面向高考咨詢問答系統的問句分類研究
2021-09-10 07:22:44劉園園李勁華趙俊莉
青島大學學報(自然科學版) 2021年1期
劉園園 李勁華 趙俊莉

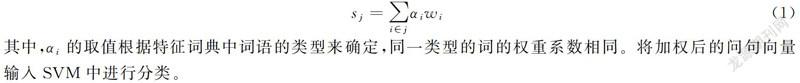


摘要:為建立一個高質量的問答系統,在建立高校信息知識圖譜的基礎上,提出一種在問答系統領域進行問句分類的方法,并構建了新的分類模型:基于改進的支持向量機模型、融合注意力機制的雙向長短時記憶網絡(BiLSTM-Attention)模型和BERT-BiLSTM相似度計算模型,并與BERT微調模型作比較。研究結果表明,本問句分類方法能獲得較高的問句分類準確率,BERT模型具有更好的分類性能,而將Bi-LSTM和BERT進行融合對句子特征的提取能力更強。
關鍵詞:問答系統;問句分類;支持向量機;長短時記憶網絡;BERT
中圖分類號:TP391
文獻標志碼:A
文章編號:1006-1037(2021)01-0018-07
基金項目:
國家自然科學基金 (批準號:61702293)資助;山東省重點研發計劃(批準號:2019JZZY020101)資助。
通信作者:李勁華,男,博士,教授,主要研究方向為軟件工程、算法理論、大數據理論與技術。
問答系統是近年來自然語言處理、信息檢索等領域研究的熱點,接收人們自然語言方式的提問,并返回簡潔、準確的答案,由于無需用戶從大量的結果頁面中手動定位所需信息,因此問答系統能更好的滿足人們對信息檢索的需求[1]。問句分類是問答系統的首要環節,能否對用戶輸入的問題進行正確分類極大地影響了問答系統的準確性:準確的問句分類不僅可以減少候選答案空間,而且能提高答案檢索效率和答案的準確率,還可以作為一種附加信息用于相似度計算[2]。問句分類的關鍵是選擇和提取問句中的特征[3],目前對問句分類的相關研究較多,如考慮疑問詞等在問句中的重要性,Xu等[4]提出了一種將依存關系和高頻詞結合作為附加特征的方法,在UIUC問題集上用支持向量機分類,比基線方法提高了大約3%;考慮到FAQ(Frequently Asked Questions)類問答模塊的實現需要同時實現問句分類和問句相似度匹配,孫澤建等[5]利用TextRank算法和IDF(Inverse Document Frequency)值來加權詞向量以表征問句,通過改進的k近鄰算法將兩個不同的問句相似度模型結合,在候選類別為3的情況下分類精確率達到92%;王東波等[6]利用TF-IDF提取類別特征詞,在BiLSTM(Bidrectional-Long Short