結合邊緣檢測的語義分割算法
2021-07-26 11:56:24侯志強趙夢琦余旺盛馬素剛
計算機工程 2021年7期
王 囡,侯志強,趙夢琦,余旺盛,馬素剛
(1.西安郵電大學計算機學院,西安710121;2.西安郵電大學陜西省網絡數(shù)據(jù)分析與智能處理重點實驗室,西安710121;3.空軍工程大學信息與導航學院,西安710077)
0 概述
圖像分割是將圖像中有意義或感興趣的目標提取出來,用于圖像后續(xù)處理。傳統(tǒng)的圖像分割方法根據(jù)圖像的低層特征信息,例如顏色、紋理、亮度、形狀等提取出感興趣的區(qū)域。但在某些復雜情況下,傳統(tǒng)方法提取的特征識別度低,分割性能也較差。因此,許多研究者嘗試將圖像的高級語義信息引入到傳統(tǒng)的分割過程中,從而得到圖像的語義分割[1]。圖像語義分割[2]是計算機視覺中一個重要的研究內容,并且廣泛應用于自動駕駛、場景識別、無人機應用等領域[3-5]。
傳統(tǒng)的圖像分割方法常見的有N-cut 算法[6]、分水嶺算法[7]、SLIC 算法[8]等。N-cut 算法[6]通過計算像素與像素之間的關系得到權重參數(shù)對圖像進行劃分,但這種圖劃分方法需要對一張圖像進行多次劃分,并且無法對圖像中顏色紋理等較為相似的部分進行分割,導致分割結果不佳;分水嶺算法[7]是一種典型的區(qū)域分割方法,雖然實現(xiàn)簡單,并且能夠很好地提取圖像輪廓信息,但容易產生過分割問題;SLIC算法[8]不僅可以分割彩色圖像,而且能夠分割灰度圖像,它使用像素之間特征的相似性對像素進行分組,并用少量的超像素代替大量的像素來表達圖像特征,從而會降低后續(xù)圖像處理的復雜性,但通常作為其他分割算法的預處理步驟,并且不容易預先確定超像素的個數(shù)。
近年來,基于深度學習的圖像語義分割方法[9]在語義分割領域中表現(xiàn)出色,分割效果與傳統(tǒng)的方法相比有了明顯提高。尤其是全卷積網絡(Fully Convolution Network,F(xiàn)CN)[10]有效地提升了語義分割的精度,因此出現(xiàn)了很多基于FCN 的改進算法。BADRINARAYANAN 等[11]提出了SegNet 網絡用于語義分割,SegNet 網絡是一種編解碼結構的分割網絡,具有更高的分割精度及更快的分割速度,但這種高效的處理會使圖像丟失許多高頻細節(jié)信息,導致目標邊緣模糊以及分割結果中的細節(jié)丟失;PASZKE等[12]提出的ENet 算法是基于改進SegNet 而來的,雖然提供了較高的分割速度,但同時也影響了分割精度,導致分割精度低;YU 等[13]提出了空洞卷積的思想,在不使用池化操作的情況下會使感受野指數(shù)變大,獲得全局特征信息,但隨之運算量也增大;ZHAO 等[14]提出的金字塔池化模塊對不同區(qū)域的上下文進行聚合,提升了網絡利用全局上下文信息的能力;CHEN 