一種改進的全卷積神經網絡多聚焦圖像融合研究
2021-09-08 10:10:22魏輝琪劉增力
電視技術 2021年7期
魏輝琪,劉增力
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
0 引 言
日常生活中,人們在拍攝照片時不但要選擇拍攝清晰的攝像機,而且希望所拍景物里所有物體都具有清晰的質量。但由于攝像機會受到景深的限制,無法將拍攝的所有目標都聚焦,造成一張照片會有聚焦和非聚焦的部分[1-3]。如何將兩幅聚焦位置不同的圖像融合到一起,并且使融合后的圖像質量優良、細節信息豐富[4],一直是多聚焦圖像融合研究的熱點。
2007年,Nencini F等人將曲率變換應用于圖像融合,以期達到優異的視覺效果,實際融合效果優于使用Contourlet變換的融合算法。一些學者提出一種使用NSCT的多焦點圖像融合算法以及一種將NSCT和空間頻率激勵脈沖與支架一起使用的圖像融合算法。隨著深度學習和遷移學習領域的發展,越來越多的學者將深度學習廣泛運用到多聚焦圖像融合中。由于卷積神經網絡以生物神經元結構思想為起點,具備網絡結構方便快捷和特征提取良好性的能力,很多學者將卷積神經網絡(Convolutional Neural Networks,CNN)應用到圖像融合任務中。有學者提出自動設置融合規則的方法,成功擺脫了手動設置融合規則的限制[5]。文獻[6]和文獻[7]采用了整體學習策略基于投票的方法進行圖像融合。也有學者對卷積神經網絡模型進行了相應改進[8],提高了網絡利用率,但仍然存在融合后圖像邊緣細節信息模糊這一缺陷。
