基于泛在物聯(lián)網(wǎng)和機(jī)器學(xué)習(xí)算法的資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)
2021-08-20 10:28:46章怡
電子設(shè)計(jì)工程 2021年16期
關(guān)鍵詞:模型
章怡
(上海電子信息職業(yè)技術(shù)學(xué)院,上海 201411)
泛在物聯(lián)網(wǎng)是泛在電力物聯(lián)網(wǎng)的擴(kuò)展,主要指其他行業(yè)的智能化物聯(lián)網(wǎng)應(yīng)用[1-2],包括高等學(xué)校在內(nèi)的各類企事業(yè)單位。其作為市場主體在經(jīng)營、生產(chǎn)過程中,通過各個(gè)環(huán)節(jié)的聯(lián)機(jī)、交互,可以實(shí)時(shí)掌握生產(chǎn)、運(yùn)行狀態(tài)并及時(shí)進(jìn)行優(yōu)化調(diào)整[3];另一方面,也能及時(shí)發(fā)現(xiàn)在生產(chǎn)、管理過程中的潛在漏洞,防患于未然[4-5]。
隨著我國經(jīng)濟(jì)進(jìn)入新常態(tài)的階段,市場經(jīng)濟(jì)充滿了不確定性,資產(chǎn)的穩(wěn)定性影響著各類市場主體的良好發(fā)展。因此,構(gòu)建合理、有效的資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)尤為必要[6]。
針對以上現(xiàn)象,文中將泛在物聯(lián)網(wǎng)與機(jī)器學(xué)習(xí)相結(jié)合,開展了資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)的研究。通過采集泛在物聯(lián)網(wǎng)中各個(gè)互聯(lián)設(shè)備與監(jiān)控系統(tǒng)的實(shí)時(shí)數(shù)據(jù),作為分析資產(chǎn)狀態(tài)的樣本數(shù)據(jù)。然后,利用機(jī)器學(xué)習(xí)中的BP 神經(jīng)網(wǎng)絡(luò)與決策樹算法對樣本數(shù)據(jù)進(jìn)行特征提取與資產(chǎn)狀態(tài)分類,從而構(gòu)建資產(chǎn)異常狀態(tài)預(yù)警模型。然后使用Bagging 對資產(chǎn)異常狀態(tài)預(yù)警模型進(jìn)行優(yōu)化,最終得到準(zhǔn)確的數(shù)據(jù)結(jié)果。
1 資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)
通過人工識別統(tǒng)計(jì)資產(chǎn)存在效率低、信息滯后與不能監(jiān)測資產(chǎn)狀態(tài)等問題,需要采用現(xiàn)代化的人工智能技術(shù)以有效提高資產(chǎn)管理效率[7]。文中基于泛在物聯(lián)網(wǎng)與機(jī)器學(xué)習(xí)技術(shù)設(shè)計(jì)了資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng),具體框圖如圖1 所示。

