基于數據庫的電商企業暢銷產品成因調查方法研究
2021-07-28 04:20:24章麗
西安航空學院學報 2021年2期
章 麗
(池州職業技術學院 經濟管理系,安徽 池州 247000)
一、引言
隨著國內外網絡消費市場的不斷擴大,實體企業和電商企業都面臨著巨大的挑戰和發展瓶頸,一方面互聯網電商企業逐漸從線上走向線下,通過對物流體系的投資和對線下門店的布局,互聯網電商逐漸下沉到實體經濟中,面對勢不可擋的數字化浪潮,電商企業急需對暢銷產品的成因進行研究,為自身企業發展尋找更好的前景[1-3]。
二、基于數據庫的電商企業暢銷產品成因調查方法設計
(一)提取用戶消費行為數據
提取用戶消費行為數據主要從三方面進行,分別是用戶所持移動設備數據,與用戶移動設備MAC地址匹配的消費信息、與商品SKU碼匹配的商品銷售數據[9]。
采集用戶所持移動設備數據主要是移動設備的WiFi數據,針對線下用戶群體,使用WiFi感應器采集數據,通過有線或無線兩種方式將數據上傳到服務器,在安裝時,每個WiFi感應器的MAC地址與各個探測區域形成一一對應的關系[10]。感應器在實際環境中的工作流程如圖1所示。

圖1 WiFi感應器工作流程
WiFi感應器中集成了信號采集、數據預處理和數據通信三個子模塊,通信協議中主要包含管理幀、控制幀和數據幀;信號采集模塊負責采集和判斷無線網絡中不同類型的幀數據,對幀數據進行合理分類,上報至服務器;數據預處理模塊主要根據數據處理程序對數據幀進行預處理操作,保證數據質量。
