基于深度學習的醫學影像分割研究綜述
2021-09-09 08:09:00曹玉紅劉蓀傲王紫霄李宏亮
計算機應用 2021年8期
關鍵詞:模型
曹玉紅,徐 海,劉蓀傲,王紫霄,李宏亮
(1.中國電子學會,北京 100036;2.中國科學技術大學信息科學技術學院,合肥 230026;3.中國科學院大學工程科學學院,北京 100049)
0 引言
隨著醫學影像成像技術和成像設備的快速發展和普及,全球每天產生大量的醫學影像數據,借助計算機進行醫學影像分析在臨床診斷、手術方案制定中的重要性日益凸顯[1]。其中,醫學影像分割能夠有效地提取目標區域的形狀和空間信息,是進行醫學影像定量分析的關鍵步驟之一[2],目的是以機器視覺方式自動從醫學圖像中逐像素地識別出目標區域(器官、組織或病灶)。早期的醫學影像分割系統主要基于傳統的圖像分割算法搭建,如基于邊緣檢測的分割算法[3]、基于閾值的分割算法[4]和基于區域的分割算法[5]。但醫學圖像通常具有對比度低、組織紋理復雜、邊界區域模糊等特點,極大地限制了此類圖像分割算法的效果和應用場景。隨后,針對特定任務設計手工特征的分割算法很長一段時間成為了醫學影像分割的研究主流[6],然而手工特征的設計極大依賴醫生的專業先驗知識,而且往往泛化能力差,無法遷移到新的任務場景下。因此在實際應用中基于傳統圖像分割技術的醫學影像分割系統仍然不夠成熟,無法獲得令人滿意的分割效果。
近年來,隨著計算機技術和人工智能的快速發展,卷積神經網絡(Convolutional Neural Network,CNN)[7-9]強大的建模能力被廣泛研究,相比傳統的算法,基于卷積神經網絡的深度學習算法在圖像處理各領域帶來了突破性的進展,如圖像分類[10]、語義分割[11]等,基于深度學習的圖像分割算法也被引入到醫學影像分割[12-15]中。深度學習算法的自動提取特征能力有效地克服了傳統醫學圖像分割算法過多依賴醫療專家先驗認知這一弊端,且深度學習算法的可移植性高,借助遷移學習能夠快速地拓展到不同的任務場景下。
盡管深度學習在圖像分割中取得了突破性的提升,醫學影像其區別于自然場景圖像的特點決定了醫學影像分割需要面臨更大的挑戰,主要來源于以下幾個方面:
1)醫學影像邊緣模糊不清。
受限于成像技術,醫學影像相較于自然圖像往往有對比度低、噪聲較大的特點,同時醫療影像中組織紋理復雜,邊界模糊不易區分。此時如何提升網絡模型的抗干擾能力和魯棒性,以及對邊界附近像素的準確性是一個非常大的挑戰。
2)醫學影像標注數據少。
醫學影像數據獲取困難(尤其對于罕見疾病),同時圖像分割任務訓練過程中需要對圖像每個像素的類別進行標注,而且醫學影像標注對醫療專業知識依賴性高,因此,獲取足夠多的標注樣本是極度耗時耗力的。如何在有限的標注樣本下,減輕訓練分割模型時對像素級標注的依賴,是醫學影像分割的另一挑戰。
3)醫學影像標注誤差大。
醫學影像病變形態學上高度異質化,使得標注過程極大依賴于醫療專家的認知和經驗,而考慮到標注醫生主觀標準上的不確定性和不同專家客觀上的認知差異化,標注過程中漏標、誤標不可避免,標注的準確度并不完全可靠。如何在有限的醫療標注資源下,對模型不確定性的準確量化,是當前面臨的又一挑戰。
綜上所述,深度學習在醫學影像分割中具有廣闊的應用前景,但同時也面臨巨大的挑戰。
1 相關工作
隨著深度學習的崛起,研究人員將應用于自然圖像的分割算法[11,16-17]引入到醫學領域。其中最具代表性的研究工作是全卷積網絡(Fully Convolutional Network,FCN)[11],FCN實現了不改變圖像尺寸的情況下對分割網絡進行端到端(End to End)的訓練,并較傳統方法取得了顯著性的提升。伴隨著FCN的成功,研究人員開始關注如何針對醫療影像的特點對分割網絡進行改進,考慮到醫療圖像具有豐富的空間信息(如復雜的紋理結構),而網絡下采樣過程容易丟失空間信息,基于編碼-解碼(Encoder-Decoder)的網絡結構開始嶄露頭角。中國科學院慈溪醫工所團隊[12]結合具有對稱結構的編解碼網絡對視網膜血管進行了精細化分割,并基于分割結果量化分析了健康人群視網膜和阿茲海默癥患者之間的差異。實際上醫學影像數據大多數為3D的容積數據(如CT(Computed Tomography)、MRI(Magnetic Resonance Imaging)數據),為了保留不同層間的位置關系,Cicek等[18]通過將二維卷積層替換為三維卷積層構建了3D U-Net,實現了3D數據的端到端處理。隨著基礎模型的完善,人們開始更多地考慮如何優化分割的效果,如引入注意力機制來優化特征,以達到減小類內差異同時增大類間差異的目的。中國科學技術大學Xie等[15]根據腫瘤位置關系提出級聯的注意力分割網絡,有效提高了腦膠質瘤區域分割精度。此外,研究人員嘗試從目標函數、增大感受野、解決類別不平衡等多種角度對分割模型進行優化。
盡管深度神經網絡相比傳統算法表現出了顯著的進展,但在實際應用中醫學圖像標注過程耗時耗力,限制了深度學習算法在該領域的進一步發展。相對地直接獲取大量的醫學影像數據較為容易,因此為了減輕對標注的依賴、降低成本,半監督學習算法得到了廣泛的關注和研究。半監督醫學影像分割的核心是如何利用未標注的數據,基于自訓練(Selftraining)和協同訓練(Co-training)的算法是此領域最常見的半監督分割算法,此類方法通過為未標注數據生成偽標簽(Pseudo Label)并優化更新方式進行迭代訓練。半監督學習中為了能夠使用少量標注數據訓練出更加魯棒的模型,提出了對未標注數據添加擾動并對預測一致性進行約束的方法[19-20],如基于均值教師(Mean Teacher,MT)的半監督方法[20]和基于幾何變換一致性的方法[21]。此外,研究人員開始考慮更多樣的利用未標注數據的方式,如基于圖(Graph)進行正則化[22-23],基于生成對抗網絡(Generative Adversarial Network,GAN)[24]來生成更多的可用于訓練的數據也是提升半監督分割效果的方法之一。
由于標注醫生主觀標準上的不確定性和不同專家客觀上的認知差異化,標注的準確度并不完全可靠,因此對醫學影像分割中的預測結果給出定量的不確定性度量是輔助診斷的重要補充,近期關于醫學影像分割的不確定性也開始引起新的研究熱潮。根據不確定性的分布類型角度,Swiler等[25]將其分為認知不確定性(Epistemic uncertainty)和隨機不確定性(Aleatoric uncertainty)。認知不確定性是指模型認知上的不確定性,研究者根據對模型不確定性評估的方式不同,將其大致分為兩大類,即深度模型集成(Deep model ensemble)[26]和深度貝葉斯網絡(Deep Bayesian Neural Network)[27]。隨機不確定性指的是觀測中固有的噪聲,這部分不確定性來源于醫療設備成像的數據本身噪聲以及標注存在的不可控誤差。
2 全監督醫學圖像分割
