改進(jìn)樣本加權(quán)K近鄰分類器用于垃圾網(wǎng)頁檢測
2021-08-06 06:27:44吳俊華譚博覺陳木生
吳俊華,譚博覺,高 切,陳木生
(江西理工大學(xué) 軟件工程學(xué)院,南昌 330013)
搜索引擎已成為人們上網(wǎng)查找資料最常用的工具。CNNIC2019年3月發(fā)布的報(bào)告稱[1]:截止2018年底,中國網(wǎng)民中使用搜索引擎的用戶規(guī)模達(dá)6.81億,占全體網(wǎng)民的82.2%,年增長率6.5%。研究表明:85%的搜索引擎用戶只查看返回搜索結(jié)果中第1頁的內(nèi)容[2-3]。這就意味著檢索結(jié)果靠前的網(wǎng)站會(huì)有更高的關(guān)注度、點(diǎn)擊率、訪問量以及由此帶來的更好的廣告收入。于是,各個(gè)網(wǎng)站使用搜索引擎優(yōu)化方法(search engine optimization,SEO)提高自身的排名。然而,通過提升自身價(jià)值的方式提高排名非常困難,于是有些網(wǎng)站通過欺騙搜索引擎的不正當(dāng)手段獲得較高的排名[4]。這種行為稱為網(wǎng)頁作弊(web spamming),這些網(wǎng)頁就是作弊網(wǎng)頁,也稱為垃圾網(wǎng)頁(web spam)。垃圾網(wǎng)頁不僅降低了搜索質(zhì)量和用戶的信任度,讓用戶轉(zhuǎn)向其他搜索引擎,而且浪費(fèi)了大量的計(jì)算和存儲(chǔ)資源,侵占了搜索引擎公司及其他內(nèi)容網(wǎng)站的合法利益[5]。
垃圾網(wǎng)頁檢測至今依然是對抗信息檢索領(lǐng)域的一項(xiàng)極具挑戰(zhàn)性的重要工作。常見的做法是將其視為一個(gè)二分類問題,提出各種有效的分類算法用于垃圾網(wǎng)頁檢測。文獻(xiàn)[6]采用支持向量機(jī)(support vector machine,SVM)、多層感知器(mulitple level perception,MLP)、貝葉斯網(wǎng)絡(luò)(bayesian network,BN)、C4.5決策樹(C4.5 decision tree,DT)、隨機(jī)森林(random forest,RF)、樸素貝葉斯(na?ve bayes,NB)、K最近鄰(K-nearest neighbour,KNN)以 及AdaBoost、LogitBoost、Real AdaBoost、Bagging、Dagging和Rotation Forest等分類算法分別基于內(nèi)容特征、鏈接特征和綜合特征進(jìn)行垃圾網(wǎng)頁檢測,但其分類結(jié)果與其他研究結(jié)果相比并非更優(yōu)。文獻(xiàn)[7]提出一種包含概率映射圖自組織映射(probabilistic mapping graph self-organizing map,PM-G)和圖神經(jīng)網(wǎng)絡(luò)(graph neural network,GNN)的圖層疊架構(gòu)用于垃圾網(wǎng)頁檢測,其中的FNN(feedforward neural network)、PM-G+GNN(3)+GNN(1)算法表現(xiàn)出較好的檢測效果,準(zhǔn)確率和AUC等指標(biāo)都達(dá)到當(dāng)時(shí)的最優(yōu)水平,但其F1-測度指標(biāo)卻偏低。文獻(xiàn)[8-9]提出一種垃圾網(wǎng)頁檢測框架WSF2,該框架集成了多種分類器,與C5.0、REGEX、SVM、Bayes等方法相比,其AUC指標(biāo)更優(yōu)。