基于基分類器系數和多樣性的改進AdaBoost算法
2021-09-09 08:09:20朱亮,徐華,崔鑫
計算機應用 2021年8期
關鍵詞:分類
朱 亮,徐 華,崔 鑫
(江南大學人工智能與計算機學院,江蘇無錫 214122)
0 引言
集成學習是機器學習研究領域的重要分支,它并非力求得到單一最優分類器,而是按照一定策略集成一組個體分類器。就像小組會中的投票表決一樣,需要考慮每個人的意見,以提高決斷的正確性。而Boosting[1]就是集成學習中的代表算法,它可將簡單的、粗糙的、略比隨機猜測好點的分類器,通過一定規則構造出一個復雜且精度高的強分類器[2],隨著Freund等[3-4]對Boosting的研究改進,它成為最流行的分類算法之一[5-6],但是很難運用于實際中。自從1999年Schapire等[7]提出AdaBoost后,才真正將集成學習運用于實際問題。很多學者從統計學和間隔理論的方向,對AdaBoost的成功進行了解釋[8-9]。由于AdaBoost的優秀表現,它被廣泛應用于機體運動估計[10]、軸承的故障診斷[11]、交通風險預測[12]、醫學診斷[13]、電力系統[14]、聲吶圖像[15]等現實問題中。
集成學習面臨的問題主要在于兩個方面:一是基分類器的選取;二是基分類器的組合。集成的泛化誤差[16]由基分類器的平均泛化誤差和平均多樣性決定,文獻[17]提供了更一般的整體泛化誤差的表現形式,以及方差、協方差、偏差、噪聲方差對泛化誤差的影響。現在存在一個被廣泛接受的觀點是選出的基分類器既要精確也要多樣,但關于多樣性度量對于集成學習的影響沒有學者給出嚴格的證明[18],也就是說,多樣性有助于集成算法的設計。如文獻[19]利用多樣性提出了基于聯結樹的多元信息多樣性近似估計方法,解決了高階信息及高階分布難以估計的問題。文獻[20]研究了集成學習中的泛化誤差和受試者工作特征曲線下的面積(Area Under Curve,AUC)分解定理,在此基礎上得出多樣性與間隔關聯的結論,進一步研究了基分類器的權重更新策略,并提出更有效的算法。2018年,王玲娣等[21]研究發現雙誤度量(Double Fault,DF)與傳統AdaBoost相關性最高,并基于雙誤度量提出了WLDF_Ada算法,改進后的算法取得了更好的效果。文獻[22]于2018年提出具有健壯的閾值機制和針對回歸問題的結構優化,基學習器在問題數據集上的錯誤統計信息可用于自動選擇最佳臨界閾值,保證了基學習器的多樣性,并結合單層神經網絡進一步調整模型結構和增強適應能力。文獻[23]通過將參數引入到傳統AdaBoost的權重調整中,抑制間隔從正到負的移動,防止已分對的樣本再次被錯分,提高了算法的收斂速度和分類精度。文獻[24]表明,傳統AdaBoost算法在訓練中樣本權重容易發生退化,于是調整正負誤差之間的偏重關系控制訓練樣本權重變化,表明樣本權重分布影響算法性能。高敬陽等[25]在2014年提出基于樣本抽樣和權重調整的改進SWA-Adaboost算法,通過對樣本的均勻抽樣和減緩錯分樣本的權值增長速度,能有效提高算法的分類效果。2018年,吳戀等[26]提出基于AdaBoost的Linux病毒檢測算法(簡記為AD_Ada(Adaptive to Detection AdaBoost)),采用了更為有效的基分類器參數求解方法,基分類器的加權參數與錯誤率和對正樣本的識別率均有關,有效地降低了在相同正樣本錯誤率的條件下負樣本的錯誤率,提高了算法的識別精度[27]。