等[15]提出了空洞金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模塊,可以增大空間分辨率,同時不改變感受野效果;CHEN 等[16]提出了DeepLab-v3 結構,在ASPP 模塊中加入了批量歸一化(Batch Normalization,BN)層,設計了串行和并行的空洞卷積模塊,采用多種不同的空洞率來獲取多尺度的特征信息,并將所有特征融合一起;之后,CHEN 等[17]提出DeepLab-v3+結構,在DeepLab-v3基礎上增加一個解碼器模塊,構成一個編解碼結構的語義分割模型。綜上所述,現(xiàn)有方法大多使用空洞卷積、特征融合等方法來提升語義分割效果,但這類方法需要高分辨率的特征圖,計算量較大,而且容易丟失邊緣細節(jié)信息。
針對邊緣細節(jié)信息丟失的問題,CHEN 等[18]提出通過條件隨機場(Conditional Random Field,CRF)對FCN 得到的分割結果進行細節(jié)上的優(yōu)化,但這種處理方法只是利用顏色信息和紋理信息等低層特征來修正分割結果,無法學習目標邊緣與輸入圖像之間的對應關系。HUANG 等[19]在原有的語義分割FCN 結構上構建了邊界檢測分支,輸入圖像先進入語義分割模塊,從分割模塊中構建檢測分支來獲取目標形狀細節(jié)信息,但會導致學習的邊緣信息不完整,影響語義分割模塊的分割效果。
為進一步解決分割中邊緣模糊與分割不準確的問題,可考慮結合邊緣檢測的方法進行語義分割。邊緣檢測可以得到局部像素灰度的突變,獲得封閉或者開放的邊緣,提供豐富的低層邊緣信息,從而彌補語義分割中的邊緣信息丟失。早期邊緣檢測方法使用Sobel 邊緣檢測算子[20]、Canny邊緣檢測算子[21]等方法檢測邊緣。隨著深度學習的發(fā)展,很多方法采用卷積神經網絡進行邊緣檢測,如N4-Fields[22]、Deep Edge[23]、Deep Contour[24]等方法。XIE 等[25]提出了整體嵌套邊緣檢測(Holistically-Nested Edge Detection,HED)算法進行邊緣檢測,該網絡實現(xiàn)了第1 個端到端的邊緣檢測模型;LIU 等[26]提出了基于更豐富特征的邊緣檢測(Richer Convolutional Features for Edge Detection,RCF),RCF 首先將網絡中每個階段的特征進行了元素相加操作,然后進行特征融合,RCF 利用了網絡中所有卷積層的特征,是目前較好的邊緣檢測算法。近年來,也出現(xiàn)了一些結合邊緣檢測的語義分割方法[27-28],但該類方法目前尚不多見。
綜上所述,本文提出了一種結合邊緣檢測網絡的語義分割算法。在語義分割網絡基礎上,并聯(lián)了邊緣檢測網絡,構建一種結合邊緣檢測的語義分割模型,利用邊緣特征改善語義分割中的目標邊緣模糊問題,為語義分割提供豐富準確的邊緣信息。設計一個特征融合模塊,將邊緣特征和語義分割特征進行concat 融合,并對融合后的特征進行多層卷積操作,最終在CamVid 數(shù)據(jù)集和Cityscapes 數(shù)據(jù)集上進行實驗。
