偽標簽半監督通信輻射源個體識別方法
2021-08-04 08:37:14呂昊遠
計算機測量與控制 2021年7期
呂昊遠,俞 璐,陳 璞
(陸軍工程大學 通信工程學院,南京 210007)
0 引言
在現代戰爭日趨復雜的電磁環境空間中,電子對抗發揮著舉足輕重的作用。作為重要的非合作識別手段,電子偵察是電子對抗的基礎和前提[1]。電子偵察手段將獲取通信輻射源信號數據的幅度、脈寬、載頻等參數經過處理,得到通信輻射源目標的信息,從而做到對于信息制取權的實時掌握[2]。
隨著技術的不斷發展,新型多功能輻射源信號參數呈現出多變性,信號樣式也變得越來越復雜,不同模式、個體間的信號參數交錯,對于輻射源目標的識別,傳統電子偵察識別方法就愈加困難。為了能夠準確地識別、干擾、打擊敵方目標,首要環節就是做到輻射源個體區分,由此提出輻射源個體識別(SEI,specific emitter identification)技術[3]。“個體特征”就是由通信設備內部的不同制造工藝而導致所發射信號的細微差異。輻射源個體識別技術通過測量手段獲取信號的外部特征,提取出反映目標身份的信息,確定發射所得信號的特定輻射源個體[4]。
作為人工智能領域近十年來最受關注的技術之一,深度學習通過深度神經網絡將底層的特征映射到高層,并且通過高層將特征抽象出來,從而發現數據的分布式特征表示[5]。深度學習的快速發展為通信輻射源個體識別提供了新的處理思路和研究方法,深度學習直接從輸入的信號數據中提取個體特征,跨越人工設計特征階段[6],應用在輻射源個體識別問題中可以節省大量科研成本。
深度網絡訓練需要龐大的數據集,但在實際環境中獲取到具有標簽信息的信號樣本數量非常有限,“小樣本”問題嚴重制約了通信輻射源個體識別技術的應用與發展[7],在這種情況下,深度學習方法中引入半監督的思想,充分利用大量無標簽信號樣本內在的結構信息提取通信輻射源個體本征特征,從半監督學習的角度提高通信輻射源個體識別技術的性能,這在信號偵察對抗和無線電監視管控等領域具有重大的研究意義和應用價值[8]。
先前的研究工作中,基于端到端半監督深度學習的通信輻射源個體識別技術研究較少。黃健航[9]提出的通信輻射源個體識別方法用到了半監督矩形網絡[10],茍嫣[11]提出的遷移極限學習機采用基于實例的遷移學習方法。半監督學習方面,Lee[12]提出的基于偽標簽的半監督深度學習方法將偽標簽訓練機制加入到深度卷積神經網絡中,在MNI-ST圖像數據集中達到較高的識別準確率。
本文在偽標簽半監督方法的基礎上,提出一種基于偽標簽半監督深度學習的通信輻射源個體識別方法,并在生成偽標簽中使用加權平均的思想進行改進,在5臺同型號USRP輻射源采集的數據集上驗證算法的魯棒性。并與全監督方法和改進前的偽標簽半監督方法進行比對,實驗結果顯示,改進后的偽標簽半監督算法在少量有標簽信號樣本條件下能夠達到更好的識別性能。
1 偽標簽半監督
在基于偽標簽的半監督學習方法中,深度網絡以有監督的方式同時訓練有標簽和無標簽數據。對于無標簽數據,使用網絡的預測輸出作為其偽標簽,加入到網絡中再次訓練,充分挖掘出無標簽樣本中與有標簽樣本完全相同的個體信息,最終在測試集上取得較好的識別效果[13]。
本章分別介紹半監督學習的思想和基于偽標簽的半監督深度學習方法,并引入熵正則化的概念,從理論方面說明偽標簽方法的有效性。
1.1 半監督學習
相比于稀缺的有標簽樣本,無標簽樣本數量眾多且相對容易獲取。為了能夠有效利用寶貴的有標簽樣本,也為了使大量且相對便宜的無標簽樣本不至于浪費而發揮出最大效用,研究學者們提出了半監督學習技術[14]。
通過近些年的不斷探索發展,半監督學習已經成為機器學習領域的研究熱點。它的基本思想是使用大量無標簽樣本輔助少量有標簽樣本進行學習,達到提高學習效果的目的[15]。如圖1(a)所示,有4個分屬于兩個不同類別的有標簽樣本點,當僅考慮這4個有標簽樣本點時,只能假設出線性決策邊界,但如果考慮到數量較多的無標簽樣本點(白色圖形)時,如圖1(b)所示,就可以繪制出正確的非線性決策邊界而確定真正的樣本分布。

