基于徑向基函數的多目標回歸特征構建算法
2021-09-09 08:09:20嚴海升馬新強
計算機應用 2021年8期
嚴海升,馬新強
(重慶文理學院人工智能學院,重慶 402160)
0 引言
在傳統的回歸問題中,每個樣本由一個特征向量和唯一的連續型輸出變量表示。假設X=Rd為d維特征空間,y∈R為連續型變量,傳統的回歸算法是從訓練集{(xi,yi)|1≤i≤N}中學習得到函數f:X→y。每個樣本只具有一個輸出變量,對應唯一的語義信息。而在現實世界中學習對象往往會很復雜,同時具有多種語義,對應多個輸出。多目標回歸(Multi-Target Regression,MTR)是一種專門針對學習樣本同時具有多個輸出目標的回歸問題[1]。在多目標回歸問題中,X=Rd表示d維特征空間,Y=Rm表示的m維輸出空間,每個樣本(xi,yi)由一個d維特征向量xi=[xi1,xi2,…,xid]和一個m維目標輸出向量yi=[yi1,yi2,…,yim]表示,學習的任務是從訓練集中學習得到函數h:X→Y,為未知樣本同時預測多個連續型的輸出值。目前,多目標回歸已經在計算機視覺[2]、醫學圖像分析[3]、生態建模[4]等領域取得了廣泛的應用,成為機器學習領域的研究熱點之一。
與傳統的回歸問題相比,多目標回歸更加復雜,面臨更多的挑戰。首先,多目標回歸需要處理特征空間到多個不同的輸出目標的映射關系,而這種映射關系可能是線性的,也可能是非線性的。此外,在多目標回歸問題中,一個樣本具有多個輸出變量,對應多種語義,而這些語義通常不是相互獨立,而是相互關聯的。對各輸出目標之間的關聯關系進行挖掘,有助于提高多目標回歸的整體預測性能。總體來說,多目標回歸面臨的挑戰[5]可以歸結為:1)處理輸入特征與多個輸出目標之間復雜的映射關系;2)如何有效地發掘輸出目標之間的關聯,提高預測性能。為解決多目標回歸問題,人們提出了很多多目標回歸算法。一種直觀的思路是為輸出空間的每個輸出目標訓練一個獨立的回歸模型,這類算法簡單、直接、運行效率高;另一種思路是將其他目標的輸出作為額外的特征,構建回歸模型,這種算法通過擴展輸入空間,在構建回歸模型時利用輸出目標之間的關聯提升模型的預測準確性。然而,現有的多目標回歸算法都是在同一個特征空間上構建多目標回歸模型,忽略了各輸出目標本身具有的特殊性質,對多目標回歸問題的預測準確性的提升有限,因為各輸出目標雖然可能相互關聯,但是并不等同,甚至會表現出完全不同的特性。因此,針對每個輸出目標構建合適的特性表達能更好地反映輸出目標的特性,從而提高預測準確性。
