基于數據驅動的鋰離子電池健康狀態評估綜述
2021-08-06 01:24:34趙顯赫耿光超李志浩
浙江電力 2021年7期
趙顯赫,耿光超,林 達,李志浩,張 楊
(1.浙江大學 電氣工程學院,杭州 310027;2.國網浙江省電力有限公司電力科學研究院,杭州 310014;3.國網浙江省電力有限公司,杭州 310007)
0 引言
鋰離子電池具有能量密度高、輸出電壓高、允許使用溫度范圍大、循環壽命長、自放電現象不明顯、污染較小等優點[1],因而被廣泛應用于電網儲能、電動汽車、通信基站、商用儲能等眾多民用領域及航天、航空、航海等軍工領域[2-3]。
在使用過程中,鋰離子電池的性能會隨其內部電化學成分的不可逆退化而下降,這被稱為電池老化。電池老化帶了電池的安全性與可靠性問題,導致用電設備性能下降或系統故障,甚至引發起火或爆炸的問題。為確保電池的安全性與可靠性,鋰離子電池的健康管理技術開始不斷發展。電池的SOH(健康狀態)與電池的RUL(剩余使用壽命)是電池健康管理的兩個重要評價指標,二者均可反映電池在使用過程中的健康狀況。已有大量學者對鋰離子電池的SOH 估計與RUL 預測進行研究,目前的主流方法分為基于物理模型的電池健康狀態評估和基于數據驅動的電池健康狀態評估兩類[4]。
隨著大數據及機器學習技術的蓬勃發展,數據驅動技術已成為當前電池健康分析的主要研究方向,數據驅動預測技術的一般流程如圖1 所示。首先采集大量電池使用數據,利用特征工程方法提取電池退化相關特征,借助數據驅動算法,訓練出與電池老化特性一致的模型,對電池進行離線或在線的退化分析及健康管理。相比于傳統基于物理模型的分析方法,數據驅動不需要對電池內部復雜的電化學機理進行精確建模,無需進行電池自身參數辨識,具有較高的可遷移性、魯棒性與自適應性。基于數據驅動的鋰離子電池健康狀態評估過程如圖2 所示。
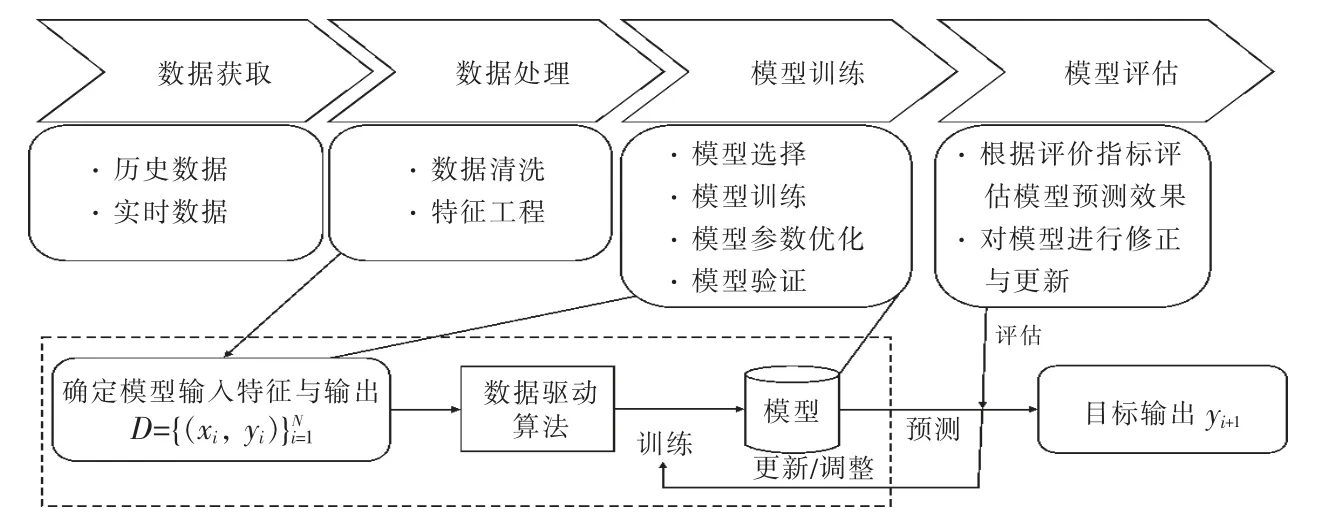
圖1 數據驅動預測技術的一般流程
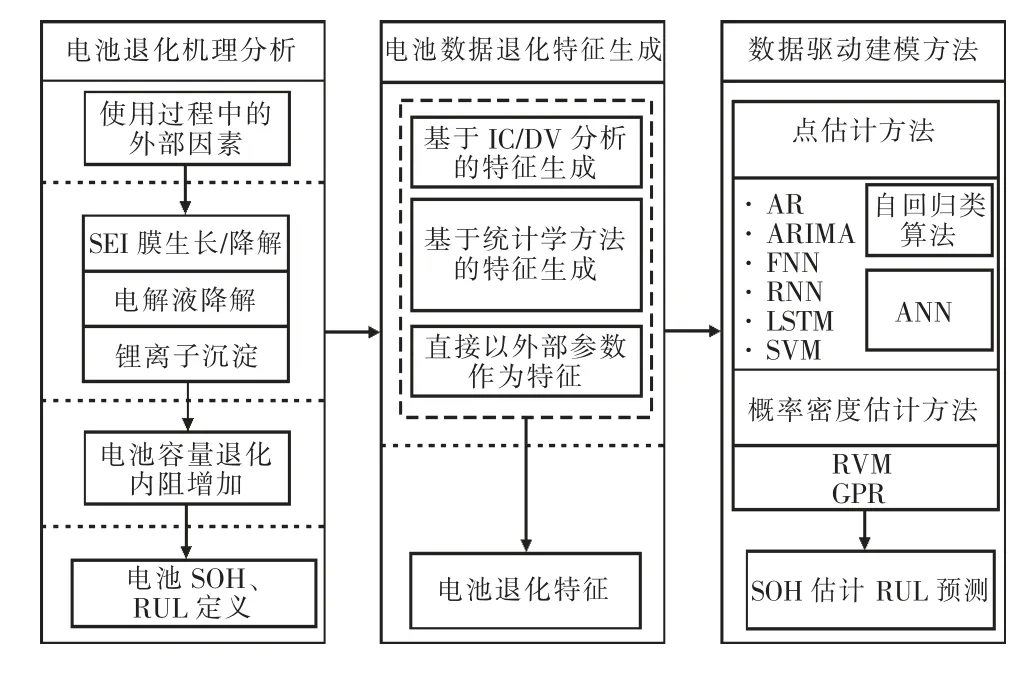
圖2 基于數據驅動的鋰離子電池健康狀態評估過程
