圖像去噪方法概述
2021-08-07 07:42:18劉利平喬樂樂蔣柳成
計算機與生活 2021年8期
劉利平,喬樂樂,蔣柳成
華北理工大學 人工智能學院,河北 唐山 063210
圖像在采集、傳輸過程中因環境、成像設備和人為等因素的影響會受到不同噪聲的干擾[1],導致采集的圖像質量下降,給后續的特征提取、文本檢測、圖像分割等圖像處理環節造成不可估計的影響,因此,需要對圖像進行去噪處理。圖像去噪作為計算機視覺研究領域中一個重要的研究方向,其目的是盡可能地減少或消除噪聲對圖像的干擾,使處理后的圖像盡可能接近原始圖像。圖像去噪的實質是對數據本身恢復和重建,以起到排除污染的作用。由于真實噪聲圖像的不足,加性白噪聲圖像(additive white noise image,AWNI)被廣泛用于訓練去噪模型[2]。AWNI包括高斯、泊松、鹽、胡椒和乘性噪點圖像[3]。
圖像去噪有著悠久的歷史,最早的作品可以追溯到20 世紀50 年代[4]。最近的去噪方法激增主要歸功于著名的塊匹配3D(block-matching and three-dimensional filtering,BM3D)框架[5],該框架結合了自然圖像的非局部相似性特征和變換域中的稀疏表示[6]。在早期階段,圖像去噪的許多相關工作都集中在過濾單通道灰度圖像上。近年來,成像系統和技術的進步極大地豐富了多維圖像(彩色圖像)保存和呈現的信息,可以為真實場景提供更真實的表示。圖像尺寸和維度的增長也對去噪提出了更高的要求。處理高維圖像的一個主要挑戰是如何有效利用多個通道或頻譜的相互關聯的信息,并且還要在噪聲消除和細節保留之間找到平衡。在過去的二十年中,具有代表性的BM3D 方法已經以兩種不同的方式成功地擴展到了多維圖像。第一種策略是應用某種相關變換,以使在變換后的空間中,每個通道可以由某個有效的單通道去噪器獨立過濾[7]。例如,CBM3D(color-BM3D)方法[8]對自然RGB 圖像建立的對比度或YCbCr 顏色變換可以提供顏色數據的近似最佳解相關[9]。另一種替代解決方案是利用信道或頻帶相關性通過聯合處理整個多維圖像數據集來建模。為了實現這一目標,Maggioni等人[10]通過使用3D像素立方體將BM3D擴展為稀疏4D變換域協作濾波(BM4D),將其堆疊為4D 組。
盡管傳統方法在圖像去噪方面已經取得了相當不錯的性能,但它們仍然存在一些缺點,包括需要針對測試階段的優化方法,手動設置參數以及單個降噪任務的特定模型。近年來,隨著神經網絡架構變得更加靈活,深度學習技術獲得了克服這些缺點的能力。
1 圖像去噪的基本框架
圖像中噪聲的來源有許多種,這些噪聲來源于圖像采集、傳輸、壓縮等各個方面。噪聲的種類也各不相同,比如椒鹽噪聲、高斯噪聲等,針對不同的噪聲有不同的處理算法。
對于輸入的帶有噪聲的圖像v(x),其加性噪聲可以用一個方程式來表示:
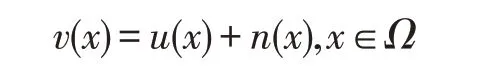
其中,x是像素;u(x)是原來沒有噪聲的圖像;n(x)是噪聲項,代表噪聲帶來的影響;v(x)是像素的集合,也就是整幅圖像。從這個公式可以看出,噪聲是直接疊加在原始圖像上的,這個噪聲可以是椒鹽噪聲、高斯噪聲。理論上來說,如果能夠精確地獲得噪聲,用輸入圖像減去噪聲就可以恢復出原始圖像。但現實往往不是很理想,除非明確地知道噪聲生成的方式,否則噪聲很難單獨求出來。
1.1 傳統去噪
