YOLO模型在視頻監測中快速識別目標的應用研究
2021-09-10 13:25:38陳旋
視聽 2021年9期
陳 旋
一、研究目的
隨著光纖入戶和5G網絡的普及,人們從視頻獲取信息的占比越來越高。視頻與文字、圖片相比,增加了時間維度,信息從二維提高到了三維。在互聯網信息監測中,用二維的技術無法滿足三維結構的要求,這給新媒體監測提出了新的挑戰。根據廣播電視監測行業的特點,在每個階段對新媒體的監測會有不同的目標,且有時會有緊急任務,也就是目標不固定、樣本少、時間緊。若單純使用人工播放并觀看的方式進行監測,將嚴重消耗人力,成為新媒體監測的難點。為了解決這個問題,需要研究當今計算機視覺的最新成果,并結合廣播電視行業的特點,找出適合業務要求的監測方法,最終實現機器自動監測,達到解放人力和減少網絡信息危害的目的。
二、目標識別方法
本文主要研究在一個視頻流中快速發現指定目標的監測過程,例如,在視頻流中找到特定的標志、植物等。此過程不同于人臉識別技術,識別目標對象沒有一個固定的分類,也沒有固定的特征,不同種類的目標具有不同的形狀、紋理、色彩、背景等特征。視頻流是由一幀一幀的畫面組合而成的,在視頻流中找到目標也就是要在每一幀畫面中找到目標。為了便于區分,目標識別定義為在視頻流中找目標,而目標檢測定義為在一幀畫面中找目標。目標識別是目標檢測的集合。目標檢測最終會得到兩個結果,即目標的定位以及目標的分類。目標的定位是指在畫面中預測出目標的位置,也就是目標的坐標值、高和寬;目標的分類是指正確判斷出目標的所屬類型。
隨著計算機視覺科技的發展,目標檢測技術先后發展出了兩類檢測模型。一類稱為two-stage模型。這一類模型檢測需要兩個步驟,先對物體進行定位,然后再對物體做識別。這類模型的經典算法是R-CNN。該模型利用了選擇性搜索(Selective Search)算法進行相鄰子塊的特征相似度評測,對相似圖像區域打分以及合并,從而獲取出感興趣區域的候選框。這些候選框被輸入到卷積神經網絡提取出圖像特征,再由支持向量機進行特征向量分類,最后做邊框回歸,最終完成目標檢測及定位。two-stage模型最大的缺點是算法性能較低,不能滿足實時要求。這源于需要對每一個生成的候選區域進行特征提取,存在大量的重復運算。雖然在R-CNN基礎上做了一些改進,推出了fast R-CNN和faster R-CNN,但還遠遠滿足不了人們對實時性能的要求。另外一種稱為one-stage模型。該類模型把兩個步驟優化成一個步驟,大大減少了計算量。YOLO模型是該類模型的杰出代表。
YOLO是You Only Look Once的英文縮寫,包含著快速檢測的意義。經過對比測試,YOLO模型在達到faster R-CNN同等準確率的情況下,表現出更高的識別速度,可以達到實時性的要求。
三、YOLO模型原理
YOLO模型與其他計算機視覺領域的模型一樣,也是充分利用卷積神經網絡(CNN)的研究成果,并對R-CNN家族算法做了架構上的優化統一。YOLO模型也創新了檢測思路,它將目標檢測作為回歸任務來解決,實現了端對端(end-to-end)的檢測,性能上得到了顯著提高。
模型進行學習訓練時,YOLO模型先將輸入的圖片分割成S×S的網格,每個網格單元負責檢測中心點落在該網格單元內的目標。如圖1所示,目標對象為一只小狗,其背景是樹木和草地。小狗的中心點位于圖像的中間位置,也就是加粗的小方格內,因此該網格單元將完成這個小狗的預測。每個單元格會預測B個邊框的坐標值、高和寬,同時也給出邊框的置信度值。YOLO模型的網絡結構參考了GooLeNet模型,包含了24個卷積層和2個全連接層。
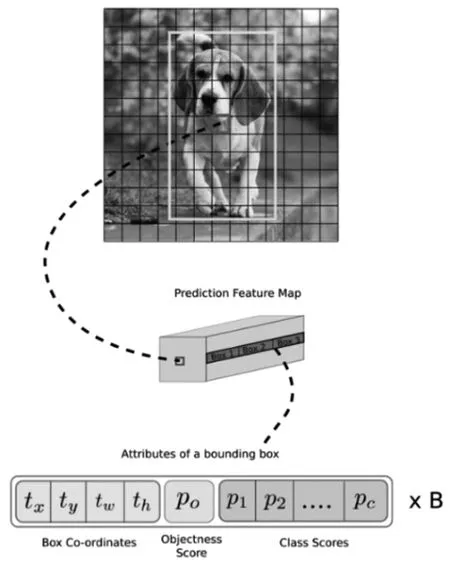
圖1 YOLO原理圖
模型在進行預測時,每個網格單元格都參與預測。每個網格單元格預測B個邊框,因此會有B個邊框置信度值,整個畫面將產生S×S×B個預測框,且每個預測框給出C個目標類別的概率值。通過閾值選出概率值高的預測框,再通過非極大值抑制算法(non maximum suppression,NMS)篩選出符合度最高的邊框。
