基于大數據集成技術的畢業生就業去向跟蹤系統研究
2021-08-20 10:29:00李一楊
電子設計工程 2021年16期
關鍵詞:系統
李一楊
(西安醫學院,陜西 西安 710021)
高校人才培養質量可通過畢業生就業率和就業質量體現,畢業生就業去向跟蹤是高校就業部門的重要工作[1]。學生畢業后崗位變動頻繁,高校與畢業生漸漸失去聯系,加大了畢業生就業去向跟蹤的難度。大數據技術是目前信息時代中應用廣泛的重要技術,人類生活、生產等各項活動趨于智能化,業務活動數據不斷提升[2],使大數據技術成為研究學者們的主要研究方向。大數據技術不斷發展,造成大量的數據孤島現象[3],數據集成技術是解決數據孤島現象的重要技術。
數據集成技術指將眾多具有不同格式、不同來源、不同性質的數據在物理層面或邏輯層面有機結合于統一數據集的技術[4]。目前,已有眾多成熟理論應用于大數據集成技術中,大數據集成技術可為數據共享提供技術支持。文獻[5]基于機器學習算法進行了大學生畢業去向預測;文獻[6]研究大數據背景下研究生就業精準服務體系的探索與實踐,以上兩種方法均針對畢業生就業去向進行研究,并取得一定成效。
將大數據集成技術應用于畢業生就業去向跟蹤中,提升畢業生就業去向跟蹤效率[7]。文中設計了大數據集成技術的畢業生就業去向跟蹤系統,利用大數據集成技術將所采集的不同來源、不同格式的畢業生就業去向數據高效集成,提升數據處理性能。畢業生可隨時登錄系統,在就業信息存在變化時實時更改信息,高校就業部門教師利用系統查詢學生就業信息,系統設定固定時間提醒學生更新就業去向狀態,使高校畢業生畢業后仍與學校保持良好聯系,為畢業生信息跟蹤與分析提供平臺。
1 畢業生就業去向跟蹤系統設計
1.1 系統總體結構
畢業生就業去向跟蹤系統具有信息數據量大、對客戶端與服務器端訪問速度要求高以及交互頻繁的特點,選取ASP.net AJAX 引擎的B/S 架構分層設計畢業生就業去向跟蹤系統,采用該架構設計系統業務邏輯層與用戶界面為分離狀態[8],使系統各程序耦合度有所降低。充分考慮高校對畢業生就業去向跟蹤需求,設計大數據集成技術的畢業生就業去向跟蹤系統總體結構圖,如圖1 所示。
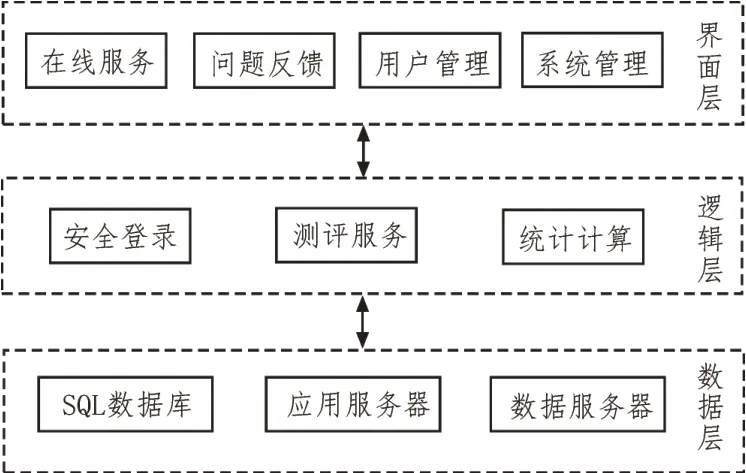
圖1 系統總體結構圖
