基于螢火蟲K-means聚類的電力用戶畫像構建和應用①
2021-09-10 07:32:16施文幸曹詩韻
計算機系統應用 2021年8期
施文幸,曹詩韻
1(國網浙江省電力有限公司培訓中心,杭州 310015)
2(東北林業大學,哈爾濱 150040)
近年來國內外逐漸興起的用戶畫像技術,為提升電力客戶體驗,提高產品和服務的競爭力,滿足客戶的用電服務需求[1]提供了有效支撐.
用戶畫像是建立在一系列真實數據之上的目標用戶模型,是真實用戶的虛擬代表[2],用戶畫像以了解用戶預測用戶需求為目的[3],但相關的文獻數量較少[4].
國網浙江省電力公司在2015年開始探索基于客戶標簽的用戶畫像,2017年在電力營銷業務應用系統中啟用了客戶畫像全景視圖,主要應用在電力營業廳.最初的標簽數量多達三百多個,建設維度包括:社會屬性、交費行為、用電行為、信用評價、風險評估和關聯行為,覆蓋浙江省所有用戶.目前基于多項業務的個體畫像構建及應用方法,涉及龐大的標簽庫和海量的電力用戶數據,存在有效性差和運算速度慢的缺陷,在各類電力業務推薦時效果欠佳,未能得到有效應用.
本文提出了一種基于改進的螢火蟲優化加權Kmeans 算法的分層聚類畫像推薦模型,僅就單項業務設計標簽模型,減少了標簽數量,提高了運行速度;通過分層聚類著重構建特征群體畫像,提高了業務推薦的針對性和精準性.
1 算法基本原理
聚類是數據挖掘中一個重要的概念,其目的是把具有相似特性的數據對象放到一起,尋找其中隱藏的有價值的信息,是將沒有分類標簽的數據集分成若干個簇的過程,是一種無監督的分類方法[5,6].
1.1 傳統K-means 算法簡介
1967年提出K-means 算法,是聚類算法中最經典的算法[7].因其思想簡單,速度快,聚類效果好而應用廣泛.其核心思想是指定初始聚類數目k,并在數據集中任選k個初始聚類中心,計算其余數據與聚類中心的相似度,將數據分配到相似度最高的聚類中心所對應的簇中;重新計算每個簇中數據平均值作為新的聚類中心,不斷迭代直到算法收斂.然而,初始聚類中心的隨機選擇,造成了對初始值的敏感和易陷入局部最優解等缺點[8],即聚類結果的好壞依賴于初始聚類中心的選擇;對異常樣本點較敏感,只能處理數值型的數據集[9].許多研究者致力于K-means 算法的各種改進方法,主要集中在初始k值的選擇、初始聚類中心的選取、離群點的檢測和去除、距離和相似性度量等方向上的優化[10].
1.2 螢火蟲算法簡介
群智能優化算法是用智能方法來搜索解空間的啟發式聚類算法[9],是近幾十年發展起來的仿生模擬進化算法,,典型算法如蟻群算法、粒子群算法、螢火蟲算法[11-13]等.螢火蟲算法用搜索空間的點模擬螢火蟲,搜索和優化模擬成螢火蟲的吸引和移動.螢火蟲有兩個要素:亮度和吸引度.螢火蟲之間相互吸引、移動,不斷搜索靠近亮度更高,吸引度更高的鄰域位置,最終使所有樣本到相應聚類中心的距離之和最小,達到分群的目的[13,14].
螢火蟲算法用螢火蟲表示聚類問題的解,亮度大的位置代表最優的聚類中心,目標函數的解反映位置的優劣[15].具有操作簡單、宜于并行處理、魯棒性強等特點,但是因為最亮的螢火蟲隨機移動,導致該算法聚類時存在收斂速度較慢、后期容易在最優值附近振蕩、穩定性較差的問題[16].
1.3 基于改進的螢火蟲優化加權K-means 算法基本思路
基于改進的螢火蟲優化加權K-means 算法利用傳統K-means 算法和螢火蟲算法自身的優點彌補了對方的缺點,在此基礎上又做了局部改進來優化算法性能.