根據去噪方法的特性將傳統去噪方法分為了四類:(1)利用濾波去噪。湯成等人[11]提出了一種改進的曲率濾波算法,用投影算子代替傳統曲率濾波的最小三角切平面投影算子,并修正正則能量函數,達到增強去噪能力,該算法有很好的強噪聲去噪效果,但是不能自適應調整鄰域內切平面投影算子,而且運行時間較長。張繪娟等人[12]通過設置適當的調整參數,動態選取固定閾值,增加調節因子來降低原小波系數和估計小波系數之間的恒定偏差,從而完成圖像去噪。(2)利用稀疏編碼去噪。李桂會等人[13]通過自適應匹配追蹤算法求解稀疏系數,然后利用K 奇異值分解算法將字典訓練成能夠有效反映圖像結構特征的自適應字典,然后將稀疏系數與自適應字典相結合來重構圖像。袁小軍等人[14]通過全局的相似塊匹配,得到理想圖像的稀疏系數估計;基于類字典和估計的稀疏系數來實現圖像的去噪。(3)利用外部先驗去噪。Buades 等人[15]提出了非本地圖像降噪算法。常圓圓等人[16]利用奇異值分解和硬閾值方法對獲得的多尺度相似矩陣進行協同來實現圖像去噪。莫一過[17]將圖像的結構先驗和稀疏先驗引入到圖像復原處理中,分別提出了基于全變分和稀疏表示的兩種改進算法。(4)利用低秩去噪。劉成士等人[18]利用低秩表示(low-rank representation,LRR)模型中的系數矩陣施加全變差(total variation,TV)范數約束,提出了一種全新的圖像去噪方法。羅學剛等人[19]將相對全變差(relative total variation,RTV)融入加權核范數最小化(weighted nuclear norm minimization,WNNM),對WNNM 低秩表示模型施加RTV 范數約束,提出一種相對全變差加權核范數極小化(relative total variation and weighted nuclear norm minimization,RTV-WNNM)圖像去噪方法,但是在圖像去噪模型構建矩陣和優化求解過程中計算量較大,導致耗時較長。表1 顯示了更多的傳統去噪方法信息。
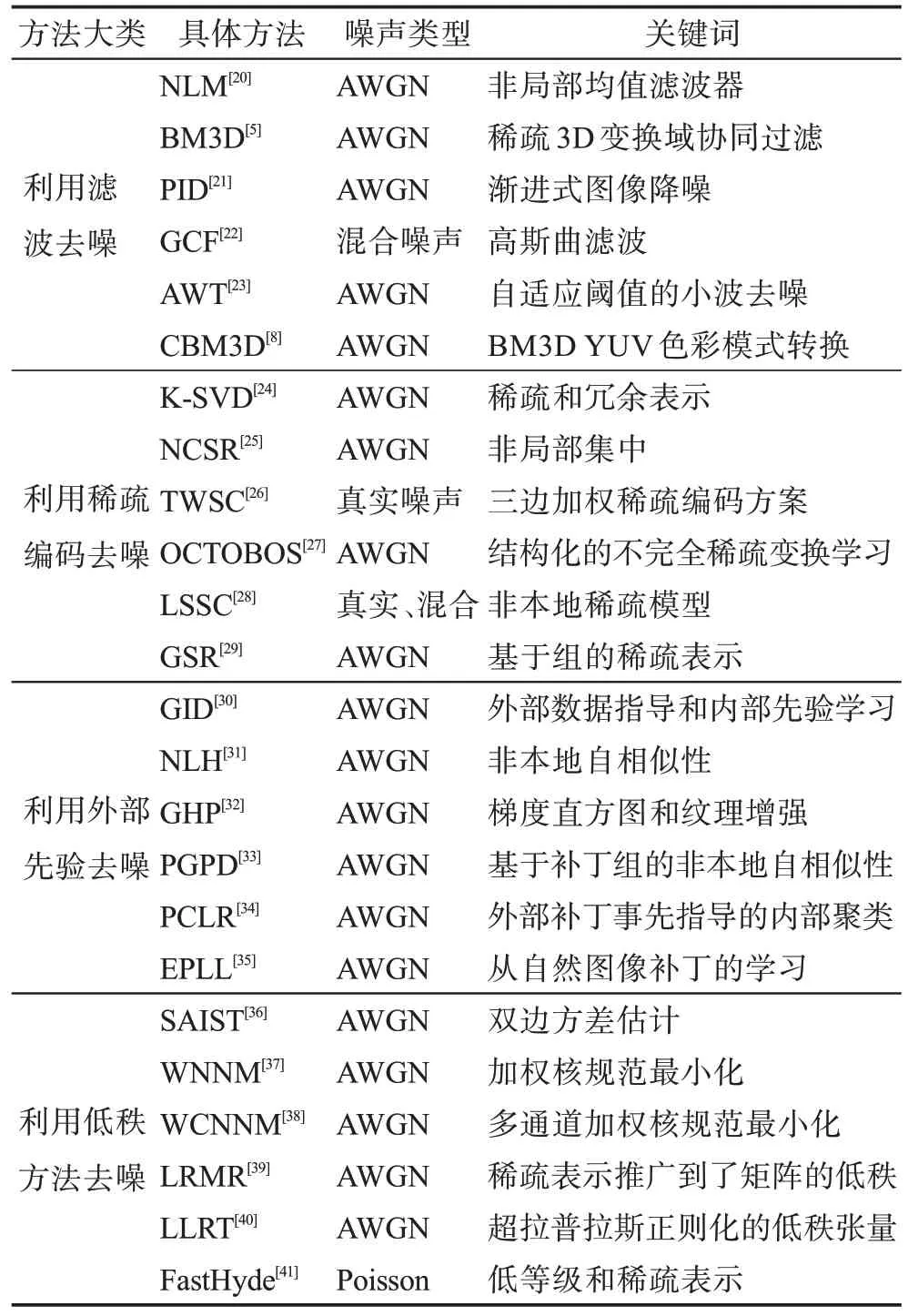
Table 1 Image denoising based on traditional methods表1 基于傳統方法的圖像去噪
在工程上,圖像中的噪聲常常使用高斯噪聲N(μ,σ2)來近似表示,其中μ=0,σ2是噪聲的方差,σ2越大,噪聲越大。一個有效的去除高斯噪聲的方式是圖像求平均,對N幅相同的圖像求平均的結果將使得高斯噪聲的方差降低到原來的N分之一。算法非局部平均(non-local means,NL-Means),就是基于這一思想來進行算法設計的。在2005 年由Buades 提出,該算法使用自然圖像中普遍存在的冗余信息來去噪聲。與常用的雙線性濾波、中值濾波等利用圖像局部信息來濾波不同的是,它利用了整幅圖像來進行去噪,以圖像塊為單位在圖像中尋找相似區域,再對這些區域求平均,能夠比較好地去掉圖像中存在的高斯噪聲。