由系統總體結構圖可知,所設計系統包括數據層、邏輯層以及界面層三部分。
數據層包括應用服務器、數據服務器以及SQL數據庫,為系統提供數據支持。系統的數據層采用大數據集成技術,提升系統的數據處理性能。
邏輯層采用模糊C 均值算法對完成集成的數據實施聚類等挖掘算法,通過聚類結果統計畢業生就業去向[9]。邏輯層完成畢業生就業去向跟蹤處理后,將處理結果發送至界面層。
界面層具有在線服務、問題反饋、用戶管理以及系統管理等功能,高校就業部門教師以及高校畢業生等用戶通過界面層登錄系統,登錄后運行系統各項應用實現人機交互。
1.2 系統功能結構
所設計的畢業生就業去向跟蹤系統采用大數據集成技術,可針對海量大數據高效集成[10],使所設計系統具有較高的畢業生就業去向跟蹤性能。系統功能結構圖如圖2 所示。由圖2 可以看出,系統主要用戶為高校畢業生、系統管理員以及高校就業部門教師。高校畢業生登錄系統后可更新個人以及就業相關信息,參與畢業生就業去向跟蹤問卷調查并查看問卷。系統管理員登錄系統后可管理高校畢業生信息,并為系統用戶賦予權限;系統管理員可對問卷調查相關內容實施數據導入、數據導出以及數據備份等調查統計功能[11];系統管理員具有設計調查問卷、更新調查問卷、修改調查問卷內容并管理問卷調查完成情況,針對不同用戶分配不同調查問卷等功能。高校就業部門教師登錄系統后可管理本校畢業生就業信息、查看畢業生調查問卷等權限,通過畢業生相關信息及調查問卷結果明確畢業生就業去向。
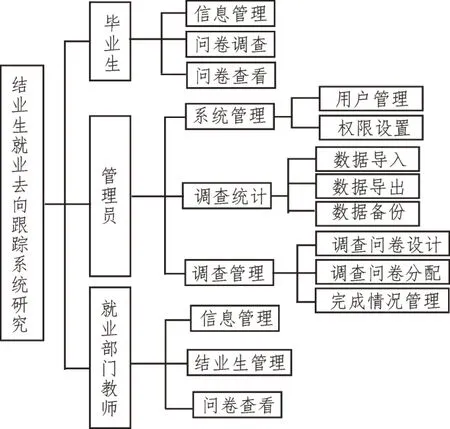
圖2 系統功能結構圖
1.3 大數據集成技術
大數據集成技術需時刻運行集成任務,系統用戶可觀測大數據集成過程中的運行任務,用戶可暫停或更改任務優先級。大數據集成技術集成運行過程如圖3 所示。
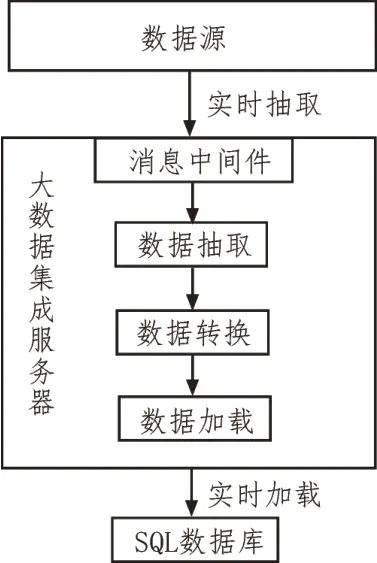
圖3 大數據集成技術運行過程
大數據集成技術的集成運行過程主要包括數據抽取、數據轉換以及數據加載三部分,完成大數據集成處理的數據存儲于系統SQL 數據庫內,便于系統跟蹤畢業生就業去向。
1)數據抽取。將數據源內存在變更行為的數據進行抽取,為數據集成做準備的過程稱為變更數據實時抽取,簡稱數據抽取[12]。畢業生就業去向跟蹤系統內變更數據抽取的實時性決定了數據的實時轉換以及加載性能,數據抽取為系統內大數據實時集成提供數據支持。
