基于注意力機制的TDNN-LSTM模型及應(yīng)用
2021-09-09 01:44:52朱文博段志奎陳建文李艾園
聲學(xué)技術(shù) 2021年4期
金 浩,朱文博,段志奎,陳建文,李艾園
(佛山科學(xué)技術(shù)學(xué)院,廣東佛山 528000)
0 引 言
在近十幾年中,深度學(xué)習(xí)技術(shù)一直保持著飛速發(fā)展的狀態(tài),極大地推動了語音識別技術(shù)的不斷發(fā)展。在大數(shù)據(jù)條件下,無論是傳統(tǒng)語音識別技術(shù)、基于深度學(xué)習(xí)的語音識別技術(shù),還是端到端語音識別技術(shù)、都已經(jīng)相當(dāng)成熟,各種商業(yè)化產(chǎn)品也相應(yīng)落地實現(xiàn)。但在小樣本數(shù)據(jù)下,由于系統(tǒng)對時序數(shù)據(jù)的上下文建模能力不足,導(dǎo)致語音識別效果仍不理想。為解決此問題,研究者們主要從豐富數(shù)據(jù)特征及優(yōu)化建模方法等方向做了相應(yīng)的研究。
在豐富數(shù)據(jù)特征方面,Saon等[1]引入了身份認證矢量(Identity Authentication Vector, IVA) i-vector,它能夠有效表征說話人和信道信息,并能提高低資源條件下語音識別的準(zhǔn)確率[2];Ghahremani等[3]提出一種結(jié)合i-vector特征的音調(diào)提取算法,被證明能夠豐富語音數(shù)據(jù)特征,提高模型上下文建模能力;Gupta等將基于i-vector矢量的說話人自適應(yīng)算法成功應(yīng)用在廣播音頻轉(zhuǎn)錄上[4],得到了良好的識別率。
在優(yōu)化建模方法方面,有研究者提出了不同于傳統(tǒng)高斯混合建模(Gaussian Mixture Model, GMM)的深度神經(jīng)網(wǎng)絡(luò)建模方法,如時延神經(jīng)網(wǎng)絡(luò)[5](Time Delay Nerual Network, TDNN)、長短時記憶網(wǎng)絡(luò)[6](Long Short Term Memory, LSTM)以及端到端[7]等基于深度學(xué)習(xí)的建模方法。但由于訓(xùn)練數(shù)據(jù)匱乏,時序特征重要程度的差異性在模型上難以體現(xiàn),導(dǎo)致模型對時序數(shù)據(jù)的上下文建模能力仍不足。例如時延神經(jīng)網(wǎng)絡(luò)在對幀級特征信息進行時序拼接時,如果不能區(qū)分重要信息和非重要信息,則容易出現(xiàn)無效信息被重復(fù)計算和有效信息丟失的問題[8]。并且對LSTM來說,雖然其對長距離時序數(shù)據(jù)有一定的信息挖掘能力,但是當(dāng)輸入的時序數(shù)據(jù)包含的無效信息過長,訓(xùn)練模型時則會出現(xiàn)不穩(wěn)定性和梯度消失的問題,導(dǎo)致模型捕捉時序依賴能力降低[9]。
由于注意力模型[10]具有使模型能夠在有限資源下關(guān)注最有效的信息的優(yōu)點,所以被廣泛應(yīng)用于機器翻譯、圖像識別等各種不同類型的深度學(xué)習(xí)任務(wù)中,具有較大的研發(fā)潛力。近年來,注意力機制開始被用于語音識別領(lǐng)域,Povey等[11]和Carrasco等[12]提出一種受限的自我注意力機制層并應(yīng)用于語音識別領(lǐng)域,有效提高了英語的語音識別率。有研究者提出了一種含有注意力模塊的卷積神經(jīng)網(wǎng)絡(luò),成功用在語音情感識別上,并取得了不錯的效果[13]。Yang等結(jié)合注意力機制能夠關(guān)注有效信息的優(yōu)點,提出了一種應(yīng)用在情感分類上的注意力特征增強網(wǎng)絡(luò)[14]。