在文獻[28]中研究了基分類器對樣本有效鄰域分類的動態加權AdaBoost算法,根據基分類器針對有效領域的分類結果以及考慮數據分布狀態,從而能更好地篩選分類器。文獻[29]在2017年提出了參數化的AdaBoost算法(簡記為Pa_Ada),改進樣本權值的調整策略,進而優化了損失函數,從而加快收斂。邱仁博等[30]于2016年提出一種改進的帶參數AdaBoost(IPAB)算法,考慮更小顆粒的樣本權值更新,同樣起到優化損失函數的作用。
以上研究表明基分類器在系數和多樣性上的改進,對于提升傳統AdaBoost算法性能具有積極作用。因此,本文對基分類器系數的計算公式進行了優化,引入雙誤度量改變基分類器的選取策略,將這兩方面的優點結合后,本文提出一種改進的AdaBoost算法,即WD AdaBoost(AdaBoost based on Weight and Double-fault measure)算法,與傳統AdaBoost算法相比,它能更高效地集成基分類器,并且分類器間有更高的多樣性。
1 相關工作
1.1 基分類器間的多樣性度量
現在普遍的觀點是基分類器之間的多樣性越強,集成后模型的泛化能力越強。多樣性度量與集成學習之間的研究主要集中在以下三個方面:1)多樣性度量方法與集成學習的結合;2)多樣性對集成學習的影響及相關性;3)如何利用多樣性度量來改善集成系統,提升集成算法的分類性能。成對多樣度量是定義在兩個分類器上的,假設分類器的集合R={r1,r2,…,rn},ri和rj(i≠j)為兩個不同的分類器,它們對同一組樣本的關系矩陣如表1所示,其中樣本總數為m,在表1中,n11代表被ri和rj共同分對的樣本數目,n00代表被ri和rj共同分錯的樣本數目,n10代表被ri正確分類、rj錯誤分類的樣本數目,n01代表被ri錯誤分類、rj正確分類的樣本數目,并且它們滿足式(1):


表1 分類器預測結果關系矩陣Tab.1 Relation matrix of classifier prediction results
當前對于兩個不同學習器間預測結果的多樣性度量主要有四種,分別為Q統計、相關系數ρ、不一致度量(Disagreement Measure,DM)和雙誤度量(Double Fault,DF)。接下來分別介紹這四種多樣性度量。
1)Q統計。
Q統計來源于統計學領域,計算方式如下:

由式(2)可知,Q統計的取值范圍是[-1,+1]。Qi,j=1表示兩個學習器差異性最小,Qi,j=-1表示兩個學習器差異性最大。
2)相關系數ρ。
ρ與Q統計具有相同的符號,代表的意義也相似,即值越小則學習器之間的差異性越大。
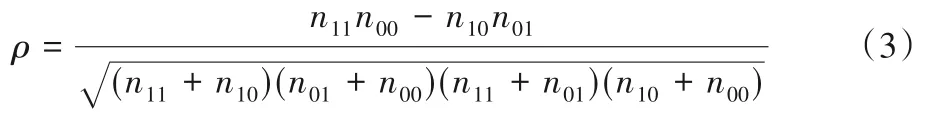
3)不一致度量(DM)。
不一致度量更關注兩個分類器之間的差異,不同分類器所占比例越大,則DM的值越大,代表分類器多樣性越大。

4)雙誤度量(DF)。
DF關注的是兩個分類器在相同樣本上出錯的情況,取值范圍[0,1],最差的情況是兩個分類器的錯誤率都是100%,此時DF的值為1,分類器的正確性與多樣性同時降到最低。計算公式如下:

評價一組分類器R={r1,r2,…,rn}的多樣性,需要計算每對分類器之間多樣性的平均值,見式(6)。其中——Div表示一組分類器的整體多樣性,Div表示兩個分類器之間的多樣性。
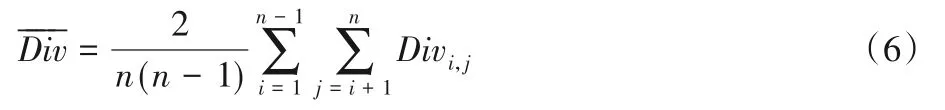
1.2 傳統AdaBoost算法存在的問題
在AdaBoost算法的研究中,如何最佳組合基分類器,一直是研究的熱點,典型的組合系數有簡單多數投票法、簡單加權投票法、傳統AdaBoost經典組合方法等,以上組合方法有一個共同的不足之處,即基分類器系數僅由錯誤率給出,然而體現基分類器的性能優劣的方面很多,僅用錯誤率的計算作為組合系數不夠全面,基分類器系數的設計應考慮到多種因素。
其次,傳統AdaBoost算法選取基分類器是以基分類器的最小錯誤率為標準,若樣本中存在大量的噪聲或錯誤樣本,算法很容易過適應,由于歸一化的作用,已經正確分類的樣本在過適應的情況下,權重變得較小,下一次可能被錯分,并且它沒有考慮到兩個分類器的差別很小或是無差別時的情形,這會導致算法退化,這在一定程度上解釋了直接最小化誤差上界來改進傳統AdaBoost算法效果不大。
2 算法的分析與改進
2.1 基分類器的系數改進與分析
在傳統AdaBoost算法中,基分類器系數如式(7)所示:

本文對樣本權重分布狀態的定義如式(8)所示:

而對基分類器系數重新定義為式(9),k為大于零的常數。
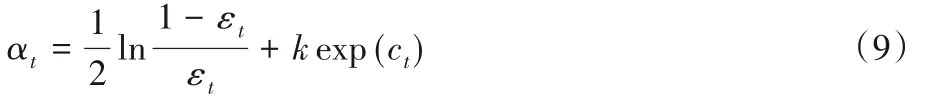
其中:t∈[1,T](T表示基分類器的個數);αt為第t次迭代基分類器的系數;εt為第t次迭代基分類器的分類錯誤率;ct表示第t次迭代時正確分類樣本權重的累加和,它能夠反映樣本權重分布狀態。
基分類器系數可以在分類器集成時,決定其作用的大小。樣本的權重分布狀態,體現了基分類器的分類效果,在基分類器系數計算時,應加入對樣本權重分布狀態的考慮。由于算法對分類錯誤的樣本賦予更大權重,隨著迭代的不斷進行,分類錯誤的樣本越來越少,但它的權重在不斷變大,在歸一化的作用下,所有樣本的權重之和為1,可能導致一部分正確分類的樣本權重過小。因此,ct的大小,反映了樣本分布狀態的好壞程度。若ct較大,說明樣本被分正確分類的數量較多,可能僅剩下少量難分或噪聲樣本,換言之,基分類器的性能較好,需要提高它在集成時的權重;若ct較小,表示錯誤分類的樣本數量較多或難分樣本的權重過大,即基分類器的性能較差,在集成時應減小它的權重。
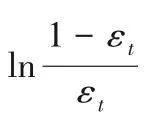
2.2 基分類器選擇策略的改進與分析
文獻[20]的研究表明:雙誤度量與測試誤差的皮爾遜相關系數值最大,表明雙誤度量與測試誤差之間的相關性最高。接下來將分析雙誤度量運用在本文算法中的可行性,并且介紹基于雙誤度量的基分類器選擇策略。
傳統AdaBoost算法使用單層決策樹訓練基分類器,在訓練的過程中不斷減小誤差的上界,進而獲得精度非常好的強分類器。由于基分類器的選擇以最小錯誤率為標準,會使算法容易過適應,不能保證有良好的泛化性能,文獻[3]中推導出的誤差上界公式如下:

式(10)表明,理論上通過多次迭代能把錯誤率降到接近于0,但在實際操作中算法很容易過適應,因為僅以錯誤率選擇基分類器,會使分類器同質化,將同質化的基分類器進行組合不會提高算法的精度。