1 本文算法
本文提出一種結合邊緣信息的語義分割算法,以此來改善語義分割中邊緣模糊、分割不準確等問題,提升語義分割精度。
1.1 網絡整體結構
本文所提出的結合邊緣檢測的語義分割模型采用一種并行結構,如圖1所示,主要由邊緣檢測子網絡、語義分割子網絡和特征融合模塊3 個部分組成(彩圖效果見《計算機工程》官網HTML 版)。圖1 中的虛線框為邊緣檢測子網絡,該網絡能捕獲和學習圖像的邊緣信息,有助于獲取目標更多的細節(jié)信息,從而可以為語義分割提供更精細的邊緣信息。圖1中的點線框為語義分割子網絡,該網絡對輸入圖像進行下采樣,再進行上采樣來提取圖像的區(qū)域特征,得到初步的語義分割特征,但是大量的細節(jié)信息在下采樣時被丟失。模型的后端是特征融合模塊,即圖1 中點劃線框所包含的部分,將邊緣特征和語義分割特征進行卷積操作融合,利用邊緣信息更強的邊緣特征來改善語義分割中邊緣模糊、分割不準確等問題。
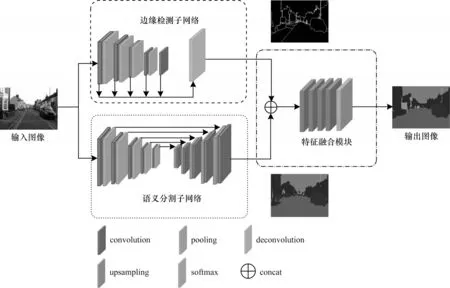
圖1 語文分割算法模型結構Fig.1 Model structure of semantic segmentation algorithm
1.2 邊緣檢測子網絡
邊緣檢測子網絡的詳細網絡結構如圖2所示。在邊緣檢測子網絡[26]中,整個網絡的卷積層分為5 個階段,每個階段由卷積層和池化層組成,然后去掉第5 階段的池化層,最后將第5 階段的卷積層使用空洞率為2 的空洞卷積[12],空洞卷積的使用有效地避免了池化操作后對高層特征信息的丟失問題,更好地捕獲了目標的輪廓特征,使得高層特征中的邊緣更加清晰和完整。
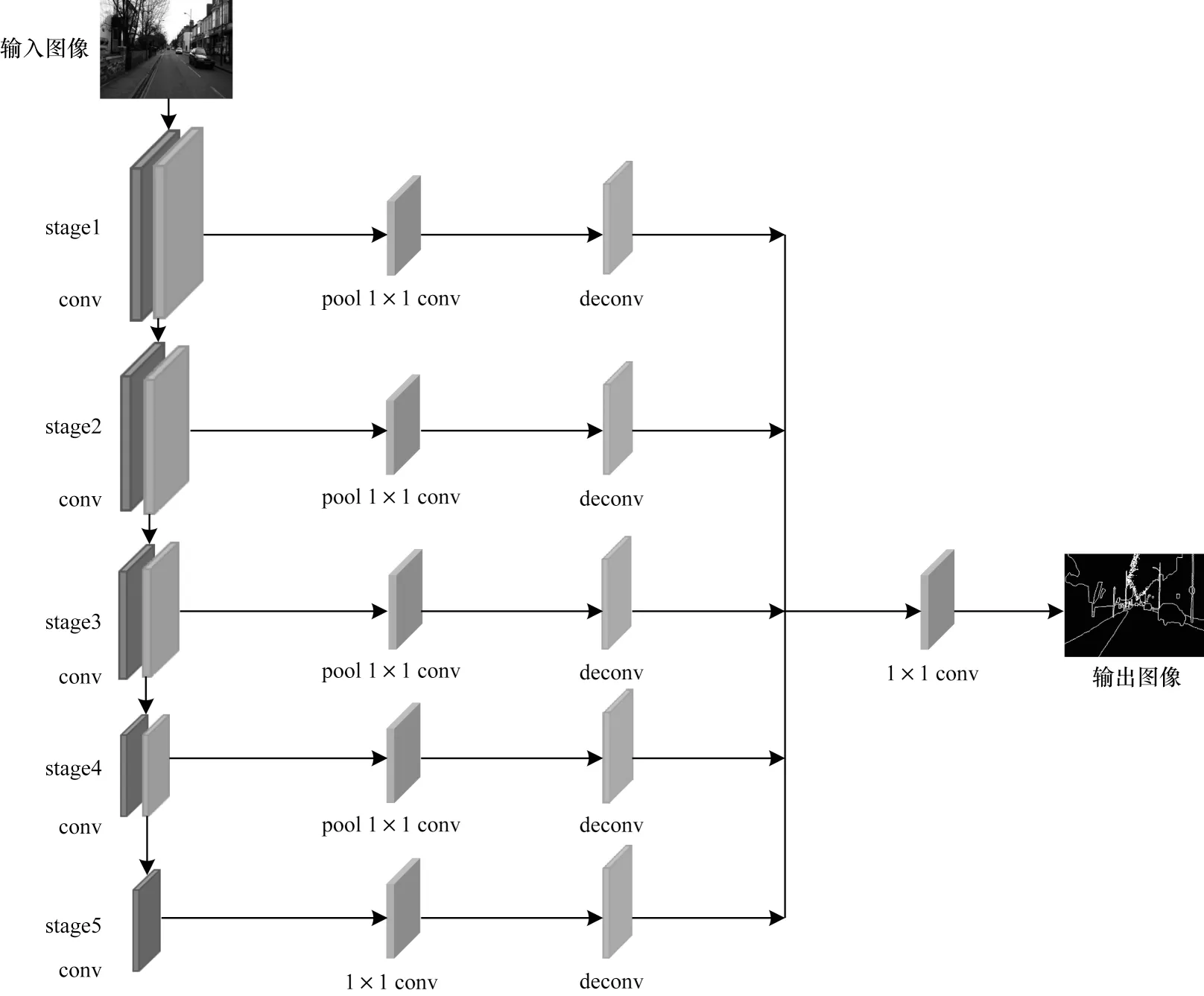
圖2 邊緣檢測子網絡的結構Fig.2 Structure of edge detection sub-network
5 個階段的結構如表1所示。
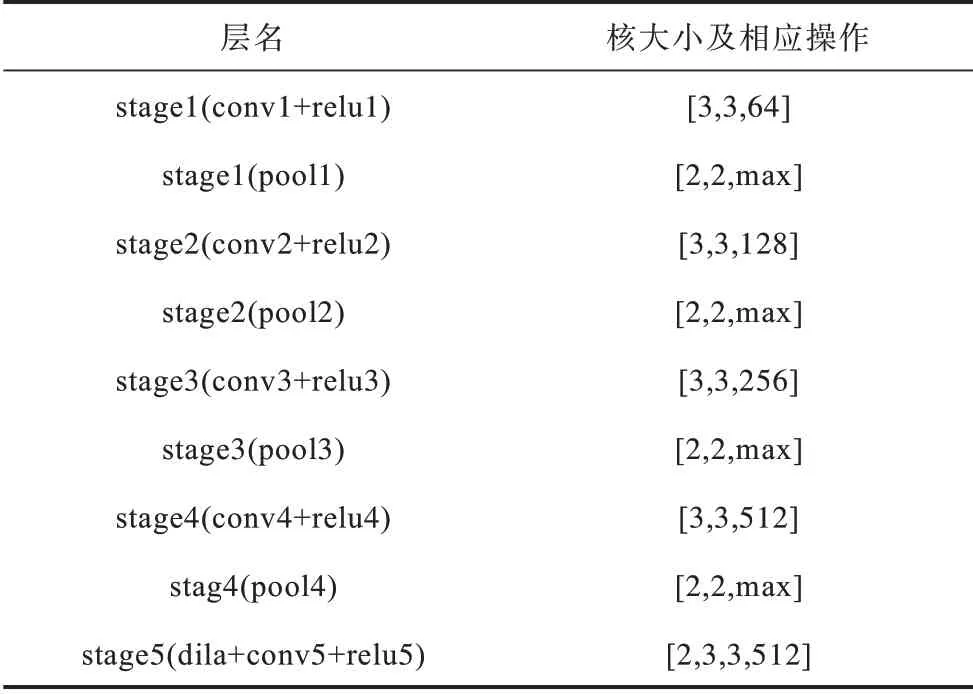
表1 邊緣檢測子網絡5 個階段的結構Table 1 Structure of edge detection sub-network five-stage
在每個階段的卷積層之后連接一個核大小為1×1卷積層,然后通過反卷積將特征圖進行上采樣到原圖像大小分辨率,最后利用一個1×1 的卷積層將5 個特征圖融合。該網絡能捕獲和學習圖像的邊緣信息,可以為語義分割提供更精細的邊緣信息。
1.3 語義分割子網絡
