機器學習在讀者需求驅動采購中的應用探析
2021-08-23 02:55:31曹莎莎徐嵐劉涓
新世紀圖書館 2021年7期
關鍵詞:機器學習
曹莎莎 徐嵐 劉涓


摘 要 隨著讀者需求驅動采購在高校圖書館的應用日益廣泛,隨之而來的經費超支、館藏結構失衡等問題引起業界關注,為有效解決上述問題,文章通過探索機器學習方法在讀者需求驅動采購中的應用,構建具體應用框架,并從讀者、圖書、模型三個角度對應用框架進行拓展和延伸,分別描述不同角度下機器學習方法應用于讀者需求驅動采購的技術路線。研究表明將機器學習方法應用于讀者需求驅動采購,可以有效預測讀者需求、圖書觸發采購概率和館藏結構,從而實現節省圖書館經費、改善館藏結構失衡的目標,事實證明其對圖書館采購決策和館藏建設有著積極的影響。關鍵詞 機器學習 ?讀者需求驅動采購 ?讀者決策采購 ?館藏建設
分類號 G253.1
DOI 10.16810/j.cnki.1672-514X.2021.07.012
Analysis on the Application of Machine Learning in Demand Driven Acquisition
Cao Shasha, ?Xu Lan, ?Liu Juan
Abstract With the wide application of demand driven acquisition in university libraries, the following problems such as over expenditure and unbalanced collection structure have attracted the attention of libraries. In order to solve the above problems effectively, the paper first puts forward a specific application framework by exploring the application of machine learning in demand driven acquisition, then expands and extends the application framework from the perspectives of readers, books and models, and respectively describes the technical route of the application of machine learning methods in demand driven acquisition from different angles. The research shows that the application of machine learning method in demand driven acquisition can effectively predict readers demand, the likelihood of books being triggered for purchase and collection structure, so as to achieve the goal of saving library funds and improving the imbalance of collection structure. Facts have proved that it has a positive impact on library procurement decision-making and collection construction.
KeywordsMachine learning. Demand driven acquisition. Patron driven acquisition. Collection development.
0 引言
