聯合多重卷積與注意力機制的網絡入侵檢測
2021-07-28 04:51:52朱金奇馬春梅鄒馨雨
天津師范大學學報(自然科學版) 2021年3期
曹 軻,朱金奇,馬春梅,杜 恬,鄒馨雨
(天津師范大學計算機與信息工程學院,天津300387)
隨著網絡技術的不斷發展,網絡滲透、網絡入侵和網絡病毒等網絡安全問題的出現愈加頻繁,給網絡的正常使用帶來極大隱患.因此,網絡安全成為人們關注的焦點[1].目前,入侵檢測是確保網絡信息安全的主要手段,其目的是識別網絡數據流中的惡意流量和攔截網絡攻擊.然而,由于因特網業務量的爆炸式增長,網絡流量類型日益復雜,尤其在5G網絡大規模應用后,網絡流量類型更加多樣,給入侵檢測技術帶來了巨大挑戰[2-3].如何高效識別惡意流量,并準確區分不同類型的惡意流量,是衡量入侵檢測系統性能的關鍵.
現有的入侵檢測系統可分為兩類:傳統方法或基于機器學習的方法[4-9]和基于深度學習的方法[10-15].早期的入侵檢測研究多使用模式匹配算法,文獻[7]對入侵檢測中的模式匹配算法進行了總結.模式匹配方法存在低準確率、高誤報率的缺陷.隨后機器學習方法被用于入侵檢測.文獻[8]提出基于支持向量機(SVM)的特征選擇和分類方法,并在NSL-KDD cup 99數據集上進行實驗.文獻[9]在最近鄰結點算法KNN分類器的基礎上結合k-均值聚類設計入侵檢測系統,使用NSL-KDD數據集進行實驗,結果表明所提方法大大提高了KNN分類器的性能.但上述方法需要進行大量的數據預處理和人為特征選取,所以基于機器學習的入侵檢測模型仍有很多不足.隨著人工智能的發展,深度學習算法在圖像分類、機器翻譯和人體行為識別[16]等任務中表現出較好的性能,一些基于深度學習理論的入侵檢測方法也被提出.文獻[10]將循環神經網絡(recurrent neural networks,RNN)應用于入侵檢測,并使用RNN的變體構建入侵檢測模型.文獻[11]建立了長短時記憶(long-short term memory,LSTM)網絡[17]對入侵流進行分類.但上述研究缺少對數據流深層關鍵特征的提取,僅單純進行了數據流特征的學習.文獻[12]搭建卷積神經網絡(convolutional neural networks,CNN)進行入侵檢測,并使用UNSW-NB15數據集[18]進行實驗,實驗結果表明,除攻擊類、模糊類和通用類數據流外,其他類型攻擊流均無法被檢測出來.因此,CNN雖然可以提取數據流的深層特征,但對數據流的分類檢測能力不強.文獻[13]基于雙向長短時記憶網絡(BLSTM)設計入侵檢測模型,并在NSL-KDD數據集上進行實驗,但其實驗所用數據集不完全具備最新的網絡入侵流特征.文獻[14]從UNSW-NB15數據集中選取樣本,建立雙向RNN網絡,選擇5個特征進行數據流分類,該工作只選擇了部分數據集并且選取的入侵流特征不全,因此其檢測能力不具有代表性.文獻[15]構建稀疏自編碼器進行數據降維,搭建RNN模型進行特征提取,使用時序生成器處理數據,得到了較高的入侵流識別準確率,該模型的數據預處理、模型預訓練以及特征選擇工序比較復雜,且自編碼器對數據的處理是有損的,只能處理與訓練樣本類似的數據,在處理海量且復雜多樣的入侵流時存在不足.
本文聯合多重卷積、注意力機制(attention mechanism)[19]和基于CuDNN(深度神經網絡的GPU加速庫)加速的LSTM網絡,建立了一種入侵檢測模型CAL(Convolution-Attention-LSTM).該模型結合網絡流的結構特點與網絡攻擊突發性的特點,在多重卷積后加入注意力層進行數據流深層關鍵特征的自動提取;通過池化計算壓縮特征,加速模型收斂,以提高模型泛化能力,防止過擬合;使用LSTM充分學習數據的上下文特征和時序信息,以提升相關入侵流的檢測能力.將CAL模型在完整的UNSW-NB15數據集上進行實驗,并與已有的檢測模型進行對比,結果表明,CAL模型在入侵流檢測準確率和入侵流類型檢測分類方面均優于已有模型.
