基于霧計算的路網- 野區路徑規劃研究
2021-08-06 06:24:44岳東峰劉嚴巖畢竹清
火力與指揮控制 2021年6期
王 礫,岳東峰,劉嚴巖,畢竹清
(北方信息控制研究院集團有限公司,南京 211153)
0 引言
隨著智能設備的普及、可穿戴計算設備的發展,網絡發展呈現出兩種明顯的趨勢:基于云計算的架構普及以及持續激增的移動智能設備。智能設備的小型化、輕量化與高性能之間存在一定的矛盾,為了解決這類矛盾,云計算框架的快速發展,已經成為現在互聯網的關鍵基礎設施之一。并且隨著智能手表、智能眼鏡的逐步普及,移動智能設備的需求會進一步激增,對云計算的負載能力、實時響應能力和安全保密能力提出了更高的要求[1-2]。為了應對該類挑戰,霧計算技術近些年發展較為迅猛,霧計算是分布式部署于網絡邊緣的小型云計算系統,能夠對邏輯上鄰近的移動設備提供有效的云服務,同時降低了大型云端的負載壓力,霧計算結合了移動互聯網與云計算技術,同時具有網絡拓撲的彈性縮放能力與云平臺的分布計算能力。能夠根據用戶需求的變化,實時調整網絡節點的接入策略,通過虛擬化技術,整合不同硬件平臺的計算、存儲等資源,合理分配網絡資源。
路徑規劃技術是目前日常生活中較為普及的技術之一,除了能夠提供快速、實時的路徑規劃功能以外,現有移動端應用程序已經能夠提供較為全面的地理信息服務,包括周圍商業設施的搜索、擁堵區域提示等信息。現有路徑規劃技術的核心分為兩部分:第1 部分是對地圖的處理,將矢量地圖進行預處理,形成可用于路徑規劃拓撲圖;第2 部分是路徑尋優算法,根據起始點、關鍵點、終止點的信息,規劃出合理的路線。根據獲取的地圖信息范圍,可以將路徑規劃方法分為:基于先驗全地圖信息的全局路徑規劃,以及基于實時地圖信息的局部路徑規劃。局部路徑規劃算法有人工勢場法、遺傳類算法等。全局路徑規劃常見的路徑尋優算法有:適用于柵格路徑尋優的Dijkstra 算法[3-4]、A*算法[5-6]與適用于可視圖的Voronoi 圖法[7]等。
本文提出了基于霧計算框架的野區路徑規劃服務設計方法。在霧計算平臺提供的計算、存儲等資源的基礎上,綜合考慮野區的地質信息、水域信息、建筑群信息、道路信息以及高程信息等,結合霧計算平臺收集的實時信息,包括橋梁被毀、道路堵塞等,并以柵格類算法中的A*算法作為野區環境下的路徑尋優方法,構建適用于野區的路徑規劃服務,提出實時的道路-野地無縫連接的路徑規劃方法。
1 云計算與霧計算介紹
1.1 云計算介紹
軍用增強現實電子沙盤以高精度三維地形數據為基礎。現在較為廣泛接受的云計算定義是美國國家標準與技術研究院(NIST)提出的,定位為:云計算是一種按使用量付費的模式,這種模式提供可用、便捷、按需的網絡訪問,提供可配置的計算資源共享池(資源包括網絡、服務器、存儲設備、應用軟件、服務等),這些資源能夠被快速提供、只需要很少的管理工作,或與服務供應商進行很少的交互[8]。