目前,國內外已有部分學者對鋰離子電池健康狀態評估方法進行綜述[6-10],文獻[6-8]綜述了基于物理模型及數據驅動模型的電池健康管理問題研究方法,但在數據驅動技術方法介紹較為簡略,文獻[9]對鋰離子電池的數據驅動方法進行對比綜述,但只討論了三種典型建模方法,對方法的總結不夠全面。文獻[10]介紹了電池SOH 與SOC(荷電狀態)預測的機器學習方法,但缺少電池退化特征提取過程的介紹。總體來看,目前國內單獨對數據驅動的電池健康狀態評估技術詳細歸納的文獻較少,且較多文獻對數據驅動的全過程把握不足。因此,有必要從數據驅動的角度出發,對電池健康狀態評估技術進行系統的綜述。
本文首先通過分析鋰離子電池的退化機理列舉了電池老化的影響因素,并概述了電池健康狀態的定義。其次歸納了數據驅動過程中電池退化特征的提取方法。然后綜述了基于數據驅動的電池SOH 估計及電池RUL 預測方法,對各類方法進行了比較。最后分析了現有數據驅動的鋰離子電池健康狀態分析方法存在的挑戰,并提出了未來趨勢及展望。
1 電池退化機理分析
1.1 鋰離子電池的性能衰退機理分析
目前,國內外已有大量學者對鋰離子電池的退化機理進行研究。目前主流的觀點認為鋰離子沉淀、SEI(固體電解質界面)膜厚度變化和電解液降解等是造成電池老化和容量衰減的主要原因[5]。在鋰離子電池使用過程中,其使用時間、電壓、充放電電流強度、溫度、充放電深度等條件是影響鋰離子電池使用壽命的主要外部因素[11],圖3 總結了鋰離子電池外部因素、衰減機制及電池性能退化間的關系。研究鋰離子電池退化機理對于電池健康狀態評估具有重要意義。
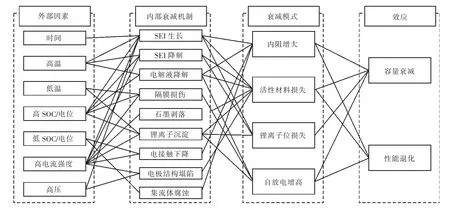
圖3 鋰離子電池外部因素、衰減機制及電池性能退化情況間的相互關系
1.2 電池健康狀態定義
電池的SOH 是表征電池當前性能及退化程度的重要指標。隨著電池的使用次數增加,其最大可用容量降低,內阻不斷提高,因此行業內一般使用容量與內阻對電池的SOH 進行定義。
從電池容量角度對電池SOH 的定義如式(1)所示,目前,該定義在電池行業中認可度最高[12]。

式中:Qcurr為電池當前最大可用容量;Qnew為電池出廠最大可用容量。
此外,也可從電池內阻角度對電池SOH 進行定義[13],表達式如式(2)所示:

式中:REOL為電池壽命結束時的內阻;Rcurr為電池當前內阻;Rnew為電池出廠時的內阻。
電池RUL 指在當前使用條件下電池工作至報廢所需要的循環次數,通常作為表征電池的健康狀態的另一個重要指標。一般認為,當鋰離子電池當前容量小于出廠容量的80%時,則判定電池報廢[14]。