對于傳統的降噪器,通常僅使用嘈雜的圖像來完成訓練和降噪。許多有效的去噪算法都是以BM3D 算法作為基礎提出來的。該算法的思想跟NL-Means 有點類似,也是在圖像中尋找相似塊的方法進行濾波,但是相對于NL-Means 要復雜得多。三維塊匹配算法流程圖如圖1 所示。該算法主要分為兩步:第一步是基礎估計,把待處理圖像分成固定大小的子模塊,對圖像中的每一塊進行逐塊估計,通過塊與塊之間的相似程度對其分組,并將這些塊聚集到一個三維數組中,再對三維數組進行3D 變換,最后通過聚集對有重疊的塊進行加權得到圖像的基礎估計。第二步是利用第一步得到的基礎估計圖像,對每一塊進行第二次估計,再次通過塊匹配找到與它相似的塊在基礎估計圖像中的位置,匹配之后得到兩個三維數組,對形成的兩個三維數組進行聯合維納濾波,最后通過對重疊塊的估計進行加權平均得到最終去噪圖像。BM3D 算法是目前最有效的傳統圖像去噪算法,但是由于圖像噪聲復合的特殊性和復雜性,在復雜的紋理區域(大多為邊緣區域)只有較少的相似塊,因此達不到很好的去噪效果,導致出現細節丟失、模糊等現象。
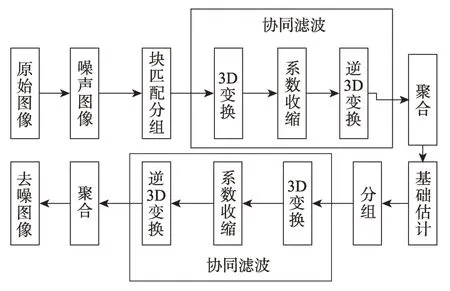
Fig.1 3D block matching algorithm flowchart圖1 三維塊匹配算法流程圖
1.2 深度學習去噪
根據圖像添加的噪聲類型將深度學習去噪算法分為了四類:(1)對加性高斯白噪聲圖像去噪。Zhang等人[42]提出了一個將批處理歸一化和殘差學習技術結合的前饋去噪卷積神經網絡(denoising convolutional neural networks,DnCNN)圖像去噪模型,雖然這種去噪方法取得了異常突出的效果,但是整個算法需要迭代太多次才能獲得一個較好的訓練模型,整個算法的快速性和收斂性不夠突出。Valsesia 等人[43]提出了一種基于圖卷積的操作來創造了非局域的感受野,通過動態計算隱藏特征中圖的相似性來得到自相似性的高效表達的圖卷積神經網絡(graph-convolutional image denoising,GCDN)模型,所提出的體系結構尚不能擴展到其他反問題,例如超分辨率。(2)對真實噪聲圖像去噪。Yan等人[44]直接從嘈雜的圖像中提取噪聲圖,從而實現無監督的噪聲建模,完成非配對真實噪聲圖像去噪。其網絡架構為自洽生成對抗網絡(selfconsistent generative adversarial networks,SCGAN)。Zhao 等人[45]提出了一種使用遞歸全卷積網絡對黑暗突發圖像進行端到端去噪,將原始的突發圖像直接映射到sRGB(standard red green blue)輸出,以生成最佳圖像或生成多幀去噪圖像序列的循環全卷積網絡(recurrent fully convolutional network,RFCN)。雖然該去噪框架具有較高的靈活性,但并未將其框架擴展到視頻去噪,并且該框架還沒有達到可以移植的要求。(3)對盲噪聲圖像去噪。Yang等人[46]提出了一種使用端到端架構的多列卷積神經網絡(multi-column convolutional neural network,MC-Net)從單幅圖像估計噪聲水平函數(noise level function,NLF)的新穎方法,但是該算法還沒有實現對自然圖像進行去噪。Yu 等人[47]提出了一種用于圖像去噪的深度迭代向下卷積神經網絡(deep iterative down-up convolutional neural network,DIDN),可以反復減少和增加特征圖的分辨率,它能夠使用單個模型處理各種噪聲級別,而無需輸入噪聲信息作為解決方法。