基于深度學習的食品安全領域實體關系抽取研究
2021-08-05 02:37:40孫劭芃汪顥懿張青川
中國釀造 2021年7期
關鍵詞:模型
孫劭芃,汪顥懿*,左 敏,張青川
(北京工商大學 電商與物流學院 農產品質量安全追溯技術及應用國家工程實驗室,北京 100048)
作為最基本的民生問題,食品安全牽動著億萬民眾的神經,一經曝光,就能迅速引起社會各階層的普遍關注,激發負面聯想,甚至誘發非理性的線下集合行為,危及社會穩定。隨著越來越多的食品安全報道在網絡上傳播,快速且準確的對突發報道中的關鍵信息進行抽取對于政府對食品安全領域的監管和預測都有著尤為重要的意義和價值。
隨著信息時代的到來,互聯網技術高速發展。作為自然語言處理[1]的重點課題之一,實體關系抽取[2]作為實現語義關系自動抽取和查詢匹配的一種新興技術,近年來一躍成為熱門研究領域,受到越來越多科研人員的重視。在諸多的實體關系抽取方法中[3-6],有監督的實體關系抽取方法[3]依然是目前最基本最常見的方法,其主要過程是在已標注過的訓練數據集上訓練出關系分類模型,從而在測試集上進行對應的實體關系抽取。本文也采用了有監督的深度學習網絡模型對實體關系抽取進行研究。
實體關系抽取一直是經典而又富有挑戰性的任務,在過去二十多年的研究發展下取得了很多階段性的突破,同時也廣泛應用在知識圖譜[7]的構建、自動問答[8]、文本摘要[9-10]等諸多重要領域。隨著以深度學習為基礎的人工智能潮流席卷全球,深度學習下的實體關系抽取也同樣得到了快速發展,它有效改善了傳統標注工具的自身缺陷,取得了良好的效果。文獻[11-15]對基于深度學習的實體關系抽取方法進行了總結歸納。文獻[12]介紹了基于深度學習的實體關系抽取方法,并進行比對;文獻[13]對基于深度學習的實體關系抽取的基本框架和流程進行了介紹。自2018年以來,BERT(bidirectional encoder representations from transformers)網絡被應用到自然語言處理(natural language processing,NLP)的各個領域,并都取得了突破性的效果[16-20],其獨有的Transformer Encoder編碼模型,能夠解決句子中的依賴關系,對句子的內部結構進行有效地學習,保證了句子字向量訓練的質量,從數據基礎的角度為后續的預測模型提供了保障,提高了后續模型的預測準確性[21-22]。值得注意的是,最近注意力機制在NLP上取得了廣泛的應用和成功。本研究也基于領域詞的位置感知注意力機制,對雙向長短期記憶網絡進行了改進,取得了較好的效果[23-24]。
本文主要研究針對食品安全領域語料的實體關系抽取方法,在分析現有的實體關系抽取方法優劣的基礎上,采用了BERT-雙向長短期記憶網絡(bi-directional long shortterm memory,BiLSTM)雙維度雙網絡模型結構,不僅很好的處理了不同實體關系的區分度,而且有效學習了文本遠程語義的信息和結構。同時,在注意力機制的層面上,為了使BiLSTM網絡更好的對詞匯特征的語義和文本內部位置信息的學習,采用了領域詞識別和詞語位置分布信息結合計算的處理方法。整個雙網絡模型在獨立構建的食品安全領域數據集上進行實驗和測試,展示出較好的性能效果。
1 數據來源與處理
1.1 數據來源
在進行研究之前,需要充足的語料資源作為數據基礎,因此首先構建了食品安全領域語料庫,并對庫中所有語料做預處理工作,最終將處理好的語料作為本次研究的數據集。
食品安全領域語料庫中的語料主要來自于百度新聞、食安通平臺、食品伙伴網、新浪微博等平臺近年來發布的食品安全領域相關文章,包括檢驗檢疫、生產銷售、制度發布、公眾投訴、安全事件等相關類型,共計5 000余篇。語料庫部分截圖見圖1。