在語義分割子網絡中,其結構采用的是經典的編碼器和解碼器結構[11]。語義分割子網絡的詳細網絡結構如圖3所示。編碼階段沿用VGG16 網絡模型,由一連串的卷積層、池化層和BN 層組成。卷積層負責獲取圖像特征,池化層對圖像進行下采樣將特征傳送到下一層,因為在最大池化過程中會損失一些信息,這里會存儲最大池化索引,保存最大池化過程中的位置信息,用于在上采樣階段進行恢復,BN 層主要對圖像的分布進行歸一化,加速學習。編碼器階段主要對圖像進行特征提取。編碼器各層的網絡結構如表2所示。

圖3 語義分割子網絡的結構Fig.3 Structure of semantic segmentation sub-network
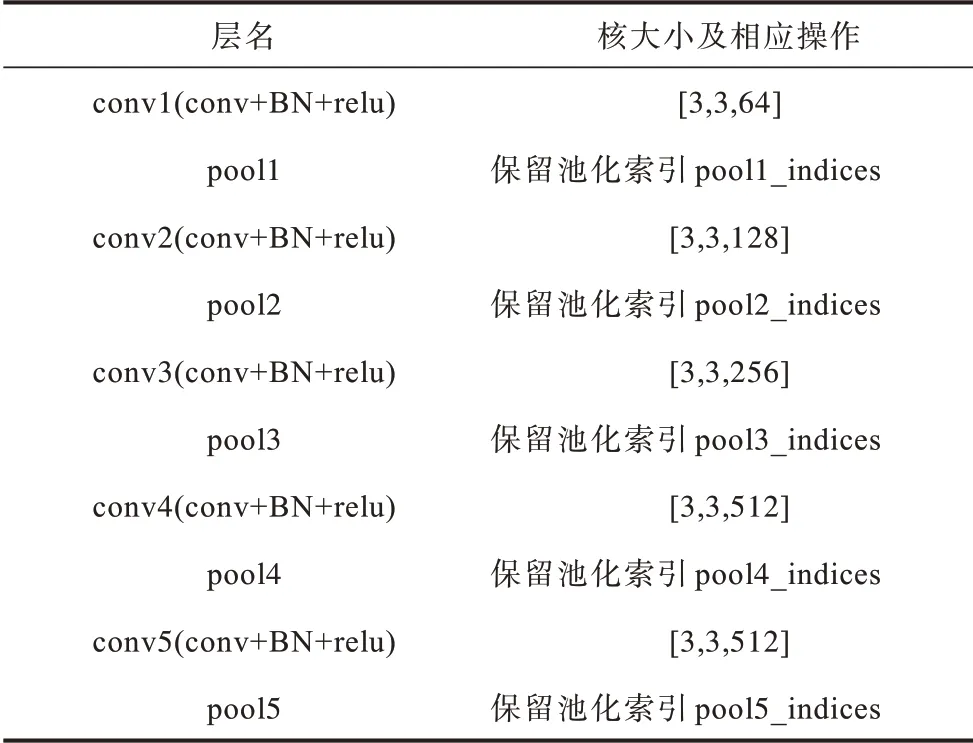
表2 編碼階段的網絡結構Table 2 Network structure of encoding phase
解碼器階段是由對應于每個編碼器的解碼器組成的,解碼器首先使用從相應的編碼器存儲的最大池化索引來獲取目標信息與大致的位置信息,并對縮小后的特征圖進行上采樣,這種上采樣方式可以減少訓練的參數(shù)數(shù)量以及減小池化對信息的損失。然后對上采樣后的圖像進行卷積處理,彌補編碼器階段池化層對目標造成的細節(jié)損失。解碼器各層的網絡結構如表3所示。
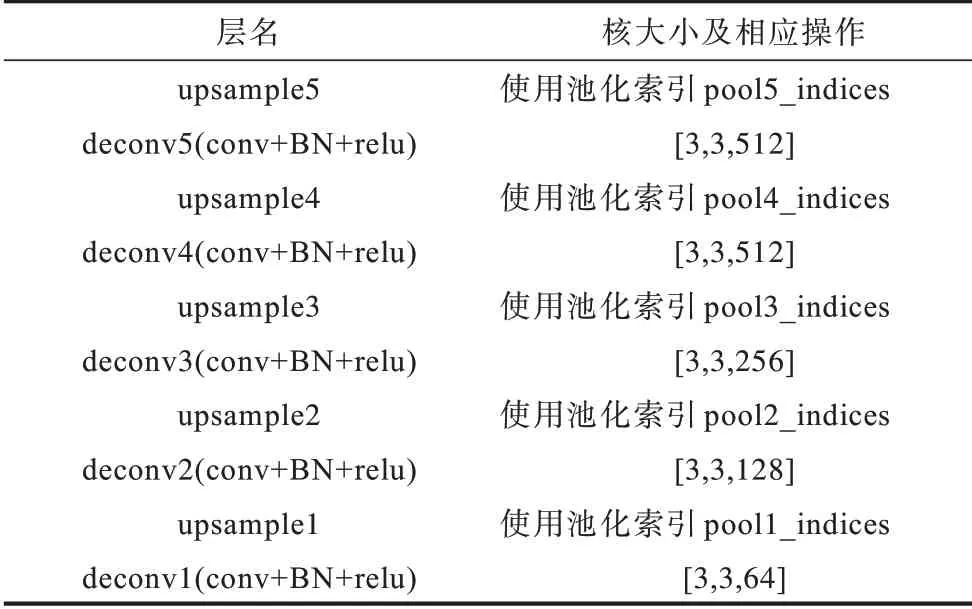
表3 解碼階段的網絡結構Table 3 Network structure of decoding phase
1.4 特征融合模塊
在本文模型中,當從邊緣檢測子網絡獲得邊緣信息和語義分割子網絡獲得語義信息時,需要對2 路特征進行融合。因為邊緣檢測子網絡和語義分割子網絡得到的特征表示不同,邊緣檢測子網絡得到的結果更多地表示圖像邊緣和細節(jié)特征,語義分割子網絡得到的結果更多的地示圖像的區(qū)域特征,所以在進行2 路特征融合時,簡單地將2 路特征進行加權融合,并不能充分地利用2 路特征,達到預期效果。因此,本文提出了一個特征融合模塊來融合邊緣檢測子網絡特征和語義分割子網絡特征。
在選擇特征融合的方式上,主要有add 融合方式和concat 融合方式2 種[29]。add 融合方式對上下2 路特征圖對應位置元素的值進行相加,但這種方式在融合過程中會損失原始特征的信息,不能體現(xiàn)特征之間的互補性,所得到的結果也并不理想;concat 融合方式對上下2 路特征直接級聯(lián)融合,將不同通道進行合并,這種方式不僅避免了add 融合方式對特征信息造成的損失,而且對上下2 路的特征進行通道數(shù)的合并,并結合前面所得到的特征得到后續(xù)的特征。
本文設計的特征融合模塊包括使用concat 特征融合方式對邊緣特征和語義分割特征進行初步融合2 個部分;然后對初步融合后的特征進行多層卷積操作,多層卷積由4 層卷積層組成,其特征圖的個數(shù)分別為64、128、256 和512,卷積核的大小為3×3。特征融合模塊的詳細結構如圖4所示。
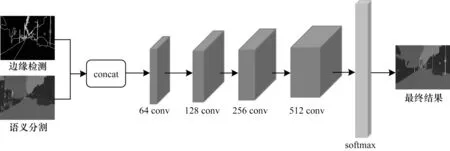