近年來,卷積神經網絡[7-8]已經成為處理圖像分割任務的主流方法,并被廣泛拓展到醫學圖像分割當中。卷積網絡能夠通過學習特定的卷積核提取豐富的圖像特征,從而生成有效、準確的分割結果。受限于計算資源,卷積網絡通常由多個小尺寸的卷積層堆疊而成,并在此過程中進行下采樣操作以減小圖像的空間尺寸,從而逐步擴大卷積核的感受野,實現由淺到深、由局部到整體的多級特征提取。
全監督學習是醫學影像分割任務最基本、應用最廣泛的方法。全監督的語義分割要求提供像素級的標注作為訓練參考,對于訓練數據量以及標注具有較高的要求。盡管醫學影像數獲取困難,數據集構建成本高,但是為了滿足醫學領域的巨大需求,目前已經出現了許多公開的醫學圖像數據集,保證了全監督醫學圖像分割研究的充分發展。
2.1 網絡結構
醫學圖像在數據結構上與自然圖像類似,同時,醫學圖像也存在與自然圖像明顯不同的特性,如空間尺寸、目標大小、成像質量等。基于這些特性,研究者對自然圖像的網絡結構進行改進,構建更適用于醫學領域的模型。總體來說,目前用于醫學分割的網絡都沿用了編碼器-解碼器的對稱結構,并在此基礎上強化圖像特征的提取。本節將首先介紹編碼器-解碼器的一系列經典網絡結構,隨后介紹改進模塊,如注意力機制與新型卷積等,最后將介紹針對特定任務使用的模型級聯策略。
2.1.1 編碼器-解碼器結構
與圖像分類任務不同,分割任務要求生成與輸入圖像尺寸一致的像素級分割結果,因此無法直接將分類任務的網絡結構應用于分割任務。全卷積網絡[11]通過將全連接層替換為卷積層,實現了基于卷積神經網絡的圖像分割。由于在特征提取過程中存在下采樣操作,在生成分割結果時需要通過插值計算進行上采樣。在此基礎上,Ronneberger等[14]提出了用于細胞分割的U-Net,這一結構隨后被廣泛應用于各種醫學圖像分割任務中。U-Net包括用于特征提取的編碼器,以及與之對稱、用于恢復空間分辨率并生成分割結果的解碼器,具體結構如圖1所示。由于網絡整體形狀類似于字母U,故被稱作U-Net。U-Net的編碼器部分通過堆疊3×3卷積層與激活函數實現特征提取,并通過2×2最大池化層降低分辨率,每次將空間尺寸減半并加倍通道數。在解碼器部分,使用2×2的轉置卷積恢復空間分辨率,并通過跳躍連接(Skip Connection)將上采樣后的特征與編碼器部分同層的特征進行級聯(concatenation),作為后續卷積層的輸入。
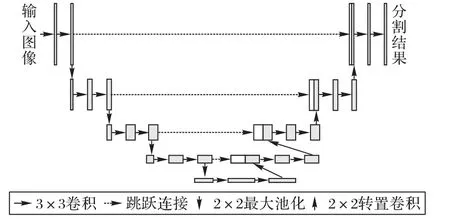
圖1 U-Net的網絡結構Fig.1 Network structureof U-Net
U-Net最初被設計用于2D圖像的細胞分割,而很多醫學圖像數據實際為3D的容積數據。盡管可以將容積數據拆分為2D圖像序列進行處理,但這種方式忽視了不同層間的位置關系,并且往往不同位置的圖像差別較大,不利于網絡學習通用特征。因此Cicek等[18]通過將二維卷積層替換為三維卷積層構建了3DU-Net,實現了3D數據的端到端處理。結合深度學習領域的相關研究,Milletari等[13]提出了V-Net以更好地處理容積數據。相比于3DU-Net,V-Net的改進包括:1)使用更有效的激活函數PReLU(Parametric Rectified Linear Unit);2)使用步長為2的2×2卷積代替最大池化(Max Pooling)實現下采樣;3)在卷積層引入了殘差連接以提升學習效果。
U-Net通過跳躍連接實現了不同層級的特征融合,提高了分割精度。Zhou等[28]進一步對多層特征的融合方式進行改進,提出了U-Net++,結構如圖2所示。U-Net++將U-Net中簡單的跳躍連接替換為卷積層,并且在同分辨率下的不同卷積層、相鄰分辨率下的卷積層間添加跳躍連接,從而形成密集連接以強化特征融合。為了保證網絡的充分學習,U-Net++還添加了多個中繼監督層同時計算損失函數。得益于此,U-Net++可以根據算力情況通過剪枝減小模型規模,而性能僅有小幅度下降。
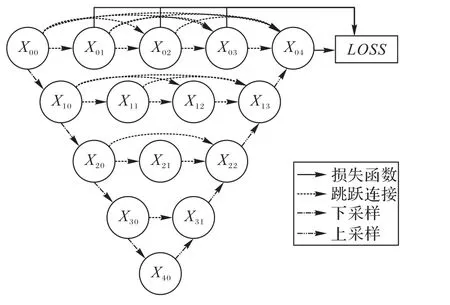
圖2 U-Net++的網絡結構Fig.2 Network structureof U-Net++
2.1.2 注意力機制
隨著對神經網絡研究的不斷深入,注意力機制逐漸得到了廣泛的應用,這一機制在人類視覺系統中同樣至關重要。概括地說,注意力機制通過計算注意力權重,對特征進行重加權,以達到強化有效特征、抑制無效特征的目的。根據應用位置的不同,可以分為空間注意力與通道注意力。通道注意力的 典 型 代 表 為SENet(Squeeze-and-Excitation Network)[29]。SENet提出了壓縮-激發(Squeeze-and-Excitation,SE)模塊以對不同通道的特征進行加權,如圖3所示。該模塊通過全局平均池化(Average Pooling)將尺寸為C×H×W的輸入特征壓縮為C×1×1,再通過全連接層計算通道注意力權重,與輸入通道相乘得到加權后的權重。此模塊的優點在于計算量小且即插即用,因此常被應用在醫學任務中作為對U-Net的改進[30],取得了較好的效果。
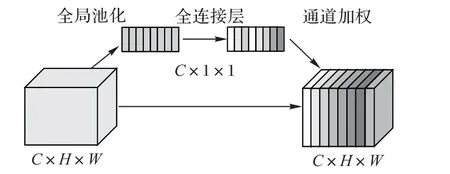
圖3 SE模塊結構Fig.3 Structure of SE module
空間注意力則以Non-local[31]的一系列工作為代表。區別于通道注意力,空間注意力給每個像素計算注意力圖以實現全圖范圍的特征提取,從而有效地彌補了卷積操作因感受野有限導致的全局特征提取能力的不足。標準的Non-local空間注意力計算流程如圖4所示。給定輸入特征X={x1,x2,…,xHW},首先計算像素間的特征相似度:

其中θ(?),?(?)為線性變換,由1×1卷積實現。σ(?)為softmax函數,用于將相似度歸一化:
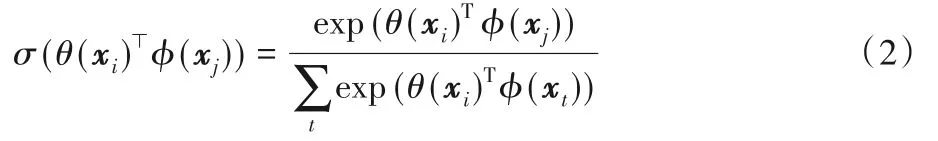
至此,可以得到每個像素的全圖注意力圖。隨后進行特征重加權:

在圖4的模塊中,還額外加入了殘差連接以保證訓練過程的穩定性。空間注意力優越的長距離特征提取能力同樣也可應用在醫學圖像分割當中,例如He等[32]表明,引入空間注意力可以有效地提升醫學圖像分割網絡對于對抗攻擊的魯棒性。
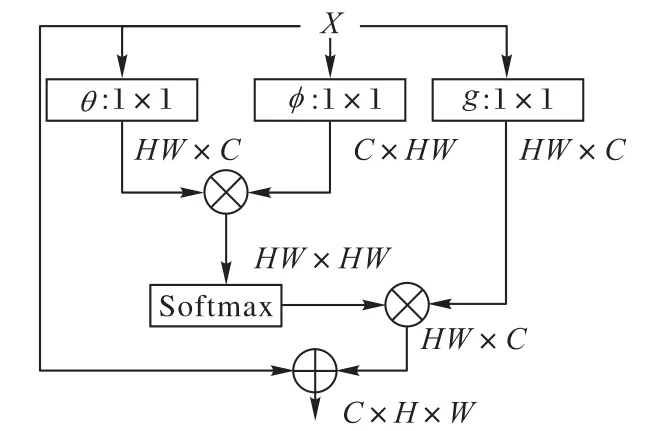
圖4 Non-local模塊結構Fig.4 Structureof Non-local module
注意力機制的核心是通過計算注意力圖實現特征的重加權,遵循這一思想,可以根據特定的醫學圖像分割任務設計與上文不同的注意力計算模塊。以腦膠質瘤的分割為例,在腦部腫瘤分割挑戰賽(BraTS)[33]數據集中,膠質瘤被劃分為三個等級:全腫瘤(Whole Tumor,WT)、腫瘤核心(Tumor Core,TC)和增強腫瘤(Enhancing Tumor,ET),而三者存在包含關系,即ET?TC?WT。因此,可以通過依次分割三個等級的腫瘤實現由粗到精的精細分割。
