基于PLS-MI組合的天牛須搜索BP神經網絡模型對汽油辛烷值的預測性能
2021-09-15 00:46:40石翠翠劉媛華
石油煉制與化工 2021年9期
石翠翠,劉媛華
(上海理工大學管理學院,上海 200093)
目前,中國石化下屬煉油廠的催化裂化汽油脫硫主要采用S Zorb工藝[1]。由于S Zorb工藝裝置非常復雜,因而影響精制汽油研究法辛烷值(RON)的特征變量間存在高度非線性和相互強耦聯的關系。傳統關聯分析和機理模型對高維度數據集的分析效果不理想,會造成催化裂化汽油精制過程的參數優化不及時,從而導致汽油產品辛烷值損失增大。因此,在對催化裂化汽油進行精制處理時,如何從S Zorb裝置的操作條件、原料性質、待生吸附劑性質與再生吸附劑性質等方面精確預測汽油產品的辛烷值并進行影響因素分析,成為降低汽油辛烷值損失的難點問題。
隨著汽油辛烷值數據不斷向非線性、多模態等復雜系統方向發展,中國石化企業實驗室信息管理系統(LIMS)獲取的數據集轉向非正態分布[2-3],導致基于傳統特征變量選擇方法模型的預測效果變差。因此,如何有效剔除冗余特征變量,建立新的特征變量選擇方法是提高汽油辛烷值模型預測精度的關鍵[4]。為此,很多學者進行了有益的探索。Albahri[5]利用基團貢獻法預測汽油的RON和馬達法辛烷值(MON),發現基團貢獻法只考慮基團之間的線性組合,其預測模型的穩定性差。Saldana等[6]研究發現定量結構性質關系(QSPR)模型在預測燃料十六烷值時的性能優于其他模型。Mendes[7]和Bao Xin等[8]發現采用偏最小二乘回歸法預測汽油RON具有較好的穩定性和預測精度。從上述研究結果可知,由于變量因子與汽油辛烷值間的函數關系非常復雜,一些學者把智能優化算法與BP神經網絡模型組合應用于汽油辛烷值的預測。Sadighi等[9]采用混合人工神經網絡(BPNN)和遺傳算法(GA)對汽油RON進行預測,提高了預測模型的穩定性和精確性。Wang Shutao等[10]用天牛須搜索(BAS)優化BP神經網絡(BASBP)來預測汽油辛烷值,發現BASBP模型在訓練中具有較高穩定性和收斂速率。