2 電池數據的退化特征生成
特征生成是電池健康狀態數據驅動建模過程中的重要一環,通過從電池數據中提取反映電池老化信息的特征參數作為模型訓練的輸入,參與模型的訓練。根據鋰離子電池SOH 的定義,電池的最大容量、內阻等參數可直接作為表征鋰離子電池退化情況的特征參與模型訓練。但通常情況下,這些參數在電池使用過程中無法直接測得,因此,往往還需要以下退化特征的生成方法。
2.1 基于ICA/DVA 的特征生成
ICA(容量增量分析)和DVA(電壓差分分析)是最常用的兩種電池退化特征生成方法[15]。ICA通過分析電池在不同循環周期中電壓與電池增量容量之間關系的變化趨勢,提取出電池的退化特征參數[16]。DVA 則通過電壓對容量的導數與電池循環退化過程中的峰谷變化,分析電池容量隨使用時間增長的衰減趨勢[17]。此外,DTV(差分熱伏安法)是一種改進的基于ICA 的電池退化特征生成方法,它將ICA 手段與溫度測量相結合,對電極材料的熱力學信息進行推斷[18-19],進而提取出電池的退化特征。基于ICA/DVA 生成的退化特征能夠反映電池內部的物理狀態,且數據容易獲得,具有較高的實用性。但ICA/DVA 僅限在較低充放電倍率條件進行,同時,該方法對于噪聲及測量誤差較為敏感,需要借助合理的濾波手段對曲線平滑處理才能提取更穩定的退化特征。
2.2 基于統計學方法的特征生成
通過各種統計學方法對采集的電池電壓、電流、溫度等數據進行分析計算可作為一種電池退化特征的生成手段,其優點在于可利用有限的電池數據生成大量電池退化相關特征。文獻[20]通過分析電池第100 次循環與第10 次循環差值曲線的最大值、平均值、散度值、偏度值、峰態系數等統計學指標,以及溫度、充放電量等曲線,生成了20 個表征電池退化特征的統計學參數,僅利用電池前100 個周期的測試數據回歸預測了電池的RUL,誤差小于9.1%。文獻[21]通過灰色關聯度和主成分分析的統計方法,提取出5 個電池HI(健康因子)作為反映電池健康狀態的特征,最終利用神經網絡得到了誤差小于2%的SOH 預測精度。