支持向量機(jī)在垃圾網(wǎng)頁檢測的研究也多有出現(xiàn),一般都采用改進(jìn)支持向量機(jī)[10]、加入新的特征[11]和組合其他智能優(yōu)化算法[12]等。這些方法雖然改善了支持向量機(jī)的分類性能,但與其他最優(yōu)結(jié)果相比,在垃圾網(wǎng)頁檢測領(lǐng)域沒有明顯優(yōu)勢。由此可見,僅對傳統(tǒng)分類算法加以改進(jìn)用于垃圾網(wǎng)頁檢測,效果提升并不明顯。這主要是由于垃圾網(wǎng)頁檢測存在兩大難題。首先,垃圾網(wǎng)頁檢測是一個(gè)不平衡數(shù)據(jù)分類問題,因?yàn)榛ヂ?lián)網(wǎng)中正常網(wǎng)頁與垃圾網(wǎng)頁相比是不平衡的,垃圾網(wǎng)頁僅占10%~15%[4]。其次,用于垃圾網(wǎng)頁檢測的數(shù)據(jù)集可以從網(wǎng)頁的內(nèi)容(content)、超級鏈接(hyperlink)和搜索引擎用戶使用信息(usage log)等3個(gè)方面提取大量特征,將這眾多的特征同時(shí)用于訓(xùn)練機(jī)器學(xué)習(xí)模型可能陷入“維數(shù)災(zāi)難”問題。為解決垃圾網(wǎng)頁檢測中的不平衡數(shù)據(jù)分類和可能存在的“維數(shù)災(zāi)難”問題。文獻(xiàn)[13]最早將集成學(xué)習(xí)算法用于解決垃圾網(wǎng)頁檢測的不平衡分類問題,其提出的基于欠采樣的C4.5集成決策樹分類器的分類性能獲得當(dāng)年垃圾網(wǎng)頁挑戰(zhàn)競賽的冠軍。文獻(xiàn)[14]則采用過采樣和隨機(jī)森林相結(jié)合的技術(shù)進(jìn)行垃圾網(wǎng)頁檢測,同樣獲得較好的分類性能。文獻(xiàn)[15]提出一種傳感-感應(yīng)圖神經(jīng)網(wǎng)絡(luò)(transductive-inductive graph neural networks,TIGNN)方法。文獻(xiàn)[16]提出一種融合人工免疫克隆選擇、欠采樣集成和C4.5決策樹的分類方法,用于垃圾網(wǎng)頁檢測,較好地解決了上述問題。但這些方法需要花費(fèi)大量時(shí)間訓(xùn)練出模型參數(shù),才能得到較滿意的結(jié)果。
本文中提出一種融合Fisher特征選擇和實(shí)例加權(quán)的K近鄰(K nearest neighbor with instance weighting,KNN-IW)分類方法用于垃圾網(wǎng)頁檢測,不需要花費(fèi)太多時(shí)間訓(xùn)練模型參數(shù),同樣可以取得理想的效果。
1 理論基礎(chǔ)
1.1 Fisher特征選擇
特征選擇是從一組特征中挑選出一些最有效的特征以降低特征空間維數(shù)的過程,是避免“維數(shù)災(zāi)難”的常用方法。依據(jù)是否獨(dú)立于后續(xù)的學(xué)習(xí)算法分,特征選擇方法可分為過濾式(filter)方法和封裝式(wrapper)方法2種[17]。Fisher準(zhǔn)則是一種常見且有效的過濾式特征選擇方法,其主要思想是:若一個(gè)特征具有鑒別能力,則該特征表現(xiàn)為類內(nèi)距離盡可能小,類間距離盡可能大。在歐氏空間中,可以用方差表達(dá)樣本之間的距離。方差越大,樣本之間的距離越大;方差越小,樣本之間的距離越小[18]。