因此,本文通過聯(lián)合TDNN和LSTM聲學(xué)模型并嵌入注意力機制,借助速度擾亂技術(shù)擴增數(shù)據(jù)同時引入說話人聲道信息特征,并結(jié)合基于區(qū)分性訓(xùn)練的無詞格的最大互信息訓(xùn)練準(zhǔn)則來訓(xùn)練模型。針對小樣本馬來西亞方言數(shù)據(jù)集進行實驗,深入分析不同輸入特征、隱藏節(jié)點個數(shù)以及注意力結(jié)構(gòu)對模型效果的影響。實驗表明,本文提出的基于注意力機制的TDNN-LSTM混合模型整體表現(xiàn)良好,相比于基線模型詞錯率降低了3.37個百分點。
1 基于注意力機制的TDNN-LSTM模型架構(gòu)
本文提出了一種基于注意力機制的TDNNLSTM混合聲學(xué)模型,即TLSTM-Attention模型,如圖1所示。利用注意力機制處理特征重要度的差異,有效結(jié)合粗細粒度特征,充分提高LSTM捕捉時序特征依賴的能力,并結(jié)合無詞格最大互信息訓(xùn)練準(zhǔn)則[15](Lattice Free Maximum Mutual Information,LFMMI)對模型進行訓(xùn)練,以增強模型上下文的建模能力。
1.1 模型整體架構(gòu)
TLSTM-Attention模型共有8層結(jié)構(gòu)組成,主要由時延神經(jīng)網(wǎng)絡(luò)模塊、長短時記憶網(wǎng)絡(luò)模塊以及注意力模塊三個部分組成。采用時延神經(jīng)網(wǎng)絡(luò)模塊和長短時記憶網(wǎng)絡(luò)模塊以及注意力模塊的交叉連接。該模型整體架構(gòu)如圖1所示,TDNN模塊對原始輸入數(shù)據(jù)進行時序拼接,以多尺度方式提取更豐富的局部短序列特征。注意力層對多尺度特征進行差異性篩選,既能增強有效信息的利用率,又能減少計算參數(shù)、精簡模型。LSTM以注意力層抽取出帶有重要程度差異性的粗粒度特征作為輸入,再度抽取具有長依賴關(guān)系的細粒度特征,實現(xiàn)粗細粒度特征有效融合,能夠在一定程度上避免因LSTM層步長過長,造成記憶丟失和梯度彌散的問題。最后結(jié)合注意力機制能夠關(guān)注有效信息的優(yōu)點,用于對輸出結(jié)果進行分類以及預(yù)測。

圖1 TLSTM-Attention模型架構(gòu)Fig.1 Structural diagram of TLSTM-Attention model
1.2 時延神經(jīng)網(wǎng)絡(luò)模塊
1.2.1 時延神經(jīng)網(wǎng)絡(luò)原理
時延神經(jīng)網(wǎng)絡(luò)是一種多層的前饋神經(jīng)網(wǎng)絡(luò),網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。與傳統(tǒng)前饋神經(jīng)網(wǎng)絡(luò)采用全連接的層連方式不同,TDNN將每層的輸出都與前后若干時刻的輸出拼接起來,相較于傳統(tǒng)只能處理幀窗口中固定長度信息的前饋神經(jīng)網(wǎng)絡(luò),TDNN的輸出不僅與當(dāng)前時刻有關(guān),還與前后若干時刻有關(guān),因此能夠有效描述上下層節(jié)點之間的時序關(guān)系,并且表現(xiàn)出更強的數(shù)據(jù)上下文信息建模能力和能夠適應(yīng)動態(tài)時域特征變化的優(yōu)勢。每層隱藏層都可以和任意時刻輸出進行拼接,體現(xiàn)了TDNN可以對更長的歷史信息進行建模的能力。但是這也意味著TDNN在每一個時間步長,隱藏層的激活函數(shù)都會被計算一次,并且TDNN相鄰節(jié)點之間的變化很小,可能包含了大量的無效信息,在訓(xùn)練的過程中容易出現(xiàn)反復(fù)計算且保留無效信息的問題。
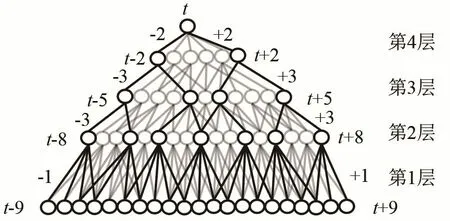
圖2 時延神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 The structure of time delay neural network