云計算的定義中,強調了云計算是根據用戶的需求提供計算服務,能夠聚合網絡帶寬、數據儲存、應用服務等資源,對外提供整合后的虛擬化資源池,并且該資源池能夠根據應用場景的需求進行配置,即提供資源的彈性擴展能力。同時采用統一的網絡訪問方式,提供標準的、與平臺無關的服務訪問接口,屏蔽了“云”內部結構的差異。
1.2 霧計算介紹
霧計算是云計算的延伸概念,能夠將云服務擴展至網絡邊緣。霧計算是地理上分布式計算架構,由大量泛在的、相互連接的、異構的設備共同組成資源池。霧計算與云計算可以相互協作,但不依賴云計算,為用戶群提供彈性的計算、存儲、通信與服務等資源[9-10]。
霧計算的特點[11]包括:1)霧計算與網絡邊緣的用戶組距離較近,從而在網絡邊緣提供對時延敏感的服務;2)霧計算提供區域感知能力,在地理上分布的各個霧節點(網絡邊緣的服務器)能夠推斷出自身的位置,并跟蹤用戶組的運動狀態,從而提供更加切合當前環境的計算服務;3)在大數據的時代,霧計算可以支持邊緣分析與流數據挖掘,在數據收集的早期階段對數據進行降維,從而降低數據延遲與節省帶寬消耗。
1.3 云計算與霧計算的關系
霧計算與云計算是相輔相成的關系,霧計算是云計算在網絡邊緣的延伸,更加貼近各類移動終端,霧計算與云計算的關系如圖1 所示。

圖1 霧計算與云計算的關系圖
通過云計算,聚合各類服務器群的計算能力、存儲能力以及相應的網絡資源,并將各類資源虛擬化后形成資源池,對各類服務的運行提供基礎支撐。霧計算通過整合不同霧節點的資源,形成局部的資源池,并對所屬的各類用戶群提供服務支撐。云計算可以為霧計算提供更多的計算能力、存儲能力以及更多的服務類型。對于用戶而言,無需知道服務所處的實際位置,只需要采用統一的訪問接口,即可向“霧”/“云”請求服務。
2 霧計算平臺上的野區路徑規劃應用場景分析
2.1 野區路徑規劃功能介紹
野區路徑服務能夠結合具體的道路信息、河流信息、湖泊信息、居民區信息等,自動識別出可通行的野地范圍,并在路徑規劃過程中,無縫銜接道路,在有道路的情況下,優先選擇道路,在道路繞遠或無道路情況下,生成合適的野地路徑規劃方案。
野區路徑規劃分為預處理模塊與路徑規劃模塊兩部分,預處理模塊是將矢量類型的地圖信息柵格化,提取每個柵格中的地理信息并保持至相應的矩陣中,并分析柵格本身的屬性,包括是否可通行、是否代表河流等信息以及柵格與柵格之間的關系,包括下一個柵格是否某障礙區域的邊界等。執行預處理模塊的耗時長、內存占用大、計算結果占用磁盤空間多。路徑規劃模塊是在預處理模塊的基礎上,根據預處理生成的結果,采用合適的尋路方法,如A*算法、蟻群算法等方式,選擇合適的路線。
