基于Scrapy+LR分類器的暗鏈檢測方法的設計與實現
2021-08-03 06:22:52張培
電腦知識與技術 2021年17期
張培

摘要:隨著網頁被植入暗鏈的網絡安全事件不斷增加,傳統基于規則檢測暗鏈的規則庫覆蓋不全面、低檢出率等問題更加凸顯。設計一種基于Scrapy和LR分類器的暗鏈檢測方法,通過Scrapy爬取目標網頁,利用分類器模型檢測是否植入暗鏈,檢測結果用來擴充數據集,迭代更新分類器模型。模型訓練中利用網格搜索與交叉驗證選擇最優超參數,最優模型的f1分數達到0.956。此外隨著數據集的擴充,測試集的暗鏈檢測召回率及f1分數逐漸提高。
關鍵詞:暗鏈;爬蟲;Scrapy;LR分類器;sklearn
中圖分類號:TP393.08? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)17-0236-03
開放科學(資源服務)標識碼(OSID):
Design and Implementation for Hidden Hyperlink Detection Based on Scrapy and LR Classifier
ZHANG Pei
(Information Center, Jiangsu University, Zhenjiang 212023, China)
Abstract: With the increasing number of cybersecurity incidents in which hidden hyperlinks are implanted into websites, the problems such as incomplete coverage and low detection of the traditional rule-based detection method have become more prominent. Design of a method based on scrapy and LR classifier, crawl the target webpage through scrapy, which use the trained classifier model to detect whether hidden hyperlinks are implanted, the detection results are used to expand the dataset and iteratively update the classifier model. In model training, grid search and cross-validation are used to select the optimal hyperparameter, and the f1 score of the optimal model can reach 0.956. In addition, with the expansion of the data set, the detection recall rate and f1 score of the test set gradually improved.
Key words: hidden hyperlink; crawler; scrapy; LR classifier; sklearn
1 背景
國家互聯網應急中心編寫的《2019年中國互聯網網絡安全報告》中指出2019年我國境內被篡改的網站數量為185573個,其中暗鏈超過50%[1]。暗鏈是網頁里一種隱藏的鏈接,常被黑帽用于提升SEO(搜索引擎優化)權重,技術上通常利用網站的漏洞或后門植入賭博彩票、淫穢色情、游戲私服、非法辦證、虛假醫療等黑灰色非法產業的網站鏈接。網站被植入暗鏈會引起瀏覽器風險提示、搜索引擎懲罰、用戶被欺騙等后果,甚至會被上級部門通報,很大程度上影響單位形象導致信譽受損。
面對網站被偷偷植入暗鏈的問題,通過定期網頁爬蟲主動發現并分析可有效減少暗鏈數目,避免不必要的損失。爬蟲是一種可以自動、高效地抓取海量網頁用來分析、挖掘的技術,市場上有多種優秀爬蟲框架(如Scrapy)可供工作中使用[2-3]。通常我們可以借助規則庫、關鍵字匹配等傳統方法檢測網頁被植入暗鏈[4-5],但隨著植入暗鏈的網頁數量的日漸增多、植入手段更加豐富,傳統方法存在的特征覆蓋不全面、特征庫無法及時更新、檢出率低等問題更加凸顯。