具體思路首先是針對傳統K-means 算法初始聚類中心選擇的隨機性等缺點,本文采用螢火蟲算法(Firefly Algorithm,FA)[17]求得最優解,作為K-means 算法的初始聚類中心;其次傳統K-means 算法由于速度快,聚類效果好又糾正了螢火蟲算法收斂慢、易振蕩的缺點;再次考慮采集數據的業務相關度不同,對傳統歐氏距離引入權值以減輕異常點影響;最后通過改進螢火蟲的移動方式和隨機擾動方式,來提高聚類的準確性和穩定性,以得到穩定的聚類結果[18].
設待聚類樣本數據集X,m為數據維度.
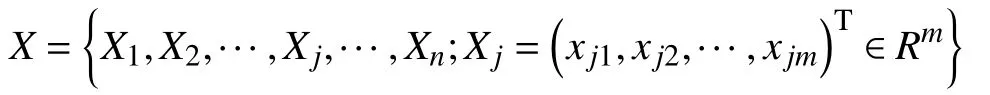
算法相關定義[16-19]如下:
定義1.螢火蟲i和j之間的距離:
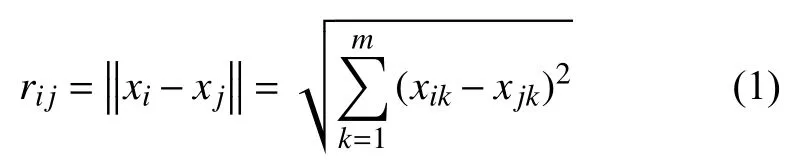
式中,m為數據維度,xij為螢火蟲i的第j個數據分量.
定義2.螢火蟲的亮度:

式中,I0為螢火蟲自身r=0 處的熒光亮度;γ為光強吸收系數,通常為常數.
式(2)計算量大,導致了螢火蟲算法收斂速度慢,而亮度與目標函數相關,所以本文算法直接采用目標函數Jc反映螢火蟲的亮度,Jc由式(11)計算.
定義3.螢火蟲吸引度:
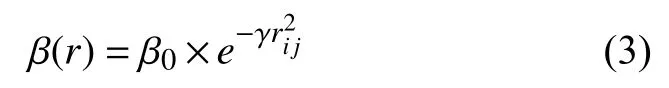
其中,β0為最大吸引度,即r=0 處的吸引度.
螢火蟲被吸引移動,距離越變越小,由等價無窮小替換原理,用式(4)代替式(3),能減小計算量,提高運算速度.

定義4.位置更新公式.
螢火蟲算法的擾動項α ×(rand-0.5)擾動作用不明顯,容易造成在局部最優值附近波動,因此在螢火蟲算法中引入了擾動算子[18]α ×rand×(Xi-V0)2,則螢火蟲i被吸引向螢火蟲j移動的位置更新公式可優化為式(5).可見位置的更新與吸引度有關,吸引度決定移動距離大小.
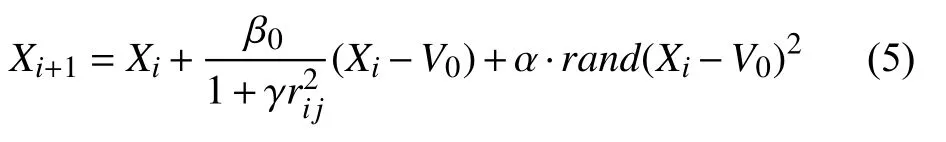
式中,V0為目前最優聚類中心,α為步長因子,是[0,1]上的常數,rand為[0,1]上服從均勻分布的隨機數.

式中,ni為聚類簇Ci中的數據個數,y代表聚類簇Ci中的數據數值.
最亮的螢火蟲X*按式(7)移動.
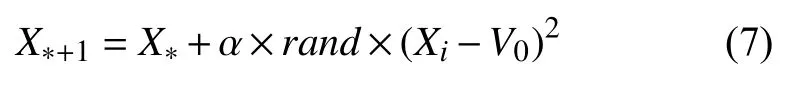
擾動算子的優化能有效避免最亮的螢火蟲隨機移動,提高算法收斂速度和精度.
定義5.權值.
考慮到待聚類樣本數據的業務相關度和影響程度不同,在目標函數的計算中引入權值Ω={ω1,ω2,···,ωj,···,ωn;ωj=(ωi1,ωi2,···,ωim)T∈Rm}來反映數據的整體分布特性.