圖1 食品安全領域語料庫(部分)Fig.1 Corpus of food safety (part)
1.2 數據處理
本文實體和關系的抽取分別是句子級別的關系識別和標簽級別的實體識別任務,目的是抽取食品安全領域語料中的二元關系和實體。將食品安全語料中實體關系定義為R,兩個實體的關系用三元組(Ei,R,Ej)表示,其中Ei為實體關系中的主體,Ej為客體,R為映射關系,根據食品安全領域語料的行文特點,定義映射關系和識別的三元組見表1。

表1 食品安全領域語料實體關系抽取類型明細(部分)Table 1 Detailed list of entity relation extraction types of corpus in food safety field (part)
在識別模型訓練過程中,把食品安全領域語料劃分成多個待識別關系和實體的句子并為每個句子進行標注,貼上正確的標簽。標注結果部分截圖見圖2。

圖2 實體關系標注結果(部分)Fig.2 Results of entity relation annotation (part)
根據設計的三元組形式,在模型訓練中,分別輸入語料句子和相應已標注的三元組信息(實體1,實體2和實體關系)。訓練完成后,在模型測試時,輸入一個新的語料句子,也按訓練集標注格式輸出識別的關系與實體對。
1.3 評價指標的計算
采用準確率(precision,P)、召回率(recall,R)與F1值作為實驗的評價指標。準確率(P)計算公式如下:

式中:P代表準確率;TP代表模型將一個關系的正類預測為正類的數量,個;FP代表模型將一個關系的負類預測為正類的數量,個。
召回率(R)計算公式如下:

式中:R為召回率;TP代表模型將一個關系的正類預測為正類的數量,個;FN代表模型將一個關系的正類預測為負類的數量,個。
F1值是機器學習評價體系中的一個通用評價指標,其公式計算如下:

在以上各個評價指標中,準確率P、召回率R它們兩者之間有明顯的負相關關系,當實驗的結果準確率高時,其對應召回率普遍較低,反之同理。所以使用F1值作為來衡量分類器綜合性能的評價指標,防止上述問題的出現。
2 詞語Word2Vec模型增量訓練
增量訓練是指在對語料進行Word2Vec詞向量訓練時,對現有的訓練模型進行語料補充和修正的二次訓練。一般所用Word2Vec的訓練模型是基于通用語料訓練而來,對于垂直領域的詞匯用法和關聯程度有所不同,當用專業領域的語料經過增量訓練后,可以在垂直領域對現有模型進行專業化的補充。
食品安全領域相關語料具有一定的專業特殊性,尤其在專業的領域詞、檢測因子、專業語義上與公共領域的語料存在較大的差異,用現有詞向量訓練工具進行分詞、詞語向量化較難有很好的訓練效果,因此需要對Word2Vec模型進行增量訓練。
本文首先在一個公共開放的預訓練模型的基礎上進行語料擴充,加入實驗構建的食品安全領域語料庫以及領域詞匯百科、領域檢測因子等語料,進行詞向量模型的訓練。增量訓練模型參數見表2。