為解決以上問題,本文提出一種改進的基于全卷積神經網絡的多聚焦圖像融合算法。采用魯棒性主成分分析法(Robust Principal Component Analysis,RPCA)對原數據集進行特征提取;在網絡特征提取部分采用更小的網絡結構,達到提取更多特征信息的目的的同時減少了網絡層級;將全連接層換為全卷積層,通過softmax層對圖像進行分類,最后通過設置分類器防止樣本偏移;通過設計的網絡結構對數據進行訓練,最終得到決策圖,有效避免了細節信息丟失以及運算速率這一缺陷。
1 魯棒性主成分分析法
魯棒性主成分分析法是Karl Pearson等人提出的一種統計方法。它最主要的功能是幫助人們優化數據和篩選數據,目前在數學建模和機器學習等領域被廣泛使用[9-11]。魯棒主成分分析法可以良好地分離多聚焦圖像中的聚焦信息和非聚焦信息,達到保留圖像細節信息的目的。將多聚焦源圖像經RPCA處理后的結果表示為:
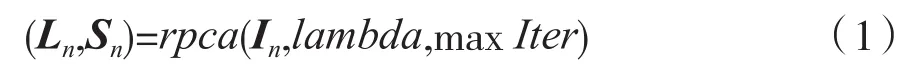
式中:Ln表示低秩分量;Sn表示稀疏分量;源圖像A和源圖像B表示為n=A,B;rpca(In,lambda,maxIter)表示圖像的RPCA分解;lambda表示代價函數中稀疏誤差項的權重。本文將lambda設為為輸入矩陣In的行數,tol設為10-7,maxIter設為1 000。
RPCA將輸入數據矩陣分解為低階主成分矩陣和稀疏矩陣。分解時間受輸入數據矩陣的矢量格式影響。本文首先在RPCA分解模型下對多聚焦圖像I∈Rm×n進行向量格式轉換,分解后得到D∈Rmn×1表示輸入矩陣。為了獲得低秩矩陣A∈Rmn×1和稀疏矩陣E∈Rmn×1,需要對輸入矩陣D∈Rmn×1進行RPCA分解,因RPCA分解模型分解后的低秩矩陣和稀疏矩陣圖像大小需保持和源圖像一致,因此還需對低秩矩陣A∈Rmn×1和稀疏矩陣E∈Rmn×1進行向量轉換,最終得到格式為A∈Rm×n、E∈Rm×n的低秩矩陣和稀疏矩陣。