WiFi數據經過預處理和打包之后,通過通信模塊上傳到服務器中。一般情況下,WiFi感應器的數據上報周期為3秒,中間層數據處理模塊通過對數據包的解壓縮,可以獲得WiFi感應器的MAC地址、用戶手持移動設備的MAC地址、發送報文時的時間戳等數據。
對于會員用戶數據,主要針對注冊會員或使用過門店線上商城的基礎上。當消費客戶在移動設備注冊會員或使用門店線上商城購物時,該客戶的消費信息將會傳輸到會員信息數據庫中。主要還是依賴移動設備的MAC地址與線上商城的匹配,具體采集流程如圖2所示。

圖2 會員客戶數據采集流程
采集產品銷售數據主要通過門店原有的商品進銷存系統數據庫實現。管理員針對當前門店的商品陳列情況,在數據庫中導入記錄了門店中每個商品的SKU碼的數據表,然后通過配置商品進銷數據庫的驗證接口實現對商品數據的調用[11]。商品銷售數據采集流程如圖3所示。
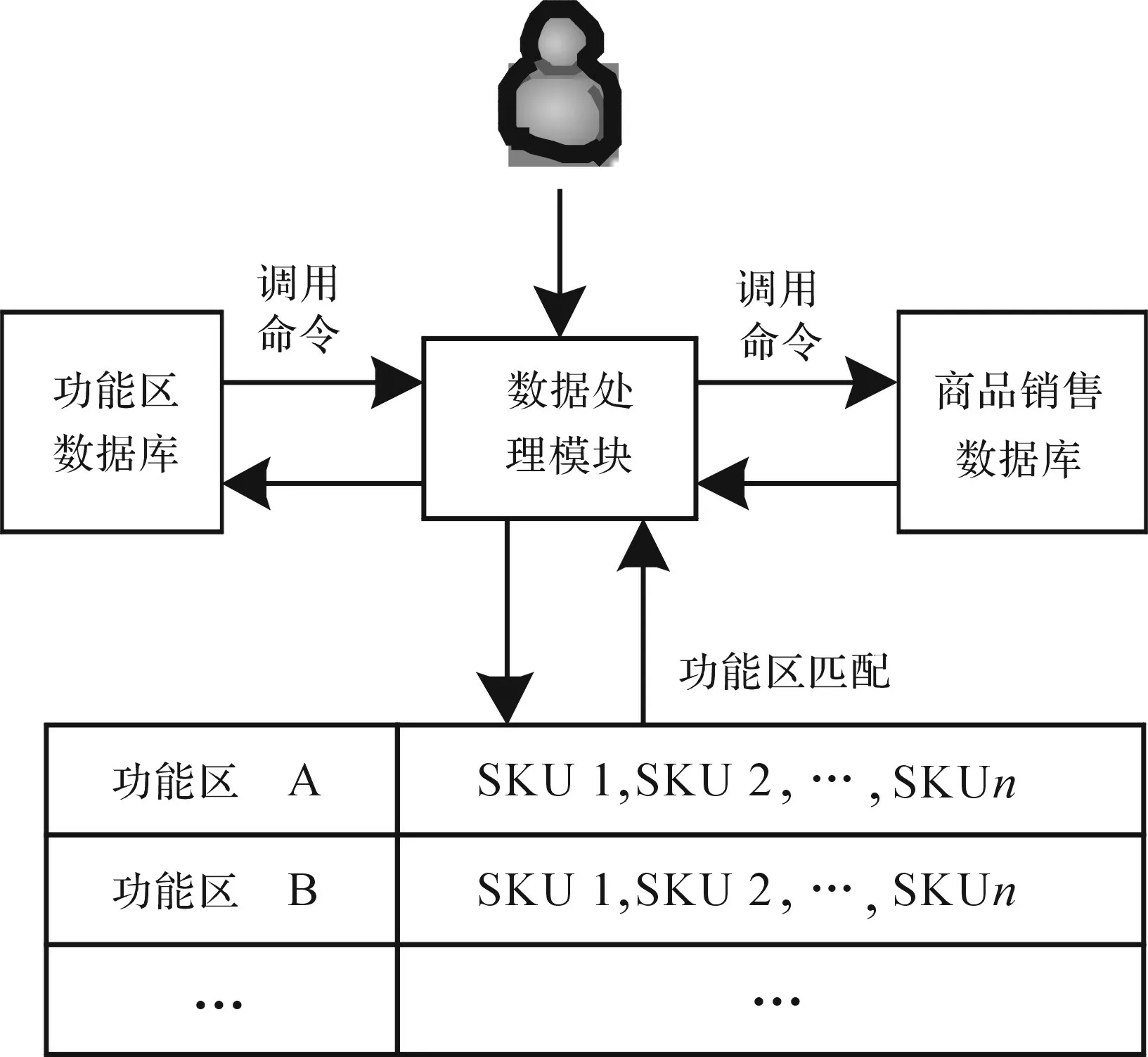
圖3 商品銷售數據采集流程
完成數據采集后,將其存儲在設計的內存數據庫中。
(二)后臺內存數據庫設計
電商企業暢銷產品成因分析需要用到大量網絡數據,原有的數據庫不能很好地適應網上數據的特點,需要引入新的數據模型,對數據庫進行優化。因此,在數據庫中引入半結構化模式,半結構化數據存在一定的結構,先有數據,后有模式,能夠準確地描述出數據的結構信息,但不會對數據結構產生強制性的約束,也能隨著數據的不斷更新而時刻處于動態變化狀態[12]。
針對半結構模式的數據庫,設計基于XML的數據管理框架,將來自各數據源的數據通過數據倉庫方法進行集成,以XML數據的形式統一存儲在數據庫中[13]。具體過程是:定義XML數據模式,根據用戶的實際需求在數據庫中抽取源數據,將各個數據源的數據集成為XML數據,同時獲得XML數據的模式,統一數據模式。在電商企業暢銷產品成因分析中,與暢銷產品相關的數據如表1所示。
