基于fastText的惡意域名分類方法
2021-09-05 11:43:00匡立偉
電子設計工程 2021年17期
姜 天,匡立偉
(1.武漢郵電科學研究院,湖北 武漢 430073;2.烽火通信科技股份有限公司,湖北 武漢 430073)
僵尸網絡(botnet)通常由大量被感染惡意代碼的主機(bot)、命令和控制服務器(C&C server)以及主控端(Botmaster)構成。攻擊者使用主控端向C&C server發送操作指令,服務器再將命令下達到各個被控制主機,進而實現對目標終端的分布式拒絕服務(Distributed Denial of Service,DDOS)、垃圾郵件分發以及惡意軟件下載等網絡攻擊[1]。為了防止C&C服務器的域名被黑名單攔截,避免出現主機域名無法解析的情況,攻擊者會使用一種域名變換技術(Domain-Flux)來達到高頻率映射C&C服務器域名到IP地址的目的[2],域名生成算法(DGA)則是該技術的具體實現。首先DGA會定期生成大量的隨機域名,接著C&Cserver選擇其中指定的域名進行注冊,注冊完成后被控制主機能夠解析服務器的地址。
使用DGA生成惡意域名,一定程度上增強了僵尸網絡的隱蔽性和靈活性。針對字符級別的DGA域名檢測,文中提出的方法能夠對DGA家族進行識別和分類,并且能夠有效提升發現和追蹤僵尸網絡的能力。
1 相關研究
對于字符級別的惡意域名,目前主要分為基于統計特征的機器學習和基于深度學習模型兩種檢測方式[3]。
由于正常域名和惡意域名之間的差異主要體現在主機名上,因此通過人工提取字符的統計特征,然后使用相應的機器學習算法即可完成DGA檢測任務。文獻[4]提取了域名字符的統計特征和n-gram特征,并使用3種機器學習模型來評估域名特征識別性能。實驗結果表明,使用特征組合的n-gram(n=1,2,3)模型所得的精確率和召回率較高,并且多層感知器(MLP)的DGA域名檢測準確率高于其他兩種算法。文獻[5]提出一種基于大數據平臺的DGA檢測系統,其核心由分類分析和聚類分析模塊構成。該系統使用預訓練好的隨機森林模型來分離正常域名和可疑DGA域名,使用X-means算法對DGA域名進行無監督式聚類檢測。文獻[6]使用隱馬爾可夫模型中的Baum-Welch算法和Viterbi算法對未知域名進行分類,實驗結果顯示,該模型可以實現惡意域名的快速高效檢測。