Chen 等人[48]提出的去噪方法GCBD(GAN-CNN based blind denoiser)是利用GAN 對噪聲分布進行建模,并通過建立的模型生成噪聲樣本,與干凈圖像集合構成訓練數據集,訓練去噪網絡模型來進行盲去噪。這種方法的局限性在于,假定噪聲為零均值的加性噪聲。(4)對混合噪聲圖像去噪。Zhang 等人提出的三層超分辨率網絡(super-resolution network for multiple degradations,SRMD)是具有維數擴展策略的通用框架,可以處理多個甚至空間變化的降級。表2~表5 分別顯示了基于深度學習的有關加性高斯噪聲、實噪聲、盲噪聲和混合噪聲圖像去噪方法的更多信息。

Table 2 Additive white noise image denoising based on deep learning表2 基于深度學習的加性白噪聲圖像去噪
最初的深度學習技術在1980 年首次用于圖像處理,并由Sullivan 等人[83]以及Zhou 等人[84]首次將深度神經網絡進行圖像去噪。深度神經網絡具有相似或甚至比馬爾可夫隨機場模型在圖像去噪方面更好的表示能力。Burger 等人提出使用多層感知器(multilayer perceptron,MLP)進行圖像去噪。此外,他們將稀疏編碼和預先訓練過的深度神經網絡結合起來。盡管這些深度神經網絡在圖像去噪方面取得了很好的性能,但這些網絡并沒有有效地探索圖像的固有特征,因為它們只是將類似MLP 的網絡級聯起來。目前,經典的深度卷積神經網絡DCNN 吸引了越來越多的研究人員,因為它可以通過大量數據來進行很好的自學習,不需要嚴格選擇特征,只需要引導學習來達到期望的目的。它被廣泛應用于圖像預處理領域,如圖像超分辨率。由于圖像超分辨率的成功,一些研究人員嘗試將DCNN應用于圖像去噪。
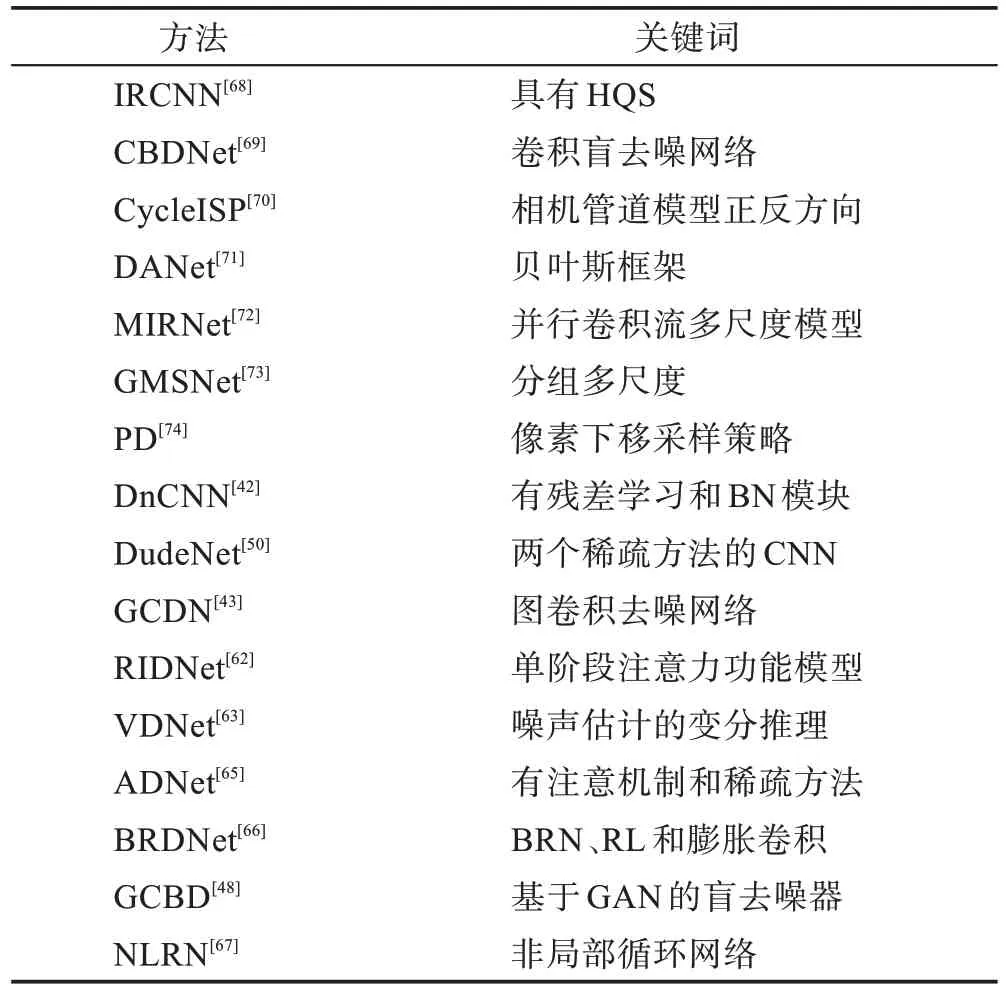
Table 3 Real noise image denoising based on deep learning表3 基于深度學習的真實噪聲圖像去噪

Table 4 Blind noise image denoising based on deep learning表4 基于深度學習的盲噪聲圖像去噪

Table 5 Hybrid noise image denoising based on deep learning表5 基于深度學習的混合噪聲圖像去噪
前饋去噪卷積神經網絡(DnCNN)用于圖像的去噪,使用了更深的結構、殘差學習算法、正則化和批量歸一化等方法來提高圖像的去噪性能。DnCNN 算法流程圖如圖2 所示。DnCNN 的深度架構:給定深度為D的DnCNN,由三種類型的層,展示在圖2 中有三種不同的顏色。(1)Conv+ReLU:對于第一層,使用64 個大小為3×3×c的濾波器生成64 個特征圖。然后將整流的線性單元ReLU 用于非線性。這里的c代表著圖像通道數,即c=1 時為灰色圖像,c=3 時為彩色圖像。(2)Conv+BN+ReLU:對應于神經網絡的2~(D-1)層,使用64 個大小3×3×64 的濾波器,并且將批量歸一化加在卷積層和ReLU 之間。(3)Conv:對應于最后一層,c個大小為3×3×64 的濾波器被用于重建輸出。
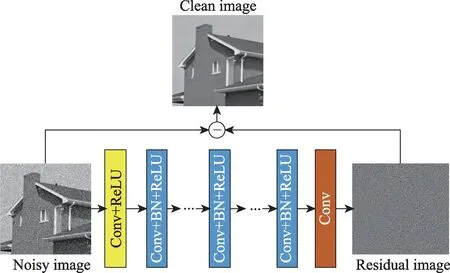
Fig.2 DnCNN denoising framework圖2 DnCNN 去噪框架