為了增強算法的泛化能力,基分類器既需要差異化,也需要保證其分類性能。在式(5)中,當DF變小時,表示n00減少,等價于n01+n10+n11增加,若n01+n10增加,說明基分類器之間的多樣性增大。若n11增加,說明強分類器的精度提升。雙誤度量既能增加分類器的多樣性,又能保證分類器的性能,根據上述分析選擇雙誤度量可行,基于DF的基分類器選擇策略如下:
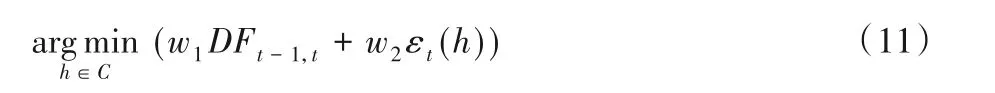
其中:DFt-1,t表示候選基分類器與上一輪迭代中已被選中基分類器之間的DF值;w1為已經加入集成的前t個基分類器之間的平均DF值;w2表示選擇基分類器時,錯誤率在選擇策略中的所占比重,且w1+w2=1。根據式(6)可得:
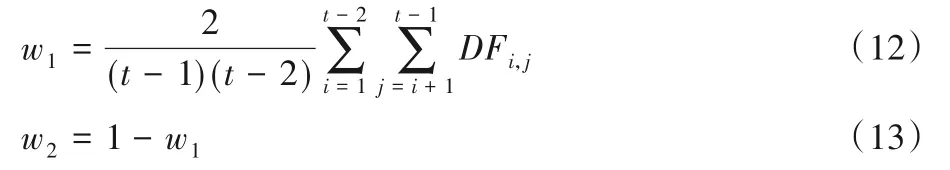
根據式(12)和式(13)可知,若是迭代中的整體平均DF值有增大的趨勢,就會增加DFt-1,t在選擇標準中的比重,控制對共同錯分樣本的關注,增加基分類器的多樣性,提高泛化性能。
2.3 改進后的算法流程
基分類器一般選用簡單分類器,大量的實驗研究表明,集成算法使用單層決策樹作為基分類器,可使算法性能表現較好。所以,本文算法使用單層決策樹訓練基分類器。WD AdaBoost算法流程如下。
步驟1 給定訓練集:
S={(x1,y1),(x2,y2),…,(xi,yi),…,(xm,ym)}其中,xi是實例樣本,有xi∈X;yi是類別標志,且yi∈Y={-1,+1},m表示訓練樣本個數。
步驟2 初始化:
Dt(i)=1/m,EDFmin=+∞,ht(xi)=null
步驟3 循環t=1,2,…,T:
1)根據式(12)和式(13)計算出w1和w2
2)循環樣本的每一特征
計算EDF=w1DFt-1,t+w2εt(h)
如果EDF EDFmin=EDF 3)針對選定的ht(xi),計算加權錯誤率 4)計算正確分類的樣本權值和 5)求解基分類器ht(xi)的加權參數 6)樣本權值更新為 其中,Zt是歸一化因子,即: 步驟4 得到強分類器: 顯然,這兩個部分的優化沒有改變傳統AdaBoost算法的結構,WD AdaBoost算法仍然按照貪心策略迭代,保證了算法的可收斂性。 WD AdaBoost算法使用的基分類器系數,可更好地用于基分類器的集成,將雙誤度量引入到基分類器的選擇策略中,能大幅削減噪聲樣本的影響。下文將分析樣本權重的更新,以及k的求解。 本小節將分析基分類器的系數與多樣性結合后,在樣本權重更新策略上的優化作用。從式(17)中可以看出分子有αt,分母Zt中也含有αt,無法對樣本權重的更新進行定量分析,需要將樣本權重與錯誤率之間建立等式。首先,對式(18)進行展開,得到Zt與εt之間的關系式。式(18)等價于式(19): 由式(14)可得正確分類樣本權重和與錯誤率之間的計算,如式(21)所示: 將式(14)和式(21)代入式(20)中,消去樣本的權重和,得到Zt只與εt有關的等式(22),如下所示: 1)當ht(xi)=yi時: 2)當ht(xi)≠yi時: 接著,還要與傳統AdaBoost算法的樣本權重的更新過程作對比,以下簡單推導傳統AdaBoost算法樣本權重的更新關系式。 