1 模型構建
本文建立的入侵檢測模型CAL結構如圖1所示.模型由輸入層、多重卷積層、注意力層、池化層、基于CuDNN的LSTM層和多重全連接層等部分組成.輸入層以網絡流數據作為模型的輸入;多重卷積層使用3層多卷積核的卷積神經網絡對數據進行特征提取,得到數據流的深層特征;注意力層得到卷積層提取的深層特征后,運用注意力機制計算數據的注意力權重,加權平均細化數據特征,并從中提取出具有判別性的關鍵特征;池化層通過池化計算來壓縮從注意力層得到的數據,以提高下層網絡的處理效率,加速模型收斂;為進一步提高模型的特征學習能力和處理效率,在池化層后加入基于CuDNN加速的LSTM層學習數據內的上下文和時序特征;最后將處理后的向量特征輸入多重全連接層進行特征融合,以softmax邏輯回歸層進行最終分類,輸出分類結果.
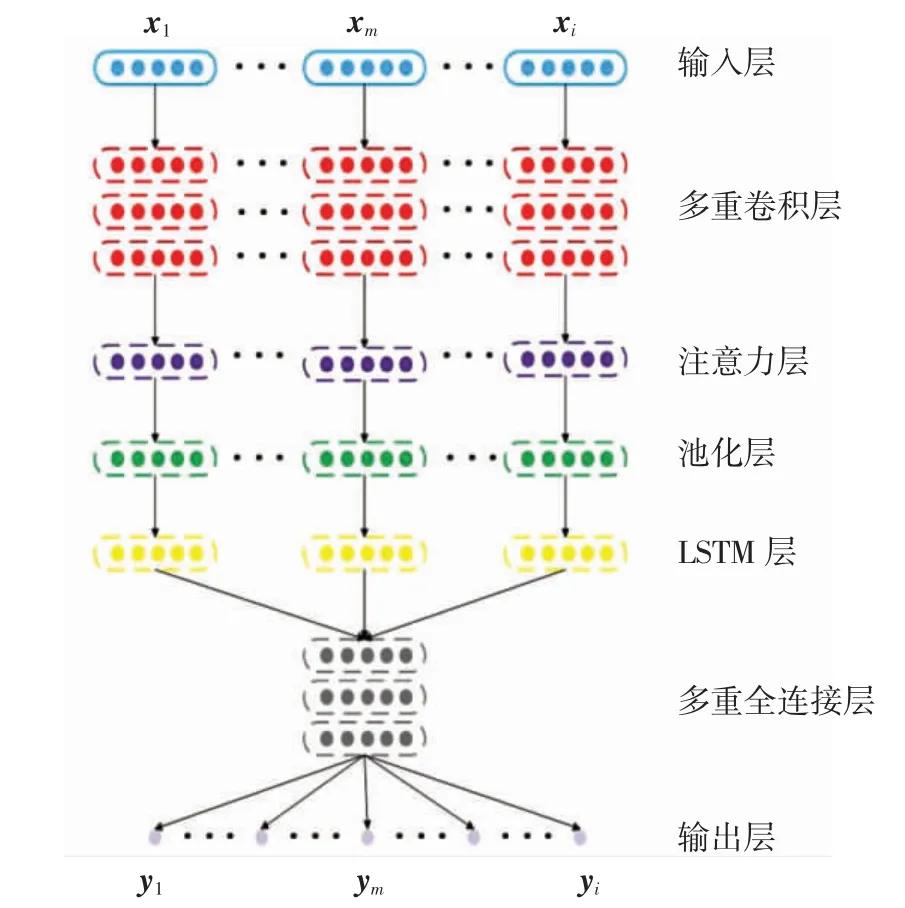
圖1 CAL模型結構Fig.1 Structure of CAL model
1.1 數據預處理
由于網絡流特征較為復雜,大都以浮點數為主,而網絡協議、狀態和服務這3個特征的值是英文表達.為便于處理,將網絡協議、狀態和服務這3個特征的所有特征值映射到0至200范圍的整數值上,然后對這3個以整數值表示的特征和其他以浮點數表示的特征進行數組化表示,以符合神經網絡的輸入標準.同時,為避免數據過大而導致的數據溢出或權重不平衡,將數據規范化處理到0至1范圍內,這樣有利于消除原始數據對模型訓練的影響.