隨著自然語言處理和計算機視覺等人工智能領域的發展,一些深度學習模型也逐漸被運用在惡意域名檢測任務中[7]。文獻[8]提出一種基于LSTM的惡意域名分類與檢測模型。通過二分類和多分類實驗結果的統計數據可以看到,該模型能夠較為準確地識別DGA域名。文獻[9]提出DBD(Deep Bot Detect)檢測模型,該模型由文本預處理、最優特征提取和分類模塊構成。DBD模型的訓練參數較少、訓練速度快且發生過擬合的概率較小。文獻[10]使用word-hashing技術,首先將域名轉換成高維稀疏向量,然后通過深度神經網絡(DNN)的隱藏層來學習bigram特征,最后使用輸出層輸出分類結果。模型整體的泛化能力強,且準確率比使用自然語言特征分類算法得到的結果高。
2 fastText模型及其原理
fastText是Facebook AI Research在2016年開源的一個被用于對詞向量和句子分類進行高效學習訓練的工具庫。該工具可以在監督和非監督模式下訓練單詞和句子的向量表示。訓練完成后生成的詞向量,可以進一步用在其他模型的初始化和特征選擇等任務中[11]。
fastText作為一種快速文本分類工具,其最大的特點是速度快。相比較其他文本分類模型,諸如邏輯回歸(Logistic Regression)和神經網絡(Neural Network)等,fastText在保留了較高分類準確度的情況下,還極大地縮短了訓練和測試的時間。除此之外,使用fastText也不需要提供預訓練好的詞向量。
2.1 基礎架構
一個簡單有效的文本分類框架通常使用詞袋模型(Bag of Words,BoW)來表示獨立的句子,同時搭配一個訓練好的線性分類器(比如邏輯回歸和支持向量機等)。但由于線性分類器不能在特征和類別信息之間共享參數,這樣會限制模型整體的泛化能力,因此需要將分類器分解為低階矩陣[12]。
fastText將上述思路與神經網絡的分層思想相結合,構成了一種快速文本分類器的設計方案。圖1展示了fastText的基礎架構。
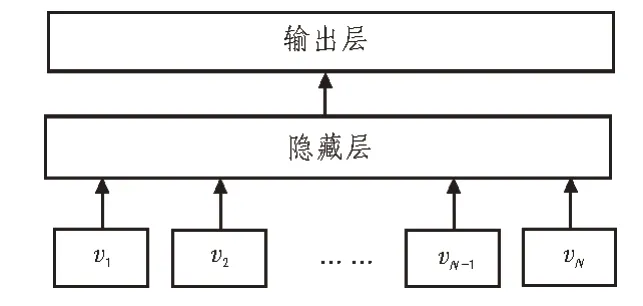
圖1 fastText基礎架構
從圖1中可以看出,fastText模型主要由輸入層、隱藏層和輸出層構成。首先通過輸入層傳入文本對應的n-gram向量,接著在隱藏層進行詞向量的疊加平均處理,最后在輸出層采用分層softmax預測結果,輸出文檔的判別類別[13]。因此,fastText的目標是將極大似然轉化為對數似然,同時使其最小化。式(1)展示了目標函數的計算方法。
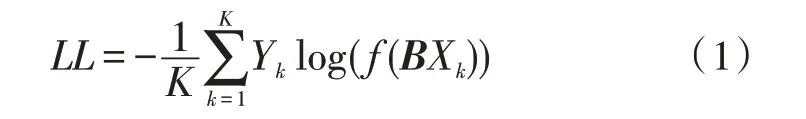
其中,Yk表示第k份樣本對應的標簽值,f表示使用softmax函數預測類別,B是一個權重矩陣,Xk代表文本特征向量。式(2)展示了Xk的計算方法。

