基于BiLSTM-Attention模型的缺血性腦卒中的年卒中風險預測
2021-09-15 02:54:16駱軼姝邵圓圓陳德華
東華大學學報(自然科學版) 2021年4期
駱軼姝, 邵圓圓, 陳德華
(東華大學 計算機科學與技術學院,上海 201620)
隨著人工智能和大數據技術的發展,醫療模式逐漸從以治療為主轉變為以預測為主。腦卒中又稱“中風”,是一種急性腦血管疾病,具有發病率、致殘率、死亡率和復發率高的特點。未來5年里,相比心臟病、糖尿病等慢性疾病,腦卒中疾病在我國將以較快速度持續增長[1]。文獻[2]研究表明,約94%的腦卒中發病因素都是可控的,根據患者當前生理狀態及早對患病風險做出預判并加以預防,將極大地降低患者腦卒中發病率。
近年來,深度學習在缺血性腦卒中疾病預測研究中受到廣泛關注。Hochreiter等[3]提出LSTM(long short-term memory)模型,增加長期依賴時序特征輸入的學習模型,Graves等[4]在此基礎上綜合后向特征計算,提出BiLSTM(bi-directional long short-term memory)模型。基于這類深度學習模型的建立,姚春曉[5]構建了具有時序性的多層LSTM作為腦血管疾病預測模型。Chantamit等[6]參考國際疾病分類標準,構建LSTM循環神經網絡模型對中風進行分類預測,將LSTM作為隱藏單元對數據特征信息進行挖掘,并利用自循環輸出結果實現中風的分類預測。安瑩等[7]提出心血管風險預測模型(risk prediction model for cardiovascular, RPMC),綜合考慮多種臨床數據的融合學習,實現BiLSTM對電子病歷數據的挖掘。Ma等[8]借助Attention機制增加模型的可解釋性,實現利用電子病歷數據對患者未來健康的預測。
上述研究為心腦血管疾病預測問題提供解決方法,但腦卒中疾病中急性缺血性腦卒占70%左右[9],發病機制不同,選取疾病預判檢查指標存在差異。因此,針對缺血性腦卒中的年卒中風險問題,將疾病輔助預測視為特征分類問題,建立深度學習預測模型。定義卒中發生和復發關鍵的一年,即12個月為時間周期。