基于DT 及PCA 的DNN 入侵檢測模型
2021-08-07 07:42:28武曉棟劉敬浩毛思平
計算機與生活 2021年8期
武曉棟,劉敬浩,金 杰,毛思平
天津大學 電氣自動化與信息工程學院,天津 300072
通信系統(tǒng)與網絡入口時時刻刻都面臨著來自于外部甚至于其系統(tǒng)內部的網絡攻擊,且不似網絡未成熟時期的單一攻擊,如今的絕大多數(shù)入侵行為種類多樣并且呈混合態(tài)勢發(fā)展,防御起來愈發(fā)困難。據(jù)相關文獻,雅虎數(shù)據(jù)泄露造成了3.5 億美元的損失,比特幣泄露導致了大約7 000 萬美元的損失[1]。基于入侵行為,入侵檢測可分為基于網絡的入侵檢測系統(tǒng)(network based intrusion detection system,NIDS)和基于主機的入侵檢測系統(tǒng)(host based intrusion detection system,HIDS)[2]。HIDS 通過查看在本地主機上生成的各種日志文件、磁盤資源信息以及系統(tǒng)信息等來檢測入侵行為,而NIDS 通過檢測出入本地的網絡數(shù)據(jù)流中的數(shù)據(jù)包來判斷是否有入侵行為。機器學習作為近幾年非常熱門的一種算法工具,理所應當?shù)挠袑<覍W者嘗試其在入侵檢測方面的應用[3]。尤其是近幾年,機器學習在入侵檢測方面的應用大范圍地出現(xiàn)在人們的視野中,從支持向量機(support vector machine,SVM)到神經網絡(neural networks,NN)再到隨機森林(random forest,RF)都有其在入侵檢測中的應用。
1 相關研究
機器學習在入侵檢測方面的應用早有先例。2003 年Kruegel 等人[4]將決策樹(decision tree,DT)應用到入侵檢測中去,相較于當時的Snort 檢測引擎[5]能夠實現(xiàn)更加迅速的檢測速度;2004 年陳光英等人提出了特征選擇與SVM 訓練模型的聯(lián)合優(yōu)化方法,并用入侵檢測數(shù)據(jù)集進行了實驗,結果證明聯(lián)合優(yōu)化方法能更好地提高SVM 性能,并且有更快的收斂速度,這是國內比較早的一篇利用了機器學習方法的入侵檢測相關文獻[6]。饒鮮等人基于支持向量機進行入侵檢測,對實時性問題進行了研究,但準確率較低[7]。2016 年,Ikram 等人提出利用主成分分析(principal component analysis,PCA)技術降維后用SVM 來檢測入侵,其新穎之處在于SVM 中應用了參數(shù)自優(yōu)化技術,提高了分類器的準確率并減少了訓練以及測試的時間[8]。2019 年,國內學者楊宏宇等人提出一種基于改進卷積神經網絡的入侵檢測模型[9],具有較高的入侵檢測準確率與真陽率,且誤報率較低。同年,F(xiàn)ernandez 等人提出利用前饋全連接深度神經網絡(deep neural networks,DNN)來訓練入侵檢測系統(tǒng)(intrusion detection system,IDS),由于DNN在動態(tài)IP地址分配的情況下表現(xiàn)出魯棒性,他們所提出的這個模型在現(xiàn)實中有更加廣泛的應用范圍[10]。