Term Memory Network)上進行了先秦典籍問句分類的研究,取得了較好的效果;Devlin等[7]提出預訓練語言模型BERT(Bidirectional Encoder Representations from Transformers),在各種自然語言處理任務中展現了良好的性能,因此陸續出現了與BERT相關的問句分類研究[8]。以上研究對于本文研究問句分類模型具有重要的借鑒意義和指導價值。但是目前對于問答系統中問句分類的研究大多只是在算法方面的改進,很少涉及知識圖譜領域,問句的類別也不多。由于知識圖譜[9]可以把碎片化知識組織起來,建立數據之間的關聯,越來越成為問答系統常用的數據存儲形式,因此在知識圖譜領域進行問句分類的研究很有必要。知識圖譜是由節點和邊組成的一種數據庫[10],節點代表實體,邊代表實體間的關系,在基于知識圖譜的問答系統中,用戶詢問的可能是某個實體,可能是實體的某一個屬性,也可能是實體間的關系,這就需要對用戶的意圖進行識別,也就是問句分類。由于知識圖譜包含的實體和屬性眾多,因此對問句分類的模型和方法提出了更高的挑戰。本文基于構建的高校信息知識圖譜,提出了一種在問答系統領域進行問句分類的方法,并提出了三種問句分類模型,然后在收集的高考咨詢問句中進行對比實驗。
1 問句分類方法
1.1 構建問句的分類體系
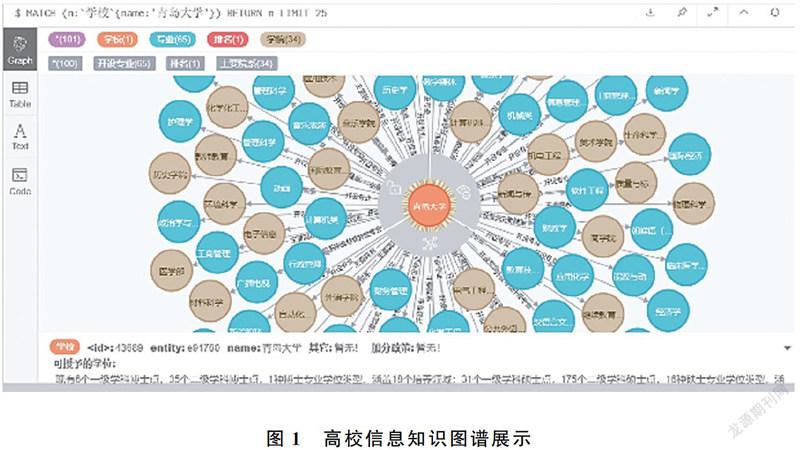
在問句分類之前要先確定問句的類別,本文構建的高校信息知識圖譜包含學校、學院、專業、人、省份、時間等多個實體,每個實體又包含多個屬性,如“學校”實體就包含地址、周邊環境、加分政策等10多個屬性,如圖1所示。問答系統必須要給用戶返回一個精確的答案,因此只涉及實體層面的分類體系無法滿足需要,但是若把每個實體的屬性都列舉出來作為問句的類別,又會因為類別太多而影響分類的準確率,而且后期如果添加新的屬性就要重新訓練分類模型,不易于系統維護。因此本文結合建立的高校信息知識圖譜,構建了新的問句分類體系,如表1所示。
本文將每個實體類型擴充為兩種類別:實體類和實體_屬性類。實體類就是這個實體本身的類別,如學校、專業等;實體_屬性類就是實體所具有的所有屬性,如學校_屬性類就包含簡介、地址、招生簡章等各種類別。所有的實體類、實體_屬性類以及一個關系類構成了問句的大類別,所有的實體_屬性類下的屬性構成了問句的小類別。如問句“山東大學有哪些專業”的類別是“專業”,而“山東大學計算機專業都開設哪些課程”的類別就是“專業_屬性”類下的“開設課程”類別,合并為“專業_開設課程”類。