同WD AdaBoost的推導過程一樣,可得傳統AdaBoost算法樣本權重的更新公式如下: 1)當ht(xi)=yi時: 2)當ht(xi)≠yi時: 接下來對式(23)與式(25)、式(24)與式(26)進行討論: 相比于傳統AdaBoost算法,通過1)可以看出WD AdaBoost算法可使正確分類的樣本權重更小,由2)可知WD AdaBoost使錯誤分類樣本更新后的權重值更大,從3)可得樣本權值更新后,正確分類的權值小于錯誤分類的權值。綜合以上三條結論可知:改進的αt會使基分類器更加關注難分的樣本,所以,算法分類精度也更高,同時對噪聲更為敏感;但基分類器的選擇策略加入了雙誤度量,分散了對難分樣本的關注程度,增加了基分類器之間的多樣性,兩者相互作用降低了噪聲的干擾,增加了分類器的泛化能力,提高了算法的精度。為了使二者產生最好的融合效果,需要對k進行討論。 WD AdaBoost并沒有改變傳統AdaBoost算法的結構,但k的選取決定了改進后的算法能否滿足傳統AdaBoost算法的誤差收斂上界,所以,k在選取時仍要保證每一次迭代都要滿足Zt<1。k取值范圍的推導過程如下: 即: k要滿足在所有基分類器上面不等式成立,由上式可解出當k<1/120時,對應的錯誤率εt<0.494,則每一輪基分類器的誤差上界都可以滿足Zt<1。εt<0.494可以保證WD AdaBoost算法的可收斂性,但由公式解不出k的最佳取值。因此,k的取值合理即可,但k太小,由式(9)可知算法會退化到傳統AdaBoost基分類器系數計算公式上。所以,k的取值是在一個區間上。 綜上所述,基分類器系數整合了錯誤率和樣本權重分布狀態,二者共同作用于基分類器,比單一地依靠錯誤率評價分類器更加準確,基分類器系數結合雙誤度量優化了樣本權重的更新過程,使之在關注難分樣本同時又增加了分類器的多樣性。WD AdaBoost算法也可以看作通過避免算法過擬合,優化基分類器的集成,使得每次迭代產生的基分類器能保持最小錯誤率上界下降,從而達到優化傳統AdaBoost的目的,提升算法的分類效果。 本文實驗分為5個部分:實驗一驗證本文所提基分類器求解方法的有效性;實驗二驗證加入雙誤度量能有效防止算法過適應;實驗三選取最合理的k值,保證WD AdaBoost算法有最大準確率;實驗四研究WD AdaBoost與其他算法相比,其收斂速度的快慢,為本文算法以后應用于實際問題提供參考;在實驗五中,為驗證本文算法的有效性,將WD AdaBoost與其他幾種改進的AdaBoost算法做對比實驗。實驗數據集來自不同的實際應用領域,具體信息見表2。 表2 實驗數據集Tab.2 Experimental datasets 本次實驗中,sk_AdaBoost算法來自python機器學習工具箱scikit-learn,將使用式(9)作為基分類器系數的AdaBoost算法記為CeffAda,使用表2中的數據集,采用十折交叉驗證,表3將給出在每個數據集上10次訓練誤差和測試誤差的平均值,基分類器數目為50個。 表3 不同基分類器系數下的誤差比較Tab.3 Error comparison under different base classifier coefficients 分析表3可得,在5個數據集上,CeffAda比sk_AdaBoost的測試誤差平均降低1.2個百分點。