OMNet(One-pass Multi-task Network)[34]將這種逐級分割的思想引入通道注意力中,根據前一級腫瘤的分割情況調整通道重要性,用于強化下一級腫瘤的分割效果。而DCAN(Deep Cascaded Attention Network)[15]則以此改進空間注意力,根據前一級的分割結果對背景區域的像素進行抑制,使下一級腫瘤的分割更集中在前一級的分割區域。
2.1.3 改進卷積計算
標準卷積的問題在于感受野有限且固定,導致其無法有效地提取全局信息。為了增大感受野,需要堆疊多層卷積層并通過下采樣操作降低空間分辨率。然而,這種操作仍存在局限性,因此出現了許多對卷積運算的改進工作,例如空洞卷積[35]與可變形卷積(圖5)[36]。空洞卷積的優勢在于可以在不進行下采樣、不增加參數量的前提下擴大卷積運算的感受野,從而可以在更高的分辨率下進行特征提取,避免因下采樣造成的空間信息損失,而將空洞卷積整合到U-Net的編碼器結構中已經被證明對醫學圖像分割同樣具有提升效果[37-38]。
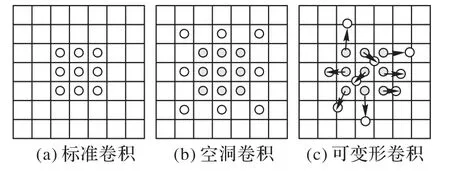
圖5 標準卷積、空洞卷積和可變形卷積示意圖Fig.5 Schematic diagram of standard convolution,dilated convolution and deformable convolution
空洞卷積僅是在標準卷積的基礎上增加空洞以擴大計算范圍,因此與后者同樣是計算位置固定的卷積操作。然而對于不同的像素,模型希望卷積核能夠根據像素之間的相關性自適應地選擇計算位置,從而實現更有效的特征提取。為了實現這一目標,可變形卷積通過額外的偏移預測分支,為輸入特征的每個像素計算卷積計算時的偏移量,使特征提取更集中、高效。這一運算同樣可以應用于醫學圖像分割中,例如Guo等[39]提出了使用可變形卷積進行多模態器官分割,并通過在偏移預測中引入全局信息進一步強化了可變形卷積的特征提取能力。
如前文所述,與自然圖像不同,相當一部分醫學圖像(如磁共振影像)實際上為三維容積數據。盡管可以使用三維卷積網絡直接計算,但相較于二維網絡,三維網絡的參數量呈指數級增加,限制了其推廣應用。而如果使用二維網絡計算,則會完全忽略一個維度的信息,影響分割效果。為了緩解這一問題,WNet(Whole tumor Network)[37]提出使用二維卷積提取平面信息,并隨后使用一維卷積提取第三個維度的信息。同時如圖6所示,醫學三維影像對于三個維度的切面具有明確的定義,即冠狀面(Coronal)、矢狀面(Sagittal)和橫斷面(Axial),每個切面能夠顯示的醫學信息有所不同。由于不對稱的卷積結構對三個維度的提取能力不同,WNet提出多視角訓練策略,即將三維數據以三個方向輸入網絡分別訓練,但也導致了計算時間的加倍。區別于WNet,MFNet(Multidirection Fusion Network)[38]在 將 三 維 卷 積 拆 分 為 偽 三 維 卷積[40]的基礎上提出了多方向融合模塊,如圖7所示。該模塊使用三支并行的計算分支,每個分支從不同方向將3×3×3卷積拆分為3×3×1與1×3×3卷積。相較于WNet,該方法同時從三個方向提取特征并進行融合,避免了多次訓練與推理的額外計算開銷。
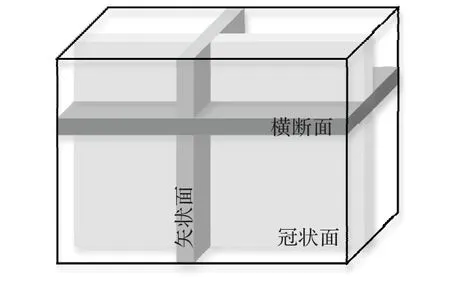
圖6 醫學影像的切面劃分Fig.6 Section division of medical image
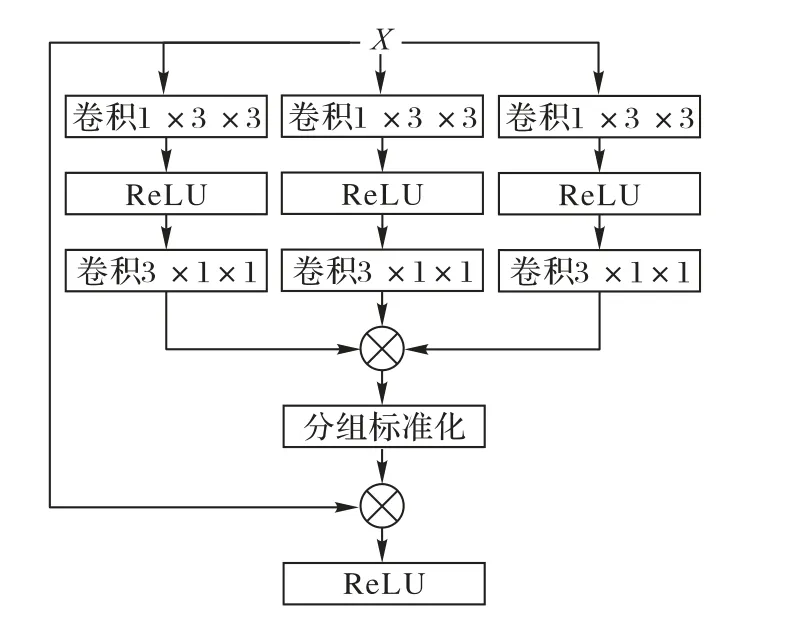
圖7 多方向融合模塊結構Fig.7 Structureof multi-directional fusion module
2.1.4 模型級聯
對于腦膠質瘤分割一類的醫學分割任務,由于存在由粗到精的分割過程,除了使用一個模型完成一次性分割,另一種經典而有效的處理方式是將多個模型級聯起來,每個模型分別完成一個分割子任務,并根據分割結果為下一個任務提供范圍更小的感興趣區域,圖8展示了級聯模型分割的基本流程。例如,Wang等[37]使用三個模型進行膠質瘤的分割,第一個模型預測全腫瘤,根據預測結果計算包圍全腫瘤的矩形框,在輸入容積數據上將該部分裁剪出來,送入第二個模型預測腫瘤核心。最后,根據預測的腫瘤核心使用模型3分割增強腫瘤。
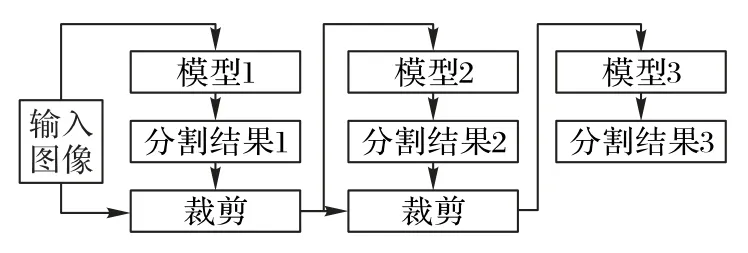
圖8 級聯模型的基本流程Fig.8 Basic flow of cascade model
與單模型分割相比,級聯模型可以根據預測結果逐步縮小感興趣區域,從而減少過度分割的情況。但由于使用多個模型,受算力限制,每個模型的規模往往無法與單模型相同。此外,由于后續分割直接依賴于前一級的分割結果,因此對分割準確性有很高的要求。為了保證后續分割的效果,級聯模型通常采取分步訓練的策略,以保證在增加更精細分割任務時能夠提供較好的粗分割結果。雖然隨著對卷積神經網絡的研究,不斷有更有效的單模型分割方法被提出,但基于簡單模型的級聯方法仍表現出十分出色的效果,例如Jiang等[41]通過兩個U-Net的級聯模型贏得了2019年腦腫瘤分割挑戰的第一名。因此,對于追求準確性與實用性的醫學影像分割來說,級聯模型是與單模型同樣值得關注的方法。
2.2 損失函數
在全監督學習中,損失函數直接決定了網絡的訓練目標。對于圖像分割任務而言,最常用的損失函數為交叉熵損失,這一損失被廣泛應用于自然圖像分割任務中。而醫學圖像相較于自然圖像又存在其獨特性,主要在于前景與背景類別的嚴重不平衡。因此,許多工作著眼于損失函數的改進,以提高分割模型在醫學圖像上的性能。此外,針對特定的醫學場景,多任務學習也經常受到關注。本節將分別對目前常用的損失函數進行介紹。
2.2.1 交叉熵損失
交叉熵(Cross Entropy)損失是圖像分割任務中應用最廣泛的損失函數,并同時適用于二分類和多分類任務。在醫學圖像分割中,任務往往定義為二分類任務,即將像素劃分為前景(正例)與背景(負例)區域。用于二分類任務的交叉熵損失可以寫為:
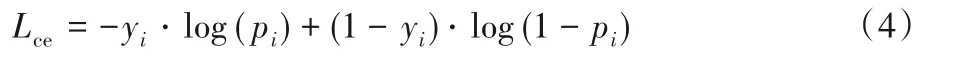
其中:pi為網絡預測第i個樣本為前景的概率,yi為標注圖中對應樣本的標簽,前景為1,背景為0。交叉熵損失均衡地考慮了全部像素的影響,而分割任務的難點在對邊界部分的準確分割。為此,U-Net[14]提出為交叉熵計算增加權重,以強化對特定像素的學習。權重的大小受像素與分割邊界的距離控制,更靠近邊界的像素具有更高的權重。類似地,Guo等[39]提出根據距離變換計算像素級權重圖,同樣可以加強對于邊界部分的分割效果。
在標準的交叉熵損失中,正樣本和負樣本對損失函數具有平等的影響權重。然而對于醫學圖像分割任務,前景類別如目標器官、病變區域往往僅占整個圖像的一小部分,意味著前景像素與背景像素的數量存在嚴重的不平衡;同時,大量背景像素可以被很簡單地分割出來,導致訓練時存在大量的簡單負樣本,嚴重影響了模型的學習效果。對于這類任務,一個可行的選擇是使用Focal Loss[42]取代交叉熵:
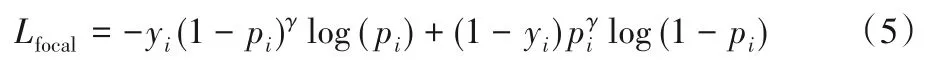
相比交叉熵損失,Focal Loss增加了權重調節項(1-pi)γ與pγi,其中γ是指數形式的權重因子,依據正確預測的概率對樣本進行指數加權。如果網絡對于像素屬于前景或背景的預測概率接近1,權重調節項則會接近0,從而自適應地降低了簡單樣本的權重,保證了網絡在訓練過程中更關注于對難樣本的學習。
2.2.2 Dice損失
在評估醫學圖像分割任務的性能時,Dice系數為一個常用的指標:

式(6)中,P表示預測結果,Y表示標注圖。在評估Dice系數時,通常只關注前景的分割結果,因此對于二分類任務,更常用的Dice系數計算公式為:

其中:pi∈(0,1)為前景預測概率,yi∈{0,1}為二值標簽。VNet[13]提出了基于Dice系數的Dice Loss:
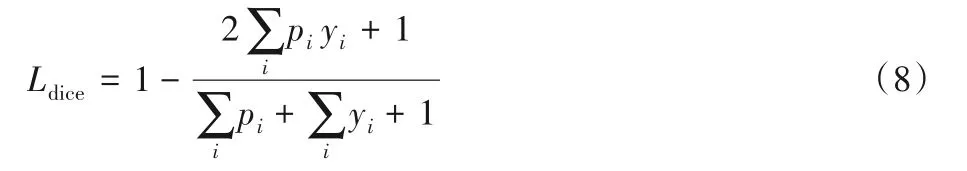
式(8)中的拉普拉斯平滑項(即分子分母同時加+1)避免了分母為0的情況,同時也定義了預測結果與標注圖均不存在前景標簽時的Dice系數為1。相比交叉熵損失,Dice Loss直接基于分割的評價指標對網絡進行優化,同時避免了前景與背景像素數量不均衡的問題。Dice Loss的局限性在于只適用于二分類情況。Sudre等[43]提出了廣義Dice Loss,將其擴展到了多類別,并統計各類別標簽數以增大標簽少的類別的權重,從而實現不同類別的平衡。
2.2.3 多任務損失
為了增強分割網絡的特征提取能力,研究者在設計損失函數時,除了最終的分割損失之外,還可以根據任務特點設計額外的預測分支以組成多任務損失。Ren等[44]設計了用于醫學圖像分割的多級任務分解,除了分割任務之外,還增加了類別和場景預測任務分支。網絡在生成像素級分割結果的同時,預測整張圖像中存在的目標類別種類,以及更高層級的任務類型。此外,Ren等還設計了一種同步正則化以加強不同任務之間的聯系,最終達到提升分割精度的效果。Guo等[45]同樣設計了類別級別的預測任務,但將類別存在性的預測精度提高到網絡下采樣后的分辨率,不同于之前全圖級別的預測。
2.3 精度優化
盡管關于改進網絡模型的工作不斷出現,但以U-Net為代表的經典網絡仍然具有相當的競爭力,在眾多醫學圖像分割比賽中具有重要地位。例如,2019年腦膠質瘤分割比賽的第一名使用的是兩個級聯的U-Net結構[41]。而nnU-Net[46]則在使用U-Net結構的基礎上使用了更有效的訓練設置,在多個醫學分割比賽中名列前茅。因此,對于醫學圖像分割而言,訓練設置同樣是至關重要的一部分。本節旨在介紹一些不依賴于模型結構的通用訓練技巧,以提升最終的分割性能。
2.3.1 數據增廣
為了避免過擬合,同時增強網絡對于各種變化的魯棒性,訓練數據增廣是模型訓練不可缺少的操作。由于醫學圖像及標注獲取的困難性,醫學數據集規模往往遠小于自然圖像數據集,因此更容易出現過擬合現象。常用的訓練數據增廣方法包括隨機縮放、隨機裁剪、隨機旋轉、隨機翻轉、隨機噪聲等。更進一步的復雜增廣方法則包括空間與灰度變換,如彈性形變[14]、B樣條插值[13]、伽馬校正[46]等。為了減少讀取開銷,數據增廣通常是在訓練過程中實時進行的,在實際使用中可根據數據規模和算力情況靈活選擇。
除了訓練數據增廣之外,測試時同樣經常進行數據增廣以強化分割效果。測試數據增廣通常包括多尺度縮放以及鏡像翻轉[41,46],并將多種增廣后的預測結果取平均值作為最終預測結果。與單尺度預測相比,增廣預測通常表現出更精確、更穩定的分割性能。
2.3.2 模塊優化
隨著深度學習研究的發展,不斷有更有效的通用網絡模塊被提出,并可以整合到U-Net的編碼器-解碼器結構中。例如,在卷積層與激活函數之間加入批標準化層(Batch Normalization)[47],可以使網絡收斂速度更快、魯棒性更好、效果更出色。然而批標準化的性能直接受批尺寸影響,在批尺寸很小時效果不理想。對于醫學影像分割中常見的三維卷積網絡,由于其本身計算開銷較大,批尺寸通常嚴重受限(往往為1或2),此時引入批標準化并不合適。對于這類網絡,使用計算不依賴于批尺寸的標準化方法,例如分組標準化[48]、樣本標準化[49]和層標準化[50],往往可以達到更好的效果。圖9給出了四種標準化的計算方式示意圖。其中,分組標準化的分組數為超參數,可以根據實際訓練情況進行調整。當分組數為1時,分組標準化變為層標準化;當分組數等于通道數時,等價于樣本標準化。
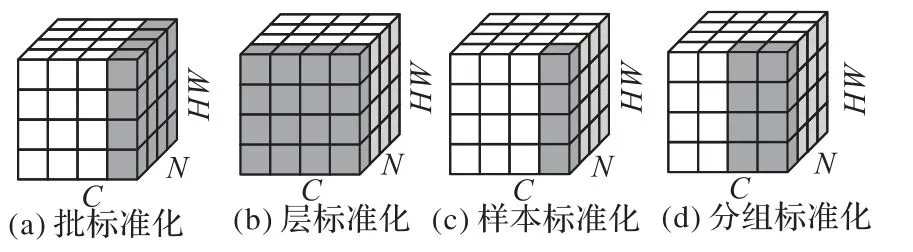
圖9 標準化方法示意圖Fig.9 Schematic diagram of normalization
除了標準化層,對激活函數的改進同樣值得關注。標準的ReLU(Rectified Linear Unit)激活函數僅在輸入大于0時保留激活值,而完全忽略了輸入為負值的情況。作為改進,LeakyReLU[51]在ReLU的基礎上為負值區域保留了較小的固定斜率,避免了完全失活的情況。PReLU[52]將負值區域的固定斜率改為可學習的參數,進一步地強化了激活函數的表示能力。
2.3.3 模型融合
多模型融合是醫學圖像分割比賽中的常用技巧,由于訓練的隨機性,單個模型容易陷入局部最優點,而整合多個模型的預測結果通常可以提高整體分割效果,增強分割的魯棒性。多模型融合的方式可以是:1)對訓練數據進行多折劃分,多次訓練同一個模型[53-54];2)選用多種模型,分別進行訓練[46,55]。類似于測試數據增廣,最終結果由多個模型的預測平均得到(圖10)。
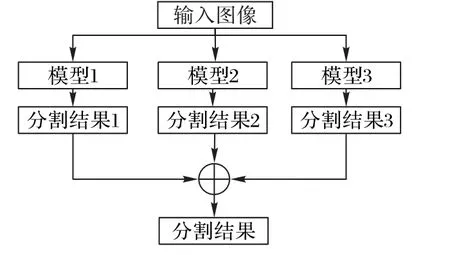
圖10 模型融合的基本流程Fig.10 Basic flow of model fusion
2.3.4 后處理
在得到網絡生成的分割圖后,還可以通過后處理方法進一步對分割結果進行細化,例如使用條件隨機場(Conditional Random Field,CRF)[35]來平滑分割圖的邊界,去除分割噪聲。針對特定的醫學任務,還可以根據先驗知識設計后處理方法,以彌補網絡分割的不足。閾值化[34,41]作為一種較為常見的后處理手段,目的是去除灰度不滿足閾值的像素,或者去除體積小于閾值的連通區域。OMNet[34]對于腦腫瘤分割任務進一步提出了基于體素灰度的聚類方法,以減少對于增強腫瘤的誤分類情況。
3 半監督醫學圖像分割
盡管深度神經網絡相比傳統算法表現出了顯著的進展,但其在訓練過程中需要大量的標注數據作為支撐。在實際應用中醫學圖像語義復雜且常包含3D信息,標注過程耗時耗力,限制了深度學習算法在該領域的進一步發展。相對地直接獲取大量的醫學影像數據較為容易,因此為了減輕對標注的依賴、降低成本,半監督學習算法得到了廣泛的關注和研究。