針對多目標回歸問題,本文提出一種基于徑向基函數的多目標回歸特征構建算法(Feature Construction Algorithm for Multi-Target Regression via radial basis function,FCA-MTR)。首先,將各目標的輸出作為額外特征對各輸出目標聚類,根據聚類中心在原始特征空間構造目標特定特征空間的基;然后,通過徑向基函數將原始特征空間映射到目標特定特征空間,基于目標特定特征空間為每個輸出目標構建一個基回歸模型;最后,將各輸出目標的基回歸模型的輸出構成一個隱藏空間,并采用低秩學習算法[6]在隱藏空間學習得到最終的多目標回歸預測模型。本文的工作主要有以下幾點:
1)采用聚類算法和徑向基映射,目標特定特征空間的基反映了不同輸出目標在輸出空間上的分布情況,因此目標特定特征空間能夠充分考慮不同輸出目標的特殊性質;
2)由輸出目標的基回歸模型的輸出形成的隱藏空間是對各輸出目標特征的更高層次的抽象,代表了多目標回歸中輸出目標的共同特性;
3)通過構建目標特定特征和低秩學習算法,可以在同一框架中同時處理多目標回歸中輸入輸出映射問題和目標間關聯問題,既考慮了各輸出目標的特性,又考慮了各輸出目標之間的共性。
1 相關工作
近年來,分類和回歸是機器學習領域兩個重要的學習任務。在分類問題中,樣本的監督信息是由離散值組成,而在回歸問題中,樣本的監督信息是由連續型的值組成。在多目標回歸問題中,每個數據樣本同時具有多個取值為連續型數據輸出的輸出目標。在對標簽分類問題中,每個樣本則同時具有多個離散型取值的輸出。兩者的不同之處在于輸出目標的取值類型不同,它們共同的核心問題都是如何發掘多個輸出目標間的關聯,以提高預測性能。目前,多標簽分類已經取得了很多重要的成果,而大多數對標簽分類算法的思想都可以應用于解決多目標回歸問題,針對多標記分類的研究可以為解決多目標回歸學習問題提供寶貴的經驗。因此,首先介紹多標記分類的研究現狀,然后介紹多目標回歸的研究現狀和發展動態。
針對多標記分類問題,目前已經涌現大量的多標記分類算法。總體上來看,現有的多標記學習算法大致分為“問題轉化”和“算法適應”兩類[7]。問題轉化算法的基本思想是通過對多標記訓練樣本進行處理,將多標記學習問題轉化成已知的機器學習問題進行求解。基準標記排序(Calibrated Label Ranking,CLR)算法[8]是一種典型的問題轉化算法,它將多標記學習問題轉化成為“標記排序”問題進行求解。