假設(shè)數(shù)據(jù)集中共有d種特征n個(gè)樣本屬于c個(gè)類w1,w2,…,wc,每一類分別包含nk個(gè)樣本,fj表示第j個(gè)特征,xi(fj)表示第i個(gè)樣本x在第j個(gè)特征上的取值,則Δb(fj)、Δw(fj)分別表示第j個(gè)特征的類間方差、類內(nèi)方差,其計(jì)算分別見式(1)(2)。

其中:μ(fj)表示所有樣本在第j個(gè)特征上的期望值;μk(fj)表示第k類樣本在第j個(gè)特征上的期望值。
將Fisher Score定義為某一特征的類間方差與類內(nèi)方差的比值,如式(3)所示。
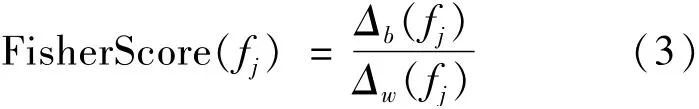
將式(1)(2)代入式(3)并化簡得到Fisher Score的計(jì)算公式如式(4)所示。
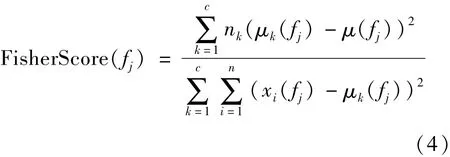
某個(gè)特征在訓(xùn)練樣本集上的Fisher Score越大說明該特征的類別區(qū)分度越好,即包含更多的鑒別信息,而噪聲特征的Fisher Score趨近于0。對每一個(gè)特征的Fisher Score進(jìn)行排序,即可選出那些鑒別能力較強(qiáng)的特征,從而達(dá)到降維的目的,且具有較優(yōu)的識別性能。利用Fisher Score進(jìn)行特征選擇的通常做法是:先求出每個(gè)特征的Fisher Score,然后設(shè)定一個(gè)閾值θ,如果某特征的Fisher Score大于θ則保留,否則放棄。
1.2 樣本加權(quán)的K近鄰分類
K近鄰(K nearest neighbor,KNN)法最早由Cover和Hart于1968年提出[19]。K近鄰分類對于訓(xùn)練數(shù)據(jù)集的平衡性較敏感,即對不平衡數(shù)據(jù)分類性能較差。解決不平衡數(shù)據(jù)分類問題的常用方法有重采樣[20](包括欠采樣和過采樣)、代價(jià)敏感分析[21]和核分類器[22]等。欠采樣方法會(huì)浪費(fèi)大量多數(shù)類樣本,過采樣方法則會(huì)使樣本數(shù)增加。隨著樣本數(shù)的增加,K近鄰分類器的比較計(jì)算量也會(huì)急劇增加,導(dǎo)致運(yùn)行性能下降。K近鄰法一般不會(huì)結(jié)合核函數(shù)一起使用。因此,結(jié)合代價(jià)敏感分析的K近鄰分類器較為常見。
劉胥影等[23]提出一種代價(jià)敏感的K近鄰分類器,命名為樣本加權(quán)的K近鄰方法(K nearest neighbor with instance weighting,KNN-IW),在多種數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果顯示:與K近鄰方法相比,其分類性能提升顯著。假設(shè)數(shù)據(jù)集中有C類樣本,Costc×c是代價(jià)矩陣,其中,Cost[i,j](i,j∈{1,…,C})表示將j類的樣本錯(cuò)分到i類的代價(jià),并且Cost[i,i]=0(i∈{1,…,C}),即正確分類的代價(jià)為0。第i類中有N[i]個(gè)樣本,樣本總數(shù)為N。設(shè)W為權(quán)值向量,其中W[i]表示第i類樣本的權(quán)值,如式(5)所示。

其中:Cost[i]是第i類樣本被錯(cuò)分的期望損失。權(quán)值反映了代價(jià)信息,錯(cuò)誤分類代價(jià)越高,權(quán)值越大。
