融入改進的K-means聚類的協(xié)同過濾算法的研究與應用
2021-08-17 13:54:07劉鑫
軟件 2021年3期

摘 要:本文通過對K-means聚類算法和協(xié)同過濾推薦算法的學習研究。針對基于用戶的協(xié)同過濾算法的不足,將改進的K-means聚類算法融入其中,設(shè)計了基于K-means聚類算法的個性化推薦算法,并將其應用于旅游景點及線路的個性化推薦中,以提高個性化推薦質(zhì)量。實驗結(jié)果表明,基于改進的K-means聚類的協(xié)同過濾算法緩解了初始數(shù)據(jù)的稀疏性問題,針對不同用戶喜愛的旅游景點及線路推薦,在準確率和召回率兩個方面證明可以提高個性化推薦的準確度。
關(guān)鍵詞:K-means聚類;協(xié)同過濾算法;最小生成樹
中圖分類號:TP183 文獻標識碼:A DOI:10.3969/j.issn.1003-6970.2021.03.027
本文著錄格式:劉鑫.融入改進的K-means聚類的協(xié)同過濾算法的研究與應用[J].軟件,2021,42(03):097-099
Research and Application of Collaborative Filtering Algorithm Incorporating Improved K-means Clustering
LIU Xin
(Jilin Institute of Architecture and Technology, Changchun? Jilin? 130114)
【Abstract】:This article is based on the study of K-means clustering algorithm and collaborative filtering recommendation algorithm. Aiming at the deficiencies of the user-based collaborative filtering algorithm, the improved K-means clustering algorithm is incorporated into it, and a personalized recommendation algorithm based on the K-means clustering algorithm is designed and applied to the personalized recommendation of tourist attractions and routes In order to improve the quality of personalized recommendations. The experimental results show that the collaborative filtering algorithm based on improved K-means clustering alleviates the sparsity problem of the initial data. It is proved that it can improve the personalization in terms of accuracy and recall rate for different users' favorite tourist attractions and routes recommendation. Recommended accuracy.
【Key words】: K-means clustering;collaborative filtering algorithm;minimum spanning tree
0引言