本文對來自某醫院真實病歷指標做缺血性腦卒中疾病影響多因子分析,在此基礎上將患者當前檢查以及基于回歸預測思想構建的12個月后指標變化的時序數據作為輸入變量,采用one-hot、歸一化等數據預處理手段,將其轉化為BiLSTM模型輸入數據,以融合前向和后向的指標數據特征,并引入Attention機制,計算每個時刻特征與整個目標特征相似性以獲得新的特征表示,最終以診斷標簽作為輸出變量,計算模型中的損失并采用優化算法對模型反向訓練優化以獲得較好的預測模型。
1 模型建立
1.1 問題描述
缺血性腦卒中的年卒中風險預測問題可描述為當前及未來t時刻預測指標數據X={x1,x2, …,xn}及對應標簽Y={y1,y2, …,yn},其中n表示樣本患者數量,通過構建模型,由訓練得到指標數據X與對應標簽Y之間特征映射的預測模型。目標是當出現新的、未帶有標簽的患者指標數據時,模型能給出最優的年卒中風險預測結果Y′={y′1,y′2, …,y′n}。
1.2 模型結構
根據第1.1節中缺血性腦卒中問題描述,提出一種BiLSTM-Attention模型解決缺血性腦卒中的年卒中疾病預測問題。BiLSTM-Attention模型結構如圖1所示。
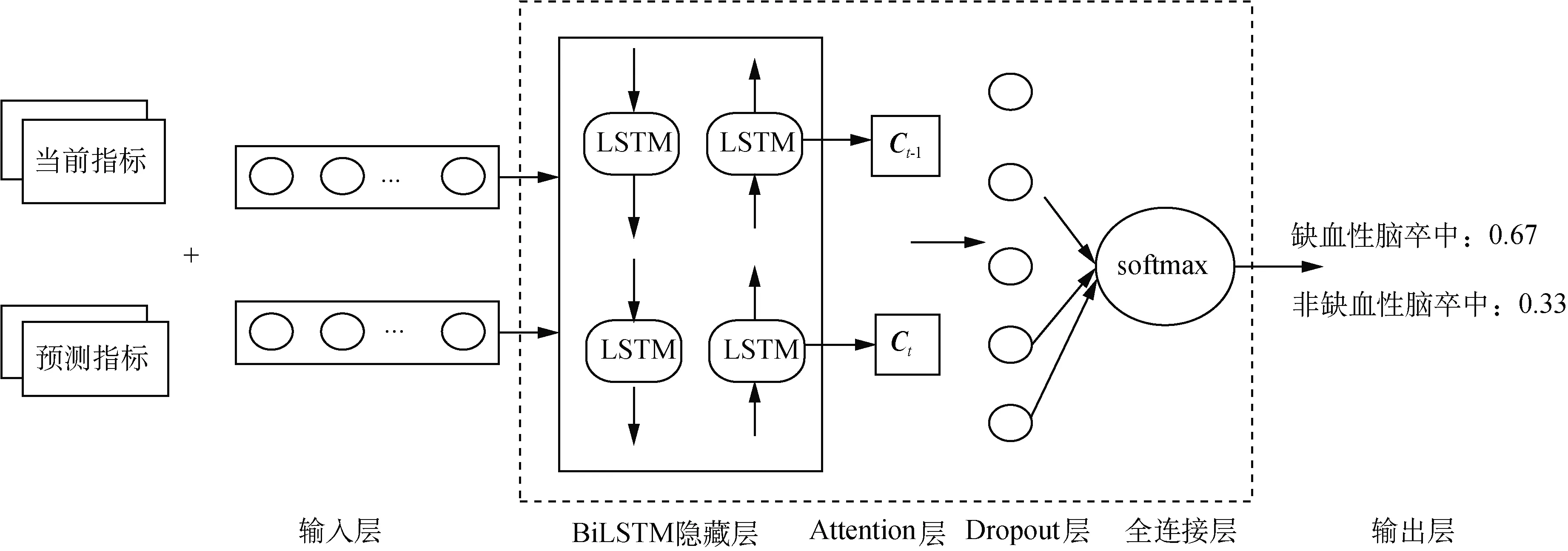
圖1 BiLSTM-Attention模型結構Fig.1 BiLSTM-Attention model structure
由圖1可知,連接患者當前檢查指標與預測未來12個月后變化指標形成輸入樣本,經BiLSTM隱藏層中神經元對特征進行計算,輸出特征向量并傳入Attention層,由該層判斷輸入時刻的特征對全局特征的重要程度,Dropout層通過設置丟棄率減少神經元個數,以防止模型出現過擬合,最后全連接層通過激活函數softmax進行連接。將上層特征映射輸出為類別的概率作為對患病風險的結果預測。
1.3 BiLSTM原理
BiLSTM是基于LSTM模型結構改進而來的。LSTM模型是由結構相同的多個隱藏單元連接構成,一個隱藏單元由遺忘門、輸入門、記憶細胞和輸出門組成。LSTM隱藏單元結構如圖2所示。
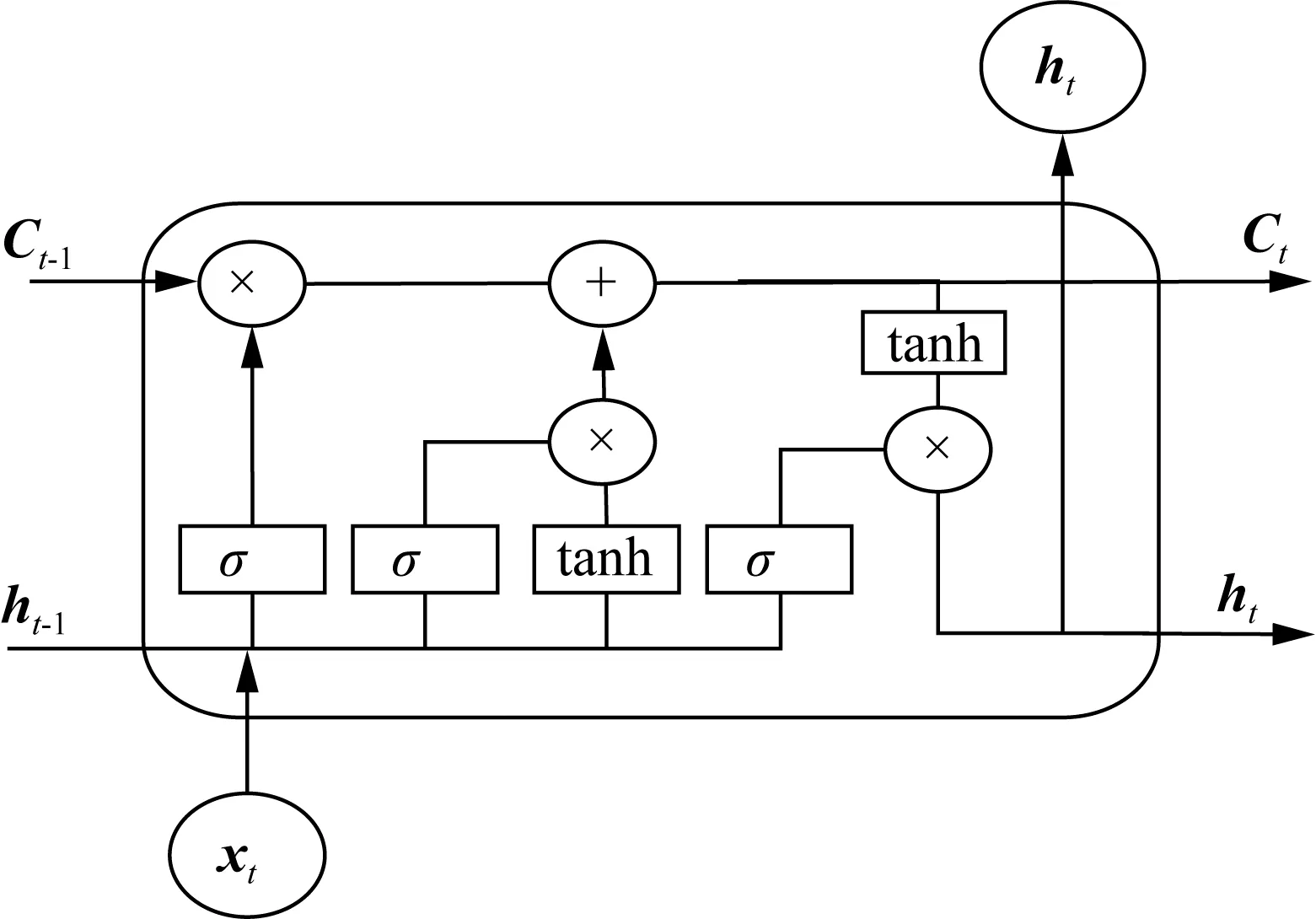
圖2 LSTM隱藏單元結構Fig.2 LSTM hidden unit structure
