基于Java 的SEED 文件解析
2021-09-10 07:17:20劉靜聞盧燕紅蔡宏雷
防災減災學報 2021年3期
張 帆,劉靜聞,付 琦,盧燕紅,蔡宏雷
(1. 吉林省地震局,吉林 長春 130117;2. 遼寧省地震局,遼寧 沈陽 110034)
0 引言
自1985 年以來,國際地震學和地球內部物理學協會(IASPEI) 制定了國際數字地震數據交換標準SEED 文件格式,SEED 格式已經成為地震行業最具權威性的國際通用標準。為了規范我國地震臺網波形數據管理,2017 年中國地震局發布了中華人民共和國地震行業標準中的《地震波形數據格式交換》白皮書,結合我國現狀,對《國際地震數據交換標準》進行解讀。在地震行業中,SEED 格式文件分為現場臺站卷、臺站臺網卷和事件臺網卷三種[1]。本文從實際應用出發,介紹最常用的事件臺網卷SEED文件的解析和使用。解析此類SEED 文件,需要了解SEED 格式文件的存儲結構和規范,針對這些問題,本研究利用Java 語言的跨平臺性[2],與大數據技術無縫整合的特點研發一套能提供快速穩定準確的SEED 格式地震波形數據解析軟件,支持WINDOWS、LINUX 等操作系統,并作為基礎軟件包應用于東北地震與火山大數據平臺業務中。
1 SEED 結構
通過“九五”和“十五”項目建設,JOPENS系統在地震行業推廣使用,解決測震多數據源的難題,提供統一準確高效的測震實時流平臺[3],以 SEED 或者 MINSEED 文件格式[4]對測震實時流數據進行數字化存儲,如:連續波形數據、事件波形數據等。MINSEED 可以理解為SEED 格式的簡化版,和SEED 格式的主要區別是不包含頭文件信息,主要存放數據體內容。因此,本軟件以SEED 文件為研究對象,并兼容MINSEED 格式的解析。
SEED 文件屬于科學類特有的國際通用型數據文件,不單單應用于地震領域,還在重力、衛星、氣象等領域廣泛應用。為了滿足這些條件,SEED 文件每部分的存儲方式都不同,但是都遵循計算機國際統一的多種編碼規范來達到通用性的效果。想要解析并讀取SEED 格式文件,不僅要了解SEED 文件底層內部結構,還要了解SEED 格式文件在地震行業的應用結構。
1.1 SEED 文件底層結構
SEED 格式文件底層結構如表1 所示。

表1 SEED 格式文件結構說明
表1 是SEED 文件的整體結構,包含序號、控制頭段類型碼和延續碼,也就是通常所說的頭文件。類型A 代表字母數字字段,是固定長度的ASCII 碼串;D 代表十進制整數。V-可變長度的ASCII 碼串,用“~”表示結束。