使用統計學手段進行特征生成的缺點在于,該方法過于依賴先驗經驗,且部分所提取的特征可能與預測目標相關性很小甚至無明顯相關性,導致模型訓練后預測效果變差。為避免這一問題,需通過一定的正則化方法削弱無關特征對模型的影響,如文獻[20]采用彈性網絡弱化了與預測相關性較小的特征對模型的影響,提高了預測的準確度與可信度。但正則化過程也增加了模型訓練的難度,增加了訓練時間。
2.3 直接以外部參數作為特征
對于一部分機器學習模型而言,其模型本身具有從輸入數據中提取隱含退化信息的能力,可直接使用電池的電壓、電流、溫度等外部參數作為特征進行模型訓練,無需額外進行電池退化特征生成。文獻[22]使用DCNN(深度卷積神經網絡)將在線監測的電池電壓、電流、溫度等外部參數直接作為模型訓練的輸入,實現了鋰離子電池容量的實時在線預測;文獻[23]利用不同的數據驅動模型,使用BMS(電池管理系統)直接測量的電流、電壓、溫度訓練機器學習模型,在動態運行條件下進行電池健康評估。直接外部參數輸入作為特征的缺點在于過分依賴模型的分析能力,模型計算復雜程度高。
不同鋰離子電池數據退化特征生成方式比較如表1 所示。

表1 3 種鋰離子電池數據退化特征生成方式優缺點比較
3 數據驅動的鋰離子電池健康狀態評估建模方法
數據驅動的電池健康狀態評估一般通過回歸分析方法或機器學習的算法,建立電池退化特征或HI 與電池健康狀態的關聯模型。以電池數據中提取出的退化狀態特征作為模型輸入,電池的最大容量或內阻作為模型輸出,得到關聯二者耦合關系及演變規律的模型,從而實現對電池未來SOH 的估計。通過判斷電池容量循環曲線到達容量退化閾值的循環次數,可進而對電池RUL 進行預測。
數據驅動方法不需要考慮電池內部的復雜電化學反應與非線性退化機理,避免了不同鋰離子電池內部結構、化學成分、制造工藝、使用條件、個體差異等困難參的數辨識過程,僅依靠電池在線監測或離線積累的數據即可建立電池的數學模型,并對電池健康狀態進行分析預測,具有極強的魯棒性與自適應性。本節將詳細介紹目前對電池SOH 估計及RUL 預測的數據驅動建模方法并進行對比分析。
3.1 自回歸類方法
AR(自回歸)是一類對時間序列預測問題建模的方法,通過對過去系統狀態作為輸入進行回歸分析,得模型參數與系統階數,建立含多個電池健康特征的時序模型,并對當前時刻系統狀態進行預測。常用的AR 類模型有ARMA(自回歸滑動平均)、ARIMA(差分整合移動平均自回歸)等[24]。