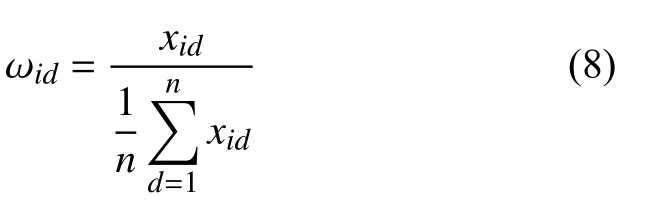
定義6.目標函數.
亮度和目標函數相關,用目標函數代表亮度,亮度越大、螢火蟲位置越佳,目標函數值越小,聚類效果越好,即亮度高的螢火蟲吸引亮度低的螢火蟲,亮度決定移動方向.
用傳統K-means 算法求得的聚類中心為V={V1,V2,···,Vk}
數據對象與聚類中心的歐氏距離為:

式中,Vj表示第j類的中心位置,i=1,2,3,…,n,j=1,2,3,…,k.

式中nj為Vj中的數據數量,xj為Vj中的樣本數據.
僅用傳統K-means 算法得到目標函數為:
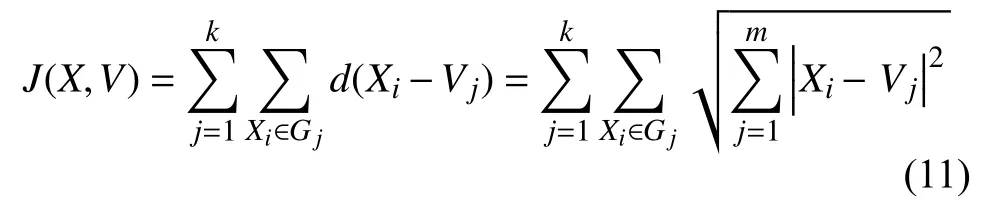
式中,Gj為j類中的數據集合.
加權后,數據對象與聚類中心的距離為:
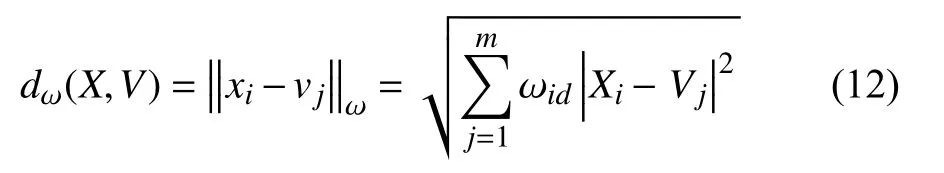
在式(11)中引入權值 ωid后,突出了數據分布特性,易于排除異常點,提高聚類精度,同時減少迭代次數,速度更快.
加權后的目標函數為:
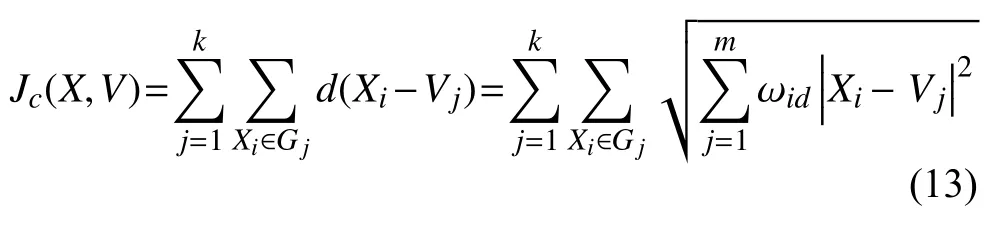
1.4 算法流程
聚類算法流程如圖1所示.