圖書館一直有讀者參與圖書采購決策的傳統,從讀者意見箱到線上薦購再到館際互借,但館藏建設的最終決策權仍在圖書館員身上。隨著讀者對文獻資源需求越來越高,電子出版物大量涌現,與此同時,圖書館經費收縮,現有館藏利用率較低,催生了讀者需求驅動的圖書采購新模式[1](Demand Driven Acquisition,以下簡稱DDA)。ProQuest2018年發布題為“Why DDA is Here to Stay”的白皮書[2],對全世界449名圖書館員(其中99%的受訪者為高校圖書館員)開展調查,有93%的受訪者稱其圖書館采用多種電子書采購模式,92%的受訪者稱需求驅動采購是其圖書館電子書的主要采購模式,可見讀者決策采購在國外圖書館,特別是高校圖書館扮演著越來越重要的角色,學界一致認為該采購方法是對當前館藏建設方法的有益補充[3]。現有DDA研究主要集中于各機構的實施案例和經驗,研究發現,依據讀者需求而非圖書館員對館藏的評估采購圖書,雖優勢明顯,但其過程中的不可預見成本及館藏結構失衡問題,對圖書館來說也是一種挑戰,如俄亥俄州立大學圖書館的DDA試點項目投入25000美元,測試預計持續18周,結果在第五周經費已花完[4];猶他大學的DDA項目被3名用戶主導,3人花了近1/3的年度經費[3]。由于不確定性廣泛存在,圖書館員一直在努力探索推動DDA實踐的積極方法,大數據時代的到來為讀者需求驅動采購提供了新的思路。
隨著互聯網的發展,數據快速增長,由此催生的數據科學研究方法和產品正在改變各行各業,也包括圖書館業[5]。現今不斷涌現的各種人工智能技術正在成為大數據獲取、預處理、存儲、分析或可視化的有效手段。機器學習作為人工智能的重要分支,是大數據時代必不可少的核心技術,其在分析讀者數據、發現讀者需求、挖掘數據隱藏的結構和關系上有著極大優勢。當前,機器學習在圖情領域的應用主要有個性化信息推薦服務、智能信息檢索以及自動文本分類等方面[6]。作為一種數據驅動的采購模式,DDA涉及大量數據,這些數據不僅能夠觸發購買行為,還可以通過機器學習方法對其分析和處理,判斷DDA模式是否符合圖書館預期,從而為讀者提供個性化服務、協助館藏建設決策制定,并對高校教學科研產生積極的影響。
1 讀者需求驅動采購的數據來源
讀者需求驅動采購源于館際互借,典型的DDA項目始于預設文檔的構建,預設文檔類似于綱目購書(Approval Plan)的綱目,圖書館可以根據圖書的主題、價格、出版社及DDA服務商提供的其他限制設置預設文檔;服務商將符合預設文檔的MARC記錄導入到OPAC中,項目過程中可以增添或刪減書目記錄來調整DDA資源庫;隨后讀者能夠在終端看到圖書并根據自己需求觸發購買。DDA主要有兩種觸發購買模式:單觸發模型和短期借閱模型。前者基于讀者請求直接購買,即10-10-1-1-1范式,讀者在某本書上停留10分鐘、查看10頁、1次下載、1次打印或1次復印則觸發購買;后者在單次或數次短期借閱之后產生購買行為,每次短期借閱行為通常也符合10-10-1-1-1參數,除最后一次以圖書標價直接觸發購買外,每次短期借閱的價格一般為圖書標價的20%~25%[7]。可以看出,DDA在實施過程中涉及大量數據,從賴以提供服務的館藏書目數據和學科建設數據,到讀者相關數據,再到讀者在利用圖書館的過程中產生的書目數據和流通數據等,對上述數據進行收集和分析,有助于提高DDA決策的科學性和精準性。
1.1 書目數據
讀者需求驅動采購中的書目數據包括館藏書目數據和預購書目數據。館藏書目數據指的是館藏MARC數據和數字資源數據,具體包括書名、作者、出版社、出版日期、編目日期、主題等內容,該數據有助于了解館藏文獻類型分布、時間分布、學科分布及館藏特色資源。預購書目數據指的是DDA項目過程中預計采購圖書的書目數據,即DDA資源庫中的書目數據。館藏書目數據和預購書目數據是制定DDA預設文檔的基礎。
1.2 讀者數據
讀者數據包含讀者身份數據、讀者行為數據和讀者偏好數據。讀者身份數據指的是讀者身份信息,如性別、年級、讀者類型、讀者所屬院系及專業等相關信息。讀者行為數據指的是讀者在利用圖書館資源中產生的行為數據,如圖書瀏覽、借閱、數據庫訪問、請求、檢索、下載、評價等數據。讀者偏好數據指的是不同類型的讀者(本科生、研究生或教職人員)對不同類型、不同載體、不同學科圖書的偏好數據。讀者數據可以用于讀者畫像描述,構建DDA讀者偏好模型。