1.2 問句分類步驟
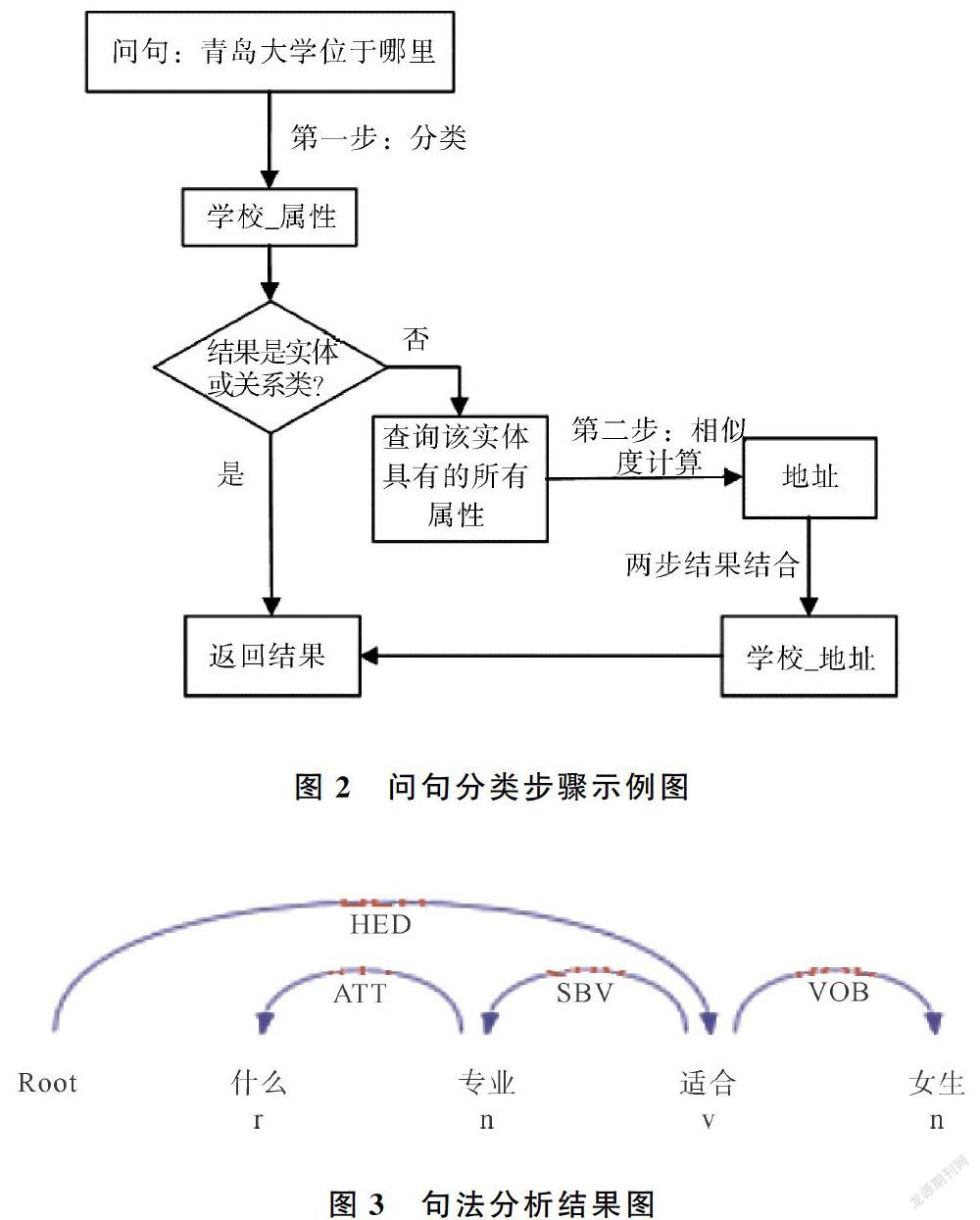
根據上述的問句分類體系,將問句分類分為兩步。首先,進行大類別分類,若是大類別分類的結果是實體,那么就直接返回結果,如果分類的結果是實體_屬性,那么就進行第二步分類。第二步分類是小類別分類,采用相似度計算算法來獲得問句類別,具體做法是從知識圖譜中獲取該實體所具有的所有屬性,然后分別與輸入的問句進行相似度匹配,選擇匹配度最高的作為小類別的分類結果。具體步驟如圖2所示。這種分類方法不僅可以減少由于問句類別過多對于分類準確率的影響,還可以提高模型的健壯性,即使后期需要在知識圖譜中添加新的屬性,也基本不需要重新訓練模型。
2 問句分類模型
本文采用了三種分類模型和一種相似度模型對高考咨詢問句進行分類研究。由于支持向量機[11]在文本分類問題上一直有著良好的效果,因此本文首先選用支持向量機進行問句分類;深度學習是近些年來研究的熱點[12],LSTM在句子建模方面[13]幾乎始終優于CNN[14],而BiLSTM能通過雙向傳播機制保存上下文信息,在處理序列化數據上有優勢[15],融合注意力機制后的BiLSTM模型能夠得到關于注意力的概率分布,提高模型的分類性能,因此,本文構建了Bi-LSTM-Attention的深度學習網絡模型用以問句分類;文本還將BERT引入高考咨詢領域進行問句分類研究,以期取得理想的效果。
2.1 基于加權詞向量的支持向量機分類模型
支持向量機(Support Vector Machine,SVM)是一種基于統計學習理論的分類器,其優化目標就是找到一個最優分隔超平面,使得離分隔超平面最近的點離超平面的距離盡可能的遠。Word2vec能夠把文本中的詞語轉換成向量空間中的向量,向量的相似度可以用來表示詞語語義的相似度,但是Word2vec詞向量不能分清詞語間的重要程度[16],而問句中所包含的疑問詞等對問句分類起著非常重要的作用,在很大程度上決定了問句的類別,如“誰”、“哪里”、“什么時候”等。另外,主、謂、賓等不同的詞對于句子類別的決定作用也不相同,因此可以通過建立疑問詞表以及結合依存句法分析等方法提取特征詞,賦予其不同的權重。
圖3為利用哈工大LTP平臺[17]的句法分析結果,以圖3為例,本模型提取問句特征的方法可以分為三步,將提取的詞按類型添加進特征字典d中:
(1)根據預先建立好的疑問詞表查找問句中的疑問詞q,圖1中包含疑問詞“什么”,因此,將疑問詞和其類型以鍵值對形式加入到特征字典中,即d={'什么':'q'};
