一種HMM的藏語安多方言文本分析方法
2021-07-24 14:00:34蘇麗
新一代信息技術(shù) 2021年3期
蘇 麗
(山東外事職業(yè)大學(xué),山東 威海 264504)
0 引言
藏族是我國少數(shù)民族之一,藏語是一門古老的語言,分為安多方言、拉薩方言、康方言。其中,安多方言是保留藏語古面貌較多的方言,有其特殊的語言現(xiàn)象。藏族豐富的古籍著作文化僅次于漢族,漢語和藏語同屬于漢藏語系,如果能夠借助語言技術(shù)分析研究安多方言,可促進(jìn)漢藏語言的交流,對保護(hù)藏族文化,推動藏族科技、經(jīng)濟(jì)、社會、文化的發(fā)展具有重要意義。
目前,安多方言主要從語言學(xué)進(jìn)行研究,例如,安多語料的設(shè)計(jì);安多方言音調(diào)習(xí)得的研究[2];安多方言農(nóng)區(qū)話的研究[3];安多尖扎話的音位的研究[4]等。但是,從工程語言的角度對藏語安多方言進(jìn)行建模分析的研究比較欠缺。
將目前語音合成的[5-9]發(fā)展技術(shù)運(yùn)用于藏語的合成中,加快藏族的快速發(fā)展。
1 基于HMM的藏語安多方言的合成原理
將文本信息通過計(jì)算機(jī)轉(zhuǎn)換成自然流暢的語音是語音合成的基本原理。語音合成包括三個系統(tǒng)模塊,即文本分析、韻律預(yù)測和語音合成。文本分析是將文本進(jìn)行預(yù)處理、規(guī)范語法信息;韻律預(yù)測是控制語音的重音、時長等信息。HMM語音合成的框架圖如圖1所示。

圖1 HMM 語音合成的框架圖Fig.1 Framework of HMM speech synthesis
基于隱馬爾可夫模型(Hidden Markov Model,HMM)的語音合成系統(tǒng)的設(shè)計(jì)中,通過對藏語安多方言文本進(jìn)行文本分析,得到安多方言文本的單因素(聲韻母)標(biāo)注信息和上下文標(biāo)注信息;在合成階段將單因素標(biāo)注信息、上下文標(biāo)注信息進(jìn)行轉(zhuǎn)換合成輸出語音。單因素標(biāo)注是提取藏語安多方言的聲韻母信息;上下文標(biāo)注主要標(biāo)注了每個基元上下文的相關(guān)信息,主要指其位置信息。我們的研究思路是:通過對藏語安多方言文本的字丁分解和拉丁轉(zhuǎn)型[10]的優(yōu)化,實(shí)現(xiàn)其聲韻母的分離(如圖2所示),從而獲得藏語安多方言文本的聲韻母信息;再通過藏語安多方言書寫的特殊分隔符,得到詞、短語、句子的分割信息;最后通過設(shè)計(jì)標(biāo)注信息算法生成標(biāo)注信息,提供語音合成的必要參數(shù)。如圖3所示,此過程主要包括訓(xùn)練和合成兩個階段[11-17]。
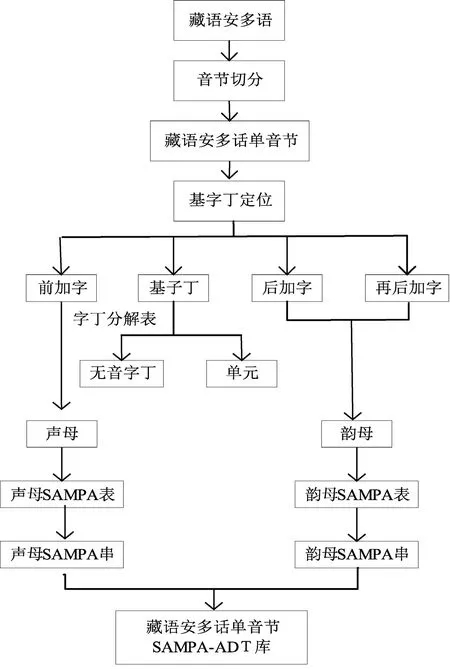
圖2 SAMP A-ADT轉(zhuǎn)換流程圖Fig.2 Flow chart of SAMPA-ADT conversion