1.3 流通數據
流通數據指的是館藏圖書的借還和續借數據,是典型的靜態數據。流通數據可以用來識別高利用率館藏和低利用率館藏,判斷一本書的生命周期及館藏文獻半衰期[8],從而評估館藏,還可以了解不同讀者群體的閱讀傾向及其對圖書的偏好,掌握其潛在信息需求。流通數據可以和書目數據一起構建圖書采購模型,還可以指導DDA預設文檔的建立,評估DDA效能以確定DDA是否按照預期執行。
1.4 學科建設數據
學科建設數據指的是高校的學科專業設置和學科發展規劃、重點學科建設和教科研文獻需求等數據。學科建設數據可以同書目數據一起科學制定館藏建設策略,明確館藏建設的方向和重點,指導DDA參數的設置,如按照學科、出版社、作者、出版時間等因素決定優先采購何種文獻資源,使DDA決策和館藏建設方向一致,進而完善館藏特色資源建設[9]。
1.5 門禁數據
門禁數據指的是讀者進出圖書館的人次數據,此類數據可以通過圖書館的門禁系統獲得,對該數據進行收集、整理和分析可以得出到館讀者構成,從而區分不同類型、不同年級、不同系部、不同專業讀者的入館比例等,提供準確時段數據。借助于門禁數據,圖書館可以根據讀者類型和到館人流變化趨勢制定服務策略。門禁數據可以同書目數據、學科建設數據、讀者數據和流通數據一起,輔助館藏決策制定。
2 機器學習在讀者需求驅動采購中的應用框架
2.1 機器學習在讀者需求驅動采購中應用的優勢
作為一種以數據為導向的方法,機器學習利用不同的理論模型和訓練方法,從特定的行業數據中尋找隱含的規律,是一種依賴數據并能夠極大提升數據利用水平的重要智能信息技術。按照學習方式,機器學習可以分為監督學習、無監督學習和強化學習。其中監督學習是根據已知類別的數據來推斷未知數據的學習任務,大致可分為回歸和分類兩大類,如邏輯回歸、K-近鄰、決策樹、貝葉斯分類、神經網絡等算法;無監督學習沒有對訓練數據進行事先標記,由機器自動對輸入的數據進行分類和分群,依靠訓練集的統計規律實現數據的分析,常見的方法是聚類和降維,如K均值算法、主成分分析等;強化學習是完全隨機的操作,通過不斷嘗試,從錯誤中學習最后找到規律[10]。在大數據和人工智能應用的背景下,將機器學習技術有機地融入圖書館讀者需求驅動采購工作,有利于提升信息時代館藏資源建設的智能化水平,為館藏建設帶來有益啟示。
讀者需求驅動采購中涉及的數據既有宏觀層面的圖書和讀者群體的特征和行為數據,也有微觀層面的讀者個性數據,這些數據蘊含了大量的特征、模式和關系,為讀者需求驅動采購提供了重要依據,也為機器學習提供了用武之地。通過機器學習方法對這些大數據進行收集、分析和處理,可以提前預測讀者需求,在讀者沒有意識到需要何種圖書的時候購買該書,理解讀者不斷變化的偏好[11],能夠為DDA預設文檔和館藏建設制定方向;可以節省DDA經費,提高圖書館投資回報率;還能對DDA項目進行評估,提高其應用效能。
2.2 機器學習在讀者需求驅動采購中的應用框架
機器學習在讀者需求驅動采購中的具體應用框架如圖1所示,其中圖書館大數據是基礎,機器學習是手段,滿足讀者需求和完善館藏結構是目標。該應用框架分為三個階段,第一個階段是圖書館多源異構數據的預處理和融合;第二階段針對讀者需求驅動采購的具體環節,利用不同的機器學習方法對數據進行分析和處理,建立對應的科學模型,通過模型在分類、聚類和預測等方面的深入應用實現讀者需求驅動采購的智能化和精準化;第三階段是讀者需求驅動采購的評估過程,重點是利用機器學習方法來評估圖書館大數據驅動下讀者需求采購的效能。
2.2.1 數據預處理和融合
圖書館大數據是典型的多源異構數據,數據來源和類型多樣,同時具有時間、空間和語義的多維度特征,往往無法直接被應用于數據分析和建模[12]。DDA中的多源異構數據包括書目數據、讀者數據、流通數據、學科建設數據和門禁數據,這些數據既有靜態數據,也有動態數據;既有結構化數據,也有半結構化、非結構化數據,需要對其預處理和融合才能形成結構完整、形式統一的數據格式。數據的預處理流程指的是對數據進行清洗、集成、變換和規約,數據清洗通常對數據缺失值和異常值進行處理,數據集成通常用于識別數據中的不一致和冗余屬性,數據變換是對原始數據進行規范化處理,而數據規約是對原始數據進行數據和屬性的約減。通過分類、回歸、聚類、關聯分析等機器學習方法對數據預處理和融合,可以提高數據的質量,為后續的數據分析提供基礎和支撐。
