基于循環神經網絡的電信行業容量數據預測方法
2021-09-09 08:09:10李曉瑜吳飛舟
計算機應用 2021年8期
關鍵詞:模型
丁 尹,桑 楠,李曉瑜*,吳飛舟
(1.電子科技大學信息與軟件工程學院,成都 610054;2.北京思特奇信息技術股份有限公司,北京 100046)
0 引言
物聯網和虛擬化等技術的不斷發展促進電信業務量和業務種類不斷增加。業務服務器數量的快速增長,使得電信運維也面臨不可避免的優化升級。容量可以理解為預先分配給特定應用系統的資源上限,比如CPU(Central Processing Unit)、內存、磁盤、網絡帶寬等,應用系統運行是否順暢受容量配置的影響[1]。當前大多數情況下,企業依靠經驗或者專家建議手動從基礎架構中管理、更新、添加或者刪除物理/虛擬服務器。面對如今快速增長的服務器數量,容量管理變得日益重要,傳統運維已經出現瓶頸。大量的服務器會產生海量的性能監測數據,為了更有效地管理和利用這些數據,電信運維行業提出智能運維(Artificial Intelligence for IT Operations,AIOps)系統。通過分析歷史性能數據,預測未來的性能趨勢,為運維人員提供參考,從而避免系統容量風險,實現系統經濟、平穩運行。容量管理的一個重要內容就是通過對未來容量資源進行預測以幫助合理分配資源,減少資源冗余。
近年來,越來越多的研究人員開始從事對云計算數據中心歷史容量數據進行分析,通過建立模型來預測未來系統容量的相關工作[2]。常見的傳統預測模型包括代數估計[3]、線性回歸模型[4-5]、差分自回歸移動平均(AutoRegressive Integrated Moving Average,ARIMA)模 型[6-8]和 反 向 傳 播(Back Propagation,BP)神經網絡模型[9]。傳統預測模型具有易建模的優點,但是難以實現高精度的預測。隨著技術的不斷發展,深度學習也逐漸被應用到容量預測中去。Mason等[10]使用基本循環神經網絡(Recurrent Neural Network,RNN)方法精確預測短期CPU利用率。Rao等[11]和Tran等[12]使用長短時記憶(Long Short-Term Memory,LSTM)網絡來預測未來正在運行的應用程序的資源使用情況。相比于傳統預測模型,RNN和LSTM具有更高的預測精度。除此之外,雙向循環神經網絡(Bi-directional Recurrent Neural Network,BiRNN)模型[13]和雙向長短時記憶(Bi-directional Long Short-Term Memory,BiLSTM)網絡[13-14]模型也逐漸被運用到容量數據預測中。單向神經網絡僅從過去的輸入中學習依賴關系來預測輸出,雙向循環神經網絡不僅能學習過去的趨勢還能集合未來的趨勢信息,具有更佳的預測效果。