1.2.2 時延神經(jīng)網(wǎng)絡(luò)模塊設(shè)計
TLSTM-Attention模型共包含4個TDNN層,分別命名為TDNN 1,2,3,4。TDNN中通過設(shè)置每層參數(shù)來表示每一層輸出拼接的時間步長以及依賴關(guān)系。使用{-m,n}表示將當(dāng)前幀的歷史第m幀、當(dāng)前幀的未來第n幀和當(dāng)前幀拼接在一起作為下一個網(wǎng)絡(luò)層的輸入,0表示最后一層沒有拼接的輸入。假設(shè)t表示當(dāng)前幀,在TDNN 1層,模型將原始數(shù)據(jù)的時序信號轉(zhuǎn)換成特定的幀級特征向量作為輸入,將幀進行{t-2,t-1, 0,t+1,t+2}時序拼接,處理后作為下一個隱藏層的輸入。在TDNN2層,將上一層拼接后的幀進行{t-3,t-2,t-1,0,t+1,t+2,t+3}拼接,并將學(xué)習(xí)到的過去5幀及未來5幀的信息分類后作為注意力層的輸入。在TDNN 3處,將對處理后賦予了注意力特性的幀級特征信息進行{t-3,t-2,t-1, 0,t+1,t+2,t+3}拼接,作為下一層的輸入,在TDNN 4處,將幀進行{t-1, 0,t+1}拼接,拼接后的時序特征包含了過去及未來的9幀信息,作為下一個隱藏層的輸入。
1.3 注意力層模塊
1.3.1 注意力機制原理
注意力機制(Attention Mechanism)被認為是一種資源分配的機制,在深度神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)設(shè)計中,注意力機制所關(guān)注的資源就是權(quán)重參數(shù)。注意力機制總體可分為硬注意力機制與軟注意力機制。硬注意力機制的核心是通過直接限制輸入來達到聚焦有效信息的能力,但是對于時序數(shù)據(jù)的特性,直接限制輸入則意味著數(shù)據(jù)完整性的缺失,將直接導(dǎo)致模型的上下文建模能力不足。與硬注意力機制不同,軟注意力機制通過對特征信息進行注意力打分,并將其作為特征信息的權(quán)重參數(shù),從而實現(xiàn)對特征信息差異性的關(guān)注。對于具有時序信息的語音數(shù)據(jù),其中的特征信息包含的重要程度存在差異,重要的顯著特征往往會包含更多的關(guān)聯(lián)信息,對建模的影響程度更大。基于上述原理,本文將軟注意力機制引入TDNN-LSTM模型中,為所有輸入特征逐個加權(quán)進行打分,將歸一化的平均打分作為特征的權(quán)重參數(shù),有效地實現(xiàn)了粗細粒度特征的結(jié)合。
1.3.2 注意力層模塊設(shè)計
TLSTM-Attention模型嵌入了兩層注意力層,分別設(shè)在整體結(jié)構(gòu)的第三層和第八層。第一層注意力層,由前端TDNN 2網(wǎng)絡(luò)進行時序拼接后的輸出,作為注意力層的輸入。首先計算每個幀級特征的標(biāo)量分?jǐn)?shù)et,其表達式為

其中:ht為前端TDNN網(wǎng)絡(luò)的輸出,vT為轉(zhuǎn)移概率參數(shù)矩陣,W為幀級特征的權(quán)重,b為特征輸出偏置項,k為特征標(biāo)量分?jǐn)?shù)偏置項,F(xiàn)(·)為ReLU激活函數(shù)。為減少異常數(shù)據(jù)影響,將得到的標(biāo)量分?jǐn)?shù)et進行歸一化處理得到αt,其表達式為



計算得到的平均權(quán)重向量系數(shù)與幀級特征信息結(jié)合,賦予模型關(guān)注重要度更高的特征,更好地實現(xiàn)時間序列的粗粒度特征的提取以及對LSTM輸入信息的優(yōu)化。在模型輸出前的注意力層,將包含18幀的幀級特征信息,簡化分類及預(yù)測,有效地精簡模型并提高模型訓(xùn)練速度。
1.4 長短時記憶網(wǎng)絡(luò)模塊
1.4.1 長短時記憶網(wǎng)絡(luò)原理