2.2 野區路徑規劃應用場景分析
根據上節介紹的野區路徑規劃模塊描述,野區路徑規劃在“霧”計算平臺上的應用場景如圖2所示。
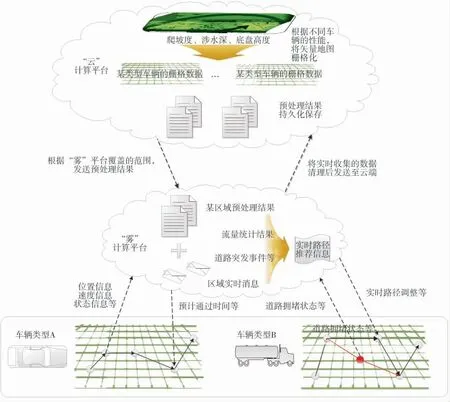
圖2 野區路徑規劃應用場景
根據云平臺提供的計算以及存儲能力,針對大范圍、多類型車輛進行預處理操作,提取出基礎的地理信息,包括道路、河流、湖泊、草地等信息,并根據不同型號車輛的通行能力,包括野地通行速度、涉水深等,結合矢量地圖與車輛通行參數,生成柵格數據,柵格數據中每個柵格點保存了該點及其周圍區域的地理信息,如該柵格區域內是否為道路、河流或者湖泊,以及該類型車輛是否可以通過該柵格等。將不同區域、不同車輛的柵格信息持久化保存在云端存儲器中,當某霧平臺需要對外提供野區路徑規劃能力時,從云端將指定區域的柵格數據信息下載到特定的霧平臺中,霧平臺采集各個車輛、平板電腦等設備的實時狀態信息,結合具體的用戶需求與“云”端預處理結果,進行實時的路徑推送功能。霧平臺可將搜集的地理變化信息,整理后反饋至“云端”,優化生成的柵格數據。
2.3 基于霧計算平臺的路徑規劃服務優點分析
基于霧計算平臺的路徑規劃服務能夠為用戶提供實時、準確的路徑建議,主要優點如下:
1)基于霧計算平臺的路徑規劃服務能夠根據當前道路與野區的狀況提供低時延的服務;
2)能夠提供靈敏的斷線重連服務,當車輛由于環境變化出現通信中斷并重新連接后,能夠繼續提供相關服務;
3)能夠有效降低終端的計算壓力,能夠提供多種類型的訪問方式,為異構的終端提供統一的路徑規劃服務;
4)能夠有效降低云計算平臺的訪問量,針對某特定位置,推送地區相關性服務,包括油料補給點、臨時休整區域等;
5)能夠搜集特定地區的天氣、水位等信息,實時修改路徑方案;
6)能夠將路徑規劃的衍生及相關的信息,如預計到達時間、前方雷雨等信息,實時推送至用戶;
7)能夠采集匯總路況、野地、水紋、居民區的變化信息,整理并融合后將變化內容上傳至云計算平臺,優化地形預處理結果。
3 野區路徑規劃算法
3.1 單類型車輛野區路徑規劃介紹
利用“云”環境下的計算能力,針對不同類型的車輛,分別對需要進行路徑規劃的區域進行地圖預處理操作。
單類型車輛路網-野區路徑規劃問題主要包括兩個部分:1)地圖預處理;2)針對單一車輛類型的路徑尋優。本文假設已獲取初始地理環境信息,包括道路橋梁信息、建筑群信息、水域信息、高程信息等。對于突發的地圖信息,包括橋梁斷裂、新建臨時橋梁等,在霧計算平臺上采用動態地圖調整的方式進行路徑調整。