由圖2可知,t-1時刻隱藏向量ht-1和記憶細胞Ct-1及t時刻輸入的特征向量xt,通過權值和激活函數的計算獲取有效信息,并輸出t時刻隱藏向量ht和記憶細胞ht,具體計算如式(1)~(6)所示。
ft=σ(Wf[ht-1,xt]+bf)
(1)
it=σ(Wi[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(Wo[ht-1,xt]+bo)
(5)
ht=ot×tanh(Ct)
(6)
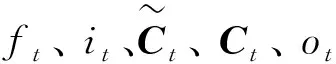
BiLSTM在LSTM模型基礎上增加模型計算的復雜度,將LSTM的單向計算改為前向和后向的計算,并將兩個方向的計算結果進行連接,以實現特征信息的雙向學習。BiLSTM總體實現流程如圖3所示。
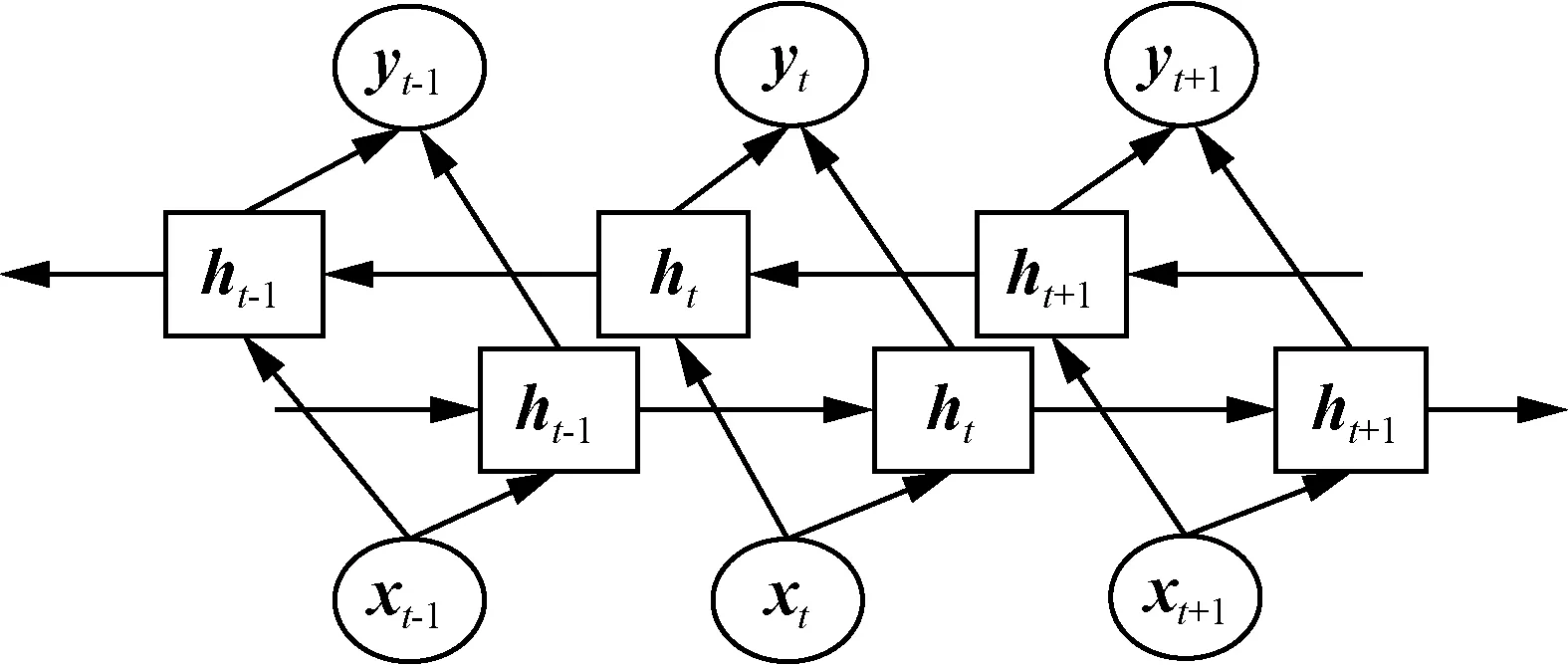
圖3 BiLSTM總體實現流程Fig.3 Overall implementation process of BiLSTM
由圖3可知,BiLSTM以LSTM作為隱藏單元,輸入特征進入兩個不同方向的模型結構中,通過隱藏單元特征計算,最后由該時刻的兩個隱藏單元的輸出向量連接構成該時刻輸出,其中,yt-1、yt、yt+1分別為對應的t-1、t、t+1時刻的輸出向量。t時刻BiLSTM計算如式(7)~(9)所示。
h(t-1)t=LSTM(h(t-2)(t-1),xt)
(7)
h(t+1)t=LSTM(h(t+1)(t+2),xt)
(8)
ht=[h(t-1)t,h(t+1)t]
(9)
BiLSTM模型的計算使每個時刻的隱藏層中信息將得到有效擴充的學習,有利于模型最終分類結果提升。
1.4 Attention機制
針對模型中可能存在忽略對關鍵特征信息的有效利用,增加Attention機制對時序特征信息的學習。該機制通過上層t時刻輸出向量ht作為輸入,計算特征權重αt,其計算如式(10)~(12)所示。
ut=tanh(Waht+b)
(10)
式中:Wa為權重系數;b為偏置系數。
(11)
式中:uw為初始化權重矩陣。
(12)