本文對“時鐘”圖像進行RPCA圖像分解,分解結果如圖1所示。由圖1可以看出,兩幅源圖像中,稀疏矩陣的顯著信息位置和源圖像的聚焦區域位置幾乎對應。然而,在多聚焦圖像融合中,融合圖像是將兩幅源圖像的聚焦區域信息最大化提取之后進行合并,因此,多聚焦圖像融合問題可以轉化為RPCA分解模型中稀疏矩陣顯著信息位置的選擇和提取最大化的問題。因RPCA分解模型分解后的稀疏矩陣具有良好的魯棒性,符合多聚焦圖像融合中聚焦和細節信息保留最大化的要求,有利于融合圖像質量的提高[12]。

圖1 多聚焦圖像“時鐘”的RPCA分解效果圖
2 本文方法
2.1 數據集預處理
本文對數據集預處理的方法采用了指定區域采樣法的思路。該方法是將原清晰度圖像數據集通過濾波器模糊后,在指定位置進行塊提取和分割,得到以該圖像塊為中心的模擬多聚焦圖像。方法原理如圖2所示。
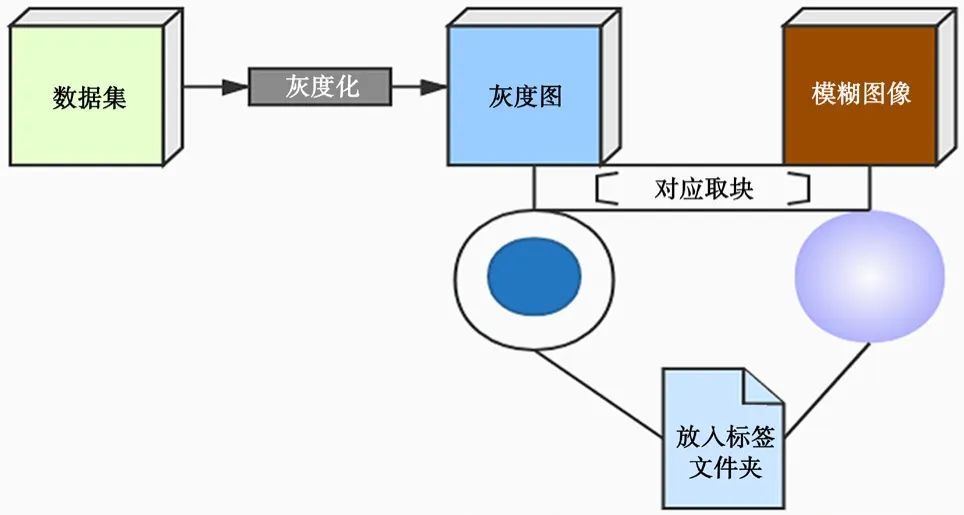
圖2 指定區域采樣法原理圖
PASCAL VOC是一種公認的圖像數據集基準,總共包含20類數據類型,類別包括動物、桌椅板凳及交通工具等。本文挑選了數據集中的4 000余張圖片用于制作圖像數據集,尺寸都標注為256*256。首先對每張圖片做高斯模糊處理,模糊處理半徑選為3,其次隨機截取模糊處理前的圖像的某一區域的圖片,最后將截取的部分區域與未進行模糊處理的相同區域進行替換,模擬出交叉模糊的方式,使得數據集更接近于真實的多聚焦圖像,使算法可以驗證多組且聚焦區域不同的多聚焦圖像。
2.2 網絡結構