總之,本文的DnCNN 模型有兩個主要的特征:采用殘差學習公式來學習,并結合批量歸一化來加速訓練。通過將卷積和ReLU 結合,DnCNN 可以通過隱藏層逐漸將圖像結構與噪聲分開。這種機制類似于EPLL(expected patch log likelihood)和WNNM等方法中采用的迭代噪聲消除策略,但本文的DnCNN是以端到端的方式來進行訓練的。
2 數據集
2.1 訓練數據集
訓練數據集[85]分為兩類:灰度噪聲圖像和彩色噪聲圖像。灰度噪聲圖像數據集可用于訓練高斯去噪器和盲去噪器。它們包括BSD400 數據集和Waterloo Exploration 數據集。BSD400 數據集由.png 格式的400 張圖像組成,并裁剪為180×180 的尺寸以訓練降噪模型。Waterloo Exploration 數據集包含4 744 個.png格式的自然圖像。彩色噪聲圖像包括BSD432 數據集、Waterloo Exploration 數據集和polyU 數據集。具體來說,polyU 數據集由100 個真實的嘈雜圖像組成,由5 個相機獲得的尺寸為2 784×1 856 大小的圖像,相機類型包括尼康D800、佳能5D Mark II、索尼A7 II、佳能80D 和佳能600D。
2.2 測試數據集
測試數據集[85]包括灰度和彩色噪聲的圖像數據集。
灰度噪聲圖像數據集由Set12 數據集和BSD68數據集組成。Set12 包含12 個場景圖像。BSD68 包含68 張自然圖像。它們用于測試高斯降噪器和盲噪聲降噪器。
彩色圖像數據集包括CBSD68 數據集、Kodak24數據集、McMaster 數據集、CC 數據集、DND 數據集、NC12 數據集、SIDD 數據集和Nam 數據集。Kodak24數據集和McMaster 數據集分別包含24 和18 個彩色噪點圖像。cc 數據集包含15 個不同ISO 的真實噪點圖像,即1 600、3 200 和6 400。DND 包含50 個真實噪點圖像,干凈圖像由低ISO 圖像捕獲。NC12 包含12 個噪點圖像,沒有真實的干凈圖像。SIDD 包含來自智能手機的真實噪聲圖像,并且由320 對噪聲圖像和真實圖像組成。Nam 包含11 個場景,這些場景以JPGE 格式保存。
3 實驗結果
為了比較傳統去噪方法及深度神經網絡去噪方法的去噪性能,在Set12、BSD68、CBSD68、Kodak24、McMaster、DND、SIDD、polyU 和CC 上進行了定量和定性評估實驗。定量評估主要是使用不同去噪器的峰值信噪比(peak signal to noise ratio,PSNR)和結構相似性(structural similarity,SSIM)的值來測試去噪效果,定性評估是使用視覺圖形來顯示恢復的干凈圖像。
對于灰度高斯白噪聲圖像去噪,將傳統去噪方法與深度學習去噪方法進行了比較,其中包括三種傳統的去噪模型方法(即BM3D、WNNM 和EPLL),16 種基于深度學習的去噪方法,可以分為兩類:分別針對每種噪聲水平學習單個模型即DnCNN、NLRN(non-local recurrent network)、RNAN(residual nonlocal attention networks)、FOCNet(fractional optimal control network)、DRUNet(dense residual and combines U-Net)等和基于CNN 的方法經過培訓可處理各種噪聲水平即IRCNN(CNN denoiser prior for image restoration)和FFDNet(fast and flexible denoising convolutional neural network)等。