圖4 特征融合模塊Fig.4 Feature fusion module
具體的融合過程為:首先將邊緣檢測子網絡和語義分割子網絡輸出的特征進行concat 方式融合;然后進行多層卷積操作,利用卷積去學習融合2 路特征;最后再進行分類,得到最終的分割圖。
在對特征融合方式選擇上,本文進行實驗比較確定選擇concat 特征融合方式。首先將得到的邊緣特征和語義分割特征分別使用add 方式和concat 方式進行初步融合;然后對融合后的特征進行多層卷積操作;最后進行分類得到最終分割結果。實驗結果表明,采用add 融合方式和concat 融合方式對融合結果有不同影響,如圖5所示。
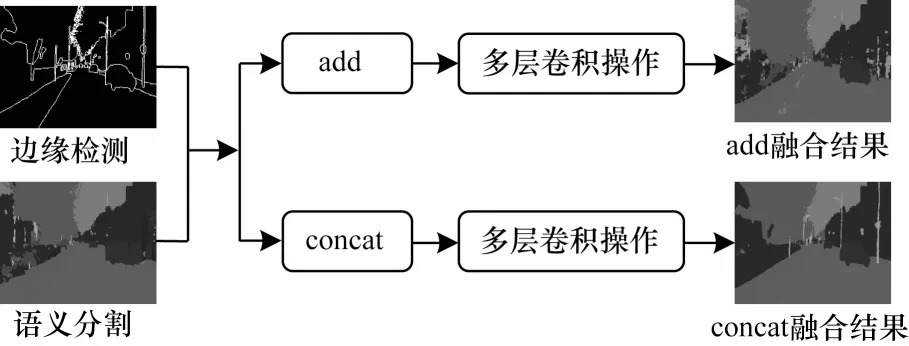
圖5 不同融合方式對分割結果的影響Fig.5 Impact of different fusion methods on segmentation results
不融合、add 融合和concat 融合方式的平均交并比(mIoU)分別為55.6%、55.7%和57.1%。
1.5 算法步驟
本文針對分割任務中目標邊緣模糊、分割不準確等問題,提出一種結合邊緣檢測的語義分割算法。考慮邊緣檢測與語義分割的結合,在語義分割網絡基礎上并聯(lián)一個邊緣檢測網絡來學習目標的邊緣信息,再將邊緣特征和語義分割特征進行融合,綜合利用2 路數(shù)據(jù)的特征信息,得到最終的語義分割結果。
本文算法的主要步驟如下:
步驟1輸入圖像。
步驟2將圖像分別送入邊緣檢測子網絡和語義分割子網絡,得到圖像邊緣的特征和圖像初步的語義分割特征。
步驟3把得到的2 類特征按concat 方式融合。
步驟4將初步融合后的特征進行多層卷積操作,利用卷積融合2 個子網絡的特征。
步驟5將步驟4 得到的特征融合結果進行softmax 分類,得到最終的語義分割圖像。
本文算法流程如圖6所示。從圖6 可以看出,本文算法改善了語義分割中邊緣不清晰、分割任務中目標邊緣模糊等問題,提高了分割精度。
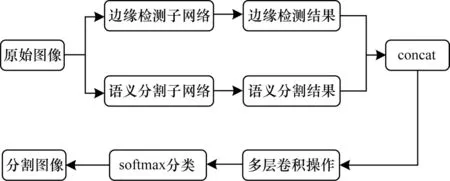
圖6 本文算法流程Fig.6 Algorithm procedure of this paper
2 實驗
本文算法實驗基于Caffe框架,系統(tǒng)為Linux16.04,使用的GPU 是NVIDIA GTX 1080Ti,并在CamVid數(shù)據(jù)集和Cityscapes 數(shù)據(jù)集上進行了實驗。
2.1 數(shù)據(jù)集及評價指標