(2)根據依存弧關系,查找疑問詞的依存詞f,更新字典為d={'什么':'q';'專業':'f'};
(3)依次根據依存弧HED、SBV、VOB找句子的核心詞h、主語s和賓語o,如果某特征詞在字典中已經存在,則跳過不添加,僅保留一個作為特征。如上一步中“專業”已經作為疑問詞依存詞添加進字典中,那么就不再作為主語添加,最終的特征字典是d={'什么':'q';'專業':'f';'適合':'h';'女生':'o'}。
對于每條問句j和句子中的每個詞i,wi是經過Word2vec模型訓練出來的詞向量,αi是詞i的權重系數,那么問句向量為
其中,αi的取值根據特征詞典中詞語的類型來確定,同一類型的詞的權重系數相同。將加權后的問句向量輸入SVM中進行分類。
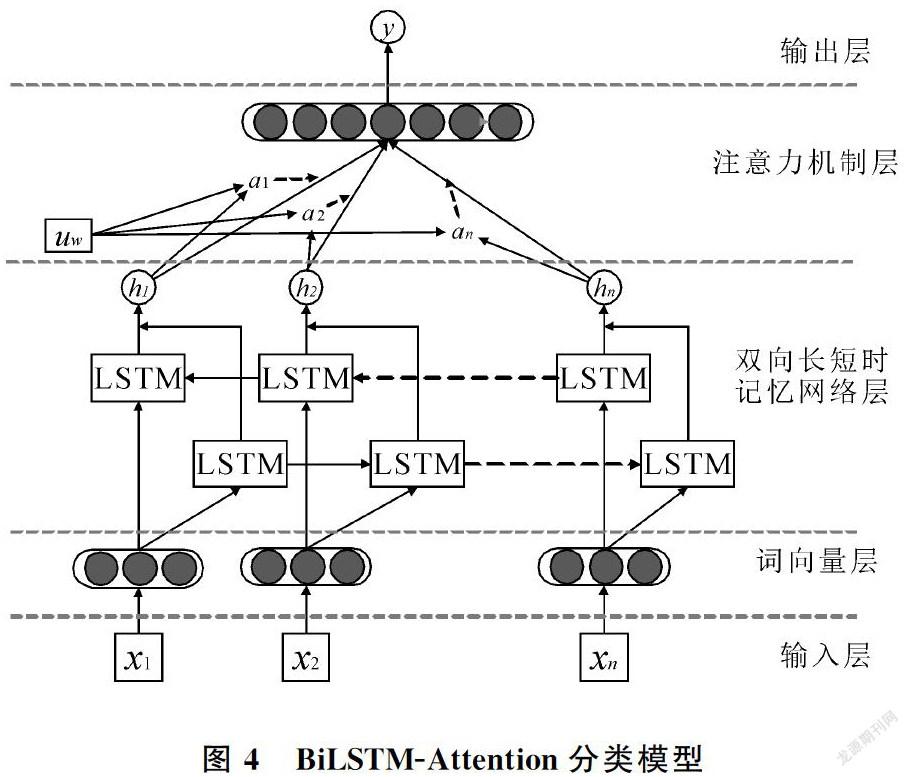
2.2 基于詞向量的BiLSTM-Attention分類模型
圖4為本文構建的BiLSTM-Attention分類模型圖,共有5層結構:輸入層,詞向量層,Bi-LSTM層,注意力層和輸出層。
(1)詞向量層:首先對輸入的問句中的每個詞x1, x2, …, xn,進行對應的詞向量表示,在此仍采用Word2vec詞向量。由于LSTM網絡可以通過增加細胞數量來記住更多的語言特征[18],而且Attention機制會對每個單詞的權重進行自行分配,因此不對詞向量進行加權;
(2)BiLSTM層:接收上一層的輸出作為輸入,充分捕捉問句信息,得到輸出向量h1, h2, …, hn;
(3)注意力層:在注意力層計算各個hi的概率分布αi,然后計算加權和得到句子表示。首先生成hi的隱藏表示ui,然后計算ui在詞級別的上下文向量uw中的重要性,uw可以看做是一個固定查詢“什么是重要單詞”的高級表示等[19],是在訓練過程中初始化和聯合學習的。然后通過softmax函數得到歸一化的權重αi,最后將上一層的輸出hi和αi的加權和作為句子的向量表示;
(4)輸出層:使用一個softmax函數得到預測類別y。
2.3 BERT預訓練語言表示模型
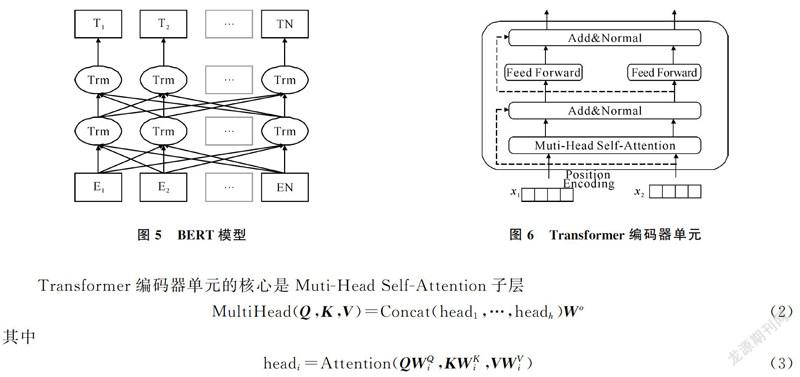
BERT是一種基于微調(fine-tuning)的預訓練語言表示模型。預訓練語言表示模型的思想就是在進行網絡訓練的時候不再對網絡模型隨機初始化,而是先預訓練通用模型,用這個通用模型的參數對網絡模型初始化,然后再根據具體應用,用有監督的訓練數據微調模型,使之適用于具體應用。BERT的模型架構如圖5所示,BERT是一個雙向Transformer[20]編碼器,具有更強大的表義能力。單個Transformer編碼器單元如圖6所示,共包含兩個子層:Muti-Head Self-Attention層和一個簡單的前饋網絡。對每個子層增加了一個殘差連接和層標準化。
