自定義模糊邏輯與GAN在圖像高光處理中的研究
2021-08-24 06:53:20郭繼峰龐志奇沈家友
小型微型計算機系統 2021年8期
郭繼峰,李 星,龐志奇,沈家友,于 鳴
(東北林業大學 信息與計算機工程學院,哈爾濱150040)
1 引 言
在圖像形成過程中,由于物體受到光照或者由于物體表面曲率過大,會在物體表面形成光斑,出現光斑的部分就是高光溢出的部分.高光溢出對于圖像處理的影響主要表現在降低圖像識別準確率、目標檢測以及場景分析的精確度.
影響圖像質量的主要因素有:光照不均勻、圖像分辨率等.許野平等[1]人根據數字圖像繪制亮度曲線,然后對高光溢出部分做非線性變換,壓縮最大亮度值規定范圍從而得到修復效果.高如新等[2]人通過雙色反射模型變換得到圖片的鏡面反射和漫反射分量,再通過改進雙邊濾波器,然后對圖像進行處理,去除圖像的鏡面反射,從而達到去除高光的效果.何嘉林等[3]人通過圖片融合的方法去除圖片高光,根據不同角度拍攝的圖像亮度不同,通過對多張圖片進行高光區域檢測、圖像融合、圖像補色來消除高光區域[4].王祎墦等[5]人改進了圖像的高光修復技術,使得對于存在飽和現象的高光區域的單一圖像也能有較好的修復效果.這些方法對圖像高光溢出的整體修復效果取得了良好的成效,但是對于圖片的紋理修復效果并不理想,且獲得的圖片質量不高.
隨著深度學習技術的不斷發展,出現了一些使用卷積神經網絡來對圖像進行修復的方法.2014年,生成對抗網絡GAN(Generative Adversarial Networks)面世,該網絡由Goodfellow[6]等人根據博弈論中的零和博弈理論提出,引起了研究者們的極大關注,并對該網絡模型做出改進,誕生了眾多版本,其中影響較大的有CGAN(Conditional Generative Adversarial Nets)、DCGAN(Deep Convolution Generative Adversarial Networks)、Wasserstein GAN(WGAN)[7].其生成對抗網絡的應用領域也在不斷拓展,正是當前圖像處理技術中的研究熱點.
結合傳統圖像處理方法與生成對抗網絡,本文提出了一種基于模糊邏輯與生成對抗網絡相結合的圖像高光處理技術,一方面利用模糊邏輯來模仿人腦的思維模式來對圖像高光區域進行識別、判斷,從而較好的實現對圖像高光區域的劃分;另一方面,引入生成對抗網絡來修復圖像,可以進一步提高在圖像紋理修復方面的能力.
2 方法引入
2.1 模糊邏輯
2.1.1 模糊邏輯判斷
圖片高光區域部分通常是漸變式的,采用過去的方法——確定超過某一值的像素點劃分為高光區域,很容易形成截斷式分界線,而且對高光區域的劃分效果不理想.為了解決這些問題,我們引入模糊控制的方法來對圖像的高光進行閾值分割處理.
隸屬度函數是模糊數學中的一個重要概念,模糊邏輯通過隸屬度函數來確定集合所屬范圍[8,9].本文方法選取S型隸屬度函數來進行處理.其表達式如式(1)所示.
(1)
由于本實驗中對圖片進行通道分離處理,因此在該式中,x表示連續通道中的亮度值,a,b,c是函數S的參數,a、c是亮度通道的取值范圍,b表示劃分為亮度區域的渡越點[10],通常取中點.使用該函數作為隸屬度函數的優點在于能較好的區分出高光位置,不會導致大面積非高光區域被劃分到高光范圍內.準確的劃分范圍對后期圖像修復的效果往往具有正向作用.
2.1.2 高光區域劃分
本文通過模糊邏輯來對圖片的高光區域進行分析,借助模糊邏輯模仿人腦不確定性的優點來精確定位高光區域范圍.