圖1 資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)結(jié)構(gòu)框架
泛在物聯(lián)網(wǎng)可以將各個(gè)資產(chǎn)設(shè)備連接起來,通過傳感器實(shí)時(shí)采集各個(gè)設(shè)備工作狀態(tài)下的數(shù)據(jù)[8]。這些數(shù)據(jù)作為分析資產(chǎn)狀態(tài)的原始數(shù)據(jù),經(jīng)過預(yù)處理后被輸入至基于機(jī)器學(xué)習(xí)算法的模型中,進(jìn)行特征提取與模型訓(xùn)練。最終,可得到能夠識別資產(chǎn)狀態(tài)等級的模型。
1.1 資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)結(jié)構(gòu)
根據(jù)上文對資產(chǎn)狀態(tài)識別系統(tǒng)的分析,整個(gè)系統(tǒng)采用B/S 系統(tǒng)架構(gòu)。該系統(tǒng)架構(gòu)中的瀏覽器,可以滿足用戶在任何地點(diǎn)使用Internet 進(jìn)行業(yè)務(wù)查詢與數(shù)據(jù)整理;而服務(wù)器可滿足相關(guān)功能數(shù)據(jù)、程序的存儲(chǔ)與運(yùn)行[9]。
1.2 資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)設(shè)計(jì)框架
輔助用戶進(jìn)行資產(chǎn)管理,及時(shí)發(fā)現(xiàn)異常資產(chǎn)狀態(tài)并預(yù)警是文中所述系統(tǒng)的設(shè)計(jì)目標(biāo)。在進(jìn)行系統(tǒng)框架設(shè)計(jì)時(shí),應(yīng)以目標(biāo)為核心,預(yù)警方法、預(yù)警指標(biāo)為設(shè)計(jì)基礎(chǔ)。通過設(shè)置合理的預(yù)警指標(biāo)閾值來衡量資產(chǎn)各個(gè)狀態(tài),具體設(shè)計(jì)框架如圖2 所示。
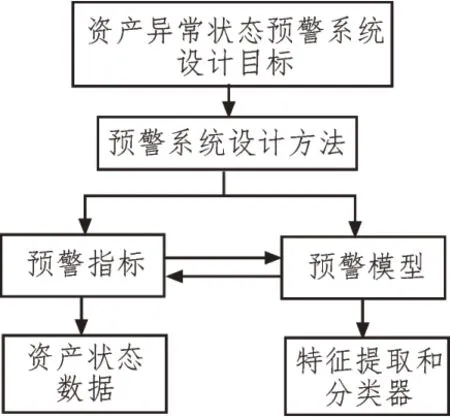
圖2 資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)設(shè)計(jì)框架
2 檢測算法
2.1 資產(chǎn)預(yù)警指標(biāo)
資產(chǎn)狀態(tài)的優(yōu)劣直接影響著用戶的生存和發(fā)展。通過泛在物聯(lián)網(wǎng)實(shí)時(shí)采集用戶日常業(yè)務(wù)運(yùn)行的數(shù)據(jù),可對資產(chǎn)風(fēng)險(xiǎn)進(jìn)行預(yù)估,進(jìn)而達(dá)到預(yù)警的效果。由此可見,對資產(chǎn)風(fēng)險(xiǎn)預(yù)估所采用的風(fēng)險(xiǎn)指標(biāo)選擇起到了關(guān)鍵作用。文中將風(fēng)險(xiǎn)指標(biāo)分為4 類:運(yùn)營能力、償債能力、盈利能力以及發(fā)展?jié)摿Γ唧w如圖3 所示[10-12]。其中,總資產(chǎn)轉(zhuǎn)換率被定義為該季度營業(yè)凈利潤占總資產(chǎn)的百分比;存貨周轉(zhuǎn)率被定義為營收額與平均庫存余額的比值;資產(chǎn)負(fù)債率被定義為總負(fù)債額與總資產(chǎn)額的比值;流動(dòng)率被定義為短期內(nèi)可使用金額與總資產(chǎn)的比值;總資產(chǎn)收益率被定義為某段時(shí)間內(nèi)營收凈利潤占總資產(chǎn)的比例;生產(chǎn)利潤率被定義為營收凈利潤占營收額的比例;總資產(chǎn)增長率被定義為今年資產(chǎn)總增長率與去年的比值;融資能力被定義為該用戶的綜合信用水平。

圖3 資產(chǎn)風(fēng)險(xiǎn)指標(biāo)體系
由于泛在物聯(lián)網(wǎng)得到的數(shù)據(jù)并不能直接用于資產(chǎn)異常狀態(tài)的分析,需要進(jìn)行標(biāo)準(zhǔn)化、聚類與排除等數(shù)據(jù)預(yù)處理。其中,文中使用Z-score標(biāo)準(zhǔn)化,具體為:

式中,x為原始數(shù)據(jù),s、a分別為各項(xiàng)指標(biāo)數(shù)據(jù)的標(biāo)準(zhǔn)差與平均值,X為經(jīng)過標(biāo)準(zhǔn)化后的數(shù)據(jù)。
2.2 資產(chǎn)異常狀態(tài)預(yù)警模型
BP 神經(jīng)網(wǎng)絡(luò)的全稱為誤差反向傳播神經(jīng)網(wǎng)絡(luò),其主要特征為誤差的傳播方向與正常計(jì)算方向相反。BP 神經(jīng)網(wǎng)絡(luò)為至少三層的多層神經(jīng)網(wǎng)絡(luò),每一層含有數(shù)量不同的神經(jīng)元。同層之間的神經(jīng)元相互獨(dú)立,相鄰層之間的神經(jīng)元以全連接的方式進(jìn)行數(shù)據(jù)的傳遞。假設(shè)神經(jīng)網(wǎng)絡(luò)的輸入為xi,則BP 神經(jīng)網(wǎng)絡(luò)的激活函數(shù)表達(dá)式如式(2)所示。