仍然在2019 年,劉敬浩等人提出了一種基于ICA(independent component analysis)與DNN 的入侵檢測模型ICA-DNN[11],相較于一些淺層機器學習模型具有更好的特征學習能力和更精確的分類能力,但是對于算法的預測時間并未進行具體評估,模型實時性較差。綜合以上學者所提出的入侵檢測模型發(fā)現(xiàn)大多數(shù)研究對入侵檢測的實時性研究不夠重視,而少數(shù)對實時性有較深入研究的入侵檢測模型則存在檢測準確率不高的問題。為了深入研究對于入侵檢測十分重要的實時性問題并保證入侵檢測的準確率,本文提出DT-PCA-DNN 模型。訓練后的DT 實際上為一系列的if-else 語句,處理大批量數(shù)據(jù)速度極高,但處理精細度不足;DNN 網絡在處理大量高維度數(shù)據(jù)時的實時性較差,但精細度高。將二者結合,首先用DT 對數(shù)據(jù)進行一次預過濾再PCA 后送入DNN,實驗結果表明,該模型在保證了較高檢測率的同時大大提升了訓練以及檢測速度。
2 基礎理論
2.1 主成分分析
PCA 是十分常用的一種線性降維算法,一般用于將高維度的數(shù)據(jù)的主要成分提取后簡化為低維度數(shù)據(jù),但是數(shù)據(jù)的完整程度可以根據(jù)需求進行調整。具體而言,PCA 希望將原始的特征空間映射到另外一個正交空間內,而且希望可以使用一個滿足最近重構性及最大可分性的超平面來對數(shù)據(jù)集內所有的數(shù)據(jù)進行適當?shù)拿枋觥W罱貥嬓裕簲?shù)據(jù)集內的點到這個超平面的距離比較近。最大可分性:數(shù)據(jù)集上的不同點在這個超平面上的投影要盡量遠。如圖1(a)所示,二維平面上存在若干數(shù)據(jù),經由適當基變換(xy→ab),得到圖1(b)。在圖1(b)中,數(shù)據(jù)點在原基兩個維度的全部信息都包含于a軸,b軸的存在與否不影響數(shù)據(jù)完整性。由此,實現(xiàn)了二維數(shù)據(jù)到一維的降維。本次實驗所采用的數(shù)據(jù)集在預處理后維度值為122,經由PCA 降維至11 維,大幅度降低了數(shù)據(jù)維度間的相關性,簡化了計算的復雜性,提供了神經網絡所需要的低維數(shù)據(jù)源。
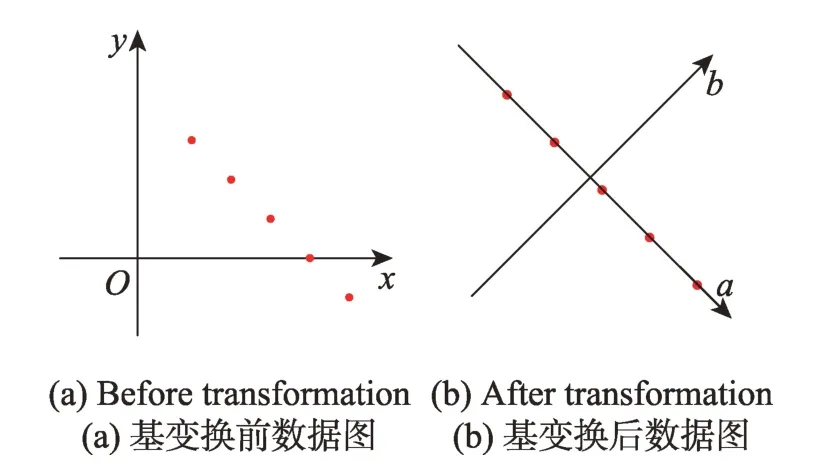
Fig.1 Diagram of data dimensionality reduction圖1 簡單數(shù)據(jù)降維示意圖
2.2 決策樹
決策樹模型是一種描述對實例進行分類的樹形結構,由節(jié)點(node)和有向邊(directed edge)組成,節(jié)點有兩種類型:表示一個特征或者屬性的內部節(jié)點(internal node),表示一個類的葉節(jié)點[12](leaf node)。決策樹由根節(jié)點開始不斷依據(jù)數(shù)據(jù)的特征進行分裂,直至所有數(shù)據(jù)到達葉子節(jié)點。作為分裂依據(jù)的屬性必須是離散屬性,對于連續(xù)屬性,可以按照實驗需求將其離散化。某售樓處想要根據(jù)對象的身份信息、年齡與是否已婚來判斷被調查對象是否有購房需求,調查結果如表1 所示。

Table 1 Respondent information and willingness表1 被調查對象信息意愿表
