音視頻大數據樣本庫入庫規范
2021-07-29 07:32:56韓志峰白雪冰蔣龍泉黃云剛馮瑞
微型電腦應用 2021年7期
韓志峰,白雪冰,蔣龍泉,黃云剛,馮瑞
(1.復旦大學 軟件學院,上海 200438;2.復旦大學 工程與應用技術研究院,上海 200438;3.復旦大學 計算機科學技術學院,上海 200438;4.上海海潮新技術研究所,上海 200438)
0 引言
隨著互聯網、物聯網的迅速普及,以音視頻為代表的非結構數據呈現爆發式增長趨勢,不僅包含了結構化數據,還包含了大量非結構化數據,如視頻、圖像和語音等。當前互聯網上的視頻有數十億,并仍然在實時急劇增長,例如流媒體視頻領域巨頭,Netflix網站視頻數量增長驚人,其中原創視頻數量平均每年在以185%的速度增長,如圖1所示。

圖1 Netflix網站平均日增原創視頻數量圖
如何對如此巨大的數據進行有效分類管理,并實現靈活調用的問題日益突出。
現在已經有很多公開的大型圖片數據集,并在目標檢測領域產生了不錯的效果,例如ImageNet就有超過1 400萬張圖片[1]。目前,圖片數據集較為成熟,但在音視頻數據領域并沒有一種完善的數據集標準。這種典型非結構化數據面臨分析理解困難、結構化難度大、數據標準不統一和智能分析模型訓練樣本不足等問題,急需形成音視頻大數據樣本庫標準,有序地組織大量的音視頻數據,提升調用效率。
1 音頻數據入庫規范
1.1 音頻樣本庫概況
大量的音頻數據來源于不同的環境,例如監控錄音、在線音頻等,包含不同的聲音類別,具有不同的文件格式和音頻長度。考慮到音頻數據使用的普適性,也為了確保讀入的音頻數據格式統一,對不同格式保存的音頻數據都會統一轉化為wav音頻格式。為保證數據的平衡性,要保證每段音頻長度介于2秒—10秒之間,過長的音頻樣本數據被切割成合適大小的多個音頻樣本,每個片段應明顯屬于某一聲音類別[2]。
大量的音頻樣本經過切割后,樣本數據文件數量會大幅增加,為減小系統查找文件的負擔,需要將音頻樣本文件分別放在不同的文件夾下面。
音頻樣本庫中,除了音頻本身,同樣包含用于描述音頻樣本相關信息的文件,需要包含音頻類別、聲音級別等信息。為減少數據冗余,消除數據的修改異常、入庫異常和讀取異常,音頻數據樣本相關信息統一放入csv文件,以行為單位,每行包含一個樣本的相關信息。
1.2 編碼設計
根據音頻的信息類別,需要對6類信息進行編碼:
(1)原始文件名:使用正整數作為ID表示,能夠唯一標識一個樣本,不能為空,從1開始每個文件增加1。具有后綴‘.wav’。
(2)聲音類別:使用正整數作為ID表示,從1開始每類增加1。每種類別應具有唯一ID。
(3)聲音來源環境:使用正整數作為ID表示,從1開始每類增加1。每種類別應具有唯一ID。
(4)聲音分級:0表示背景音,1表示前景音。
(5)切割后文件名:[原始文件ID]-[聲音類別ID]-[聲音分級]-[聲音片段序號]。具有后綴‘.wav’。其中聲音片段序號使用正整數作為ID表示,從1開始每條增加1。來自不同原始文件的切割文件聲音片段序號互不相關,都重新計數。
(6)存放文件夾名:使用字符化正整數作為ID表示,從1開始每個文件夾增加1。
1.3 概念結構設計
每個樣本(指切割后的音頻文件)的相關信息應該包含文件名、文件夾名、原始文件ID、在原始文件中起始時間、在原始文件中結束時間、聲音分級、聲音類別ID和聲音來源環境ID。將所有樣本的信息依照順序保存到一個csv文件中。
為盡量減少數據冗余,將一個csv文件當作聲音類別對照表保存聲音類別與ID的對應關系。同樣也使用一個csv文件當作聲音來源環境與ID的對應關系。
1.4 信息設計規范
(1)數據文件
? 樣本文件名稱
切割后的樣本的文件名。‘[原始文件ID]-[聲音類別ID]-[聲音分級]-[聲音片段序號].wav’
示例:100-20-0-5.wav
上述文件名表述了是第100個原始文件切割所得,聲音類別是第20種,0表示是背景音,5說明是這個原始文件切割出的第5個片段。
? 原始文件ID:
原始文件的ID,可以由此ID找到原始文件。
示例:100
表示這個樣本是由100號原始文件切割得來。
? 開始
本樣本在原始文件中的開始時間。
示例:12.12
表示樣本從原始文件12.12秒開始。
? 結束:
本樣本在原始聲音中的結束時間。
示例:19.12
表示樣本到原始文件19.12秒結束。
? 聲音分級:
聲音的(主觀)顯著性等級。0 表示是背景音,1表示是前景音。
? 文件名:
該文件分配到的文件夾編號。
示例:100
表示樣本存放在第100個文件夾下。
? 類別ID:
聲音類別的數字ID。
? 環境ID:
聲音類別的數字ID。
(2)對照表
? 聲音類被對照關系:[類別ID] [類別名]
示例:1 boom
表示第一類聲音是爆炸聲。
? 聲音來源環境對照關系:[環境ID] [環境名]