天牛須搜索算法雖然優于其他算法,但在提高模型的預測精確度上仍有較大空間。本研究以催化裂化汽油精制脫硫裝置歷史數據集為基礎,提出了一種基于偏最小二乘法(PLS)和互信息(MI)組合的改進天牛須搜索算法(RSBAS)優化BP神經網絡的模型(PLS-MI-RSBASBP)。該模型采用PLS和MI的組合降維法選取與汽油辛烷值強相關且弱冗余的特征變量,并用改進的天牛須搜索算法優化BP神經網絡。在此基礎上,用S Zorb工藝裝置數據集對該模型進行多次訓練與測試,得到最優的PLS-MI-RSBASBP模型;進而,采用該模型對精制汽油RON進行預測,為控制汽油辛烷值的關鍵變量因子提供依據。
1 模型算法
1.1 基本天牛須搜索算法
天牛須搜索算法(BAS)是根據天牛覓食時的探測行為和搜索行為提出的一種仿生智能算法,具有只需單個個體即可完成尋優的優點,運算量小[11]。天牛在覓食時,利用觸須擺動接收空氣中食物信息的濃度,從而搜索行動方向。在BAS算法中,食物為待優化的目標函數,某時刻(t)天牛質心的位置為自變量(xt),其表達式見式(1)。
(1)
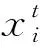
覓食過程中,天牛隨機搜索未知區域,其搜索方向見式(2)。
(2)
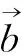
(3)
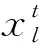
(4)
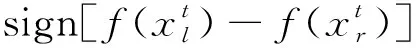
ht=rh×ht -1+0.01
(5)
stept=eta×stept -1
(6)
式中:rh為衰減系數;eta為0~1的衰減系數,一般取0.95。
1.2 改進的天牛須搜索算法
BAS算法雖然在優化性能方面優于其他部分算法,但收斂速率小、預測精度低、易陷入局部最優解,且對參數設置比較敏感,手動參數調節比較麻煩[12]。因此,國內外學者對BAS算法的步長更新[13-15]、位置更新[16]等方面進行了改進。本研究提出了一種隨機更新步長的天牛須搜索算法(RSBAS),對BAS的參數與步長調節方面進行了改進,在自適應步長更新中引入隨機數來提高BAS算法的優化性能。首先,按式(7)對模型的變量維數(d)進行優化。
