基于改進單點多盒檢測器的大壩缺陷目標檢測方法
2021-09-09 08:09:10毛鶯池王龍寶王子成
計算機應用 2021年8期
陳 靜,毛鶯池*,陳 豪,王龍寶,王子成
(1.河海大學計算機與信息學院,南京 211100;2.華能瀾滄江水電股份有限公司,昆明 650214;3.中國電建集團昆明勘測設計研究院有限公司,昆明 650051)
0 引言
我國是世界上建成大壩最多的國家,其中95%的大壩建齡在30年以上(http://www.thepaper.cn/newsDetailforward_1858088)。大壩的日益老化與環境、災害等因素的影響導致了缺陷的形成,大壩的安全性逐漸降低[1]。定期巡檢是維護大壩工程安全的重要措施,現有的巡檢方法主要為人工目視檢查[2],隨著大壩建齡的增加和不斷疊加的環境影響,人工巡檢的工作量與難度逐漸增大,研發自動化巡檢設備[3]是提高大壩安全運維效率的重要舉措。本文以某水電站各類表觀缺陷圖像為實驗數據集,提出可變形卷積單步多框檢測器進行大壩缺陷檢測,輔助巡檢人員完成大壩缺陷識別。
目標檢測[4]的基本框架基于檢測流程的區別可以分為兩個分支:one stage系列算法和two stage系列算法。two stage算法如基于區域卷積神經網絡(Region-based Fully Convolutional Network,R-FCN)[5]、快速區域卷積神經網絡(Fast Regionbased Convolutional Neural Network,Fast R-CNN)[6]、基于區域的更快卷積神經網絡(Faster Region-based Convolutional Neural Network,Faster R-CNN)[7],由于two stage算法細致的候選框提取和分類回歸流程,在目標檢測的精度上有很大的優勢。one stage的開篇算法YOLO(You Only Look Once)[8]于2016年緊接Faster R-CNN提出,將原先two stage框架生成預選框和預測階段合二為一,直接在特征圖上利用卷積層進行候選框的提取和目標的檢測,極大提升了目標檢測的速度。YOLOv2[9]和YOLOv3[10]算法更是在速度方面作出了極大的改進。單點多盒檢測器(Single Shot MultiBox Detector,SSD)[11]作為one stage的另一經典算法,承接了YOLO的單階段檢測框架,彌補了YOLO算法檢測小物體時精度的不足,提出了采用多尺度特征圖進行檢測,同時借鑒了Faster R-CNN中采用錨點機制提取候選框,這種方式對于低分辨率的圖像和尺寸較小的目標同樣能達到較高的檢測精度。2020年Lin等[12]重新定義了目標檢測中的損失函數,引入一種新的損失函數Focal loss用來替代傳統one stage算法中的損失函數,解決單階段目標檢測算法中普遍存在的正負樣本不均衡的問題。