其中,Q,K,V都是向量矩陣,dk是向量維度。式(3)中的Attention函數可以描述為將Q和K-V對映射到輸出。Self-Attention的核心思想是一句話中每個詞對于其他詞的重要程度是不同的,通過計算這些詞與詞之間的關聯程度來調整每個詞的權重以獲得每個詞新的表示,這個新的表示包含了其他詞與這個詞的關聯程度,因而比詞向量包含更全面的信息。
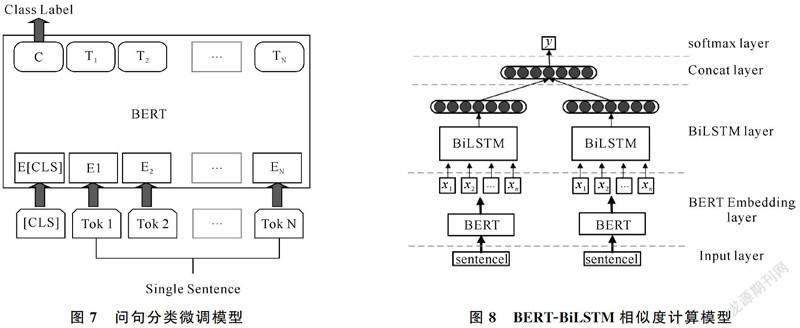
傳統的語言模型只能通過一個詞的上文或下文信息去預測該詞,不能完整地理解整個語句的語義,即使雙向LSTM能通過雙向傳播機制實現雙向預測,但也只是把從前往后和從后往前得到的兩個預測拼接在一起,仍然不能完整地理解整個語句的語義。BERT模型用了兩個訓練任務——“Masked語言模型”任務和“下一句話預測”任務實現上下文同時預測,取得了較好的效果。這兩個訓練任務合在一起,稱為預訓練。在得到的預訓練模型的基礎上,只需將特定任務的輸入和輸出插入到BERT中,對端到端的所有參數進行微調就能得到符合要求的模型。本文的任務是問句分類,所需要的微調模型如圖7所示,由于[CLS]的向量表示包含了整個句子的語義信息,因此被送到輸出層用于分類。
2.4 相似度計算模型
BERT在相似度計算方面的微調模型和問句分類類似,都是將第一個Token的輸出作為整個句子的語義表示,但效果卻不如問句分類的微調效果好,因此本文將BERT與Bi-LSTM結合[21]來構建新的相似度計算模型:使用BERT初始化詞向量,將每個Token的輸出,作為雙向長短時記憶網絡的輸入[22],進行進一步的特征提取,然后生成句子的語義表示,最后將兩個向量拼接在一起經過一個softmax層得到相似度標簽。搭建的模型結構如圖8所示。
3 實驗及結果分析
3.1 評價標準
本文采用精確率(Precision)、召回率(Recall)、調和平均值F1對結果進行評價
其中各參數含義如表2所示,A、B、C、D代表實驗結果中符合所屬情況的問句個數。
3.2 實驗結果
本文通過Python爬蟲在百度知道、貼吧、各個學校的招生網站等爬取和收集與高考咨詢相關的問句,共3 000條,共有21種大類和42種小類。標注數據集時首先按大類別進行標注,然后再將實體_屬性類的問句按小類別進行標注。小類別相似度計算模型的輸入是兩個句子,第二個句子分別是該實體的所有屬性,相似標為1,不相似標為0。將標注好的數據按照7:3的比例分為訓練集和測試集。實驗的運行環境均是在聯想深度學習綜合應用平臺DeepNEX上,使用Python語言以及TensorFlow1.12.0框架。實驗結果如表3、表4所示。