圖3 基于HMM的統(tǒng)計(jì)參數(shù)語音合成原理圖Fig.3 Schematic diagram of statistical parameter speech synthesis based on HMM
2 安多方言文本分析
2.1 安多方言的SAMPA分析
國際通用的機(jī)讀音標(biāo) SAMPA(Speech Assessment Methods Phonetic Alphabet),可表示音標(biāo)所有符號,藏語和漢語屬于漢藏語系,根據(jù)漢語音標(biāo),標(biāo)注安多方言音標(biāo)。
根據(jù)漢語國際音標(biāo) SAMPA-SC[18](Speech Assessment Methods Phonetic Alphabet for standard-Chinese),設(shè)計(jì)安多出音標(biāo) SAMPA-ADT(Ando dialect Tibetan)漢語和藏語中部分語法相同[19]。音標(biāo)一致時直接轉(zhuǎn)寫,不一致時利用鍵盤上已有的符號,設(shè)計(jì)安多方言的SAMPA-ADT進(jìn)行標(biāo)記。其流程圖如4所示。
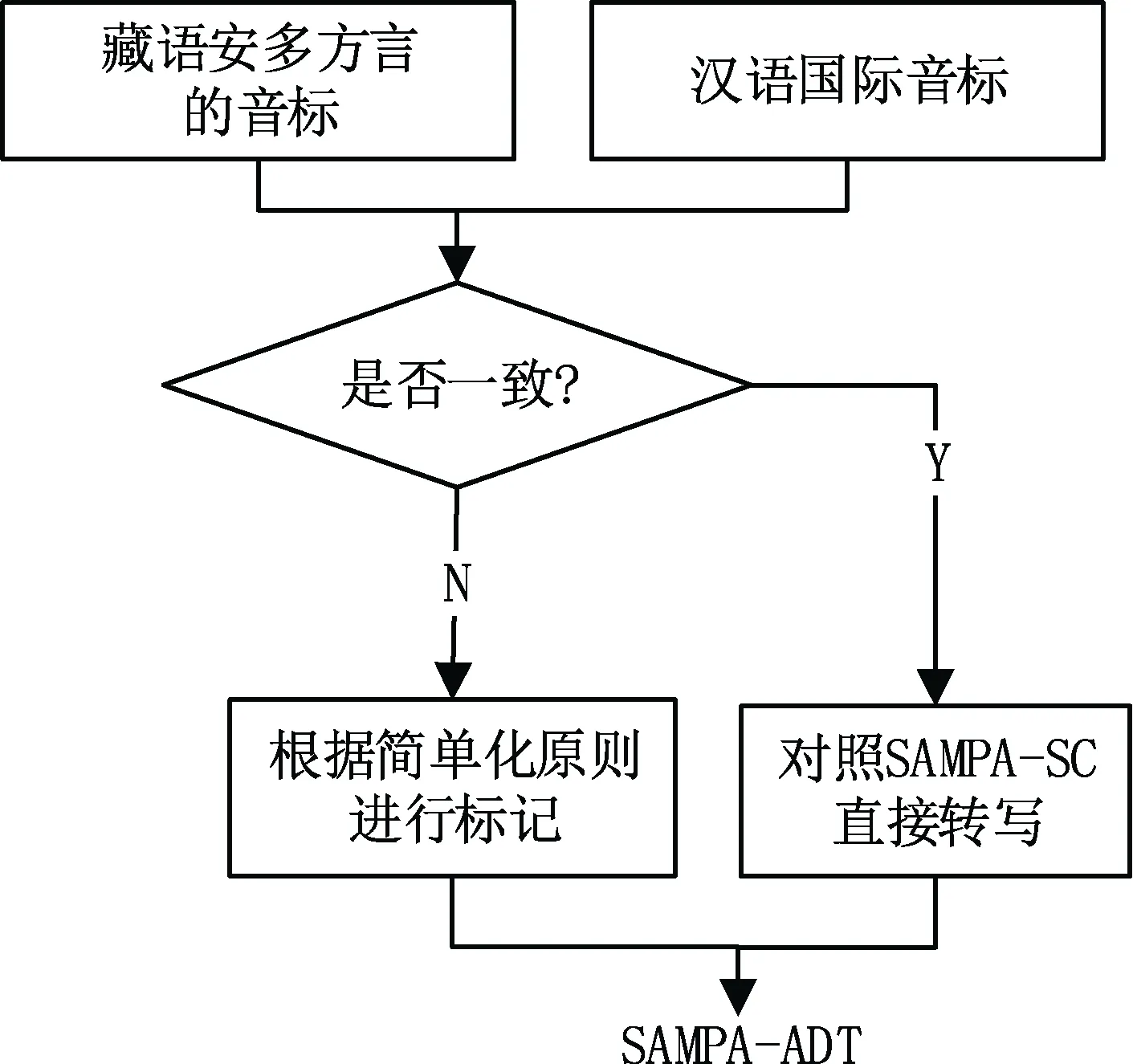
圖4 SAMP A轉(zhuǎn)寫規(guī)則Fig.4 The rules of SAMPA's transliteration
2.1.1 聲母的SAMPA-ADT設(shè)計(jì)
藏語安多方言中,聲母有55個,包括27個單輔音與28個復(fù)輔音,其中有19個單輔音與漢語音標(biāo)相同,有7個單輔音與28個復(fù)輔音與漢語國際音標(biāo)不同。
聲母SAMPA-ADT的設(shè)計(jì)如下:(1)漢語國際音標(biāo)可直接用ASCII字符表示。安多方言聲母的SAMPA-ADT機(jī)讀音標(biāo)與漢語國際音標(biāo)一致的可直接進(jìn)行表示,輔音聲母 b、x、g、z、d、dz在SAMPA-ADT中與國際音標(biāo)字母相同,其對應(yīng)的機(jī)讀音標(biāo) SAMPA-ADT 分別標(biāo)記為/b/、/x/、/g/、/z/、/d/、/dz/;(2)其他藏語安多方言音標(biāo),在漢語國際音標(biāo)的基礎(chǔ)上用鍵盤上其它符號表示與其關(guān)聯(lián)的 SAMPA-ADT;(3)送氣與不送氣的發(fā)音效果不同,為區(qū)別這一特征,定義了送氣符號。例如,/sh/所定義的具體機(jī)讀音標(biāo) SAMPA-ADT則標(biāo)記為/s_h/。
2.1.2 韻母SAMPA-ADT的設(shè)計(jì)
安多方言中共有35個韻母,其中包含6個單元音韻母/a/、/o/、/i/、/u/、/?/、/e/,3 個復(fù)元音韻母/ao/、/ai/、/eo/ 以及26個帶輔音韻尾的韻母。元音中帶韻尾的韻母分別為/e/、/o/、/a/、/?/與韻尾 l、p、?、m、n、r相結(jié)合所形成,而/u/、/i/這兩個元音與任何韻尾都不能相結(jié)合。
安多方言中除/o/、/a/、/e/、/i/、/u/這 5 個可直接輸入,/?/SAMPA-ADT設(shè)計(jì)為“^”我們分兩步設(shè)計(jì)元音和帶輔音韻尾的韻母。安多方言韻母的設(shè)計(jì)方式與拉薩方言的基本一致。