分類器鏈集成(Ensemble of Classifier Chains,ECC)算法[9]將多個二分類器連成一條鏈,訓練樣本每經過一個二分類器,就將其預測結果添加到樣本特征向量之中,繼續下一個二分類器的訓練,并通過組合多條隨機產生的不同標記序列的分類器鏈,以減輕不同標記序列給分類結果帶來的不利影響。算法適應的主要思想是對傳統機器學習算法進行改進,將其直接應用于多標記數據學習。其中較為典型的是多標記k近鄰(Multi-LabelkNN,MLkNN)算法[10],該算法基于待分類樣本的k個最鄰近樣本中各標記出現的先驗概率和后驗概率,使用最大化后驗概率原則確定待分類樣本的類別標記集合。排序支持向量機(Rank-Support Vector Machine,Rank-SVM)[11]采用最大間距策略來處理多標簽數據,以最小化排序損失為目標,針對每一對相關與不相關標簽構建線性分類器,并通過核算法處理非線性分類問題。Sun等[12-14]和王進等[15]將演化超網絡模型用于解決多標簽分類問題,演化超網絡最大的優點在于能夠以標簽規模的線性復雜度,深度發掘標簽之間的高階關聯,從而提高多標簽分類的準確性。多標簽分類問題與多目標回歸問題的區別在于多目標回歸中輸出值是連續型的數值,而多標簽分類的輸出是離散型的。兩者的核心問題都是處理輸入空間與多個輸出的映射關系以及多個輸出之間的關聯關系。因此,多標簽分類的研究能夠為多目標回歸提供重要的參考和經驗。
多目標回歸是一種同時預測多個相互關聯的連續型目標變量的回歸分析問題,由于多目標回歸的輸出空間不再是一維而是多維的,多目標回歸又被稱作多變量回歸或多維輸出回歸。和多標記分類問題一樣,多目標回歸也需要通過挖掘、利用多個目標變量之間的關聯關系,以提高預測的準確性。文獻[16]通過擴展輸入空間的方式處理多目標回歸問題,并提出了兩種多目標回歸算法:層疊單目標回歸(Stacked Single-Target,SST)算 法 和 回 歸 器 鏈 集 成(Ensemble of Regressor Chains,ERC)算法。SST算法的訓練由兩個階段組成。在第一個學習階段,SST算法為每個輸出目標訓練一個獨立的回歸模型。在第二個學習階段,SST算法首先通過將輸出空間的其他目標變量的預測值作為額外的輸入變量擴展原始的輸入空間,然后在擴展后的輸入空間上為每個目標變量訓練一個回歸模型。ERC算法是ECC算法針對多目標回歸問題的一種改進算法,它通過組合多條隨機產生的不同目標序列的回歸器鏈,以利用多個目標變量之間的關聯關系提高多目標回歸的預測性能。