KNN-IW分類時(shí)首先計(jì)算測試樣本和訓(xùn)練樣本之間的距離,選擇距離最小的K個(gè)近鄰訓(xùn)練樣本進(jìn)行加權(quán)投票。每個(gè)類別標(biāo)簽得到的票數(shù)用式(6)計(jì)算得到。
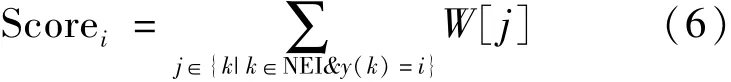
其中:NEI是近鄰樣本的索引組成的集合;y(·)表示樣本所在的類別;W則通過式(5)計(jì)算得到。
測試樣本所屬的類別即為Score值最大的那個(gè)類別,當(dāng)不止一個(gè)類別的Score值最大時(shí),選取其中Cost[i]最小的類。當(dāng)所有樣本的權(quán)值相同時(shí),樣本加權(quán)后的Score值與K近鄰分類算法的投票結(jié)果是一致的。
2 方法
將Fisher特征選擇和KNN-IW的分類方法融合一起進(jìn)行垃圾網(wǎng)頁檢測。首先,使用Fisher特征選擇方法針對訓(xùn)練數(shù)據(jù)集進(jìn)行特征選擇,按Fisher Score從大到小排序;然后,按照Fisher Score從大到小的順序依次選擇特征,對訓(xùn)練數(shù)據(jù)集本身使用KNN-IW方法進(jìn)行分類,以整個(gè)訓(xùn)練數(shù)據(jù)集分類結(jié)果的AUC值作為選擇標(biāo)準(zhǔn),采用貪婪算法,選擇那些會(huì)使AUC值提升的特征;最后,將選擇得到的特征訓(xùn)練K近鄰分類模型,用此模型對測試數(shù)據(jù)集進(jìn)行分類。將此方法命名為基于Fisher最優(yōu)特征選擇和KNN-IW的分類器(K nearest neighbor classifier with instance weighting based on optimal fisher feature selection,KNN-IW-OFisher),其主要流程如圖1所示。
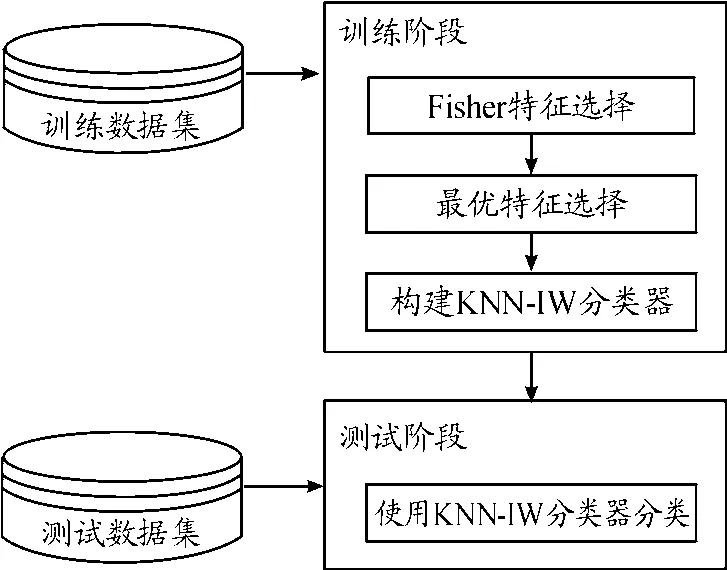
圖1 方法主要流程框圖
本文方法除了融合Fisher特征選擇和KNNIW兩種方法外,還在以下幾個(gè)方面做出了改進(jìn)。
首先針對訓(xùn)練數(shù)據(jù)集在計(jì)算出每一個(gè)特征的Fisher Score之后,并不是直接設(shè)定一個(gè)閾值θ,根據(jù)特征是否大于θ值來確定其去留,而是采用一種貪婪算法選擇最優(yōu)特征。該算法稱為最優(yōu)特征選擇算法,其偽代碼如算法1所示。
算法1最優(yōu)特征選擇算法
輸入數(shù)據(jù)集X,數(shù)據(jù)集標(biāo)記Y,特征排序向量Features,分類算法Classifier
輸出被選中特征的排序向量SelectedFeatures
步驟
1)MaxAUC=0
2)SelectedX=[]
3)SelectedFeatures=[]
4)for i=1 to m //其中m為特征總個(gè)數(shù)
5)Temp X=[Selected X X[Features[i]]]//其中Features[i]為排在第i個(gè)位置的特征下標(biāo),X[Features[i]]為數(shù)據(jù)集針對第Features[i]個(gè)特征進(jìn)行劃分得到的子數(shù)據(jù)集
6)AUC=Classifier(Temp X,Y) //使用分類器對子數(shù)據(jù)集Temp X、Y進(jìn)行分類,采用n-折交叉驗(yàn)證,根據(jù)分類結(jié)果計(jì)算AUC值
7)if AUC>MaxAUC then
8)Seletec X=Temp X