在電池SOH 評估及RUL 預測方面,文獻[25]介紹了一種基于AR 的多元時間序列模型用于電池SOH 的預測,并達到了90%以上的置信精度;文獻[26]通過提取等幅壓升時間,等幅流降時間等特征建立電動汽車電池SOH 的多元AR 模型,使得模型預測的MAE(平均絕對值誤差)小于3%,RMSE(均方根誤差)小于4%。一些研究在傳統的AR 模型基礎上進行改進與優化,提高了模型的預測效果。文獻[27]提出了一種結合EMD(經驗模態分解)的ARIMA 模型的來預測RUL,對電池的容量恢復過程實現了高精度預測,先比與傳統ARIMA 方法,平均誤差下降了83.08%。
AR 類模型具有模型參數少、計算復雜度低、訓練時間短等優點,一般用于電池樣本數據量較小的應用場景中。但自回歸模型無法分析多個輸入特征間的隱含關系,結果置信程度與預測精度較低,甚至可能出現預測結果違背實際物理規律的問題。
3.2 人工神經網絡
ANN(人工神經網絡)是以數學形式模擬人類大腦思考過程,將神經元以一定方式相互連接形成的網絡通過大量數據對神經元間的閾值及權重進行訓練得到預測模型,ANN 的基本結構如圖4所示,包含輸入層、輸出層、隱藏層三層。ANN適用于多相關特征復雜非線性建模問題,具有自主學習能力強、預測精度高的優點。在電池健康狀態評估領域中,ANN 目前已成為一種主流的數據驅動技術,且具有優異的預測性能。常見的ANN 模型有FNN(前饋神經網絡)、RNN(循環神經網絡)、CNN(卷積神經網絡)以及其他改進神經網絡模型。
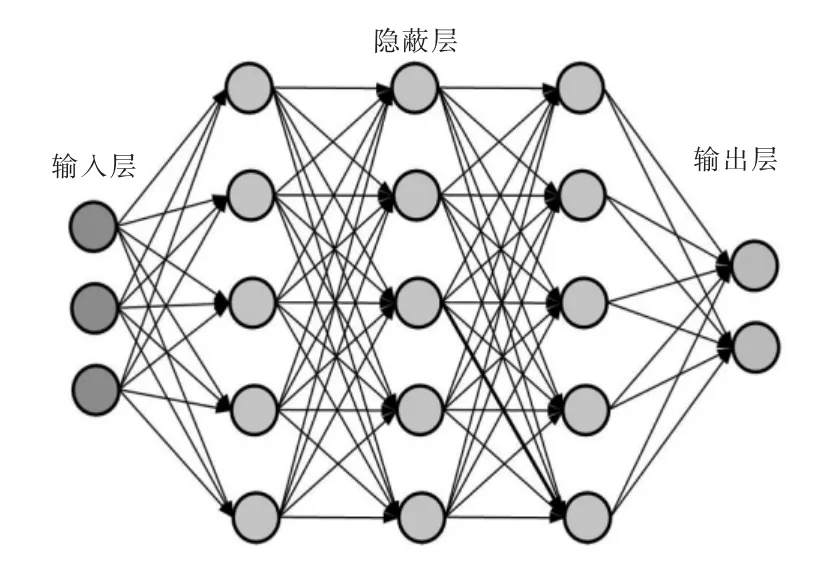
圖4 ANN 基本結構示意
大量文獻應用神經網絡對電池健康狀態進行估計及預測。文獻[28]使用ANN 模型建立了電池最大可用容量與溫度、電池循環充放電量、放電深度等因素之間的模型,進而對電動汽車動力電池的SOH 進行準確估計。文獻[29]使用模擬退火算法改進的FNN,分析了微分電壓、循環次數等健康因子對電池SOH 的影響,改善了傳統FNN在訓練過程中容易陷入局部最優的問題,降低了預測誤差。相比于FNN,RNN 通過網絡參數循環反饋機制,能在一定時間內保留網絡的重要信息并更新,在電池退化這類時間序列問題建模中更具優勢。文獻[30]利用GRU-RNN(門控循環神經網絡)建立電壓時序特征與電池SOH 的映射規律,實現了MAE 小于1.25%的預測精度。文獻[31]使用RNN 類中的LSTM(長短期記憶神經網絡)神經網絡對磷酸鐵鋰離子電池進行SOH 估計和RUL預測,該方法能分析出電池測試數據與壽命的長期依賴關系,相比傳統RNN 方法,LSTM 方法的預測效果提高了20%~50%。