為了實現工程實際應用環境中的實時檢測,并保證不同尺度缺陷特征的檢測精度。首先將巡檢人員現場采集的缺陷圖像進行數據增強,擴大訓練樣本數量。本文提出模型采用one stage算法中的單點多盒檢測器作為基礎框架,引入可變形卷積[13]替換傳統標準卷積。針對特征的尺寸,改進先驗框比例,提高條形特征的檢測精度與模型的泛化能力。采用改進的非極大值抑制(Non-Maximum Suppression,NMS)算法緩解訓練時正負樣本不均衡,進一步優化學習效果。本文總體研究框架如圖1所示。
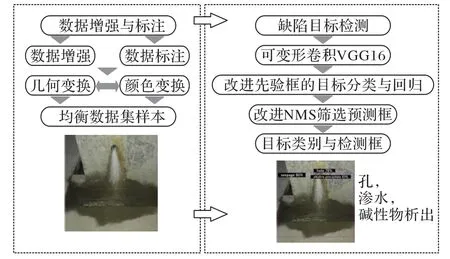
圖1 總體研究框架Fig.1 Overall research framework
1 缺陷的分類和圖像處理
1.1 缺陷的分類
本文以實際工程環境為背景,使用某電站采集到的缺陷圖像作為實驗數據集,進行缺陷圖像目標檢測。該數據集涵蓋了4類缺陷,分別為裂縫(crack)、滲水(seepage)、堿性物析出(alkaline precipitate)、混凝土剝落(concrete spalling)和1類工程特征孔(hole)[14],如圖2所示。

圖2 缺陷示意圖Fig.2 Schematic diagram of defects
1.2 數據增強
陷樣本數據集包含5類缺陷與特征,但各類的樣本集不均衡現象嚴重,由于缺少公開的工程缺陷數據集以供訓練,因此在對缺陷數據集進行訓練前,通過數據增強的方式來均衡樣本,使得訓練效果更具有魯棒性[15]。本文采用幾何變換和顏色變換兩種方式進行數據增強。
1)幾何變換。
幾何變換即對圖像進行幾何變換,包括翻轉、旋轉、裁剪、變形、縮放等各類操作。變換后的缺陷圖像如圖3所示。

圖3 樣本幾何變換Fig.3 Sample geometric transformation
2)顏色變換。
基于噪聲的數據增強就是在原來的圖片的基礎上,隨機疊加一些噪聲,最常見的做法就是高斯噪聲。本文進行變換處理時,選擇噪聲、模糊、顏色變換等不同方式以實現不同程度的增強。缺陷數據集的顏色變換如圖4所示。

圖4 樣本顏色變換Fig.4 Sample color transformation
經數據增強處理后,缺陷數據集各類樣本量如5所示,各類樣本數量得以均衡。
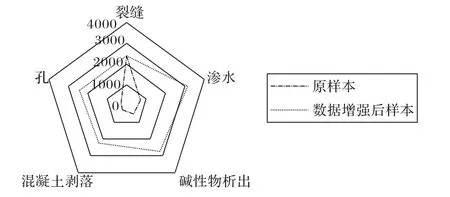
圖5 數據增強前后對比Fig.5 Comparison of data before and after augmentation
1.3 圖像標注
根據《水電站大壩安全定期檢查辦法》[16]中水工大壩檢查與安全評價要求,以及水工大壩專業巡檢人員對缺陷分析的指導,采用labelme對巡檢人員發現的大壩表觀缺陷圖像按照變形趨勢編輯標準組閉合框。可變形卷積單步多框檢測器(DeFormable convolution Single Shot multi-box Detector,DFSSD)模 型 采 用MS COCO(MicroSoft Common Objects in COntext)數據集與缺陷數據集共同作為實驗數據集,為保證兩數據集共用讀取標簽文件的代碼保持一致,將缺陷數據集標注完成的標簽格式,使用python腳本轉化為COCO標簽格式。轉換后的標簽文件中包含以下3個基本類型:images、categories、annotations,分別表示圖片、標簽類別、標簽詳情。