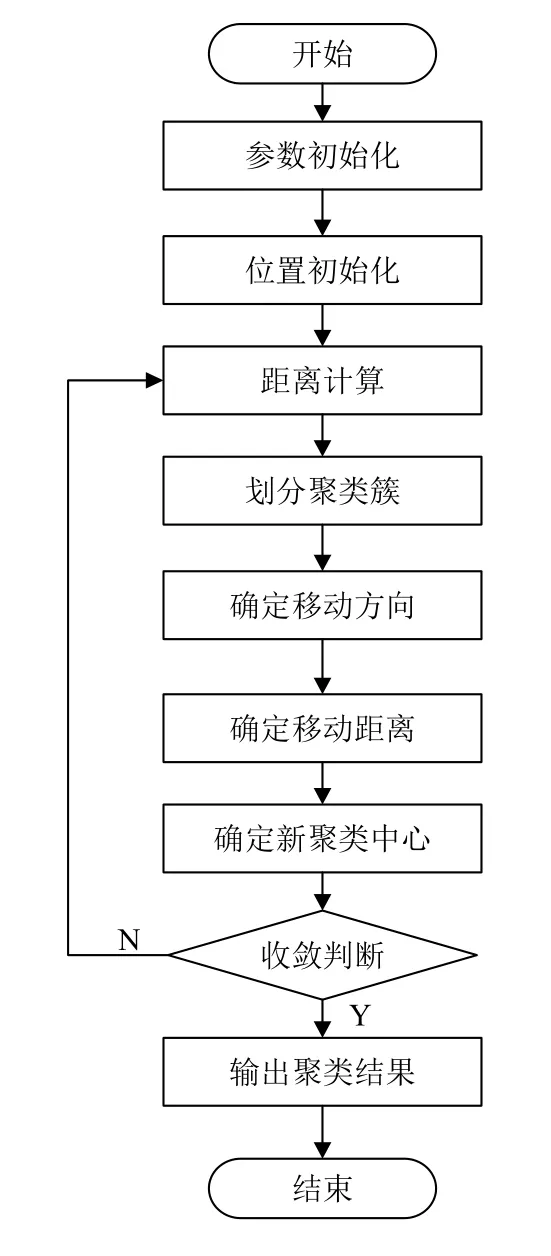
圖1 聚類算法流程
(1)參數初始化:確定群體數據規模n、最大吸引度 β0、光強吸收系數 γ、步長因子α、最大迭代次數Tmax、迭代停止閾值ε;
(2)位置初始化:選擇k個數據對象作為初始聚類中心V;
(3)距離計算:由式(12)計算數據對象與聚類中心的距離dω(X,V);
(4)劃分聚類簇:根據計算所得距離,依次將對象劃分到距離最近的聚類中心所在的類中;
(5)確定對象移動方向:由式(13)計算加權后的目標函數Jc(X,V),以確定對象移動方向.亮度決定移動方向,目標函數值越小,亮度就高,所處位置就越好;
(6)確定對象移動距離:由式(5)計算螢火蟲移動后的新位置,確定對象位置;
(7)確定新的聚類中心:由式(7)計算最亮的螢火蟲的新位置,作為新的聚類中心;
(8)收斂判斷:判斷如果達到最大迭代次數或滿足停止閾值,則停止算法,否則轉到步驟(3);
(9)輸出聚類結果.
2 用戶畫像構建和應用
為提高計算速度和精度,本文提出一種基于改進的螢火蟲優化加權K-means 算法的分層聚類畫像推薦模型.首先就單項業務,比如電能替代推廣業務,設計簡單的,針對性強的標簽庫,找出具有某些典型共性的特定用戶群體,通過對群體的數據分析,深度挖掘,進一步提取出用戶的群體特征,采用基于改進的螢火蟲優化加權K-means 算法對電力用戶進行兩層聚類,分別構建兩組不同相似特征的KY類和KN類群體畫像模型[20].其次通過計算兩組聚類中心的相似度,將構建得出的電能替代群體畫像,應用到電能替代的業務推薦中.最后用同樣的方法,拓展到其它新業務的推薦應用中,以實現電力營銷業務的全面推廣.
電力用戶可劃分為高壓、低壓非居民、低壓居民3 種,這3 種用戶的數據特征分布有較明顯差異,但建模算法等沒有差異.本文僅以高壓客戶組為例,介紹了向目標潛力用戶推薦電能替代和其它新業務的應用方法.
2.1 用戶畫像建模流程
(1)數據采集:對于電力企業最有優勢的方法是直接從企業的電力業務系統中獲得大量真實可靠的用戶數據,比如電力客戶用電信息采集系統、電力營銷業務應用系統、95598 客戶服務系統,還有網上國網平臺.采集與電能替代密切相關的業務數據,高壓用戶數據采集重點應放在用電設備清單、增容減容等業務的辦理情況、用電容量、行業分布、能耗情況、用電趨勢、經營現狀及其前景等方面.