2)數據加載。將已完成抽取的集成數據發送至數據倉庫內,以滿足畢業生就業去向跟蹤系統決策查詢和實時數據檢索需求。數據加載過程需要依據固定順序執行SQL 語句分析系統所分配的任務,更新實時數據過程容易造成分析結果不一致問題[13]。解決數據倉庫數據實時更新和系統應用層聯機分析查詢之間的沖突是數據集成需要重點考慮的問題[14]。選取歷史數據與高實時性數據、一般實時性數據分開存儲的方式實現集成數據實時加載,提升數據實時加載性能。將實時性較高的數據發送于實時數據緩存區域,將歷史數據和實時性一般的數據發送至數據倉庫內。由于僅存在少量更新的實時數據于實時數據緩存區域內,因此數據實時更新與實時加載于實時數據緩存區域內極為方便,可提升數據實時處理和自動分析效率;對不具有實時性的歷史數據依據設置規則批量發送至數據倉庫,避免數據倉庫內物理設計由于頻繁更新而出現故障。
3)數據轉換。大數據集成技術中并發轉換任務調度區別于以往人為設置的直接執行、定時執行以及周期性執行等執行方式[15]。大數據集成技術依據數據源內的數據變化執行數據集成任務,可使多個轉換任務同時觸發,需高效的任務調度策略,利用并發執行任務提升大數據集成技術內服務器的運行性能,提升系統數據集成效率。
1.4 模糊C均值算法
將完成大數據集成處理的數據庫內數據利用模糊C 均值算法實現畢業生就業去向跟蹤系統的數據挖掘與統計,模糊C 均值算法是通過目標函數實施聚類分析的高效算法。該算法利用存在約束條件的優化問題代替聚類轉化問題,通過優化問題求解獲取模糊聚類結果。設向量集合為xi=(i=1,2,…,n),n表示向量數量,采用聚類算法將向量劃分為c個模糊組,將各組之間的非相似性指標作為目標函數,使各模糊組與聚類中心之間的距離最小。利用模糊劃分思想使特定數據對象隸屬于不同組,且隸屬程度通過(0,1)區間的值體現,采用全部數據對象隸屬于各組的值構建隸屬度矩陣U,對于隨機數據,隸屬度之和為1,那么可得:

通過以上步驟可知,模糊C 均值聚類算法為逐步迭代求解過程,其具體流程為:
1)將隸屬度矩陣依據隨機數方法初始化,完成初始化的隸屬度矩陣需符合式(1)要求;
2)利用式(4)獲取聚類中心數量c;