多層、多目標回歸(Multi-layer Multi-target Regression,MMR)算法[17]通過魯棒的低秩學習處理多目標回歸問題中的非線性輸入輸出關系和多目標變量的關聯關系。文獻[18]將多目標回歸應用于中藥藥效預測,通過利用輸出目標之間的關聯,解決了藥效預測問題中樣本數量少、數據維度高給預測模型帶來的困難。Melki等[19]提出了一種基于相關回歸器鏈的多目標回歸(multi-target Support Vector Regression via Correlation regressor Chains,SVRCC)算法,該算法首先計算一個具有最大關聯的輸出目標序列,然后基于該序列建立一條回歸器鏈。文獻[20]將構建的目標特定特征加入到原始特征中,通過擴展原始輸入空間,學習預測模型解決多目標回歸問題。Aho等[21]利用決策規則集成的算法解決多目標回歸問題。文獻[22]利用決策樹具有學習結果可讀性強、學習效率高的優點,通過改進預測聚類樹(Predictive Clustering Trees,PCT)算法,提出了一種叫作選擇預測聚類樹(Option PCT,OPCT)的多目標回歸算法。
2 基于目標特定特征構建的多目標回歸算法
多目標回歸需要解決的主要問題在于輸入輸出的映射關系以及輸出目標之間的關聯。本文算法在同一個框架中同時處理多目標回歸的這兩個關鍵問題。具體來講,針對輸入輸出的映射關系問題,通過構建目標特定特征,為每一個輸出目標構建反映輸出目標特性的新的特征空間。針對輸出目標之間的關聯問題,構建一個共同的隱藏空間,并采用低秩學習算法在隱藏空間中發掘和利用輸出目標的關聯,提高多目標回歸的預測性能。本文提出的多目標回歸算法的框架如圖1所示。
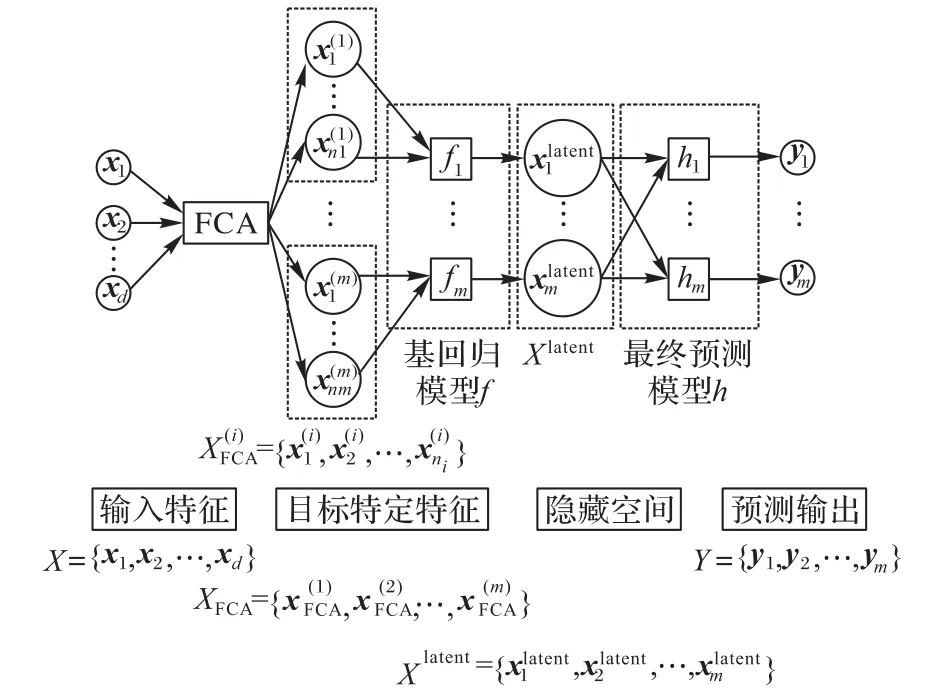
圖1 基于目標特定特征構建的多目標回歸算法框架Fig.1 Multi-target regression algorithm framework constructed on basis of target specific features
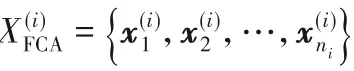
2.1 目標特定特征構建算法
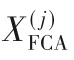
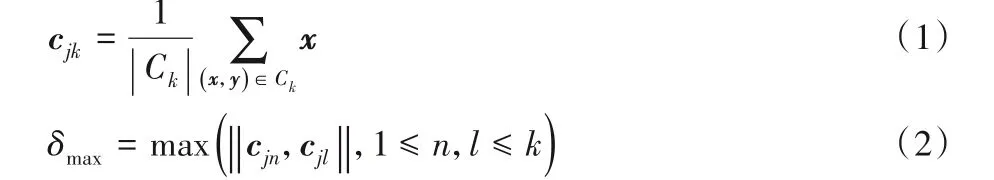
其中‖cjn,cjl‖表示任意兩個聚類中心cjn,cjl之間的歐氏距離。