2 可變形卷積單步多框目標檢測
2.1 總體思路
本文提出可變形卷積單步多框檢測器(DFSSD)模型用于大壩缺陷目標檢測。DFSSD模型采用one stage算法單階段目標檢測器作為模型的基礎架構,引入可變形卷積(Deformable Convolution)作為處理幾何變換的中間機制,針對特征的尺寸大小,在錨點機制中修改了先驗框尺寸比例,提高條形特征的檢測精度與模型的泛化能力。在訓練過程中,為了緩解訓練時正負樣本不均衡的問題,進一步提高檢測精度,改進了非極大值抑制算法,優化學習效果。DFSSD框架如圖6所示,首先采用可變形卷積對缺陷特征進行提取,再將特征映射到多尺度特征圖中,最后在每個尺度的特征圖中進行每個候選框中目標的分類與回歸。
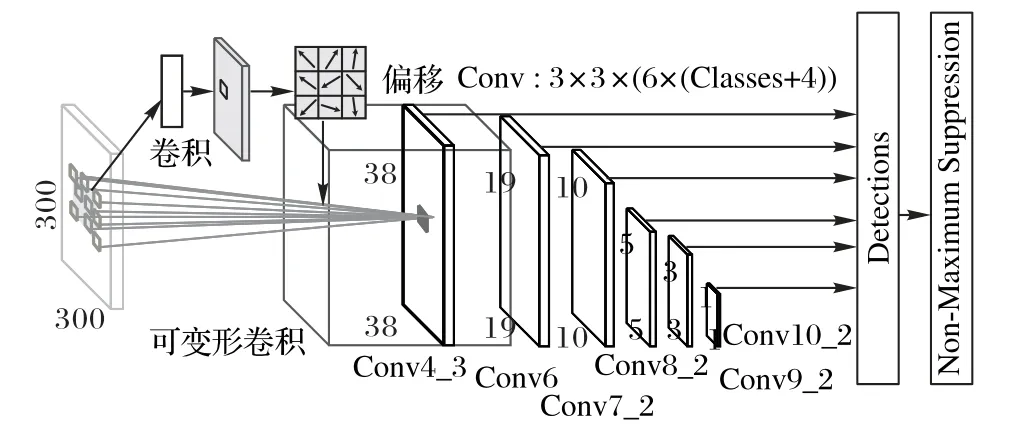
圖6 DFSSD整體框架Fig.6 DFSSD overall framework
2.2 可變形卷積
DFSSD沿用了SSD中的VGG16(Visual Geometry Group)[17]作為主干網絡,提取輸入圖像的特征。由于缺陷數據集中同類別的缺陷存在幾何變化,如滲水面積的變化、裂縫的延伸等,卷積神經網絡由于固定的幾何結構導致幾何變換的建模能力不足,因此DFSSD模型將可變形卷積替代VGG16中的標準卷積,實現適應特征幾何變換的網絡結構,提升整個目標識別框架的空間信息建模能力。本文模型的可變形卷積的流程如下:
1)輸入原始圖片,記為U,其中設置batch為b。
2)原始圖片batch經過一個普通卷積,卷積填充為same,即輸出輸入大小不變,對應的輸出結果為原圖片batch中每個像素的偏移量,輸出值的個數為b×H×W×2N,記為V,其中2N表示每個方向上的x偏移量與y偏移量。
3)將U中圖片的像素索引值與V相加,得到偏移后的坐標(即在原始圖片U中的坐標值),需要將坐標值限定為圖片大小以內,將浮點類型的坐標值獲取像素。
4)使用雙線性插值法[18]獲取浮點類型的坐標處的像素值。
5)計算坐標值對應的所有像素后,得到新的特征圖,并將新的特征圖作為輸入數據輸入到下一層中。
2.2.1 偏移量計算
相較于傳統卷積采樣,可變形卷積在卷積過程中添加了偏移量的學習,如圖7(b)、(c)、(d)所示。可變形卷積的卷積核不是簡單的矩形,而是適應特征幾何變化的帶有偏移量的感受野。
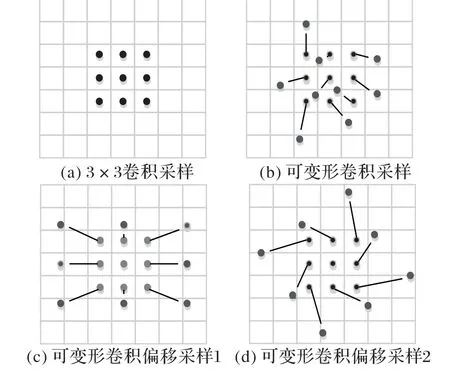
圖7 感受野上的偏移量學習Fig.7 Offset learning on receptive field
標準2D卷積過程可以分為兩個步驟:
1)采用標準網格R對輸入特征圖x進行采樣,此時R為感受野的尺寸,分別對應基于卷積位置的各個方向,定義為:
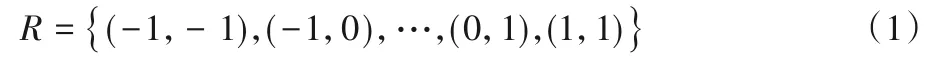
2)將帶權重w的采樣值進行求和,對于輸出特征圖中每一個位置p0,可以得到:

其中pn為各個方向所映射的各個位置。
在可變形卷積中,R通過偏移量{Δpn|n=1,2,…,N}來增大感受野的范圍,其中,N=|R|,由式(2)可得:
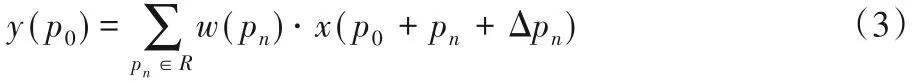
此時,采樣的卷積核由不規則的R組成,距卷積核中心位置偏移量為pn+Δpn,由可變形卷積結構圖可得,原先標準的卷積過程被分為兩路,一路學習偏移量,得到H×W×2N個輸出偏移量,N=|R|表示卷積核中的像素個數,2N代表兩個垂直方向的偏移量。通過在相同的輸入特征映射上應用卷積層來獲得偏移,卷積核具有與當前卷積層相同的空間分辨率和伸縮性。輸出偏移量具有與輸入特征圖相同的空間分辨率。經偏移計算可得,對于原始卷積的每一個卷積窗口,不再是標準的矩形,而是適應特征幾何變化的偏移變形卷積窗口,獲得偏移后像素點的目標值后,計算過程與標準卷積一致。
偏移量Δpn的計算的結果往往是一個高精度的小數,非整數的坐標無法在圖像這種離散型的數據上使用,如果采用簡單的取整方法會有一定程度的誤差,從而x(p0+pn+Δpn)處的像素值需通過雙線性差值來計算,即通過尋找距離坐標最近的四個像素點來計算該點的像素值。將x(p)=x(p0+pn+Δpn)簡化為:

其中x(q)表示相鄰4個整數坐標處的像素值G(?,?)為p相鄰4個整數點對應的權值參數。
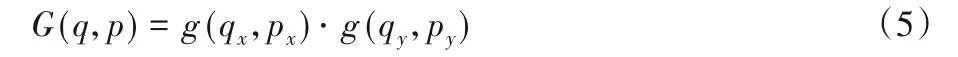
由式(4)~(5)可得:
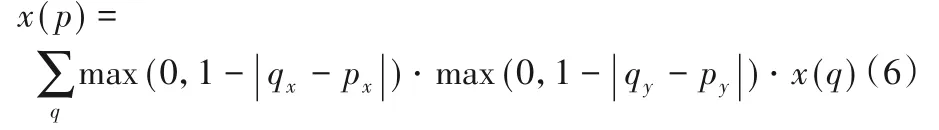
2.2.2 反向傳播
可變形卷積的核心思想是用額外的偏移量增加模塊中的空間采樣位置和從目標任務中學習偏移量,不需要額外的監督。改進后的可變形卷積模塊可以很容易地取代現有卷積神經網絡(Convolutional Neural Network,CNN)中的普通模塊,并且可以通過標準的反向傳播進行端到端的訓練,從而產生可變形的卷積網絡。為了學習偏移量,梯度通過可變形卷積(式(3))和雙線性插值計算(式(5)、(6))進行反向傳播,偏移量Δpn的梯度計算公式為:
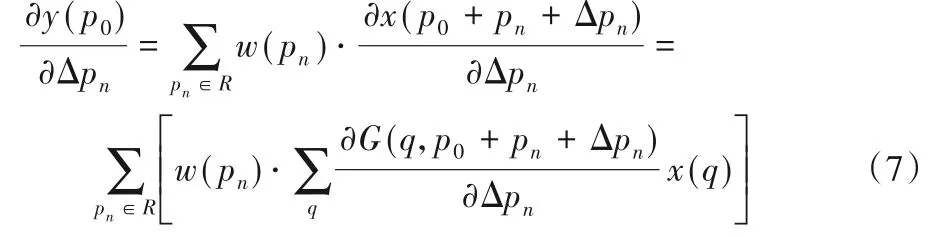
DFSSD目標檢測方法將可變形卷積替代原始VGG16中的普通卷積,不改變輸入和最終輸出參數,提升了CNN模塊的空間信息建模能力。
2.3 特征圖檢測
DFSSD在可變形卷積之后增加了額外的4個卷積層以引入更多不同尺度的特征圖,作為后續預測網絡的輸入。卷積神經網絡由于卷積、池化等操作,隨著層數的增加,特征圖的尺寸會越來越小,當在每個像素點上生成特定大小的先驗框,在這些不同尺度的特征圖上進行檢測,就可實現比較大的特征圖來檢測相對較小的目標,而小的特征圖負責檢測大目標的任務。
2.3.1 改進先驗框
對于多尺度特征圖的輸出,DFSSD為特征圖中每個像素單元設置了尺度或長寬比不同的先驗框。同一個特征圖上每個單元設置的先驗框是相同的,對于不同尺寸的特征圖設置的先驗框數量就有一定程度的變化。預測的邊界框以先驗框為基準,由于one stage的方法沒有生成建議候選框這一流程,事先生成先驗框在一定程度上降低了訓練難度,又保證了目標區域定位的精確性。先驗框的設置包括尺寸和長寬比兩個方面。