1.2 多重卷積層
卷積層包含連續的3層卷積,第1層卷積負責提取一些低級的邊緣特征,第2和第3層卷積利用低級的特征進行迭代提取,獲得數據流全局的更深層更復雜的特征.第1層卷積使用雙曲正切激活函數,第2和第3層使用指數線性單元激活函數,具體如下:
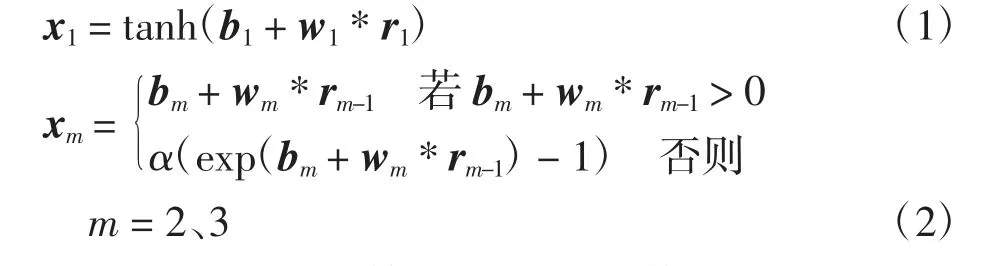
式(1)和式(2)分別為第1層卷積和第2、3層卷積的的計算過程,其中:xm為第m層卷積的輸出;bm為偏置參數;rm為數據特征值;wm為卷積核;“*”表示卷積運算.
1.3 注意力層
為獲得對入侵流具有判別性的關鍵特征,提高檢測精度,本文引入注意力層以使模型可以動態地關注有助于執行當下決策的數據特征.注意力層負責計算多個向量或向量組的加權平均.注意力機制對每個從卷積層輸出的數據流向量組計算注意力分布,得到注意力權重,最后加權得到數據流最終的向量表示.注意力權重系數αi為

其中:xiT為網絡流深層特征的特征向量;xw為上下文相關的選擇向量,用來評估xiT的重要性.加權得到的向量特征s為

1.4 池化層
池化計算用來壓縮數據和減少參數數量,以減小計算量,提高下層網絡的處理效率,同時防止過擬合,提高模型整體的泛化能力和收斂速度.池化層的操作與卷積層基本相同,下采樣的卷積核對輸入的向量取對應位置的最大值,其計算過程為
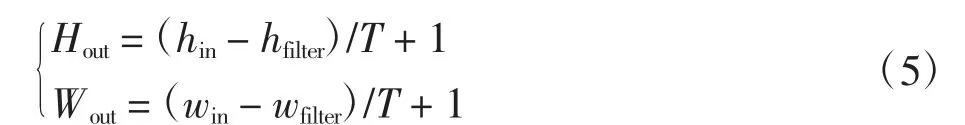
其中:Hout和Wout為輸出向量的高度和寬度;T為濾波器每次掃描的步長;hin和hfilter分別為輸入向量和濾波器的高度;win和wfilter分別為輸入向量和濾波器的寬度.