綜上可知,國內(nèi)外學(xué)者對人力資本與企業(yè)價值關(guān)系的研究大多采用單一維度的時間序列數(shù)據(jù)或截面數(shù)據(jù),聚焦于具體的行業(yè)或企業(yè)進(jìn)行分析。由此,本文針對商業(yè)銀行這一特殊金融服務(wù)行業(yè),采用包含時間序列與截面兩個維度的面板數(shù)據(jù)進(jìn)行建模分析。
2.2 文本分析
文本分析模塊是對輸入的文本信息進(jìn)行處理,使其成為計(jì)算機(jī)可理解的語言,其主要工作是對文本規(guī)范化處理。分析文本中的詞邊界、句子邊界信息,是將文本或文字中約定俗成的書寫形式,轉(zhuǎn)化成標(biāo)準(zhǔn)書寫形式,確定其正確讀音。因此,通過語法規(guī)范知識庫對文本進(jìn)行規(guī)范化處理,可轉(zhuǎn)換成為標(biāo)準(zhǔn)書寫格式,如濾除系統(tǒng)不能識別的字符,全角轉(zhuǎn)換成半角,檢查字符的規(guī)范性等。
2.3 韻律處理
韻律處理主要是對句子的重音、時長、停頓、語調(diào)以及韻律結(jié)構(gòu)的處理。對語音韻律的時長、基頻、普參數(shù)等信息進(jìn)行處理,可確定經(jīng)文本分析后語句的輕重音、停頓以及具體發(fā)音,將每個特征參數(shù)存儲形成語音庫。
2.4 上下文相關(guān)標(biāo)注格式設(shè)計(jì)
基于HMM的語音合成系統(tǒng)中,需準(zhǔn)備訓(xùn)練的標(biāo)注文件。文本標(biāo)注是將語言環(huán)境的信息符號化處理,主要是不同位置音節(jié)的重音、時長等語境信息,利用文本分析程序自動生成標(biāo)注文件,需對上下文標(biāo)注格式進(jìn)行設(shè)計(jì)。我們選取安多方言的所有聲韻母為合成基元。設(shè)計(jì)安多方言的上下文標(biāo)注格式。共6層,分別是聲韻母層、音節(jié)層、字層、詞層、短語層和語句層。各層描述分別如下:
聲韻母層:描述當(dāng)前聲韻母、前一聲韻母、后一聲韻母的信息。
音節(jié)層:描述當(dāng)前音節(jié)、前一音節(jié)、后一音節(jié)的信息及音節(jié)的位置。
字層:描述當(dāng)前字、前一字、后一字的信息及字在詞、詞組中的位置。
詞層:當(dāng)前詞、前一詞、后一詞的信息、詞的個數(shù);當(dāng)前詞組中詞的位置。
短語層:描述當(dāng)前短語、前一短語、后一短語的信息及聲調(diào)信息。
將各層描述的信息用符號表示,用程序識別,如表1所示。
標(biāo)注中還涉及停頓和靜音的相關(guān)標(biāo)注。表 2是對停頓和靜音的表示。
標(biāo)注的文本分析程序,自動生成單因素標(biāo)注文件和上下文相關(guān)的標(biāo)注文件。HTS訓(xùn)練合成過程中,mono.lab(單因素的標(biāo)注文件)及 full.lab(上下文相關(guān)的標(biāo)注文件),與wav(音頻)文件是相對應(yīng)的。單因素文件是文本語料所包含的所有音素信息,上下文相關(guān)的標(biāo)注文件是各層級的相關(guān)語境信息。圖5和圖6分別是mono.lab文件和full.lab文件的部分示例。