圖1 半監督學習示意圖
因此,在半監督學習中,結合使用稀少的有標簽和海量無標簽樣本,得到更精確的決策邊界來提高模型的推廣性能[16]。
1.2 偽標簽方法
偽標簽就是對于無標簽樣本數據,通過網絡預測結果,賦予其標簽值。賦標簽值時只選擇對每個未標記樣本具有最大預測概率的類別。

(1)
再以有監督的方式同時使用有標簽和無標簽數據對網絡進行訓練。對于未標記的數據,其偽標簽值要隨著網絡權值的變化而不斷更新[17]。由于偽標簽的可信度以及有標簽數據和無標簽數據的數量規模的差距,兩部分損失之間的平衡對于網絡訓練的性能至關重要,因此整體損失函數為:
(2)
C是類別數,n是有標簽樣本數目,n′是無標簽樣本數目,L是交叉熵損失函數,f是神經網絡對于有標簽樣本的輸出預測,y是對應的標簽,f′是神經網絡對于無標簽樣本的輸出預測,y′是其對應的偽標簽。α(t)是平衡兩部分損失權重的系數函數,t是當前的迭代輪次。
在訓練過程中。α(t)決定著無標簽數據損失部分在整體損失中所占比重的大小。在訓練初始階段,因為網絡輸出預測不夠準確,所以賦予的偽標簽值準確性較低,此時如果α(t)值過大,增大無標簽數據損失權重會導致訓練性能退化,但α(t)值太小就不能充分利用無標簽數據的好處,對于網絡性能提升有限。設置α(t)為退火過程,初始值為0,再隨著訓練迭代次數的增加而緩慢增長并最終固定,網絡的預測能力也會隨之增強[18]。
(3)
T1為加入無標簽損失時的起始輪次值,T2為權重固定的輪次值,αf為最終無標簽損失部分的權重固定值,3個值的設置需要在實驗中結合具體應用場景設置。這個退火過程的設置可以使得優化中避免較差的局部最小值,使得無標簽數據的偽標簽盡可能地類似于真實標簽。
1.3 熵正則化
理想的深度網絡模型中,不同的輻射源信號在特征空間分類邊界上密度較小,而來自同一個輻射源的信號特征距離較近、密度較大并且具有連續性。熵正則化從這個思想出發,在最大后驗估計框架下充分利用無標簽信號樣本[19]。熵正則化通過最小化無標簽數據類別的條件熵來支持類之間的低密度分離,其表示形式如下:
(4)

(5)
n是有標簽信號樣本的數量,xm是第m個有標簽信號樣本,λ是權重系數平衡兩部分。熵正則化的意義在于讓模型對于無標簽信號樣本的識別概率盡可能地集中在某一類,減小決策邊界附近的信號密度。通過最大化有標簽信號數據的條件對數似然和最小化無標簽樣本的熵,使得深度網絡的泛化能力增強。通過比較式(5)和式(2)可以看得,前文所提的偽標簽方法相當于熵正則化,式(5)中的前后兩項分別對應式(2)中的前后兩項,權重系數λ對應于α。
2 深度學習方法設計
2.1 算法過程
基于偽標簽半監督深度學習的通信輻射源個體識別方法訓練流程如圖2所示。