本文旨在設計與實現一種通過Scrapy爬取待檢測的目標網頁、然后利用LR分類器識別是否植入暗鏈的檢測方法。此外,檢測結果用來擴充數據集,迭代更新分類器,使用網格搜索與交叉驗證選擇最優參數,提高檢出率。
2 方法設計
本文使用Scrapy爬蟲框架編寫頁面爬蟲程序,定期爬取目標域名下的全量網頁。利用訓練好的LR分類器模型進行預測抓取到的網頁是否被植入暗鏈,將標記為存在暗鏈的數據追加到分類器模型訓練中用到的數據集,重新訓練模型,具體設計流程如圖1所示。
2.1 LR分類器模型
暗鏈檢測本質上就是判斷一個網頁存在暗鏈還是不存在暗鏈,是一個典型的二分類問題。本文選擇機器學習中常見的二分類算法-邏輯回歸(LR,Logistic Regression)[6-7]訓練分類器,邏輯回歸以概率的形式輸出結果,可解釋性強、訓練快。這里利用機器學習工具包sklearn[8]完成LR分類器模型的訓練與應用。
2.1.1 暗鏈特征提取
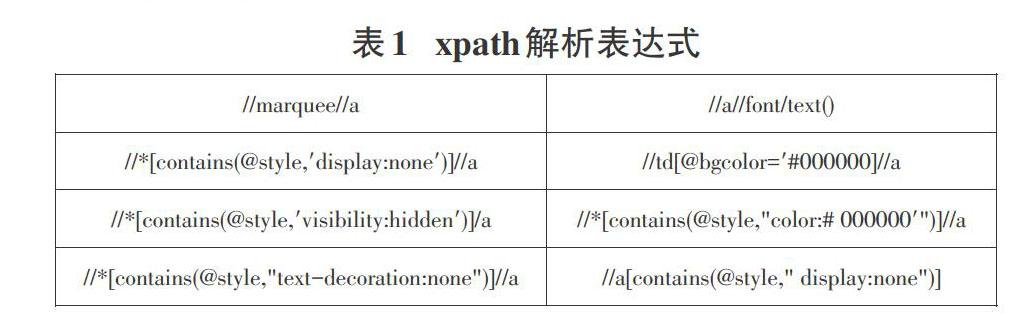
通過篡改網頁源碼中的HTML屬性、CSS樣式、JavaScript腳本可以達到部分鏈接“看不見”的效果,本文參考文獻[9]中提出的源碼可疑域、敏感域,借助xpath解析庫提取了可疑域及敏感域中的a標簽主要文本特征(href、text/title),表1列舉了常見a標簽的xpath提取暗鏈的解析表達式。
2.1.2 特征工程
對2.1.1提取的文本特征進行特征值化,考慮中文文本語句無用詞、標點符號多的情況,這里利用分詞工具jieba將暗鏈的文本特征轉換成topK個詞特征,這里設置K為60。
利用常用的TFIDF(Term Frequency/Inverse Document Frequency)算法進行向量化,該算法綜合考慮詞在單個樣本中的存在頻率和在整個數據集中的存在頻率,適當地對某些出現頻率低的關鍵詞進行加權。實際環境中網頁類型復雜、鏈接數目多,使用TFIDF進行特征值化后的特征維度成千上萬,這里使用PCA(Principle Component Analysis)技術在解決維度泛濫的情況下保留大部分的特征信息,這里選擇保留95%,圖2給出了特征工程的偽代碼。
2.1.3 訓練準備
由于實際我們能準備的暗鏈語料很少,但希望得到更高檢出率的分類器模型,這里使用交叉驗證將訓練數據分成為訓練集和驗證集,利用驗證集在訓練過程中及時評估模型結果選擇合理的參數。此外,使用網格搜索技術提高模型效果,即對部分超參數取不同值進行排列組合,最終窮舉得到一個最優的模型超參數。
2.2 LR分類器模型
Scrapy是一個代碼結構簡單、開發速度快的異步網絡爬蟲框架,通過Scrapy Engine完成了Spider(爬蟲)、Scheduler(調度器)、Downloader(下載器)、Item Pipeline(管道)等模塊之間的信號、數據傳遞。
在自定義的Spider模塊中定義入口待爬隊列start_urls,例如某高校全部子域名的首頁。此外,明確待檢測的目標域名列表,這里要求待爬取頁面的域名或Referer的域名在目標域名列表中。
針對爬取的網頁響應體Response,我們主要進行以下三類處理:
使用LR分類器模型判斷是否植入暗鏈。若存在暗鏈,將referer、url、response等信息生成Item,提交給Item Pipeline處理,存入數據庫/文件中,用于擴增數據集。
當前爬取頁面的域名在目標域名列表中,構建Selector(選擇器)解析對象,提取a標簽中的url,若url的域名不在目標域名列表中,則構建Request加入Scheduler的url隊列。
當前爬取頁面的域名在目標域名列表中,使用正則表達式'((http(s)?:\/\/)[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+(:[0-9]{1,5})?[-a-zA-Z0-9()@:%_\\\+\.~#?//=])'提取顯示頁面可見的url,若url的域名不在目標域名列表中,則構建Request加入Scheduler的url隊列。