(2)數據特征映射:假設用戶數據集為X={X1,X2,···,Xj,···,Xn},將高壓用電客戶數據進行預處理,采用向量空間模型(Vector SpaceModel,VSM)將高壓用戶的m維特征映射為X={X1,X2,···,Xj,···,Xn;Xj=(xj1,xj2,···,xjm)T∈Rm}.
(3)第一層聚類:用基于改進的螢火蟲優化加權Kmeans 算法提取用戶與電能替代密切相關的用電特征,將用戶聚成2 類.識別出辦理過電能替代的Y群體和未辦理電能替代的N群體兩大類.
(4)第二層聚類:再次用基于改進的螢火蟲優化加權K-means 算法分別對Y群體和N群體進行聚類,將Y群體分成KY類,將N群體分成KN類.
(5)群體特征提取:經過了兩層聚類,共得到KY+KN個聚類簇和聚類中心.聚類簇的聚類中心代表該聚類簇的所有對象,其各個參數即標簽反映了該群體的共性特征.
(6)群體畫像表達:將標簽可視化,最終得到了KY+KN個高壓用戶的群體畫像.
畫像建模的總體流程如圖2所示.
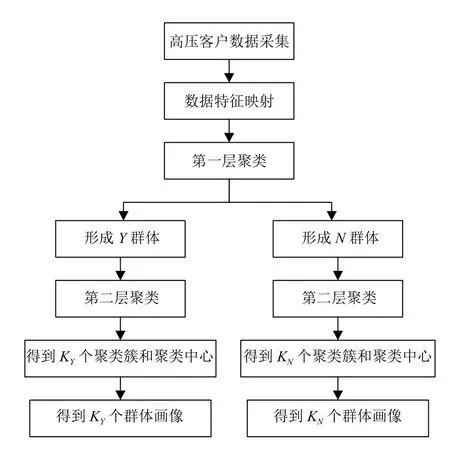
圖2 畫像建模流程
2.2 用戶畫像的應用
2.2.1 電能替代業務推薦
畫像模型構建完成之后,向目標潛力客戶推薦電能替代業務.檢查審視未辦理電能替代的目標用戶群體N={N1,N2,···,Ni,···,NKN},通過式(14)逐個計算群體N的聚類中心Ni與群體Y={Y1,Y2,···,Yi,···,YKY}的聚類中心之間的歐氏距離.

對計算所得的d(Ni,Yj)進行排序,求出Ni與群體Y的最小距離集合DNYmin={dmin(N1,Y),dmin(N2,Y),···,dmin(NKN,Y),} 即目標群體N={N1,N2,···,Ni,···,NKN}的最近鄰.距離越小,相似度越高,推薦偏好越一致,依次按DNYmin向目標群體N推薦相應的電能替代業務.由系統自動發送“…的用戶已成功辦理了電能替代”的信息,發送“如何辦理電能替代”、“現在就辦電能替代”的鏈接.拉近企業與用戶的關系,使用戶從不了解到有意向,再到成功辦理業務.
2.2.2 其它新業務推薦
前文所述,將畫像技術應用在電能替代這一項業務的推薦應用上.這一推薦方法,同樣適用于開展其它新業務的推薦,比如分布式光伏發電、節能服務等.只要按照推薦的新業務類型,再一次利用基于改進的螢火蟲優化加權K-means 算法,由所得的目標潛力群體畫像即可推薦又一項新業務.由系統自動發送“辦理了…的用戶也成功辦理了…”之類的信息,發送“如何辦理…”、“現在就辦…”的鏈接.照此思路,可以逐漸將用戶畫像拓展應用到一項項具體的電力業務中,提升自身競爭力,開拓出更大的用戶市場.
目前有許多學者致力于大數據處理技術的研究,數據挖掘技術和用戶畫像技術日益成熟,但電力用戶數據量巨大,而且持續增長,導致海量的交互數據大大超過企業自身的數據抓取、數據存儲與數據分析能力,增大了用戶畫像的難度[21].為加快運算速度,提高推薦精準度,本文通過壓縮標簽數量,降低采集數據維度,在畫像建模的數據采集環節,只關注與推薦業務密切相關的數據,雖然每項業務推薦都需要用算法分層聚類來完成畫像的構建和應用,但總的來說大大減少了交互數據量,同時精準度更高.