ANN 的方法在電池健康狀態預測過程中具有出色的表現,但仍存在以下不足:首先,由于ANN 網絡參數復雜,所需訓練時間與計算資源隨數據量增長急劇增加,對于小樣本數據的預測能力差;其次,ANN 在訓練過程中,容易陷入參數局部最優,導致過擬合問題;同時ANN 的表現效果與選取的模型網絡結構高度相關,而目前缺乏選取網絡結構的明確方法,通常需借助一定先驗經驗或多模型比較確定最終網絡結構。
3.3 支持向量機
SVM(支持向量機)是一種目前常用數據分析算法,其通過核函數將低維空間的非線性問題映射至高維空間中的線性問題,從而對復雜的非線性系統建模,其原理示意如圖5 所示。

圖5 SVM 方法的原理示意
與ANN 相比,SVM 具有更嚴格的數學證明,計算復雜度較低,收斂速度較快。同時,SVM 克服了ANN 易陷入局部參數最優的問題,對小樣本數據的訓練能力強[32],預測精度高,因此在電池健康狀態評估領域受到廣泛關注。
文獻[33]使用了等充電電壓差時間間隔和等放電電壓差時間間隔兩個實時可測的HI,通過SVM 對健康指標與在線容量之間的關系進行建模,從而實現了RMSE 小于1.97%的預測RUL。
SVM 方法也存在很多不足,如核參數復雜難以選取、對交叉訓練及正則化方法的依賴程度高等。另外,SVM 對訓練過程中的缺失數據敏感,在實際應用中對原始電池數據質量及數據預處理方法要求較高。
3.4 相關向量機
RVM(相關向量機)與SVM 的基本原理相同,但采用稀疏貝葉斯理論框架得到網絡權重,因此其輸出形式為概率密度估計而非點估計。RVM 具有SVM 相似的計算精度高、運算復雜度低等優點,且由于其概率預測的輸出形式,受到鋰離子電池預測領域的廣泛關注。文獻[34]提取電池放電表面溫度特征的HI,使用RVM 模型對電池RUL 實現了預測,RMSE 小于2.84%。文獻[35]提出了一種RVM 增量在線學習策略,通過在線電壓、電流、溫度數據的實時輸入對模型進行更新,以實現RMSE 小于1.95%的RUL 在線精確預測,并較少了50%的訓練時間。