表1 上下文的相關(guān)標(biāo)注格式Tab.1 Context-r elated annotation formats

表2 停頓和靜音符號表Tab.2 Symbol table of pause and mute
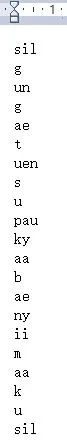
圖5 m ono.lab(單音素標(biāo)注文件)部分示例Fig.5 Some examples of mono.lab(monophone labeling file)

圖6 full.lab(上下文相關(guān)的標(biāo)注文件)部分示例Fig.6 Some examples of full.lab(context-related annotation labeling file)
由圖5可得,單因素的標(biāo)注文件中,記錄了每句中的聲韻母信息,其中sil為靜音段,pau為句中停頓。圖6得出fuii.lab文件中記錄了音節(jié)、詞、短語句子上下文相關(guān)信息。
3 合成語音測評
我們采用合成語音的 MOS(Mean Opinion Score)評估法對合成安多方言的自然度進(jìn)行了測評,利用 DMOS(Degradation Mean Opinion Score)評估法對合成安多方言的的相似度進(jìn)行測評。測評者對每個語句的語音質(zhì)量按5分制打分,其評測標(biāo)準(zhǔn)及測評結(jié)果分別如表3及圖7、圖8所示。
圖7為MOS評分的測評結(jié)果中,隨著訓(xùn)練語句的增加得分都明顯提高。30句 MOS得分 1.8分,100句MOS得分3.2分,300句是3.8分,500句是 3.9分,對比可知自然度明顯提升,總的來說合成的語音自然度較高。由實(shí)驗(yàn)可以說明隨著訓(xùn)練語句的增加,合成效果越來越好。

表3 MOS測評等級Tab.3 MOS evaluation level

圖7 MOS評測等級Fig.7 MOS evaluation level

圖8 DMOS評測等級Fig.8 DMOS evaluation level
從圖8中DMOS評測結(jié)果可以看出,訓(xùn)練語句為30句得分是2.3分,100句時得分3.4分,300句評分4.1稍微比500評分4.0高一些。我們可以得到結(jié)論,隨著訓(xùn)練語句的增加,語音的相似度增加,語音合成效果優(yōu)良。
4 結(jié)論
本文總結(jié)了藏語安多方言的聲韻母特性,設(shè)計(jì)了安多方言的機(jī)讀音標(biāo)(SAMPA-ADT),設(shè)計(jì)出安多方言文本分析的標(biāo)注文件。進(jìn)一步地,分別采用MOS和DMOS評估法對合成語音的自然度和相似度進(jìn)行了測評,測評結(jié)果表明,語音合成效果優(yōu)良。實(shí)現(xiàn)了藏語安多方言文本分析的研究,能夠很好合成藏語安多方言。
猜你喜歡
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2017年5期)2017-06-05 08:53:16
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
舒適廣告(2008年9期)2008-09-22 10:02:48