表3是大類別的分類結果,其中加權SVM模型中疑問詞及其依存詞、核心詞、主謂賓的權重系數分別是3.4、1.6、1.4,此時達到較好的效果。從對比實驗可以看出,加權詞向量比不加權的詞向量的分類效果要好,說明疑問詞和依存句法對特征的提取是有效的,加權之后更能表達問句特征;基于注意力機制的Bi-LSTM模型的準確率略高于SVM,而BERT的準確率最高,即BERT對特征的提取能力最強。
表4是小類別相似度計算的實驗結果,可以看到BERT-BiLSTM模型的準確率稍高于BiBERT,說明在BERT基礎上利用LSTM對特征進行進一步優化可以有效提高相似度計算的準確率。表5是利用BERT微調在所有的68種問句上直接進行問句分類的實驗結果,聯合表3、表4的最優實驗結果(即本文方法)進行對比,可以看到實驗準確率要偏低。
3.3 問句分類可視化
本文將改進的問句分類模型用Python的tkinter模塊搭建GUI界面進行可視化包裝,實現問句的分類查詢,如圖9所示,將待查詢的問句輸進輸入框內,點擊分類按鈕,即可查詢問句類別。
4 結論
本文對問句分類進行了研究,提出了問答系統領域的問句分類方法,首先按照實體和屬性將問句分為大、小類別,然后分兩步進行問句分類,不僅能提高準確率,而且能提高模型的健壯性。同時研究了4種分類模型,實驗結果表明,結合依存句法分析和疑問詞表進行特征加權的SVM模型能有效提高句子的分類效能,表明問句特征對于問句類別十分重要;而融合注意力機制的BiLSTM-Attention模型的分類準確率比加權的SVM模型高,說明人工選擇的特征相對粗糙,而Attention實際就是一種自動加權機制,無需手動選擇特征,能自動達到較好的效果;BERT模型的分類效果最好,因為BERT通過雙向Transformer編碼器動態生成字的上下文語義表示,解決了一詞多義問題,生成的語義表示比傳統的詞向量更能表達語義特征。由于將BiLSTM模型與BERT結合能達到更好的效果,因此下一步的研究方向是嘗試將其他傳統的深度學習模型與BERT結合,探索更好的模型融合方式,以及問答系統的具體實現。
參考文獻
[1]鎮麗華,王小林,楊思春. 自動問答系統中問句分類研究綜述[J]. 安徽工業大學學報(自然科學版),2015,32(1):48-54+66.