func表示疊加平均函數,用來計算文本的特征向量。A是一個權重矩陣,vN(N=1,2,…)代表文本中的n-gram詞向量。
2.2 分層softmax
當判別類別過多時,使用標準softmax計算概率值會非常耗時。因此,fastText采用基于哈夫曼樹(Huffman Tree)的分層softmax(Hierarchical softmax),在計算目標類別的概率值P(y=j)時,只關心一條路徑上的所有節點,而無需考慮其他節點的狀態[14]。式(3)是計算從根節點到達y2節點(假設途經一個非葉子節點n(y2,1))概率值的過程。

?代表sigmoid函數,θn(y,m)表示第m個節點的參數,X是softmax層的輸入矩陣。以此類推,當最終輸出類別為w時,對應的概率值可以用式(4)來表示。
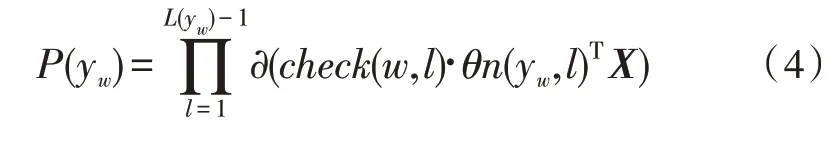
其中,L(yw)用來計算節點w距離根節點的深度,是一種自定義的函數。當第l+1個節點是n(yw,l)的左孩子時,check函數的返回值為1;當第l+1個節點是n(yw,l)的右孩子時,check函數的返回值為-1。
2.3 n-gram特征
根據劃分粒度的不同,提取到的特征可以分為詞粒度的n-gram特征和字符粒度的n-gram特征[15]。fastText同時支持兩種切分模式,因此可以根據實際情況來設置相關的參數。文中提出的方法采用詞粒度的切分方式,將分割開的域名字符當做獨立的單詞,整個域名字符串當做一個句子,從而分析域名字符排列順序的合理性。
假設提取域名“baidu”的bigram特征,那么根據滑動窗口大小(n=2)進行劃分,可以得到[“
fastText使用n-gram來提取文本特征,一方面可以使模型學習到局部單詞順序的部分信息,另一方面可以從字符級別n-gram中構造單詞的詞向量。這樣即使有不在語料庫中的詞語出現,也可以利用預訓練好的字符向量來組合表示[16]。
3 實驗
3.1 實驗環境
實驗機器安裝的操作系統為win10(64位),Python版本為3.5.4,sklearn版本為0.21.2,Keras的版本為2.3.0且以TensorFlow作為后端運行,tensorflowgpu的版本號為1.14.0。
3.2 實驗思路
實驗過程中模擬fastText的標準三層架構,依次使用Embedding(嵌入層)、GlobalAveragePooling1D(全局平均池化層)和Dense(全連接層)來拼接成最終的分類模型。使用定義好的評價指標來量化各參考模型的分類效果,在分析模型性能的同時討論影響最終結果的參數因素和參數優化規則。
3.3 數據收集與處理
實驗數據主要由兩部分組成,一部分是從Alexa網站選取了排名前100萬的域名,并將這些數據標記為正常樣本(whitesample);另一部分是從安全實驗室Netlab官網上下載的DGA種子文件,文件大小約為84 MB,其中包含了44種不同的惡意域名家族,共計1 256 160個DGA域名。
實驗過程中采用了字符級n-gram切割方式,首先將組成域名的各個獨立字符轉換為ASCII碼序號的表示形式,然后使用散列表(字典)存儲n-gram特征的鍵值對,并且將n-gram特征值添加到每一個字符序列集合的尾部。由于嵌入層需要輸入向量的維度保持一致,因此還需要使用pad_sequences函數來截取或填充數據。實驗過程中保留了域名原來的“{二級域名.頂級域名}”結構。實驗數據按照6∶4的比例劃分為訓練集和測試集。
3.4 參考模型
實驗過程中除了使用fastText對惡意域名進行分類,還另選了兩種深度學習模型(LSTM和CNNLSTM)以及一種機器學習模型(XGBoost)來對比測試。圖2展示了提出的基于fastText的域名分類模型結構。

圖2 基于fastText的域名分類模型結構圖
從圖2可知,攜帶n-gram特征的域名字符序列被送入模型后,首先經過詞嵌入層轉化為多維向量。接著使用一維全局平均池化層作為模型的隱藏層,用來對上一層輸出的向量進行特征映射;最后的全連接層用來對特征映射進行softmax分類,并輸出分類結果。
3.5 分類評估標準
在評估模型的過程中,用到了混淆矩陣中的3個一級指標,分別是TP(True Positive)、FN(False Negative)和FP(False Positive)。下面分別介紹各個指標代表的含義以及相關二級評價指標的計算方法。
TP代表真實值為positive,并且模型將樣本劃分到positive類的個數;FN代表真實值為positive,而模型認為是negative的數量;FP代表真實值為negative,而模型認為是positive的樣本數量。由此可以使用式(5)得到精確率(Precision)的計算結果。精確率代表在模型預測為positive的所有結果中,模型預測正確的比重。
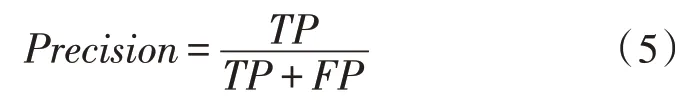
召回率表示在真實值為positive的所有結果中,模型預測正確的比重。式(6)是召回率(Recall)的計算方法。

F1值綜合了精確率和召回率的結果。式(7)是F1值的計算方法。
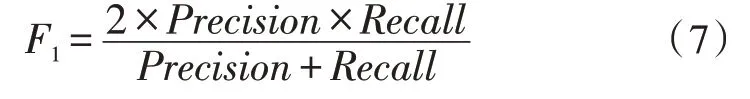
除此以外,后續實驗中還增加了兩個評價指標。使用Accuracy(準確率)來表示被分對的樣本比例,使用Loss(損失)來記錄模型最終的損失值。
3.6 實驗結果與分析
表1匯總了4種模型的分類情況,其中精確率、召回率和F1值均是指在45種類別上的平均表現。