半監督學習除了使用少量數據XL=(xl)l∈[1,N]和對應的標注YL=(yl)l∈[1,N]外,還引入了大量的未標記數據XU=(xu)u∈[N+1,M]輔助訓練,在研究中通常將已有數據集的部分標簽丟棄來模擬該情況。半監督學習在應用時的一個必要條件是數據的分布p(x)包含后驗分布p(y|x)的相關信息,這在多數情況下都是成立的,但是在訓練前無法得知兩者間的關系,因此如何有效地從中提取出關于后驗分布的信息是半監督學習方法的關鍵。目前的方法通常遵循三個基本假設來描述p(x)與p(y|x)的關系:平滑假設(smoothness assumption)、低密度假設(low-density assumption)和流形假設(manifold assumption)。平滑假設認為兩個在輸入空間中相近的數據點應有相似的標簽,低密度假設認為分類時的決策邊界應盡可能地穿過數據稀疏的區域,也稱為聚類假設,流形假設認為在同一低維流形中的數據點應有相同的標簽。
本章將介紹目前醫學分割領域中各類半監督算法中的代表性工作。
3.1 基于自訓練和協同訓練的算法
自訓練算法和協同訓練算法均通過流形假設來利用已標記數據傳播信息生成偽標簽并進行迭代優化,已有很多研究將此思想應用于醫學影像分割,文獻[54,56-57]等方法采用自訓練的分割算法,這些算法僅使用單一模型完成訓練過程。相對地,文獻[58-60]等方法使用的協同訓練算法利用兩個或以上的模型共同完成訓練優化。
自訓練算法是最常見的半監督學習算法之一,它使用單一的模型,通過為無標記數據預測偽標簽,進而在學習偽標簽并重新預測更新的迭代過程中增強網絡的泛化能力。以LS、LU表示常用損失函數(如交叉熵),yi表示偽標簽,則此方法訓練時的優化目標可表示如下:
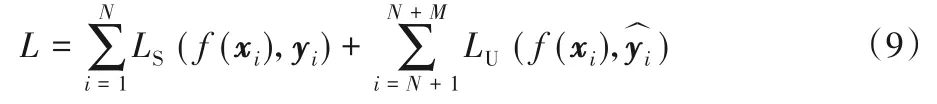
從優化方式可以看出,此類方法的缺陷是需要依賴于生成偽標簽的質量,當網絡學習到錯誤的標記后可能會不斷將其放大從而影響最終性能。由于自訓練算法僅參考了網絡本身提供的信息,預測結果中的信息量有限且通常伴隨著部分誤判,特別是對于語義歧義性高、邊緣模糊的醫學影像,生成偽標簽的質量并不穩定,因此目前對自訓練算法的研究主要集中于如何在嘈雜的偽標簽中進行學習。
一個改進的思路是對分割結果進行后處理以精煉提升偽標簽的質量,Bai等[56]將條件隨機場的后處理方法與自訓練算法結合并應用于心室MRI的分割任務中。該方法首先學習已標記數據,然后對于未標記數據進行分割,之后使用了CRF來精煉分割結果并使用優化后的分割圖來指導下一輪的迭代,最終有效地提升了分割的質量。相似地,Tang等[57]則使用了水平集(level set)的方法來作為后處理精煉偽標簽。另外Rajchl等[54]也基于自訓練的方法并額外使用了邊框級的弱標注輔助監督過程。
自訓練算法通過網絡本身的預測來分配標簽,可以看作運用流形假設將學到的標簽傳播至相似的數據上,從而學習了所有數據在其特征空間上的分布特點,并且在優化損失函數(如交叉熵)的同時隱式地使決策邊界遠離高密度數據區域,根據低密度假設最終學到了更加合理決策邊界,進而提升了網絡的魯棒性。
協同訓練算法將自訓練算法進行了擴展,為了降低單一模型預測帶來的局限性提出使用多個預訓練的模型以綜合預測偽標簽,通過模型間的融合來提升偽標簽的質量。需要注意的是,協同訓練需要使不同的模型在預訓練過程中相互獨立以提取不同的知識,實現時通常需要將數據集進行額外的劃分保證子集間存在差異性或利用同一數據的不同視圖,這樣在隨后的訓練階段就可以通過在未標記數據上的預測來傳播每個模型學到的知識達到相互補充的效果,最終得到更加魯棒的網絡。
Zhou等[60]基于協同訓練的方法定義了額外的學生模型來學習融合后的偽標簽。為了獲取獨立的子數據集,Zhou等利用器官分割中3D醫學影像數據可以分解為不同的軸向視圖(矢狀面、冠狀面和軸向)的特點,在不同的軸上對3D數據進行切片構造子數據集并使用2D分割網絡進行預訓練得到3個教師模型。融合階段通過“投票”的方式選擇偽標簽,對于預測一致的像素直接保留結果,而對不一致的部分則取置信度得分最高的標簽作為偽標記。最后使用一個新的學生網絡在擴充后的數據集上進行訓練。
另一種常見的協同訓練方式沒有使用學生模型,而是使用了相互指導的學習策略,即每個模型使用其他模型融合得到的偽標簽進行訓練,從而直接學習互補的知識。在此基礎之上為了進一步過濾噪聲數據,Xia等[59]提出了基于不確定性的融合生成策略,通過添加Dropout利用貝葉斯深度網絡估計預測的不確定性,進而在融合階段以加權和的方式生成更可信的偽標簽。
Peng等[58]使用多個模型預測的均值作為偽標簽,同時為了使模型學習到更多互補的知識,引入了對抗樣本以捕捉不同模型間的差異。此方法額外定義了差異損失函數,針對每個模型fi對輸入x進行調整生成對應的對抗樣本gi(x),如圖11,其中無標簽的對抗樣本由虛擬對抗訓練(Virtual Adversarial Training,VAT)生成,有標簽的對抗樣本則使用快速梯度法(Fast Gradient Sign Method,FGSM)生成,進而在其他模型的指導下優化使其對于對抗樣本更加魯棒。
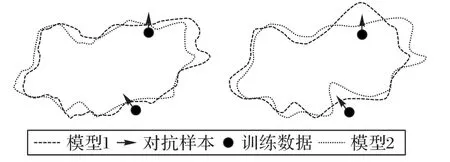
圖11 對抗樣本示意圖Fig.11 Schematic diagram of adversarial samples
還有一些方法對學習偽標簽的過程進行了調整,通過引入額外的約束以提高偽標簽的利用效率,Kervadec等[61]針對偽標簽不可靠的問題提出了課程半監督學習(curriculum semi-supervised learning),此方法通過學習更加寬松的區域表達來提升網絡的泛化性能。具體地,課程半監督學習框架定義了一個輔助分類網絡預測輸入圖像中前景部分區域的大小R,進而在網絡分割無標記數據時統計輸出結果的前景區域大小并將其限制在R的附近(1-λR,1+λR),優化時將超出的部分作為正則懲罰項加入到損失函數中,從而避免了利用錯誤的像素級預測作為偽標簽帶來的影響。最終通過左心室分割任務展現了其算法的優勢。
使用帶噪的偽標簽容易造成模型退化而約束后的偽標簽又無法提供足夠的信息量,為了平衡兩者間的矛盾,Min等[62]定義了深度注意力網絡(Deep Attention Network,DAN)以自適應地發現和糾正噪聲標簽中錯誤的信息,并且提出了分級蒸餾的方法生成更加可靠的偽標簽,最終在多個醫學分割任務上有效地提升了網絡的性能。整個框架的訓練過程分為三步,首先使用DAN在有標記數據下進行預訓練,然后通過分級蒸餾的方式為無標記數據生成偽標簽,最后使用所有的數據和標簽重新訓練模型。其中DAN模型在訓練時使用兩個學生網絡同時學習相同的數據,并根據模型間的預測和內部特征的關聯篩選出可靠的梯度部分執行反向傳播,使其對錯誤標簽擁有一定的糾正能力。此外在生成偽標簽時,融合了數據蒸餾與模型蒸餾的特點,通過將模型蒸餾中每個模型的預測替換為每個模型在多種數據變換下的預測將兩種方式分層次地結合起來,如圖12,從而進一步提升偽標簽的質量。