1.5 CuDNN-LSTM層
為進一步提高模型對網絡流的分類能力,引入基于CuDNN的LSTM網絡來學習數據流的上下文特征和時序信息.當信息進入LSTM層后,神經元判斷它對決策是否有用,無用信息則會被遺忘門遺忘,門控循環單元通過不同的時間信息計算隱藏單元在時間步長t的激活值[20].LSTM內部的計算流程如圖2所示,其神經元的計算過程為
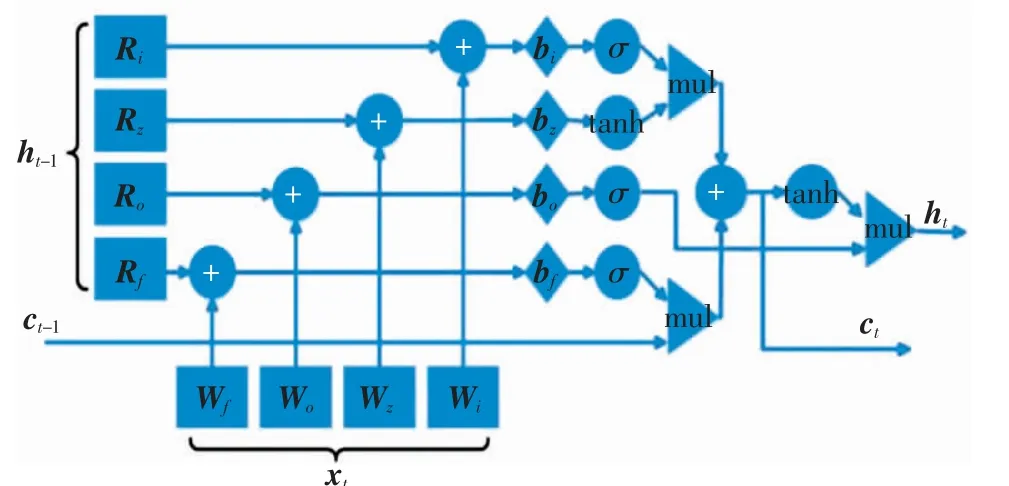
圖2 LSTM計算流程Fig.2 Computing flowchart of LSTM
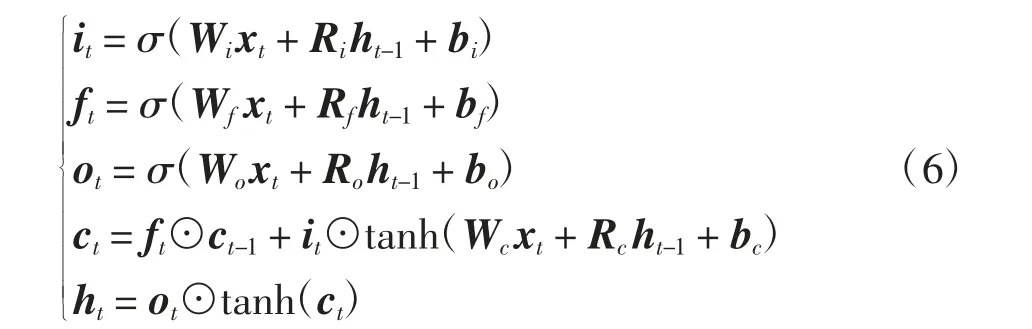
其中:xt為當前時刻上層神經網絡輸入的特征;Wi、Wf、Wo、Ri、Rf和Ro為權重矩陣;bi、bf和bo為偏置向量;σ和tanh為激活函數;ht和ht-1分別為當前時刻和上一時刻的輸出;it、ft和ot分別為輸入門、遺忘門和輸出門的輸出;ct為細胞狀態;⊙表示矩陣的Hadamard積.