9)SelectedFeatures=SelectedFeatures Features[i]]
10)MaxAUC=AUC
11)End if
12)End for
該算法輸入?yún)?shù)中的數(shù)據(jù)集X及其標(biāo)記Y僅為訓(xùn)練數(shù)據(jù)集,在算法內(nèi)部通過n-折交叉驗(yàn)證的辦法驗(yàn)證特征的有效性。輸入?yún)?shù)中的特征排序向量是指根據(jù)Fisher Score從大到小排序后所對應(yīng)特征的下標(biāo)向量。例如,設(shè)有5個(gè)特征的Fisher Score分別為[3 5 1 6 2],則其特征排序向量為[4 2 1 5 3]。這里的分類算法是指KNN-IW分類器,將其作為輸入?yún)?shù)傳遞使得算法更具通用性,可適用于其他分類器。Fisher特征選擇的計(jì)算Fisher Score并排序的過程未包含在算法內(nèi),而只根據(jù)Fisher Score計(jì)算出特征排序向量作為參數(shù)傳入,也是為了保持算法的通用性和模塊化。
其次,在使用KNN-IW分類時(shí),對于測試樣本和訓(xùn)練樣本之間的距離度量,針對連續(xù)特征、離散特征和缺失特征值時(shí)3種情況,文獻(xiàn)[23]分別給出了不同的距離計(jì)算方式。而在本文的垃圾網(wǎng)頁檢測實(shí)驗(yàn)中所用到的數(shù)據(jù)集無缺失值特征,所以未考慮該情況。對于連續(xù)特征值,本文與文獻(xiàn)[23]一樣采用歐氏距離度量。對于離散特征,本文與文獻(xiàn)[23]不同的是將離散特征數(shù)量化后依然采用歐氏距離度量。
最后是在進(jìn)行KNN-IW分類時(shí)樣本權(quán)值即代價(jià)矩陣的確定。樣本加權(quán)是一種基于代價(jià)敏感的方法,即認(rèn)為不同類別的樣本被錯(cuò)誤分類后的代價(jià)是不同的。代價(jià)矩陣一旦確定,則樣本權(quán)值也隨之確定。在垃圾網(wǎng)頁檢測問題中,垃圾網(wǎng)頁與正常網(wǎng)頁被錯(cuò)誤分類的代價(jià)是不一樣的。但問題是,代價(jià)矩陣如何確定?在一般的代價(jià)敏感分析方法中,常根據(jù)用戶經(jīng)驗(yàn)確定代價(jià)敏感矩陣,但垃圾網(wǎng)頁與正常網(wǎng)頁被錯(cuò)誤分類的代價(jià)難以憑經(jīng)驗(yàn)確定。本文在確定代價(jià)矩陣時(shí)不從錯(cuò)誤分類的代價(jià)入手,而從網(wǎng)頁分布的不平衡性入手。KNN算法針對不平衡數(shù)據(jù)集進(jìn)行分類容易偏向大類,使用過采樣方法使得數(shù)據(jù)集更為平衡后再進(jìn)行KNN分類,分類性能會(huì)顯著提高。假設(shè)使用KNN-IW算法進(jìn)行不平衡數(shù)據(jù)的二元分類,其代價(jià)矩陣為,表示將大類樣本錯(cuò)分為小類的代價(jià)為1,而將小類樣本錯(cuò)分為大類的代價(jià)為7。這樣大類樣本的樣本權(quán)值為1,而小類樣本的樣本權(quán)值為7。該分類方法的最終效果與使用KNN算法進(jìn)行分類時(shí)將小類樣本重復(fù)7次即進(jìn)行7次過采樣的思路是一致的。本文假設(shè)在對垃圾網(wǎng)頁檢測問題采用KNN進(jìn)行分類時(shí),正負(fù)樣本數(shù)完全相等時(shí)分類效果最好。