在sonarM數據集上,CeffAda算法比sk_AdaBoost算法的誤差低3.43個百分點。在german3、pimax、chessM數據集上,CeffAda算法比sk_AdaBoost算法平均降低了1.08個百分點。在breastM數據集上,sk_AdaBoost算法僅比CeffAda算法低0.14個百分點,綜上所述,CeffAda算法的精度在4個數據集上領先,而sk_AdaBoost算法的精度僅在1個數據集上領先,說明本文所提的基分類器系數求解方法有效。 在本次實驗中,WD AdaBoost為本文算法,使用表2中的數據集,采用十折交叉驗證,表4將給出在每個數據集上10次訓練誤差和測試誤差的平均值,基分類器數目為50個。 表4 兩種算法的誤差比較Tab.4 Error comparison of twoalgorithms 分析表4可知,在sonarM數據集上,CeffAda算法的訓練誤差收斂到0,但測試誤差卻是15.43%,CeffAda算法明顯過適應,而WD AdaBoost算法訓練誤差為0.22%,測試誤差為15.14%,WD AdaBoost算法沒有表現出過適應現象。在german3、pimax、sonarM數據集上,CeffAda算法的訓練誤差均小于WD AdaBoost算法,但測試誤差卻比WD AdaBoost算法高,說明WD AdaBoost的泛化能力更好。在chessM和breastM數據集上,二者均表現正常,以上分析表明DF能有效防止算法過適應。 在k<1/120的條件下,能保證算法的可斂性,為防止k值太小導致算法退化。因此,k在0.008 3、0.008、0.007 7、0.007 4、0.007 1、0.006 8中進行實驗,從0.006 8到0.008 3可以看作是一個不連續的區間,實驗要在這個區間里找出最合理的值。本次實驗采用10折交叉驗證,取10次測試誤差的平均值。通過圖1可以看出:當k=0.008 3時,本文算法在pimax、sonarM、chessM三個數據集上表現最好;當k=0.008時,本文算法在german3、pimax、chessM數據集上表現最好;當k=0.007 7時,本文算法在chessM和breastM數據集上表現最好;當k=0.007 4時,本文算法在breastM數據集上表現最好;當k=0.007 1時,本文算法在chessM和breastM數據集上表現最好;當k=0.006 8時,本文算法在chessM數據集上表現最好。將k在不同值下的最優取值次數繪制成一個簡單的表格,如表5所示。 圖1 不同k值下本文算法的分類效果Fig.1 Classification effect of the proposed algorithm under different k values 由表5可以看出k在0.0083與0.0080時,本文算法效果最好,但k=0.008 3時的最大誤差為0.242,最小誤差為0.04;而k=0.008 0時的最大誤差為0.241,最小誤差為0.037。k=0.008 0時的最大誤差和最小誤差均小于k=0.0083時的最大和最小誤差。所以,k=0.0080最合理。 