隨著互聯(lián)網(wǎng)的飛速發(fā)展,信息資源呈現(xiàn)幾何級數(shù)增長,用戶在大量的信息中很難獲取到真正需要的數(shù)據(jù)信息。傳統(tǒng)的搜索引擎已無法滿足用戶的特殊需求,因此個性化推薦系統(tǒng)應運而生,并成為了解決信息過載問題的有效方法。一個完整的個性化推薦系統(tǒng)總體框架包含三個部分:數(shù)據(jù)特征提取模塊、個性化推薦模塊、推薦結(jié)果模塊。個性化推薦系統(tǒng)能夠根據(jù)用戶個人喜好自動進行信息推薦,減少信息的冗余,簡化用戶的操作,因此個性化推薦算法也逐漸成為學術(shù)界的研究熱點之一[1]。
1主要技術(shù)
1.1協(xié)同過濾算法及其存在的問題
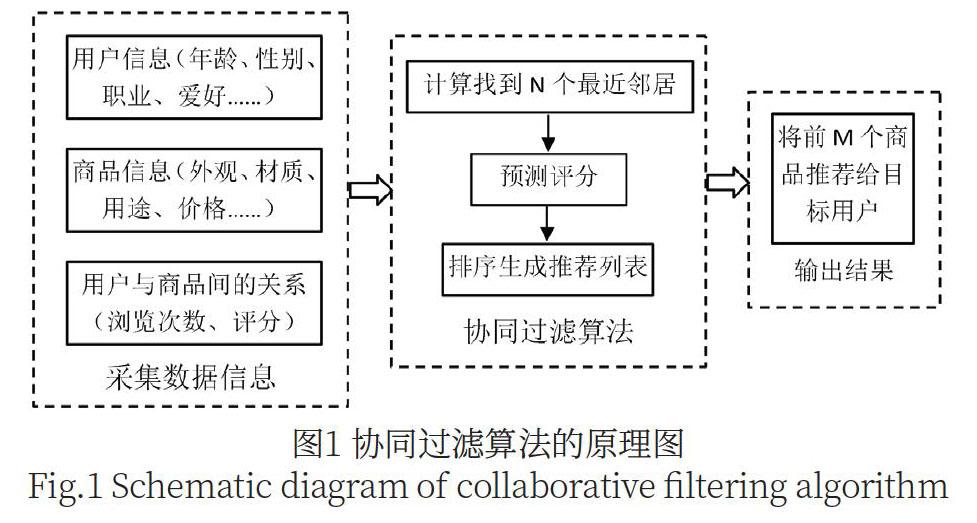
推薦系統(tǒng)中協(xié)同過濾推薦算法是當前應用最為廣泛,研究最多,影響最為深遠的個性化推薦技術(shù),協(xié)同過濾推薦算法的主要思想是:為了更好的服務目標用戶,為用戶推薦個性化的商品信息,需要獲得用戶的喜好,即在一個大的數(shù)據(jù)庫中使用相似度計算公式計算搜索目標用戶的N個最近鄰居,根據(jù)N個用戶對商品喜好的評分,建立評分矩陣,并預測目標用戶所喜好的商品的評分,進行降序排序,將評分最高的前M個商品推薦給目標用戶。協(xié)同過濾算法的原理圖如圖1所示。首先進行算法的輸入,即數(shù)據(jù)信息的采集,包括用戶的基本信息、商品的基本信息及用戶與商品間的關(guān)系信息,然后進行協(xié)同過濾算法處理,即相似度計算,找到N個最近鄰居,最后得到輸出結(jié)果,即將前M個商品推薦給目標用戶。協(xié)同過濾算法依據(jù)初始評分矩陣,因此存在著數(shù)據(jù)稀疏性問題,會導致推薦準確性不高[2]。
1.2 K-means 算法
K-means算法是James MacQueen在1967年提出的,K-means算法是一種基于最近距離劃分進行聚類的算法,算法根據(jù)目標函數(shù)求得最近距離計算相似度,是數(shù)據(jù)挖掘研究領(lǐng)域中最常用的算法之一。K-means的基本思想是首先在預定的樣本集中隨機選取K個質(zhì)心作為初始聚類中心,構(gòu)成K個簇集,然后計算剩下樣本和 K 個初始聚類中心的距離即相似度,將各個樣本分別劃分給離他最近也就是相似度的值最大的一個簇集中,每次劃分后,再根據(jù)現(xiàn)有簇集重新計算獲得新的聚類中心。不斷循環(huán)這個過程,直到聚類中心不再變化或者函數(shù)滿足了收斂條件[3]。
K-means算法進行聚類操作,算法原理簡單,易于操作,基于大數(shù)據(jù)集合進行聚類的運算速度快、效率高。但由于K-means算法中初始的聚類中心是由隨機選取方式選定,因此,在聚類過程中初始聚類中心的不確定性會影響推薦結(jié)果的準確性。本文提出改進的K-means聚類算法。
2 改進的K-means算法
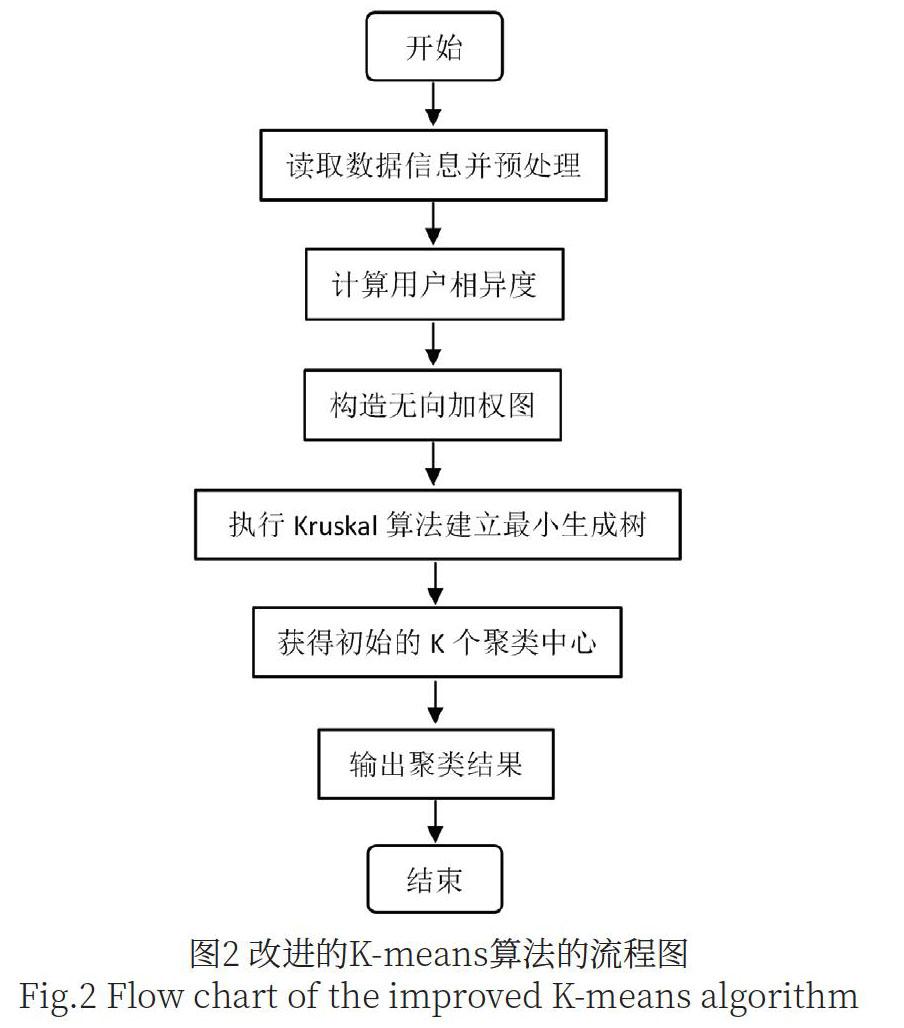
針對K-means算法由于初始聚類中心不確定帶來的影響,增加了用戶的屬性描述,并基于用戶屬性計算用戶相異度的值,作為邊的權(quán)值建立圖結(jié)構(gòu),應用kruskal算法計算生成初始聚類中心,將其用于K-means算法中,該算法可以提高初始聚類中心的個數(shù)和位置的準確性,提高推薦系統(tǒng)的推薦效率[4]。改進的K-means算法的具體步驟如下:
(1)初始用戶信息,對系統(tǒng)中用戶基本信息進行預處理,增加用戶屬性描述(性別、年齡、學歷、職業(yè)、興趣愛好)使用公式1.1計算用戶間的相異度值C(不同用戶相同屬性的相異值的個數(shù)P(ui≠uj)與用戶屬性總個數(shù)P(ui,uj)的比值),規(guī)定相異度值越小則用戶間的相似度越大。