“封禁令”封住了山,封住了沙坨子,卻也禁了羊的口。老百姓的羊怎么辦?舍飼圈養。剛開始的時候,農民不知怎么養、羊舍怎么建,也不知優質的種羊從哪里引進。何況,養羊戶更需要一筆不大不小的啟動資金——這是農民心里不愿說出來的話。于是,政府搭臺,肉類加工企業與農民結成“羊對子”,簽訂合同,一方出資,一方出工,借羊養羊,養羊還羊,增值分成。出欄的羊全部由肉類加工企業收購,農民沒有任何風險,收益還能得大頭。有了新的出路,農民對“封禁令”不再抗拒。
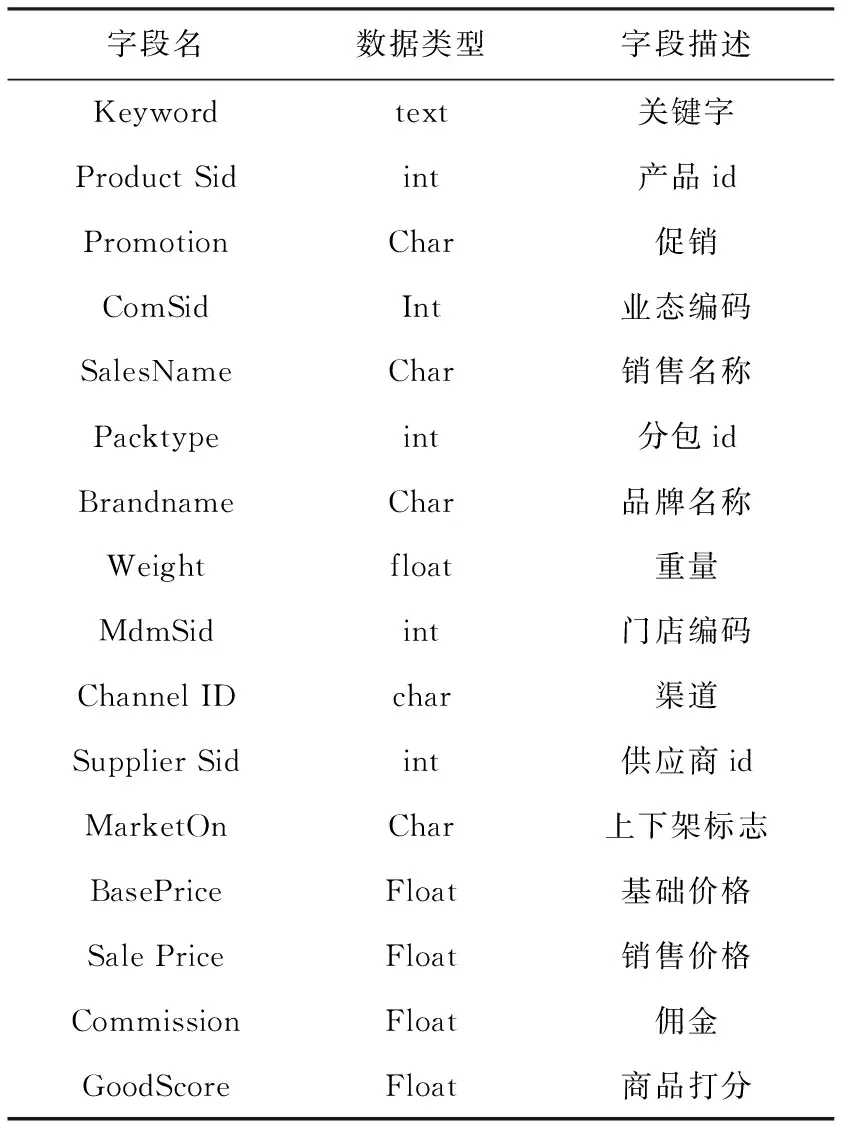
表1 暢銷產品相關數據
為了保證后臺數據的安全,在事務進入提交狀態之前,對每個活動事務分配一個“影子內存工作區”,將數據修改工作記錄到影子內存工作區中,不修改真正的數據庫數據,當工作進入提交狀態時,根據“影子內存工作區”中的記錄作相應修改,即使某一事務由于某種原因夭折時,也只需要釋放其相應的影子內存工作區即可[14]。
半結構模式數據的實際操作效率存在一定的不足,通過使用“影子內存工作區”,可提高一定的數據庫操作效率。為了更好地提高工作效率,改變數據庫存儲結構,將元數據和數據存儲在一起,使得元數據可以直接存取,減少查找元數據帶來的開銷[15]。考慮到不同操作的并發程度不同,可能會造成資源開銷比較高,因此采用動態多粒度鎖機制適應不同操作。當并發程度比較高的時候,采用較小粒度的鎖;當并發程度比較低的時候,使用粗粒度鎖。在這種機制下,既保證了并發性,又保持了較低的開銷。至此,基于數據庫的電商企業暢銷產品成因調查方法設計完成。