目前,多數研究忽視了容量數據種類繁多的問題,對于同一個業務,CPU和內存往往表現出不同數據特征和趨勢,對于不同業務,監測到的不同設備的CPU數據特征也不盡相同,使用同種方法對所有容量指標數據進行預測,得到的預測效果參差不齊。楊海民等[15]在對時間序列進行研究時,提出了時間序列具有趨勢性、周期性和不規則性,但是未提出具體的分類方法。基于此,結合電信行業相關業務特點,本文提出一種指標數據類型分類方法,利用該方法將數據類型分為趨勢型、周期型和不規則型。針對其中周期型數據預測,提出基于雙向循環神經網絡的周期型容量指標預測模型,記作BiRNNBiLSTM-BI。首先,提出一種忙閑分布分析算法;其次,搭建循環神經網絡模型;最后,將忙閑信息融入預測結果中。
1 循環神經網絡
1.1 LSTM模型
LSTM是RNN的一種變體,主要的改進之處就是增加了三個控制門單元:遺忘門、輸入門和輸出門[16]。LSTM單元結構如圖1所示。

圖1 LSTM單元結構Fig.1 LSTM cell structure
為便于了解,描述LSTM和BiLSTM模型所用到的相關變量在表1中聲明。
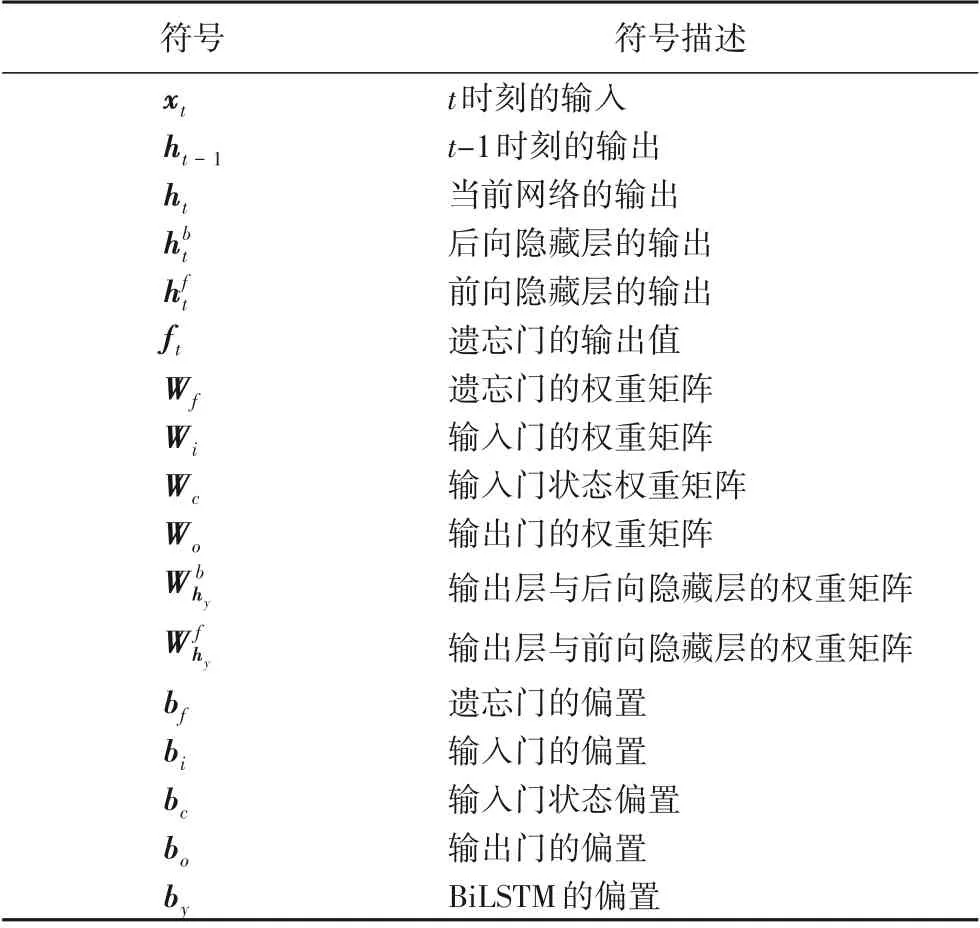
表1 LSTM模型相關變量說明Tab.1 Description of LSTMmodel related variables
遺忘門計算公式如式(1)所示:

輸入門計算公式如式(2)所示:
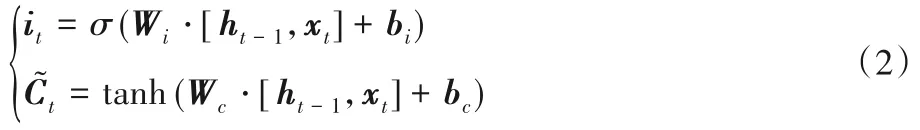
新細胞狀態信息由遺忘門和輸入門共同決定,如式(3)所示:

LSTM的輸出由輸出門和細胞狀態信息Ct共同決定,如式(4)所示:
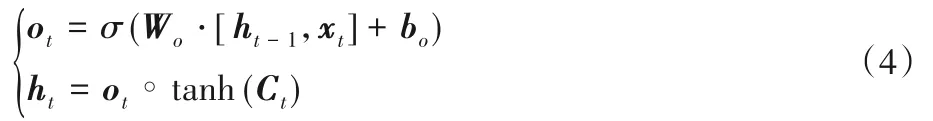
1.2 BiLSTM模型
單向神經網絡僅從過去的輸入中學習依賴關系來預測輸出,雙向神經網絡不僅能學習過去的趨勢還能集合未來的趨勢信息。圖2展示了BiLSTM的結構模型。模型通過兩個獨立的隱藏層來分析正向和方向序列,將這些隱藏層作為輸入傳遞給同一輸出層[11]。輸出yt的計算公式如式(5)所示:

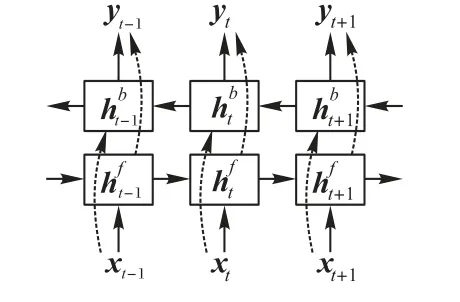
圖2 BiLSTM結構Fig.2 BiLSTM structure
2 基于雙向循環神經網絡的預測模型
本章詳細闡述基于雙向循環神經網絡的周期型容量指標數據預測模型。首先,介紹本文提出的指標數據類型分類方法;其次,介紹提出的忙閑分布分析方法;最后,結合系統忙閑分布,通過有監督學習,實現對雙向循環神經網絡輸出結果的優化調整。