SEED 除了V、A、S、T 控制頭段邏輯記錄外(每個卷都是4096 字節),數據記錄的卷(4096 字節) 包含了 8 個 MSEED 數據結構體。MSEED 結構體存儲的內容就是帶時間片的數據,與頭文件的S 和T 對應匹配。
SEED 文件格式含控制頭端(ASCII) 和時間序列(二進制) 兩種格式體,如圖1-2 所示。
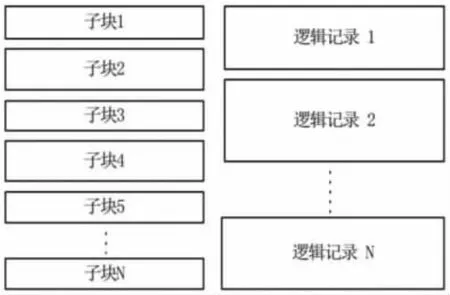
圖1 控制頭段格式體Fig.1 SEED header format
從圖1 可以看到,每個控制頭段由多個子塊組成,每個子塊包含子塊標識符、長度、若干個數據字段。
從圖2 可以看到,數據體由多個記錄文件組成,每個文件記錄包含多個邏輯區域。每個邏輯區域包含多個數據記錄,每個數據記錄由標識塊、一個固定頭段、一個可變頭段和數據區組成。每個數據記錄都有一個數據記錄標識塊與控制頭相對應。文件的整體結構是以一種可擴展的鏈式方式進行數據的存儲。
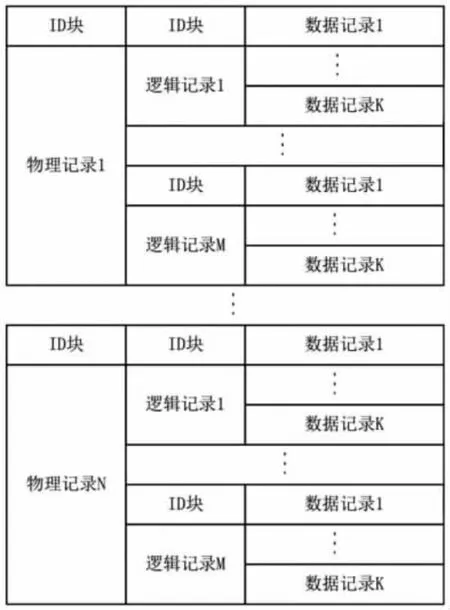
圖2 時間序列格式體Fig.2 Time series format
1.2 SEED 文件應用結構
SEED 文件地震應用結構圖:
從圖3 可以看出,SEED 格式文件分為頭文件和數據體文件兩大部分[1],其中頭文件采用ASCII 編碼方式對臺網編碼、臺站標識碼、位置標識、通道標識碼、采樣率、靈敏度、正則化因子、零極點、零極點單位、時間序列等重要信息。其中,時間序列拆分為N 組,每一組稱為時間切片。數據體部分采用計算機十進制編碼方式,分成八個數據塊存儲數據記錄,每一個數據塊為4096 個字節,也可以理解為常用的MINSEED 格式文件。

圖3 SEED 地震格式體Fig.3 SEED seismic format volume
頭文件與數據體文件通過時間序列進行匹配,才能將記錄的數據與對應臺站關聯起來,時間序列中每一個時間切片會形成唯一的索引值,這個索引值是與數據體中數據塊的索引值相對應還原出完整的地震事件信息。一個完整SEED 文件包含的主要元素有臺網編碼、臺站標識碼、位置標識、通道標識碼、數據頭段/數據質量標識、記錄開始和結束時間、偏移量等。其中,采樣率表示儀器1 秒鐘采集數據的個數,通道標識碼表示地震儀的三分項 (東西、南北、垂直),零極點是地震儀線性動態系統傳遞函數的參數,分子項是零點,分母項是極點,與正則化因子功能一樣,主要用于去儀器響應及波形仿真。
2 解析流程
利用Java 的I/O 流技術[5]讀取SEED 臺網事件卷,解析頭文件和數據體文件。頭文件參數涉及到數據仿真和量綱轉化重要信息。數據體記錄的數據體量大小是由采樣率的大小決定,模擬短周期DD-1 一般采樣率為100Hz,所以數據體量龐大,需要利用緩存技術進行存儲。利用地震學研究聯合會(Incorporated Research Institutions for Seismology) 發布的 SEED 軟件包進行SEED 文件的讀取和解析處理。解析SEED 文件分為頭信息和數據體兩部分。