(三)挖掘成因數據
從大量與暢銷產品的信息數據中篩選出成因數據,主要利用事物與事物之間的關聯性和相互依存性,在成型的數據庫中挖掘出目標數據。假設用戶行為數據庫D中有N個不同集合I={i1,i2,…,in},數據庫D中一個事務U是一個項目子集(U?I)。支持度是項集在數據庫D中出現次數與數據庫D中項集總數的比。在計算之前,用戶根據自身的需求設置最小支持度閾值,當計算的項集支持度超過最小支持度閾值,得到頻繁項集。
支持度計算公式為:
式中:X∪Y=?;M表示數據庫D中的事務總數;X和Y表示集合I中事務;support(X∪Y)表示數據庫中支持X∪Y的事務數。則信任度計算公式為:
式中:Sup(X∪Y)表示X∪Y的支持度;Sup(X)表示X的支持度。將以上公式轉換為概率計算:
Sup(X?Y)=P(X∪Y) (3)
Conf(X?Y)=P(Y/X) (4)
掃描整個數據庫D,計算數據庫中所有事務的支持度,將支持度不小于最小支持度的項目構成集合存入到數據集中,對數據庫中的每一個事務重復上述過程,最后將支持度不小于最小支持度的潛在頻繁項集存入數據集中,最后輸出數據集,即為暢銷產品成因數據集。通過整理即可得到暢銷產品成因分析結果。
三、電商企業暢銷產品成因調查方法實驗研究
(一)實驗數據集準備
在電商企業暢銷產品成因調查方法實驗研究中,從Yahoo!Autos網站隨機抽取1000000條記錄,合成數據集MerDB,其中包括type、color、model、price、make數據集,測試數據集的總大小為1550.36 MB。