2.1 指標數據類型劃分方法
2.1.1 動態時間規整
動態時間規整(Dynamic Time Warping,DTW)通過最小化 原 始 序 列x(i),i∈[1,M]和 待 對 齊 的 時 間 序 列y(j),j∈[1,N]之間的累積距離來提供兩個時間序列之間的非線性對齊最佳路徑[17],故可以通過兩個時間序列之間的累積距離來衡量兩個時間序列的相似性。用d來表示序列兩點之間的距離集合,其中di,j定義如式(6)所示:

用D來表示累積距離合集,其中Di,j表示從原點(1,1)到點(i,j)的最小累積距離。具體計算方式如式(7)所示,其中i=2,3,…,M,j=2,3,…,N。
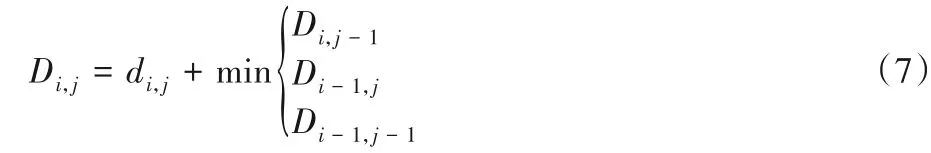
初始條件如式(8)所示:
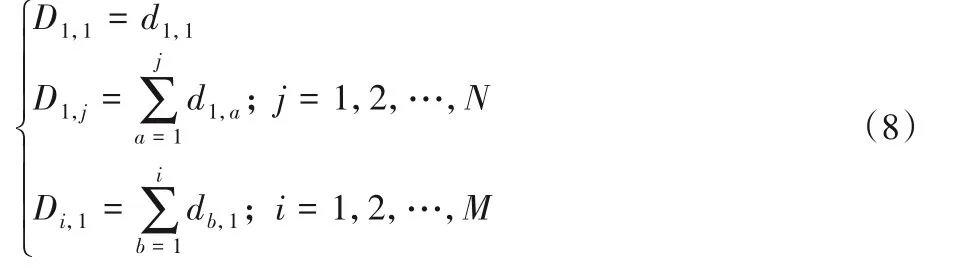
經過初期調研得知不少業務的關鍵指標數據呈現日周期性。本文選取了一段時長為k天的時間序列value,比較相鄰兩天時間序列之間的相似度,即求相鄰兩天的DTW距離,得到長為k-1的距離序列dist_list,將dist_list與預先設置的DTW閾值比較判定該時間序列是否具有一定的日周期性。
2.1.2 數據類型劃分方法
利用動態時間規整、平均值、標準差等數據特征將指標數據類型劃分為趨勢型、周期型和不規則型,數據類型劃分流程如圖3所示。
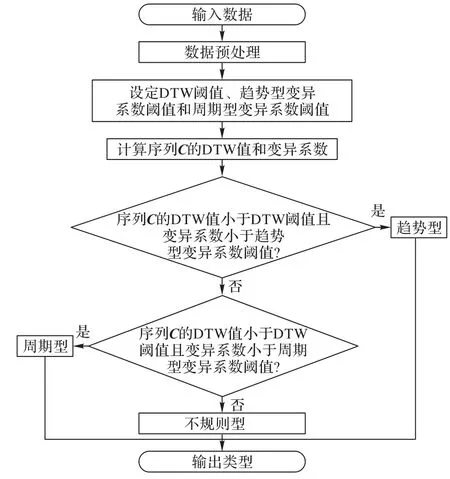
圖3 數據類型劃分流程Fig.3 Data type division process
具體方法如下:
1)數據預處理。對監測到的目標設備的指標數據進行清洗,得到指定格式的指標序列C。
2)數據類型判定。計算序列C的DTW值value_dtw和變異系數value_cv,其中變異系數是原始數據標準差與原始數據平均數的比值,用來比較衡量數據離散程度大小。將value_dtw和value_cv與設定DTW閾值threshold_dtw、趨勢型變異系數閾值threshold_cv_trend和周期型變異系數閾值threshold_cv_periodic進行比較,判定數據類型,具體過程如下:
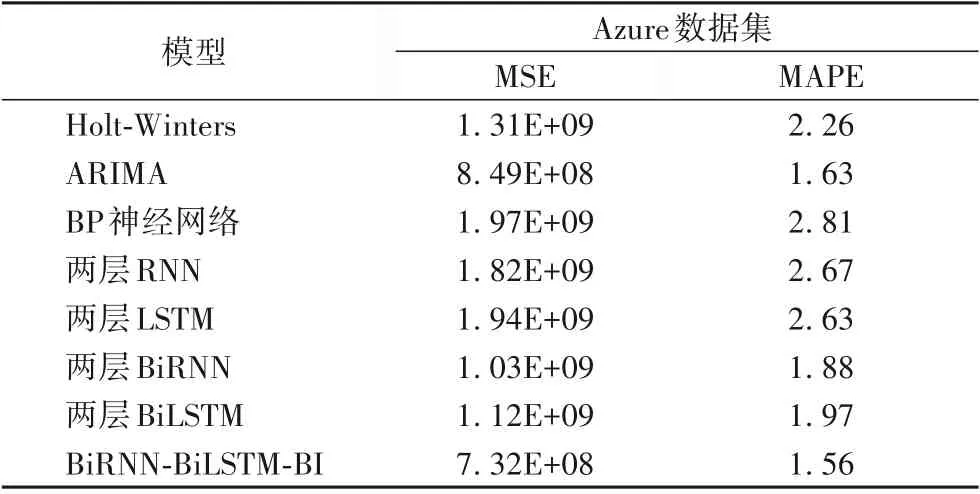