2.1 頭文件解析
頭信息解析流程如下:
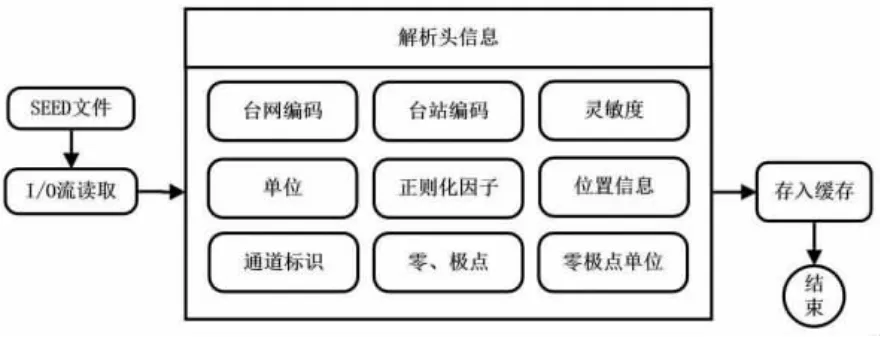
圖4 解析讀取SEED 頭信息流程Fig.4 Analysis of SEED header information process
根據《地震波形數據格式交換》白皮書讀取SEED 頭信息,臺站編碼的卷索引標識為“011”,通過索引標識可以提取出臺站編碼。通過卷索引標識“052”來獲取通道信息(Z、N、W 三分項)、采樣率、位置(臺站經度和緯度)、靈敏度、T-時間片控制字段等信息。這些信息與數據體相匹配,得到臺站完整的波形數據。


此流程只是將數據體進行分類處理,要想得到按照時間排序的正確的數據格式,還需要數據體解析流程。
2.2 數據體解析
讀取SEED 數據體過程中,由于數據體分塊存儲,還需要根據時間序列(即:T-時間片控制字段) 來判斷數據塊的連續性和時序性,解析流程圖如圖5 所示。
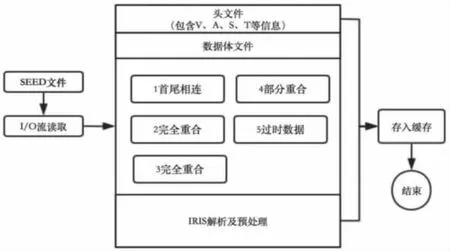
圖5 解析讀取SEED 數據體流程Fig.5 Analysis of SEED data process
利用Java 的I/O 流技術將SEED 格式文件轉換成byte [] 數組結構,將SEED 頭文件解析存儲以后,根據解析出的頭信息再去與數據體索引的時間片控制字段相匹配,對SEED 數據體內容進行分塊讀取和解析,這樣就能將一個地震事件的數據全部匹配解析出來。在采樣率一致的前提下,判斷SEED 數據塊在程序中是否進行拼接解析處理,大致有5 種情況:
(1)源數據塊和新數據塊時間連續剛好可以拼接,即:首尾相連。程序根據時間進行排序,直接將數據塊進行合并。
(2)源數據塊和新數據塊時間完全重合或者新數據在源數據時間段內,即:完全重合。程序從連續率、完整性、穩定率三方面選取數據質量較好的記錄納入處理流程。
(3)源數據和新數據中存在漏包,即:不連續。程序會自動根據時間序列對漏包的部分進行補零填充處理。如果漏包嚴重,程序不會將記錄納入處理流程。
(4)源數據和新數據存在部分重合,即:部分重合。程序從連續率、完整性、穩定率三方面選取重合部分數據質量較好的記錄納入處理流程。
(5)源數據塊比新數據塊時間還大,這時新數據為過時包,不進行拼接操作。即:過時數據。
程序對以上5 種情況處理以后,才保存到緩存中。