在數字圖像中,物體的顏色R、G和B分量都與照射到物體上的光相關聯,使用RGB模型來對圖像進行高光區域劃分是較為困難的,因此本文中選用了HSV(Hue,Saturation,Value)模型來對圖像進行處理.HSV是一種直觀的顏色模型,它將顏色與強度分隔開的程度較其他模型更多,這對于圖像高光區域的劃分有很大的優勢[11].
圖像的高光區域劃分完畢后,將本環節生成的高光區域劃分以及二值掩碼傳入生成對抗網絡模型中,在卷積神經網絡中對圖像進行后續處理.
首先將圖片格式轉換為HSV模型,將圖片的三通道進行分離,對分離出來的亮度通道(V通道)進行模糊邏輯處理,圖像傳入模糊邏輯程序中后,使用上文中的S型隸屬度函數對圖像進行全局處理,從中選取屬于高光部分的區域進行高光定位,取邊界處位置進行框選,并生成二值掩碼.至此高光區域的劃分就結束,其流程圖如圖1所示.
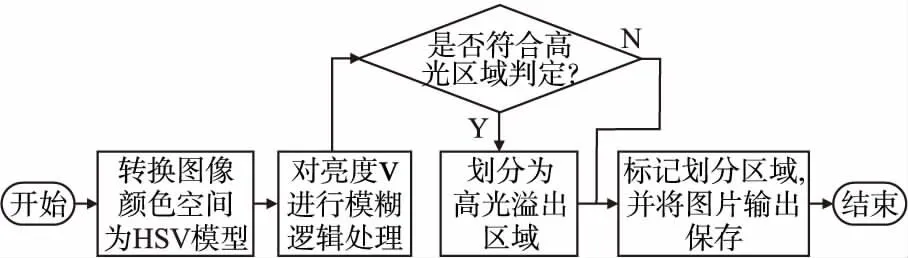
圖1 高光區域劃分流程圖
2.2 生成對抗網絡引入
劃分高光區域后需要對高光溢出部分修復,常規方法是從高光溢出區域周圍獲取像素點的顏色來對溢出部分進行填充,但是這種方法生成的顏色通常不夠自然,而且填充區域較為死板、不真實,用這種方法修復的區域通常沒有原圖像的紋理.本文使用基于深度卷積的生成對抗網絡(GAN)來對圖像高光區域進行修復,并在此網絡的基礎模型上做了一些改動.GAN的目標函數表示見式(2):

(2)
其中G表示生成器,D表示判別器,x表示來自于真實數據Pdata(x)中的部分采樣,[·]表示期望值計算,Z表示經過模糊處理的數據,也就是輸入到生成器網絡中的數據,PZ(Z)表示原始的數據分布.生成對抗網絡的框架主要有由一個生成器和一個判別器組成.兩者互相對抗訓練,判別器返回判斷結果給生成器,生成器根據返回結果不斷調整生成圖像,最終當判別器難以區分生成器產生的數據時,該網絡實現生成以假亂真的圖像的目標.
2.2.1 生成器網絡
本文的主要目的是通過該生成網絡修復圖像由于高光溢出導致的圖像局部失真或缺失的問題,修復后的圖像應盡量滿足與真實圖片在同一區域的相似度,并滿足圖像整體的完整性[12].本文生成器網絡模型結構如圖2所示.

圖2 生成器網絡結構模型
標準的卷積網絡使用到的像素較少,難以完成大面積的圖像修復[13],而擴張卷積能夠擴大感受野區域[14],這對圖像紋理以及圖像的整體恢復發揮著重要的作用.
本文中對局部區域的恢復使用擴張卷積,改卷積方式可以通過使用更大的輸入面積來計算每個輸出像素,因此即使掩碼部分圖像有所缺失也能對圖片進行良好的修復.選定區域的輸入是具有二進制通道的圖像,該通道標志著圖像需要完成的掩碼,而對于選定區域以外的其他部分,如果不希望它發生任何變化,則可以將選定區域以外的其他部分的輸出像素改為輸入RGB值.