四、衡量監測效果方法
為了量化目標監測的效果,需要定義相關指標參數。平均準確度均值mAP(mean average precision)是目標檢測的常用評價標準,用于衡量識別精度。mAP應用于多類目標的檢測,每一個類別存在一個AP值,多個目標時取其加權平均,也就是mAP。AP是查準率(P值,Precision)和查全率(R 值,Recall)綜合考慮的值。查準率是指模型判為目標的結果中實際也正確的比率,查全率是指模型判斷正確的數量占該類樣本總數的比率。比如模型識別出10個目標,經過人工檢查,這10個判斷結果中正確的判斷是8個,那么查準率為80%;但樣本中卻有16個是正樣本,因此查全率是50%。AP在幾何上是PR曲線下的曲線面積。準確率與召回率是反相關的關系,也就是增加準確率時會降低召回率,增加召回率意味著會降低準確率。結合廣播電視監測行業對視頻快速監測的業務要求,通常來說樣本數是較少的,往往是幾十到一兩百個,且在視頻中判斷出有目標存在即可,因此可以適當犧牲查全率來獲得較高的準確率。
五、目標監測步驟
本文假設以球星梅西作為監測對象。以人物目標作為識別對象,一方面是素材容易獲得,另外在難度水平上,人物識別的難度高于大部分日常監測目標,可獲得推廣意義。本文將在windows10平臺下訓練和測試模型,使用YOLO模型的代碼版本為v4。為了加快訓練速度且考慮可接受的成本,選用Nivida GeForce GT 730作為GPU設備。其他相關軟件版本如下:cuda10.2、cudnn7.6.5、Python3.7、VisualStudio2019、Opencv3.4.0。
(一)數據采集。工作中不能采集到很多且場景多樣的樣本,也沒有足夠時間進行標注。根據這個特點,本次研究只從3段錄像中提取182張圖片。實踐證明,有意識地篩選出具有強烈特征區別的樣本,可以提高準確度。如清晰反映出梅西的發型、球服、人臉、動作等的樣本。數據采集是一件費力的事情,為了減輕工作量,可編寫Python腳本。該腳本能夠一邊低速播放,一邊接收鍵盤輸入,按空格鍵將抓取一幀圖片并保存到磁盤目錄中。
(二)數據標注。實踐證明,YOLO模型只識別一個對象比識別多個對象準確度低,這是由于多個識別對象可以相互作為負樣本,正負樣本同時存在可提高精度,因此在標注監測目標的同時也多標注一類輔助目標,本文選擇足球為輔助目標。LabelImg是常用的目標標注工具,支持多平臺。根據8:2的比例生成訓練集和測試集,最終整理出訓練所需的訓練圖片列表,測試圖片列表,標注文件、文件存放路徑。
(三)網絡模型訓練。本文使用遷移學習的方法進行網絡模型訓練。遷移學習是把已訓練好的模型參數遷移到新的模型中來,起到幫助新模型快速收斂的目的。在樣本少的情況下,該方法顯得很有幫助。實踐也證明,從已有的類似場景中遷移過來,花費時間不僅更少且效果更佳。訓練經歷了4個小時,loss值降到0.5后結束訓練。
(四)網絡模型測試與性能。圖2是模型測試的效果截圖,可以看到識別出梅西球星和足球,也給出了概率值。可直觀地認為YOLO模型學習到了梅西的球服、膚色、動作等綜合特征,而不是單純地以白色球服、人體的輪廓來判斷。測試顯示幀率(FPS)在40左右,可以流暢播放。
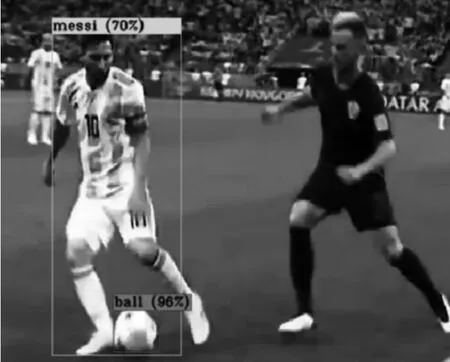
圖2 視頻測試
(五)性能和效果分析。通過運行darknet.exedetector map命令可計算出mAP的值。IoU=0.5時mAP=87%,IoU=0.7時mAP=35%,因此在不要求框得十分完整的情況下,可以較好地查找到目標。
六、結語
通過上述討論,可以得出YOLO模型應用于廣播電視監測行業的視頻監測是可行的,所需樣本的數量、樣本標注的工作量、模型訓練的耗時、設備的成本等方面都是可接受的。為了減少誤報率,一方面可以提高閾值,另一方面可采集并標注更多的訓練樣本(如500張以上且盡可能場景多樣)。本文的研究過程使用了不同的工具,若能在一個系統中實現所有流程,將可以節約時間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