作為一種非競爭性的NMDA受體拮抗劑,有效劑量的氯胺酮可以抑制NMDA受體活性,對電針刺激不反應的Nep模型進行逆轉,并聯合脊髓電針對疼痛治療,可以進一步將療效增強。最新研究也顯示[4],將低于1 mg/kg的氯胺酮應用在缺血性疼痛與癌痛治療中,容易取得較為明顯的療效,可以減少阿片類鎮痛藥物的用藥,從而將不良反應減少,達到減輕患者痛苦。其他非選擇性NMDA受體拮抗劑,包括美金剛、去甲右美沙芬等燈光,這些對于NeP患者也可以發揮顯著的鎮痛效果。
2 實驗與性能分析
2.1 UNSW-NB15數據集
UNSW-NB15數據集樣本數量大,特征復雜,所含攻擊類型多,是入侵檢測的基準數據集之一.該數據集涵蓋1種正常類和9種攻擊類共10種網絡流類型,9種攻擊類分別為分析類(Analysis)、后門類(Backdoor)、拒絕服務類(DoS)、攻擊類(Exploits)、模糊類(Fuzzers)、通用類(Generic)、偵察類(Reconnaissance)、外殼代碼類(Shellcode)和蠕蟲類(Worms).UNSWNB15數據集分為訓練集和測試集,共257 670條數據,訓練集共175 340條數據,測試集共82 330條數據,數據集中的記錄沒有冗余.每條數據具有44個特征,如表1所示,特征1~30是從數據包中收集的綜合信息,31~37是網絡連接特征,38~42是通用特征,43為攻擊類型,44代表是否為攻擊流的標簽信息.本文使用UNSW-NB15的訓練集訓練模型,使用其測試集評估模型性能.

表1 UNSW-NB15數據集特征列表Tab.1 List of features for UNSW-NB15 dataset
2.2 實驗評估與設置
使用準確率(accuracy,ACC)、檢測率(detection rate,DR)、虛警率(false alarm rate,FAR)和假陽性率(false positive rate,FPR)[21]等4個指標評估入侵檢測模型的性能.表2為用于評估實驗的混淆矩陣.

表2 混淆矩陣Tab.2 Confusion matrix
ACC、DR、FAR和FPR的計算公式為
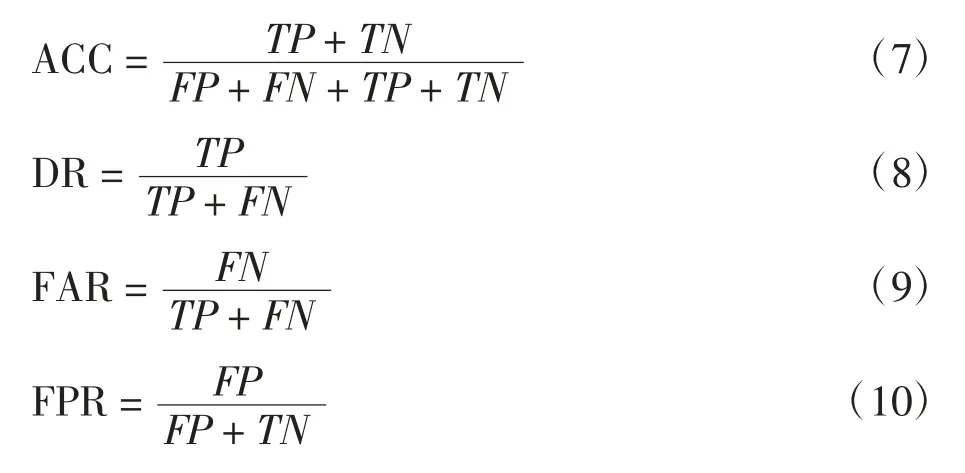
實驗采用基于TensorFlow的深度學習框架Keras,使用python編程,python版本為3.6,服務器顯卡為NVIDIA RTX2080TI,顯存為10 GB.
2.3 模型訓練
模型訓練包括前向傳播和后向傳播.在前向傳播中,輸入的數據順次經過多重卷積層、注意力層、池化層和CuDNN-LSTM層,前向傳播完成后得到網絡流分類的結果.模型的反向傳播過程使用Adam優化器優化,學習率設置為0.001.由于UNSW-NB15數據集中有部分特征數據為0,所以本文使用稀疏多分類對數損失函數減小數據的稀疏性對損失評估的影響.模型利用前向與后向傳播獲得目標函數對于各網絡層權重的導數后,通過隨即梯度下降來最小化目標函數,從而完成訓練過程.在數據集上進行了100次迭代訓練,從中選擇準確率最高的參數作為模型參數,并在測試集上進行實驗.
2.4 實驗結果分析
2.4.1 二分類實驗
二分類實驗是將數據流的預測結果分為2類:正常和攻擊.表3為CAL模型在UNSW-NB15測試集上生成的混淆矩陣,可見大多數的樣本數據位于混淆矩陣的對角線上.由二分類混淆矩陣的數據計算得正常樣本的FPR為2.33%,攻擊樣本的DR為97.67%.