由此可生成對應決策樹如圖2,當有對象F 身份為公司職員,已婚,29 歲,可根據(jù)決策樹得知其有購房需求。
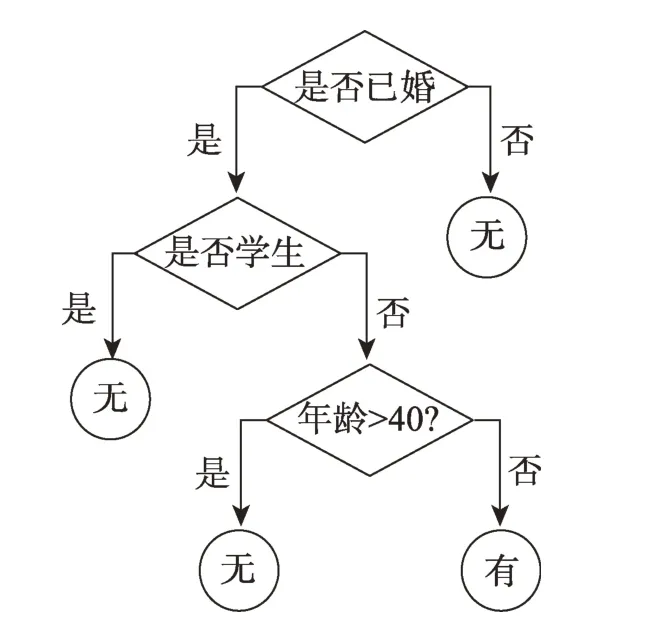
Fig.2 Decision chart of respondent圖2 對象決策圖
上例中調查對象的特征選擇順序不同,就可以生成不同的決策樹。依據(jù)選取不同分裂特征有三種判決依據(jù),分別為信息增益、增益率、基尼指數(shù)。ID3(iterative dichotomiser 3)算法的核心是在決策樹各個節(jié)點上應用信息增益準則選擇特征,C4.5算法用信息增益比來選擇特征,CART(classification and regression tree)則將基尼指數(shù)作為選擇特征的依據(jù)。關于決策樹剪枝以及具體特征選擇由于篇幅原因不予贅述,參考文獻[12]即可。
2.3 深度神經網絡
神經網絡是由具有適應性的簡單單元組成的廣泛并行互連的網絡,它的組織能夠模擬生物神經系統(tǒng)對真實世界物體所作出的交互反應[13],此處所說的神經網絡指的是機器學習與廣義上的神經網絡的交叉領域。神經網絡中最基礎的結構是神經元(neuron)模型,即定義中的簡單單元。生物神經網絡中,每個神經元與其他神經元相連,當其處于“興奮”狀態(tài)時,就會向相連的神經元發(fā)送神經遞質,從而改變這些神經元的電位。若某個神經元的電位超過了一個“閾值”(threshold),該神經元就會被激活,即處于“興奮”狀態(tài),向其相連的神經元發(fā)送神經遞質[14]。1943年,國外學者將上述情況抽象為圖3 所示的簡單模型,即一直沿用至今的“M-P 神經元模型”[15]。
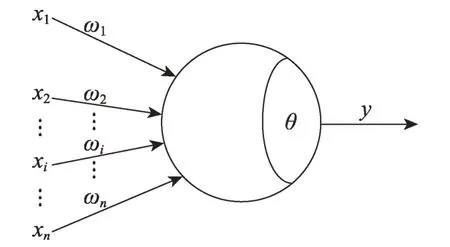
Fig.3 M-P neuron model圖3 M-P 神經元模型
在此模型中,xi為來自第i個神經元的輸入,ωi為第i個神經元的連接權重,θ為閾值,神經元接收到來自于n個其他神經元傳遞來的輸入信號,這些輸入信號通過帶權重的連接進行傳遞,神經元將接收得到的總輸入與θ進行比較,通過激活函數(shù)f(x)處理得到該神經元的輸出y如式(1):

常用的激活函數(shù)有sigmoid 函數(shù)、tanh 函數(shù)、ReLU 函數(shù)[16]。將多個神經元組合在一起即構成了神經網絡,擁有超過兩層及兩層以上隱藏層的神經網絡就是所提到的深度神經網絡,單純由輸入輸出層構成的神經網絡只能解決線性可分問題,隱藏層的引入是為了解決非線性可分問題。圖4 就是一個全連接的神經網絡,即前一層的任一神經元一定與其下一層的任一神經元相連。輸入層神經元僅僅是接受輸入,不進行函數(shù)處理,神經網絡的學習過程實質上就是不斷調整神經元之間的連接權重與神經元的閾值,從而不斷接近訓練樣本的輸出結果,其中最杰出的算法就是誤差逆?zhèn)鞑ィ╞ack propagation,BP)算法,現(xiàn)今大多數(shù)神經網絡的訓練都采用BP 算法。
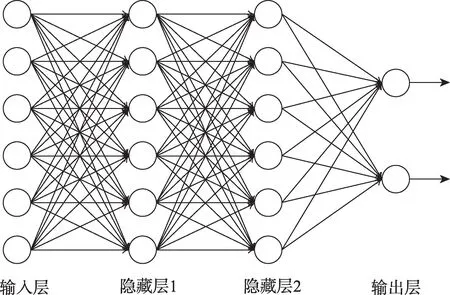
Fig.4 Double hidden layer fully connected DNN圖4 雙隱層全連接深度神經網絡
3 系統(tǒng)設計