長短時記憶網(wǎng)絡(luò)是由循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network, RNN)衍生而來的時序卷積神經(jīng)網(wǎng)絡(luò),并在隱藏層的內(nèi)部作了改進,增加了三個特殊的門控結(jié)構(gòu),通過權(quán)重參數(shù)的更新來選擇有效的歷史信息進行傳遞,實現(xiàn)對重要信息的保留和非重要信息的過濾,內(nèi)部結(jié)構(gòu)如圖3所示。相較于RNN能更好地從輸入數(shù)據(jù)學(xué)習(xí),獲得更好的上下文建模能力并能夠挖掘時間序列中的時序變化規(guī)律。
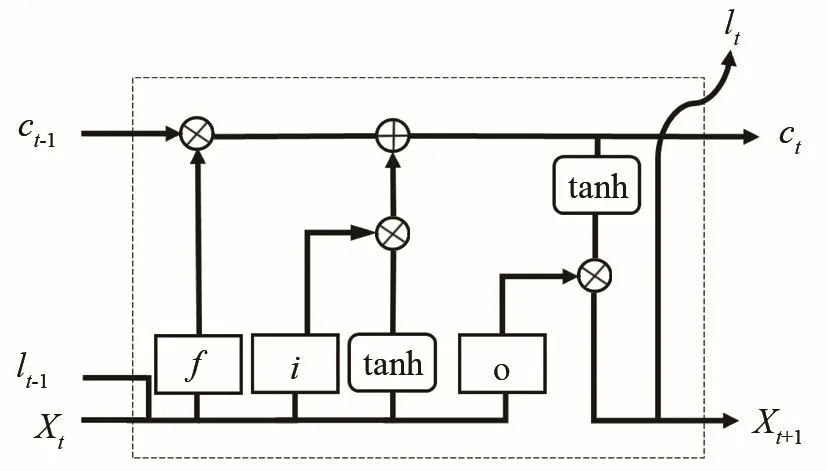
圖3 長短時記憶遞歸網(wǎng)絡(luò)內(nèi)部結(jié)構(gòu)圖Fig.3 Internal structure of LSTM recurrent network
其中xt為t時刻的輸入,lt為t時刻的輸出,c為長短時記憶單元信息的狀態(tài),維持信息的傳遞,i代表輸入門,決定當(dāng)前信息xt保留多少信息給ct;f代表遺忘門,遺忘門結(jié)構(gòu)根據(jù)具有注意力特性的特征信息,決定保存多少前一時刻的單元狀態(tài)ct-1;o代表輸出門,決定t-1時刻的隱層狀態(tài)有多少傳遞至當(dāng)前狀態(tài)的輸出lt。
1.4.2 長短時記憶網(wǎng)絡(luò)模塊設(shè)計
LSTM模塊設(shè)計如圖4所示,模型整體包含兩層LSTM,分別為LSTM 1、LSTM 2。經(jīng)過注意力層處理后的平均權(quán)重向量與特征信息結(jié)合得到xt,作為LSTM 1層的輸入。通過LSTM特有門控結(jié)構(gòu)處理,對賦有注意力特征的時序特征進行長序列依賴發(fā)掘,進一步增強模型上下文信息的建模能力。設(shè)σ(·)表示門控sigmoid激活函數(shù),Wx·為與輸入層連接的權(quán)重參數(shù)矩陣,Wc·為與記憶單元連接的權(quán)重參數(shù)矩陣,上述流程對應(yīng)公式為LSTM 1通過學(xué)習(xí)前端TDNN網(wǎng)絡(luò)模塊的11幀賦予了注意力特性的特征,能夠充分利用有效信息的權(quán)重比,對特征信息進行精準(zhǔn)分類。并且通過TDNN 4層對特征數(shù)據(jù)進行時序拼接后,LSTM 2層至少可以學(xué)習(xí)到上下文相關(guān)的9幀歷史信息及9幀未來信息,整體提高模型上下文建模能力以及預(yù)測分類能力。


圖4 LSTM模塊設(shè)計結(jié)構(gòu)Fig.4 Structure of LSTM module
1.5 模型訓(xùn)練準(zhǔn)則
本實驗采用基于區(qū)分性訓(xùn)練的改進無詞格最大互信息準(zhǔn)則(Lattice Free Maximum Mutual Information, LFMMI),建模單元如圖5所示。改進的LFMMI準(zhǔn)則由于降低神經(jīng)網(wǎng)絡(luò)對齊后的輸出幀率,幀移從10 ms增加為30 ms,因此音素狀態(tài)數(shù)從3降為1,用sp表示,另外加上了一個用于自旋可重復(fù)0次或多次的空白狀態(tài)sb。這樣對于1幀的聲學(xué)特征就要遍歷整個隱馬爾科夫模型(HiddenMarkov Model, HMM),相較于傳統(tǒng)的LFMMI[16]中HMM在音素狀態(tài)級別建模,改進的LFMMI,在音素級別建模,直接計算出相應(yīng)的最大互信息(Maximum Mutual Information, MMI)和所有正確路徑和混淆路徑的后驗概率。

圖5 改進的Lattice-free MMI建模單元Fig.5 Improved lattice-free MMI modeling unit