示例:2 street
表示第二類聲音是來自與街道。
2 視頻數據入庫規范
2.1 視頻樣本庫概況
視頻監控在現代城市中正發揮著越來越重要的作用,交通要道、景區、商場、超市和樓道等地方都安裝有監控攝像機,每時每刻都會產生大量的視頻數據,對數據存儲的方式方法都有較高要求,不同格式的視頻數據處理也會不同,因此需要統一將所有視頻轉換成wmv格式進行存儲[3]。
在利用智能分析算法處理視頻時需要逐幀分析處理,1小時的視頻數據按標準25 bps測算,需要處理9萬幀圖像,計算需求極大。為了保證數據的平衡性以及針對性的處理視頻,需要對視頻數據文件進行切割,將原視頻分成5到10分鐘不等的視頻片段,并對拆分的視頻片段進行信息標注。
2.2 編碼設計
視頻數據文件的編碼應包括以下內容。
(1)原始視頻文件名:使用字符化正整數作為ID表示,從1開始每個文件增加1。具有后綴‘.wmv’。
(2)視頻類別:使用正整數作為ID表示,從1開始每類增加1。每種類別應具有唯一ID。
(3)切割后文件名:[原始文件ID]-[視頻類別ID]-[視頻片段序號]。具有后綴‘.wmv’。
其中聲音片段序號使用正整數作為ID表示,從1開始每條增加1。來自不同原始文件的切割文件聲音片段序號互不相關,都重新計數。
(4)存放文件夾名:使用字符化正整數作為ID表示,從1開始每個文件夾增加1。
2.3 概念結構設計
每個原始視頻文件應該包含一個csv文件,用于記錄文件名、文件夾名、原始時長和所分片段數。
分割后的每個視頻的csv文件應在包含原視頻信息的基礎上,增加分割信息,如視頻的起止時間、視頻段ID和視頻類別。
2.4 信息設計規范
(1)數據文件
樣本文件名稱
切割后的樣本的文件名。‘[原始文件ID]-[視頻類別ID]-[視頻片段序號].wmv’。
示例:100-2-5.wmv
上述文件名表述了是第100個原始文件切割所得,視頻類別是第2種,5說明是這個原始文件切割出的第5個視頻片段。
? 原始文件ID:
原始文件的ID,可以由此ID找到原始文件。
示例:100
表示這個樣本是由100號原始文件切割得來。
? 開始:
本樣本在原始文件中的開始時間。
示例:12
表示樣本從原始文件12分鐘開始。
? 結束:
本樣本在原始聲音中的結束時間。
示例:19
表示樣本到原始文件19分鐘結束。
示例:-1
表示樣本到原始文件最后時刻結束。
? 文件名:
該文件分配到的文件夾編號。
示例:100
表示樣本存放在第100個文件夾下。
? 類別ID:
聲音類別的數字ID。
示例:5
表示樣本屬于視頻類別中的第5類。
(2)類別對照表
對照關系:[類別ID] [類別名]。
示例:1 Abandon
表示第一類視頻用于遺留物檢測。
3 圖片數據入庫規范
3.1 圖片樣本庫概況
隨著深度學習的快速發展,各種優秀的目標檢測算法相繼涌現。目標檢測的任務就是找出圖像中我們所需要的目標,并且確定其位置及其他屬性[4],如圖2所示。

圖2 目標檢測效果示例圖
圖2左側輸入為待檢測圖片,右側輸出為標注了小狗位置的圖片,要使用深度學習算法[5]實現上述的處理,就需要用大量標注了小狗位置的圖片對神經網絡進行訓練。本文建立的圖片樣本庫將仿照PASCAL VOC數據集對圖片進行分類存儲[6],并產生相應的標簽文件,對圖片中的信息進行存儲[7]。
3.2 層級結構
目前分成4大類、8小類,后續可針對相應的需求進行擴展,加粗字體為最終檢測的目標,層級結構圖如圖3所示。
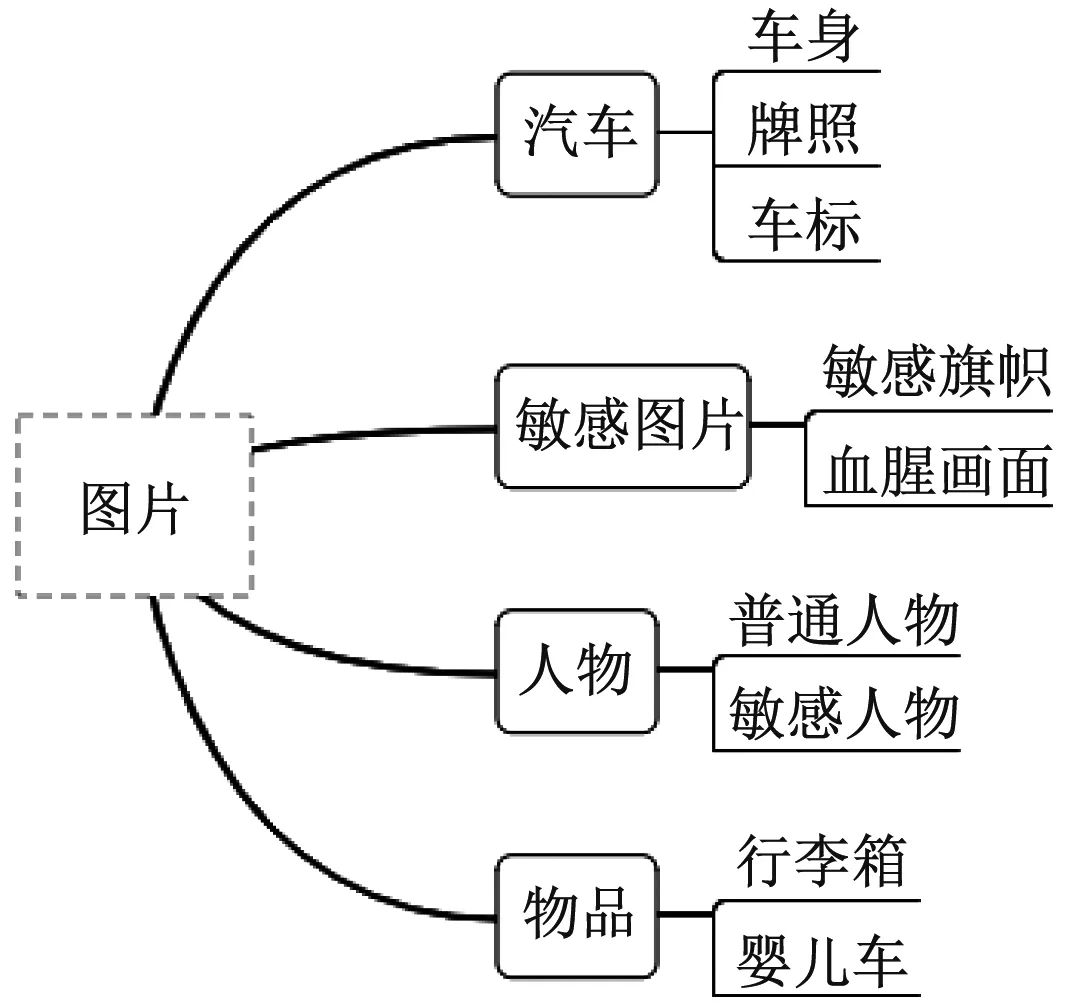
圖3 層級結構圖
3.3 編碼設計
(1)圖片文件名:使用字符化正整數作為ID表示,從1開始每個文件增加1。具有后綴‘.jpg’。
(2)xml標簽文件[8]:使用字符化正整數作為ID表示,文件名與對應的圖片相同。具有后綴‘.xml’。
(3)數據集分割文件名:訓練集為train,驗證集為val,測試集為test,并且具有后綴‘.txt’。
3.4 標簽文件設計
圖片的注釋方式為xml文件,注釋規則[9]如表1所示。
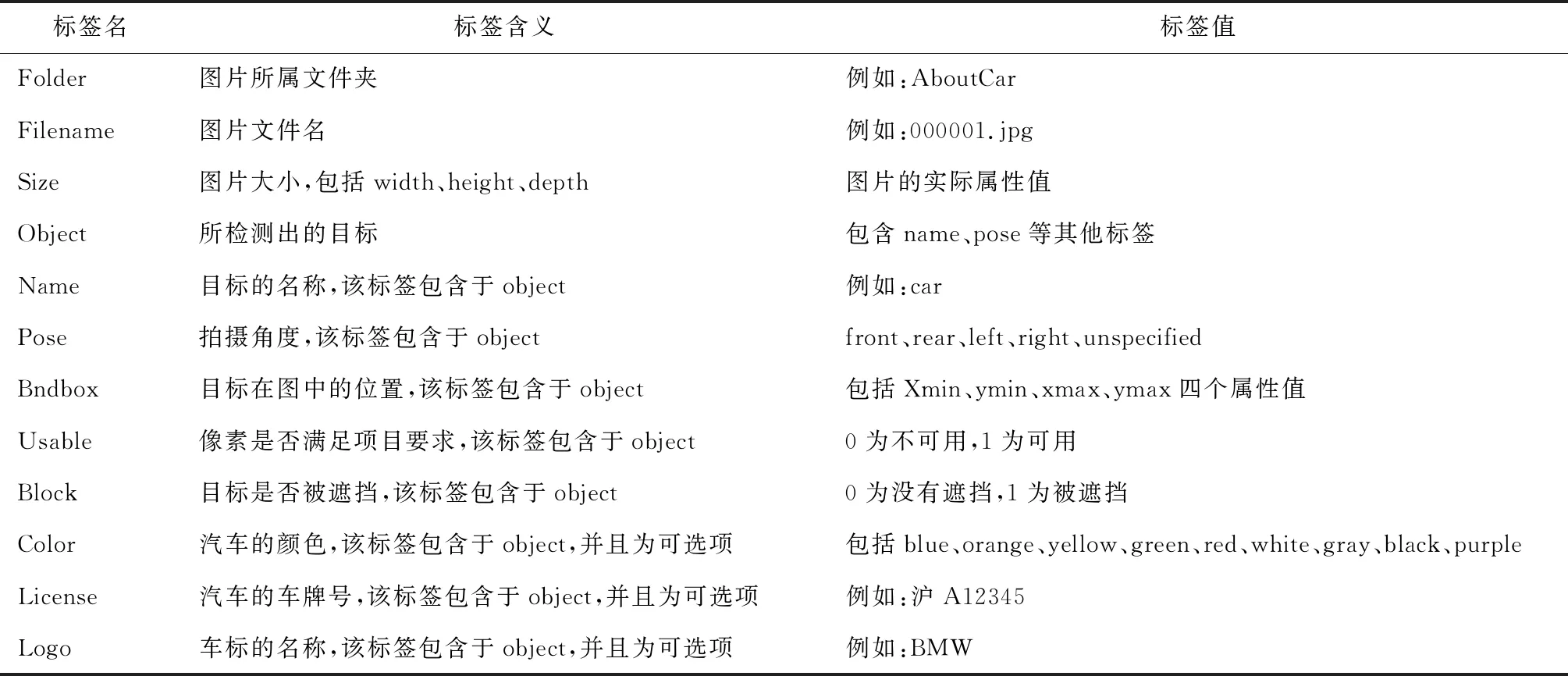
表1 xml注釋規則表
4 總結
本文針對當前海量音視頻樣本數據管理難的問題,形成了一套面向大規模音視頻數據的入庫規范,在實驗中運行聲音識別算法和視頻處理算法時,都能夠正確調用特定范圍的音視頻。在一定程度上優化了音視頻數據的調用效率,減少了數據的冗余度。
在數據實驗過程中發現,大規模音視頻樣本數據集仍存在一些問題,例如數據重疊、數據分類不明確等,對數據調用的準確性有一定影響。后續將對樣本入庫規范進一步優化,細化數據信息,盡可能降低數據的冗余。此外將結合半自動化標注工具,為用戶提供接口,針對模糊數據進行人工修正和更新,以保證樣本庫的準確性和時效性。