通過計算t時刻的輸出對結果的重要性ut,計算ht的特征權重αt并輸出向量Ct,對t時刻輸入指標向量進行加權。計算得到的權重αt越大,表示該時刻隱藏層特征的重要程度越大,則該時刻的向量Ct對預測結果的貢獻程度就越大。
通過上述計算,模型最終由全連接層中的softmax激活函數轉化為二分類問題,輸出年卒中風險發生概率y′i,計算如式(13)所示。
y′i=softmax(WiCt+bi)
(13)
2 缺血性腦卒中的年卒中風險預測
2.1 多因子確定
為篩選與缺血性腦卒中疾病發生的影響指標,采用Logistic邏輯回歸分析法確定影響疾病的多重因子,該分析方法被廣泛應用于醫學疾病影響因子分析研究中自變量與因變量之間的因果關系。該依賴關系通過回歸系數表示,計算類別概率,再得出回歸系數,計算方法如式(14)和(15)所示。
(14)
(15)
式中:j為因變量;x為自變量;k為自變量的個數。
當k=1時,模型進行單因素分析,建立單一自變量對因變量的影響程度分析;當k>1時,模型進行多因素分析,建立的多個自變量同時變化,對因變量結果產生影響。綜合兩種分析以尋找疾病發生發展的多危險因子。
2.2 輸入輸出變量的確定

(1) 輸入變量輸入數據X。通過確定的z計算融合卷積神經網絡(CNN)的LSTM非線性回歸預測模型,根據當前t-1時刻指標zt-1擬合未來t時刻zt中連續型數值的變化z′t,如式(16)所示。
z′it=σ(LSTM-CNN(zi(t-1),zit))
(16)
t-1和t時刻的數據組成的時序輸入變量X, 如式(17)所示。
X=concat(zi(t-1),z′it)
(17)
(2) 輸出變量風險預測結果Y′。獲取L標簽,轉化為一維數組,得到患者t時刻的真實標簽Y,如式(18)所示。
Y=[y1,y2, …,yn]
(18)
式中:yi∈li,i=1,2,…,n。
根據X和標注真實標簽Y的轉化,最終由模型尋找X與Y之間的特征關系,風險預測結果Y′如式(19)所示。
Y′=softmax(BiLSTM-Attention(X,Y))
(19)
2.3 數據預處理
采用one-hot作為一種通過N位狀態寄存器對N個狀態編碼實現離散特征映射到歐氏空間的獨熱編碼方式。在分類問題中,一方面提高模型的計算特征之間距離的效率,另一方面對數據特征的維度有了一定的擴充作用。同時,為減小數據在不同維度影響的訓練效果,采取歸一化的處理,如式(20)所示。