公式1.1
(2)根據(jù)公式1.1計算用戶相異度值;
(3)將用戶相異度值C作為邊的權(quán)值,構(gòu)造無向加權(quán)圖G=({V},{E});
(4)應用Kruskal算法求出圖G的最小生成樹T= (U,TE),步驟如下:
1)初始化:U=V;TE={ };
2)將邊集E按照從小到大進行排序,依次在E集合中尋找最短邊(u,v)
3)如果頂點u,v位于T的兩個不同的連通分量,則將邊(u,v)加入到最小生成樹的邊集合TE中,頂點u,v 加入到頂點集合U中;
4)循環(huán)執(zhí)行第③步,直到最小生成樹T中的連通分量個數(shù)為1結(jié)束;
(5)在建立的最小生成樹中選擇權(quán)值最大的N個WeightMax和權(quán)值最小的N個WeightMin,求出它們的平均值,在最小生成樹中刪除大于平均值的邊及孤立的頂點,將剩余頂點作為k個用戶集合,然后計算得到k個分類的集合中心,即構(gòu)成了初始的k個聚類中心。
(6)執(zhí)行K-means聚類算法,通過余弦相似度計算公式,完成聚類劃分。改進的K-means算法的流程圖如圖2所示。
3融入改進的K-means聚類的協(xié)同過濾算法在旅游景點及線路個性化推薦系統(tǒng)中的應用
本文將融入改進的K-means聚類的協(xié)同過濾算法在旅游景點及線路個性化推薦系統(tǒng)中,通過用戶數(shù)據(jù)及評分矩陣,建立相似用戶集,完成旅游景點及線路的個性化推薦[5]。
第一步,數(shù)據(jù)預處理,初始化用戶特征屬性信息、各景點游覽路線信息及用戶對已游覽過的景點評分信息,建立初始評分矩陣Aij;
第二步,根據(jù)初始評分矩陣Aij,運用kruskal算法獲得個數(shù)及分布均勻的初始C個聚類中心;再執(zhí)行改進的K-means 算法完成對用戶的聚類劃分,形成不同的相似用戶簇集;
第三步,對于目標用戶u,首先根據(jù)余弦相似度計算公式計算其與新生成的聚類中心的相似度,選擇相似度最大的簇集Cu,將目標用戶劃分到此簇集中;在簇集內(nèi)查找目標用戶的K個最近鄰居;
第四步,根據(jù)預測評分算法及目標用戶的K個最近鄰居,對目標用戶中未評分的景點項目進行預測評分,將評分由高到低排序,并將前Top N個線路進行推薦。
系統(tǒng)測試產(chǎn)生的推薦結(jié)果表明:融入改進的K-means聚類的協(xié)同過濾算法提高了推薦質(zhì)量,針對不同用戶的喜好提高了個性化推薦的準確率。
4總結(jié)
本文首先針對K-means聚類算法隨機選取初始聚類中心,導致聚類效果不佳的問題,將最小生成樹Kruskal算法應用在K-means聚類算法中,設(shè)計了改進的K- means聚類算法,并將其融入到協(xié)同過濾算法中,應用于旅游景點及線路個性化推薦系統(tǒng)中,同時在建立系統(tǒng)的評分矩陣時,引入了旅游用戶、景點信息及用戶對線路的特征屬性等信息,解決了協(xié)同過濾算法在初始數(shù)據(jù)上的稀疏性問題,提高推薦算法的準確率。
參考文獻
[1] 劉榮權(quán),袁仕芳.基于用戶屬性聚類與矩陣填充的景點推薦算法[J].計算機技術(shù)與發(fā)展,2020(11):206-210.
[2] 顧明星,黃偉建.結(jié)合用戶聚類與改進用戶相似性的協(xié)同過濾推薦[J].計算機工程與應用,2020(9):185-189.
[3] 常亮,曹玉婷.旅游推薦系統(tǒng)研究綜述[J].計算機科學,2017 (10):1-6.
[4] 劉鑫.改進的協(xié)同過濾算法在商品推薦中的應用[J].電子技術(shù)與軟件工程,2020(2):220-222.
[5] 李俊.基于聚類的推薦算法研究與應用[D].南京:南京郵電大學,2018.