d=Nin×Nhid+Nout×Nhid+Nhid+Nout
(7)
式中:Nin為輸入層節點個數;Nhid為隱含層節點個數;Nout為輸出層節點個數。
此外,考慮隨機時滯情況,加入部分個體自身經驗信息,并保持個體的多樣性,在步長更新中引入一個隨機數,增強算法的搜索能力。因此,步長更新算法由式(6)變為式(8)。
stept=r1×h0+r2×eta×stept -1
(8)
式中:r1和r2均為0~1的隨機數。
2 組合預測模型的構建方法
2.1 RSBASBP神經網絡模型
在BP神經網絡(BPNN)的結構中,特征變量的權重、閾值,隱藏層的層數和每個層中神經元的數量都會影響其預測性能[17]。BPNN結構的復雜性取決于隱藏層的數量,隱藏層的層數由經驗公式及試錯的方法確定;而輸入層和輸出層的神經元數量由具體問題確定。BPNN的學習速率是固定的,收斂速率較小,訓練時間較長,因而處理大樣本數據時訓練能力差,預測能力也差,且有時會出現“過擬合”現象,即隨著訓練能力的提高,預測能力會下降[18]。因此,采用RSBAS算法優化BP神經網絡的特征變量權重和閾值,提升訓練效率,避免“過擬合”現象,得到RSBASBP神經網絡模型。其優化過程如下:
(1)由式(7)確定RSBAS模型的變量維數;利用MATLAB R2018a進行預測模型的多次調試,選擇出預測模型最優的初始化參數,RSBAS模型中天牛的位置、步長及迭代次數。
(2)用式(4)更新天牛的位置及搜索方向,由式(8)更新搜索步長,計算并比較適應度函數fleft與fright的值,以選擇較好的位置。
(3)判斷適應度函數值是否達到預設精度或迭代次數,若滿足則停止迭代,進入下一步,若不滿足則返回第二步繼續迭代。
(4)結束迭代,跳出循環,得到最優解xbest和fbest,并把此最優解作為BPNN模型特征變量的初始權值和閾值,構建的RSBAS優化BP神經網絡預測模型如圖1所示。
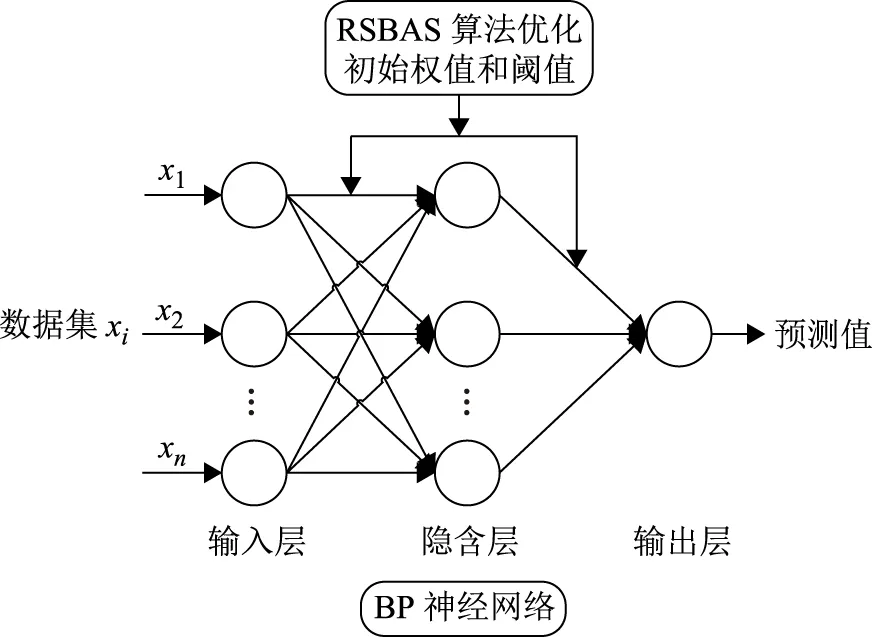
圖1 RSBAS優化BP神經網絡的預測模型框圖
2.2 組合預測模型的構建方法