系統(tǒng)整體設計如圖5 所示,第一步對整體數(shù)據(jù)集預處理。數(shù)據(jù)預處理首先將連續(xù)數(shù)據(jù)歸一化,其次對離散取值的數(shù)據(jù)進行one-hot 編碼。數(shù)據(jù)預處理后的數(shù)據(jù)集分為訓練數(shù)據(jù)集以及測試數(shù)據(jù)集,用預處理后的訓練數(shù)據(jù)集建立DT 同時訓練DNN。PCA 為無監(jiān)督學習,不需要進行訓練,在DT 以及DNN 訓練完成后,DT-PCA-DNN 模型建立。此時用經預處理的測試數(shù)據(jù)集對建立的入侵檢測模型進行測試并調整完善相關參數(shù)。訓練后的DT 實際上為一系列的if-else 語句,處理大批量數(shù)據(jù)速度極高,但處理精細度不足;DNN 網絡在處理大量高維度數(shù)據(jù)時的實時性較差,但精細度高;PCA 恰好可以解決數(shù)據(jù)維度過高帶來的問題。將三者結合,首先用DT 對數(shù)據(jù)進行一次預過濾再PCA 后送入DNN 二次分類,用DT 篩選出易判斷的入侵數(shù)據(jù)減輕DNN 工作量,PCA 解決DNN 網絡遇到高維數(shù)據(jù)訓練慢的問題,三種方法彌補了彼此的不足之處,在實時性較好的同時保證了檢測的準確率。
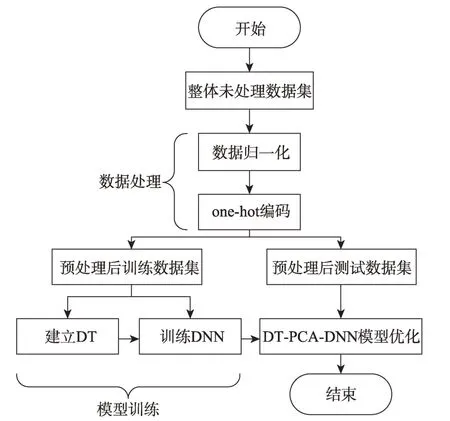
Fig.5 System flow chart圖5 系統(tǒng)流程圖
3.1 數(shù)據(jù)處理
對數(shù)據(jù)的處理應為兩部分,首先將連續(xù)數(shù)據(jù)歸一化,其次對離散取值的數(shù)據(jù)進行編碼。
3.1.1 數(shù)據(jù)歸一化
本文實驗歸一化處理采用min-max 標準化,該標準化方式是對原始數(shù)據(jù)進行線性變換,變換后數(shù)據(jù)落入[0,1]區(qū)間之內。所用變換函數(shù)如式(2):

設數(shù)據(jù)集中有m條數(shù)據(jù),每條數(shù)據(jù)都有n維特征,則式中x為歸一化前第i條數(shù)據(jù)的第j維特征值,min為歸一化前這m條數(shù)據(jù)第j維特征中的最小值,max為歸一化前這m條數(shù)據(jù)第j維特征中的最大值,x*為歸一化后第i條數(shù)據(jù)的第j維特征值。
3.1.2 one-hot編碼
獨熱編碼,又稱為一位有效編碼,用于離散數(shù)據(jù)編碼。采用N位狀態(tài)寄存器來對N個狀態(tài)進行編碼,每個狀態(tài)都有其獨立的寄存器位,且任何時間皆為一位有效。存在樣本集合如表2 所示。
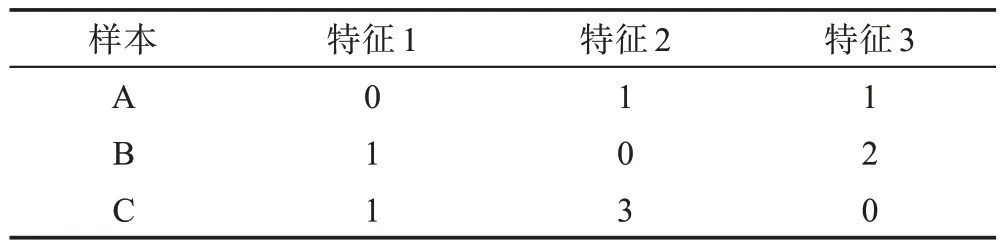
Table 2 Feature distribution of sample set表2 樣本集合特征分布表
表2 中的樣本特征維度為3,特征1 有兩種取值[0,1],特征2 有四種取值[0,1,2,3],特征3 有三種取值[0,1,2]。
特征1 有兩種取值,則編碼規(guī)則應為:
0→10
1→01
相應的特征2 有四種取值,則編碼規(guī)則應為:
0→1000
1→0100
2→0010
3→0001
特征3 的編碼規(guī)則同上,則不予贅述。
樣本A、B、C經過one-hot編碼后結果如表3所示。
