的輸入。由此來看,TDNN 中的每一層都被給予了上下層級的時間信息,對于處理時序數據是非常有效的。
3 聯合總變率空間和時延神經網絡模型
同為生物識別技術,說話人識別許多的技術都是借鑒于人臉識別的經驗,比如信道補償的概率線性判別模型(PLDA)[19]、Face net以及新引入的代價函數三元組損失(triplet loss)。典型關聯分析(canonical correlation analysis,CCA)[20]可以被看作是為兩組變量間尋求基向量的問題,由此變量在基向量上的投影之間的相關性就可以相互最大化,這樣可以聯合特征提高分類的效果。CCA 主要在人臉識別中多視圖學習的特征融合方面,在驗證目標人身份時,利用不同信息的人臉照片進行多視圖信息學習。ivector 的獨到之處在于它結構簡單,只考慮說話人差異和信道差異兩部分,這讓它在文本無關方面優勢明顯。x-vector 是話語層級提取的嵌入特征,更符合說話人在多段話語中的一個平均代表。兩種向量都能單獨代表說話人,且又從不同形式下表征說話人獨有的信息。典型相關分析尋求一對線性轉換,每組變量對應一對,當這組變量被轉換時,對應的表示說話人的向量就會最大程度相關,聯合兩個向量組成說話人超向量,用來增強說話人信息。
假設訓練階段總變率空間,TDNN 已被訓練。那么注冊和測試階段,每個說話人的i-vector 身份向量表示為I=(i1,i2,…,in)T,x-vector 向量為X=(x1,x2,…,xn)T,對于I其對應的投影向量為α,對于X,對應的投影向量為β,令Z=[I X]T,則:

設W=αTI,V=βTX,計算W、V方差和協方差:

由Pearson 相關系數可得優化目標為:

其中,cov(W,V)為W、V協方差,而σW、σV分別是I、X標準差,優化的目標是:

構造Lagrangian 等式對式(16)進行求解:

式(17)分別求導令等于0 得:

式(18)分別左乘αT和βT,結合式(16)得:
λ=θ(19)

將式(20)中下式帶入上式得:

將式(20)中上式帶入下式得:


Fig.2 Model combining total variability space with TDNN圖2 聯合總變率空間和時延神經網絡模型
流程如圖2 所示。訓練階段,分別訓練總變率空間和時延神經網絡。建立一個獨立說話人的適應集提取i-vector 和x-vector 用來學習總變率空間與TDNN在說話人表示上的線性關系,i-vector 用來學習關聯性的輸入矩陣I,維度為P1×N,x-vector 學習關聯性的輸入矩陣X,維度為P2×N,獲得r個投影向量拼接為矩陣形式,其中N是適應集說話人話語數,P1為總變率空間維度,本次實驗取400 維,P2為TDNN全連接層第一層輸出維度,同文獻[21]保持一致取512 維。若仍使用訓練集提取說話人向量,說話人已存在訓練集之中,不能表達集外說話人的普適特性,使用適應集目的為解決CCA 學習中說話人的泛化能力和魯棒性問題。注冊和測試階段,提取i-vector 和x-vector 與投影變換α、β矩陣映射,得到一組線性關聯向量,組合得到超向量xi-vector。
4 實驗與分析
4.1 實驗設置
語料庫選自Librispeech 英文演講集、TIMIT 英文集,共1 257 人。語料庫分為注冊集、適應集、測試集和訓練集。注冊集為100 個說話人;測試集與注冊集說話人對應,適應集為500 個說話人,剩余人數為訓練集。特征預處理設置同i-vector、x-vector 原文獻保持一致:預加重系數0.95,幀長25 ms,幀移10 ms,使用基于能量的端點檢測對語音去靜音。總變率空間設置方面:通用背景模型和總變率空間的訓練集保持一致,高斯混合度為512,總變率空間維度400,20維梅爾倒譜系數(Mel frequency cepstrum coefficient,MFCC),以及一階、二階差分[6]。提取i-vector,使用LDA(linear discriminant analysis)降維至200 維,以及PLDA 信道補償和相似度打分。時延神經網絡方面:TDNN 網絡結構與文獻[21]保持一致,特征取24 維FilterBank,提取x-vector 向量,后端與i-vector 保持一致。
4.2 實驗指標
本次實驗使用的說話人指標為等誤差率(equal error rate,EER)。EER定義如下式:

式中,Pfrr(θ)為錯誤拒絕率(false rejection rate),Pfar(θ)為錯誤接受率(false acceptance rate)。stws為冒充者測試得分(spoof trials with score),tst為總冒充次數(total spoof trials);htws為正確測試得分(human trials with score),tht為總正確測試次數(total human trials);θ為判斷兩語音為同一人閾值,Pfrr(θ)和Pfar(θ)隨著θ變換而發生變化,當θ=θEER時,使Pfrr(θ)、Pfar(θ)值相等,該值為EER,其中:

以錯誤接受率為橫坐標,錯誤拒絕率為縱坐標,做檢測錯誤權衡圖(detection error tradeoff,DET),反映說話人識別系統性能。
4.3 實驗分析
首先,在不同注冊和測試時長下,分別統計了三種說話人向量的等誤差率。通過表1 的實驗結果和圖3 的DET 曲線可以看出,固定說話人測試語音為全時長,注冊時長為30 s 時,xi-vector 的誤差率相比ivector、x-vector 下降了6.15%和15.2%;20 s 時,同比下降7.02%和15.6%;10 s 極短注冊語音下,分別下降6.5%和29.6%。面對逐漸縮短的短語音任務,短注冊語音給i-vector 帶來的問題是對說話人語音分布估計的偏差,注冊說話人的身份偏差導致即使使用全時長的語音去測試說話人也不能獲得較好的等誤差率。而時延神經網絡也會遇到相同的問題,雖然能夠利用自身結構學習上下文的相關信息,但為了加速計算而會選擇在輸入層對語音進行固定時長的分塊操作,直接造成了短注冊語音被再次分割和剔除,上下文信息的捕獲變得少之又少。從整體變化來看,i-vector 等誤差率上升幅度較大也印證了基于統計模型對于短語音的魯棒性能力較差的缺點,而x-vector上升幅度趨緩的表現得益于時延神經網絡連接softmax 的架構,所取出的x-vector 在說話人分類上有著極強的區分能力,這也讓x-vector代替i-vector成為近幾年說話人識別挑戰賽的基線系統。xi-vector 在上升幅度中有著最好的表現,它在三者之中保持了短語音下較好的魯棒性,聯合總變率空間的信道變化,說話人差異變化的同時又有著時延神經網絡的超強分類器能力。

Table 1 EER of each vector under different registered speech lengths表1 不同注冊語音長度下各向量的等誤差率

Fig.3 DET of each vector under different registered speech lengths圖3 不同注冊語音長度下各向量的檢測錯誤權衡圖
值得注意的是,在全時長注冊和測試語音下,xivector 的效果并沒有i-vector 和x-vector 的好,原因就在于基于總變率空間提取i-vector 的說話人差異性和基于時延神經網絡提取x-vector 的分類性在全時長下都可以完全表達說話人個人信息,反而聯合總變率空間和時延神經網絡下的xi-vector 在結合兩者之間線性關系在某種情況下成為一種冗余。x-vector等誤差率最低也說明在全時長注冊和測試的情況下,基于時延神經網絡的x-vector已經能達到較好的性能。
通過表2 的實驗結果和圖4 的DET 曲線可以看出,固定注冊時長為全時長,測試時長為10 s 時,xivector 的等誤差率相比i-vector、x-vector 分別下降了4.01%和15.8%,5 s測試語音時,相比分別下降6.0%和22.1%,3 s 短測試語音下,分別下降了1.7%和12%。盡管注冊說話人已經得到了充分的注冊,短測試語音下總變率空間對語音概率估計不足的問題,讓測試i-vector 缺少區分不同人的能力,而時延神經網絡輸入的語音特征在短測試語音下并沒能在上下文關系上給予信息的共享。xi-vector 對上述情況做出補償,在i-vector 和x-vector 學習線性關聯關系,以結合的方式增強說話人個人信息,這一點讓xi-vector 在短測試環境下優于前兩者。整體來看,本文所提出的聯合總變率空間和時延神經網絡的新向量xi-vector,在短注冊和短測試環境下,與基線i-vector、x-vector相比表現最佳,系統性能較基線系統有了良好改善,尤其是在極低時長環境下,依然有著較為理想和穩定的等誤差率。

Table 2 EER of each vector under different test speech lengths表2 不同測試語音長度下各向量的等誤差率