3)利用式(2)判斷目標函數與上次目標函數改變范圍是否小于指定閾值以及算法是否超過所設置循環次數,通過以上兩部分判斷算法是否收斂,算法收斂表明算法結束;算法未收斂需進行下一步;
4)通過式(5)獲取新隸屬度矩陣U,并返回步驟2),直至算法完全收斂為止。
由以上步驟可以看出,模糊C 均值算法的初始聚類中心決定了算法聚類效果。
算法的聚類數量c以及加權指數m兩個輸入參數同樣決定算法收斂效果,算法聚類數量應大于1且明顯低于數據樣本總數量。
算法加權指數是決定聚類結構模糊程度控制算法的權重指數,算法加權指數過大與過小都將造成算法聚類效果差。算法加權指數宜選取[1.5,2.5]范圍內的數,文中選取算法加權指數為2。
模糊C 均值算法的輸出結果是隸屬度矩陣以及聚類中心,各數據樣本點針對不同類別的隸屬程度可通過隸屬度矩陣體現[16],不同對象所屬的類可依據最大隸屬原則以及隸屬度矩陣獲取。針對符合正態分布的數據,模糊C 均值算法具有較好的聚類效果,符合畢業生就業去向跟蹤系統需求。
2 系統測試
為檢測所設計系統跟蹤畢業生就業去向的有效性,選取某地某高校畢業生作為實驗對象。利用所設計系統統計該校于2018 年畢業的本科、碩士、博士畢業生就業去向,該校于2018 屆畢業的畢業生包括15 個學院(65 個專業)共7 590 名。采用所設計系統統計該校2018 年畢業生就業分布城市、就業去向、不同就業方式、就業行業分布情況、就業單位分布情況如圖4~8 所示。

圖4 畢業生就業分布城市
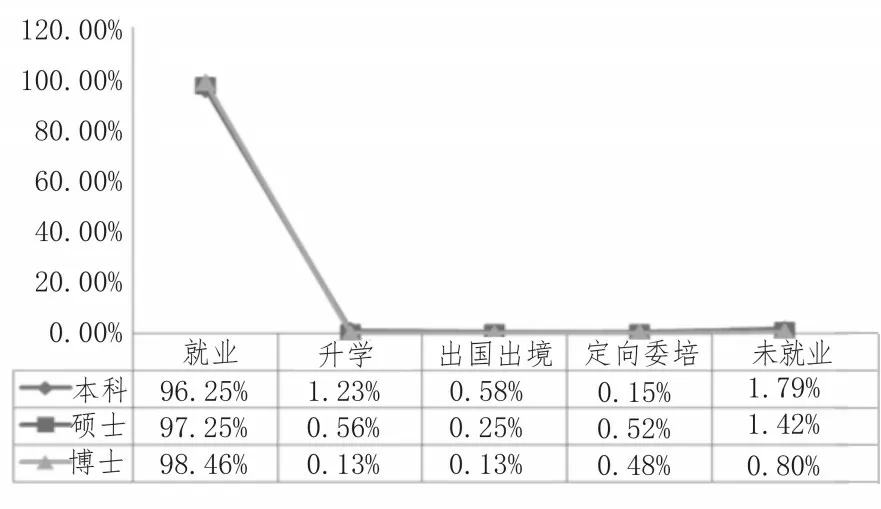
圖5 畢業生畢業后去向
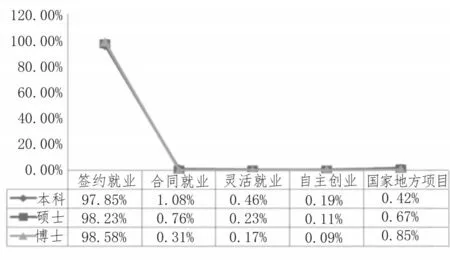
圖6 不同就業方式所占比例
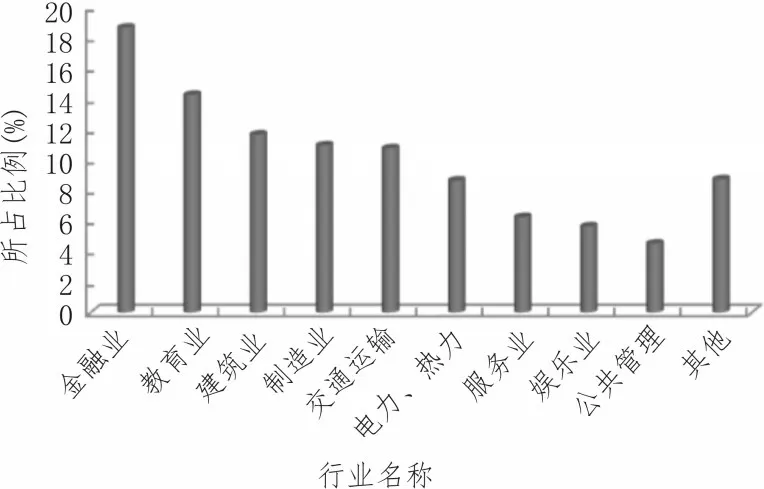
圖7 畢業生行業分布情況
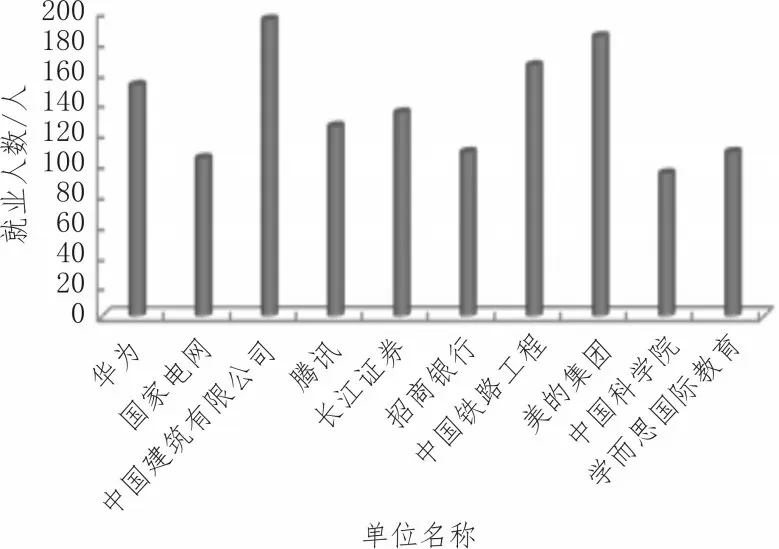
圖8 畢業生就業單位統計
由圖4~8 可以看出:
1)該校2018 年畢業生主要分布于北京、上海、深圳、廣州等地,其中分布于北京的畢業生占該校2018年畢業生的13%;分布于上海的畢業生占12%。跟蹤結果說明北京與上海為該校畢業生去向首選;
