深度學習在文本相似度中的應用
2021-08-06 08:27:04梅玉婷趙曙光
現代計算機 2021年18期
梅玉婷,趙曙光
(東華大學信息科學與技術學院,上海201620)
0 引言
隨著人們在智能領域的探索,人工智能被應用于多個方面,包括金融、醫療、圖像識別等領域。而自然語言是人工智能的一部分,其基于文本相似度計算的相關技術在人們的日常生活中大量應用,包括機器翻譯、信息檢索、文本分類、自動摘要、輿情分析、語義情感分析、對話系統[1]、論文查重等。鑒于其廣泛的應用領域,文本相似度分析吸引了很多學者去研究。要將自然語言與深度學習算法結合處理,通常需要首先將文本語言數學化,詞向量就是用來將語言中的詞進行數學化的一種方式。經過詞向量化的詞語將以向量形式表示。Word2Vec作為神經概率語言模型的輸入,是為了通過神經網絡學習某個語言模型而產生的中間結果(權重矩陣),其是基于局部語料庫訓練的,且特征提取是基于滑動窗口的。Word2Vec模型分為CBOW和Skip-gram。GloVe也是一種詞向量訓練模型,其本質上是對共現矩陣進行降維。GloVe的滑窗是為了構建共現矩陣,是基于全局語料的。可見GloVe需要事先統計共現概率。本文選擇Word2Vec進行預訓練。基于深度學習的文本相似度算法大多是基于RNN(Recurrent Neural Network),RNN是一類用于處理序列數據的神經網絡。其處理的序列數據有一個特點:后面的數據跟前面的數據有關系。為解決RNN在長序列中出現的梯度消失或爆炸問題[2],一般采用RNN的特例,如LSTM(Long Short-Term Memory)和GRU(Gat?ed Recurrent Unit),它們都使用神經門控制信息流來緩解梯度消失或爆炸的問題,其次RNN并不太適合并行化,其輸出狀態的計算需要等到計算完成后才能開始。這阻礙了獨立計算,并大大減慢了序列處理的速度。而SRU(Simple Recurrent Units)簡化了計算過程,新增加了兩個特征:首先,在循環層之間增加了high?way連接,此前的研究已經證明,如highway連接這樣的skip connections,在訓練深度網絡時非常有效;其次,在將RNN正則化時,他們在標準的dropout外,增加了變分dropout,變分dropout在時間步長t與dropout使用相同的mask[3]。而在文本相似度分析中,為能捕獲文本上下文相關信息與雙向的語義依賴,獲得更復雜的文本表達,提出了BiLSTM(Bi-directional Long Short-Term Memory)。本文對比BiLSTM與BiSRU算法。采用Siamese網絡模型,該模型是由2個權值共享的孿生網絡構成。Siamese網絡能從數據中學習一個相似性度量,用這個學習出來的度量去比較和匹配新的未知類別的樣本。
1 模型介紹
1.1 LSTM模型
LSTM(Long Short-Term Memory)通過門來避免長期依賴問題。其通過輸入門it、遺忘門ft和輸出門ot這三個門結構來實現信息的保護和控制。在運算過程中,對舊的狀態乘ft,用來忽略不需要的部分。輸出值的確定依賴于可過濾狀態。在sigmoid層來確定狀態的哪個部分將進行輸出。
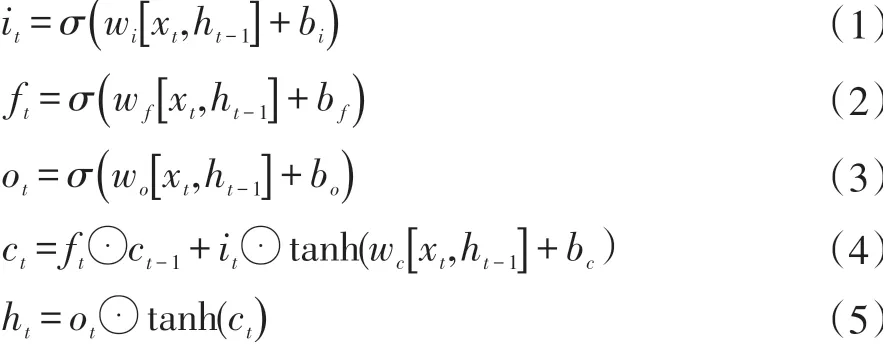
其中ht為t時刻的隱藏層的狀態,σ為激活函數sigmoid,xt為t時刻的輸入詞向量。w和b分別為權重矩陣和偏置。⊙為逐點乘積。
1.2 SRU模型
SRU網絡結構為能夠并行化處理,將大部分運算進行并行處理,將有具有小量運算的步驟進行串行處理。其在每一步獨立的進行操作,循環組合與輕量級的計算,提高了計算速度。SRU基礎結構包含了一個單一的遺忘門,假定輸入Xt和時間t,需要計算線性的轉換x?和遺忘門ft。整個SRU網絡結構的計算結構如下:
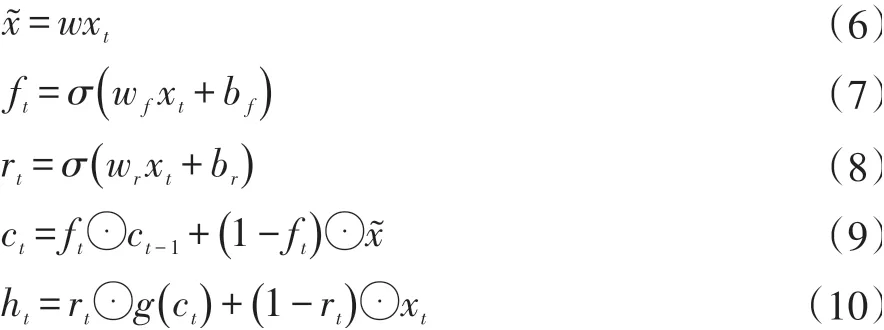