所有的實驗均在配置Windows10的計算機和Microso SQL Serve的環境下進行。考慮到提出的調查方法需要利用用戶的網絡行為,因此,從電商企業網站中獲取用戶網絡行為數據。具體內容如表2所示。
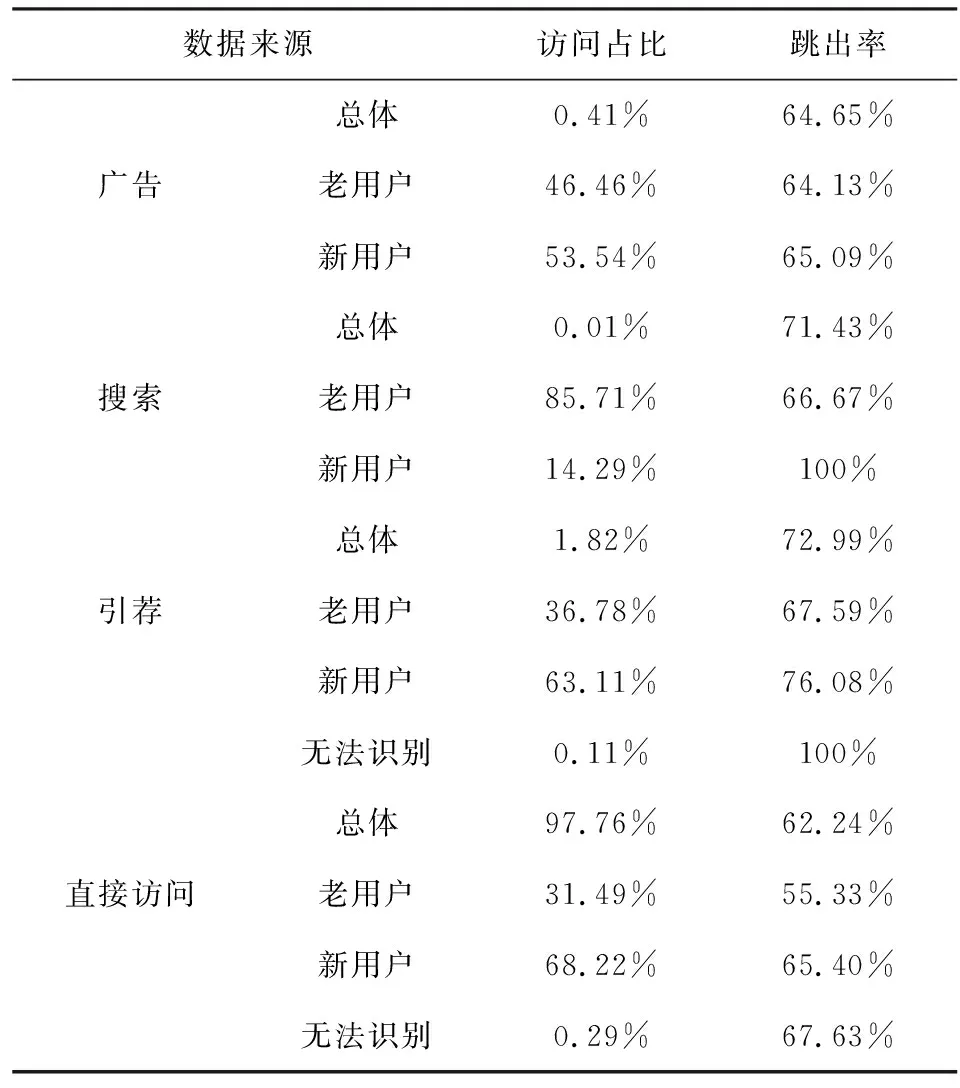
表2 實驗數據來源明細
依據以上數據設計對比實驗,實驗對象為提出的基于數據庫的成因調查方法、常規的基于Logistic回歸分析的成因調查方法和基于SEM的成因調查方法,以調查方法的可靠性為衡量標準,設計兩組對比實驗,分別是數據清洗實驗和網關壓力實驗。
(二)數據清洗實驗及分析
數據清洗實驗中,使用不同的成因調查方法分析實驗數據,在分析完成后,將得到的數據進行數據清洗,對得到數據進行字符數校驗,執行程序如圖4所示。

圖4 數據清洗reduce過程部分代碼
對比觀察處理后的數據,分析成因調查方法的實際水平。具體結果如圖5至圖7所示。
圖5 基于Logistic回歸分析的成因調查方法實驗結果

圖6 基于SEM的成因調查方法實驗結果
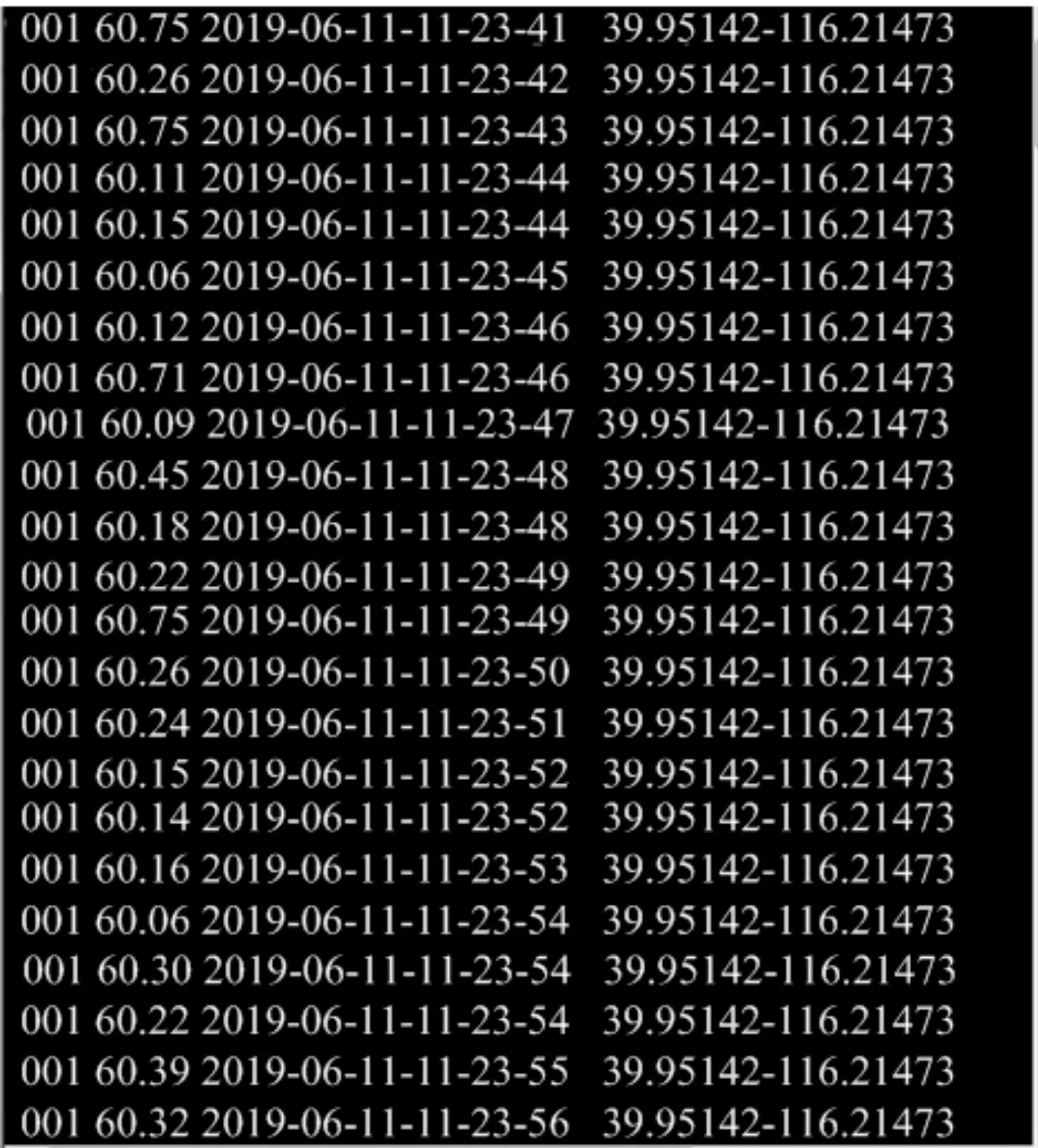
圖7 基于數據庫的成因調查方法實驗結果
對比觀察圖中結果,圖5顯示的結果中,數據中不僅有屬性缺失的數據序列,還有異常序列的數據,異常數據序列包括歸零數據和字符長度異常數據;圖6顯示的結果與圖5中存在的數據異常相同,異常數據更多;圖7中結果顯示,數據整齊有序,不存在異常數據。綜上所述,提出的基于數據庫的電商企業暢銷產品成因調查方法數據質量更好。