步驟1 若value_dtw 步驟2 若value_dtw 步驟3 該類型為不規則型。 3)數據類型輸出。輸出2)中數據類型判定結果。 國有企業在我國國民經濟中的獨特地位和作用,其會計信息披露工作就尤為重要。我國國有企業傳統的發展模式存在的弊端使得國有企業的經營和發展存在著很多漏洞,長此以往,不只會影響到國有企業的正常經營和發展,對于我國經濟社會發展也會起到不利的影響。所以在當今的經濟社會背景下,國有企業只有通過會計信息披露,加強公眾對其的監督,才能夠保證國有企業的健康穩定發展。 業務系統的運行狀態往往與人類日常行為密切相關,比如電信行業的“前臺頁面”這一業務系統,主要集中在日間工作時間,由營業廳工作人員進行使用,夜間的使用率則會降低。如此,業務系統的性能數據就會表現出一些規律,并且根據業務性質的不同,表現出的規律也會不同。為了實現高效的容量預測,首先要對性能數據和業務系統進行分析,此處主要通過對系統歷史性能數據進行分析以了解該業務系統的忙閑分布情況,應用方可結合系統忙閑時段分布和相關性能指標閾值合理配置系統資源。本文設計了一種忙閑分布分析算法對業務系統的關鍵指標進行分析以得到系統的忙閑分布規律。具體方法如下: 1)以CPU指標為例,對采集到的歷史指標數據序列C=[c1,c2,…,ct]進行預處理,得到等時間間隔分布的指標數據,其中ci∈[0,100]。 2)設定想要獲取的忙閑粒度interval,以及周期長度period,其中interval和period均代表時長。 3)將一天中采集到的歷史數據按從大到小進行排序得到序列A,設定一個閾值百分比μ,則當天的忙閑閾值λ=A[INT(len(A)?μ)]。 4)對歷史數據進行忙閑標記,若第i天的第n個采集指標值cn小于當天忙閑閾值λi即cn<λi時,將該采集點標記為閑;否則標記為忙。 5)將標記后的序列C按每interval時長為一段劃分為interval_nums段,舍棄掉最后不足的部分,對每段數據進行如下處理直至該段只剩一個標記點: 步驟1 每N個連續標記點為一組,對歷史數據進行劃分,舍棄掉最后不足N的部分; 步驟3 對重新標記的忙閑標記序列重復步驟1、2。 6)將忙閑序列按照周期時長period進行劃分,得到二維數 組A=[a1;a2;…;am],其 中ai=[bi1,bi2,…,bin],bij∈{0,1},ai表示第i個周期,bij表示第i個周期中第j段的忙閑值,其中0表示閑,1表示忙。對A的每列進行頻數統計,用第n列出現頻數多的值sn表示該段狀態,得到指定周期的忙閑分布規律S=[s1,s2,…,sn]。 忙閑時段分布算法將一天劃分為忙、閑和過渡三個時段,為充分利用忙閑信息,模型通過在循環神經網絡后增加一層線性回歸對預測結果進行進一步的優化,具體設計如下: 1)數據預處理。首先對監測到的目標設備的指標數據進行清洗,填充空值,得到指定格式的指標序列C。 2)使用忙閑時段分布算法對序列C進行分析。將序列C按天進行劃分得到每天的數據序列An,即C=[A1,A2,…,An],設定兩個忙閑閾值百分比μ1、μ2,則第i天對應的兩個閾值λi1和λi2分別為Ai[INT(len(Ai)*μ1)]和Ai[INT(len(Ai)*μ2)]。