對于一個大小是h×m卷積層,假設它的下一個卷積層大小是h′×m′,那么對于當前卷積層的擴張卷積計算公式可以表示為式(3):
(3)
其中kw和kh分別表示卷積核的寬高,η是擴張系數,xu,v和yu,v分別表示圖層的輸入和輸出分量,σ(·)表示一個非線性傳遞函數,b是卷積層的偏置向量,W是內核矩陣,當η=1時該方程表示標準的卷積操作.
為了控制生成區域的光照強度,本實驗在網絡中引入一個亮度的參數l,該參數通過模糊邏輯計算獲得.傳入生成網絡中的圖片經過模糊邏輯獲得當前圖片x的亮度參數l,圖片經過生成網絡處理后得到圖片x′,該圖片再次經過模糊邏輯獲得一個處理后的圖片亮度l′,在本文中定義生成器部分的基本損失函數見式(4):
LossG1=logDG(x)+log(1-DG(G(MB,l′)))+αlog(-logDl(l′,l))
(4)
其中DG表示生成器網絡的判別器,MB表示二值掩碼,Dl是一個x和x′的亮度判斷器,α是超參數,用來控制亮度的權重,本實驗中取值為1.
為了使生成網絡的效果趨于穩定,降低過擬合產生的可能性,本文還在均方誤差(MSE)的基礎上添加了L2正則項作為損失函數,并添加了二值掩碼來代表需要生成的區域位置,其表達函數如式(5)所示:
(5)
其中MB表示二值掩碼,⊙表示圖像矩陣逐元素相乘,λ表示正則項系數,n表訓練集中的樣本數量,w表示生成器網絡中的所有權重參數.
綜上所述,生成器的損失函數可以表示為式(6):
LossG=LossG1+LossG2
(6)
2.2.2 判別器網絡
本文判別器網絡采用全局判別器和局部判別器網絡兩者相結合,兩者協同工作來區分圖像是來自真實數據分布還是由生成器生成.局部判別器也在其他一些論文中使用過,并且取得了良好的效果[15,16].
局部判別器主要識別缺失部分的結果是否正確,局部判別器的輸入是原始丟失圖像部分或者是被遮擋的部分,以及生成器的生成部分,局部判別器約束著圖像的細節信息和局部一致性.而全局判別器需要判斷整個圖像的真實性,全局判別器的輸入也分為兩類:原始圖像和由生成器生成的整個圖像.判別器網絡結構模型如圖3所示.

圖3 判別器網絡模型結構
在判別器網絡的體系結構中,全連接層都是標準的神經網絡層.全局判別器和局部判別器處理完后,在判別器網絡中通過一個連接層將兩者的輸出連接到一起,形成一個2048維度的矢量,再經過一個全連接層處理后得到一個連續的值.最后使用sigmoid函數作為轉移函數,使該值的范圍在[0,1]來表示圖像是真實圖像的概率.
判別器在評分過程中需要對真實圖片x做出盡可能高的評分,對生成圖像G(·)盡可能降低評分.因此將對判別器的損失函數進行優化見式(7)、式(8):
Lossglo=-logDglo(X,MB)+log(1-Dglo(G(X′,MG),MG)
(7)
Lossloc=-logDloc(x,MB)+log(1-Dloc(G(x′,MG),MG)
(8)
其中MB表示二值掩碼,MG表示輸入的圖像,x′表示圖像的缺失區域,Lossglo表示全局判別器的損失,Lossloc表示局部判別器的損失.
局部損失函數的主要作用是判斷生成區域相對于原圖像的區域相似度,使得生成區域的真實性更加接近原始圖像,由于生成器部分亮度參數的存在導致生成的局部區域與原圖像必然存在差異,因此需要全局判別器的來進行圖像的整體判斷.全局判別器需要判斷包含掩碼所在區域的全局圖像的真實性,保障局部區域與全圖的融洽性,進一步降低由于局部亮度差異而引起的誤差.