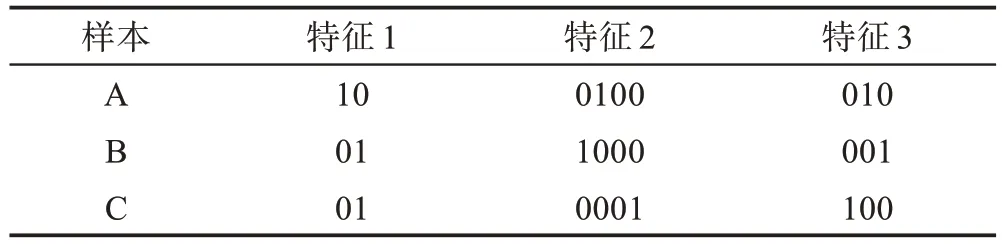
Table 3 One-hot encoded result of sample set表3 樣本集合one-hot編碼后結果表
3.2 模型訓練
3.2.1 建立DT
首先選擇所用決策樹類型,因ID3 算法所使用的信息增益對可取值數(shù)目較多的屬性有所偏好,且所用模型在實驗數(shù)據(jù)未降維之前就使用了DT,數(shù)據(jù)維度高,因此此處本文選用ID3 算法。其次是DT 的深度問題,由于DT 的作用并不是盡可能多地識別出入侵數(shù)據(jù),而是盡可能少地將正常數(shù)據(jù)誤判為入侵數(shù)據(jù),DT 的深度不宜過深。如果DT 的深度過深,第一次分類的準確率會有所提升,但是已經被判斷為入侵的但實際為正常的數(shù)據(jù)會影響最終的準確率。
3.2.2 訓練DNN
由于DNN 對高維數(shù)據(jù)進行處理需要比較大的隱藏層層數(shù),一旦隱藏層層數(shù)過低,欠擬合現(xiàn)象會十分嚴重。而隱藏層越多,訓練DNN 所耗時間呈指數(shù)式增長,與本文的實時性要求不符。引入PCA 對數(shù)據(jù)進行降維處理后降低了數(shù)據(jù)特征維度之間的相關性與數(shù)據(jù)冗余度,DNN 訓練更加迅速的同時保證了DNN 的準確率。
DNN 使用BP 算法進行訓練,使用ReLU 作為激活函數(shù)來簡化神經網絡的計算過程,使用占用資源少、模型收斂更快的adam 優(yōu)化算法縮短訓練時間。
3.3 DT-PCA-DNN 模型優(yōu)化
如圖6 所示,首先以訓練過后的DT 對預處理后的測試數(shù)據(jù)集初次分類,分類結果為入侵的數(shù)據(jù)判定為入侵并存入臨時訓練樣本,分類結果為正常的數(shù)據(jù)去除這次DT 分類所給的標簽,準備第二次判斷數(shù)據(jù)類型。DT 這一層相當于過濾網,將易于篩選的入侵數(shù)據(jù)篩選出來。由于訓練后的DT 實際上為一系列的if-else 語句,處理大批量數(shù)據(jù)速度極高,由此大大減輕了DNN 的工作量,提高了算法的運行速度。
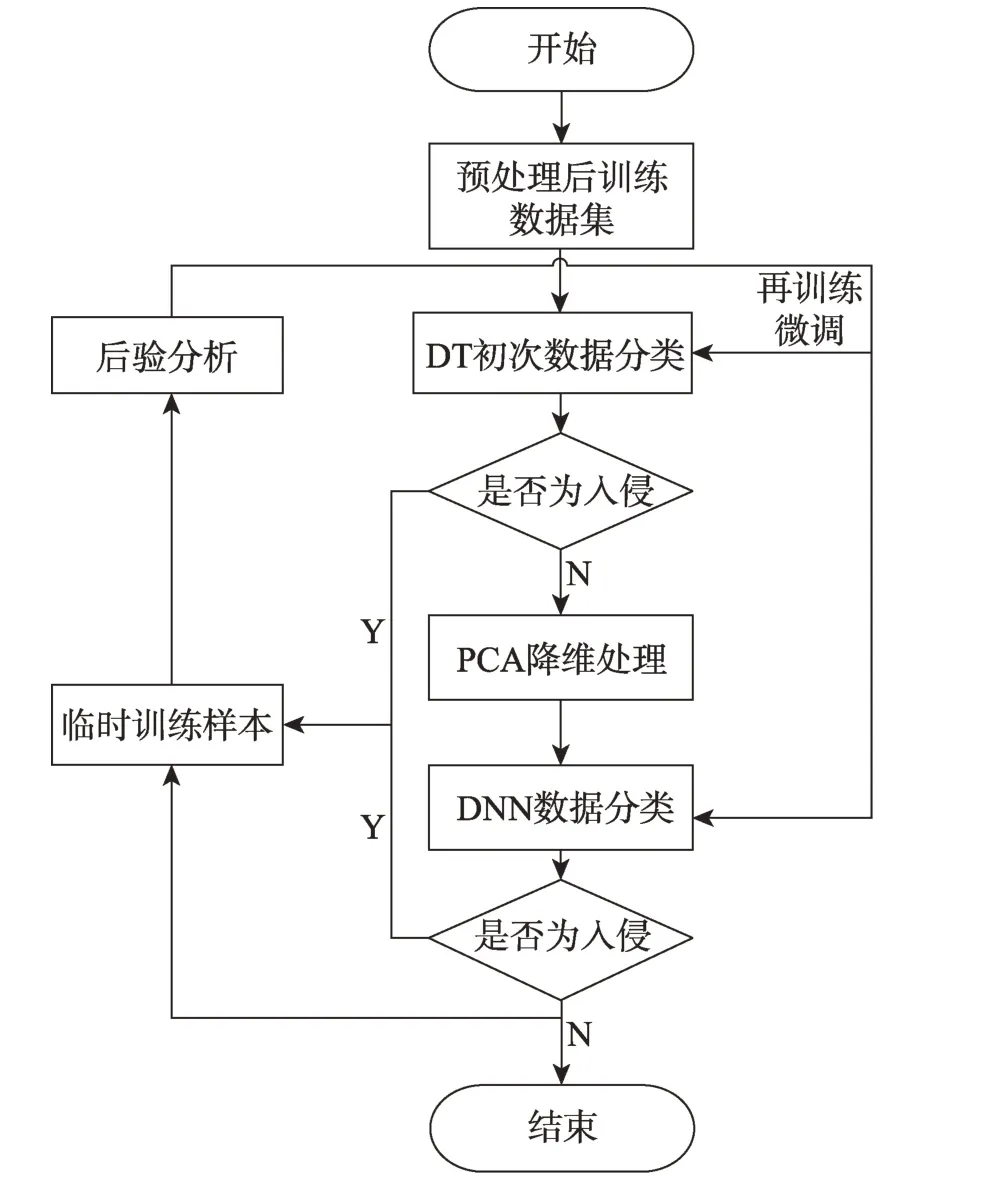
Fig.6 DT-PCA-DNN model optimization圖6 DT-PCA-DNN 模型優(yōu)化
第二步,對DT 判斷為正常但已去除標簽的數(shù)據(jù)進行PCA 降維處理。訓練后的DNN 對PCA 處理后所輸出的低維數(shù)據(jù)進行第二次分類,分類結果為入侵則添加入侵標簽后存入臨時訓練樣本,分類結果為正常則添加正常標簽后存入臨時訓練樣本。由于DT 與DNN 屬于監(jiān)督學習,在利用臨時訓練樣本集再訓練時需要用到所賦予數(shù)據(jù)的標簽。由于入侵檢測過程是逐條數(shù)據(jù)進行的,可在檢測過程中將測試數(shù)據(jù)集的原本數(shù)據(jù)類型與所對應數(shù)據(jù)所添加標簽的比對結果進行量化,量化值累積到設定閾值后利用剛才積累的數(shù)據(jù)對DT 以及DNN 做一次再訓練微調。經過若干次的微調之后,所設計模型達到最優(yōu)。
4 實驗仿真