表3 CAL模型的二分類實驗混淆矩陣Tab.3 Confusion matrix for dichotomous experiment of CAL
圖3為模型在訓練集和測試集上進行100次迭代的準確率,由圖3可見,迭代84次時,模型在測試集上的準確率達到90.37%,同時在訓練集上的準確率達到94.41%.以上結果表明CAL模型在二分類實驗中體現了良好的檢測性能.
2.4.2 多分類實驗
多分類實驗將數據流的預測結果細分為前述的10種數據流類型(1種正常類和9種攻擊類).圖4為這10種數據流類型的混淆矩陣,由圖4可見,Normal、Exploits、Reconnaissance和Generic等類型的大多數樣本都在矩陣對角線上,而Analysis、Backdoor和DoS類型因為樣本數量太少沒有體現出很好的檢測率.
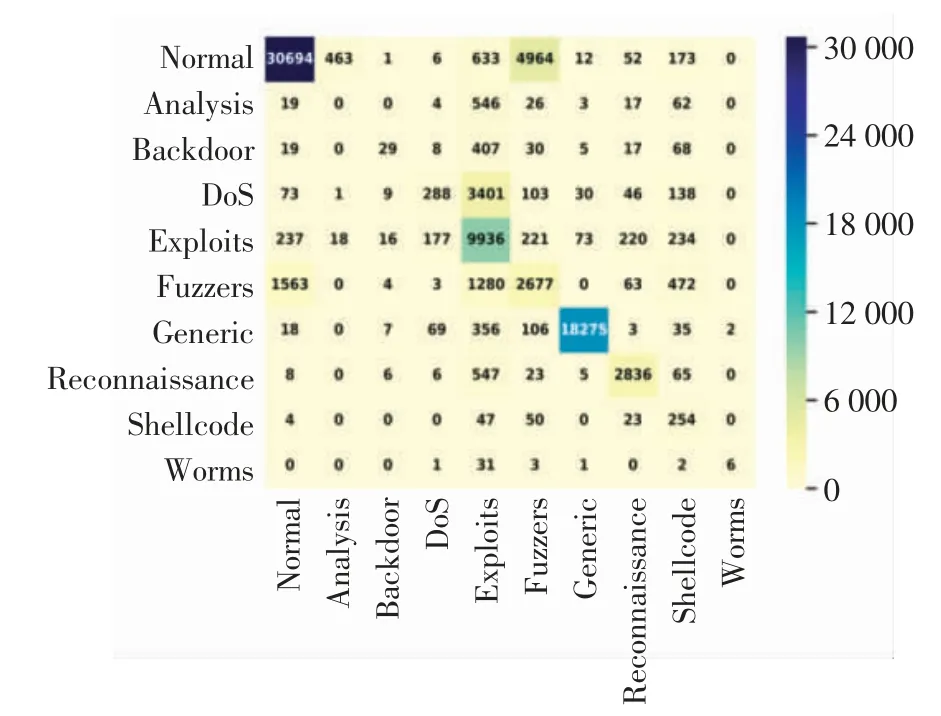
圖4 CAL模型的多分類實驗混淆矩陣Fig.4 Confusion matrix for multi-type intrusion experiment of CAL
表4為每個類型對應的DR和FPR,由表4可見,Generic入侵流檢測率最高,為96.84%,而Analysis入侵流因為樣本數量太少導致特征并沒有被很好地學習,因此未被檢測出.此外,10種類型都顯示出較低的FPR,其中Backdoor、Generic和Worms入侵流的FPR幾乎為0%,而最高的Exploits為10.18%.