為此,如果采用過采樣方法,則對小類樣本的采樣比率是大類樣本數(shù)對小類樣本數(shù)的倍數(shù)。同理,如果采用代價(jià)敏感方法KNN-IW,則小類樣本的錯(cuò)分代價(jià)與大類樣本的錯(cuò)分代價(jià)的比值應(yīng)等于訓(xùn)練集中大類樣本個(gè)數(shù)對小類樣本個(gè)數(shù)的倍數(shù)。因此,在垃圾網(wǎng)頁檢測問題中,只需將大類樣本的權(quán)值設(shè)為1,將小類樣本的權(quán)值設(shè)為訓(xùn)練集中大類樣本個(gè)數(shù)與小類樣本個(gè)數(shù)的比值即可。
3 實(shí)驗(yàn)與討論
3.1 數(shù)據(jù)集及評價(jià)指標(biāo)
實(shí)驗(yàn)所用數(shù)據(jù)集為用于垃圾網(wǎng)頁檢測研究的公 開 數(shù) 據(jù) 集WEBSPAM-UK2006[24],最 初 用 于2007年網(wǎng)絡(luò)對抗信息檢索研討會(huì)進(jìn)行垃圾網(wǎng)頁檢測競賽。WEBSPAM-UK2006數(shù)據(jù)集本身已按保持法(Hold-out)的要求,分為訓(xùn)練集和測試集2個(gè)部分,擁有多種不同的特征。本文實(shí)驗(yàn)采納了其中4種共274個(gè)特征,分別是基于內(nèi)容的特征96個(gè),基于鏈接的特征41個(gè),基于鏈接轉(zhuǎn)換的特征135個(gè),基于鄰接圖的特征2個(gè)。訓(xùn)練集和測試集的樣本數(shù)情況如表1所示。由表1可知:訓(xùn)練集中正常網(wǎng)站與垃圾網(wǎng)站的比例約為7∶1,這表明訓(xùn)練集是不平衡的,與真實(shí)情況較為一致。
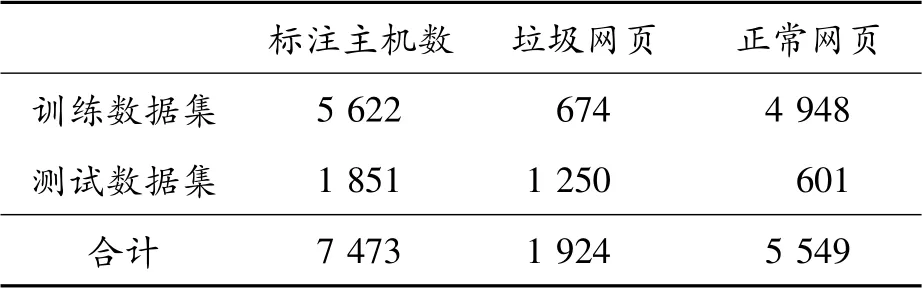
表1 WEBSPAM-UK2006數(shù)據(jù)集的樣本數(shù)
使用3種指標(biāo)評估分類模型,分別是準(zhǔn)確率(Accuracy),F(xiàn)1-測度(F1-Measure)和AUC值。垃圾網(wǎng)頁檢測是一個(gè)二元分類問題。對于二元分類問題,表達(dá)測試樣本集分類結(jié)果的混淆矩陣由TP、TN、FP和F 4個(gè)值構(gòu)成,其中TP為被正確分類的正例,TN為正確分類的負(fù)例,F(xiàn)P為錯(cuò)誤分類的正例,F(xiàn)N為錯(cuò)誤分類的負(fù)例。于是準(zhǔn)確率和F1-測度值可分別用式(7)和式(8)計(jì)算得到。
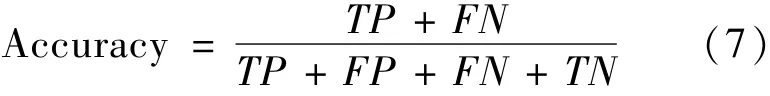
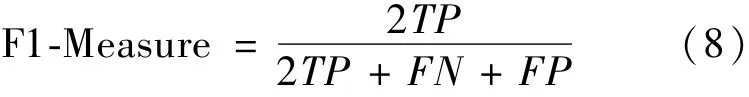
對于二元分類而言,隨機(jī)挑選一個(gè)正樣本以及一個(gè)負(fù)樣本,分類算法根據(jù)計(jì)算得到的分?jǐn)?shù)(Score)值將正樣本排在負(fù)樣本前面的概率即為AUC值[25]。AUC值越大,表明當(dāng)前的分類算法越有可能將正樣本排在負(fù)樣本前面,即能夠更好地分類。AUC值相比準(zhǔn)確率和F1-測度而言,更適用于不平衡數(shù)據(jù)集的分類性能評價(jià)[26]。
3.2 實(shí)驗(yàn)結(jié)果分析