(20)
式中:Imin和Imax分別為指標I數據中的最小值和最大值。
通過計算指標中最大值與最小值的差值比,將指標數據壓縮到同一范圍。
2.4 模型訓練
模型訓練中每一步都經損失函數計算誤差,并使用優化器反向調整更新,以尋找模型效果最優的參數設置。
計算損失:交叉熵損失函數被廣泛應用于二分類損失問題,通過計算預測值與真實標簽之間的誤差,反映模型訓練效果。交叉熵損失函數如式(21)扭洋。
(21)
式中:n為樣本數量。
通過極大似然運算,計算年卒中風發生概率y′i與真實標簽yi的損失差異。
優化器:為減小模型訓練損失且不產生局部最優結果,選取Adam優化器進行反向計算以調整網絡權重參數。將計算梯度的一階矩估計和二階矩估計作為不同的參數設計自適應性學習率。
根據目標損失函數f計算出t時刻的梯度gradt,如式(22)所示。
gradt←Δθft(θt-1)
(22)
計算梯度gradt一階、二階矩估計值mt、vt,如式(23)和(24)所示。
mt←β1mt-1+(1-β1)gradt
(23)
vt←β2vt-1+(1-β2)gradt2
(24)
式中:β1、β2為矩估計衰減指數,分別默認為0.900、 0.999;θ為通過矩估計校正的更新參數。
缺血性腦卒中的年卒中風險預測模型訓練算法如下:
Initializeθ0
ForiinT:
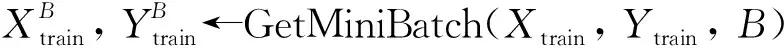
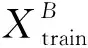
A←Attention(V)
Llogits←Matmul(A,θi)
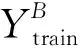
θi←Adam(Llearning_rate,Lloss)
End For
Evaluate(Xtest,Ytest,θ)
End
其中:T為訓練步長;B為批大小數據集;Llearning_rate為學習率;Xtrain/Ytrain、Xtest/Ytest分別為訓練集和測試集;V、A為特征提取層輸出向量、注意力層輸出向量;Lloss為模型訓練誤差;θi為第i次訓練網絡模型參數。