表5 最優取值次數統計Tab.5 Statistics of times of optimal value 為了更好地驗證WD AdaBoost算法的穩定性,實驗四采用10折交叉驗證,在不同迭代次數下,比較WD AdaBoost與sk_AdaBoost、WLDF_Ada、AD_Ada、SWA_Adaboost、Pa_Ada、IPAB六種算法10次訓練誤差的平均值,實驗結果如圖2所示。在german3上,WD AdaBoost、sk_AdaBoost、WLDF_Ada、AD_Ada、SWA_Adaboost迭代20次后收斂,Pa_Ada迭代5次后收斂,IPAB迭代45次后收斂。在pimax上,WD AdaBoost、sk_AdaBoost、WLDF_Ada、AD_Ada迭代15次后收斂,Pa_Ada迭代5次后收斂,SWA_Adaboost在迭代25次后收斂,IPAB在迭代35次后收斂。在sonarM上,WD AdaBoost、sk_AdaBoost、AD_Ada、WLDF_Ada同時在迭代49次后收斂到0,SWA_Adaboost、Pa_Ada、IPAB在迭代30次后收斂,只有IPAB在迭代35次后完成收斂。在chessM上,WD AdaBoost、WLDF_Ada、AD_Ada在迭代5次后完成收斂,sk_AdaBoost在迭代10次后完成收斂,IPAB、SWA_Adaboost、Pa_Ada在迭代45次后收斂。在breastM上,WD AdaBoost、sk_AdaBoost、WLDF_Ada、AD_Ada迭代45次后完成收斂,SWA_Adaboost、Pa_Ada、IPAB在迭代40次后開始收斂,之后仍然有輕微波動。綜上可得,WD AdaBoost收斂速度與sk_AdaBoost、WLDF_Ada、AD_Ada相比,收斂速度幾乎無差別,與Pa_Ada相比有一定的優勢,與SWA_Adaboost、IPAB相比有較大優勢,說明WDAdaBoost算法在訓練時間上達到了較好效果,在強調訓練速度的應用場景,WD AdaBoost不失為一個好的選擇。 圖2 七種算法的收斂速度對比Fig.2 Convergence speed comparison of seven algorithms 本次實驗,對比7種不同算法的測試誤差,使用表2中的數據集,采用十折交叉驗證,表6將給出每個數據集10次測試誤差的平均值,基分類器數目為50個。 表6 不同算法的測試誤差比較Tab.6 Comparison of test error of different algorithms 分析表6可知,在german3、pimax、sonarM、breastM數據集上,WD AdaBoost都優于其他6種算法:在german3數據集上對比其他6種算法平均降低7.49個百分點;pimax數據集上最高降低40.26個百分點,平均降低12.43個百分點;sonarM數據集上最高降低14.93個百分點,平均降低4.65個百分點;breastM數據集上最低降了0.29個百分點,平均降低0.84個百分點;只有在chessM數據集上WD AdaBoost算法的精度不及AD_Ada算法,但二者并沒有很大的差別,AD_Ada算法精度只比本文算法高0.06個百分點,這個差值可以忽略。以上實驗結果表明WD AdaBoost算法具有更好的分類能力與泛化性能,驗證了本文理論的正確性。 