為了比較本文方法的有效性,首先將其與相關(guān)方法進(jìn)行比較。由表2可知:決策樹(classification and regression tree,CART)、支持向量機(jī)(support vector machine,SVM)、樸 素 貝 葉 斯(na?ve bayesian classifier,NBC)、K近鄰(KNN)等方法用于垃圾網(wǎng)頁檢測,其分類性能較差。僅有K近鄰法(KNN)的AUC值還比較高,達(dá)到90%以上,但其準(zhǔn)確率和F1測度依然很低。
KNN-IW方法因?yàn)榭紤]了訓(xùn)練數(shù)據(jù)集的不平衡性,與KNN算法相比,準(zhǔn)確率提升16%,F(xiàn)1測度提升20%,雖然AUC值降低了1%,但依然可以說,樣本加權(quán)方法的引入,使得分類性能得到大幅度提升。將KNN與Fisher特征選擇方法相結(jié)合(KNN-Fisher),所得到的分類性能與KNN相比,其準(zhǔn)確率、F1測度和AUC值分別提升9%、11%和1.3%。該方法表明Fisher特征選擇對于KNN算法的有效性。進(jìn)一步,將KNN與樣本加權(quán)、Fisher特征選擇三者相結(jié)合(KNN-IW-Fisher),與KNN相比,其準(zhǔn)確率、F1測度和AUC值分別提升20%、22%和1%,分類性能得到再次提升。最后,將KNN-IW-Fisher方法與最優(yōu)特征選擇方法相結(jié)合(即本文方法KNN-IW-OFisher),與KNN相比,其準(zhǔn)確率、F1測度和AUC值分別提升22%、24%和2.6%,成為這眾多分類結(jié)果中的最優(yōu)結(jié)果。另外,本文曾選用過互信息、InfoGain、卡方檢驗(yàn)、Laplacian Score等多種過濾式特征選擇方法進(jìn)行實(shí)驗(yàn),最終結(jié)果是Fisher特征選擇的方法是最優(yōu)的。表2中將次優(yōu)的結(jié)果,即采用InfoGain特征選擇方法(KNN-IW-OInfoGain)也一并列出,可見其準(zhǔn)確率、F1測度和AUC均比本文方法KNN-IWOFisher差1%左右。
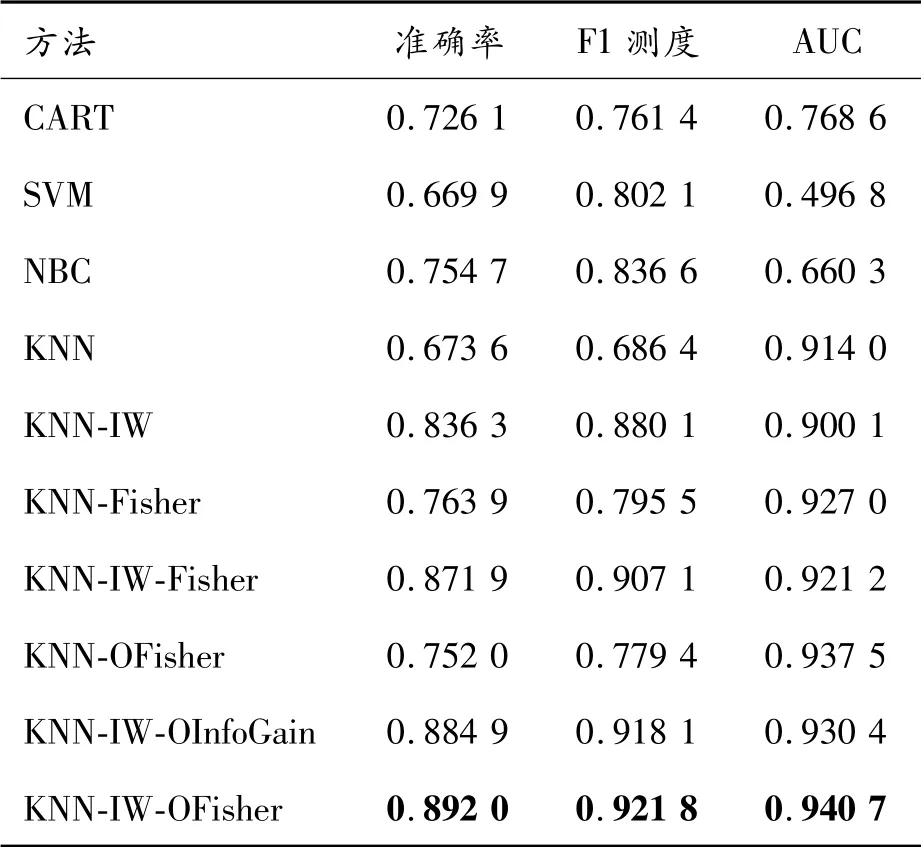
表2 相關(guān)方法的有效性
需要說明的是:本文所有KNN相關(guān)算法所采納的K值都采用了19。實(shí)驗(yàn)表明:K=19可以達(dá)到較好的分類效果。另外,F(xiàn)isher特征選擇時(shí),F(xiàn)isher Score閾值設(shè)為1%,此時(shí)分類性能達(dá)到最優(yōu),最終保留的特征數(shù)為81個(gè)。而本文方法KNN-IW-OFisher無需設(shè)置閾值,最終保留的特征只有47個(gè)。
表3列出了2007年垃圾網(wǎng)頁挑戰(zhàn)賽各優(yōu)勝團(tuán)隊(duì)的檢測結(jié)果。KNN-IW-OFisher分類器的分類性能在F1-測度這個(gè)指標(biāo)上,其值為0.92,高于競賽團(tuán)隊(duì)的最優(yōu)結(jié)果0.91;而在AUC這個(gè)指標(biāo)上,其值為0.94,僅次于最優(yōu)結(jié)果,即滑鐵盧大學(xué)團(tuán)隊(duì)的結(jié)果0.96。然而,滑鐵盧大學(xué)團(tuán)隊(duì)的F1-測度值僅為0.67,表明其分類準(zhǔn)確率很差。跟F1測度和AUC都較優(yōu)的匈牙利科學(xué)院團(tuán)隊(duì)相比,本文方法依然更優(yōu),高出1%。
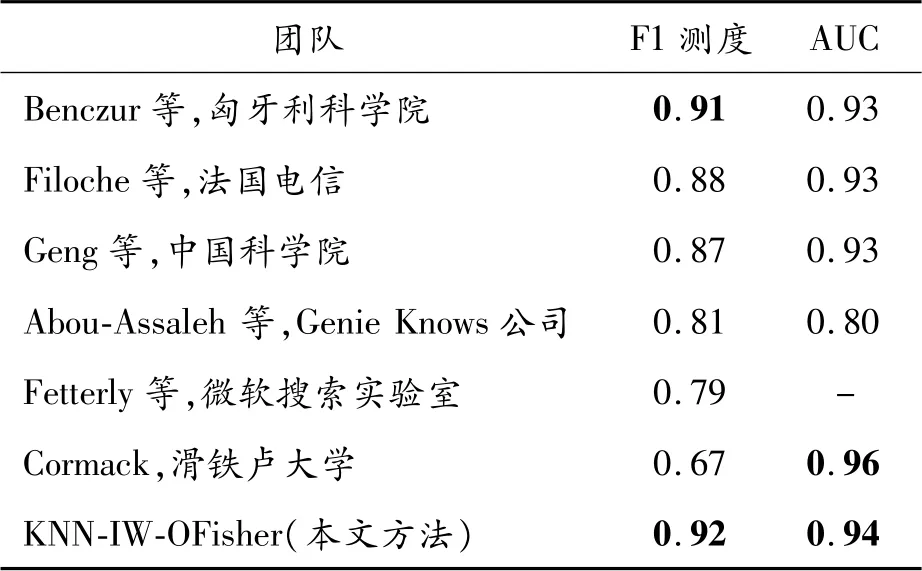
表3 web spam challenge 2007優(yōu)勝團(tuán)隊(duì)檢測結(jié)果