2.2.2 模型建立
完整的讀者需求驅動采購流程分為三個部分,依次是預設文檔構建、導入符合預設文檔的MARC記錄、讀者觸發購買。其中預設文檔的構建跟圖書密切相關,具體購買行為則與讀者密切相關,對圖書和讀者分別進行分析可以建立相應的圖書預測模型和讀者偏好模型。
讀者分析模塊中,讀者在利用圖書館資源的過程中產生系列數據,這些數據既包含讀者顯性興趣,也包含其隱性需求傾向,這類讀者偏好信息無法被主動獲取。借助于機器學習方法中的監督學習方法,從讀者屬性、歷史行為等方面抽取出關鍵的特征,利用這些數據和特征訓練得到讀者偏好模型,該模型能計算出讀者對圖書的喜好概率,從而更加準確、有效地預測讀者需求。對于預購新書,可將其加入到讀者偏好模型中預測其被觸發購買的概率,根據項目經費確定是否需要將該書加入DDA資源庫,以防經費超支;還可以通過該模型對館藏資源進行效用評價,確定館藏資源是否符合讀者需求及館藏建設目標,改善館藏結構失衡。
圖書分析模塊中,通過對圖書的題名、責任者、出版社、主題、出版時間等屬性信息進行深入挖掘和分析,掌握不同屬性的圖書利用情況。將圖書的屬性信息抽取出來構成關鍵的特征,不同特征的組合可以用來表示不同的圖書,由于缺乏足夠的先驗知識,開始可以利用無監督學習的算法如聚類分析,區分出不同的圖書群體,并且概括出同一類圖書的特點,把注意力放在某一特定的類上以作進一步的分析;或者可以利用關聯分析,分析圖書不同特征和實際利用效率的關聯關系,得到每一個特征和不同特征組合對圖書利用的影響,其后利用監督學習的算法構建圖書預測模型。對于預購圖書,可將其加入到模型中,預測是否會被購買以及多長時間會被購買,根據預測的觸發因素推斷詳細的經費支出,評估DDA經費分配或者調整預設文檔參數。
2.2.3 模型評估
讀者需求驅動采購的評估過程,重點是利用機器學習方法來評估圖書館大數據驅動下讀者需求采購不同環節在長期運行后的實際效果。評估是對讀者需求驅動采購的必要信息反饋,只有進行評估才能知道讀者需求驅動采購是否滿足預期效果,以及讀者偏好模型、圖書預測模型等機器學習背景下建立的模型是否能有效提高工作效率,從而構成一個閉環,促進讀者需求驅動采購的優化。評估的核心是在各種靜態和動態的圖書館大數據基礎上,引入機器學習在數據挖掘和數據建模方面的方法,驗證讀者需求驅動采購過程中所構建讀者偏好模型和圖書預測模型的準確性,運用不同分類和聚類算法來衡量館藏資源結構、圖書采購經費運用是否合理,利用機器學習方法建立的模型預測館藏圖書以及讀者需求驅動采購的圖書在當前和未來的利用率。
3 機器學習在讀者需求驅動采購中的應用模式
為將機器學習思想和算法引入讀者需求驅動采購中,學界進行了有益探索。Kohn[13]通過建立包含主題、出版社和供應商的邏輯回歸模型確定何種因素最利于預測電子書的利用率;Walker[14]等人利用自適應增強(AdaBoost)模型預測DDA項目中新書被觸發購買的可能性,其準確率超過82%;Zhehan Jiang等人[15]利用基于隨機森林算法的生存分析預測圖書館新書是否會觸發購買及何時會被觸發購買,其中涉及出版社、出版時間、分類和價格等參數的復雜模型產生的AUC(一種測量預測模型預測能力的方法,AUC越接近1表明模型越完美)高于0.8,預測效果良好。然而,這些應用模型存在手段單一、效果不顯著、應用場景受限制等問題。本文對如何在數據驅動下將讀者需求驅動采購和機器學習進行有機的結合開展了深入思考,總結了機器學習技術在讀者需求采購中的三個應用方向,其一,基于讀者分析的應用模式,重點研究如何深入分析和挖掘讀者數據中隱含的信息,利用機器學習的不同算法建立準確的讀者偏好模型,提升讀者需求驅動采購的智能化水平;其二,基于圖書分析的應用模式,重點研究如何深入挖掘圖書采購和利用的規律,利用書目數據和流通數據建立圖書預測模型,提升讀者需求驅動采購和利用的效率;其三,基于模型分析的應用模式,重點研究如何針對讀者需求驅動采購的不同環節需求,選擇合適的機器學習方法,準備訓練數據構建最佳模型,實現對應環節服務能力的全面提升。