模型的原始數據集采自中國石化上海高橋石油化工有限公司實時數據庫(霍尼韋爾PHD)及LIMS實驗數據庫。其中,操作變量數據來自于實時數據庫,采集時間為2017年4月至2020年5月,采集樣本數為325個,選取60個特征變量。
采集汽油辛烷值數據時,由于受到主觀和客觀因素的影響,獲取的數據存在異常值,而且部分特征變量與目標變量的相關性較弱。為了消除變量間的共線問題,排除系統噪聲的干擾,降低預測模型的復雜度,因此基于偏最小二乘法(PLS)和互信息(MI)組合方法,構建PLS-MI-RSBASBP組合預測模型。
首先,利用拉伊達(3σ)準則,以置信概率99.7%為標準,以3倍的標準偏差為界限,對數據集中的異常值進行修正處理[19]。
其次,采用偏最小二乘法(PLS)[20-21]計算特征變量xi(i=1,2,…,60)和目標變量y(汽油RON)的投影重要性值(VIP),提取VIP>1的特征變量,得到與y相關性較強的特征變量xi(i=1,2,…,24)數據集;然后,利用互信息(MI)[22-23]分析每個特征變量與目標變量間的非線性關系,計算特征變量xi(i=1,2,…,24)與y的互信息值,選擇其中與RON強相關的特征變量xj(j=1,2,…,19)。
最后,把優選的19個特征變量作為RSBASBP模型的輸入層,分別采用PLS-MI-RSBASBP網絡模型、PLS-MI-BP網絡模型、PLS-MI-GABP網絡模型、PLS-MI-BASBP網絡模型對汽油RON進行預測,并對比分析4種模型的預測結果。
3 基于組合模型的汽油RON預測
3.1 數據預處理
(9)

3.2 特征變量優選
首先,采用偏最小二乘法(PLS)的變量投影重要性(VIP)值分析特征變量xi(i=1,2,…,60)與目標變量y之間的相關性。根據PLS的原理[24]計算出每個特征變量的VIP值,提取VIP>1的相關特征變量,結果如圖2所示。
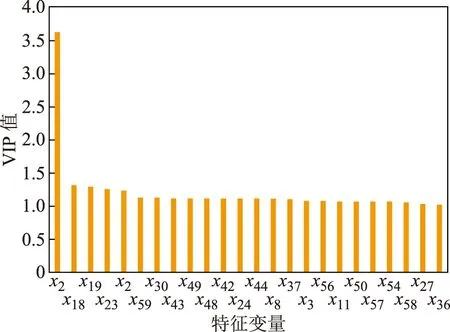
圖2 變量投影重要性VIP值