(三)網關服務壓力實驗與分析
網關壓力實驗中,使用Jmeter壓力測試工具通過編寫測試腳本模擬多個事務并發調用API請求,通過不斷提升并發API請求數量,判斷網關所能承受并發數量的極限值。實驗結果如表3所示。

表3 不同成因調查方法網關服務壓力實驗結果
從表3可以看出,傳統的兩種成因調查方法網關服務能力比較差,實際處理的數據請求與預期處理的數據請求相差比較大,在回歸測試中也并沒有得到校正。相比之下,提出的基于數據庫的電商企業暢銷產品成因調查方法抗壓能力更強,能夠在極短的時間內處理所有數據請求。結合數據清洗實驗結果可知,提出的基于數據庫的電商企業暢銷產品成因調查方法具有更好的可靠性,該方法優于傳統的成因調查方法。
四、結語
電商企業暢銷產品成因調查對電商企業的發展有很強的推動作用,很多企業在暢銷成品調查研究中投入了大量精力。在這種背景下,本文圍繞著電商企業暢銷產品成因調查方法展開研究與設計,對原有的暢銷產品成因數據庫進行了優化。在調查方法設計完成后,通過實驗對比,驗證了提出的暢銷產品成因調查方法的可靠性,為電商企業發展提供理論依據與技術支撐。
猜你喜歡
中學生數理化·八年級物理人教版(2021年10期)2021-11-22 08:00:02
寶藏(2017年7期)2017-08-09 08:15:19
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
唐山文學(2016年11期)2016-03-20 15:25:54
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