3.2 地圖預處理
通過預先獲取的地理信息,對指定地域的地圖進行柵格化。單個柵格中包含的信息為:道路信息與可通行/不可通行信息,道路信息的優先級最高,當該柵格同時有道路和不可通行區域,如代表橋梁穿過湖泊的柵格,認為該柵格代表道路。不可通行信息包括建筑物或建筑物群信息、湖泊信息、河流信息、高程障礙信息等,同一標示為不可通行區域。地圖預處理流程,如圖3 所示。
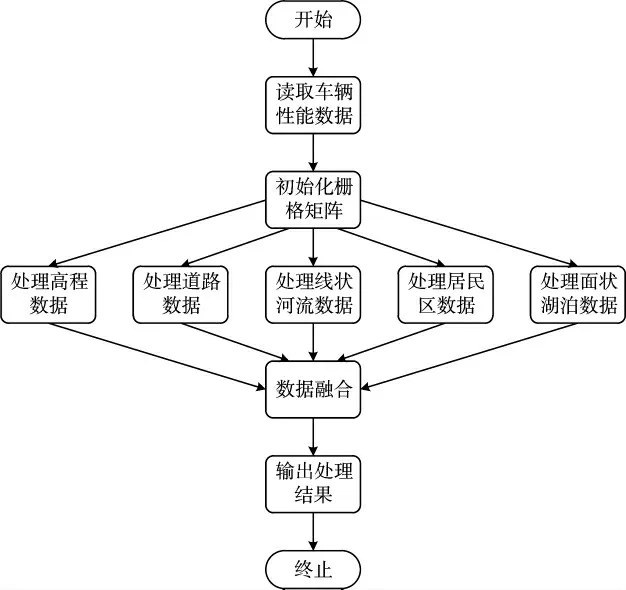
圖3 地圖預處理流程圖
3.3 地圖動態調整
隨著道路與野區的環境發生變化,初始化的柵格信息無法滿足后續路徑尋優的需求,此時需要設立動態地圖調整圖層,根據該圖層中的信息進行柵格矩陣的二次調整。動態地圖調整圖層中包括:1)臨時可通行區域;2)動態障礙區域。
臨時可通行區域:當開拓出新路、新建臨時橋梁等情況下,在動態圖層中設置臨時可通行圖元,將對應區域的柵格設置為可通行區域。臨時可通行區域信息優先級高于湖泊、河流等初始障礙信息。
動態障礙區域:臨時設置禁入區域、道路堵塞等情況下,在動態圖層中設置動態障礙區域,將對應區域的柵格設置為障礙區域,動態障礙區域的優先級高于原始道路信息。
3.4 野區路網路徑尋優
將地圖映射為柵格矩陣的基礎上,采用A*算法作路徑尋優方法。A*算法是一種啟發式路徑搜索算法,具有較高的搜索效率。A*算法的核心為啟發函數,如式(1)所示。
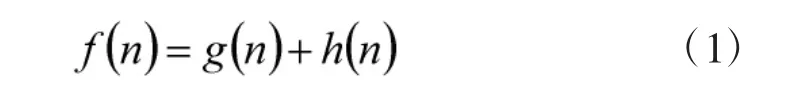
其中,f(n)為第n 個柵格點的啟發函數值,g(n)為從起始柵格點到當前柵格點的累計消耗,h(n)為從當前柵格點到終止柵格點的預計消耗。
野區路網環境下需要提供不同的規劃模式,包括:1)路徑最短模式;2)道路優先。路徑最短模式情況下,采用傳統的A*算法的啟發函數;時間最短模式下,采用優先道路的原則。本節在結合地圖預處理的基礎上,根據柵格中保存的道路相關屬性,創新性地提出含有道路損耗的啟發函數,在靠近道路的情況下,優先使用道路機動,當道路繞遠時,采取抄近路的方式,進入野地機動,野區路網的啟發函數如式(2)所示。

其中,gi,j為從起始柵格到第i 行、第j 列柵格的累計損耗,hi,j為從第i 行、第j 列柵格到終點柵格的預計損耗,μLast表示上一柵格點至該柵格點的道路損耗,計算公式如式(3)所示。
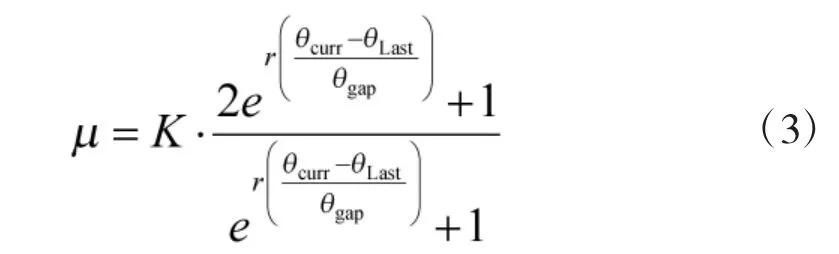
其中,r 為接近道路率,r 越大,道路損耗的變化率越快,K 為道路因子的上限值,K 越大遠離道路的消耗越高。θcurr為當前柵格點的道路距離,θLast為上一柵格點的道路距離,θgap為相鄰兩個柵格間最大的道路距離差,在初始化矩陣的過程中,通過式(4)計算得到。