3 試驗結果分析
3.1 試驗數據
試驗數據來源于上海市某醫院的真實樣本數據,共983名患者,其中,非缺血性腦卒中作為負樣本共732名,缺血性腦卒中為試驗正樣本共251名。病歷數據的選取充分考慮缺血性腦卒中疾病的發病機制,其中多因子篩選包含性別、年齡、高血壓史、C反應蛋白(c-reactive protein, CRP)、總膽固醇(cholesterol, CHOL)、脫脂轉化酶、斑塊、狹窄程度以及內中膜厚度共計9個檢查指標以及診斷結果標簽,經輸入變量處理后,均包含兩次時間窗口為12個月左右的非稀疏數據。模型訓練中,對該數據劃分為80%訓練集和20%測試集。
3.2 數據歸一化處理
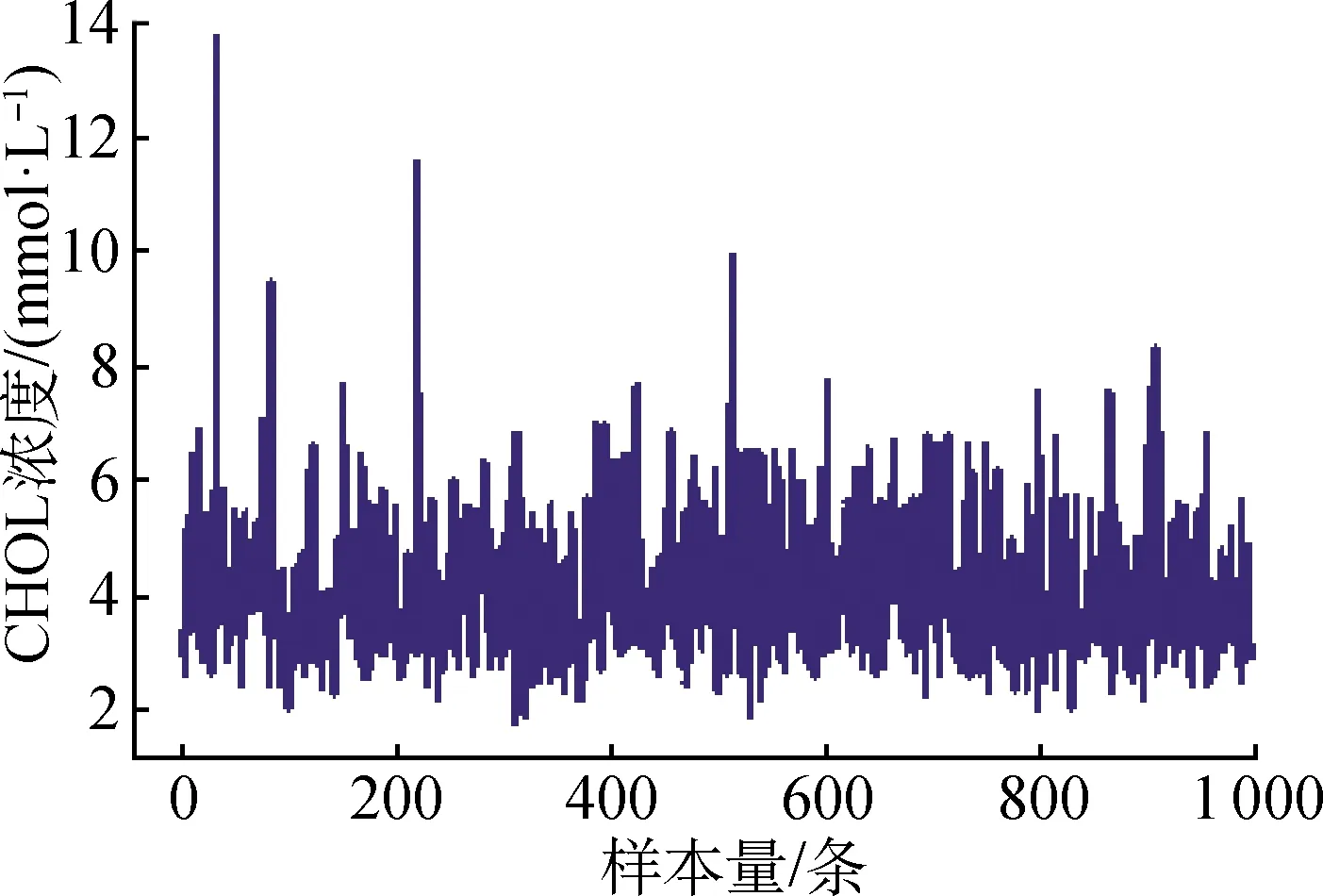
試驗中,對所有輸入樣本數值均通過歸一化處理方式壓縮到[0, 1]。以選取1 000條CHOL濃度樣本數據在歸一化處理前后的特征比較為例。樣本CHOL濃度歸一化處理前后的結果如圖4所示。
(a) 處理前
(b) 處理后
由圖4可知,經數據轉換,CHOL由[0, 14]被壓縮到[0, 1],并且保持原始數據的特征。
3.3 模型訓練過程
試驗中將加載預處理后當前檢查數據與回歸預測數據作為模型的數據集輸入,具體模型訓練過程如下:
(1) 輸入2×9×1313大小的訓練集樣本,經預處理轉化為(None, 2, 13)形狀數據,即步長為2,維度為13,批大小隨機的數據輸入。
(2) 隨機初始化網絡參數,設置dropout=0.9, learning_rate=0.100, training_step=500。
(3) 訓練數據經過雙向LSTM學習后輸出(None, 2, 32)的特征向量,經連接由注意力層對時序狀態的加權,輸出(None, 2)的上下文向量,最終softmax輸出對缺血性腦卒中疾病是否發生的概率值。
(4) 將輸出的預測值與真實標簽計算交叉熵損失,網絡中權重參數通過Adam優化器按照設置學習速率計算誤差損失梯度反向優化更新。
(5) 按照訓練步數,不斷重復模型訓練(1)~(4)過程。