為了對輸出目標之間的關聯進行建模,本文采用低秩學習算法從隱藏空間中為每個輸出目標yj學習得到最終的回歸預測模型hj。最終的回歸預測模型hj通過最小化如式(5)所示的目標函數獲得。
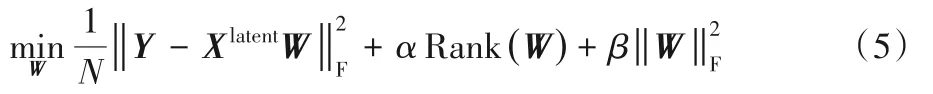
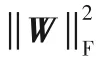
由于Rank函數的不連續性和非凸性,式(5)所示的目標函數不能直接通過梯度下降算法求解。核范式被廣泛應用于低秩學習[23],因此本文采用核范式對Rank函數進行近似表示,式(5)所示的目標函數可以被表示如式(6)所示:

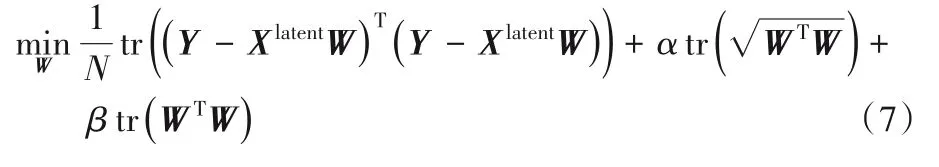
3 實驗結果及分析
3.1 數據集
為驗證本文算法的有效性,在18個多目標回歸數據集上進行仿真實驗,實驗過程的使用的數據都來自http://mulan.sourceforge.net/datasets-m tr.htm l。數據集的統計特征如表1所示。
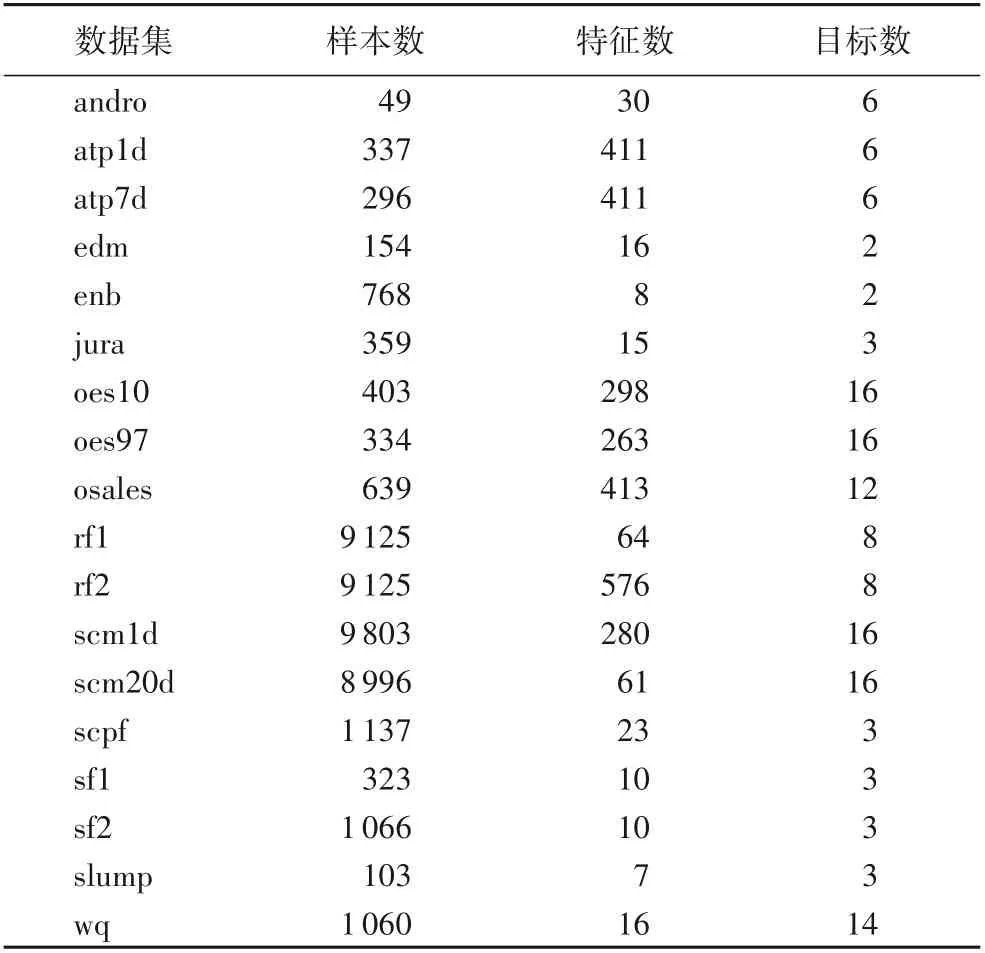
表1 實驗數據集及其統計特征Tab.1 Experimental datasets and their statistical characteristics
3.2 評價指標
多目標回歸問題中,需要為每個測試樣本同時預測多個輸出,為對多目標回歸算法的預測性能進行評價,本文采用平均相關根均方誤差aRRMSE(average Relative Root Mean Square Error)[17]作為評價指標,其中相關根均方誤差(Relative Root Mean Square Error,RRMSE)的 定 義 如 式(8)所 示,RRMSE值越小,預測準確性越高。
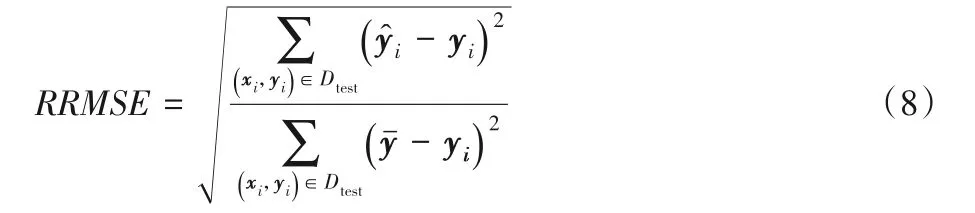
3.3 實驗與結果分析
本文算法與當前最具代表性的多目標回歸算法,包括SST[16]、ERC[16]、MMR[17]、SVRCC[19]進行比較。為了體現對比結果的客觀性,本文采用與對比算法相同的實驗設置,即在scm1d和scm20d數據集上采用2折交叉,在rf1和rf2數據集上采用5折交叉,在其余數據集上采用10折交叉進行實驗結果的對比。
本文算法與對比算法在18個數據集上的預測結果的RRMSE如表2所示,每個數據集上的最好結果用粗體標識。從表2中,可以看出本文算法在絕大多數的數據集上比對比算法有更高的預測準確性。
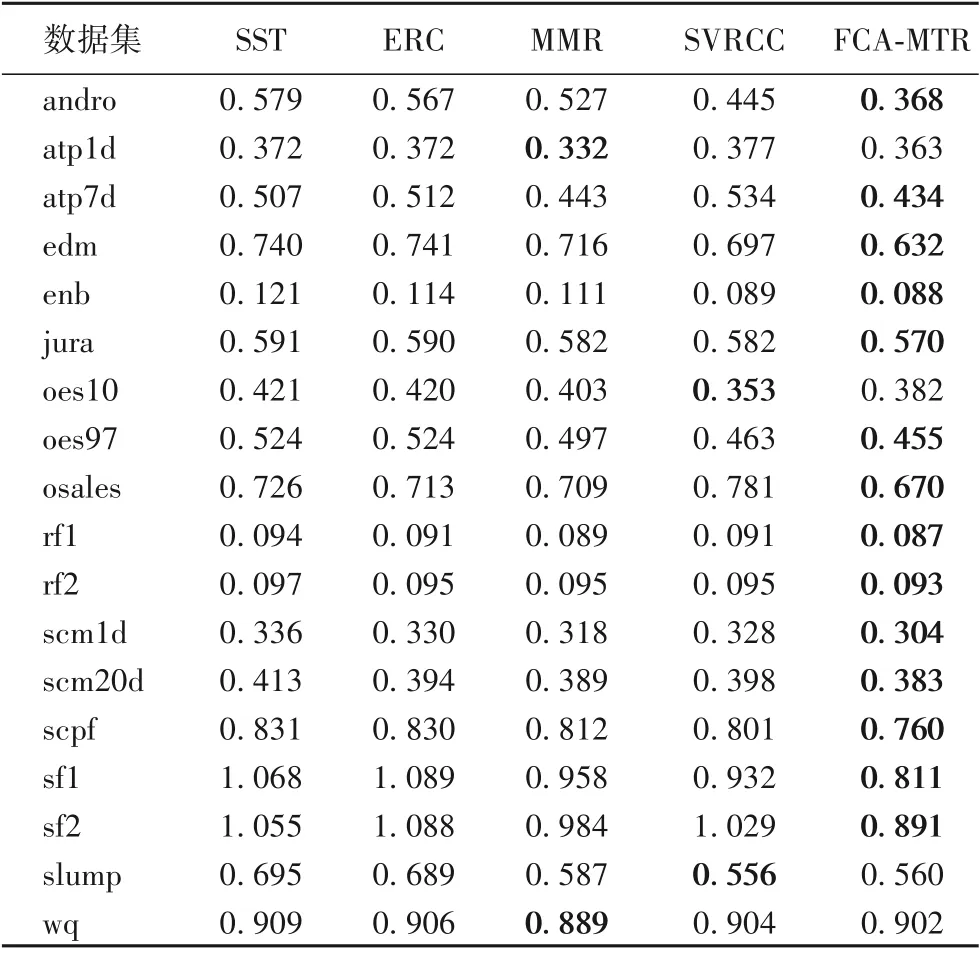