4.1 數(shù)據(jù)集
本次實驗所用數(shù)據(jù)集為NSL-KDD[17]數(shù)據(jù)集,它是KDD 99 數(shù)據(jù)集的改進,相較于KDD 99 數(shù)據(jù)集,該數(shù)據(jù)集不包含冗余記錄,來自每個難度級別組的所選記錄的數(shù)量與原數(shù)據(jù)集內記錄的百分比成反比,對所建立模型的評估會更加有效[18]。NSL-KDD 數(shù)據(jù)集訓練集共有125 937條數(shù)據(jù),測試集共有數(shù)據(jù)22 544條,具體的數(shù)據(jù)類型如表4。
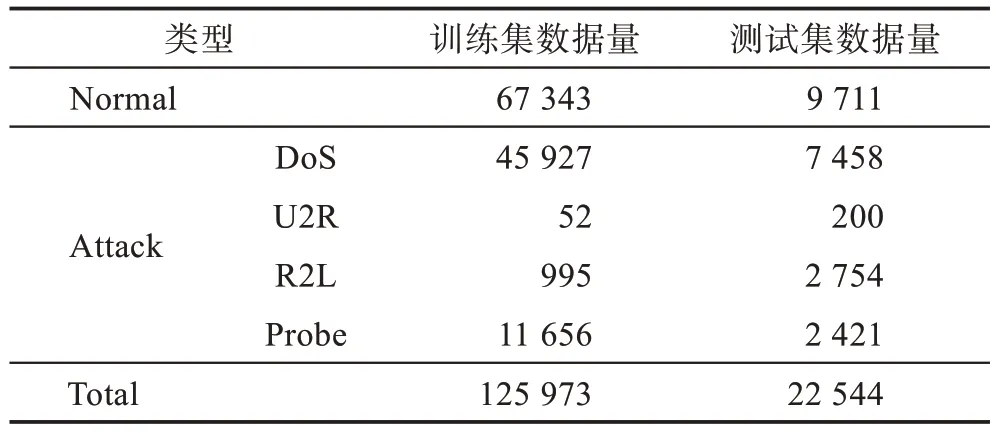
Table 4 Data distribution of NSL-KDD data set表4 NSL-KDD 數(shù)據(jù)集數(shù)據(jù)分布表
NSL-KDD 數(shù)據(jù)集有41 種特征,分為TCP 連接基本特征、主機上的操作特征、基于時間的網絡流量統(tǒng)計特征、基于主機的網絡流量統(tǒng)計特征這四大特征類;41 種特征的前三種為離散特征,分別為protocol_type(協(xié)議類型,共有三種:TCP、UDP、ICMP)、service(服務類型,訓練集有70個取值,測試集有64個取值,取二者大值)和flag(連接正常或錯誤的狀態(tài),共11個取值)。
對數(shù)據(jù)進行歸一化處理后進行one-hot 編碼。對protocol_type 編碼后數(shù)據(jù)維度上升至43,對service 編碼后數(shù)據(jù)維度由43 上升至112,對flag 編碼后數(shù)據(jù)維度由112 上升至122,最終NSL-KDD 數(shù)據(jù)集經過onehot編碼后的數(shù)據(jù)維度為122。
4.2 度量指標
首先列出混淆矩陣如表5 所示,TP表示真實數(shù)據(jù)類型為正常且模型預測結果仍為正常的數(shù)據(jù)條數(shù),TN表示真實數(shù)據(jù)類型為入侵且模型預測結果也為入侵的數(shù)據(jù)條數(shù),F(xiàn)P表示真實數(shù)據(jù)類型為入侵但模型預測結果為正常的數(shù)據(jù)條數(shù),F(xiàn)N表示真實數(shù)據(jù)類型為正常但模型預測結果為入侵的數(shù)據(jù)條數(shù)。當然,僅僅不同數(shù)據(jù)條數(shù)的大小是不足以作為評估實驗結果的標準的,因此在以上參數(shù)的基礎上建立了相對合理的評估標準,即準確率AC(accuracy)、檢測率DR(detection rate)、查準率PR(precision)、虛警率FAR(false alarm rate),各自定義分別如下:
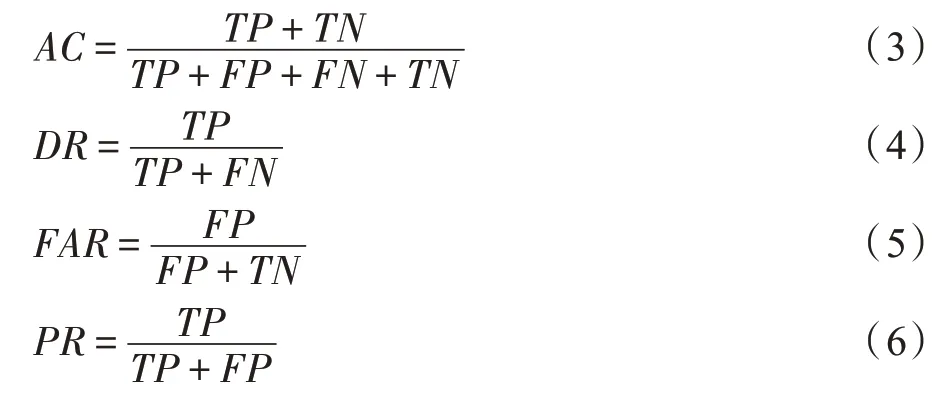
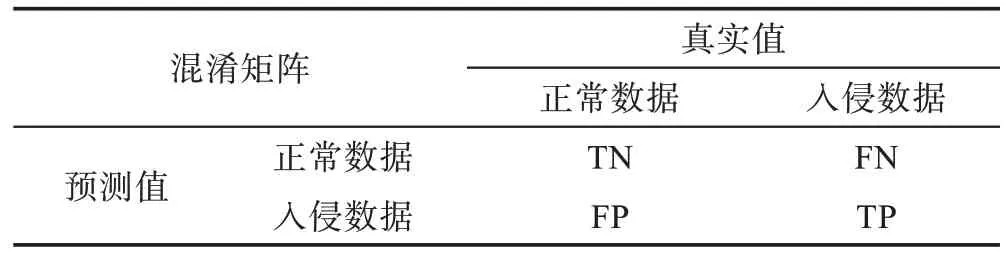
Table 5 Data confusion matrix表5 數(shù)據(jù)混淆矩陣
4.3 參數(shù)設置