2)該校2018 年畢業生本科、碩士、博士就業率分別為96.25%、97.25%、98.46%,未就業率分別為1.79%、1.42%、0.80%,統計結果說明該校具有較高的就業率;
3)該校就業的畢業生中,本科、碩士、博士簽約就業的畢業生分別占全部畢業生的97.85%、98.23%以及98.58%,畢業生就業去向跟蹤系統說明簽約就業仍為高校畢業就業的主要就業方式;
該校就業的畢業生主要分布于金融業、建筑業、教育業以及交通運輸業,驗證了文中系統跟蹤畢業生就業去向行業分布具有較高的有效性。
該校畢業生分布于中國建筑有限公司以及美的集團的就業人數均高達200 人,是該校畢業生分布人數較多的單位。統計結果再次驗證文中系統具有較高的畢業生就業單位跟蹤有效性。
采用文中系統針對畢業生設計調查問卷,從工資滿意度、適應能力等方面統計畢業生對就業的滿意程度,統計結果如圖9 所示。從問卷統計結果可以看出,文中系統可有效統計調查問卷,根據調查問卷統計結果有助于高校進一步明確畢業生就業去向以及畢業生對就業的滿意程度。
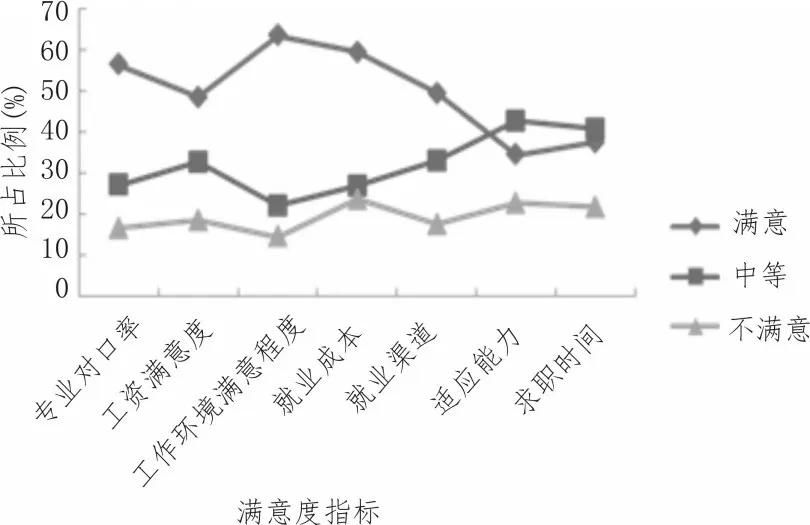
圖9 畢業生滿意度指標
選取100 名畢業生用戶,通過問卷調查的方式選取系統兼容性、界面友好性、用戶并發連接響應速度等指標測試所設計系統性能,統計結果如圖10 所示。從系統測試結果可以看出,文中系統可基本滿足系統性能要求,各項評分均在8 分以上,說明所設計系統性能可符合就業去向跟蹤需求,文中系統可滿足系統使用條件。系統設有反饋功能,用戶使用過程中可針對系統缺陷提出改進措施,利于系統優化等后續工作,提升系統易用性。
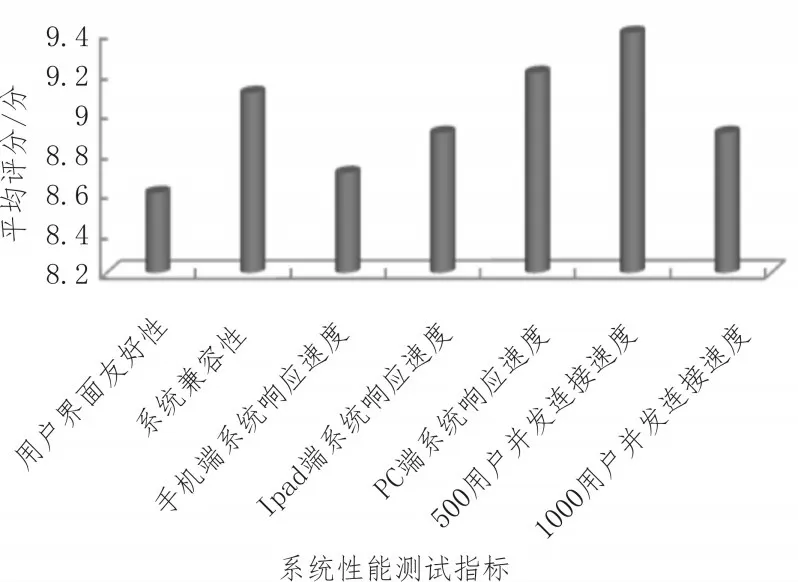
圖10 系統測試結果
3 結束語
數據庫作業中數據集成技術的數據抽取、轉換以及加載占據數據庫作業的大量工作量,批量作業方式可提升集成任務的數據抽取、處理以及加載的運行效率。將大數據集成技術應用于畢業生就業去向跟蹤系統中,提升了系統應用需求的實時性。所設計畢業生就業去向跟蹤系統便于高校實時了解畢業生的就業去向,降低高校就業部門管理人員的工作量,提升高校畢業生就業管理的效率。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