表2 本文算法與對比算法在18個數據集上的測試結果Tab.2 Test results of the proposed algorithm and comparison algorithmson 18 datasets
為客觀反映各算法在預測準確性上的差異,設置原假設H0,即各算法的預測準確性不存明顯的差別,再采用Friedman檢驗[25]對算法之間預測性能的差異進行總體統計分析,Friedman檢驗的相關統計信息如表3所示,從表3中可以看出Friedman檢驗的統計特征值50.76遠大于顯著性水平α=0.05時的臨界值2.52,原假設H0被拒絕,說明各算法在預測準確性上存在顯著性差異。

表3 Friedman檢驗統計特征Tab.3 Friedman test statistical characteristics
為進一步分析各算法在預測準確性上的具體差異,采用Bonferroni-Dunn檢驗[25]進行事后檢驗。在Bonferroni-Dunn檢驗中,兩個算法之間預測性能的差異通過算法的平均排序以及顯著性差異值(Critical Difference,CD)表示,當兩個算法的平均排序差值大于CD值時,說明這兩個算法中一個算法的預測性能明顯優于另外一個算法。顯著性差異值CD的計算如式(9)所示,其中J表示比較算法的個數,K表示數據集的個數,qα表示顯著性水平為α時的臨界值。本文取α=0.05,則qα=2.498,由式(9)可以得出CD值等于1.32,即當任意兩個算法的平均排序差值超過1.32時,說明一個算法的預測準確性明顯高于另一個算法。圖2通過CD圖直觀地展示了各算法之間預測性能的差異,在圖2中平均排序最靠前的算法位于CD圖的最右邊,平均排序最靠后的算法位于CD圖的最左邊,如果任意兩個算法的平均排序差值超過CD值,則兩者的性能有明顯的差異,且位于右邊的算法的預測性能明顯好于位于左邊的算法。從圖2中可以看出,本文算法的預測準確性明顯高于SST、ERC和SVRCC算法,而與MMR算法的預測性能雖然沒有顯著的差異,但是卻總體上比MMR算法略高。

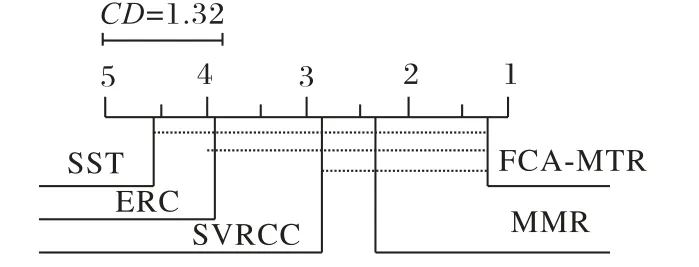
圖2 算法平均排序的CD圖Fig.2 CD chart of average ranksof algorithms