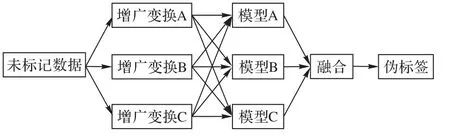
圖12 分級蒸餾示意圖Fig.12 Schematic diagram of hierarchical distillation
3.2 基于一致性正則的算法
根據平滑假設,對數據進行擾動后應該得到一致的輸出結果,然而通常訓練得到的卷積神經網絡無法保證這種變換不變性,從而泛化性能較差。半監督學習中為了能夠使用少量標注數據訓練出更加魯棒的模型,提出了對數據擾動前后的一致性進行約束的方法,實現上常通過定義額外的子任務提取對應的不變性以輔助優化網絡。一些代表性的研究方法包括使用均值教師的半監督方法,如MT[19]、UAMT(Uncertainty Aware Mean Teacher)[20]。還有基于幾何變換一致性的方法,包括TCSM(Transformation Consistent Selfensembling Model)[21]、semiTC(semi-supervised Transformation-Consistent network)[63],以及兩種方法的結合TCSMv2[64]等。
在文獻[65]中Π-Model和Temporal Ensembling的啟發下,均值教師算法[66]對兩者的思想進行了融合,Perone等[19]基于此方法在脊髓灰質分割任務上進行了實驗,整體的訓練框架如圖13。首先在初始化時定義了相同結構的教師模型ft和學生模型fs,其中教師模型僅通過學生模型每次迭代參數的指數滑動平均(Exponential Moving Average,EMA)更新以融合不同時期的訓練成果,泛化能力更強。訓練時對于同一數據在添加不同了噪聲η、η'后分別讓教師和學生模型進行預測,將兩者分割結果的均方差作為輔助損失優化學生模型,此一致性損失既包含了與時序融合后模型預測的一致性,又含有不同噪聲擾動下的不變性,最終整體損失函數如下:
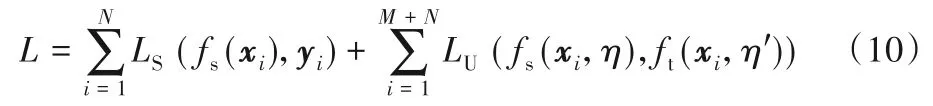
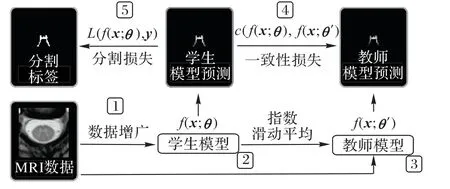
圖13 均值教師分割算法Fig.13 Mean teacher segmentation method
均值教師算法可以看作利用擾動不變性的同時融入了偽標簽的思想,由于進行了時序上的融合,教師模型的預測更加穩定并可以作為標簽指導學生模型的更新方向。
Yu等[20]從不確定性的角度對教師模型的預測進行了篩選,增加了蒙特卡羅Dropout(Monte Carlo Dropout)用于衡量教師模型預測的不確定度,進而根據閾值選取低不確定度的部分計算一致性損失,最終模型的精度在左心室分割任務中相比原始均值教師方法得到了進一步的提升。
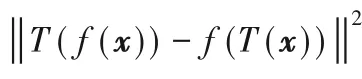
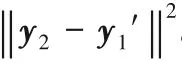
此外還有一類思路使用重建的方法,即約束從編碼器輸出的特征中還原的圖像應與真實的圖像相似,進而強化編碼器的特征提取能力。Chen等[67]利用重建的方法構建了多任務注意力機制半監督學習(Multi-task Attention-based Semi-Supervised Learning,MASSL)框架輔助訓練,總體框架如圖14。具體來說在經編碼器得到深層特征后,除了執行分割任務外,定義了重建解碼器預測前景和背景部分的輸入圖像,再與二值分割結果相乘后和真實的前背景圖計算均方誤差。

圖14 MASSL網絡框架Fig.14 Network structureof MASSL
3.3 基于圖的算法
基于圖的算法在特征空間中的數據點上建立加權無向圖G=(V,E),其中V表示數據點,圖結構中的邊用于描述樣本之間局部相似性,相連的樣本相似度較高,因而根據流形假設信息可以沿著圖的邊進行傳播,最后將圖上所有數據點劃分到不相交的子集中完成分類過程。其中的代表性算法包括Baur等[68]提出的隨機特征嵌入的半監督學習算法,以及使用圖正則化的[22-23]等方法。
嵌入半監督學習(semi-supervised embedding)算法[69]通過減小相似數據距離、增大無關數據距離的方式利用圖中數據的分布進行優化,但對于像素級的分割任務此方法計算開支較大,因此Baur等[68]對算法進行了調整,在多發性硬化病變分割任務中提出了隨機特征嵌入(Random Feature Embedding,RFE)的思想,針對圖像中大量的像素進行了采樣,只使用部分像素參與計算,從而能夠在像素級分割結果上進行優化。
圖正則化的方法使用圖平滑(Graph-smooth Regularization)的思想來標記額外的數據,其中使用圖拉普拉斯算子衡量節點間的相似性,并作為正則器優化圖的平滑性。
在腦部MRI腫瘤分割中,Song等[22]提出了一種基于圖正則化的歸納學習方法,使用隱變量來生成最終預測:x→t→y并基于高斯隨機場(Gaussian Random Field,GRF)對潛在變量t進行建模,之后使用圖拉普拉斯算子衡量節點間的相似性并作為正則器對其進行優化。
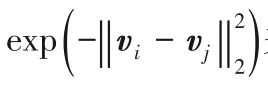
3.4 基于生成對抗網絡的算法
生成對抗網絡(Generative Adversarial Network,GAN)[70]是一種基于對抗的學習生成模型算法,包含生成器(generator)與判別器(discriminator),其中生成器用于數據的生成,判別器用于結果的評估。訓練時判別器學習如何將生成器產生的數據與真實數據區分開,而生成器學習如何產生可以迷惑判別器的數據。在對抗中兩個模型的能力均能夠得到強化提升。由于在相互對抗的過程中不需要數據本身的標簽,GAN在半監督學習中得到了大量的應用與改進,基于對抗過程設計思路的不同包括Chaitanya等[71]和Mondal等[72]的生成數據的方法,Zhang等[73]、Nie等[74]和Zhou等[75]的評估分割結果的算法,以及Ross等[76]定義額外對抗任務訓練特征提取能力的方法。
缺少數據是需要進行半監督學習的主要原因,而GAN的生成器本身就具有生成數據的能力。Chaitanya等[71]從該角度出發,提出將GAN中的生成器用于合成虛假影像與標簽以緩解數據不足的困難。對于生成器G,輸入標記數據XL和隨機生成的向量z,輸出變形場以扭曲輸入圖像得到新的數據XG。另外定義了判別器D用于區分生成數據XG與真實數據XL∪XU,對抗訓練時提升生成器在分類器上的得分LG=log(1-D(G(XL,z))),分 類 器 損 失LD=log(D(XL∪XU))-log(1-D(G(XL,z))),對抗學習后將新生成的數據加入分割網絡S的訓練中。具體地,研究了兩種數據生成方式:變形場生成器和加性強度場生成器,如圖15,變形場生成器通過產生變形場v同時扭曲輸入圖像與標簽進行增廣,而加性強度場生成器輸出強度信號ΔI通過與輸入圖像相加并保留標簽實現數據增廣。在心臟MRI分割數據集上的實驗結果驗證了GAN可以作為一種強大的數據增廣方式擴充緩解數據不足的問題。