3 實 驗
3.1 實驗環境
本實驗運行在Ubuntu18.04 LTS操作系統,處理器為Intel?Xeno(R)CPU E5-2407,顯卡為GeForce GTX TITAN X,運行內存16GB.實驗使用pytorch 0.4.0框架,用python實現.
3.2 實驗具體內容
在本文的實驗中,關于實驗中的部分數據搜集于Kaggle,數據包含人臉和一些水果的圖片,其中人臉部分數據來自于CelebA數據集.訓練使用的學習率是0.0002,上下文內容損失的權重λ是0.0001.
在訓練開始之前為了保證實驗的穩定性,需要對數據集圖像進行統一預處理.本實驗中通過預處理將實驗圖片處理為256×256×3的規格.此外為了使對圖片的修復更加具有普遍性,在訓練過程中,還需要對圖像進行隨機處理.即對于輸入的圖像,需要在圖片主體部分隨機生成一個需要修復的區域,并將該區域的大小限定在128像素之內.
3.3 實驗結果分析
圖4是根據本文算法獲得的實驗結果,對比最終的輸出結果與原始圖片,高光區域亮度有明顯下降.

圖4 部分實驗結果
為了進一步評估圖片的修復效果,本文引入峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和結構相似性指標(structural similarity index,SSIM index)來評估圖像修復質量,并對比了不同算法修復圖像的耗時,來評估算法的工作效率.
峰值信噪比是一個表示信號最大可能功率和影響,是表示進度的破壞性噪聲功率的比值的工程術語[17].結構相似性指標是一種用來衡量兩張數位影像相似程度的真值表[18].本實驗中使用峰值信噪比PSNR和結構相似性指標 SSIM兩種數據作為圖像修復的質量檢測的指標.
PSNR一般使用均方誤差(MSE)來進行定義.對于大小為m×n的兩張單色圖像I和k,如果I和k的噪聲相似,那么可以將I和k的均方誤差定義為式(9):
(9)
峰值信噪比定義為式(10):
(10)
其中MAXI表示像素點的顏色最大值,它由采樣點的編碼方式計算得來,當采樣點使用N位線性脈沖編碼調制表示時,MAXI的值為2N-1,,生活中的圖像采樣點通常用8位表示,MAXI的值為255.
結構相似性指標的范圍在-1到1,該指標數值越大,則說明兩張圖片的相似度越高.對于給定的兩個圖片信號x和y,其結構相似性定義為式(11):
SSIM(x,y)=[l(x,y)]α[c(x,y)]β[s(x,y)]γ
(11)
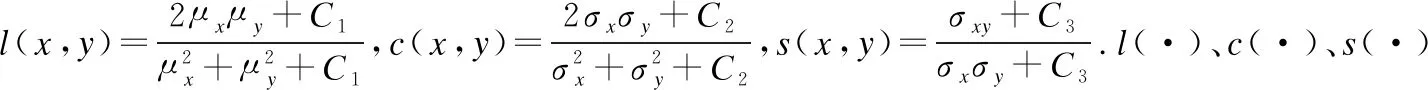
文獻[5]中作者的主要目的是針對具有高光飽和現象的圖片進行處理,其實現方法基本符合傳統圖像處理中先劃分高光區域,再根據高光區域的鄰域和邊緣信息來修復高光部分的步驟.文獻[19]根據WGAN網絡來對圖像進行修復,其主要面向對象是人臉修復.文獻[20]的算法中僅僅使用了局部判別器而沒有使用全局判別器,對于圖像的修復效果并不穩定,容易出現模糊扭曲等現象,在紋理方面的修復效果較為微小.文獻[21]的算法能在一定程度上修復圖像的紋理,但是在某些場景下會出現不連續以及偽影的情況,修復效果不夠穩定且圖片質量不佳.本表格的數據通過使用以上4種修復方法得到的修復結果,再通過Scikit-image中的metrics庫計算獲得,其質量評價指標數據如表1所示.