Fig.4 DET of each vector under different test speech lengths圖4 不同測試語音長度下各向量的檢測錯誤權衡圖
最后,更換數據集為aidatatang 中文普通話數據集和Primewords 中文語料庫,旨在驗證本文算法對中文語料下的處理能力以及與不同針對短語音的改進技術的文獻在等誤差率上進行對比。設置中文語料庫注冊集為100 人,測試集與注冊集人數對應。其余實驗細節部分與上述實驗保持一致。短語音時長設置方面,固定注冊時長為全時長,測試語音劃分為10 s、5 s和3 s三部分,固定測試時長為全時長,注冊語音劃分為30 s、20 s、10 s三部分,總計6 個短語音條件下對文獻[5]、文獻[6]、文獻[7]、文獻[9]和xi-vector 進行實驗,對比結果如圖5 所示。
從圖5 可以看出,固定全時長注冊語音,在10 s測試語音下,xi-vector 比文獻[5]、文獻[6]、文獻[7]、文獻[9]在等誤差率上降低了44.46%、7.67%、39.9%、9.33%;5 s 測試語音下,xi-vector 相比下降30.16%、8.36%、25.03%、6.44%;3 s 測試語音下,xi-vector 相比下降30.41%、5.36%、22.21%、5.15%。固定全時長測試語音,在30 s 注冊語音下,xi-vector 在等誤差率上同比降低了32.74%、2.56%、26.89%、2.57%;在20 s 注冊語音下,xi-vector 在等誤差率上同比降低30.01%、7.42%、18.45%、7.2%;在10 s 注冊語音下,xi-vector 在等誤差率上同比降低26.9%、9.37%、18.68%、6.53%。文獻[5]所使用特征融合再進行降維的方法,通過對淺層特征融合達到增強說話人信息的行為,但任何降維都導致原始信息的損失,而同樣是以總變率空間作為說話人模型的文獻[7]借助通用背景模型增強短語音下的Baum-Welch 統計量,但人為選擇超參量的方法對統計量進行融合,在不同環境下應用的魯棒性還有待商榷。文獻[6]提取線性頻率倒譜系數代替傳統梅爾倒譜系數特征,并且將i-vector 與x-vector在提取后直接串聯實現融合,但串聯的方法增加維度的同時,并不能有效提升識別性能。文獻[9]是基于時延變率空間的基礎,將語譜圖作為x-vector輸入,并在統計池化層上添加注意力機制對幀級信息疊加權值,但是對于語音序列來說,使用注意力機制的缺點是忽略了序列中的上下文順序關系,這樣其實浪費了TDNN 網絡的優勢。相比上述文獻,xi-vector 聯合i-vector 和x-vector 的說話人信息,進行說話人識別在等誤差率上均優于上述針對短語音所改進的i-vector與x-vector 算法。有一點值得考慮的是,xi-vector 在優化誤差率的同時也增大了計算量和負載量,對于實時性要求嚴格的識別系統來說,運算時間可能是本文算法的一大挑戰,相比實時性,本文算法更合適于離線識別,要求精度較高的說話人識別系統,比如軍隊以及公安刑偵等方面。

Fig.5 EER comparison of various documents under different speech lengths圖5 不同語音長度下各文獻等誤差率對比
總體來看,在注冊測試語音不匹配條件下,xivector 在中文數據集的等誤差率比英文數據集上的表現上升了4.87%、9.21%、7.72%、10.19%、6.29%、6.36%,這說明xi-vector 在中文語料庫下的性能沒有英文下的好。原因可能是所使用的Librispeech 與TIMIT 是相對純凈的數據集且語音的長度分布較為均勻,可以保證注冊語音的長度足夠長而不需要進行拼接的操作,而實驗所使用的數據集的特點是較短語句,且大部分語音都在日常移動設備聊天應用上采集,更加貼近現實生活的說話人識別使用情況。另外一個原因是,所采用數據集的采集設備情況不一,所造成各個說話人之間的信道差異也有所不同,雖然實驗后處理使用PLDA 進行信道補償,但整體來說對基于總變率空間的模型產生些許影響。
綜上所述。本文實驗在英文語料庫下對xi-vector進行測試,在實驗中均比i-vector、x-vector 等說話人嵌入向量在等誤差率上有所下降;同時,在中文語料庫中對幾種針對短語音改進說話人向量的方法進行對比發現,xi-vector 在等誤差率上均低于其余幾種方法,實驗證明了本文算法的有效性。
5 總結
短語音條件下收集說話人語音信息的不足,嚴重制約了說話人現實商用的落地。針對短語音條件下總變率空間對不同時長魯棒性不足的問題,本文結合時延神經網絡,提出一種聯合總變率空間和時延神經網絡的短語音說話人識別方法。通過典型關聯分析兩者的關聯性,并將其嵌入向量進行投影,組合成新向量xi-vector 以獲取更加豐富的說話人信息超向量。實驗證明,將本文方法應用在說話人識別方面,能夠有效降低在短注冊語音或短測試語音中說話人識別的等誤差率,改善了說話人識別在短語音環境下的時長不匹配的魯棒性問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