Scarselli等[7]提出一種包含概率映射圖自組織映射(probabilistic mapping graph self-organizing map,PM-G)和圖神經(jīng)網(wǎng)絡(luò)(graph neural network,GNN)的圖層疊架構(gòu)用于垃圾網(wǎng)頁檢測,同樣基于WEBSPAM UK-2006進(jìn)行實(shí)驗(yàn)。表4第1行列出其所得最優(yōu)方法FNN,PM-G+GNN(3)+GNN(1)的實(shí)驗(yàn)結(jié)果。本文方法與其相比,除了準(zhǔn)確率更低外,AUC接近其分類結(jié)果,而F1測度則明顯更優(yōu)。對于不平衡分類而言,F(xiàn)1測度和AUC是更為重要的2個(gè)指標(biāo)。從這2個(gè)指標(biāo)看,本文方法有一定優(yōu)勢。
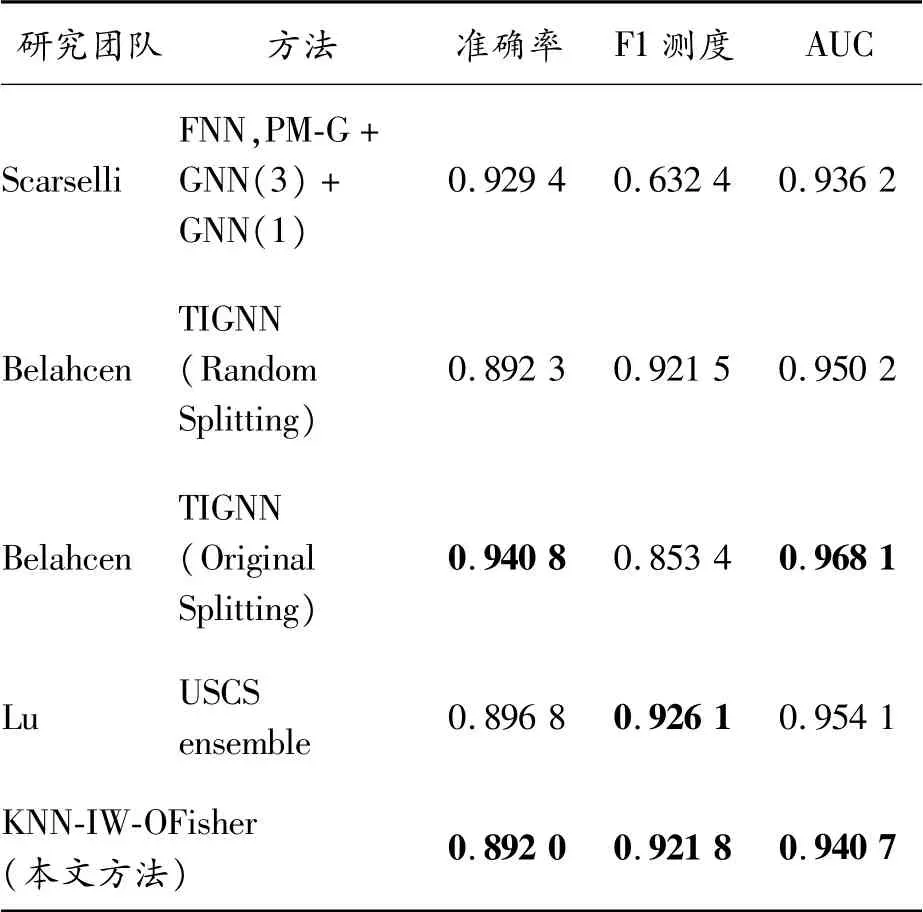
表4 Scarselli其他研究團(tuán)隊(duì)的分類結(jié)果
Belahcen等[15]提出一種傳感-感應(yīng)圖神經(jīng)網(wǎng)絡(luò)(transductive-inductive graph neural networks,TIGNN)方法基于WEBSPAM UK-2006數(shù)據(jù)集實(shí)驗(yàn)。如果采用不同于2007年垃圾網(wǎng)頁挑戰(zhàn)競賽原始的數(shù)據(jù)切割方式,其方法得到最優(yōu)(state-ofthe-art)的分類結(jié)果,如表4第3行所示。但如果采用原始的數(shù)據(jù)切割方式,其方法的實(shí)驗(yàn)結(jié)果也表現(xiàn)優(yōu)異,如表4第2行所示。本文方法未考慮數(shù)據(jù)重新切割的問題,因此與其在原始切割數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果相比更為合適。與其相比,本文方法的實(shí)驗(yàn)結(jié)果也比較接近,F(xiàn)1測度更優(yōu),AUC值略少1%。
Lu等[16]提出一種融合人工免疫克隆選擇、欠采樣集成和C4.5決策樹的分類方法,如表4第4行顯示其在WEBSPAM UK-2006上的實(shí)驗(yàn)結(jié)果,其方法的分類結(jié)果略優(yōu)于本文方法,但其采用的基于人工免疫克隆選擇的特征選擇方法耗時(shí)太長,同時(shí)其抗體個(gè)數(shù)還成為一個(gè)超參數(shù),算法的實(shí)用性比本文方法更差。
4 結(jié)論
提出一種融合最優(yōu)Fisher特征選擇和樣本加權(quán)的K近鄰分類的機(jī)器學(xué)習(xí)算法KNN-IW-OFisher用于垃圾網(wǎng)頁檢測。在WEBSPAM-UK2006數(shù)據(jù)集上的實(shí)驗(yàn)表明:本文方法的分類效果明顯優(yōu)于決策樹、支持向量機(jī)、樸素貝葉斯、K近鄰等傳統(tǒng)分類器。與其他最優(yōu)的實(shí)驗(yàn)結(jié)果相比,本文方法也接近最優(yōu)結(jié)果。對KNN-IW-OFisher算法在垃圾網(wǎng)頁檢測上取得較好的分類效果的原因進(jìn)行了分析和探討,并指出了可以進(jìn)一步研究的相關(guān)問題。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