總的來說,RVM 算法模型精度高,運算復雜性低,并能輸出概率形式的預測,在電池健康狀態建模中具有出色的表現。但由于RVM 模型矩陣過于稀疏,其對訓練數據量的需求相對較高,預測結果穩定性較差。
3.5 高斯過程回歸
GPR(高斯過程回歸)是一種基于貝葉斯框架與先驗知識對系統行為過程進行回歸分析的概率估計模型。與RVM 模型相似,GPR 的輸出也為概率密度估計形式,可用作電池老化健康狀態估計的一種方法。文獻[36]針對容量再生現象影響鋰離子電池健康狀態建模精度的問題,提出一種基于EMD(經驗模態分解)的能量加權的GPR 方法,利用EMD 分解獲得樣本的能量分布情況,建立基于能量加權GPR 的鋰離子電池SOH 預測模型。文獻[37]從恒流恒壓充電過程中提取3 個健康因子,用通過統計學相關系數分析健康因子與電池容量之間的相關性,以健康因子和容量數據建立GPR 模型以預測容量,獲得電池RUL 預測結果。
總的來說,GPR 具有模型預測精度高,預測結果為概率密度形式等優點。但由于其模型固有結構導致在分析電池數據量較大的問題時,計算復雜度較高。同時,該模型超參數較多,訓練時超參數調整過程繁瑣。
3.6 各種數據驅動方法比較
綜上所述,基于數據驅動的鋰離子健康狀態評估技術目前已比較成熟,不同數據驅動方法具備各自優點與適用場景。從圖6 對各種模型的預測精度進行對比可知,AR 類模型的預測精度相對最低,其他四類方法在情況合適的條件下均有較出色的預測效果。ANN 類模型雖然預測平均精度最高、但預測的穩定性較差,其預測效果與所選取的網絡結構相關性很大。各類模型性能比較如表2 所示。
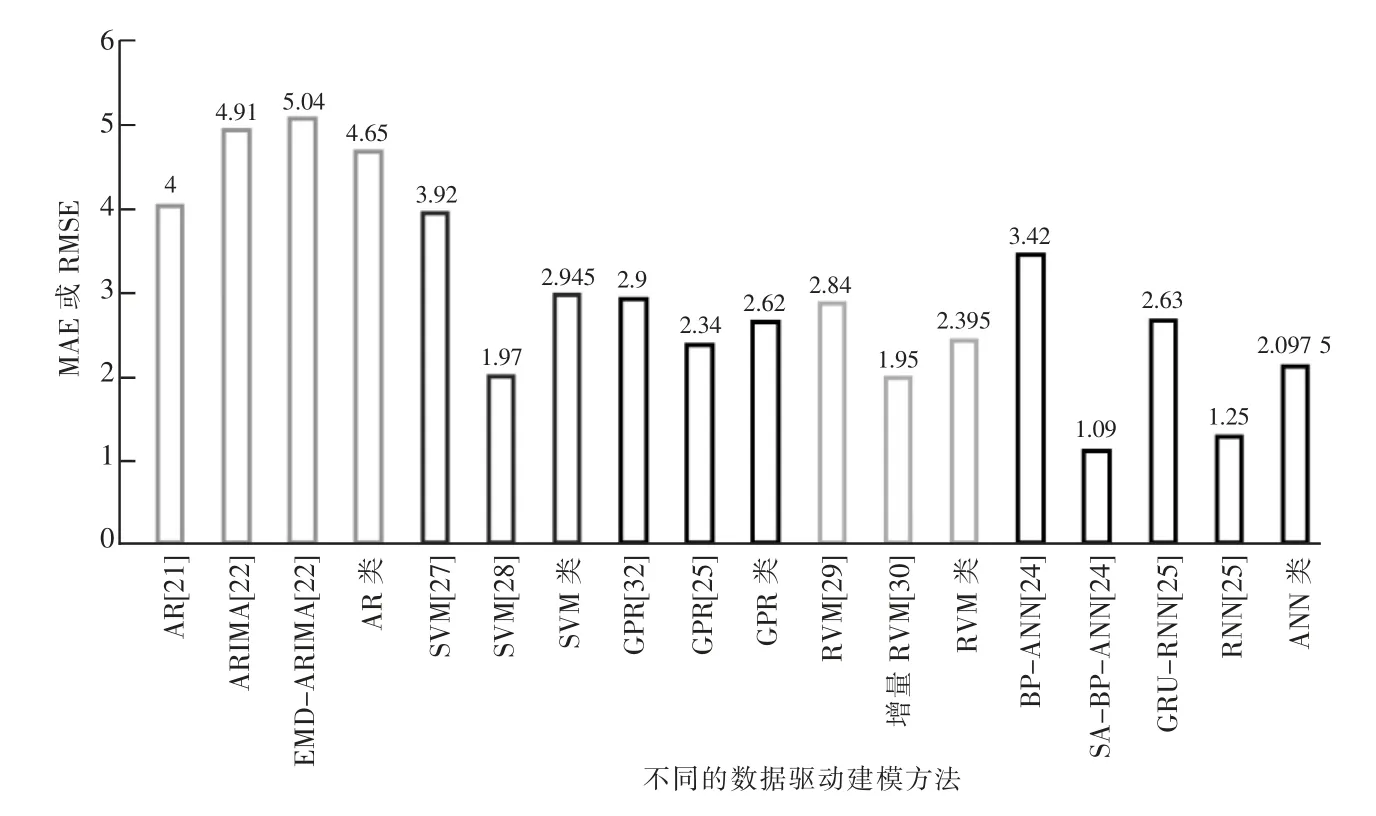
圖6 不同數據驅動的電池健康狀態建模方法的精確度比較

表2 鋰離子健康狀態評估數學驅動模型性能比較
4 挑戰與展望
總的來說,目前對于基于數據驅動的鋰離子電池SOH 估計與RUL 預測技術目前已比較成熟,各類方法的驗證也較為充分。但仍面臨以下挑戰:
首先,數據驅動的鋰離子電池SOH 一般屬于“黑盒模型”,對模型的物理可解釋性較差。目前,已有部分研究使用數據驅動與物理模型相結合的方式進行鋰離子電池健康或電荷狀態進行分析[38-39],但仍無法準確描繪電池的電化學特性,且兩種模型結合方式的合理性有待驗證。隨著電池老化機理研究的日益完備與人工智能算法的不斷更新,物理模型與數據驅動相結合的方法將是未來電池SOH 評估的主流發展趨勢。