對數(shù)據(jù)進行預處理后,包括one-hot 編碼與歸一化,所有數(shù)據(jù)值都位于區(qū)間[0,1],以0.5 為標準對數(shù)據(jù)各維度進行離散化后用DT 對所有訓練數(shù)據(jù)進行第一次篩選,所用DT 主要參數(shù)設置如表6 所示,之后進行PCA 降維,PCA 主要參數(shù)設置如表7 所示,降維后數(shù)據(jù)送入DNN,DNN 主要參數(shù)設置如表8 所示。因所設計系統(tǒng)為線性系統(tǒng),所有參數(shù)均可以通過固定其他參數(shù)求得該最優(yōu)參數(shù)的方法逐個得出。
criterion(屬性切分準則),值為字符串類型,有兩種標準可供選擇,分別為“gini”與“entropy”。splitter(切分點),值為字符串類型,有兩種標準可供選擇,分別為“best”與“random”,“best”意味著在所有特征中尋找最優(yōu)切分點,“random”意味著在隨機選擇的部分特征中尋找最優(yōu)切分點。max_depth(所構建決策樹的最大深度),可以是整數(shù)型或None。max_features為尋找最佳切分時所考慮的特征數(shù)。random_state(用以產生隨機數(shù)的多種狀態(tài)),其取值可以為整數(shù)型、RandomState 實例或None。經實驗證明,該值取392時達到最佳效果。

Table 7 PCA main parameters表7 PCA 主要參數(shù)

Table 8 DNN main parameters表8 DNN 主要參數(shù)
n_components(降維后的特征維度),可以為所降至維度數(shù)或者保留數(shù)據(jù)百分比;whiten(是否白化),使特征之間的相關性減低并且所有特征具有相同的方差;svd_solver(奇異值分解器),字符串,當其值為“auto”,且滿足一定條件時,調用完整的奇異值分解函數(shù)。
hidden_layer_sizes(隱藏層大小),元組類型。通過調整該值來確定隱藏層層數(shù)與隱藏層內的神經元個數(shù)。此處引入兩個隱藏層,第一層內有140 個神經元,第二層內有70 個神經元;activation 為激活函數(shù);solver(權重優(yōu)化函數(shù)),通過選擇不同字符串來選擇對應權重優(yōu)化函數(shù)。
4.4 實驗結果
實驗采用Windows10 系統(tǒng),64 位操作系統(tǒng),處理器版本為Intel?CoreTMi7-9750H CPU@2.60 GHz,物理內存總量16.0 GB,開發(fā)語言是Python3.5,所用軟件包為sklearn。
4.4.1 實驗1
本次實驗主要研究二分類檢測時間,即二分類下檢測的實時性問題。本次實驗主要對比了FC[19]、DT、PCA-DNN、EDF[20]、CNN[20]、DT-PCA-DNN 模型的二分類預測準確率以及訓練時間。為體現(xiàn)DTPCA-DNN 的特點,所用測試數(shù)據(jù)為NSL-KDD 測試數(shù)據(jù)集內所有數(shù)據(jù)。
為便于觀察,由表9 得出圖7,圖中因FC 訓練時間過長,對選取縱軸間隔影響過大,不予列出。
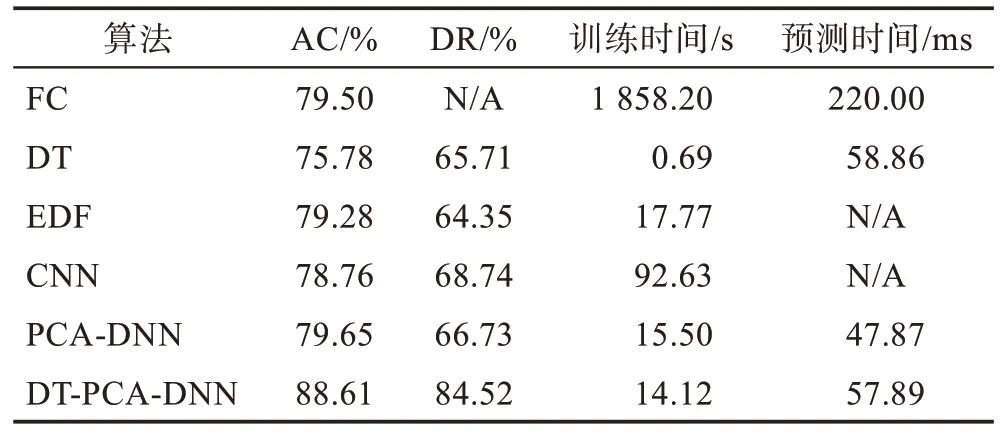
Table 9 Results of experiment 1表9 實驗1 結果