CamVid 數(shù)據(jù)集是從駕駛汽車的角度來看的一個街景數(shù)據(jù)集。它總共包含701 張圖像,其中367 張用于訓練,101 張用于驗證,233 張用于測試。圖像分辨率為960 像素×720 像素,數(shù)據(jù)集包含11 個語義類別。在SegNet[10]中將其進行處理,將圖像分辨率改為480 像素×360 像素,所以使用修改后的數(shù)據(jù)集驗證模型的有效性。Cityscapes 是另一個大型城市街道場景數(shù)據(jù)集,在語義分割領域中廣泛使用。它有5 000 張具有高質量精細標注的圖像和20 000 張具有粗略標注的圖像。在本文的實驗中,只使用具有精細標注的圖像,它包含2 975 張用于訓練的精細注釋圖像、1 525 張用于測試的圖像和500 張用于驗證的圖像。為了實驗方便,將圖像分辨率由2 018 像素×1 024 像素改為480 像素×360 像素,其中每個像素都被注釋為預定義的19 個類。
本文采用的評價指標為平均交并比(mean Intersection over Union,mIoU)和每秒處理幀數(shù)(Frames Per Second,F(xiàn)PS),這2 種評價指標為當前語義分割中使用較多的標準度量。
mIoU 計算2 個集合為真實值和預測值的交集和并集之比,用于評價算法精度。IoU 是每一個類別的交集與并集之比,而mIoU 則是所有類別的平均IoU。其計算公式如下:
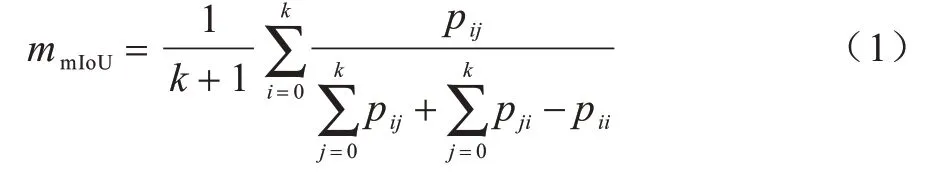
其中:k是前景對象的個數(shù);pij是指原本屬于第i類卻被分類到第j類的像素的數(shù)量。
FPS 用于評價算法速度,其計算公式如下:

其中:N為圖像數(shù)量;Tj為算法處理第j張圖像的時間。
2.2 實驗方法
本文提出的結合邊緣信息的語義分割模型使用端到端的聯(lián)合訓練方式。在模型訓練過程中,使用SGD 優(yōu)化器,初始學習率設置為0.001,將batchsize設置為2,momentum 設置為0.9,weight_decay 設置為0.000 5,最大迭代次數(shù)為100 000。在訓練過程中,本模型涉及邊緣檢測和語義分割2 種分類網絡,因此采用2 種損失函數(shù)。
邊緣檢測網絡是一個對像素點進行是否為邊界的二分類問題。邊緣檢測網絡的損失函數(shù)采用常用的交叉熵損失函數(shù),其可以定義為:
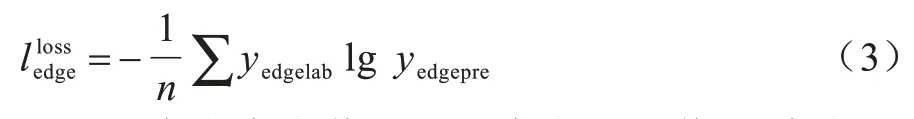
其中:yedgelab代表真實值;yedgepre代表預測值;n代表圖像的總像素點數(shù)量。
語義分割網絡通常將圖像的每個像素點的分類看作是一個多分類問題,因此同樣采用交叉熵損失函數(shù),可以定義為:

其中:yseglab代表真實值;ysegpre代表預測值;n代表圖像的總像素點數(shù)量。
在實驗中,因為涉及語義分割和邊緣檢測2 種分類網絡,除了需要已有的語義分割標注外,還需要數(shù)據(jù)集的邊緣標注圖像,本文并不需要額外地進行邊緣標注,而是利用已有的語義分割標注生成邊緣標注圖像。
2.3 實驗結果與分析
2.3.1 CamVid 數(shù)據(jù)集