相比于標(biāo)準(zhǔn)語音識別系統(tǒng),采用隱馬爾科夫狀態(tài)圖(Hidden Markov, H)、音素上下文(Phone Context, C)、發(fā)音詞典(Pronunciation Lexicon, L)、語言模型(Grammer Model, G)四部分有限狀態(tài)轉(zhuǎn)換器(Finite State Transducer, FST)組合成HCLG靜態(tài)解碼網(wǎng)絡(luò)。改進的LFMMI針對小樣本數(shù)據(jù)在音素級別建模,用音素語言模型(Phone Grammer Model,PGM)來代替詞語言模型(Word Grammer Model,WGM)。由于小樣本條件下音素個數(shù)比詞個數(shù)少很多,因此PGM產(chǎn)生的FST圖很小,最后得到的HCP解碼網(wǎng)絡(luò)也會小很多,P代表PGM,真正做到純序列區(qū)分性訓(xùn)練,可以動態(tài)更新MMI部分的統(tǒng)計量并且減少模型訓(xùn)練時間。
2 實驗設(shè)置
2.1 實驗數(shù)據(jù)
實驗采用的是由Sarah Samson Juan 和 Laurent Besacier收集的開源伊班語(IBAN)語料庫。伊班語是婆羅洲的一種語言,并且是馬來語和波利尼西亞語的一個分支,主要在馬來西亞、加里曼丹和文萊等地普及。該語料庫是由23個說話人錄制完成的,采樣率設(shè)為16 kHz,每個采樣點進行16 bit量化,聲道為單聲道。該語料庫總時長大約有8 h,共包含3 132句伊班語語音數(shù)據(jù),每句話時長約為9 s。實驗中隨機選擇17個說話人的語音數(shù)據(jù)作為訓(xùn)練集,6個說話人的語音數(shù)據(jù)作為測試集。發(fā)音詞典包含大概3.7萬個單詞。本文從網(wǎng)上的新聞演講收集了大約104萬個單詞的文本進行3元語言模型訓(xùn)練。
2.2 語音識別系統(tǒng)搭建及性能指標(biāo)
為避免語料庫不足而產(chǎn)生過擬合的問題,本實驗在訓(xùn)練集采用速度擾亂技術(shù)進行數(shù)據(jù)擴增[17]。為保證音頻質(zhì)量,語速調(diào)整應(yīng)保持在0.85倍和1.25倍之間,因此本實驗將扭曲因子參數(shù)設(shè)置為0.9和1.1。每次訓(xùn)練期間會隨機根據(jù)扭曲因子的參數(shù),生成不同量的扭曲訓(xùn)練數(shù)據(jù)擴充訓(xùn)練集。同時由于采用速度擾亂技術(shù)后信號長度發(fā)生了變化,需要使用GMM-HMM系統(tǒng)對生成數(shù)據(jù)對齊,并將對齊后的低精度聲學(xué)特征額外加入音量擾動以提取高精度聲學(xué)特征,以40維梅爾頻率倒譜系數(shù)(Mel Frequency Cepstrum Coefficient, MFCC)作為基礎(chǔ)特征參數(shù),同時添加說話人聲道信息特征用于聲學(xué)模型訓(xùn)練。將深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks,DNN)模型作為基線模型,使用基于加權(quán)有限狀態(tài)轉(zhuǎn)換器(Weight Finite State Transducer, WFST)作為系統(tǒng)解碼器,以KALDI[18]為平臺搭建了一個馬來西亞方言語音識別系統(tǒng)。
每組實驗在測試集上運行3次,以3次實驗的平均詞錯誤率為最終實驗結(jié)果。詞錯誤率的計算方法為

式中:S代表替換錯誤詞數(shù),D代表刪除錯誤詞數(shù),I代表插入錯誤詞數(shù),T為句子中的總詞數(shù)。RWE結(jié)果越小,表示識別性能越好。
3 實驗結(jié)果及分析
3.1 不同神經(jīng)網(wǎng)絡(luò)的比較實驗