NLRN 和RNAN 在網絡體系結構設計中采用非本地模塊,以便事先利用非本地映像。表6 顯示出了在噪聲水平為15、25 和50 的Set12 數據集上不同方法的平均PSNR 結果。加粗表示最優結果,下劃線表示次優結果。可以看出DRUNet 達到了最佳PSNR 結果。在噪聲水平為15、25 和50 的Set12 數據集上與傳統去噪(即BM3D)相比,DRUNet 的平均PSNR 增益約為0.9 dB,其他的深度學習去噪方法相比于傳統去噪方法也有很好的去噪性能,從中展現出了深度學習技術的優勢。Set12數據集的平均PSNR 增益超過DnCNN、IRCNN 和FFDNet 約為0.5 dB。盡管NLRN、RNAN 和FOCNet針對每種噪聲水平都學習了一個單獨的模型,并且具有非常好的競爭性能,但它們無法勝過DRUNet。圖3 顯示了噪聲水平為25 的Set12 數據集上不同方法對“House”圖像的灰度白噪聲圖像去噪結果。其中去噪算法(c)~(e)是在Windows 10系統中的Matlab-R2019a 環境下完成,去噪方法(f)~(j)是在Windows 10 系統中的python3.6 搭載PyTorch 1.1.0 環境下完成的。從圖3 中可以看出,DRUNet 比BM3D、IRCNN、FFDNet 還原的圖像邊緣更加銳利。DRUNet 僅去除了高斯白噪聲,相比于BRDNet(batch-renormalization denoising network)保留了更多的細節,視覺去噪效果要優于BRDNet還原的噪聲圖像。

Table 6 Average PSNR of different methods on Set12 data set表6 Set12 數據集上不同方法的平均PSNR dB
由于現有方法主要關注灰度圖像去噪,僅選用了幾種去噪方法來對比分析。其中包括一種傳統去噪(CBM3D)模型和六種深度學習方法來對彩色圖像進行去噪。表7 顯示了在CBSD68、Kodak24 和Mc-Master 彩色數據集上針對噪聲水平15、25 和50 的不同方法的彩色圖像去噪結果。加粗表示最優結果,下劃線表示次優結果。與傳統去噪(即CBM3D)相比,在CBSD68 數據集上DRUNet 的平均PSNR 增益約為0.8 dB,在Kodak24 和McMaster 數據集上的平均PSNR 增益更是高達1.5 dB 左右。相比DnCNN、IRCNN 和FFDNet 深度學習算法,DRUNet 的增益也有約0.5 dB 的增益,盡管ADNet(attention-guided CNN for image denoising)和BRDNet 對比前幾種算法有了一定的提升,但是與DRUNet 相比還是有很大的不足,可以看出DRUNet 在三個彩色數據集上都表現出了較大的優勢。圖4 顯示了來自噪聲水平為50 的CBSD68 數據集的圖像“296059”和McMaster 數據集的圖像“15”上幾種方法的視覺結果。其中CBM3D去噪算法在Windows 10 系統中的MatlabR2019a環境dB下運行,去噪算法(c)~(f)是在Windows 10 系統中的python3.6 搭載PyTorch 1.1.0 版本下完成的。從圖4中可以看出,DRUNet 相比于其他方法可以恢復更多的細節和紋理。