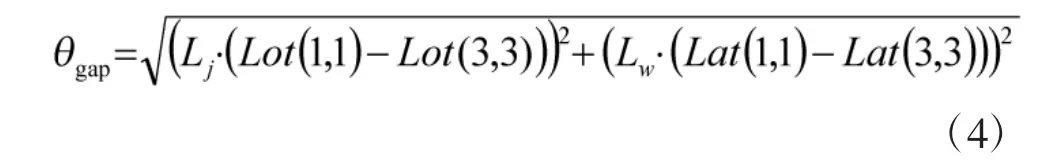
其中,Lot(1,1)表示第1 行、第1 列的經度值,Lot(3,3)為第3 行、第3 列的經度值,Lat(1,1)表示第1 行、第1 列的緯度值,Lat(3,3)表示第3 行、第3列的緯度值,Lj表示該地區單位經度的實際距離(m),Lw表示該地區單位緯度的實際距離(m)。
A*算法收斂的充要條件是:對于任意節點n,都有h(n)≤h'(n),h'(n)是n 到目標的實際最短距離。此時也稱h(n)是可采納的。本文中采用Moore型柵格,路徑尋優時,只能向上、下、左、右、左斜上、左斜下、右斜上、右斜下這8 個方向移動,所以,第i行、第j 列的預計消耗函數h(i,j)如式(5)所示。
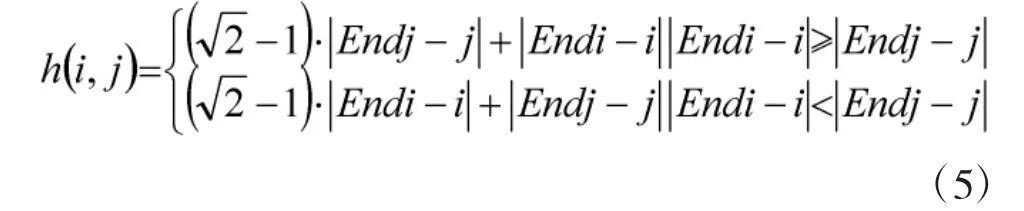
其中,Endi、Endj 是終點的柵格坐標信息,i,j 是當前路徑點的柵格坐標。根據野區路網啟發函數,結合A*算法的常見步驟,實現野區路網的路徑規劃功能。
4 基于霧計算平臺的路徑規劃結果
本次仿真中,首先試驗了路網-野區的路徑規劃結果,預處理區域分別涵蓋了居民區、河流、道路、橋梁、溝渠等常見矢量地理信息,預處理結果如圖4 所示。
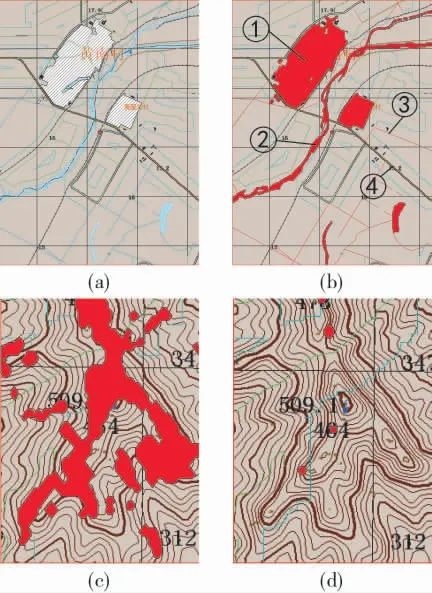
圖4 路網-野區預處理結果
其中,圖4(a)表示原始地圖情況,圖4(b)表示預處理后的結果,其中標號①標簽表示識別該區域為居民區障礙;②號標簽表示識別該區域為面狀湖泊障礙;③號標簽表示識別出河流障礙;④號標簽表示識別該區域為道路。其余未標示為可通行野地區域。
圖4(c)與(d)分別表示當預處理的車輛爬坡度為30°與45°時,識別出該區域的坡度障礙,紅色區域表示高程障礙區域。爬坡度為45°相比于車輛爬坡度為30°的情況,高程障礙明顯減少,只有零星區域為高程障礙。
在完成地圖柵格化的基礎上,考慮了時間最短模式與路徑最短模式,在時間最短模式中,設置優先接近道路,假設車輛在道路上的行駛速度是野地上行駛速度的一倍,兩種路徑尋優結果如圖5所示。
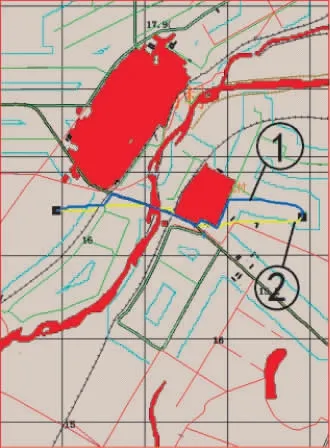
圖5 靜態雙模式路徑尋優結果
圖5 中,標號①表示時間最短模式,標號②表示路徑最短模式,在時間最短模式中,從起始點出發后,優先考慮在道路上行駛,當靠近終點時,脫離道路進入野地行駛,在路徑最短模式中,以快速接近終點為最優目標,在靠近重點的過程中,通過道路跨越水系障礙物。
通過模擬器向霧計算平臺發送橋梁被毀以及新建臨時橋梁的模擬數據,并執行動態路徑調整功能,仿真結果如圖6 所示。