最后,為驗證本文算法有效性,對各輸出目標在原始特征空間和目標特定特征空間分別訓練線性回歸模型,并比較模型在測試集上對各輸出目標的預測性能。圖3展示了MTRBR、MTR-TSF、FCA-MTR三種算法在預測準確性上的差別,MTR-BR在原始特征空間采用二分法為每個輸出目標分別訓練線性回歸模型,MTR-TSF則是在構建的目標特定特征空間上采用二分法為每個輸出目標分別訓練線性回歸模型。從圖3中可以看出MTR-TSF所有的數據集上的預測性能都高于MTR-BR,并且在大部分數據集上的預測準確性明顯比MTRBR高,說明構建的目標相關特征能夠提高各輸出目標的預測準確性。此外,圖3中FCA-MTR的預測準確性在所有數據集上都高于MTR-TSF,表明目標特定特征結合低秩學習表示的輸出目標間的關聯能夠進一步提升多目標回歸的總體預測準確性。
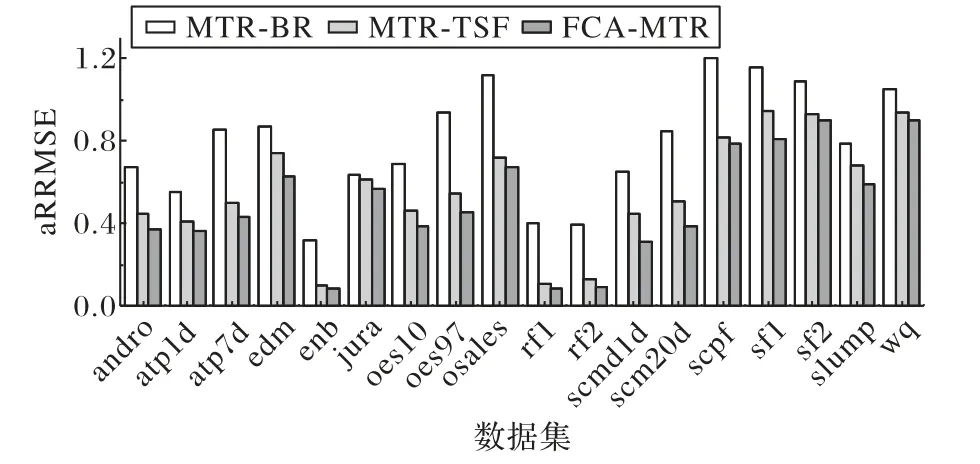
圖3 MTR-BR、MTR-TSF、FCA-MTR三種算法在預測準確性上的比較Fig.3 Comparison of prediction accuracy of threealgorithms:MTR-BR,MTR-TSF,and FCA-MTR
從以上實驗結果的對比可以看出,本文算法能夠通過目標特定特征提高各輸出目標的準確性,從而總體提升多目標回歸的預測準確性。
4 結語
本文提出了一種基于徑向基函數的目標相關特征構建算法,用于解決目標回歸中的輸入輸出映射關系以及輸出目標之間的關聯性問題。首先通過聚類分析和徑向基函數,將原始輸入特征映射到目標特定特征上,構建的目標特定特征能夠更準確地反映各輸出目標特有的性質;然后利用目標特定特征構建隱藏空間;最后在隱藏空間上,通過低秩學習算法來發掘和利用輸出目標之間的關聯關系,提高多目標回歸的預測準確性。在18個多目標回歸數據集上,本文算法取得了較好的結果,驗證了算法的有效性。未來的其中一個工作方向是優化目標相關特征構建算法,進一步增強模型處理輸入輸出之間非線性映射關系的能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
當代陜西(2021年17期)2021-11-06 03:21:36
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
學苑創造·A版(2018年11期)2018-02-01 06:29:20
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
讀者(2017年5期)2017-02-15 18:04:18
光學精密工程(2016年6期)2016-11-07 09:07:19