[2]LI D,WEI F,ZHOU M,et al. Question answering over freebase with multi-column convolutional neural networks[C]// Meeting of the Association for Computational Linguistics & the 7th International Joint Conference on Natural Language Processing. Beijing:2015:260-269.
[3]SUN H, WEI F, ZHOU M. Answer extraction with multiple extraction engines for web-based question answering[C]// CCF International Conference on Natural Language Processing and Chinese Computing. Berlin, 2014.
[4]XU S,CHENG G,KONG F. Research on question classification for automatic question answering[C]//2016 International Conference on Asian Language Processing (IALP).Tainan,2016:218-221.
[5]孫澤健,司光亞,劉洋.面向兵棋演習的問答系統問句分類模型研究[J]. 計算機與數字工程,2019,47(2):308-313+319.
[6]王東波,高瑞卿,沈思,等. 基于深度學習的先秦典籍問句自動分類研究[J]. 情報學報,2018,37(11):1114-1122.
[7]DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of deep bidirectional transformers for language understanding[DB/OL],(2019-05-24)[2020-12-11]. https://arxiv.org/pdf/1810.04805.pdf.
[8]楊飄,董文永. 基于BERT嵌入的中文命名實體識別方法[J/OL]. 計算機工程,[2020-10-02]. https://doi.org/10.19678/j.issn.1000-3428.0054272.
[9]ZHU S G, CHENG X, SU S. Knowledge-based Question Answering by Tree-to-sequence Learning[J/OL]. Neurocomputing, 2020, 372: 64-72(2019-12-21)[2020-12-11].https://pdf.sciencedirectassets.com/271597/1-s2.0-S0925231219X00429/1-s2.0-S0925231219312639/main.pdf.
[10] ZHANG K, WU W, WANG F, et al. Learning distributed representations of data in community question answering for question retrieval[C]//Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco: ACM, 2016: 533-542.
[11] 范支菊,張公敬,楊嘉東.基于密度裁剪的SVM分類算法[J].青島大學學報(自然科學版),2018,31(3):46-51.
[12] 陳茗楊,趙志剛,潘振寬,等.基于深度學習的圖像實例分割[J].青島大學學報(自然科學版),2019,32(1):46-50+54.
[13] TANG D,QIN B,LIU T. Document modeling with gated recurrent neural network for sentiment classification[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon,2015:1422-1432.
[14] 王炳琪,吳則舉.基于改進的CNN的啤酒瓶蓋字符識別[J].青島大學學報(自然科學版),2020,33(3):34-42.
[15] 任勉,甘剛. 基于雙向LSTM模型的文本情感分類[J]. 計算機工程與設計,2018,39(7):2064-2068.
[16] 汪靜,羅浪,王德強. 基于Word2Vec的中文短文本分類問題研究[J]. 計算機系統應用,2018,27(5):209-215.
[17] CHE W, LI Z, LIU T. LTP: A Chinese language technology platform[C]// COLING 2010, 23rd International Conference on Computational Linguistics.Beijing, 2010.
[18] RAZZAGHNOORI M,SAJEDI H,JAZANI I K. Question classification in Persian using word vectors and frequencies[J]. Cognitive Systems Research,2018,47:16-27.
[19] YANG Z,YANG D,DYER C,et al. Hierarchical attention networks for document classification[C] //Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. San Diego, 2016:1480-1489.
[20] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need[DB/OL]. (2017-12-06)[2020-12-11]. https://arxiv.org/pdf/1706.03762.pdf.
[21] THYAGARAJAN A. Siamese recurrent architectures for learning sentence similarity[C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Phoenix: AAAI Press, 2015: 2786-2792.
[22] REIMERS N, GUREVYCH I. Sentence-BERT: Sentence embeddings using siamese BERT-Networks[DB/OL]. (2019-08-27)[2020-12-11]. https://arxiv.org/abs/1908.10084.