利用忙閑算法得到代表指定時間粒度忙閑分布規律的0,1序列Sa、Sb,利用式(9)得到最終忙閑分布規律序列S=[s1,s2,…,sn],sn∈{0,1,2},0代表閑,1代表忙,2代表過渡段。 3)構建基于雙向循環神經網絡的周期型容量數據預測模型。較單層網絡而言,兩層循環神經網絡能學習到更多隱藏信息,且進過初步實驗比較,兩層模型效果更佳,故本模型設計為兩層網絡。首先將性能指標序列輸入到第一層雙向RNN,其中RNN用來挖掘性能指標隨時間變化的規律,而雙向神經網絡不僅能學習過去的趨勢還能集合未來的趨勢信息。為防止過擬合,模型在雙向RNN層后面設計了Dropout層,然后再與雙向LSTM層連接。本文設計的模型在雙向LSTM層后面添加了一層全連接層,通過全連接層匯總各個時間步的歷史數據對未來時間點數據的影響然后輸出一個實數值作為兩層循環神經網絡的預估。最后將全連接層的輸出按照日忙閑分布分為忙、閑和過渡段三類,將三類數據分別輸入到三個線性回歸模型。模型結構如圖4所示。 圖4 BiRNN-BiLSTM-BI模型結構Fig.4 BiRNN-BiLSTM-BImodel structure 4)訓練模型。把歷史數據劃分成訓練集和測試集,將訓練集原始數據輸入忙閑分布算法模型得到忙閑分布序列,然后將數據輸入基于雙向循環神經網絡的周期型容量數據預測模型進行訓練,并對訓練好的模型進行評估。 本章首先介紹了實驗數據的概況;然后,給出實驗運行環境、使用到的工具、實驗參數的設置以及評價指標等;接著,實現本文提出的基于雙向循環神經網絡的周期型容量數據預測模型,并且實現相關研究中提到的一些算法以作對比;最后,對實驗結果進行比較分析。 作為衡量主機性能最重要的指標之一的CPU,是需求最高的資源故而也是主機資源短缺的主要原因[18],故本文選擇CPU資源作為實驗對象。本實驗使用的是北京思特奇信息技術有限公司(http://www.si-tech.com.cn)提供的某省電信運營商客戶關系管理(Customer Relationship Management,CRM)系統的性能監測數據。從呈現日周期型數據特性的分支業務中選取了規模較大的統一日志和分布式緩存兩個業務,再各隨機選擇了約4個月CPU數據作為實驗數據。服務器每6 min采集一次指標數據,每臺服務器約31 200條CPU數據,監控中心采集數據樣例如表2所示。由于頻繁預測會占用大量資源,公司實際生產中要求以小時為粒度進行預測,故在預測前需要對數據進行處理。 