雖然上述情況不是很多,經過初步分析,主要是因為網絡延時、地震儀故障或老化等客觀因素。為了能準確順利的讀取SEED 信息,程序對上述情況做了相應預處理。
3 大數據結合應用
吉林省大數據應用采用的是基于Java 語言的Hadoop 技術[6],此項技術是針對海量存儲及計算問題的最佳解決方案,Hadoop 的框架最核心的設計就是:HDFS 和MapReduce。HDFS 為海量的數據提供了存儲,而MapReduce 則為海量的數據提供了計算,是大數據時代最重要的技術。大數據平臺解決了傳統存儲的弊端,實現數據實時安全存儲、處理、解析、共享、運算、公共服務等問題。
基于Java 的I/O 流技術SEED 格式文件解析程序是波形仿真、P 波拾取、定位、震級計算等一系列自動處理環節中最基礎的部分,此程序直接影響自動處理過程中的準確性和時效性。與大數據技術一脈相承,大大地提高了系統的穩定性。已經應用于東北地震與火山大數據平臺業務中,為地震分析預報和應急提供重要的參考依據。
4 應用效果
SEED 格式文件解析在大數據平臺中的應用效果,通過Echart 畫圖工具即可在瀏覽器中顯示完整的事件波形,如圖6 所示。

圖6 解析SEED 文件效果圖Fig.6 Analysis of read SEED file rendering
以 2018 年 5 月 18 日凌晨 1:50 分,松原5.7 級地震為例,SEED 解析在大數據平臺自動定位應用中的效果,如圖7 所示。
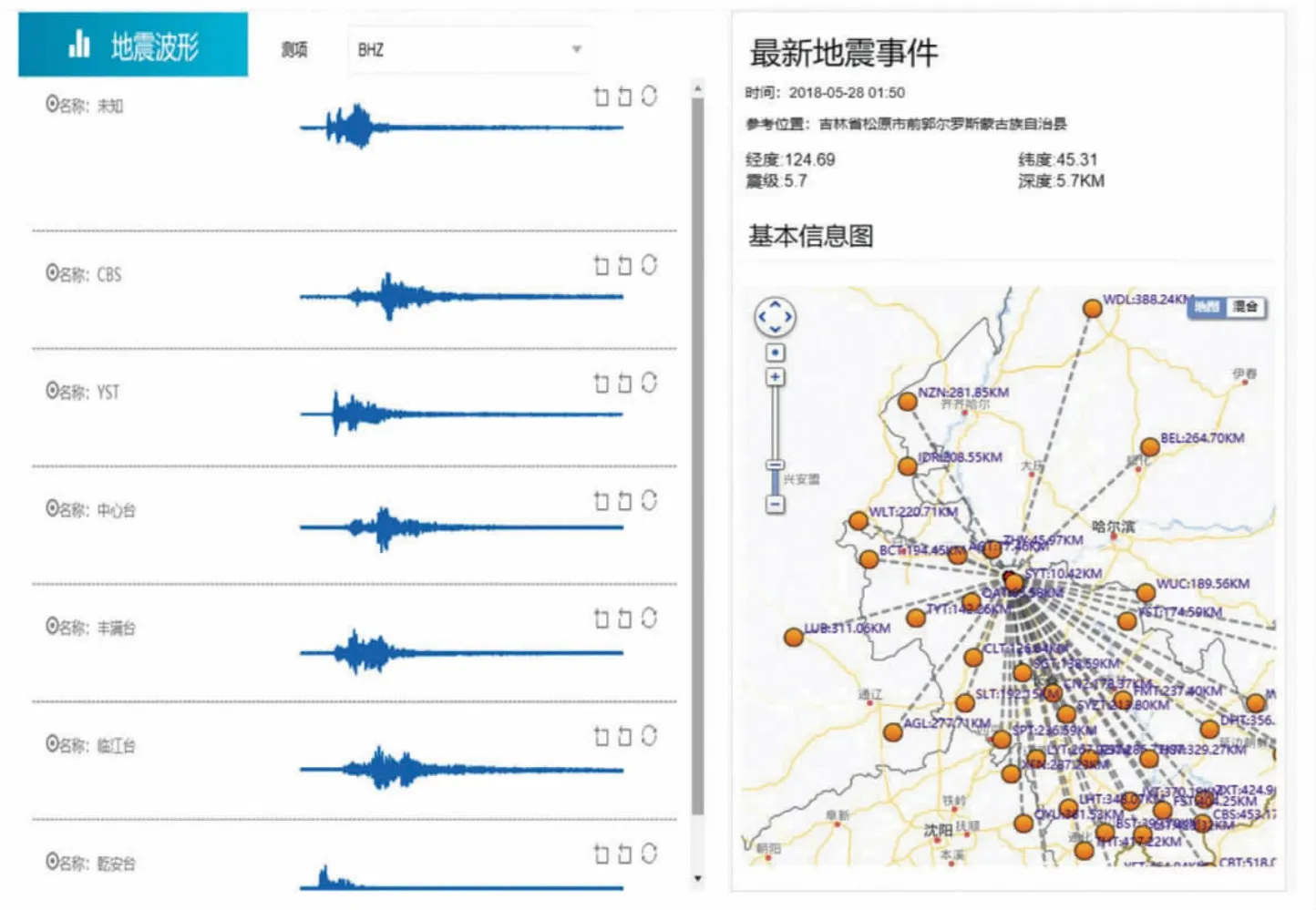
圖7 震例效果圖Fig.7 Earthquake case
圖7 中,左側為此次地震事件自動拾取的波形記錄,右側為記錄臺站到地震的距離。該軟件通過基于Java 技術解析SEED 文件的處理方法和流程,以及對數據體部分特殊情況的預處理方法,對SEED 文件讀取達到準確、快速、穩定的要求,與Hadoop 技術[5]實現無縫集成,已經應用于大數據平臺實際業務中,并通過多次實際震例檢驗。為大數據平臺后續業務:波形的實時解析、存儲、地震自動處理流程(地震自動定位、震級自動計算)、烈度圖的快速自動產出等功能,提供底層支撐。
5 結論
SEED 文件的讀取和解析程序是實現地震自動處理環節中最基礎的部分,也決定了自動定位和震級計算的準確性,通過波形展示和多個真實震例(M2.0 以上) 的計算驗證,定位誤差10 公里以內,震級誤差0.1~0.3 之間,震級越大,參與的臺站越多,誤差率越小,與人工審核后的地震信息越接近吻合,完全可以應用在實際業務中,為地震速報及震后快速產出烈度圖提供重要的參考依據。程序具有良好的跨平臺性和移植性,也可以作為獨立的子程序,為其他應用提供基礎服務,也可以作為服務提供給其他程序使用。