本文提出的網絡模型,在經典的全卷積神經網絡模型上進行了改進,整個網絡結構如圖3所示。
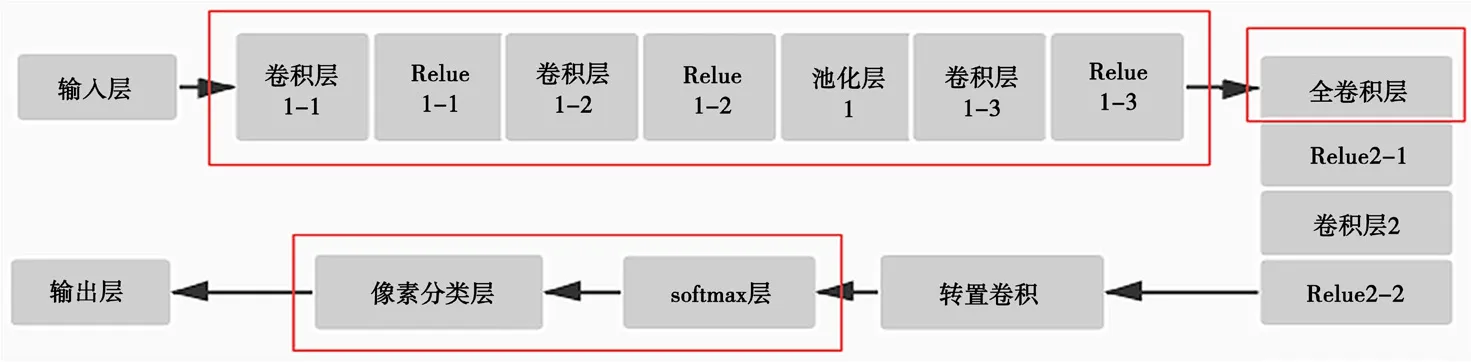
圖3 網絡結構圖
模型在特征提取部分采用3個卷積層和1個池化層。因多聚焦圖像在融合時只用提取到聚焦以及非聚焦重要信息,因此3個卷積層和1個池化層足以獲得所需的特征信息,如圖4所示。

圖4 特征提取部分網絡示意圖
圖像經過最大池化層壓縮后進入全卷積層,如圖5(b)所示。普通卷積神經網絡在對圖像識別時得到的是聚焦信息與非聚焦信息的概率分布;而全卷積神經網絡識別的結果是聚焦圖像和非聚焦圖像,圖像到圖像的傳輸可以使得整個網絡在訓練時的運算時間有所降低。
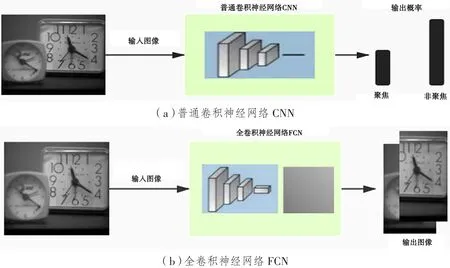
圖5 不同網絡中聚焦非聚焦識別過程
最終通過轉置卷積恢復圖像大小,通過softmax層以及權重設置進行像素分類。像素分類器可以確定聚焦、非聚焦像素的類別,達到防止樣本偏移的目的。
全卷積神經網絡結構參數如圖6所示。可以看出,本算法所訓練的網絡結構相較于以往的全卷積神經網絡結構而言層級更少。另外,本文網絡所用的卷積核大小為3×3,步長為1;池化層核的大小為2×2,步長為2。實驗表明,卷積核的選擇不宜太多或者太少,分別會造成分類結果較差和像素點提取過少,達不到特征信息提取的目的。池化的本質是數據壓縮,一方面抑制響應較低的信號,降低噪聲;另一方面減少需要學習的參數,降低網絡規模,在空間上實現感受野的增大,有利于使用較小的卷積核實現更大尺度上的特征學習。
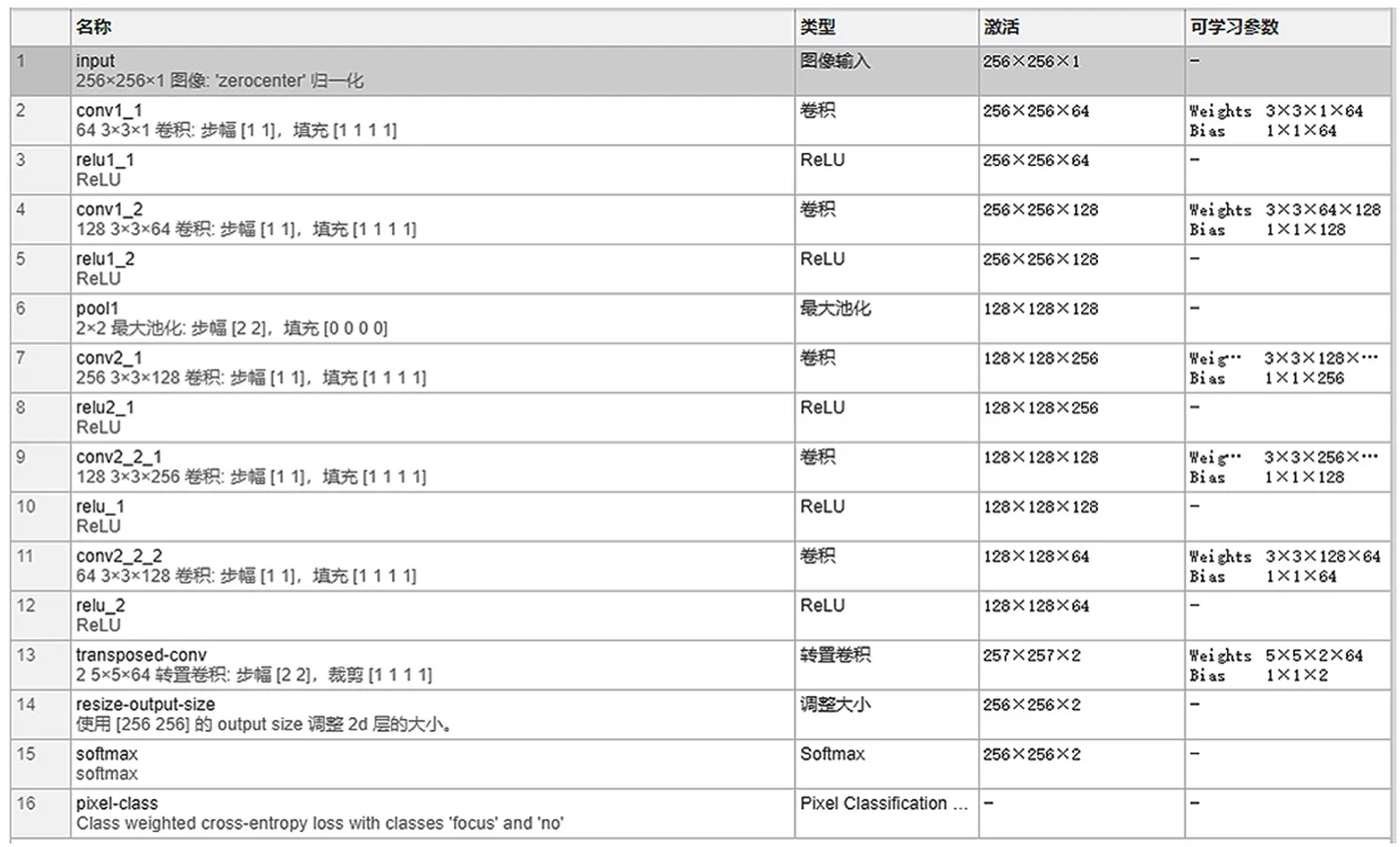
圖6 全卷積神經網絡結構參數