Fig.3 Gray-scale image denoising results of different methods on“House”圖3“House”上不同方法的灰度圖像去噪結果
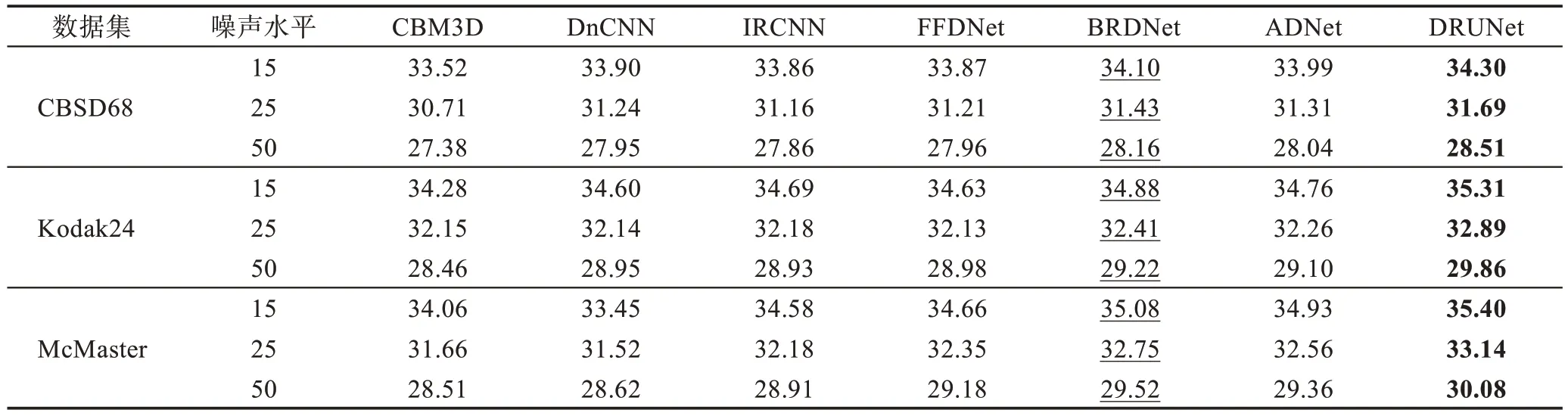
Table 7 Average PSNR of different methods on color data set表7 彩色數據集上不同方法的平均PSNR

Fig.4 Color image denoising results with different methods圖4 彩色圖像用不同方法的去噪結果
為了測試用于實噪聲圖像的深度學習技術的去噪性能,本文選擇了DND、SIDD、PolyU 和CC 等公共數據集來設計實驗。本文選擇不使用NC12 數據集,是因為無法獲得來自NC12 的真實的干凈圖像。將4種傳統的降噪方法和16 種深度神經網絡去噪方法進行比較。表8 顯示了在DND 數據集和SIDD 數據集上不同去噪方法的PSNR(dB)和SSIM 值,加粗表示最優結果,下劃線表示次優結果。從表中可以看出深度學習去噪算法在DND 數據集和SIDD 數據集上要比傳統去噪算法有很大的優勢,在SIDD 數據集上GMSNet(grouped multi-scale network)去噪算法比傳統去噪(EPLL、BM3D、WNNM 和KSVD)的平均PSNR 增益最大更是達到14 dB 左右,相似度也高出了0.14 左右。在DND 數據集上GMSNet 系列也比傳統的去噪方法高出了約5 dB,在兩個數據集上與最近的深度學習算法相比GMSNet 系列算法同樣也具有很大的優勢。在DND 數據集和SIDD 數據集上的測試充分展現出了深度神經網絡在圖像去噪領域要比傳統去噪方法有更好的去噪性能。值得注意的是,盡管MIRNet 在SIDD 數據集上表現出色,但在DND 數據集上表現不佳。這種差異突出了減少訓練和圖像降噪測試之間的圖像域差距的重要性。表9顯示了在CC15、CC60 及PolyU 數據集上不同去噪方法的PSNR(dB)和SSIM 值,加粗表示最優結果,下劃線表示次優結果。可以看出傳統去噪方法CBM3D、MCWNNM(multi-channel weighted nuclear norm minimization)和NLH(non-local Haar)在三個數據集上相比于深度神經網絡算法DNCNN、FFDNet 和MIRNet展現出了非常有競爭力的性能,而深度神經網絡方法并不總是展示出優于傳統去噪器的優勢,這在很大程度上是由于缺乏訓練數據。
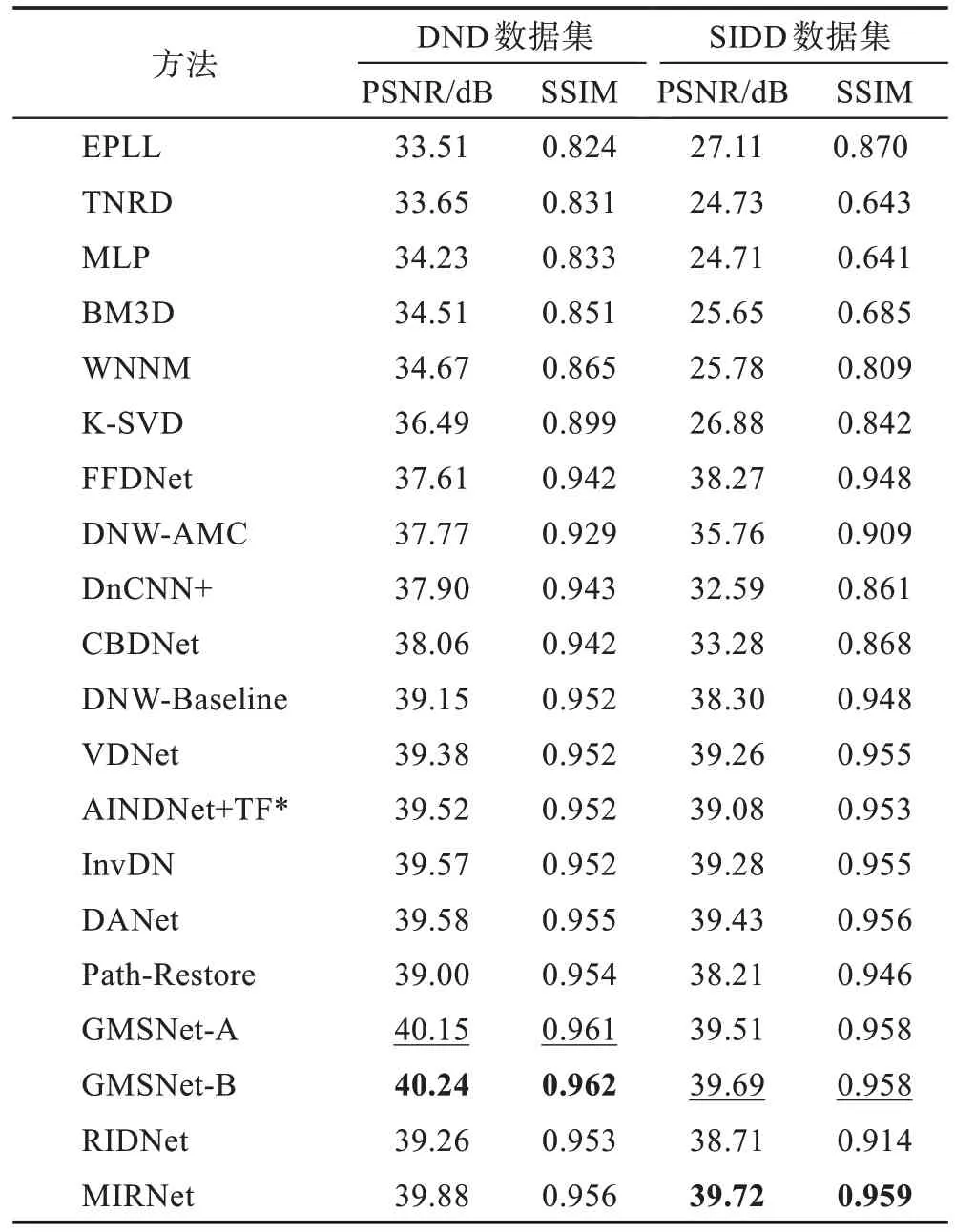
Table 8 PSNR and SSIM of different methods on two data sets表8 兩個數據集上不同方法的PSNR、SSIM