圖2 訓練流程
首先初始化深度網絡的參數,少量有標簽和大量無標簽信號樣本構成算法的輸入數據,接著開始訓練樣本數據,由于在訓練初始階段模型的預測準確率不高,偽標簽的可信度非常低,所以當訓練周期數小于T1時,只計算有標簽數據部分的損失值。當模型訓練到一定階段(周期數大于T1)時,網絡的預測能力增強,這時偽標簽信息相對可信,結合有標簽和無標簽信號樣本兩部分損失,構建整體損失函數,并根據式(3),在接下來的訓練中,動態調整兩部分損失的權重系數。
偽標簽原算法在一輪迭代中,將網絡的輸出預測值強銳化作為樣本的偽標簽,然后在同一輪中計算輸出預測和偽標簽的損失值,這對于本實驗的輻射源信號數據而言,在訓練初期偽標簽的優劣條件下都存在問題(具體如表1所示)。本文引入加權平均的思想,提出改進的輪次標簽法。
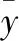

圖3 輪次標簽
輪次標簽法在訓練初期,有效增強了偽標簽的質量,提升了網絡模型的魯棒性,具體的算法改進前后,在預測正確和錯誤兩種情形下的比較如表1所示。

表1 算法改進前后比較
在訓練過程每個周期內,網絡對于無標簽信號樣本都要預測標簽值,將加權平均結果作為其偽標簽,然后就可以作為有標簽信號樣本,加入到訓練集中重復訓練,直至訓練周期達到預設值結束。
2.2 網絡結構
根據輸入信號樣本的形式,以及對網絡的需求關系,設計出如圖4所示的CNN模型,除輸入輸出層外,中間的特征提取過程包括兩個卷積層和兩個全連接層。具體的信號樣本劃分,構建數據集會在下一章中說明。

圖4 CNN結構圖
網絡的輸入樣本維數為 2×128,兩個卷積層的核數量分別為 32,16,大小分別是(1,3),(2,3)。第一個全連接層的神經元個數為 128,第二個全連接層神經元個數為5,對應5個輻射源個體的5分類問題,最后通過softmax層輸出預測值。除最后一層使用softmax激活函數,其余層使用ReLU激活函數。并且在每層后會連接至dropout層進行正則化,參數設置為 0.1,實驗選用交叉熵損失函數和Adam優化器。
3 實驗與分析
3.1 實驗數據準備
為了評估基于偽標簽半監督深度學習算法對于通信輻射源個體識別問題的可行性與有效性,在實驗室條件下,采用6臺USRP N210設備作為信號樣本采集的輻射源,其中5臺作為發射端,固定1臺為接收端,在采取的輻射源信號上實驗驗證。
發送端和接收端程序采用LabVIEW軟件實現,USRP通過網絡電纜與計算機相連[20]。所采集的數據是相互正交的IQ兩路載波信號。采集數據過程中設置頻率帶寬為1 GHz,采樣頻率為1 MHz。
對采集到的通信輻射源信號進行預處理制作成數據樣本集,去除采樣幀初始階段幀與幀切換時產生的不規則樣本點,并且進行功率歸一化比例變換,再設置5類標簽值,將輻射源個體類別進行標號。
將所采集到的信號樣本按照一定比例劃分為訓練集和測試集,并且選取訓練集中的少量樣本作為有標簽訓練集,和大量樣本作為無標簽訓練集。設置有標簽信號樣本數為1 000和2 000。有標簽信號樣本與無標簽信號樣本的比例大小為(1:3)。測試集的樣本數為500。
3.2 實驗結果分析
本文使用深度學習框架PyTorch實現對深度神經網絡的構建以及算法的訓練與測試。計算機系統環境為Windows10-64-bit,開發環境為anaconda+pytorch+pycharm,軟硬件環境配置如表2所示。

表2 軟硬件環境
半監督訓練過程中,設置200次的迭代次數,根據多次實驗效果,設置T1的值為30,T2的值為180,αf的值為0.2。
圖5~8分別繪制在不同有標簽信號樣本數量條件下,訓練過程中訓練樣本的損失函數和識別準確率隨著迭代次數增加的變化曲線。識別準確率包括全監督訓練和半監督訓練,半監督訓練中又分為有標簽信號樣本和無標簽信號樣本兩部分,其中無標簽樣本的原有標簽值只用在每次迭代后計算樣本的識別準確率,不投入深度網絡指導訓練。