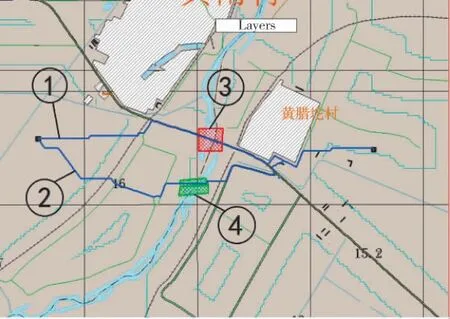
圖6 地圖動態調整路徑規劃仿真
圖6 中①號標簽指向地圖為動態調整之前規劃的路徑;②號標簽指向地圖動態調整之后規劃的路徑;③號標簽指向障礙信息,該障礙區域覆蓋在原圖層中跨越河流的橋梁上;④號標簽指向臨時可通行區域,表示在該區域建立一座新的橋梁,提供跨越水系的通行能力。仿真的順序為:1)先設定起始點與終止點并進行路徑規劃,生成①號標簽指向的路徑;2)模擬器向霧計算平臺發送橋梁被毀信息,如③號標簽所示,此時進行路徑規劃,顯示為“未找到合適路徑”;3)模擬器向霧計算平臺發送新建橋梁信息,如④號標簽所示;4)重新進行路徑規劃,生成動態調整后的路徑,如②號標簽所示。
選取高層區域,設定車輛的爬坡度為30°,并進行預處理,通過模擬器向霧計算平臺發送高程變化數據,并執行動態路徑調整功能,仿真結果如圖7所示。
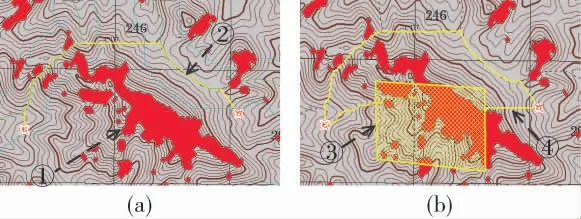
圖7 高程變化動態仿真
圖7 中,(a)圖表示針對爬坡度為30°的車輛,進行預處理后,霧計算平臺的路徑規劃服務識別出的不可通信區域,如①號標簽指向的紅色區域;(b)圖表示高程變化后的動態路徑規劃效果,③號標簽指向高程平滑區域,如通過炸裂山體等方式將坡度過高的地方移除后,重新進行路徑規劃,規劃結果如④號標簽所示,霧計算平臺的路徑規劃服務識別出新的可通信區域,并采用新開辟出的通路作為規劃結果。
5 結論
本文提出了基于霧計算環境下的道路- 野區路網的路徑規劃的方法,分別闡述了路徑規劃服務在霧計算平臺下的應用模式。并從地圖預處理、地圖動態調整、路徑尋優這3 個方面,闡述了單類型車輛的路徑規劃方法。今后的研究過程中,在路徑規劃時要考慮更多的約束信息,如某通道的流量約束,并將單類型車輛的路徑規劃擴展至包含不同類型車輛隊伍的聯合路徑規劃。
猜你喜歡
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中華手工(2017年2期)2017-06-06 23:00:31
中國衛生(2016年2期)2016-11-12 13:22:16
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
中國工程咨詢(2016年4期)2016-02-14 07:28:28
電測與儀表(2015年5期)2015-04-09 11:30:52
中外會展(2014年4期)2014-11-27 07:46:46
民生周刊(2012年10期)2012-10-14 09:06:46