其中,wikj被定義為第i層第j個(gè)神經(jīng)元到第i+1層第k個(gè)神經(jīng)元的連接權(quán)重;而aik被定義為第i層第j個(gè)神經(jīng)元的輸出。神經(jīng)元j的誤差能量函數(shù)被定義為下式:
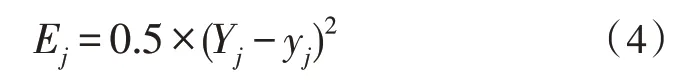
其中,Yj為神經(jīng)元j的期望輸出,yj為神經(jīng)元j的實(shí)際輸出。
在BP 神經(jīng)網(wǎng)絡(luò)中有兩種方式可降低整個(gè)神經(jīng)網(wǎng)絡(luò)的誤差,一種方式為增加隱藏層的數(shù)量;另一種方式為增加單層隱藏層神經(jīng)元的數(shù)量。兩種方式所消耗的訓(xùn)練時(shí)間及降低誤差的大小對比結(jié)果,如圖4所示。由圖可知,隨著隱藏層層數(shù)的增加,模型訓(xùn)練時(shí)間顯著增加;單層神經(jīng)元個(gè)數(shù)的增加也會(huì)使訓(xùn)練時(shí)間增加,且會(huì)逐漸趨于定值。而圖5 中,隱藏層層數(shù)與單層神經(jīng)元個(gè)數(shù)的增加均會(huì)使誤差降低。值得注意的是,雖然隱藏層層數(shù)可顯著降低誤差,但在相同神經(jīng)元個(gè)數(shù)時(shí),無論神經(jīng)元個(gè)數(shù)多少,高層數(shù)的模型訓(xùn)練時(shí)間均比低隱藏層層數(shù)的模型大。

圖4 隱藏層神經(jīng)元個(gè)數(shù)和隱藏層層數(shù)對訓(xùn)練時(shí)間的影響
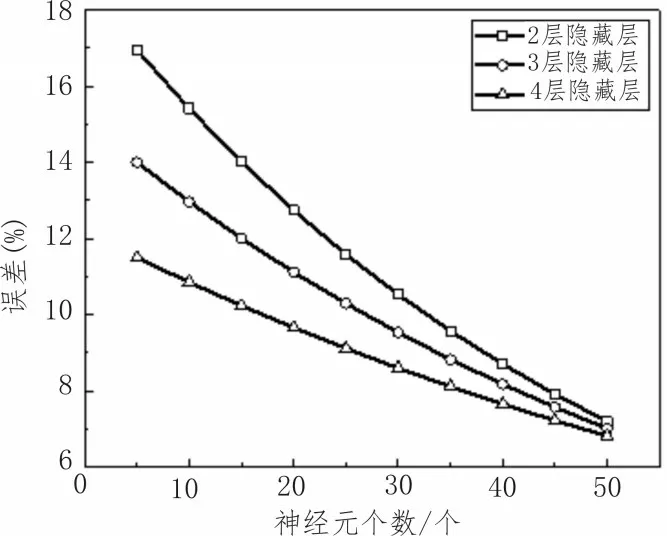
圖5 隱藏層神經(jīng)元個(gè)數(shù)和隱藏層層數(shù)對誤差的影響
BP 神經(jīng)網(wǎng)絡(luò)的使用雖然降低了誤差,但其分類識別能力相對較低。為了加強(qiáng)資產(chǎn)狀態(tài)分類的識別精度,從而實(shí)現(xiàn)精準(zhǔn)預(yù)警,文中將決策樹與BP 神經(jīng)網(wǎng)絡(luò)相結(jié)合。決策樹是一種樹形的結(jié)構(gòu),在該結(jié)構(gòu)中每一個(gè)內(nèi)部節(jié)點(diǎn)代表一個(gè)分類屬性的判斷。由該節(jié)點(diǎn)引出的分支代表判斷結(jié)果,最終形成的每一個(gè)葉節(jié)點(diǎn)均表示分類的結(jié)果[13-16]。文中使用基尼指數(shù)進(jìn)行分類屬性的選取與劃分,具體過程如下:
1)計(jì)算樣本數(shù)據(jù)集S的純度,表達(dá)式如下:

2)計(jì)算各個(gè)屬性的Gini指數(shù),表達(dá)式如下:

3)選擇所有Gini_index(S,q)中的最小值作為該節(jié)點(diǎn)劃分時(shí)的最佳屬性。
當(dāng)不修剪決策樹的枝條時(shí),BP 神經(jīng)網(wǎng)絡(luò)模型容易受到樣本數(shù)據(jù)的干擾,出現(xiàn)識別精準(zhǔn)度下降的現(xiàn)象。為了提高BP 神經(jīng)網(wǎng)絡(luò)模型的識別精準(zhǔn)度,文中使用Bagging 算法對BP 神經(jīng)網(wǎng)絡(luò)模型進(jìn)行優(yōu)化。具體過程如下:
1)從輸入數(shù)據(jù)中隨機(jī)抽取k次含有n個(gè)數(shù)據(jù)的訓(xùn)練樣本,從而得到k個(gè)數(shù)據(jù)集;
2)對這k個(gè)數(shù)據(jù)集分別輸入至BP 神經(jīng)網(wǎng)絡(luò)模型中進(jìn)行訓(xùn)練;
3)通過投票表決的方式生成資產(chǎn)狀態(tài)的識別結(jié)果。
至此,文中所述的資產(chǎn)異常狀態(tài)識別預(yù)警模型的結(jié)構(gòu),如圖6 所示。一共分為4 個(gè)部分:輸入層、隱藏層、分類層與輸出層。經(jīng)過數(shù)據(jù)預(yù)處理的樣本數(shù)據(jù)被輸入至隱藏層進(jìn)行特征提取,并在分類層進(jìn)行資產(chǎn)狀態(tài)的識別和在輸出層進(jìn)行結(jié)果輸出與風(fēng)險(xiǎn)預(yù)警。文中將資產(chǎn)狀態(tài)分為3 種類別:無風(fēng)險(xiǎn)D1、低風(fēng)險(xiǎn)D2 與高風(fēng)險(xiǎn)D3。
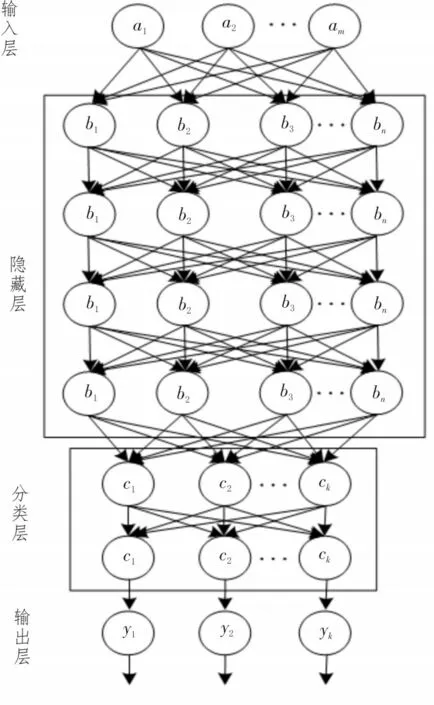
圖6 含有BP神經(jīng)網(wǎng)絡(luò)和決策樹算法資產(chǎn)異常狀態(tài)預(yù)警模型示意圖
3 測試與驗(yàn)證
通過調(diào)用某用戶的泛在物聯(lián)網(wǎng)平臺(tái)數(shù)據(jù),得到了用于資產(chǎn)異常狀態(tài)識別模型訓(xùn)練的原始數(shù)據(jù)。該數(shù)據(jù)為2014-2019 年4 個(gè)季度相關(guān)指標(biāo)的數(shù)據(jù),文中采用Modeler 18.1 作為BP 神經(jīng)網(wǎng)絡(luò)模型的創(chuàng)建平臺(tái)。綜合上文的分析,文中采用4 層隱藏層,每個(gè)隱藏層均有50 個(gè)神經(jīng)元來構(gòu)建資產(chǎn)異常狀態(tài)分析模型。設(shè)定訓(xùn)練周期為100 次,決策樹中CART 樹深度為5,并使用Bagging 算法進(jìn)行模型優(yōu)化。表1 為該公司4 個(gè)季度的部分指標(biāo)數(shù)據(jù)。分別將以上數(shù)據(jù)進(jìn)行Z-score 標(biāo)準(zhǔn)化,并利用聚類法將指標(biāo)進(jìn)行分類。為了確定各個(gè)指標(biāo)對資產(chǎn)狀態(tài)判斷結(jié)果影響的大小,分別對各個(gè)指標(biāo)進(jìn)行因子分析。考慮到各指標(biāo)的初始數(shù)值差距較小,需要使用方差最大正交旋轉(zhuǎn)法將數(shù)據(jù)特征放大。由于決策樹中樹的數(shù)量會(huì)影響到整個(gè)模型對資產(chǎn)狀態(tài)的識別精度與計(jì)算速度,有必要合理選擇決策樹的數(shù)量。圖7 展示了決策樹數(shù)量對資產(chǎn)狀態(tài)識別精度的影響。綜合考慮識別精度與模型運(yùn)算速度,文中將決策樹數(shù)量定為70 個(gè),整體識別精度為81.3%[17]。
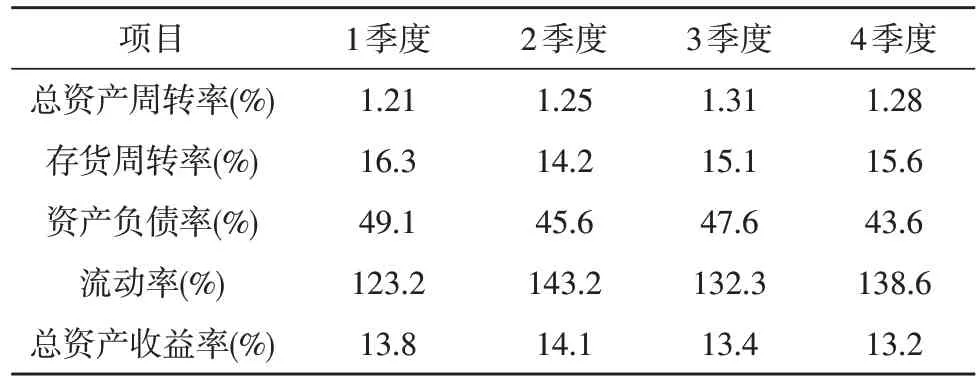
表1 某公司4個(gè)季度的部分指標(biāo)數(shù)據(jù)