3.1 基于讀者分析的應用模式
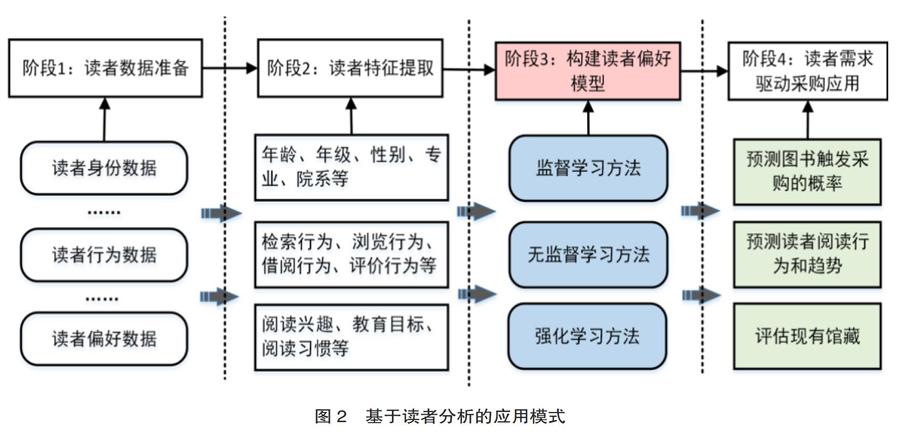
基于讀者分析的應用模式是從深入分析讀者的角度,利用圖書館大數據中讀者身份數據、讀者行為數據和讀者偏好數據,經預處理后依據不同的維度抽取出可以用來揭示讀者區別的特征,如讀者性別、年級、類型、專業等內在特征,檢索行為、瀏覽行為、借閱行為和評價行為等動態特征[16],以及閱讀興趣、閱讀習慣、教育目標等深層次的特征,再利用不同的機器學習方法挖掘讀者的需求傾向,具體搭建下圖2所示的讀者偏好模型,該模型能實現預測圖書觸發采購概率、預測讀者閱讀行為和趨勢、評估現有館藏三大目標。
3.1.1 預測圖書觸發采購概率
讀者偏好模型的重點是反映讀者對不同類型圖書的偏好程度,具體過程是分析讀者年級、專業等內在特征數據,如法律系的讀者可能更偏好法律類的圖書;或者分析讀者對圖書的檢索、瀏覽、借閱、評價等行為特征數據,如借閱武俠小說多的讀者們比較偏好武俠小說;或者分析讀者閱讀目標等深層次特征數據,如低年級本科生偏好參考類圖書、高年級本科生偏好考研類圖書。讀者偏好模型一般可以訓練決策樹、貝葉斯網絡、神經網絡等數學模型來表達,其表現形式是不同讀者對不同圖書屬性(題名、作者、出版社、價格、出版時間等)或者屬性組合喜好的概率,如周志華著的《機器學習》一書,清華大學出版社2016年出版,通過該模型可以分別計算出喜歡該書以及不喜歡該書的讀者比例。日后對于預購圖書,都可以利用該模型分別計算出讀者對某本書每個屬性喜歡和不喜歡的概率,綜合得出該書的需求概率,從而做出購買與否決策。
3.1.2 預測讀者閱讀行為和趨勢
分析讀者行為歷史數據,諸如檢索過哪些關鍵詞,借閱過哪些書,對哪些書進行過點評,對檢索關鍵詞、圖書屬性和讀者評價進行分析,統計讀者不同行為的分布特征,可以從側面反映出讀者的閱讀需求。讀者本質上由性別、年齡、專業、年級、類型等特征進行區分,將讀者上述本質屬性與對應的行為聯系起來,即挖掘讀者屬性和行為特征的關聯,利用決策樹、貝葉斯分類等方法訓練具體的讀者偏好模型。隨著讀者組成結構的變化,讀者需求也隨之變化,而需求變化的規律將遵循讀者偏好模型所表達的規律,通過模型抽取出新的讀者屬性特征,經過計算可以得到新的讀者需求變化趨勢,對讀者需求采購進行指導,提升采購智能化水平。此外,結合館藏流通數據和門禁數據,可以得知不同時間段讀者對館藏文獻的需求,從而調整DDA項目的實施時間及經費,如在讀者對館藏需求較高的時段開展DDA項目并適當加大這一時期的經費投入。
3.1.3 評估現有館藏
分析讀者不同屬性特征的分布,建立讀者屬性和行為特征的關聯,一般采用貝葉斯網絡、關聯規則等知識表示的手段來總結規律,構建讀者偏好模型,利用上述模型實現對館藏圖書的深入分析。具體分析流程如下:館藏圖書經過特征提取以后可由讀者偏好模型計算得到對應的讀者需求概率,概率越高表示圖書被讀者借閱的概率越大,相應的利用率也越高;概率越低表示圖書被借閱的概率越小,越有可能成為閑置資源。讀者偏好模型的建立,能夠對館藏資源的整體效用進行計算和評價,明確現有館藏資源是否符合讀者的需求及館藏建設目標。同時隨著讀者結構的變化,該模型還能評估館藏圖書的結構是否沿著滿足讀者需求的方向發展。
3.2 基于圖書分析的應用模式
基于圖書分析的應用模式從分析圖書的角度,以圖書館大數據中預購書目數據、館藏流通數據和館藏書目數據為基礎,經過預處理以后根據不同的維度抽取出可以用來區分圖書的特征,如題名、作者、出版社、價格、出版時間、借閱時間、借閱頻率等特征。在不直接依賴讀者偏好數據的前提下,深入挖掘圖書特征與圖書采購和利用之間潛在的規律,利用機器學習方法構建圖書預測模型,實現圖書觸發采購、圖書流通趨勢和館藏資源結構預測的目標,模型如圖3所示。
圖3 基于圖書分析的應用模式
3.2.1 預測圖書觸發采購
