基于機器學習的阿爾茲海默癥初期行為辨識方法*
2021-07-23 08:44:24楊邦坤汪樂生聶穎熊文平
生物醫學工程研究 2021年2期
楊邦坤,汪樂生,聶穎,熊文平△
(1.武漢大學中南醫院神經外科,武漢 430071;2.武漢市第一醫院兒科,武漢 430033)
1 引 言
隨著人口老齡化進程的加快,老年人患阿爾茲海默癥的幾率日益上升[1]。阿爾茲海默癥病情復雜多樣,其不僅給患者和家人的正常生活帶來重大危害,還對醫療機構以及國家造成沉重負擔。目前,阿爾茲海默癥的診斷方法主要由醫生根據患者的MRI圖像對病情進行判斷,主觀性較強,且風險性較高[2-3]。雖然無法避免老年人的患病風險,但在患病初期階段進行干預治療,可有效控制病情,因此,正確辨識阿爾茲海默癥初期行為尤為重要。
目前相關的研究成果有很多,如卓奕楠等[4]和郁松等[5]分別使用多模態典型相關特征表達和3D-ResNet方法辨識阿爾茲海默癥初期行為,兩者均具有較穩定、準確的辨識效果,但辨識精度仍需進一步細化,且耗時、延遲較高。
近年來,機器學習被廣泛應用于各個領域,本研究基于機器學習的阿爾茲海默癥初期行為的辨識方法,通過核支持向量機和十折交叉驗證保證辨識效果,為阿爾茲海默癥初期行為辨識準確性的提高和臨床診斷提供可靠依據。
2 材料與方法
2.1 基于機器學習的阿爾茲海默癥初期行為辨識流程
基于機器學習的阿爾茲海默癥初期行為辨識流程見圖1。
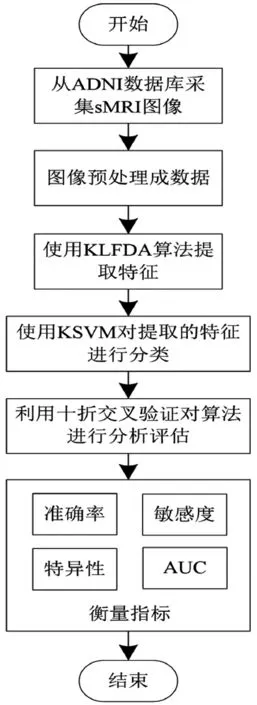
圖1 機器學習算法流程圖
2.2 數據預處理
以ADNI公共數據庫作為本研究的數據來源,在432例受檢者中包含126例阿爾茲海默癥(AD)、258例輕度認知障礙(MCI)和48例正常對照組(NC)。從數據庫獲取sMRI圖像,詳情見表1。將各受檢者的sMRI圖像,通過Freesurfer軟件執行圖像平滑、分割、時間層校正等操作,使其轉換為282個sMRI數據[6-8],詳情見表2。

表1 sMRI圖像詳情

表2 sMRI數據詳情
2.3 特征提取
使用內核局部Fisher判別分析算法(KLFDA)提取sMRI數據特征[9-10],具體步驟如下:
(1)將采集的原始數據集執行標準化操作,劃分為訓練與測試兩組數據集。
(2)局部類間圖,用Gb描述;局部類內圖,用Gw描述;對訓練數據集的兩圖進行創建。
(5)內核局部類間散度矩陣,用KLb描述;內核局部類內散度矩陣,用KLw描述;對二者進行計算。
(6)LLbα=λKLwα表示新廣義特征方程,與λ(即最大特征值)相對應的αopt(即特征向量),可通過對該方程執行計算獲得。
2.4 基于核支持向量機的數據分類算法
使用核支持向量機(KSVM)分類提取的sMRI數據特征。
設置測試樣本,用V={v1,...vj,...vm}描述,式(1)描述了KSVM的決策函數:
(1)
訓練樣本以及對應的類別標簽,分別用xi、yi描述;偏差項用b描述;拉格朗日乘子,用αi描述;核矩陣用k描述[11-13]。
式(2)描述了徑向基函數內核的形式:
(2)
核中尺度因子用σ表示,徑向基函數內核樣本以及對應的類別標簽分別用xm、xn描述。將解決優化問題的公式帶入投影訓練式內,得到式(3)描述的KSVM訓練函數:
(3)
樣本數用N表示,KSVM訓練樣本以及對應的類別標簽分別用ym、yn描述,投影訓練樣本以及對應的類別標簽,分別用αm、αn描述。
2.5 十折交叉驗證
為保證辨識準確性,利用十折交叉驗證進行分析評估。將原始數據集劃分為10個子樣本,9個子樣本對算法進行訓練,1個子樣本對算法進行測試,每次操作后均會得到KSVM算法的訓練準確率及測試準確率,各子樣本均需驗證,重復操作10次,對10次結果求平均值,即KSVM算法的最終分類結果[14-15]。
2.6 衡量指標
衡量本研究方法的性能,可通過靈敏度(SEN)、曲線下面積(AUC)、準確率(ACC)、特異性(SPE)及受試者工作特征曲線(ROC)五個指標完成[16-18],定義如下:
(4)
(5)
(6)
正確分類的患者數量用TP描述;患者分類為正常對照組的數量用FN描述;正常對照組分類正確的數量用TN描述;正常對照組分類為患者的數量用FP描述。分類精度越高,AUC值越大,ROC曲線越向左上角靠近[19-20]。
3 結果與分析
以ADNI數據庫中432例受檢者的sMRI圖像作為實驗對象,驗證本研究方法的有效性與可行性,受檢者詳情見表3。