圖7 決策樹數(shù)量對資產(chǎn)狀態(tài)識別精度影響
為了驗(yàn)證文中所述方案的有效性,設(shè)置對照組進(jìn)行對比。對照組使用BP 神經(jīng)網(wǎng)絡(luò)與Softmax 分類器,來進(jìn)行資產(chǎn)狀態(tài)識別預(yù)警模型的構(gòu)建。實(shí)驗(yàn)組與對照組使用相同的樣本數(shù)據(jù)和軟硬件配置,實(shí)驗(yàn)結(jié)果如圖8 所示。由圖可知,文中所述實(shí)驗(yàn)組的識別精準(zhǔn)度均比對照組高,平均識別精準(zhǔn)度為80.1%,可為用戶提供有效的資產(chǎn)風(fēng)險(xiǎn)預(yù)警。

圖8 實(shí)驗(yàn)組與對照組對資產(chǎn)狀態(tài)識別精度影響
4 結(jié)束語
文中基于泛在物聯(lián)網(wǎng)與機(jī)器學(xué)習(xí)技術(shù),設(shè)計(jì)了資產(chǎn)異常狀態(tài)預(yù)警系統(tǒng)。根據(jù)現(xiàn)階段所面臨的資產(chǎn)風(fēng)險(xiǎn)現(xiàn)狀,文中從系統(tǒng)框架出發(fā),采用B/S 系統(tǒng)結(jié)構(gòu)滿足多場地、實(shí)時(shí)登入功能。利用泛在物聯(lián)網(wǎng)平臺(tái)收集用戶生產(chǎn)、運(yùn)營的各項(xiàng)數(shù)據(jù),作為分析資產(chǎn)狀態(tài)的樣本數(shù)據(jù),再利用機(jī)器學(xué)習(xí)中的BP 神經(jīng)網(wǎng)絡(luò)與決策樹算法對樣本數(shù)據(jù)進(jìn)行特征提取和資產(chǎn)狀態(tài)分類,從而構(gòu)建資產(chǎn)異常狀態(tài)預(yù)警模型。最終,采用Bagging 對資產(chǎn)異常狀態(tài)預(yù)警模型進(jìn)行優(yōu)化。經(jīng)測試,文中所提出的算法有較高的準(zhǔn)確率,證明了該方案的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