本實驗將TLSTM-Attention模型與4種模型進行對比實驗:(1) DNN模型包含六個隱藏層,一個輸入層,一個輸出層,每層節(jié)點數(shù)為2 048個,激活函數(shù)為tanh。固定15幀上下文窗口,每幀提取40維MFCC特征,共計600維特征向量作為網(wǎng)絡(luò)輸入。(2) TDNN聲學(xué)模型包含六個隱藏層,一個輸入層,一個輸出層。每個隱藏層包含256個節(jié)點,激活函數(shù)為tanh,分別采用{0},{-1,1},{-1,1},{-3,3},{-3,3},{-3,3}配置進行時序拼接,其中{0}表示不進行時序拼接,{-1,1}表示對當(dāng)前時刻的前后各一幀拼接。固定5幀上下文窗口,每幀提取40維MFCC特征,共計200維特征向量作為網(wǎng)絡(luò)輸入。(3) LSTM聲學(xué)模型包含六個隱藏層,一個輸入層,一個輸出層。每個隱藏層包含256個節(jié)點,包含5幀歷史信息和5幀未來信息,后三個隱藏層為常規(guī)隱藏層,激活函數(shù)為tanh。固定3幀上下文窗口,共計120維特征向量作為網(wǎng)絡(luò)輸入。(4) TDNN-LSTM包含六個隱藏層,一個輸入層,一個輸出層。第一個隱藏層為包含256個節(jié)點的TDNN,固定5幀上下文窗口,每幀提取40維MFCC特征,共計200維特征向量。第2、4和6隱藏層為包含256個節(jié)點的LSTM,模塊包含5幀歷史信息和5幀未來信息。第三層和第五層是TDNN隱層,配置信息為{-3,3}。
表1為馬來西亞方言在不同神經(jīng)網(wǎng)絡(luò)的聲學(xué)模型的識別結(jié)果。從實驗結(jié)果可以看出,TDNN-LSTM-Attention得到的識別性能明顯優(yōu)于基線DNN模型,RWE從18.20%下降到15.06%,實驗表明,基于TDNN-LSTM-Attention的聲學(xué)模型能夠有效提高模型上下文建模能力。

表1 不同神經(jīng)網(wǎng)絡(luò)的詞錯誤率對比結(jié)果Table 1 Comparison of word error rates between different neural networks
3.2 基于注意力機制的TDNN-LSTM模型的不同結(jié)構(gòu)比較實驗
3.2.1 不同隱層個數(shù)和節(jié)點數(shù)的比較實驗
在本實驗中,分別對TDNN和LSTM神經(jīng)網(wǎng)絡(luò)不同隱藏層個數(shù)和節(jié)點數(shù)進行對比試驗,其配置信息如表2所示。實驗中分別設(shè)置隱藏層個數(shù)為3、4、5和6,每個隱藏層包含256個節(jié)點。當(dāng)隱藏層個數(shù)為3時,第2層為LSTM隱藏層;當(dāng)隱藏層個數(shù)為4時,第3為LSTM隱藏層;當(dāng)隱藏層個數(shù)為5時,第3層和第5層為LSTM隱藏層。當(dāng)隱藏層個數(shù)為6時,第3層、第6層為LSTM隱藏層,其余層均為TDNN隱藏層。例如,使用TDNN-LSTM-6-2表示TDNN-LSTM包含 6個隱藏層,對當(dāng)前時刻前后兩幀進行降采樣。

表2 不同隱層個數(shù)和節(jié)點數(shù)的詞錯誤率對比結(jié)果Table 2 Comparative of word error rates for different numbers of hidden layers and nodes
實驗結(jié)果如表2所示,其中TDNN-LSTM隱層數(shù)為5時,TDNN降采樣節(jié)點配置為{-2,2}的網(wǎng)絡(luò)結(jié)構(gòu)得到的實驗結(jié)果最好,單詞錯誤率為17.05%,與基線DNN模型相比降低1.15個百分點。實驗表明,隨著隱藏層個數(shù)增加隱藏層節(jié)點數(shù)增加,單詞錯誤率明顯降低。這是因為隨著層數(shù)和節(jié)點數(shù)的增加,將使TDNN-LSTM在訓(xùn)練過程中可以獲得更多固定長度的時間上下文關(guān)聯(lián)信息。
3.2.2 不同注意力層結(jié)構(gòu)的比較實驗