分析圖書的題名、作者、出版社、價格、出版時間等特征,結合圖書被檢索、被借閱、被評價等歷史流通行為數據,建立圖書屬性和流通數據之間的關聯,一般采用貝葉斯網絡、決策樹、隨機森林等方法,建立圖書預測模型。模型表達的是滿足什么樣屬性值的圖書容易被讀者借閱,以及被讀者借閱的概率,如知名作者、權威出版社、近期出版的圖書被借閱的概率更大。對于預購圖書,首先提取其特征值,在圖書預測模型中檢索對應的特征值或者特征值組合,計算得到對應的被借閱概率,從而得出該書被采購的概率,這個值即該書被讀者需要的程度,從而實現圖書觸發采購概率預測。
3.2.2 預測圖書流通趨勢
通過對圖書屬性特征進行區分,分析圖書不同的屬性在流通過程中的分布規律,如分析具備哪些特征或特征組合的圖書被借閱的概率更高,建立圖書屬性和圖書流通數據的關聯,利用邏輯回歸、貝葉斯網絡、決策樹、隨機森林、關聯分析等機器學習方法,建立圖書預測模型。模型表達的是不同屬性和屬性組合的圖書在當前環境下被借閱的概率,結合歷史流通數據預測未來一段時間內館藏圖書將被借閱的概況,實時、精準了解館藏需求的變化,實現預測圖書流通趨勢的目標。
3.2.3 預測館藏資源結構
與預測圖書觸發采購概率功能方法一致,采用貝葉斯網絡、決策樹、隨機森林等方法,建立圖書屬性和圖書被觸發采購的關聯,構建圖書采購預測模型。模型表達的是不同屬性值的圖書被觸發購買的概率,結合歷史觸發數據預測各類圖書被觸發購買的數量和比例,及時反應館藏結構的變化。隨著讀者需求的變化,該模型對館藏資源結構的預測結果也將保持動態更新,有利于圖書館及時調整館藏建設決策。
3.3 基于模型分析的應用模式
基于模型分析的應用模式是從不同機器學習算法的特點入手,面對讀者需求驅動采購的不同業務環節要求,抽象出需要機器學習算法解決的問題,確定最佳機器學習建模方法。然后依據方法對準確性、效率和穩定性的不同要求選擇具體的機器學習算法,其中監督學習有邏輯回歸、貝葉斯分類、決策樹、集成學習、深度神經網絡等方法,無監督學習有K均值算法、分層聚類算法、主成分分析、奇異值分解等方法。確定好機器學習建模算法以后,根據算法對輸入數據的特征和格式需要采集數據、提取特征,對采集來的數據預處理生產訓練集。最后在訓練集的基礎上利用對應的機器學習算法訓練模型,直到滿足模型預期的參數指標,完成訓練的模型可以在實際應用中完成預測、分類和聚類的任務,代替人工的工作。
4 結語
圖書館多年實踐表明,圖書采選的質量并不能保證其實用性或流通率,隨著圖書館經費收縮,讀者需求驅動采購將發揮重要作用。在大數據和人工智能技術廣泛應用的背景下,本文通過構建機器學習在讀者需求驅動采購中的具體應用框架,從讀者、圖書和模型三個角度闡述了構建和應用相應模型的方法,能夠實現讀者需求驅動采購的智能化和精準化,有效改善DDA項目成果,幫助圖書館更好地管理采購決策,提高經費的投資回報率。機器學習在讀者需求驅動采購中的應用有助于圖書館積極應對信息技術的挑戰,促進館員向新的工作流程轉變,不斷提升信息服務能力。然而,由于圖書館數字化程度的不同,傳統機器學習技術在圖書館館藏建設中的應用往往受限于數據樣本少,無法發揮出應有的價值,當前人工智能領域涌現的新技術,如遷移學習、自監督學習等可以彌補數據準備的不足。未來,開展此類研究將大大提升機器學習在讀者需求驅動采購領域,甚至是整個圖書館領域的應用效果。
參考文獻:
曹莎莎, 徐嵐.“互聯網+館藏建設”:讀者決策采購[J].新世紀圖書館,2016(12):21-24,29.
ProQuest. Why DDA is ries[EB/OL].[2020-06-20]. https://go.proquest.com/ddawhitepaperemail.
BLUME R. Balance in demand driven acquisitions: the importance of mindfulness and moderation when utilizing just in time collection development [J]. Collection Management, 2019, 44(2-4),105-116.