2.3 網絡訓練
將預處理好的數據集輸入到網絡結構中,開始訓練。本文訓練的基礎學習率為0.001,每訓練一次共4輪,每輪迭代393次,共1 572次。訓練導出的訓練曲線如圖7所示。從圖7可以看出,當訓練達到700次左右,損失降到最低并且在一定范圍內浮動,準確度達到最高并且在一定范圍內浮動。
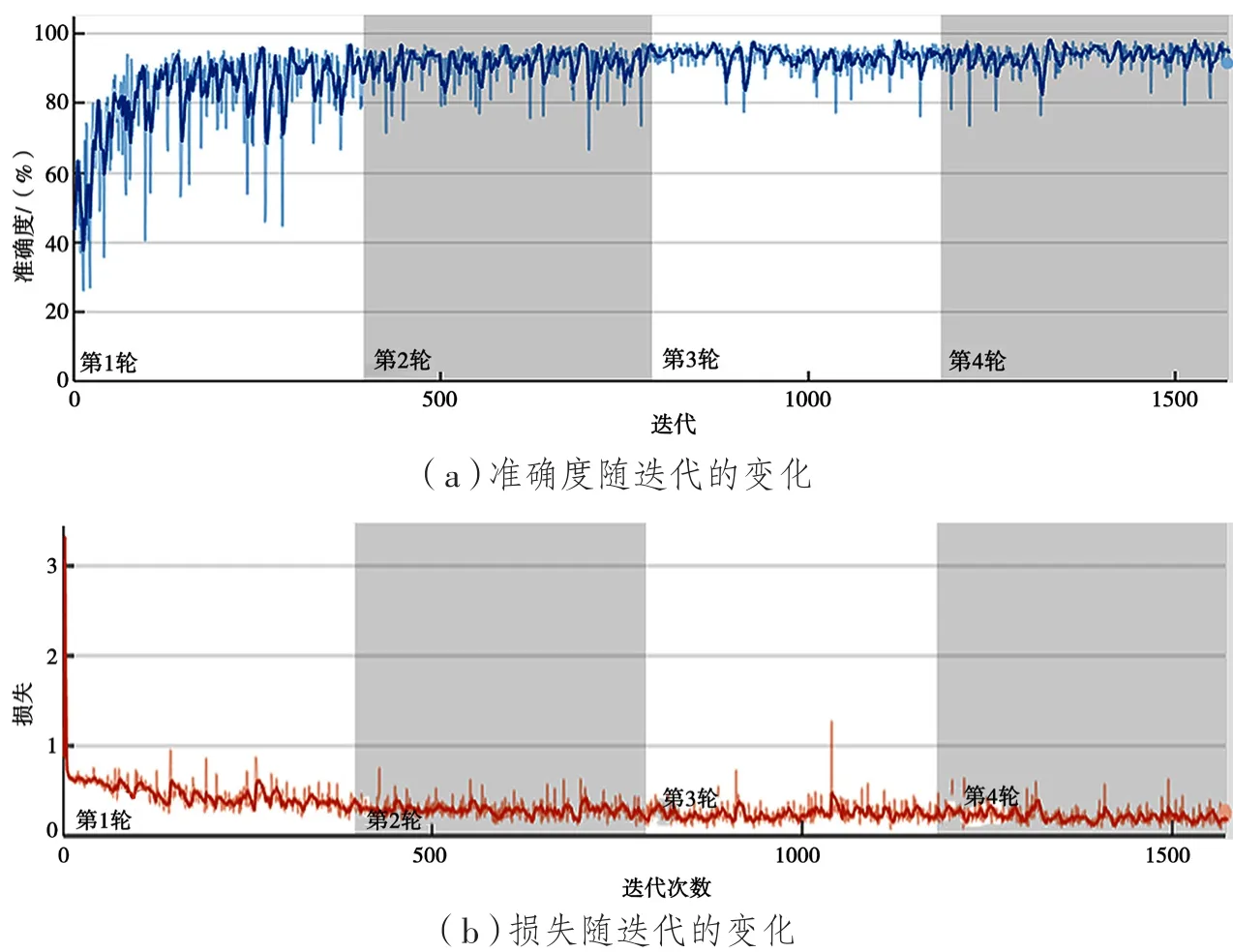
圖7 全卷積神經網絡網絡訓練圖
2.4 本文融合過程
通過RPCA對圖像進行特征提取,之后利用全卷積神經網絡模型進一步獲得特征以及決策圖,以決策圖為依據對圖像進行最終的融合。整個融合過程如圖8所示。
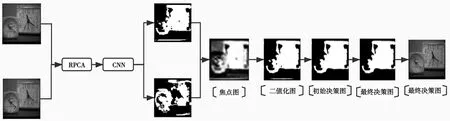
圖8 基于RPCA的卷積神經網絡圖像融合過程
融合過程主要分為3個步驟。
(1)網絡訓練。選擇合適的網絡參數;確定卷積層、池化層以及全卷積層的輸入與輸出,根據網絡特性選擇損失函數和激活函數;確定網絡訓練所需的學習率和總迭代次數等。
(2)用全連接層替換卷積層后,輸入圖像的大小就可以不受限制。可以一次性輸入網絡,根據圖片所有位置的檢測目標概率得到功能圖。
(3)生成決策圖。在本文算法中,網絡首先對圖像像素進行分類,輸出焦點圖。得到焦點圖后,通過二值化得到二值圖,進一步得到初始決策圖。對初始決策圖進行細節信息處理后得到最終決策圖。
3 實驗結果與分析
為驗證算法的有效性,將本文提出的融合算法與其他4種算法進行比較。其他算法分別是基于離散小波變換(DWT)[17]、非下采樣剪切波變換(NSST)[18]、非下采樣輪廓變換(NSCT)[19]以及卷積神經網絡(CNN)[16]。