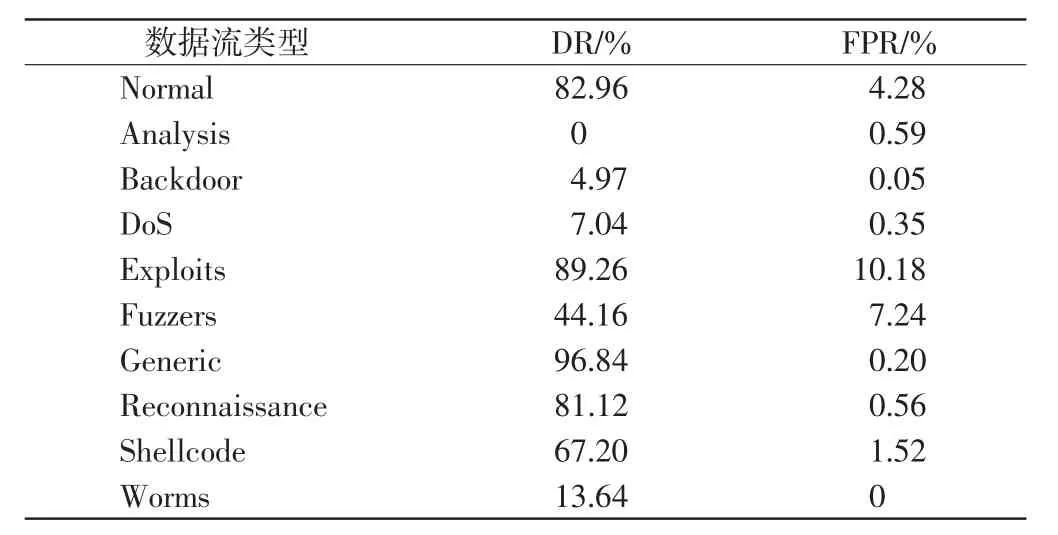
表4 CAL模型多分類實驗的DR和FPRTab.4 DR and FPR of multi-type intrusion experiment of CAL
圖5為模型在訓練集和測試集上進行100次迭代的準確率,由圖5可見,迭代59次時,模型在測試集上的準確率為78.94%,在訓練集上的準確率為82.90%.多分類實驗相比二分類實驗檢測難度要高出許多,并且其中一些類型因為樣本數量太少導致檢測失效,所以模型檢測性能有所波動.
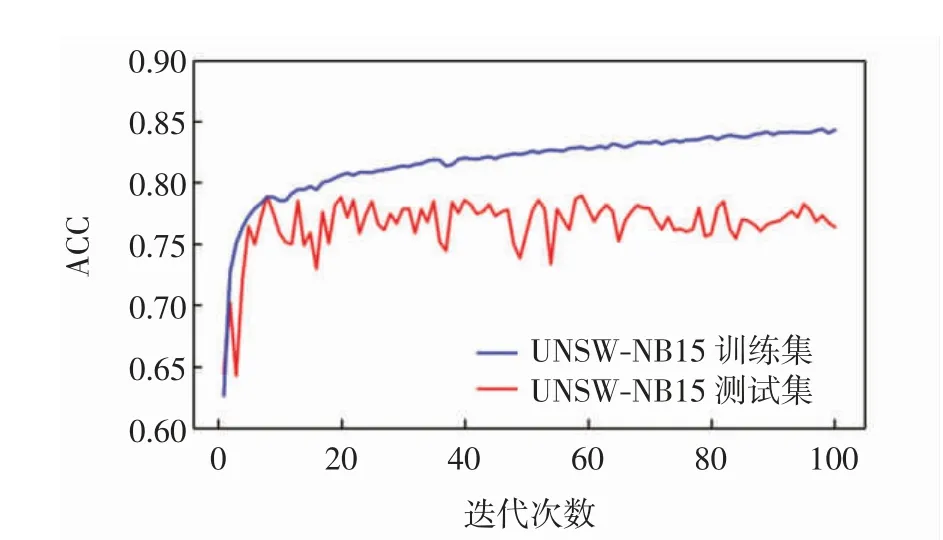
圖5 CAL模型多分類實驗的準確率Fig.5 ACC of multi-type intrusion experiment of CAL
2.4.3 與其他方法的比較
將本文所提入侵檢測模型CAL與其他方法進行實驗比較,包括HNGFA[22]、SVM[23]、LR(logistic regression)、DT(decision tree)、NB(naive Bayes)、RF(random forest)[24]和LSTM模型,在UNSW-NB15測試集上進行實驗.