基于CamVid 數(shù)據(jù)集,采用未結合邊緣檢測的語義分割算法SegNet[11]、ENet[12]與本文算法進行對比,分析算法的性能表現(xiàn)。圖7所示為本文算法與其他對比算法的實驗結果。

圖7 不同算法分割結果對比1Fig.7 Comparison of different algorithms segmentation results1
從圖7 可以看出,本文算法在道路、車輛、路燈桿、指示牌等的邊界分割更為精準。在圖7(a0)中,本文算法對路燈桿的分割更加連續(xù)和清晰;在圖7(a1)中,本文算法可以清晰地分割出車輛旁邊的行人以及遠處車輛之間的黏連;在圖7(a2)、圖7(a3)中,不僅在道路、路燈桿處邊緣更連續(xù),更清晰,而且也較完整地分割出路邊指示牌的邊緣。
表4 是本文方法與其他語義分割方法在相同的實驗環(huán)境下的分割效果對比。從表4 可以看出,本文算法在分割精度上高于其他2 種算法,在分割速度上,本文算法相較于SegNet[11]算法沒有明顯下降,雖然ENet[12]算法的分割速度要優(yōu)于本文算法,但分割精度遠低于本文算法。
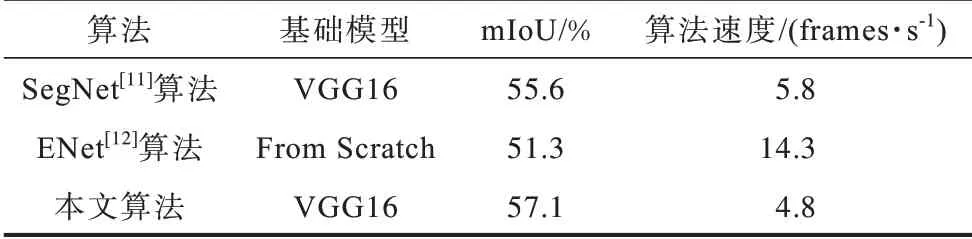
表4 不同算法在CamVid 數(shù)據(jù)集上的對比Table 4 Comparison of different algorithms on CamVid datasets
2.3.2 Cityscapes 數(shù)據(jù)集
基于Cityscapes 數(shù)據(jù)集,同樣采用未結合邊緣檢測的語義分割算法SegNet[11]、ENet[12]與本文的算法進行對比,分析算法的性能表現(xiàn)。圖8所示為本文算法與其他對比算法的實驗結果。

圖8 不同算法分割結果對比2Fig.8 Comparison of different algorithms segmentation results 2
從圖8 可以看出,在圖8(a0)中,本文算法結果可以更好地將路燈桿等細小目標分割出來;在圖8(a1)中,SegNet[11]的分割結果圖8(c1)將大巴車分割錯誤,而本文算法分割正確,雖然ENet[12]的結果圖8(c2)也分割正確,但本文分割結果相比于ENet[12],道路分割更加平滑清晰;在圖8(a2)中,本文算法結果相比于SegNet[11]、ENet[12],可以明顯地分割出來交通燈,改善了路邊行人黏連的問題;在圖8(a3)中,SegNet[11]、ENet[12]不能清晰地分割出路中間的行人,而本文算法可以很好地分割出來。
表5 是本文算法與其他語義分割算法在相同的實驗環(huán)境下的分割效果對比。從表5 可以看出,本文算法在分割精度上高于其他算法,在分割速度上,本文算法相較于SegNet[11]算法沒有明顯下降,雖然ENet[12]算法的分割速度要優(yōu)于本文算法,但本文算法分割精度要高于ENet[12]算法。