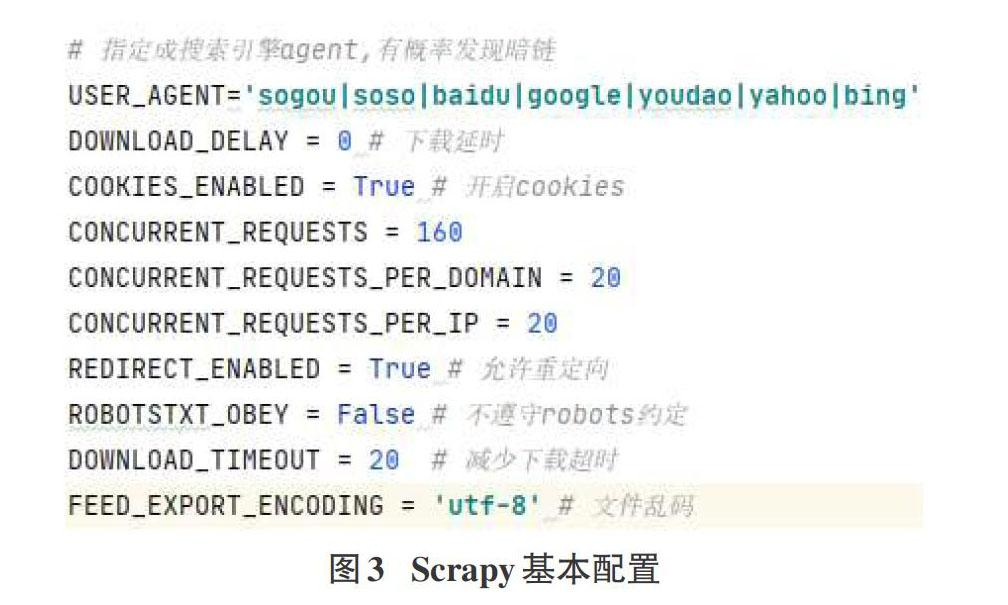
實際爬蟲過程中,我們會遇到waf攔截、安全狗、IP限制、等反爬手段,通常我們可以指定User agent、IP代理、對接Selenium等方式避免。此外過程中還存在下載超時、編碼異常、url重定向等問題,圖3給出了Scrapy爬蟲中的一些應對配置。
3 方法評估
本文數據集來自2017中國網絡安全技術對抗賽《惡意網頁分析》賽題,我們選擇其中417個被植入暗鏈的頁面作為反例,隨機選擇1074個正常頁面作為正例。
上文提到利用網格搜索技術選擇最優超參數,這里正則化項參數選擇l1、l2,優化算法參數選擇liblinear、lbfgs、newton-cg、sag。這里我們選擇f1分數作為評估指標,f1分數兼顧了分類模型的精確率和召回率,結果在0和1之間,越接近1效果越好。此外我們選擇10折交叉驗證,訓練集中9份被用作訓練,剩下的1份用來驗證。表2給出了各參數下的f1分數的平均值及標準差,可以看出正則化項選擇l1,優化算法選擇liblinear的情況下可以得到最高為0.956的f1分數。
現實工作中我們希望越多真實被植入暗鏈的頁面被檢測出來,召回率可以表示實際植入暗鏈頁面有多少被預測成反例。這里數據集按3:1劃分訓練集和測試集,利用測試集預測模型的真實效果。圖4給出不同反例數目下的召回率及f1得分結果,隨著反例數目的增加,模型效果越來越好。這表明我們通過Scrapy爬蟲持續擴充數據集中的反例數量,迭代訓練新的模型,進而會得到更高的檢出率。
4 結束語
本文基于實際工作中利用規則檢測暗鏈存在的檢出率低、規則更新不及時等問題,設計與實現了一種基于scrapy和LR分類器的暗鏈檢測方法。使用LR分類器模型預測scrapy爬取的目標網頁,檢測結果用來擴展數據集反例,迭代訓練分類器。實驗結果表明本方法可以得到較高的f1分數,且實際暗鏈檢出率在模型迭代的過程中逐漸增加。下一步的工作會進一步豐富網頁的暗鏈特征提取。
參考文獻:
[1] CNCERT.2019年中國互聯網網絡安全報告[EB/OL].[2020-08-11].https://www.cert.org.cn/publish/main/46/2020/20200 811124544754595627/20200811124544754595627_.html.
[2] Yin F L,He X T,Liu Z X.Research on scrapy-based distributed crawler system for crawling semi-structure information at high speed[C]//2018 IEEE 4th International Conference on Co mputer and Communications (ICCC).December 7-10,2018,Chengdu,China.IEEE,2018:1356-1359.
[3] 安子建.基于Scrapy框架的網絡爬蟲實現與數據抓取分析[D].長春:吉林大學,2017.
[4] 杜小芳.一種快速檢測網頁黑鏈的方法:CN109981604A[P].2019-07-05.
[5] 邢容.基于文本識別技術的網頁惡意代碼檢測方法研究[D].北京:中國科學院,2012.
[6] 張蕾,崔勇,劉靜,等.機器學習在網絡空間安全研究中的應用[J].計算機學報,2018,41(9):1943-1975.
[7] Liu T,Zhang L T.Application of logistic regression in WEB vulnerability scanning[C]//2018 International Conference on Sensor Networks and Signal Processing (SNSP).October 28-31,2018,Xi'an,China.IEEE,2018:486-490.
[8] 黃永昌. scikit-learn機器學習:常用算法原理及編程實戰[M].北京:機械工業出版社,2018.
[9] 孟雷.多域識別構建監督學習模型檢測網頁暗鏈[J].信息安全與通信保密,2019(10):63-71.
【通聯編輯:代影】