首先對于先驗框的尺度,遵守線性遞增規則:隨著特征圖尺寸的減小,先驗框的尺寸線性增加:
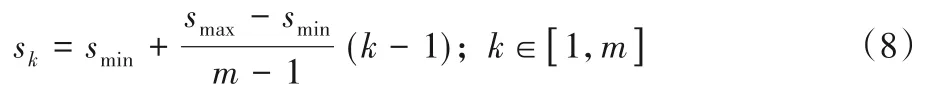
其中:m為特征圖的個數,由于在主干網絡中的卷積層單獨設置先驗框大小,所以此處m取5;smax與smin表示基于特征圖尺寸比例的最大值和最小值,原始論文中,smax與smin設定為0.9和0.2,并將第一個特征圖的尺寸比例設為smin。對于第一層之后的特征圖,先驗框的尺寸比例依照式(8)線性增加,可得各個特征圖的sk分別為0.2,0.37,0.54,0.71,0.88,將比例sk與特征圖各自的尺寸相乘,可得到各個特征圖先驗框的尺寸。
一般將先驗框的長寬比設定為ar∈{1,2,3,1/2,1/3},由于本文的檢測目標為工程缺陷,對于裂縫等條形缺陷,原有先驗框的長寬比不足以將缺陷完整地標注出來。結合實際應用背景,DFSSD模型將先驗框長寬比設定為ar′∈{1,2,5,1/2,1/5},如圖8所示。對于已知長寬比,按照式(9)計算先驗框的實際寬度與高度:
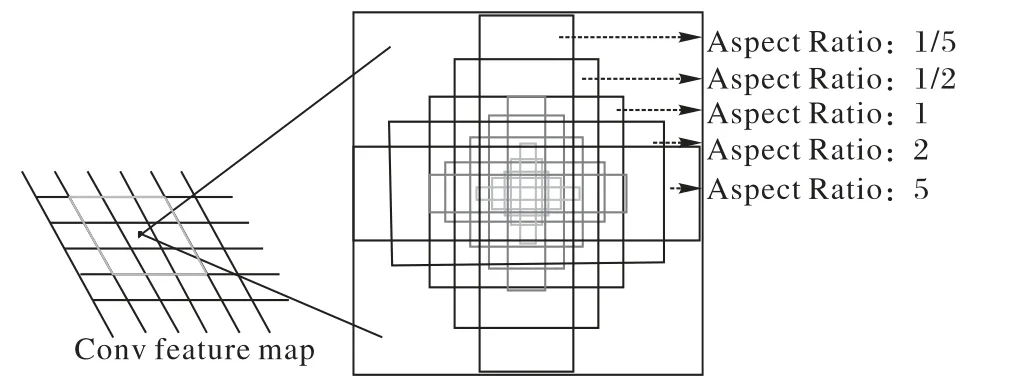
圖8 DFSSD anchor機制Fig.8 DFSSD anchor mechanism

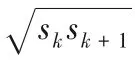
對于不同尺度的特征圖的輸出分別用兩種不同的3×3的卷積核進行卷積,每個像素點的每個先驗框的輸出分為兩個部分,分別對應預測框位置和該先驗框中各個類別的置信度評分。其中預測框位置包含4個值(cx,cy,w,h)分別表示預測框的中心坐標以及寬高。置信度評分代表了該先驗框中的目標對應各個類別的可能性,若檢測目標共有c個類別,則需要預測c+1個置信度值,其中第一個置信度指的是不含目標或者屬于背景的評分。
2.3.2 改進非極大值抑制
在DFSSD模型的訓練階段,通過IoU(Intersection over Union)確定訓練圖片與真實目標之間的匹配度,區分正負樣本。由于本文使用的缺陷數據集,每張圖片中的真實目標非常少,但先驗框非常多,且在極端條件下:真實目標與先驗框的最大IoU小于0.5的情況幾乎不存在。因此針對現有的正負樣本不均衡的問題,DFSSD采用非極大值抑制的方法使得正負樣本比例均衡。
非極大值抑制(NMS)[19]指抑制非極大值的元素,并搜索局部最大值。在目標檢測任務中,非極大值抑制是對一種檢測結果進行冗余去除操作的后處理算法。本文中模型將非極大值抑制算法作出了改進,步驟如下:
1)對所有負樣本先驗框的置信度進行降序排序,選取置信度最小的負樣本;
2)遍歷余下負樣本先驗框,如果和當前得分最低的先驗框的重疊面積大于閾值0.5,就將此負樣本先驗框刪除;
3)從未處理的負樣本先驗框中選取置信度最低的進行刪除。
重復上述步驟,僅刪減負樣本,相比傳統NMS,在刪除冗余先驗框的前提下,增加了樣本訓練的多樣性。