其次,數據驅動估計對數據有效性要求較很高,在預測過程中,當出現訓練數據中不包含的電池工作模式時,往往模型預測效果很差。目前數據驅動的電池SOH 評估的研究一般都使用數據相對完整、電池循環次數較多、充放電模式規范的電池公共數據集或實驗室測試的數據進行方法驗證,而很少有研究直接采用實際儲能應用場景的隨機性高、波動性強、缺乏部分工況、測量誤差較大、完整性差的真實數據。因此,對于電池的SOH 研究仍多局限于實驗室測試條件下的理想情況。未來主流的發展趨勢是借助工業大數據、云邊協同計算、數字孿生等先進技術,通過對海量實際應用場景電池數據進行分析,得到具有普適性的電池退化規律模型,進而提升電池SOH 分析評估水平。
最后,目前的電池數據驅動建模大多只使用電池的電壓、電流、溫度、內阻等測量參數進行分析。但由于電池多種老化因素的復雜非線性耦合方式,這些測量參數中隱含的電池退化信息難以被充分提取出來。X 射線、紅外成像、核磁檢測、聲紋識別等非侵入式檢測技術可直接檢測電池內部結構改變、溫度分布、電解質降解程度、電池噪聲等直接反映電池健康情況的信息,可應用于新一代BMS 中作為電池SOH 監測的手段。
5 結論
本文針對基于數據驅動的鋰離子電池SOH評估方法開展綜述性研究,可得出以下結論:
(1)鋰離子電池退化機理主要為鋰離子沉淀、SEI 膜厚度變化和電解液降解等,這與電池使用的時間、電壓、電流、溫度等外部因素有關。
(2)電池退化特征生成的主要方法有ICA/DVA法、統計學方法、直接外部參數輸入等方法,其中前兩種方法使用較為廣泛,能提取多個有效的電池退化特征;后者對模型復雜度要求較高,一般用于ANN 等復雜模型。
(3)目前鋰離子電池健康狀態評估的數據驅動建模方法主要包括AR,ANN,SVM,RVM,GPR 等方法,不同模型具備各自的優缺點與應用場景,目前ANN,SVM,GPR 是目前最主流的3種數據驅動的鋰離子健康狀態評估模型。
(4)數據驅動的電池健康狀態評估領域仍存在模型可解釋性差、數據質量要求高、電池測試方法有限等挑戰,隨著科技的不斷進步,數據驅動的電池健康狀態評估將具有更廣闊的應用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