表2 食品安全領域詞語Embedding模型增量訓練參數Table 2 Incremental training parameters of embedding model in food safety field
隨著時間的推移,未來可能出現新的領域詞匯,而且業務情景可能發生變更。此后每隔一段時間,當積累了一定的核技術利用單位的檢察建議語料時,對詞向量模型再進行增量訓練。持續的增量訓練可以使得詞向量模型能學習到新詞匯的向量表示并適應最新語料的語義關系,更好地將文本向量化,以提升后續算法準確性。
3 食品安全領域實體關系抽取模型建立
3.1 BERT-BiLSTM雙維度模型描述
整個雙網絡模型結構見圖3。由圖3可知,右半部分的網絡結構圖展示了基于領域詞的位置感知注意力機制的雙向長短期記憶網絡模型(BiLSTM)提取出語料中的關系,左半部分的網絡結構圖展示了基于BERT網絡提取出語料中存在的實體對。
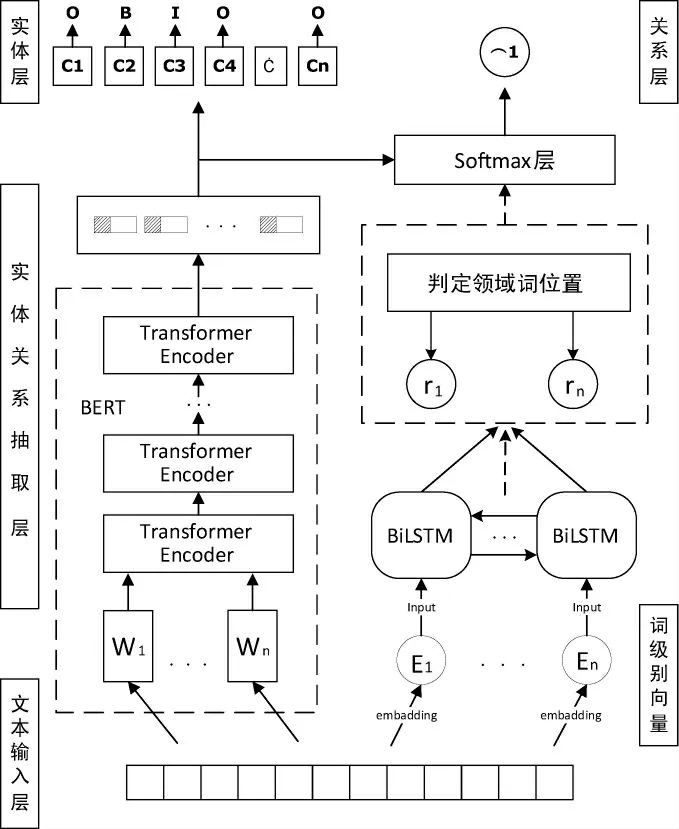
圖3 網絡模型結構圖Fig.3 Network model structure
在模型的右半部分,使用提前訓練好的詞嵌入模型將食品安全領域的語料進行文本向量化處理。之后將得出的詞級別向量作為BiLSTM網絡層的輸入,由BiLSTM生成隱層向量。首先,將提前構建好的領域詞詞庫與當前的每個詞語進行逐一匹配,引入基于領域詞的位置感知注意力機制,通過進行計算之后,則可計算出相應的影響向量,同時模型將影響向量與隱層向量進行結合,影響BiLSTM模型輸出結果;在模型的左半部分,將標注好的文本句子輸入BERT模型進行訓練,并將訓練所得字向量加入偏旁部首的修正向量,進一步修正訓練結果,最終提取出句子中包含的實體對并提取其隱層向量,最后模型將會在兩個網絡輸出向量的結合層累積影響向量,進一步得出實體及其關系抽取結果。
在實體關系抽取模型的輸出層中,利用SoftMax層,對每個輸出節點的輸出向量進行概率轉化,并找到概率最高的輸出節點所對應的詞作為該句子的關系詞。關系詞的概率轉化計算公式如下:

式中:P(q|S)為關系詞的概率值,%;S為輸入的句子;q為預測的關系詞;wν為權重;V為輸出向量;bν為偏置向量。
對于關系標注部分,輸入句子的每一個詞會被指派一個關系標簽,本文中采用0~1標簽為關系做標注,其中識別出的關系詞被標記為1,非關系詞標記為0。因此,關系標注問題可以轉變為:對于給定的長度為n的句子S=(s1,…st,…sn),假設標注輸出結果為Q=(q1,…qt,…qn),在已知序列S下,找出使得Q=(q1,…qt,…qn)的概率P=(q1,…qt,…qn)最大的序列(q1,…qt,…qn)。概率P計算公式如下:
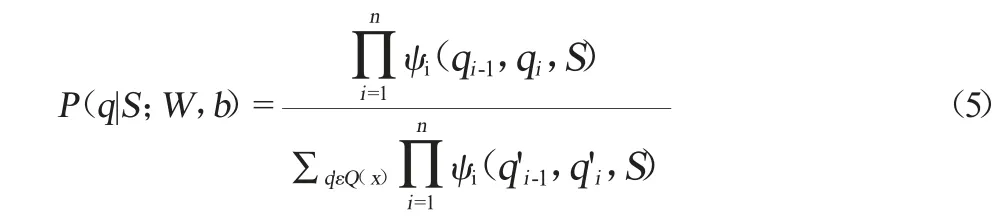
式中:P(q|S;W,b)表示輸出序列Q為最優序列的概率;W為權重;b為偏置向量;ψ(q',q,S)=exp(WTq',qz+b,q)是一個隱含函數(其中,WT表示權重向量的轉置,b表示偏置向量,z表示詞向量的權重向量)。
最后,使用維特比算法對式(5)所得P(q|S;W,b)進行有效的解碼運算,得到每個詞最終的標注向量。
3.2 基于領域詞的位置感知注意力機制
為了將食品安全領域的語言特點融入模型網絡中,使得實體關系抽取效果更加優異,在模型中引入了基于領域詞的位置感知注意力機制。
依據食品安全領域的專業詞匯,構建食品安全領域詞庫,依據詞語是否匹配到領域詞庫的原則,篩選詞語,確定領域詞匯。具體執行過程見圖4。
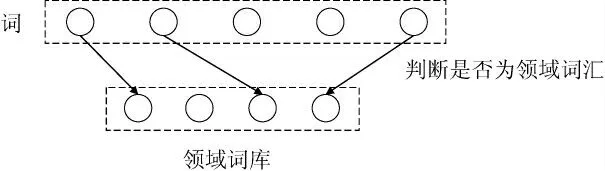
圖4 領域詞匯匹配示例Fig.4 Examples of domain vocabulary matching
本模型對輸入詞向量中的領域詞進行識別,經過基于領域詞的位置感知注意力機制的計算,將影響向量傳播到BiLSTM隱層向量中結合計算,從而影響BiLSTM的輸出結果。最后模型將會在兩個網絡輸出向量的結合層累積影響向量,進一步得出實體及其關系抽取結果。
注意力機制所生成的影響向量具體計算過程為:假設領域詞在隱層向量各維度上的影響是基于高斯分布的,同時設K為影響的基礎矩陣,則其影響的表達式如下:

式中:K(i,m)表示距離向量第i維度距離為m的領域詞對其產生的影響;N(Kernel(m),σ2)表示期望值為Kernel(m)、標準差為σ的正態分布。Kernel(m)表示高斯核函數,可以對位置感知的影響傳播進行模擬,其表達式如下:

式中:m表示領域詞到其影響維度的距離;σ表示高斯濾波器寬度。
根據領域詞的位置關系,可以計算每個領域詞的影響矩陣,通過計算的積累,最后獲得每個特定位置下領域詞的影響向量:

式中:cfj代表領域詞在位置j處的累計影響向量;Sj表示一個距離的計數向量,用來測量屬于領域詞的數量,K為設定的基礎影響矩陣。
4 結果與分析
4.1 實驗構建
本次實驗以Python3.7語言為依托,利用Tensorflow和Pytorch框架構建深度學習模型,同時選用MySQL數據庫進行數據的調用與存儲。實驗設備方面,工作站內存為16 GB,搭載Windows 10(X64)和Linux CentOS7操作系統,Intel酷睿i7 7700HQ處理器。
本次實驗數據集按4∶1的比例拆分,其中訓練集有效語句近6 000條,主要用作對BERT模型和雙向長短期記憶網絡(BiLSTM)模型進行訓練,并使各項參數達到最優值;測試集有效語句約為1 500條,用于對模型的實體關系抽取效果進行評估。
實驗參數的設置與選擇上,設置詞嵌入層使用100維的Glove詞向量,BiLSTM網絡輸出向量的維度是128維,注意力機制中設置μ為8。BERT模型的參數設置見表3。