表2 監控中心采集數據樣例Tab.2 Sample data collected by monitoring center 實驗是在具有3.20GHz時鐘頻率的Inter Core i7-8700處理器上運行的,內存大小為16 GB。實驗設計為通過前t小時CPU使用率預測t+1小時CPU使用率。結合運維人員工作經驗,并考慮到電信行業運營部門的工作時長約占一天的0.33,故設定兩個忙閑閾值百分比μ1=0.25,μ2=0.35,求得忙閑閾值λ1,λ2。將原始數據按照0.8∶0.2劃分成訓練集和測試集,通過對不同個數神經元和不同損失函數進行嘗試,選擇最優組合進行實驗,具體如表3所示。 表3 參數設置Tab.3 Parameter setting 預測的準確率通過均方誤差(Mean Squared Error,MSE)和平均絕對百分比誤差(Mean Absolute Percentage Error,MAPE)衡量。MSE和MAPE計算公式如下: 其中:truet為第t個時間點的真實值,predictedt為第t個時間點的預測值,m為樣本總數。 3.3.1 忙閑結果分析 以某服務器CPU指標數據為原始數據進行忙閑分析,設定兩個波動值μ1=0.25,μ2=0.35。將μ1和μ2分別作為忙閑閾值百分比代入忙閑分布算法,求得以小時為粒度的每天忙閑分布序列S1和S2。 S1=[0,0,0,0,0,0,0,0,0,1,1,1,0,0,1,1,1,1,0,0,0,0,0,0] S2=[0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0] 如圖5所示,實線為標準化后的CPU使用率。分析灰實線可以看出,該業務服務器CPU使用率在日間較大而夜間較小,且日間中午時會稍微回落。黑虛線為當μ1=0.25時所得的忙閑分布序列S1,由于此時忙閑閾值λi1較大,所以處于忙狀態的時段并不多,大部分時段處于閑狀態。灰虛線為當μ2=0.35時所得的忙閑分布狀態序列S2,此時忙閑閾值λi2相對較小,所以處于忙狀態的時段較S1相比更多。通過式(9)求得最終忙閑分布序列S。 圖5 忙閑分布Fig.5 Busy and idle distribution S=[0,0,0,0,0,0,0,0,0,1,1,1,2,2,1,1,1,1,2,2,0,0,0,0] 3.3.2 預測結果分析 為驗證基于雙向循環神經網絡的周期型容量指標數據預測模型是否具有良好效果,以LSTM、BiLSTM、RNN和BiRNN等模型作為對照組進行實驗。 圖6為使用一層BiRNN和一層BiLSTM構成的BiRNNBiLSTM網絡模型進行測試得到的結果,圖7為使用基于雙向循環神經網絡的周期型容量指標數據預測模型進行測試的結果。圖6、7中橫軸為時間軸,總共有624個時間切片,每個時間切片表示1 h;縱軸表示范圍在[0,100%]的CPU使用率。