表1 質量評價指標數據
分析表中的數據可以發現,相比于傳統圖像處理方法,使用生成對抗網絡的方法都得到了顯著的提高,特別是在結構相似性方面的提升尤為顯著.本實驗方法與其他生成對抗網絡相比較,在PSNR方面平均提高了約23.41%,在SSIM方面提高了約19.49%,可以推斷出本實驗方法修復后的圖像在視覺感受上明顯優于其他3種方法.
除對PSNR和SSIM兩個指標進行統計分析,表2中統計了文獻[19]、文獻[20]、文獻[21]和本文算法在運行時處理單張圖片所需要的平均時間.

表2 各算法消耗時間
分析表1和表2中的數據發現,文獻[5]和文獻[21]的處理時間相對較少,但是這兩種算法的圖像修復效果都不及本文的算法,運行時間較文獻[21]減少了51.23%,并且本文算法的圖片修復效果更加優秀.在圖5的圖像修復效果對比中恰好證實了本文算法的修復效果優于其他3種文獻.
圖5中的折線圖表示,在不同大小的掩碼下,本文算法的質量評估指標PSNR和SSIM的變化過程.隨著掩碼的增大,圖像的修復質量有所下降,主要是因為,隨著圖片上的掩碼區域擴大,圖片上可供學習的區域越小,神經網絡難以收集足夠數據對進行良好的修復.當圖片的掩碼區域達到90(約占全圖35%)時,圖像PSNR值約為33,SSIM值約為0.953,對比其他文獻,本文在PSNR方面提高約8%,SSIM提高約15%.可以推斷出,本文在較大缺失區域的修復能力優于其他算法.

圖5 PSNR和SSIM折線圖
根據圖6中不同算法的修復效果對比發現,在圖片的紋理修復方面,本文有著極大的優越性,文獻[19]和文獻[20]對圖片的修復能力較差,僅僅能恢復出少量的紋理,而且恢復的區域與原圖像的契合度不高、過度不自然;文獻[21]的紋理修復效果稍好一些,但是同樣存在過度不自然的情況,本文算法在紋理方面的修復效果較前3種算法取得了極大的進步.

圖6 圖像修復結果對比
綜合各種指標,經過大量的實驗觀察,本文在圖像高光區域的修復效果良好,較傳統的圖像處理方法,本文的方法修復效果更加優秀,圖片質量更高,不僅能有效降低高光區域的亮度,還能對部分圖像紋理缺失的情況做出修復.此外在圖像修復部分,與其他采用GAN的修復方法相比較,本文算法在運行時間上略微得到了提高,在圖像質量方面,本文的修復質量更高,修復后的圖像紋理更加清晰合理.
4 結 論
針對圖像由于高光溢出導致的圖像部分區域與紋理的缺失,提出了一種基于生成式對抗網絡的圖像高光修復方法.通過實驗對比分析,本文方法較傳統圖像處理各方面都得到了極大的提高,尤其是圖像質量方面,提高了約93%;對比神經網絡的圖像修復技術,本文修復效率提高了18.04%,修復質量提高了22.96%,綜合以上信息可知,本文方法對圖像高光修復做出了有效的改進.
但是這項研究任然帶有一些局限性.首先本研究中提出的算法主要用于圖像高光修復,對圖像的高光區域有比較好的修復效果,但是由于本文沒有對人臉關鍵標識性區域修復做出針對性訓練,對于人臉關鍵位置的修復效果不夠理想,在以后的研究中將對這一部分做出改進,提高本文算法在其他方面的圖像修復效果;另外,本研究中的水果數據集只包含了常見水果,未來希望能夠獲取更多其他類型的水果數據,提高本實驗的兼容能力.
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
中國醫藥科學(2015年19期)2015-02-27 12:33:11