表1 模型分類結果表
從表1中可以明顯看到,使用提出的fastText模型獲得的3個二級指標對應的值均高于其他模型。其中,fastText的精確率比其他兩種深度學習模型的值高約4%,比機器學習模型的值高約13%。fastText的召回率和F1值也較其他模型有很大提升,且模型最終的損失值也維持在0.1以下。
實驗過程中還發現,分層softmax在效果上略差于完全softmax。考慮到分層softmax是完全softmax的一個近似,同時分層softmax可以在大數據集上高效地建立模型,但通常會以損失精度的幾個百分點為代價,因此,fastText使用分層softmax得到的精確率略低于97.860%。
綜上所述,fastText之所以能夠具有較高的分類性能,主要得益于模型使用了字符的n-gram特征,以及在隱藏層對多個特征映射作spatial average(空間平均)。而其他模型的隱藏層通常包含大量參數,這樣一方面影響了整個模型的泛化能力,另一方面增加了模型的訓練開銷。fastText不僅可以更深層次地學習域名字符的分布規律,同時降低了模型訓練的難度。
3.7 模型性能的影響因素
由于在實驗過程中涉及到超參數的設置,而這些參數的取值也在一定程度上決定了模型最終的分類性能,因此下面討論部分參數對分類結果的影響,以及參數的優化規則。
3.7.1 詞向量維度
Embedding的主要功能是數據降維和稠密表示,實驗過程中使用多維向量來轉換字符序列和n-gram特征。實驗設置了幾個依次遞增的詞向量維度作為自變量,圖3展示了詞向量維度分別為50、100、150、200、250、300時的模型準確率。

圖3 向量維度與準確率關系圖
準確率(Accuracy)反映了全體預測正確占全部樣本的比例,是一個綜合評價指標。圖3統計了不同詞向量維度下的模型準確率,并且利用四次函數擬合出準確率的變化趨勢。從圖3中可以直觀看出,在向量維度等差增長的同時,準確率也在隨著自變量由快漸慢地增長,當維度數達到200時基本趨于平穩。
由此可知,當詞向量維度過低時通常表示能力不夠,模型的準確率也維持在一個相對較低的水平。當詞向量維度過高時,雖然模型的準確率相對較高,但在訓練過程中容易出現過擬合現象,同時伴隨Diminishing Return(收益遞減)[17]的產生。
3.7.2 批處理大小
批梯度下降法(Mini-batches Learning)能最準確地朝著極值方向更新參數,同時每次迭代選取批處理大小(batch_size)的樣本進行更新。圖4展示了批處理個數分別為64、128、192、256時的模型損失值。

圖4 批處理大小與損失值關系圖
同樣,使用四次函數來繪制損失值的變化趨勢,可以看出,損失值隨著自變量的增加而增加,且變化增幅趨于線性。經初步分析可知,當batch_size取值較小時,其每次迭代下降的方向并不是最準確的,Loss是在小范圍內震蕩下降的,這樣有利于跳出局部最小值,從而尋找下一個Loss更低的區域[18]。而當batch_size取值較大時,雖然減少了訓練時間以及加速了網絡收斂,但是Loss值會很大概率落入局部最小區域,最終影響模型的分類性能。
4 結論
文中提出一種基于fastText的惡意域名分類方法。通過提取域名字符以及n-gram特征來生成詞向量,使用隱藏層對向量進行全局平均池化,并將softmax與全連接層相結合來對惡意域名進行分類。實驗結果顯示,fastText模型的各項性能指標優于其他方法,同時模型復雜度和訓練難度也相對較小。實驗部分討論了影響模型性能的參數因素,比較了不同取值條件下模型的泛化能力。
下一步會研究如何進一步提升模型整體的分類性能,同時考慮如何將fastText更廣泛地應用在網絡安全領域中。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