分析圖6、7可知,BiRNN-BiLSTM網絡雖然能夠反映CPU使用率的變化趨勢,但是在波峰和波谷處與真實曲線擬合效果不理想,而基于雙向循環神經網絡的周期型容量指標數據預測模型能夠更好地跟蹤CPU使用率的變化趨勢,實現了更精確的預測。 圖6 BiRNN-BiLSTM預測結果Fig.6 BiRNN-BiLSTM prediction results 圖7 BiRNN-BiLSTM-BI預測結果Fig.7 BiRNN-BiLSTM-BIprediction results 表4分別列出了在統一日志業務和分布式緩存池業務這兩個數據集上,使用5種模型進行預測得到的MSE值。由表4可知,對于統一日志業務,兩層BiLSTM模型的MSE為5.568 0,小于除本文模型的其余幾個網絡模型,而BiRNNBiLSTM-BI模型的MSE為4.176 6,MSE值比兩層BiLSTM模型少24.99%。對于分布式緩存池業務,BiRNN-BiLSTM-BI模型比其余模型中最優的兩層BiRNN模型減小了5.33%。 表4 五種兩層網絡模型預測結果Tab.4 Prediction resultsof five two-layer network models 將其與傳統的預測方法即ARIMA、Holt-Winters算法及BP神經網絡做對比,幾種算法MSE平均值如表5所示。由表5可知,對于統一日志業務,Holt-Winters三次指數平滑算法結果為4.923 0,小于ARIMA和BP神經網絡,而BiRNNBiLSTM-BI模型的MSE為4.176 6,誤差值比Holt-Winters指數平滑算法降低15.16%。對于分布式緩存池業務,BiRNNBiLSTM-BI比其余模型中最優的Holt-Winters降低了45.67%。 表5 本文模型與傳統模型預測結果比較Tab.5 Prediction results comparison of proposed model and traditional models 為了驗證該容量預測模型的能力,在Kaggle上選取了一個Microsoft Azure發布的虛擬機CPU使用量數據集做進一步實驗。由于數據集記錄的是CPU的具體大小而不是使用率,故加入MAPE作為評價指標。 由表6可知,充分利用忙閑分布信息的BiRNN-BiLSTMBI模型表現最優,其MAPE分別比文獻[13]中提出的BiRNN模型和BiLSTM模型降低了0.32和0.41。 表6 Azure數據集上的預測結果Tab.6 Prediction results on Azure dataset 從上述實驗結果中可知,BiRNN-BiLSTM-BI網絡模型預測精度更高、誤差更小,說明該模型能更好地對周期型容量指標數據進行預測。 