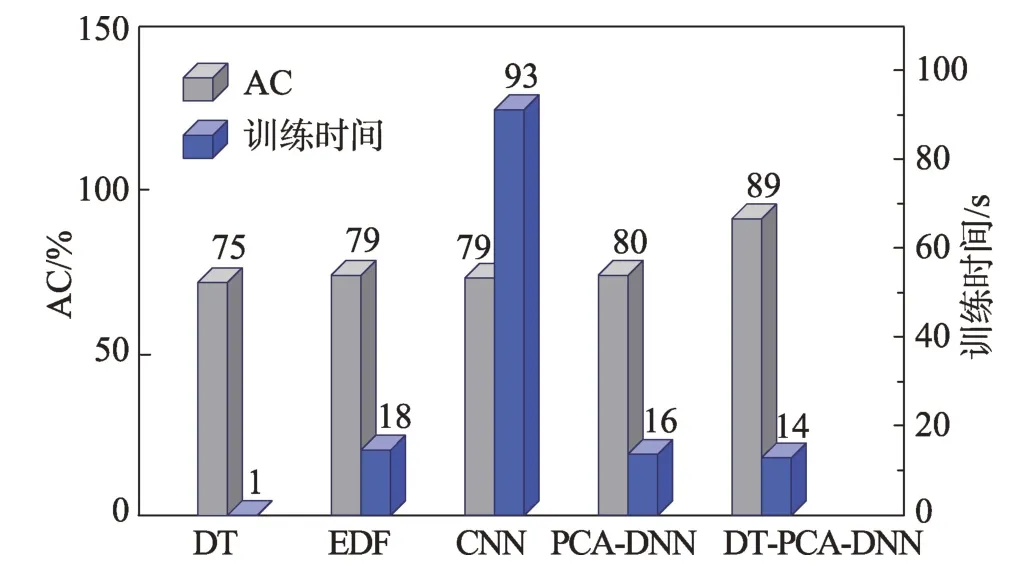
Fig.7 Results of experiment 1圖7 實驗1 結果
觀 察圖7 可 知:PCA-DNN 與FC 的準確率AC 基本相當,但是FC 訓練時間遠高于PCA-DNN,并且預測時間稍長,檢測實時性差。EDF 算法訓練時間稍長于PCA-DNN,且準確率AC 與PCA-DNN 基本持平;CNN 算法訓練時間長達90 s,準確率也稍低于EDF 以及PCA-DNN,劣于二者。DT 雖然訓練速度極快,但是準確率比EDF 以及PCA-DNN 都要低4 個百分點。
較不使用DT 的PCA-DNN,DT-PCA-DNN 訓練125 973 條數(shù)據(jù)多耗時1.32 s,預測22 544 條數(shù)據(jù)多耗時10 ms 左右,但是準確率AC 有將近10 個百分點的提升,效果十分顯著。DT 的引入對訓練時間及預測時間的影響極小,但是大大提升了預測的準確率。
4.4.2 實驗2
本次實驗主要研究DT-PCA-DNN 模型的五分類檢測時間,即五分類下的檢測實時性問題。將正常樣本標記為0,DoS 樣本標記為1,Probe 樣本標記為2,U2R 樣本標記為3,R2L 樣本標記為4。
分析表10 可知,DT-PCA-DNN 在五分類上的速度優(yōu)勢是十分明顯的,但總準確率稍遜色于EDF 以及CNN,而作為對比的DT 與PCA-DNN,雖然訓練時間短,但是相對的總準確率較低,性能不佳。在五分類實驗中將PCA-DNN 以及DT-PCA-DNN 進行比較,訓練時間長3 s,準確率有6 個百分點的提升,證明DT的引入在保證準確率的同時也并沒有造成多大的時間損失。
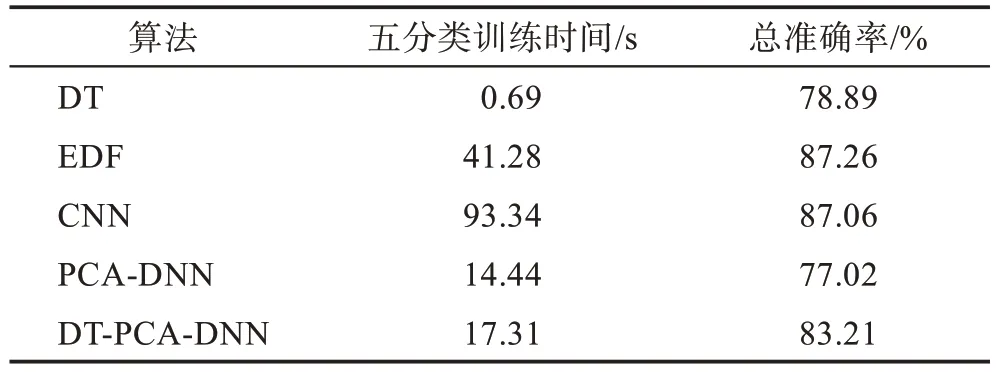
Table 10 Total results of experiment 2表10 實驗2 總結果
分析表11 可知,DT-PCA-DNN 在DT 預篩選時可能處理掉了一部分數(shù)據(jù)導致U2R 無結果顯示(U2R 樣本量小)。DT-PCA-DNN 的優(yōu)勢主要體現(xiàn)在對R2L 的識別能力上,但因其數(shù)據(jù)集中占比小,所以導致整體準確率低于EDF 以及CNN,同時該模型對Normal 數(shù)據(jù)在檢測率比較高的情況下虛警率也比較高,這是一個需要指出的問題。
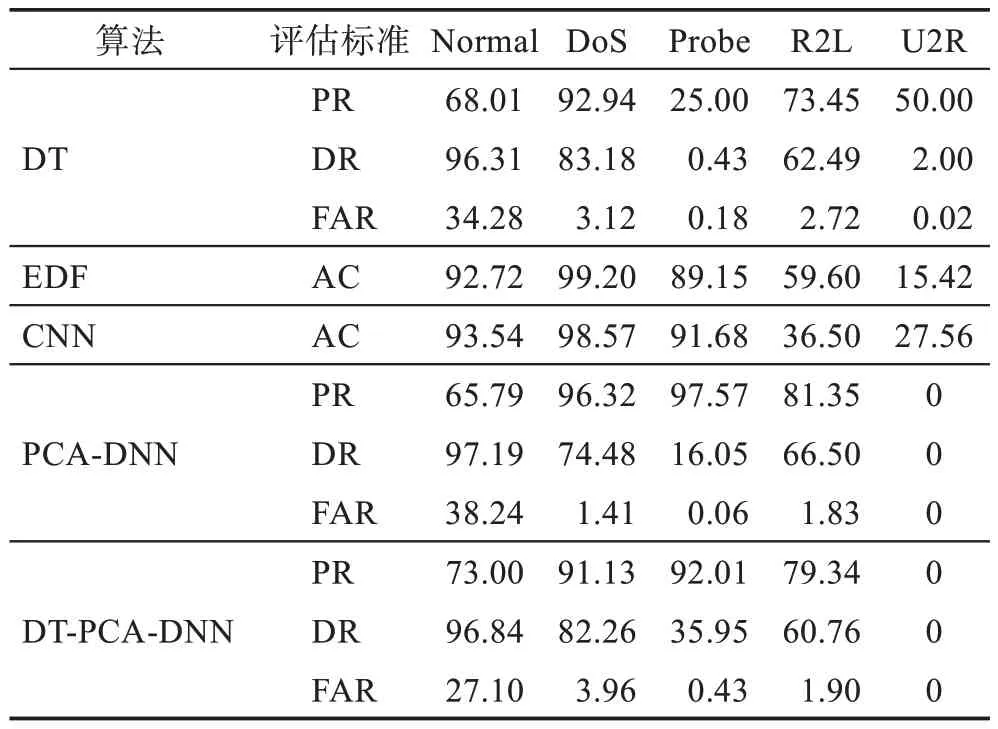
Table 11 Five classification results of experiment 2表11 實驗2 五分類結果 %
5 結束語
本文所提出的基于深度學習方法的入侵檢測模型DT-PCA-DNN 在保證準確率的基礎上大大提高了訓練以及檢測的速度。模型利用DT 對預處理完畢待檢測數(shù)據(jù)初步篩選再PCA 降維后作為輸入由DNN進行二次判決。引入DT 后訓練時間增加幅度小,但準確率有了很大提升,同時DT 預篩選減輕了后續(xù)DNN 的工作量,對整體訓練速度有一定的提升作用。下一步的研究方向主要是解決DT-PCA-DNN 模型在五分類實驗中對Normal 數(shù)據(jù)虛警率高的問題,同時提高DT-PCA-DNN 的五分類能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