作為驗證融合圖像質量的兩種重要方式,主觀評價和客觀評價缺一不可。本文采用主觀肉眼以及客觀指標評價兩種評價方式進行評價。客觀評價指標有信息熵(H)、互信息(MI)[13]、結構相似度(SSIM)[14]以及邊緣保持度融合質量指標QAB/F[15]。通過以上指標對本文的算法進行驗證。
信息熵的定義為:
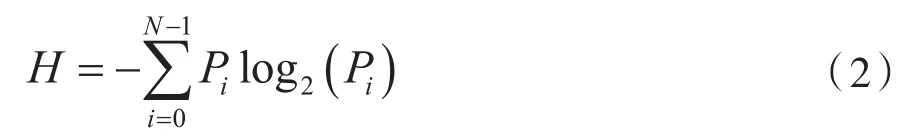
式中:N為灰度級;Pi為概率。
互信息量MI定義為:

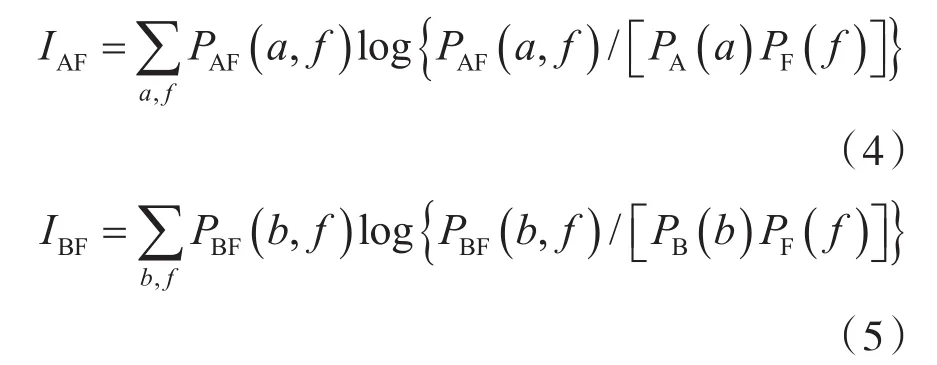
式中:a、b、f為源圖像A、B和融合圖像F的像素灰度值;PA(a)、PB(b)、PF(f)為概率密度函數;PAF(a, f)、PBF(b, f)為聯合概率密度函數。
結構相似度定義為:
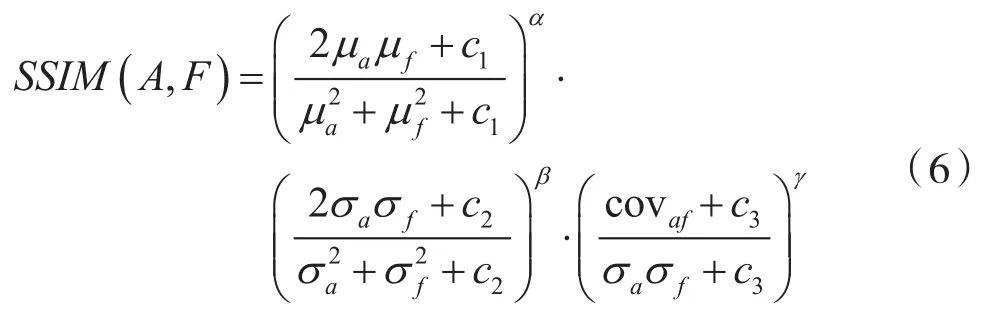
式中:F為融合圖像;A為源圖像;μa、μf為A和F間的均值;σa、σf為A和F間的標準差;covaf為A和F間的協方差;α,β,γ分別表示亮度、對比度及結構三部分的比例參數;c1,c2,c3表示三個常數。
邊緣保持度融合質量指標QAB/F的定義為:
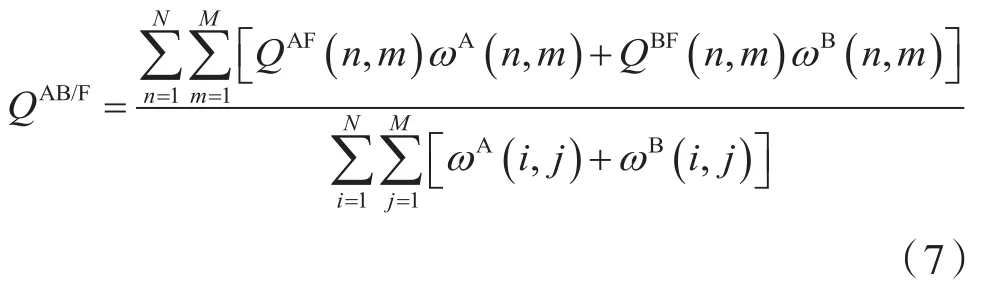
式中:M和N是圖像尺寸;QAF(n,m)、QBF(n,m)分別是融合圖像相對于原始圖像A和B的邊緣保持值;ωA(n,m)、ωB(n,m)是邊緣強度的函數;QAB/F∈[0,1]表示融合圖像相對于原始圖像A和B的總體數據保留,其值越大,融合圖像質量越高。
3.1 主觀評價