表5給出了二分類實驗中不同模型的ACC和FAR.由表5可見,CAL模型的性能均為最優,CAL模型的ACC僅略高于HNGFA模型,但CAL模型的FAR為10.46%,顯著低于HNGFA的13.03%,說明CAL模型具有優勢.
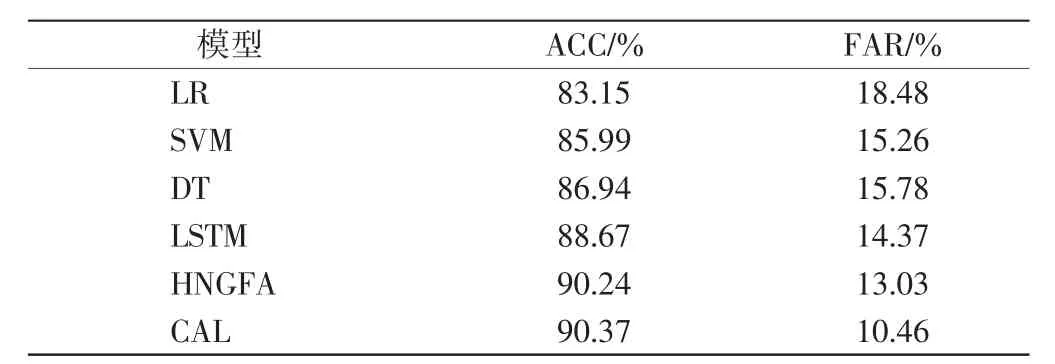
表5 不同模型的二分類實驗結果Tab.5 Results of dichotomous experiment of different models
表6給出了多分類實驗中不同模型的ACC和FPR.由表6可見,CAL模型在多分類實驗中的ACC和FPR均優于其他方法.與其他方法相比,CAL模型在處理復雜困難的數據流分類時,因為采用了卷積層和注意力層進行特征提取,并且引入LSTM層學習數據的上下文和時序特征,使得模型對數據流關鍵特征的提取能力更強,因此性能表現優于其他方法.
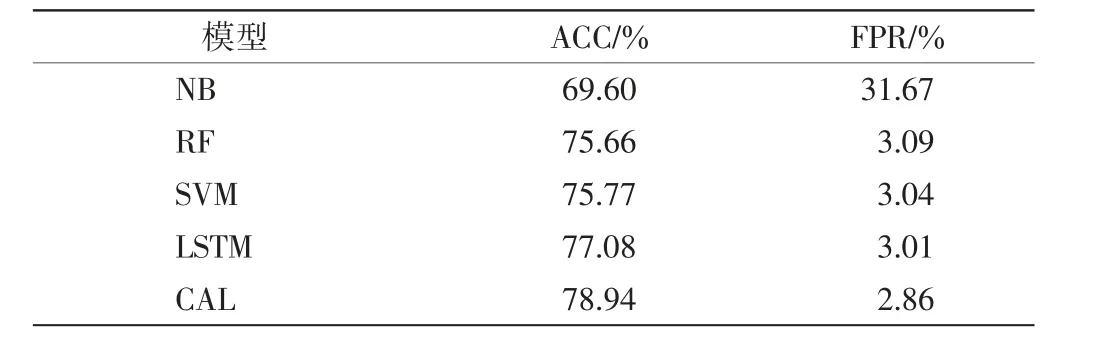
表6 不同模型的多分類實驗結果Tab.6 Results of multi-type intrusion experiment of different models
3 結語
針對目前網絡流類型的多樣性和網絡攻擊的突發性,提出入侵檢測模型CAL,該模型能夠提取數據流深層的關鍵特征,在完整的UNSW-NB15數據集上進行實驗,結果表明,CAL模型的識別準確率為90.37%,性能表現優于其他已有方法,并能以較高的準確率識別各種類型的入侵流.此外,CAL模型的數據預處理、模型預訓練以及特征工程比較簡單,適合在復雜多變的網絡環境中進行入侵檢測.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