表3 受檢者詳情
實驗分析十折交叉驗證的評估性能,以AD和NC兩組數據作為測試對象,將其分別賦值為2、5,共計174例,劃分的測試樣本數為18,利用十折交叉驗證得到的分類結果與真實結果的對比情況,見圖2。

圖2 十折交叉驗證分類結果與真實結果對比
實驗分析對AD和NC、MCI和NC以及AD和MCI三種情況的辨識效果,并設計對比實驗,選擇基于多模態典型相關特征表達的阿爾茲海默病辨識方法(多模態辨識方法)[4]和基于3D-ResNet的阿爾茲海默癥辨識方法(3D-ResNet辨識方法)[5]作為本研究的對比方法,三種方法的靈敏度、特異性、準確率以及曲線下面積四個指標的統計結果分別見圖3、圖4和圖5。

圖3 不同方法對AD-NC的辨識結果

圖4 不同方法對MCI-NC的辨識結果

圖5 不同方法對AD-MCI的辨識結果
使用受試者工作特征曲線(ROC)評估三種方法對AD-NC、MCI-NC和AD-MCI三種情況的辨識效果,結果見圖6。

圖6 受試者工作特征曲線評估結果
4 討論
由圖2可知,利用十折交叉驗證得到的分類結果與真實結果基本一致,僅有1個樣本分類錯誤,分類準確率為94.44%。由此說明,十折交叉驗證具有較好的算法評估性能,可保證本研究方法的KSVM算法評估準確性。
由圖3和圖4可知,本研究方法對AD-NC及MCI-NC兩種情況的分類靈敏度、特異性、準確率、曲線下面積四個指標均優于其它兩種方法,且數值在95%以上;與之相比,3D-ResNet辨識方法對AD-NC的各項分類指標數值最低,僅為73%、80%、79%、82%;多模態辨識方法對MCI-NC的各項分類指標數值最低,分別為80%、77%、82%、72%。
由圖5可知,本研究方法對AD-MCI的分類指標數值仍保持最高,而其它兩種方法的分類指標數值大幅度下降。對比可知,3D-ResNet辨識方法與多模態辨識方法的分類性能相對較差,尤其是對阿爾茲海默癥和輕度認知障礙(AD-MCI)之間的辨識效果不明顯;本研究方法具有較優異的分類性能,不僅能在患者與健康人之間進行有效辨識,在兩類不同患者中,依舊能獲得較好的辨識效果,阿爾茲海默癥初期行為辨識能力優勢顯著。
由圖6可知,本研究方法的受試者工作特征曲線最靠近左上角,分類精度較高;3D-ResNet辨識方法的受試者工作特征曲線距離左上角最遠,分類精度低。由此可以說明,本研究方法具有更好的阿爾茲海默癥初期行為辨識效果,其次是多模態辨識方法,3D-ResNet辨識方法的效果最差。
5 結論
為及時發現阿爾茲海默癥患者大腦的早期病變,本研究基于機器學習的阿爾茲海默癥初期行為辨識方法,使用KLFDA算法提取經預處理的sMRI數據特征,并利用KSVM算法對其進行分類,完成阿爾茲海默癥初期行為辨識。為獲得更精準、穩定的分類性能,使本研究方法更好地用于阿爾茲海默癥初期行為辨識,后續會增加人口統計學資料、功能性磁共振成像等數據類型,并擴大樣本的數據量,為阿爾茲海默癥的臨床診斷提供科學、可靠的數據支持。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