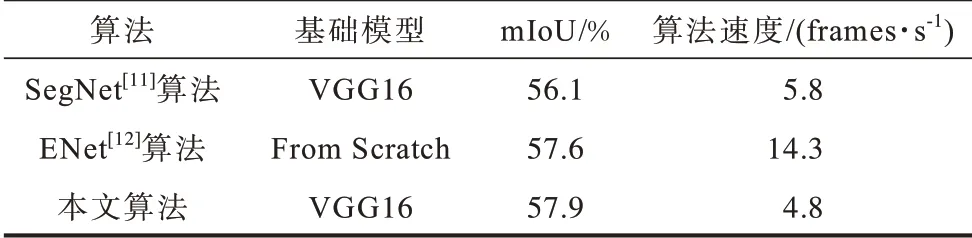
表5 不同算法在Cityscapes 數(shù)據(jù)集上的對比Table 5 Comparison of different algorithms on Cityscapes datasets
通過對以上實驗結果的分析,證明了該方法在分割精度方面的有效性,并且與未考慮邊緣檢測的SegNet[11]算法相比,本文算法在CamVid 數(shù)據(jù)集和Cityscapes 數(shù)據(jù)集上的性能分別提升了1.5 和1.8 個百分點。
2.3.3 與現(xiàn)有算法的比較與分析
本文算法采用結合邊緣檢測的方法改進語義分割中邊緣模糊問題,與已有的邊緣檢測與語義分割相結合的ESNet[27]算法比較結果如表6所示。

表6 與ESNet 算法的比較結果Table 6 Comparison result with ESNet algorithm
本文算法與已有的邊緣檢測與語義分割相結合的方法主要有以下不同:
1)網絡結構不同。本文采用的語義分割網絡為SegNet[11]網絡,ESNet[27]采用的語義分割網絡為ESPNetV2[30]網絡,由于選擇的語義分割baseline 的差異,ESPNetV2 的分割效果比SegNet 的分割效果要好;本文采用的邊緣檢測網絡為已有的邊緣檢測算法RCF[26],而ESNet 采用MobileNetV2[31]作為邊緣骨架,雖然MobileNetV2 作為輕量級網絡,在速度上占有優(yōu)勢,但本文選用的邊緣檢測網絡結構簡單,使用了結構中所有卷積層的特征,利用了更多的有用信息,可以提供更好的邊緣效果。
2)輸入圖像分辨率不同。在ESNet 方法中,輸入圖像分辨率為1 024 像素×512 像素;而本文算法由于baseline 的限制,輸入圖像分辨率為480 像素×360 像素,不同的圖像分辨率會帶來不同的分割結果,分辨率越高,分割結果越好。
3)實驗環(huán)境上的不同。本文實驗使用的顯卡是1 臺NVIDIA GTX 1080Ti,而ESNet 使用了4 臺NVIDIA Tesla P40 顯卡,可以得到更大更穩(wěn)定的性能。由此,本文算法精度與ESNet 方法相比略低。
通過以上的比較與分析,驗證了本文算法的有效性。
3 結束語
本文提出一種結合邊緣檢測的語義分割算法。整個網絡由邊緣檢測網絡和語義分割網絡并行組成,邊緣檢測網絡用來提取圖像的邊緣特征,語義分割網絡用來提取初步的語義分割特征,后端將2 路特征進行融合,以獲得最終的語義分割結果。實驗結果表明,結合邊緣檢測的語義分割算法可以有效改善邊緣模糊、分割不準確等問題,能夠得到較理想的語義分割結果。下一步將研究結合邊緣檢測的語義分割方法來提高分割精度并加快分割速度。
猜你喜歡
今日農業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