HODGES D, PRESTON C, HAMILTON M J. Patron-initiated collection development: progress of a paradigm shift[J]. Collection Management, 2019(35):3-4, 208-221.
OLIVER J C, KOLLEN C, HICKSON B, et al. Data science support at the academic library[J]. Journal of Library Administration, 2019,(59):241-257.
張坤,王文韜,謝陽群.機器學習在圖書情報領域的應用研究[J].圖書館學研究,2018(1):47-50.
WALKER K W, ARTHUR M A. Judging the need for and value of DDA in an academic research library setting[J]. The Journal of Academic Librarianship, 2018, 44(5):650-662.
RENAUD J, BRITTON S, WANG ?D D, et al. Mining library and university data to understand library use patterns[J]. The Electronic Library, 2015, 33(3):355-372.
王芙蓉.大數據環境下基于讀者決策的圖書館文獻資源采購模型研究[J].圖書館學研究,2017(12): 54-59.
周志華.機器學習[M].北京:清華大學出版社,2016.
LITSEY R, MAULDIN W. Knowing what the patron wants: using predictive analytics to transform library decision making[J]. The Journal of Academic Librarianship, 2018, 44(1):140-144.
馬曉亭.圖書館多源大數據融合研究:問題與挑戰[J].新世紀圖書館,2017(1):28-31,35.
KOHN K. Using logistic regression to examine multiple factors related to e-book use[J]. Library Resources & Technical Services. 2018, 62(2):54-65.
WALKER K W, JIANG ZHEHAN. Application of adaptive boosting (AdaBoost) in demand-driven acquisition(DDA) prediction: a machine-learning approach[J].The Journal of Academic Librarianship. 2019,45: 203-212.
JIANG ZHEHAN, FITZGERALD S R, WALKER K W. Modeling time-to-trigger in library demand-driven acquisitions via survival analysis[J]. Library and Information Science Research. 2019, 41(3):1-8.
沈敏,楊新涯,王楷.基于機器學習的高校圖書館用戶偏好檢索系統研究[J].圖書情報工作,2015,59(11):143-148.
曹莎莎 安徽警官職業學院圖書館館員。 安徽合肥,230031。
徐 嵐 安徽警官職業學院圖書館研究館員。 安徽合肥,230031。
劉 涓 安徽警官職業學院圖書館館員。 安徽合肥,230031。
(收稿日期:2020-10-06 編校:陳安琪,左靜遠)
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