眾所周知,噪聲在現實世界中是復雜的,并且不受制于規則。這就是為什么開發盲降噪技術,尤其是深度學習技術。比較不同深度學習技術的降噪性能是非常有用的。選擇了在BSD68 數據集上用最新的去噪方法例如DnCNN、FFDNet、ADNet、SCNN(shrinkage convolutional neural network)和DudeNet(dual denoising Network)來設計實驗。如表10 所示,顯示了BSD68 數據集在不同噪聲水平下每種圖像去噪方法的PSNR(dB)值,加粗表示最優結果,下劃線表示次優結果,可以看出DudeNet的PSNR優于SCNN約0.3 dB,ADNet 在SCNN 上的增益約為0.2 dB,而FFDNet 也有與DnCNN 不弱的去噪性能。FFDNet、ADNet 和DudeNet 在盲去噪方面有不弱于其他去噪方法的性能。
用于混合噪聲圖像降噪的深度學習技術在現實世界中,損壞的圖像可能包含不同種類的噪聲,這使得恢復潛在的干凈圖像非常困難。為了解決這個問題,已提出了基于深度學習技術的多退化思想。在這里,本文介紹了多退化模型的降噪性能。如表11所示,顯示了在Set5、Set14、BSD100 和Urban100 數據集上不同方法在Bicubic 降采樣退化下的PSNR 和SSIM 結果比較。加粗表示最優結果,下劃線表示次優結果。SRMDNF 大大超過了SRCNN,相比DRRN(deep recursive residual network)和DnCNN-3 也 有0.1~0.4 dB 的增益。SRMDNF 無論是在小比例因子上還是在大比例因子上都取得了最佳的結果。
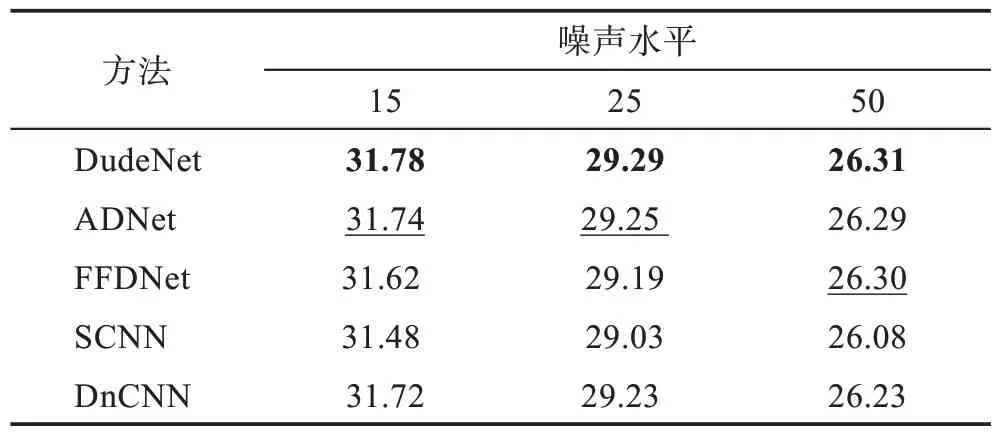
Table 10 Average PSNR of different methods on BSD68 data set表10 BSD68 數據集上不同方法的平均PSNR dB
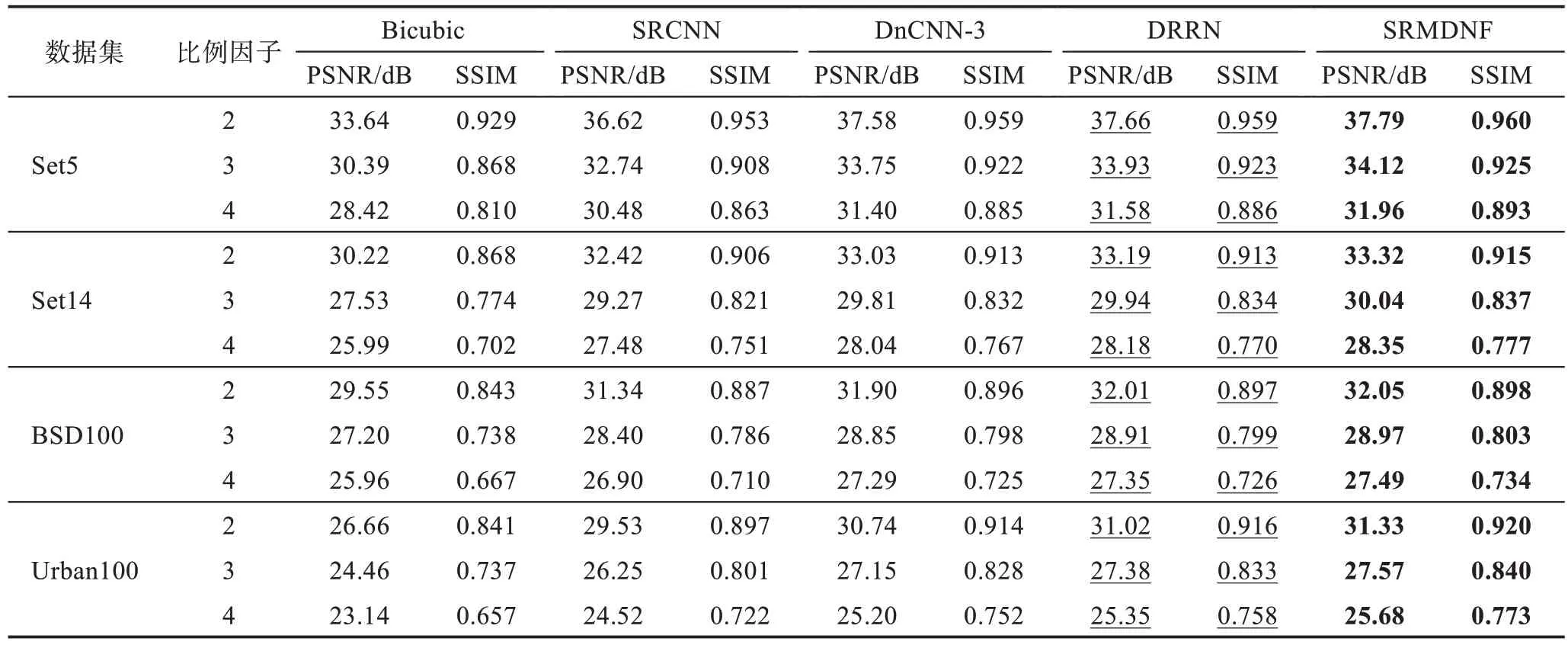
Table 11 PSNR and SSIM under Bicubic downsampling degradation表11 Bicubic降采樣退化下的PSNR、SSIM
4 結束語
近年來,圖像去噪已成為具有潛在重要應用的有吸引力的研究課題。BM3D 方法的巨大成功極大地推動了許多相關降噪方法的出現,從傳統的高斯去噪器到深度神經網絡方法不等。本文比較、研究和總結了用于圖像去噪的傳統方法以及深層神經網絡。首先,本文展示了用于圖像降噪的經典的傳統去噪的基本框架。然后,展示了用于圖像降噪的深度學習的基本框架并且介紹了用于有噪聲圖像降噪的深度學習技術,包括加性白噪聲、盲噪聲、真實噪聲和混合噪聲圖像降噪。接著比較了基準數據集上不同網絡的去噪結果。盡管深度學習技術在圖像去噪領域已經取得了巨大的成功,但最新的方法仍然存在一些局限性,將它們的應用限制在關鍵的實際場景中。最近,一種新趨勢集中在如何共同處理圖像去噪和其他計算機視覺任務[86]上,例如去霧[87]、去馬賽克[88]、超分辨率[89]和分類。收集真實的基準數據集來進一步探索它們之間的相互影響是一件非常有趣的事情。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
兒童故事畫報(2019年5期)2019-05-26 14:26:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
新聞傳播(2015年10期)2015-07-18 11:05:40