訓練過程中,采用控制變量法,分別對參數dropout、 learning_rate、 training_steps進行設值,其中learning_rate按0.100、 0.010、 0.001遞減形式、dropout按步長為0.1改變、training_step按500步長的原則進行模型訓練效果的比較。最終確定learning_rate=0.001, dropout=0.5, training_step=2 000時,模型訓練準確度達最優。
3.4 結果分析
采用準確度(AAccuracy)、靈敏度(SSensitivity)、特異度(SSpecificity)、陽性預測率(PPPV)、陰性預測率(NNPV)及F1_score值評估標準FF1_score,衡量模型對缺血性腦卒中疾病診斷能力,計算方法如式(25)~(30)所示。
(25)
(26)
(27)
(28)
(29)
(30)
式中:TTP表示真實為缺血性腦卒中患者且被正確預測為缺血性腦卒中患者的數量;TFP表示真實為非缺血性腦卒中患者但被錯誤預測為缺血性腦卒中患者的數量;TFN表示真實為缺血性腦卒中患者但被錯誤預測為非缺血性腦卒中患者的數量;TTN表示真實為非缺血性腦卒中患者但被正確預測為缺血性腦卒中患者的數量。為獲得年卒中風險最優預測效果,在不同條件下進行試驗結果對比。受數據正負樣本不平衡問題影響,試驗采用SMOTE(synthetic minority oversampling technique)過采樣進行正負樣本的平衡。該方法一方面解決了樣本不平衡所帶來的分類預測性能差的問題,另一方面擴充了數據集中樣本特征的多樣性。SMOTE過采樣前后試驗結果如表1所示。

表1 SMOTE過采樣前后試驗結果Table 1 Experimental results before and after SMOTE oversampling %
由表1可知:SMOTE過采樣后預測結果比SMOTE過采樣前預測結果準確率高;受正負樣本不平衡的影響,SMOTE過采樣前,模型靈敏度較特異度結果低10%以上。這表示模型更多學習了負樣本非缺血性腦卒中特征信息,因此對患者缺血性腦卒中患者確診的遺漏情況較高;同理陽性預測率比陰性預測率低,這樣模型在預測時會誤判患者為缺血性腦卒中的診斷結果。當對數據采用SMOTE算法處理后,正負樣本的試驗結果明顯提升且達到平衡的效果。