3 實驗例證
3.1 實驗數據集
實驗數據于2019年6月采集自電力營銷業務應用系統,以某市供電公司的高壓用戶為實驗對象,選取A、B、C、D、E 這5 個樣本個數依次遞增的供電所高壓用戶集,數據集的描述如表1所示.實驗的運行環境為Windows10 操作系統、8 GB 物理內存、CPU 速度為3.1 GHz、Matlab2018b.
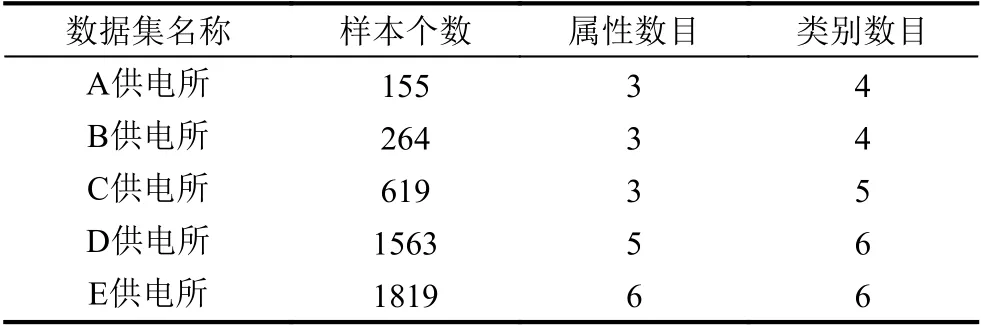
表1 數據集描述
3.2 實驗結果與分析
為驗證本文算法在電力用戶畫像構建和推薦應用中的聚類精度和收斂速度,設計了實驗將本文算法與傳統K-means和FA 算法作了對比.在5 個高壓用戶數據集上分別進行100 次實驗,比較目標函數值、運行時間和迭代次數,實驗結果如表2至表4所示.實驗參數設置如下:最大吸引度 β0=1、光強吸收系數γ=1、步長因子α=0.05、最大迭代次數Tmax=150、迭代停止閾值ε=105.
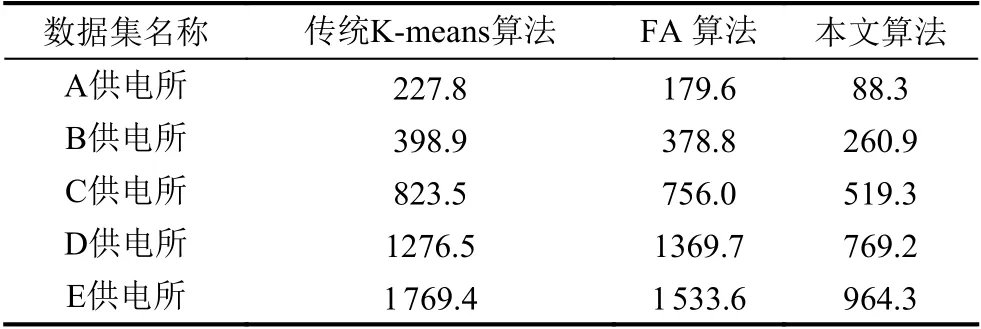
表2 目標函數值對比

表3 迭代次數對比
為了方便比較,將表2至表4的對比結果,以折線圖的形式表示出來,如圖3至圖5所示.