本文選取了4種融合方法測試圖像來進行算法驗證。圖像“時鐘”的融合結果如圖9所示。其中,圖9(a)和圖9(b)分別為聚焦源圖像A和聚焦源圖像B;圖9(c)、(d)、(e)、(f)、(g)分別為算法DWT、CNN、NSST、NSCT以及本文算法的融合結果。

圖9 “時鐘”融合結果圖
從“時鐘”實驗融合結果可以看出,基于DWT、NSST以及NSCT算法融合后的圖像都出現了不同程度的“偽影”現象,融合效果不理想。而CNN算法的結果則可以看到融合后的邊緣細節部分出現了丟失。
為更方便、清晰地觀察本文網絡結構算法與卷積神經網絡算法融合圖像后的效果差異,使用對比軟件對實驗結果“時鐘”圖分別在基于卷積神經網絡(CNN)算法與本文全卷積神經網絡(FCN)算法產生的融合結果進行差異對比,可以清楚地看出結果的差異,如圖10中紅色區域所示。

圖10 “時鐘”融合圖CNN與FCN對比差異
3.2 客觀評價
表1列出了使用上述4個客觀評價指標以及運算速度針對5種不同融合方法的評價結果。從實驗結果可以看出,本文提出的算法的互信息、結構相似度等指標都高于其余4種方法,即使在圖像清晰度以及互信息方面與目前運用較廣泛的CNN算法相差不多,但是在運算速率上大大提升,說明了本文算法的優越性和有效性,更具有應用價值。

表1 針對“時鐘”融合圖像的評價指標結果
4 結 語
本文提出了一種改進的全卷積神經網絡多聚焦圖像融合算法,與傳統算法RPCA相結合,在圖像特征信息過程提取到了更多有用信息。網絡結構輕便、快捷,使得算法在整個融合過程既保證了融合質量的提升又節省了運行時間。實驗結果表明,該算法在保持邊緣信息、整體融合圖像的質量以及運算速度上有一定提升,具有一定的研究價值。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