表3 BERT模型參數設置Table 3 Parameters setting of BERT model
4.2 實驗結果對比與分析
為了展示雙網絡及其注意力模型的效果,利用傳統的神經網絡模型與本文模型針對同一數據集展開了一系列對比實驗。對比模型整體分為卷積神經網絡(convolutional neural network,CNN)模型、BiLSTM模型和BERT模型,并通過是否引用注意力機制來提升對比效果。具體的實驗結果見表4。
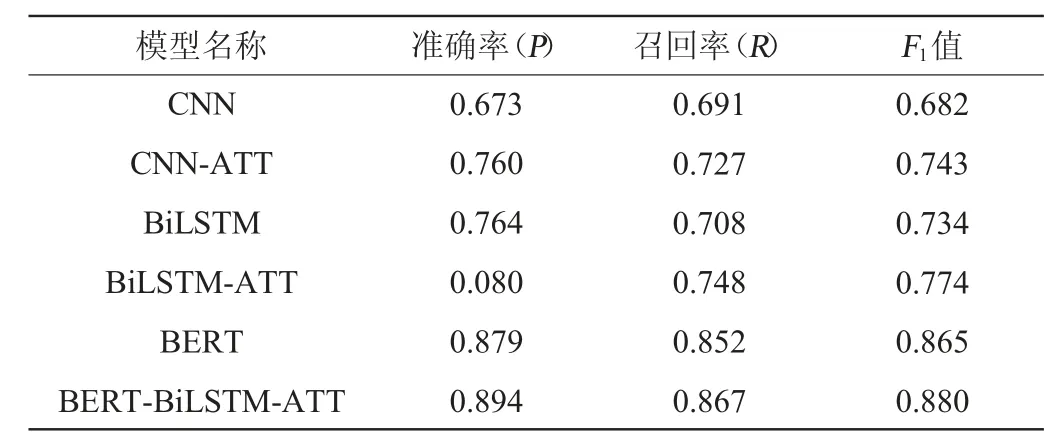
表4 不同模型在實驗數據集上的性能對比Table 4 Performance comparison of different models on experimental data set
由表4可知,BiLSTM-ATT模型在實驗數據集上準確率、召回率、F1值分別達到了0.801、0.748和0.774,整體上要比CNN及CNN-ATT模型具有更好的性能表現,但帶有注意力的CNN仍有著不俗的表現,F1值達到了0.743。而BERT模型憑借著自身強大的訓練機制,不出意外的將整體實體關系抽取效果提升了一個檔次,三項評價指標均達到了0.850以上,較傳統的深度學習模型有很大的提升。值得注意的是,本文提出的BERT-BiLSTM-Attention雙網絡模型在準確率和召回率層面上均體現出了更好的性能,分別達到了0.894和0.867,F1值高達0.880,較單網絡的BERT模型提高了1.5個百分點。在本文模型中,BERT模型自身就有著優秀的字向量訓練機制,并根據偏旁部首的加強訓練,結合BiLSTM在領域詞上的注意力機制,進一步優化了網絡整體的注意力權值計算。對于關系抽取而言,本文所使用的雙網絡模型針對句子結構上有著較好的反饋,同時又不拋棄垂直領域詞匯帶來的更多有用的信息。
5 結論
本研究完成的主要工作是基于BERT-BiLSTM-Attention構建了一個關系抽取模型,應用到食品安全領域的關系和實體識別中,進行關系抽取,通過BERT模型對語料中的關系進行提取,并將隱層向量與BiLSTM-Attention模型隱層向量相結合,更優的提取出食品安全語料中的對應實體,這兩個模型共同組合成食品安全事件實體關系抽取模型,其在測試集上取得了很好的實體關系抽取效果,準確率、召回率、F1值分別達到了0.894、0.867和0.880。
本文的研究為食品安全領域的文本抽取以及知識圖譜構建提供了新的方法及思路,為實現相關食品安全監管可視化平臺、智能問答等應用奠定了基礎。此外如何對抽取后出現的噪音數據進行識別、校正以及對食品領域詞、知識的補全將會是下一步工作的重點。未來可通過人工智能進一步打造食品安全監管智能化系統,實現資源共享,提高監管力度,為人民群眾提供更優質的服務。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