由圖2可知,采用PLS的VIP值分析篩選雖然剔除了部分冗余的弱相關變量,降低了特征變量集的維數,但在提取的特征變量中仍存在著弱相關變量,可解釋性較弱。采用互信息(MI)算法選擇特征變量,會在保留強相關特征的同時剔除冗余特征,但存在過度剔除現象,導致有用數據丟失。在采用PLS提取相關性較大特征變量的基礎上,再用MI算法計算選擇特征變量與汽油RON的MI值,可以避免有用信息的丟失,得到與汽油辛烷值相關性強且冗余度低的特征變量。具體優選結果如表1所示。
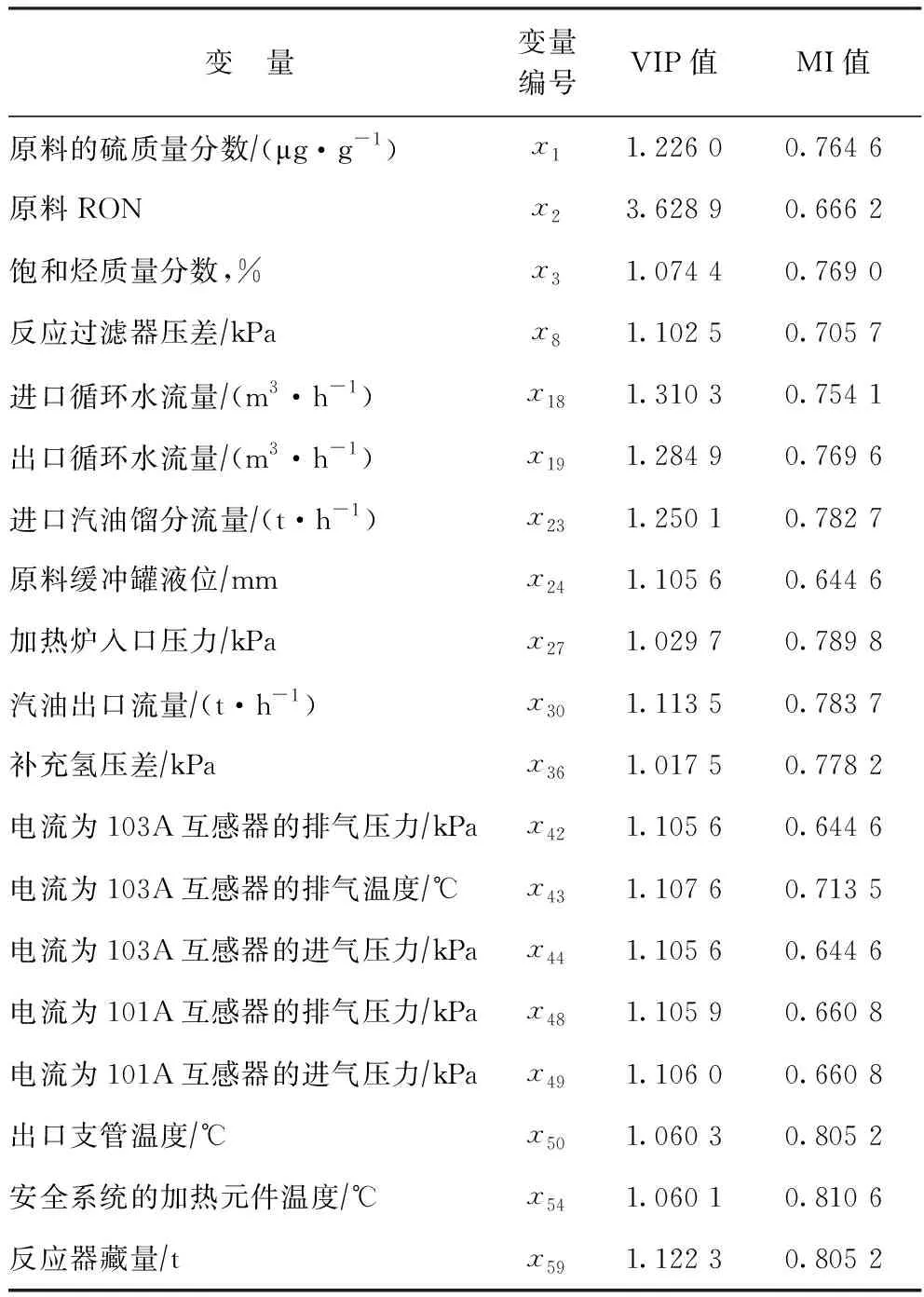
表1 優選的特征變量與汽油RON的VIP值和MI值
3.3 汽油RON的預測
為了考察組合預測模型對汽油RON的預測效果,分別對比用BP,GABP,BASBP,RSBASBP模型直接預測,用PLS特征提取的組合模型PLS-BP,PLS-GABP,PLS-BASBP,PLS-RSBASBP,MI-BP,MI-GABP,MI-BASBP,MI-RSBASBP預測以及用特征提取和特征選擇的組合模型PLS-MI-BP,PLS-MI-GABP,PLS-MI-BASBP,PLS-MI-RSBASBP預測的結果。
在評價RON預測模型的性能時,選取平均絕對誤差(MAE)、均方誤差(MSE)和均方根誤差(RMSE)作為評價指標,其具體計算方法見式(10)~(12)。
(10)
(11)
(12)
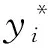
采用模型預測汽油RON時,將325個樣本按4∶1的比例分為訓練集和測試集,即前260組數據為訓練集,后65組數據為測試集。模型直接預測、特征提取預測、特征提取與特征選擇組合預測的特征變量個數分別為60,24,19個,作為模型的輸入層神經元;目標變量為汽油RON,作為輸出層神經元;隱含層的個數Nhid的確定,先由式(13)得到一個預估值,然后通過仿真計算,選取誤差較小結果對應的層數,優化的隱含層個數為5。
(13)
式中:m與n分別為輸入層與輸出層神經元個數;a為1~10之間的常數。
采用BP,GABP,BASBP,RSBASBP模型對汽油辛烷值分別進行直接預測、特征提取預測、特征提取與特征選擇組合預測,結果如圖3所示。由圖3可知,經PLS-MI方法降維處理后,各模型預測值與工業真實值的擬合度最高。