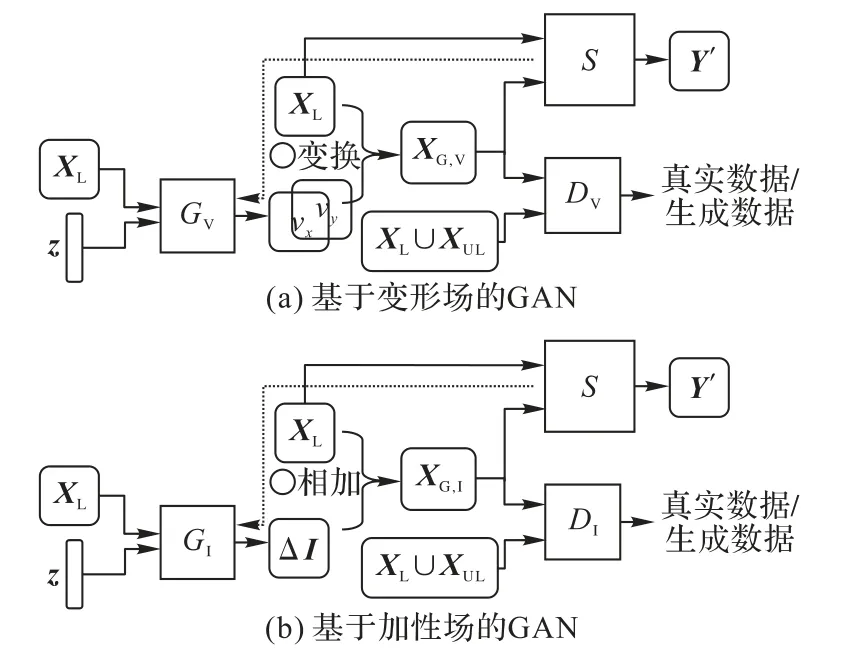
圖15 基于GAN的數據增廣方式Fig.15 Dataaugmentation methodsbased on GAN
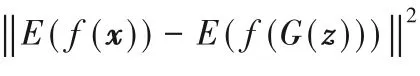
另一類方法結合了偽標簽的思路,將分割網絡作為生成器來產生分割圖,進而將分類器(如ResNet[7])作為對抗網絡中的判別器用于評估分割網絡預測的偽標簽質量,從而監督分割網絡生成更真實的預測結果。
其中代表性的算法是Zhang等[73]提出的深度對抗網絡(Deep Adversarial Network,DAN)框架,DAN將對抗網絡應用于腺體分割與真菌分割任務,首先在有標記數據上預訓練分割網絡,在加入無標記數據后定義了判別網絡來評價分割網絡的預測質量,使其在訓練過程中判斷分割結果是否來源于訓練過的有標記數據,最后固定訓練好的判別器,鼓勵分割網絡欺騙評價網絡,使其對所有數據的分割結果都判定為有標記數據,以此促使分割網絡從對抗學習的過程中提高預測的質量,整個訓練框架如圖16。
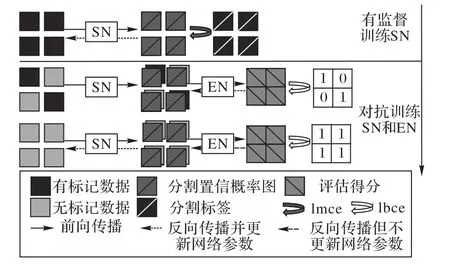
圖16 DAN訓練框架Fig.16 Training framework of DAN
Nie等[74]根據分割任務的特點進一步細化了評價網絡的目標,將判別器同樣改為二分類的分割網絡,使其產生像素級的質量評估,最后對無標記數據選取高質量的分割區域作為偽標簽參與訓練,之后根據自訓練的方法迭代地優化模型。
Zhou等[75]探討了使用了圖像級標注的弱監督情形下偽標簽的優化,仍然使用判別器評估圖像級分割網絡的真偽,此外還定義了使用圖像級標注預訓練的分類網絡,利用其產生的注意力特征輔助優化原分割網絡的結果得到新的偽標簽用于監督分割網絡訓練。

表1 半監督醫學影像分割方法匯總Tab.1 Summary of semi-supervised medical image segmentation methods
此外還有的研究在額外的輔助任務上執行對抗訓練,從而間接提升網絡的特征提取能力。Ross等[76]在內窺鏡器官分割任務中定義了從灰度圖中還原的著色任務。訓練流程如圖17,與其他半監督學習的流程不同,該方法首先在無標記數據上學習得到預訓練模型。具體地,考慮到此類外科分割任務中的數據為彩色影像的特點,先將其轉換至Lab顏色空間,再使用分割網絡預測彩色部分分量,相對的判別網絡負責區分輸入圖像為原始彩色分量還是分割網絡輸出的結果。得到預訓練模型后,再使用有標記數據對分割網絡的最后一層進行調整以實現分割任務。實驗結果表明,著色可以為分割提供一定的特征提取能力,在只有很少的標記數據時效果明顯。
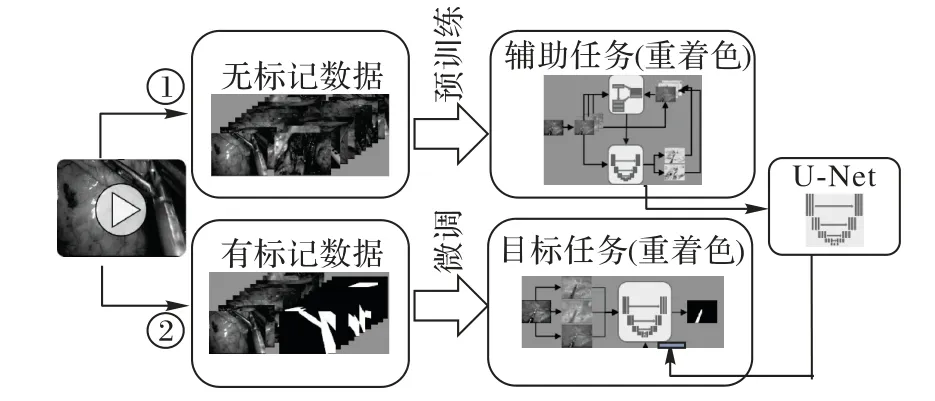
圖17 基于重著色的訓練流程Fig.17 Training framework based on re-colorization
4 醫學影像分割中的不確定性度量
基于深度學習的醫學影像分割在醫學分割各任務中均取得了顯著的成果,但是獲取十分準確而且可靠的分割結果對大多數任務來說仍然具有挑戰,尤其是在目標的邊緣區域。因此,在給出分割的結果的同時對預測結果不確定度進行定量分析對理解分割結果的可靠性有重大意義[77],例如,不確定性度量可以用來指示出潛在可能的誤分割區域,從而指導醫生對模型不確定度高的部分進行復查。
早期關于深度學習網絡不確定性度量的研究主要集中在圖像分類和檢測這些粗粒度的預測任務中,隨后,研究者Kendall等[78]在2015年將其推廣到需要對逐像素預測結果進行不確定性度量的圖像分割領域。文獻[26]根據不確定性的分布類型角度,將不確定性分為認知不確定性(Epistemic uncertainty)和隨機不確定性(Aleatoric uncertainty)。
4.1 模型認知不確定性
認知不確定性也稱為模型不確定性,指的是系統原則上具備某種認知能力,但是受限于標注數據量、訓練策略以及評價體系,從而導致的模型認知上的不確定性。可以通過提供額外的訓練數據和改進模型訓練策略來減輕和消除這種不確定性。在有限的醫療標注資源下,對模型不確定性的準確量化,是對當前醫療智能診斷系統的重要補充。模型不確定性的核心是獲得模型參數改變時預測結果的分布,而傳統卷積神經網絡參數固定只能得到一次預測結果。研究者根據對模型不確定性評估的方式不同,將其大致分為兩類,即深度模型集 成(Deep model ensemble)[26]和 深 度 貝 葉 斯 網 絡(Deep Bayesian Neural Network)[79]。
4.1.1 深度模型集成
早期深度模型集成的方式主要采用生成多個訓練模型來近似預測分布,如圖18。文獻[26]改變模型初始化參數從而獲得不同初始化條件下的訓練模型,進一步用獲得的多個模型下的預測集成來表征模型不確定性:
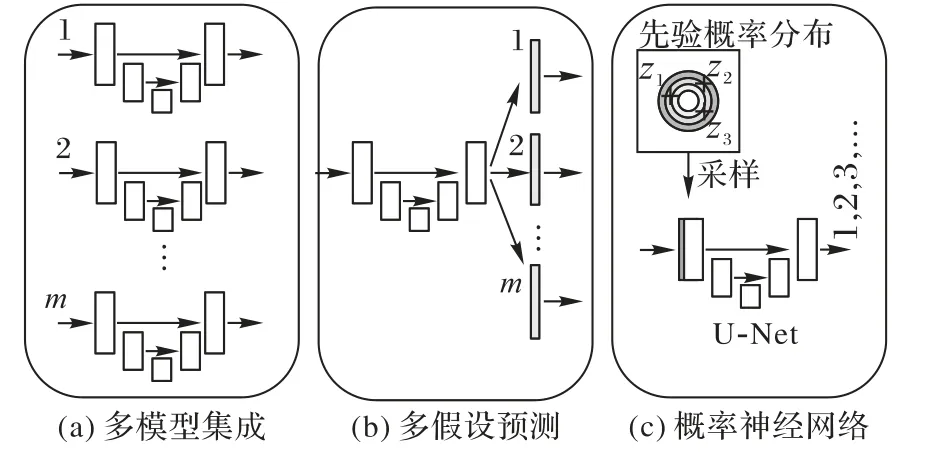
圖18 深度模型集成方式Fig.18 Deep model integration method
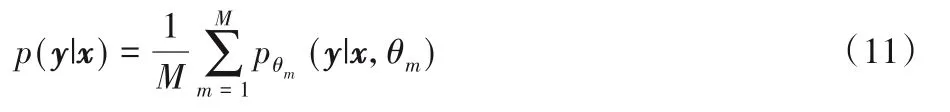
文獻[80]對模型集成方式進行簡化,用多假設預測(Multiple Hypothesis Prediction)替換模型原來的單一假設預測(Single Hypothesis Prediction)。根據不同假設輸出損失將標簽空間進行沃羅伊諾劃分(Voronoi tessellation),更新過程計算最近標簽空間的損失進行反向傳播。
上述模型集成的方法能夠得到一致的輸出預測,但是受限于固定的集成模型數目,無法得到更多假設數目或者連續空間假設下的輸出結果,同時訓練隊計算資源的消耗也大大增加。隨后,Kohl等[81]在2019年NIPS(advances in Neural Information Processing Systems)會議上提出概率神經網絡,設計先驗網絡獲得輸入在潛在空間(Latent space)下的分布,然后通過計算KL散度(Kullback-Leibler Divergence,KLD)與后驗網絡下標簽在潛在空間的分布對齊,以獲得連續空間下的預測結果,從而獲得模型預測的不確定性。Baumgartner等[82]通過對多尺度下特征空間進行層級化(Hierarchical)建模,進一步提升了模型在連續空間下預測的精細化程度。
4.1.2 深度貝葉斯網絡
傳統的神經網絡模型可以視為一個條件分布模型P(y|x,w):輸入為x,模型參數w,輸出預測y的分布。網絡的學習過程是對模型參數w的最大似然估計:

其中D代表訓練數據。此種優化過程下模型的參數w是固定的取值,以此得到輸出y的預測也是固定的,無法體現不確定性。而深度貝葉斯網絡[78]為神經網絡的參數引入概率分布,如圖19,根據輸入數據的分布去學習網絡參數的后驗概率分布,建立基于模型參數概率分布的預測期望以度量不確定性:
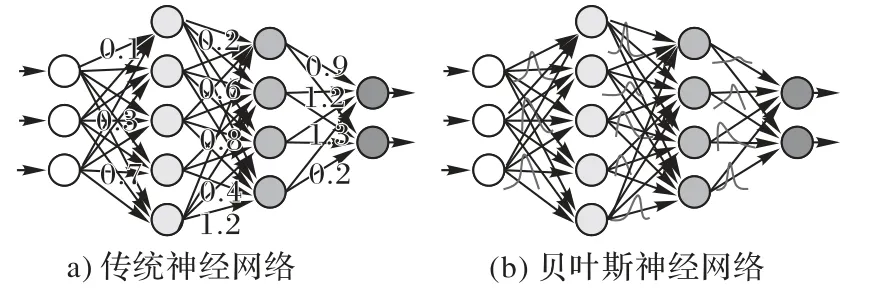
圖19 兩種神經網絡的區別Fig.19 Differencebetween twoneural networks

而根據貝葉斯理論,模型參數后驗概率P(w|D)是無法直接求解的,因為:

式(14)中各項均無法直接求解。為了將求w后驗分布的問題轉化為更好求解的優化問題,研究者們引入變分推斷[83](variational)的思想,這類方法基于由一組參數θ控制的先驗假設概率分布q(w|θ)去逼近待求解的模型參數真實后驗概率分布p(w|D),轉化為如基于高斯先驗假設的(μ,θ)的參數優化問題。這個問題可以通過最小化假設先驗分布和真實后驗分布的KL散度進行求解,
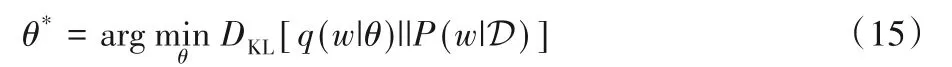
上面優化目標中的KL散度可以分解成DKL[q(w|θ)||P(w)]和Eq(w|θ)[logP(D|w)]兩項之差。文獻[84]中用蒙特卡洛采樣法去近似KL散度中的積分項求解,而以一定概率隨機關閉模型中參數的Dropout策略[27,85]可以結合蒙特卡洛采樣以達到變分貝葉斯近似的目的,同時降低模型訓練的復雜度。
4.2 隨機不確定性
隨機不確定性指的是觀測中固有的噪聲,這部分不確定性來源于醫療設備采集成像的數據本身噪聲以及標注存在的不可控誤差,不能通過獲取更多的數據來減輕這種不確定性。對醫學影像分割過程中隨機不確定性的量化能標識出分割不確定性很高的區域,有助于輔助醫生的判斷。其中按照隨機不確定性的分布主要可以分為輸入不確定性和輸出不確定性。
輸入不確定性指的是由于成像設備的限制導致的醫學影像的模糊性,進而導致標注結果受到醫療專家主觀認知以及客觀差異化的影響,造成誤標、漏標的情況,如圖20所示,圖中不同的輪廓表示了不同專家的標注結果。Joskowicz等[86]通過多輪次標注對標簽的差異性進行統計建模,界定差異范圍(variability range)對輸入不確定性統計分析,對不確定性高的樣例或者區域可以進一步重新標注以達到糾錯的目的。而實際應用過程中,不確定性統計建模的方式耗時耗力,無法滿足動態高效的需求,因此基于模型輸出分布的輸出不確定性被較廣泛研究。文獻[78]對輸入分別賦予同方差(Homoscedastic)噪聲和異方差(Heteroscedastic)噪聲以對模型輸出的分布建模,達到對隨機不確定性量化的效果。對輸出分布的研究也可以利用測試過程對數據增廣的方式達到,Wang等[87]采用幾何變換和顏色空間變換對測試過程中輸入數據進行增廣,觀測輸出空間的差異性,進而推斷數據本身的觀測固有噪聲。
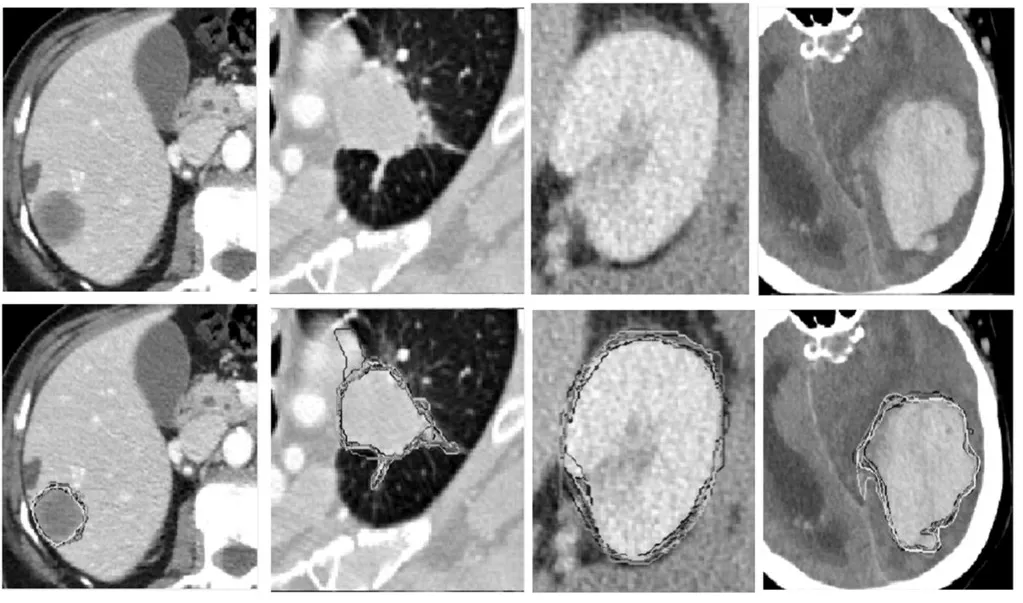
圖20 隨機不確定性示意圖Fig.20 Schematic diagram of random uncertainty
5 基于深度學習的醫學影像分割趨勢展望
醫學影像分割在醫療智能輔助診斷中的價值明顯,盡管基于深度學習在醫學影像分割領域中已經取得了顯著的進展,但基于深度學習思想和方法建立更加精確、高效、魯棒的分割模型仍然值得更深入的研究。目前醫學影像分割質量的提升主要得益于網絡模型在圖像表征學習能力上的優勢,以及現有計算技術下處理大規模數據的高效性。多數醫學影像任務場景下目前的分割算法還達不到符合醫療應用的要求,算法要求標注數據量大且重復標注多,另外分割結果單一,有效信息少。未來醫學影像分割需要在以下幾個方向開展更深入的研究。
5.1 優化網絡結構
醫學影像中的組織不像自然圖像具有清晰的邊緣、紋理和顏色,因此病變和健康組織的視覺紋理很難被區分開,病變區域附近的背景冗余信息會嚴重干擾目標視覺特征的表達能力。而由于病變組織的多變性和復雜性,類別內的樣本紋理也存在著巨大的差異。因此,醫學影像分割會面臨較小的類間區分性和較大的類內差異性。如何針對醫學影像的特點,設計能夠將網絡注意力側重在目標區域,且優化網絡的特征表達,使得提取到的目標區域更加緊湊,和背景特征之間的距離盡可能大,是一個亟須解決的問題。
5.2 不確定性度量
由于醫療業務數據特點(數據模糊、標注不準確)和應用場景的特殊性,對模型的魯棒性和精度要求很高,目前的醫學影像分割算法通常僅能給出單一的分割結果,有用信息量少。醫生希望模型給出預測結果的同時,對結果的不確定性也能給出量化,這樣的話醫生就可以將精力重點放在模型不確定度高的地方,減少重復勞動。因此亟須在已有分割模型的預測基礎上,增加關于分割網絡不確定性的研究;同時如何結合不確定性的量化指標,優化模型訓練過程,提升模型的分割性能,值得進一步的探索。
5.3 智能數據標注策略
目前,醫學影像智能分析算法多以純數據驅動的方式進行訓練,造成模型泛化能力受標注數據質量的嚴重影響,過擬合嚴重。數據標注主要問題包括樣本分布不均衡、標注差異化、同質樣本冗余、樣本孤立點等。針對這些問題,需要提出高效的與數據交互驅動的數據標注策略,使得模型訓練過程中能夠主動挑選出高價值的數據樣本,交給醫療專家進行標注,從而減少重復標注工作,優化標注流程,達到海量樣本空間下模型高效學習的目的。
5.4 無標注數據的利用
隨著醫學技術的發展,醫學影像數據將會更加龐大,而醫療資源無法對所有數據進行標注,因此未來半監督學習算法還有很大的發展空間,并將獲得更多的關注與研究。目前在半監督醫學分割領域中還存在一些問題,首先是現有算法的性能上距離全監督學習的效果還有很大距離[88],原因主要在于無標記數據中的信息難以被利用。一方面僅靠三個基本假設來定義數據分布與后驗間的關系并不準確,使用某些特定先驗的半監督學習策略在其他分布的數據上會造成一定的性能下降。另一方面盡管大多數算法對無標記數據中的信息進行了篩選約束,訓練過程中仍不可避免地學習到錯誤的信息,從而導致了潛在的性能下降。綜上所述,如何在醫學影像分割任務中提出新的半監督學習算法,更深入挖掘未標注數據的有用信息,是研究的一個重要方向。
6 結語
醫學影像分割是計算機輔助診斷中的重要一環,在過去幾年隨著深度學習的迅速發展得到廣泛的關注。本文充分總結了基于深度學習的醫學影像分割的研究進展。首先,本文重點介紹了醫學影像分割深度學習模型的基本框架,并對比分析了基礎網絡結構的發展過程、用于優化的目標函數和用于提升模型性能的各種方法。隨后本文針對醫學影像中標注獲取困難的問題,重點討論了半監督條件下醫學影像分割的發展現狀,對半監督分割方法進行了歸納整理。還對醫學影像分割中分割的不確定性研究這一較為新興的研究方向進行了分析,論述了醫學圖像模糊、標注噪聲大的不確定性分析的重要意義,并對比了主流的模型不確定性和隨機不確定性的研究方法。最后,本文對深度學習在醫學影像分割中的發展方向進行了展望,深度學習的進步也將推動著醫學影像分割向更深、更廣的領域發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