總體而言,改進后的非極大值抑制算法過程是迭代-遍歷-消除,其中消除冗余先驗框和置信度低的負樣本先驗框達到樣本均衡。
2.3.3 損失函數
DFSSD的損失函數定義為位置誤差(localization,loc)、置信度誤差(confidence loss,conf)與可變形卷積偏移誤差(df)的加權和:
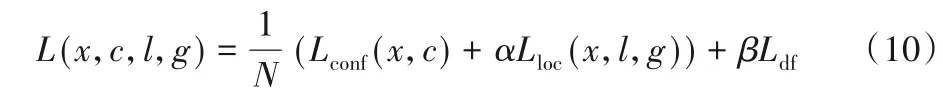
對于位置回歸誤差,采用穩定的smoothL1損失函數[20]:

smoothL1損失函數能從兩個方面限制梯度:當預測框與真實目標差別過大時,梯度值不至于過大;當預測框與真實目標差別很小時,梯度值足夠小。整體位置誤差定義如下:

其中:c為類別置信度預測值,p為真實目標的類別索引。
3 實驗與結果分析
3.1 實驗環境
實驗環境使用的是GeForce RTX 2080 Ti,操作系統是Ubuntu 16.04,使用的深度學習框架是pyTorch 1.3.1,DFSSD模型的訓練測試都在GeForce RTX 2080 Ti進行。
3.2 實驗數據及評價指標
1)實驗數據。
目標檢測任務需要聲明一個對象屬于一個特定的類別,并在圖像中定位它,對象的定位通常以矩形框來表示。本文采用目前主流目標檢測數據集MSCOCO(MicroSoft Common Objects in COntext)和大壩缺陷數據集作為實驗驗證數據集。
①MSCOCO數據集:用于檢測和分割在自然環境及日常生活中發現的對象,包含91個公共對象類別,其中82個具有5 000多個標記實例,在328 000張圖像中總共有2 500 000個標記實例。
②大壩缺陷圖像:缺陷數據集來源于某電站大壩工程巡檢結果,包含4類缺陷和1類工程特征,其中經數據增強后的圖片達8 890張,包含12 995個標記實例。將數據集的85%作為訓練集,15%的數據作為測試集,并盡可能保證每個缺陷類別分布均勻。
2)評價指標。
在實驗過程中,為了評估缺陷圖像目標檢測模型準確性和檢測速度,采用了以下三種評價指標:平均精度(Average Precision,AP)、平 均 精 度 均 值(mean Average Precision,mAP)、速率(單位:frame/s)。
3.3 實驗對比方法
在實驗中,本文在MSCOCO數據集和大壩缺陷圖像兩個數據集上進行檢測,并采用以下兩個模型和本文提出的DFSSD檢測結果進行對比。
1)SSD:使用VGG16為主干網絡,通過每個像素點的不同尺寸和長寬比的錨點框來檢測各種幾何尺寸的目標。
2)Faster R-CNN:任意大小的圖片經CNN卷積后形成特征圖后,將特征圖輸入區域侯選網絡(Region Proposal Network,RPN),采用事先設定好的不同大小的錨點框(anchor boxes)通過滑動窗口的形式,選取候選區域。
3.4 缺陷數據集結果分析
DFSSD模型部分檢測結果如圖9所示。
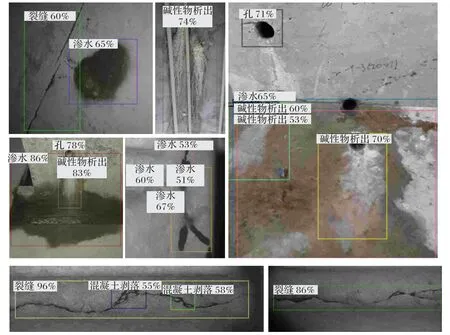
圖9 缺陷數據集檢測結果Fig.9 Detection results on defect dataset