圖5 1 000個有標簽樣本的訓練過程中的損失值
可以看出,當迭代次數小于T1時,兩種訓練方式的損失和準確率的變化趨勢一致,當迭代次數為T1時,半監督訓練過程中由于加入了無標簽信號樣本這部分損失值,整體的訓練損失值產生波動,在T2之后逐漸趨于穩定。與全監督訓練比較,因為半監督訓練中使用了更多的無標簽信號樣本,所以損失值收斂的速度更慢波動更大,且隨著無標簽信號樣本的數量增多,這一現象會更加明顯。半監督訓練過程,相比較于有標簽信號樣本,無標簽信號樣本的識別準確度較低,這是因為有標簽信號樣本在訓練過程中使用了真實標簽值,而無標簽信號樣本而無標簽信號樣本在訓練過程中使用的偽標簽值與真實標簽值還存在著一些差異。

圖6 1 000個有標簽樣本的訓練過程中的準確率

圖7 2 000個有標簽樣本的訓練過程中的損失值

圖8 2 000個有標簽樣本的訓練過程中的準確率
圖9和圖10將兩種條件下測試集的識別結果用混淆矩陣展示,顏色表示識別程度,顏色越深表示識別為此類的概率越大。混淆矩陣對角線上的數據表示被正確分類的準確率,其余表示被錯誤分類,由此可見,改進的偽標簽半監督方法在測試集上分別達到了88.92%和94.14%的識別準確率,第二類輻射源的識別準確率最高,相比之下,第一類輻射源與第三類輻射源的差別較小,在識別過程中有一定的識別難度。

圖9 有標簽樣本數為1 000的混淆矩陣

圖10 有標簽樣本數為2 000的混淆矩陣
設置有標簽和無標簽信號樣本數比例,并與兩種有標簽樣本數構建不同的組合方式,如表3和表4所示,通過100次蒙特卡洛實驗最終得出不同設置條件下全監督方法,原偽標簽半監督方法和改進后的偽標簽半監督方法的識別準確率,其中帶*的為改進后的偽標簽半監督方法。

表3 1 000標簽數時的識別準確率

表4 2 000標簽數時的識別準確率
全監督訓練過程中只用到有標簽樣本,所以改變有標簽訓練樣本所占比其值不變。全監督方法受標簽數目影響較大,當標簽數目較少時,測試集的識別準確率較低,加入無標簽樣本的半監督在標簽數目較少的情況下,取得了較高的識別準確率,相比于原偽標簽方法,改進后的偽標簽方法識別準確率得到提升。
一定范圍內當無標簽樣本數所占比增大時,半監督學習的識別準確率會增大,實驗中發現有標簽樣本和無標簽樣本數目為(1:3)時效果最好,但如果繼續增大無標簽數目,模型的識別性能反而會下降,且結果具有波動性,這是因為過多的無標簽樣本會使生成錯誤偽標簽的概率增大,訓練過程中就會受到錯誤的偽標簽影響使得識別準確率降低。
當標簽數目較多時,全監督和半監督方法的識別準確率相差較小,這也說明了,只有在標簽信號樣本數目較少的情況下,偽標簽半監督學習在訓練過程中才更能體現出避免過擬合增強魯棒的特性。
4 結束語
本文提出了一種基于偽標簽半監督深度學習的通信輻射源個體識別方法,介紹了偽標簽半監督深度學習方法的提出背景、理論基礎和算法過程,并且根據加權平均的思想加入了輪次標簽法。對比分析改進的偽標簽半監督方法與全監督方法和原有的偽標簽半監督方法在5臺USRP輻射源數據集上的訓練過程和分類結果,當有標簽信號樣本數為1 000和2 000,所占樣本總數的四分之一時,分別得到88.92%和94.14%的識別準確率,證明了在少標簽樣本條件下的輻射源個體識別問題上有著很好的應用效果。在后續的工作中,將對于偽標簽質量的提高,深度網絡結構改進等方面繼續深入研究探索。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
人大建設(2020年4期)2020-09-21 03:39:12
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電子制作(2018年11期)2018-08-04 03:25:42
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