為測試不同模型訓練擬合的效果,試驗在LSTM、 LSTM-Attention、 BiLSTM以及BiLSTM-Attention等4種模型下進行預測結果的對比,試驗結果如表2所示。

表2 不同模型下的試驗預測準確率對比Table 2 Comparison of experimental prediction accuracy under different models %
由表2可知,4個模型預測總體準確率均達80%以上,對正負樣本預測性能總體保持平衡。從橫向結果對比看,單獨的BiLSTM模型比LSTM模型在時序特征數據集的學習能力表現稍降低。這說明該模型結構對于本試驗數據集相對復雜,性能上有所降低,但在增加注意力機制后,預測的準確度明顯提升。此外,這也表示各時序特征分配了相應注意力權重值,其中各模型靈敏度差異較小,對正確判定缺血性腦卒中的能力無明顯差異,但在非缺血性腦卒中診斷中,無注意力機制的模型遺漏情況較明顯。從縱向結果對比看,靈敏度對比特異度以及陽性預測率和陰性預測率而言,其存在較小的差異。這說明過采樣中的正樣本存在與負樣本界限模糊的情況,使得模型對其學習存在差異。在召回率和準確度上,由于在本試驗數據中融合了注意力機制的BiLSTM模型,因此結果較好,總體性能具有一定優勢,有一定輔助意義。
4 結 語
根據缺血性腦卒中疾病發生發展及數據特征,提出BiLSTM-Attention模型對缺血性腦卒中的年卒中風險發生進行預測。通過當前樣本性別、年齡、高血壓史、CHOL、 LPA、 CRP以及超聲斑塊等指標對其未來時刻CHOL、 LPA、 CRP指標變化的預測,使指標連接當前檢查指標形成帶有時間序列病歷數據,實現基于BiLSTM的缺血性腦卒中的年卒中風險預測。同時融合Attention機制對關鍵特征加權,采用SMOTE對數據平衡處理,提升模型預測準確性,因此,在智慧醫療缺血性腦卒中的年卒中發展預測等方面具有良好的應用價值。由于試驗數據為某醫院真實數據,存在數據清洗不干凈、數據觀察窗口較短等不足,結果存在一定誤差,未來希望針對該方面準確性開展進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