表1為各模型檢測精度對比數據,Faster R-CNN作為傳統two stage算法,識別效果穩定,尤其對于“孔”這類幾何形狀較穩定的特征,識別精度高于本文的改進模型DFSSD,充分展現了Faster R-CNN的穩定性。然而對于一些幾何形狀不斷變化的特征,如“堿性物質析出”“滲水”“裂縫”這些缺陷,DFSSD則展現出了它的機動性的精度優勢,對于“裂縫”缺陷,由于數據集足夠,未經過數據擴增,因此訓練數據集區分度較好,識別精度高達68.9%。而“混凝土剝落”和“堿性物析出”特征由于自身數據集偏少,特征形狀與大小也不固定,即使通過數據增強手段擴充了數據集,但在隨機裁剪過程中會導致裁剪存在不完整的情況,使得有效數據變少,在實驗模型中識別精度較接近。相較于基線SSD模型,DFSSD模型平均識別精度提升5.98%。

表1 大壩缺陷數據集模型檢測性能對比Tab.1 Performance comparison of different detection modelson dam defect dataset
在檢測速度上,Faster R-CNN首先要經過RPN生成候選框,再通過先驗框進行后續分類和回歸任務,所以速度較慢,這也是大部分two stage目標檢測算法的局限性。而SSD和DFSSD均采用one stage框架,省去了生成候選框的過程,因此在速度上擁有絕對的優勢,為將來實際工程環境的實時缺陷檢測提供可能性。
總體而言,DFSSD引入可變形卷積網絡,在目標檢測任務中,各類別的識別精度均優于SSD,即使是在幾何特征較穩定的目標下,也有一定的精度優勢;同時DFSSD模型還具備了速度指標上的優勢。
表2展示了數據擴增預處理操作對于實驗結果的影響。其中,“裂縫”缺陷由于沒有進行數據擴增,但可能在擴增其他缺陷數據集時包含了“裂縫”特征,因此對于該類別的檢測精度擁有較小的提升效果。而對于其他的特征,精度提升率最高達23%,所有類型特征總體平均精度增長了15.1%,由此可見,對于有限的數據集而言,對數據集進行適當的數據擴增預處理,將對目標檢測的表現能力有可觀的提升。
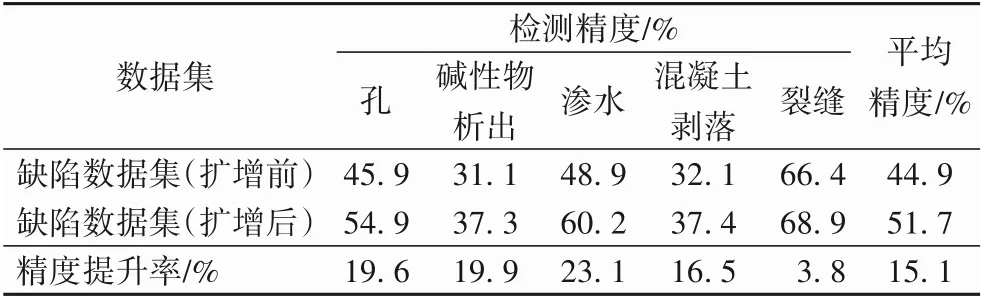
表2 數據擴增前后檢測精度對比Tab.2 Detection accuracy comparison beforeand after data augmentation
DFSSD對原始SSD框架中的先驗框和非極大值抑制模塊作出了改進。對比實驗結果如表3,改進的NMS對于實驗結果有了普遍的提升,提升率在1~1.6個百分點%左右。AP@0.5表示結果生成框和真實框之間的IoU閾值設為0.5時,測試集的模型檢測結果,依此類推可得,閾值設定越大,檢測精度結果越高。若將先驗框設為原始ar∈{1,2,3,1/2,1/3}的比例,對于總體精度而言降低了13.1%,而當閾值設為0.5時,精度則降低了1.6%。
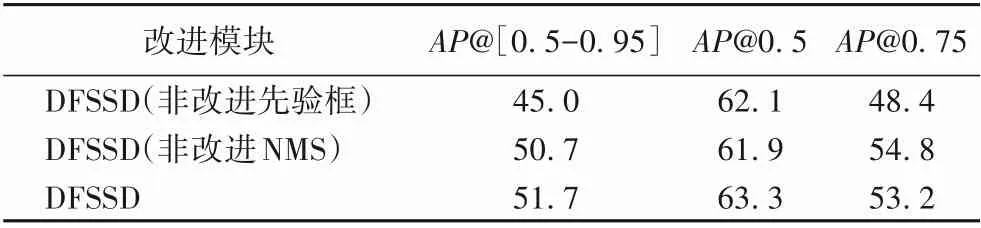