本實驗以上面實驗中表現(xiàn)最好的 TDNNLSTM-5-2模型為基準(zhǔn),模型基礎(chǔ)結(jié)構(gòu)不變,對注意力層的個數(shù)以及位置結(jié)構(gòu)進行對比實驗。實驗中分別設(shè)置注意力層數(shù)為1、2及3。當(dāng)注意力層個數(shù)為1時,注意力層有兩個位置結(jié)構(gòu),1-3表示模型有1個注意力層結(jié)構(gòu),且位于該模型第3層;1-6表示模型1個注意力層結(jié)構(gòu),且位于該模型第6層。當(dāng)注意力層個數(shù)為2時,注意力層分別位于模型的第3、8層,用2-3-8表示。當(dāng)注意力層個數(shù)為3時,注意力層分別位于模型的第3、6、8層,用3-3-6-8表示。
實驗結(jié)果如表3所示,當(dāng)注意力層個數(shù)為2時,即Attention2-3-8網(wǎng)絡(luò)結(jié)構(gòu)得到的實驗結(jié)果最好,單詞錯誤率為14.83%,與基線DNN模型相比相對降低3.37個百分點。實驗表明,適當(dāng)嵌入注意層能夠有效提高識別效果。這是因為模型中的注意力層能夠關(guān)注特征的差異性,有效結(jié)合粗細粒度特征,但當(dāng)注意層增加時模型將會過多的關(guān)注信息差異性,造成數(shù)據(jù)的原始性缺失進而導(dǎo)致識別率不佳。

表3 注意力層的層數(shù)和位置不同的詞錯誤率對比結(jié)果Table 3 Comparison of word error rates for different layer numbers and positions of attention layers
3.3 基于TLSTM-Attention不同特征的比較實驗
本實驗以13維MFCC作為模型輸入的基礎(chǔ)特征,將基礎(chǔ)特征進行二階差分處理得到26維差分特征和1維的音高特征組合得到40維MFCC,同時添加100維的i-vector特征作為附帶特征。提取特征后對特征計算倒譜均值并在模型訓(xùn)練時動態(tài)進行歸一化處理,減少異常特征信息數(shù)據(jù)對模型訓(xùn)練的影響。訓(xùn)練所用模型為TDNN-LSTM-5-2-Attention2-3-8模型,實驗結(jié)果如表4所示。

表4 不同聲學(xué)特征的TLSTM-Attention模型詞錯誤率對比結(jié)果Table 4 Comparison of word error rates for TLSTM-Attention model with different acoustic features
表4的實驗結(jié)果顯示,對于基礎(chǔ)特征來說,高維的MFCC能夠更好地擬合基于注意力機制的TDNN-LSTM模型,并且基于40維的MFCC特征和i-vector特征組合的多輸入特征,使得神經(jīng)網(wǎng)絡(luò)可以獲取不同說話人特點和信道信息進行訓(xùn)練,比單輸入特征在測試集上取得更好的識別率。能夠在更長時序的語音序列建模,充分挖掘了上下文信息,從而提高模型的魯棒性。
4 結(jié) 論
本文針對小樣本資源下,模型上下文能力不足的問題,以基于注意力機制的TDNN-LSTM的模型為核心構(gòu)建了一個馬來語方言的語音識別系統(tǒng),同時添加說話人聲道信息特征,結(jié)合LFFMI訓(xùn)練準(zhǔn)則,讓模型在有限資源下充分對音素進行建模。實驗結(jié)果表明,相比于DNN基線模型,基于注意力機制的TDNN-LSTM模型可以有效提高上下文建模能力,并且由于添加了說話人聲道信息特征,在特征層面克服了用說話人無關(guān)的語音特征進行聲學(xué)模型訓(xùn)練的不足。另外,本文的主要任務(wù)是從提高上下文建模能力角度來提高低資源下的語音識別效果,對于如何更有效提高小樣本資源下語音識別的效果仍需要繼續(xù)深入研究和探討。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