針對容量指標數據類型繁多、預測算法在不同數據類型的指標數據上表現參差不齊的問題,本文提出具體指標數據類型分類方法,對數據類型進行劃分,再進行預測。針對其中周期型容量數據預測,提出了一種基于雙向循環神經網絡的周期型容量指標預測模型。首先,提出了一種分析忙閑狀態分布情況的算法,利用該算法對業務系統的忙閑分布進行分析;其次,搭建循環神經網絡模型;最后,結合忙閑分布特征對結果進行優化。通過在真實數據集上進行對比實驗,驗證了本文提出模型的有效性。后續工作將繼續研究如何優化趨勢型和不規則型的預測準確度,并將模型應用于實際電信容量管理中。 感謝電子科技大學-思特奇未來信息科技聯合研究院對實驗工作的支持;感謝電子科技大學詹會蘭、王問驍等同學對本文實驗工作的幫助。2.2 忙閑時段分布算法
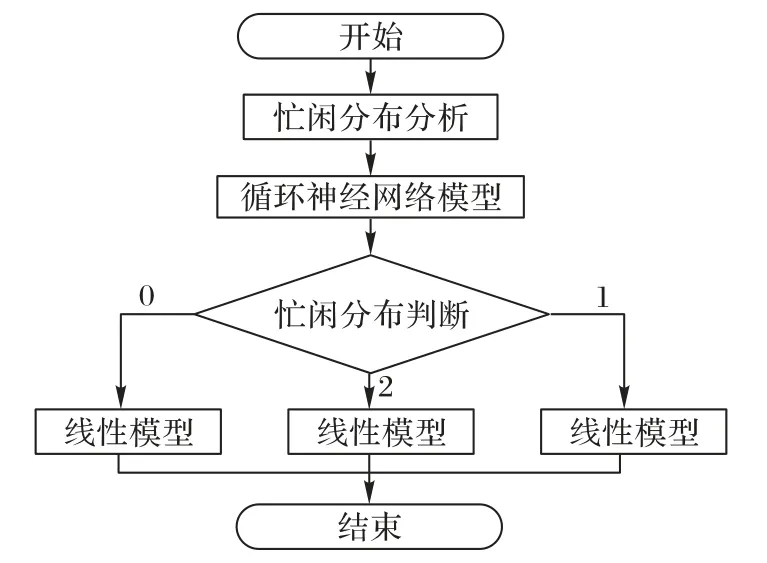
2.3 基于雙向循環神經網絡的預測模型

3 實驗與結果分析
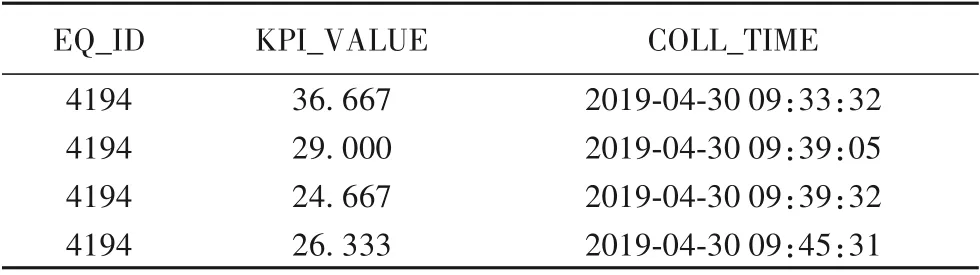
3.1 實驗數據
3.2 實驗環境
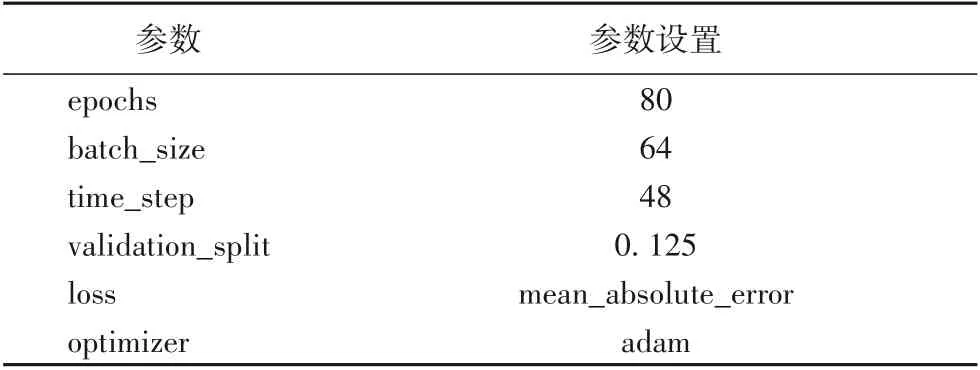
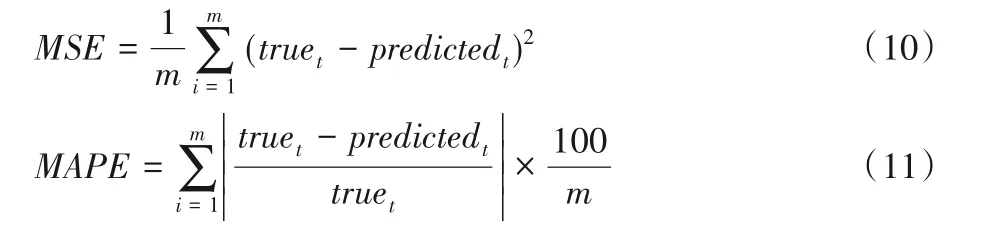
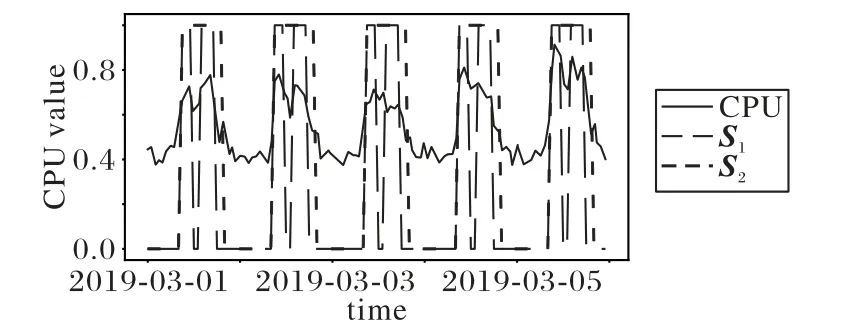
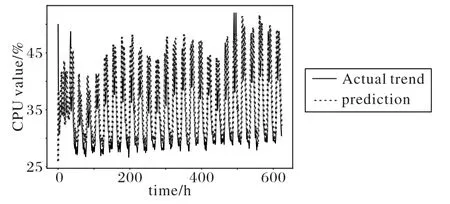
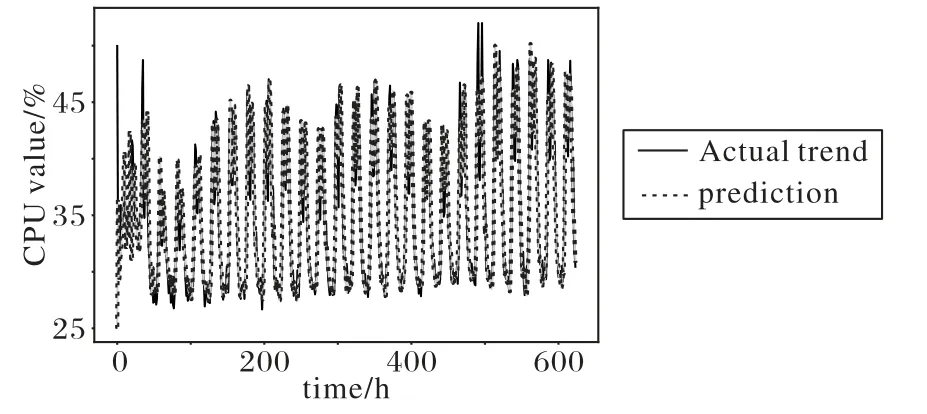
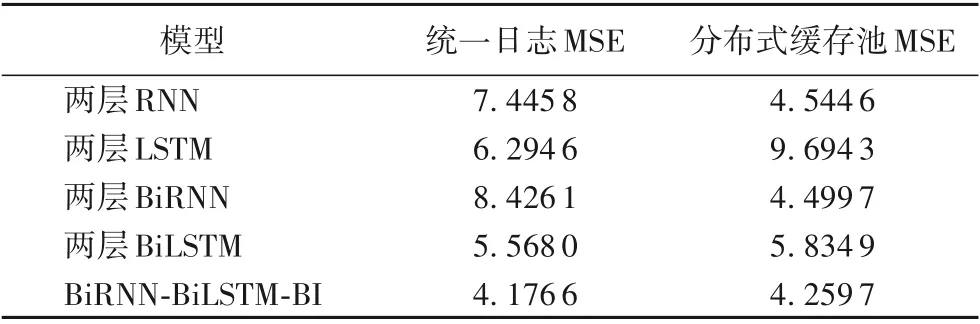
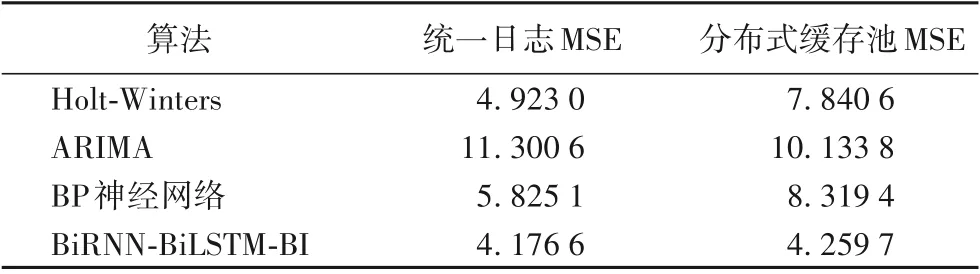
3.3 基于雙向循環神經網絡的預測模型
4 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38網絡安全與數據管理(2022年1期)2022-08-29 03:15:20導航定位學報(2022年4期)2022-08-15 08:27:00中學生數理化·中考版(2022年8期)2022-06-14 06:55:24新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36成都醫學院學報(2021年2期)2021-07-19 08:35:14新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24光學精密工程(2016年6期)2016-11-07 09:07:19