表3 改進模塊對檢測精度的影響 單位:%Tab.3 Influenceof improved moduleson detection accuracy unit:%
為了進一步驗證DFSSD的收斂性,將SSD和DFSSD的損失函數以迭代次數的時間步為橫軸繪制如圖10,進行損失分析。通過比較SSD和DFSSD的損失曲線可以看出,雖然DFSSD在初始階段的損失值較高,但隨著迭代的進行,迅速收斂,且收斂速度大于SSD,并隨著迭代的進行而穩步降低直至趨于穩定。實驗結果表明,DFSSD在保持了精度的同時也提高了收斂性能。
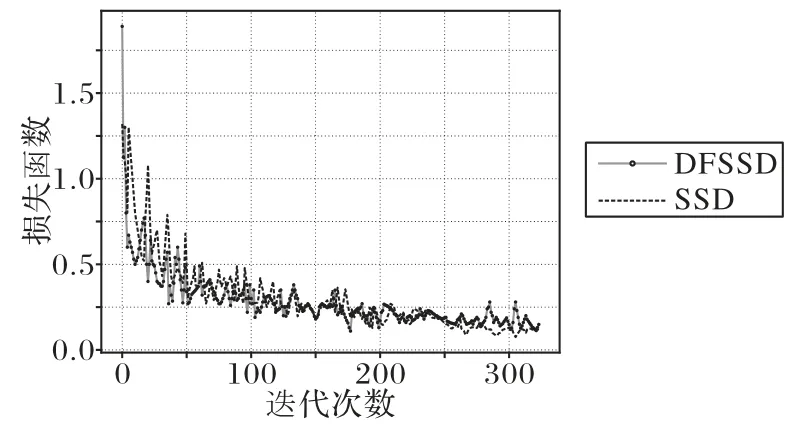
圖10 收斂性能對比Fig.10 Convergence performance comparison
為了驗證DFSSD模型的通用性,將使用公開數據集COCO數據集進行對比實驗,實驗結果如表4所示。
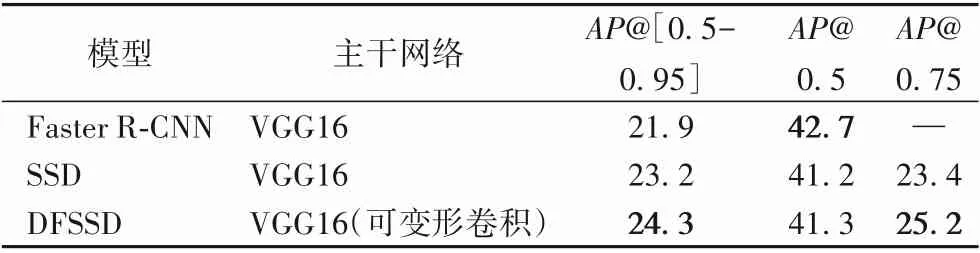
表4 COCO數據集上的模型檢測精度對比 單位:%Tab.4 Comparison of model detection accuracy on COCO dataset unit:%
由表4可得,在COCO數據集上,傳統的兩階段算法Faster R-CNN由于細致的候選框預測算法,在IoU閾值較小的AP@0.5的指標上表現較好。而在AP指標上,DFSSD相對于其他兩種模型均有提升,與SSD相比,AP提高4.74%,原因可能有以下兩點:COCO數據集對于缺陷數據集而言非常龐大,種類繁多,識別難度也很大,各大主流算法對于COCO數據集的檢測能力也有待提高,對于龐大的數據集而言,可變形卷積的改進對于目標檢測精度的提升效果并不明顯。COCO數據集多源自日常生活場景,目標幾何特征變化不明顯,因此針對性能的提升率不高。
3.5 實驗結論
對于足夠龐大、種類繁多以及幾何特征變化不頻繁的應用環境來說,DFSSD保持了識別精度的穩定性,展示了可變形卷積的優勢。
4 結語
針對缺陷的幾何變換特征和工程應用環境,提出了可變形卷積網絡單階段目標檢測器DFSSD模型。該模型采用輕量級的單階段目標檢測器SSD作為基礎框架,在此基礎上進行改進。在特征提取階段將可變形卷積網絡替換傳統卷積層,使得卷積核不再是固定的形狀,提高模型的空間建模能力。為提高模型對于不同尺度比例缺陷的泛化能力,調整了先驗框比例。通過改進非極大值抑制算法解決檢測階段正負樣本不均衡的問題。基于大壩缺陷數據集和MSCOCO數據集上的實驗結果表明,DFSSD模型相較于改進前的基準模型SSD對于缺陷目標檢測的精度有了顯著的提高,并且也比兩階段目標檢測模型Faster R-CNN的目標檢測精度要好。今后將考慮采集更多的數據進行訓練,并在此基礎上與最新的目標檢測模型作比較,已便更好驗證DFSSD模型缺陷檢測有效性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中華詩詞(2020年1期)2020-09-21 09:24:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