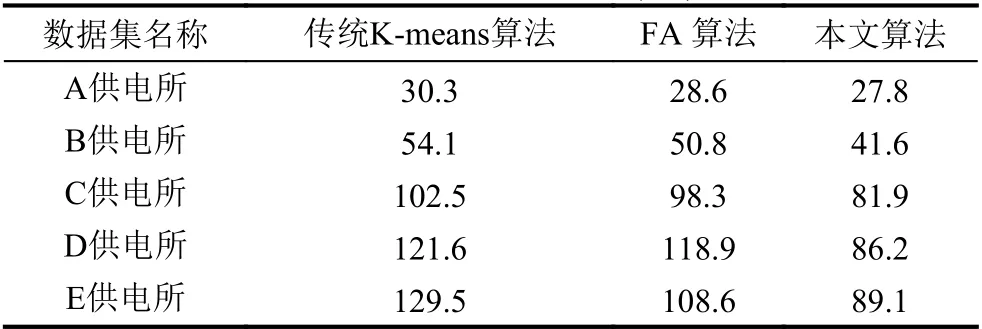
表4 運行時間對比(ms)
通常用目標函數值來衡量聚類效果,目標函數值越小,聚類簇越緊湊,聚類效果越好.對比本文算法與傳統K-means和FA 算法,由圖3可見本文算法的目標函數Jc(X,V)平均值較小,而傳統K-means 算法和FA 算法的目標函數值相近,明顯較大,反映出本文算法的聚類有效性、聚類效果更好.由圖4可見本文算法的平均迭代次數更少,由圖5可見本文算法的運行時間更短,在數據量增多的情況下優勢更明顯,反映出聚類收斂速度的加快.由于本文算法結合了K-means和FA 算法的優點,引入了加權的目標函數,引入了平方項作為擾動算子進行優化,使得原來分布不明顯、不容易分類的數據變得有利于劃分,使算法的每一次迭代更快地接近于真實的數據劃分,進而減少算法的迭代次數,有效避免了聚類結果的隨機性,提高了算法穩定性和收斂速度.實驗結果表明本文算法構建的用戶畫像更清晰準確,快速,推薦針對性更強,
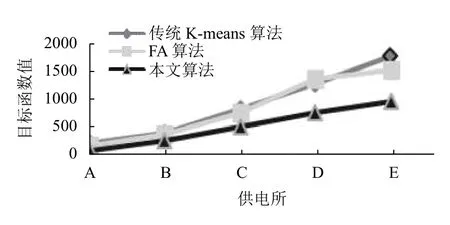
圖3 目標函數值
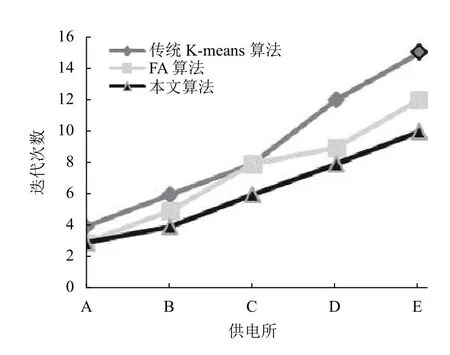
圖4 迭代次數
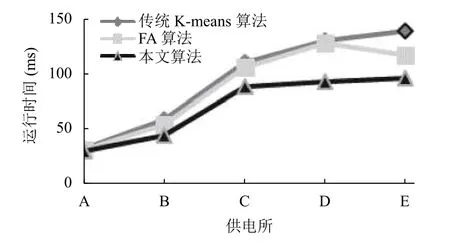
圖5 運行時間
4 結論
本文針對電力企業用戶畫像在應用中效果欠佳的現狀,提出一種基于改進的螢火蟲優化加權K-means算法的分層聚類推薦模型.該模型優點如下:
(1)算法結合K-means和FA 算法的優點,并采用了兩層聚類方法,使得原來分布不明顯、不容易分類的數據變得有利于劃分,使算法的每一次迭代更快地接近于真實的數據劃分,進而減少算法的迭代次數,有效避免了聚類結果的隨機性.算法穩定性和收斂速度的提高,使用戶畫像的構建和應用過程更快速更有效,從而為畫像技術在電力業務的推廣應用提供有力支撐.
(2)通過就某一項具體業務,壓縮標簽數量,降低采集數據維度的方法,大大減少了交互數據量,避免了無關數據和異常數據的干擾,提高了畫像的速度和精準度.
(3)畫像重點由個體畫像轉移到群體畫像,更易于提取出用戶的共性特征,提升了畫像構建和應用的效率.
實驗階段,選取供電公司的5 個高壓用戶樣本集設計了仿真實驗,實驗表明本文方法有效提高了運算精度和速度,使畫像構建和應用的針對性和精準性得到了提升.
猜你喜歡
奧秘(創新大賽)(2020年1期)2020-05-22 02:42:38
小學科學(學生版)(2019年10期)2019-11-16 08:55:02
小哥白尼(趣味科學)(2019年12期)2019-06-15 10:56:32
通信電源技術(2018年3期)2018-06-26 06:34:18
人大建設(2018年2期)2018-04-18 12:17:00
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