其中,f表示遺忘門,r表示重置門,h表示輸出狀態,c表示內部狀態,x表示輸入。
雙向BiLSTM[4]通過兩個LSTM來得到時序相反的隱藏層狀態并將其連接得到一個輸出,前向LSTM和后向LSTM可以分別獲取輸入序列的上文信息和下文信息,BiLSTM模型能夠有效地提高準確率。BiLSTM模型在t時刻的隱藏狀態包括前向htforward和后向htbackward。BiLSTM輸出Ht。Ht=[htforward,htbackward]。
1.3 注意力機制
通過對BiLSTM層的輸出進行計算,可以得到一個注意力的概率分布,進而由該概率分布可知每個時刻LSTM單元的輸出對句子語義的重要程度,將單詞級別的特征組合成句子級別的特征,更準確的表達句子的語義。其核心思想是在輸入序列上引入注意權重,以優先考慮存在相關信息的位置集,網絡結構中的注意力機制模塊負責自動學習權重[5],它可以自動捕獲編碼器的隱藏狀態和解碼器的隱藏狀態之間的相關性。
在輸出計算層中,計算2個向量的距離采用的是曼哈頓距離,計算的輸出是在(0,1]區間內的值。
1.4 模型結構
模型采用孿生長短期期記憶模型(Siamese LSTM)[6],其由兩個相同的網絡結構network1和network2組成,即network1和network2的權重相等。孿生神經網絡有兩個輸入,將兩個輸入值輸進神經網絡,這兩個神經網絡可分別將輸入映射到新的空間,在新的空間中形成新的輸入表示。在訓練階段使來自相同分類的一對訓練樣本的損失函數值最小,同時使來自不同分類的一對訓練樣本的損失函數值最大。通過Loss的計算,評價兩個輸入的相似度。傳統的Siamese network使用Contrastive Loss。本次的應用方向是自然語言方向,在計算向量距離方面,cosine更適用于詞匯級別的語義相似度度量,而exp function更適用于句子級別、段落級別的文本相似性度量。在本文中,選擇曼哈頓距離作為評價函數。其結構如圖1。
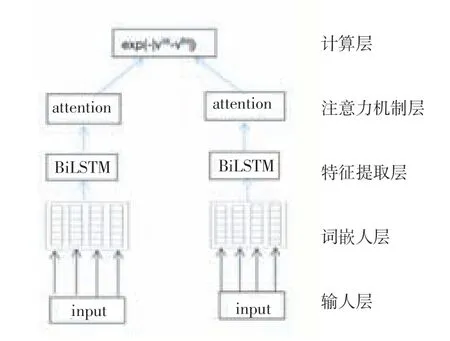
圖1 模型結構圖
2 實驗
2.1 實驗集及評價指標
數據來源于CCKS2018評測項目中的微眾銀行客戶問句匹配大賽數據集[7],總數據集大小為10萬條。數據集格式是問句匹配,1代表語義相似,0代表語義不同。實驗中選擇8萬條為測試集,2萬條為訓練集。本實驗首先選擇了BiLSTM和BiSRU模型進行對比,采用accuracy、recall、total進行模型效果衡量。在這基礎上,在對比Att-BiLSTM和Att-BiSRU的accuracy、recall、F-1值。

2.2 實驗參數
實驗之前首先對文本使用jieba分詞工具對句子進行分詞,采用Word2Vec進行預訓練。本文中的優化函數采用Adam優化器。學習率為1e-4,訓練采用dropout=0.5和L2約束防止過擬合。
2.3 實驗結果與分析

表1 不同模型實驗結果
根據對比BiLSTM和BiSRU,發現BiLSTM算法性能優于BiSRU,但在訓練速度上,BiSRU比BiLSTM快。

表2 不同模型實驗結果
根據對比Att-BiLSTM和BiLSTM,發現融入注意力機制后的算法性能會更好。
3 結語
本文在研究基于深度學習的文本相似度時,針對現有模型語義表達不準確及訓練速度慢的缺點,提出一種訓練速度更快的Att-BiSRU算法,為使句向量表達更加準確,將注意力機制融入其中,并采用孿生網絡模型進行文本相似度研究。同時,本文對比了BiLSTM、BiSRU、Att-BiLSTM、Att-BiSRU四種模型,發現雖然LSTM算法模型效果更加好,但在訓練速度方面沒有SRU模型快。本文采用Word2Vec進行預訓練,也對提升模型效果也有所幫助。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