傳統AdaBoost算法只將錯誤率作為基分類器的系數,設計也沒有體現防止過擬合的思想,導致泛化能力與分類性能較差。基分類器的權重計算與多樣性結合是優化傳統AdaBoost算法的一個重要思路,WD AdaBoost算法基于這一思路將樣本權重分布狀態進行量化,并結合錯誤率對基分類器的系數進行了改進。將新的系數公式與雙誤度量結合起來,既提高了分類器的組合效率,又優化了分類器的選擇策略。但在WD AdaBoost算法的基分類器系數中,求解不出k的最佳取值,下一步會繼續研究基分類器系數的求解方法,并尋找更適合WDAdaBoost算法的多樣性度量方式。


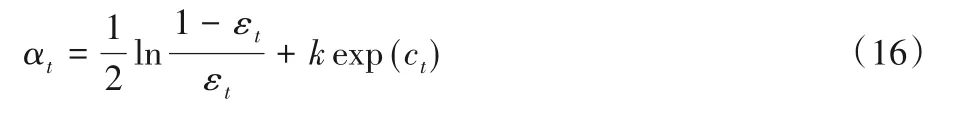
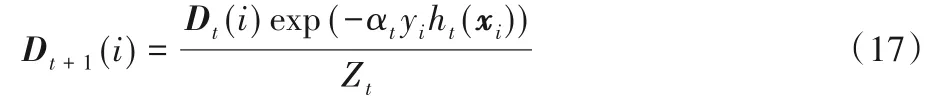
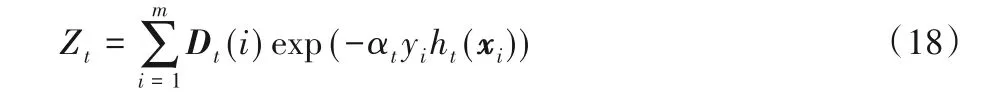
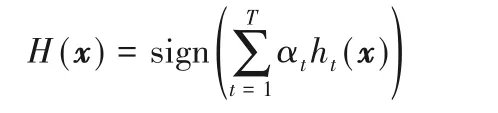
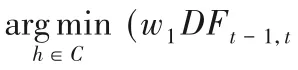

3 WD AdaBoost樣本權重更新分析
3.1 樣本權重的更新
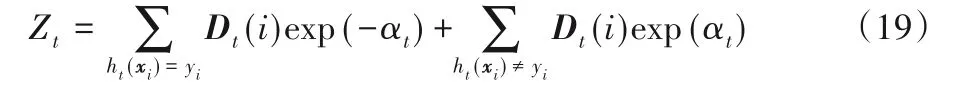
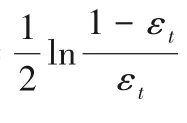
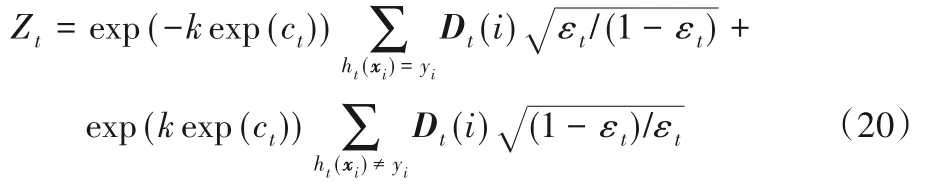

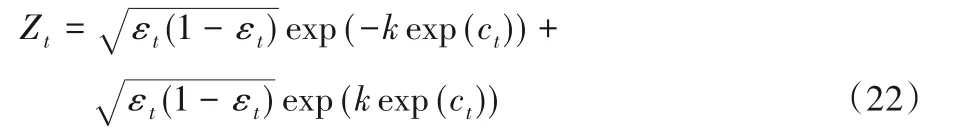
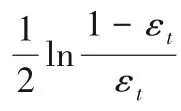
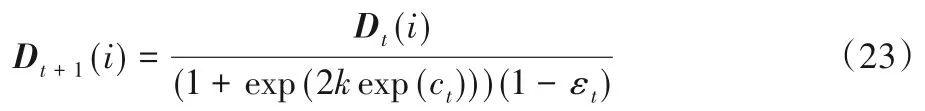
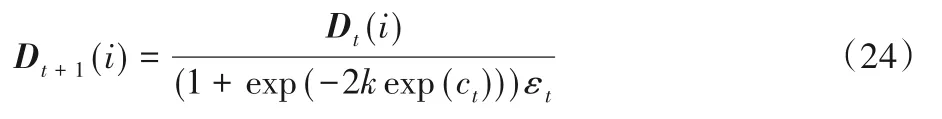
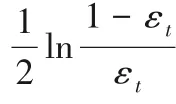


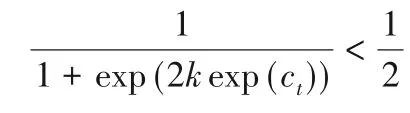
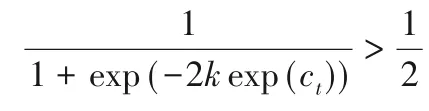
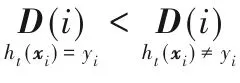
3.2 對k的分析
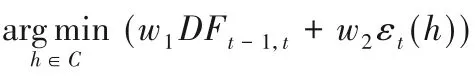
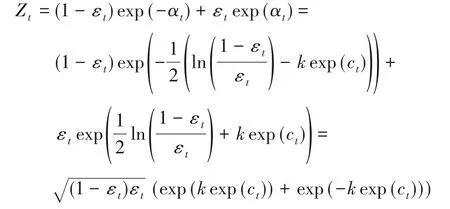
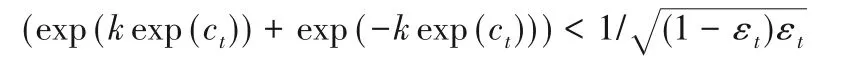
4 實驗
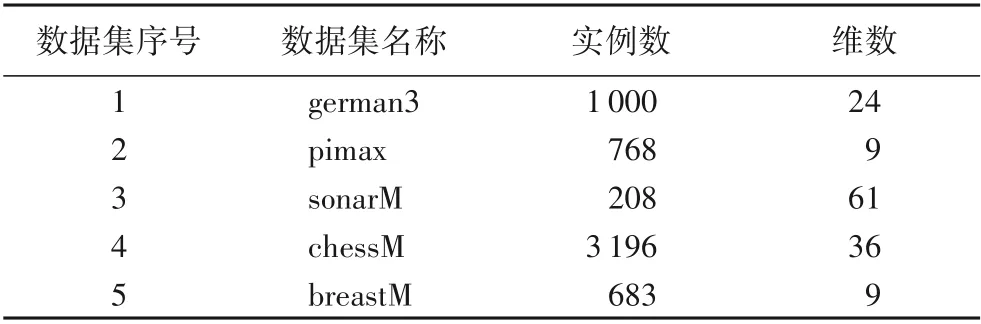
4.1 實驗一的結果與分析
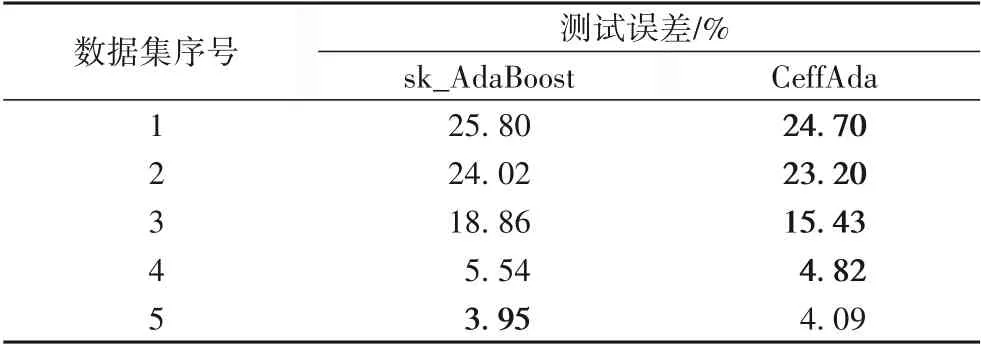
4.2 實驗二的結果與分析

4.3 實驗三k值的選取

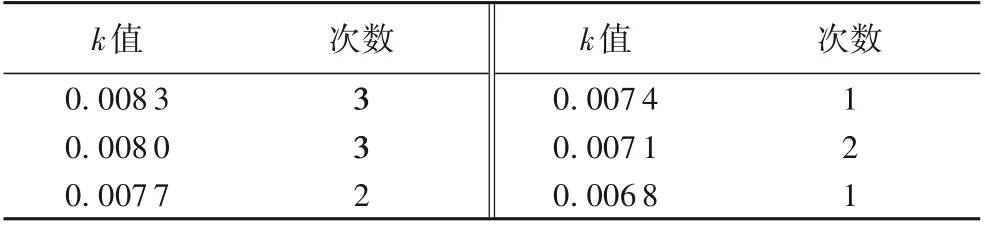
4.4 實驗四不同算法收斂速度的對比與分析
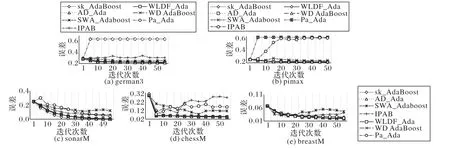
4.5 實驗五的結果及分析
5 結語
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