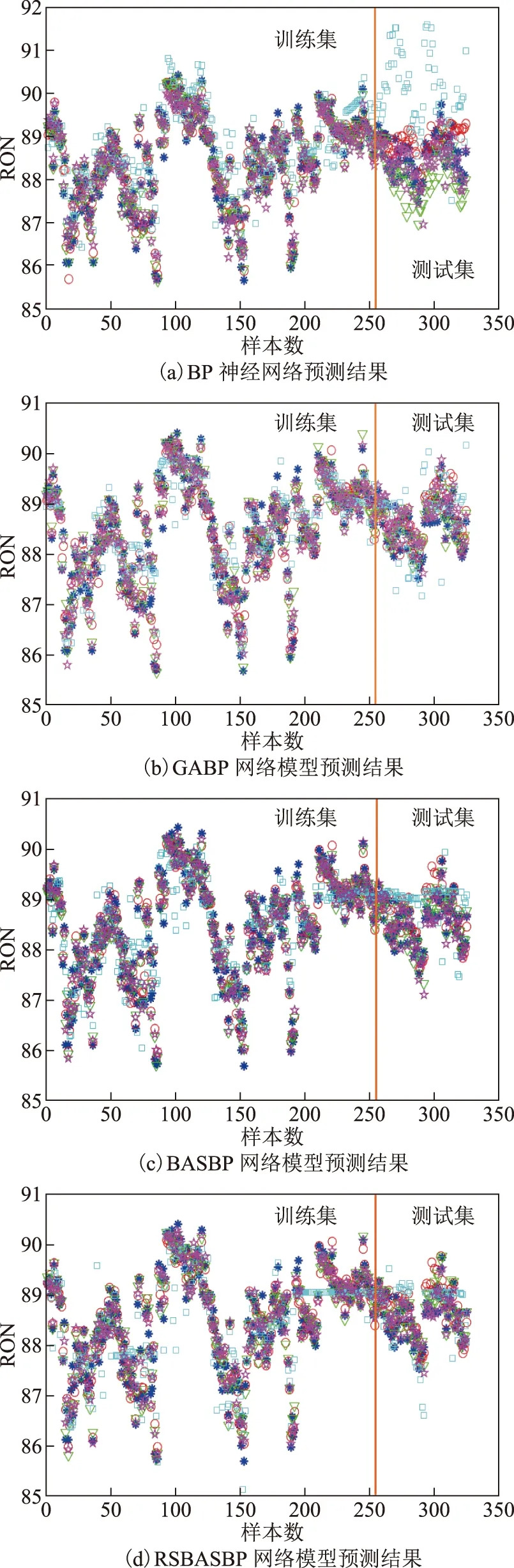
圖3 不同模型在未降維和不同降維方法上的預測結果 —工業裝置RON真實值; ○—RON直接預測值; 特征提取RON預測值; □—MI特征選擇RON預測值; ☆—PLS-MI特征提取+特征選擇RON預測值
不同模型預測值與工業真實值的誤差比較如表2~表5所示。由表2~表5可知:在用PLS特征提取模型預測結果中,PLS-BP模型預測的MAE值低于BP模型,其他PLS特征提取模型的預測結果均明顯優于直接預測結果;而用MI特征選擇模型預測的結果不但沒有提高預測性能,反而大幅降低了模型的預測精度,尤其是MI-BP的MSE和RMSE的值均超過了1,說明只采用MI選擇特征變量,未評估特征子集的整體性能,導致大量有用信息丟失,模型預測性能降低。對比分析可知,PLS較MI方法能更有效提高模型預測性能,但二者都有一定的局限性;采用PLS-MI組合特征提取和特征選擇方法較PLS、MI單一特征變量選取方法效果更好,預測誤差更小、精度更高。
從表2~表5還可以看出,RSBASBP比GABP、BASBP模型的擬合效果更好,說明RSBAS算法可以避免BP神經網絡的“過擬合”現象;對于非線性數據集,應采用RSBASBP模型的進行預測。
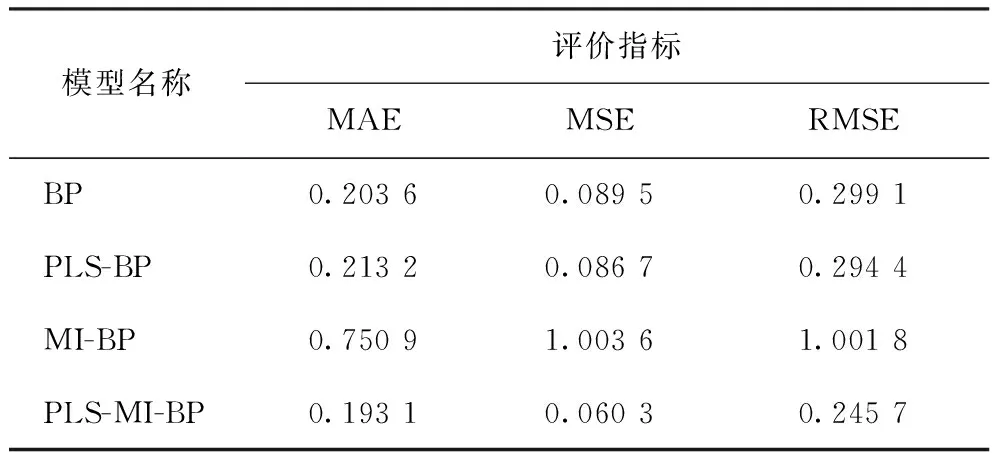
表2 不同特征變量選擇方法的BP神經網絡模型的仿真結果
將PLS-MI-BP,PLS-MI-GABP,PLS-MI-BASBP,PLS-MI-RSBASBP模型對汽油RON預測值和工業真實值進行擬合處理,如圖4所示。從圖4可以看出,4種組合模型都有較好的預測效果,但對一些突出值而言,PLS-MI-RSBASBP模型的擬合效果更好。因此,PLS-MI-RSBASBP模型的預測結果精度最高。

圖4 4種PLS-MI組合模型的預測結果 —工業裝置RON真實值; ☆—PLS-MI特征提取+特征選擇模型RON預測值
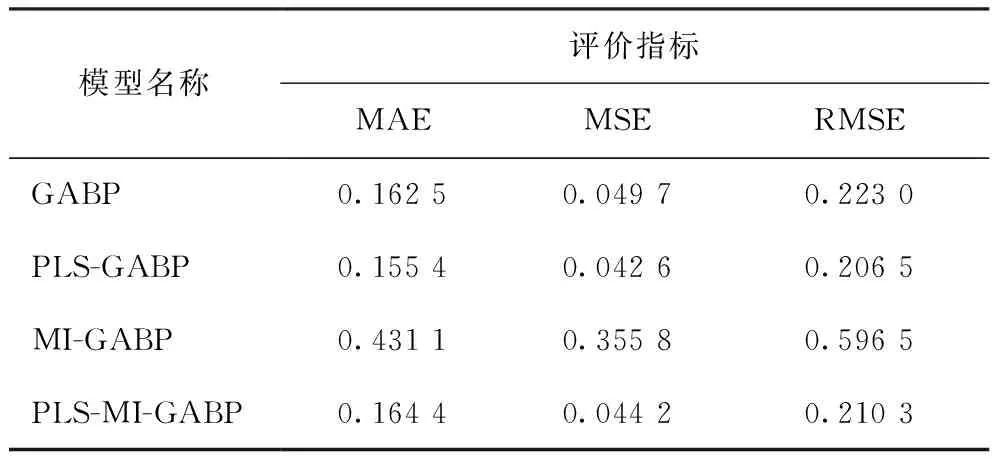
表3 不同特征變量選擇方法的GABP網絡模型的仿真結果
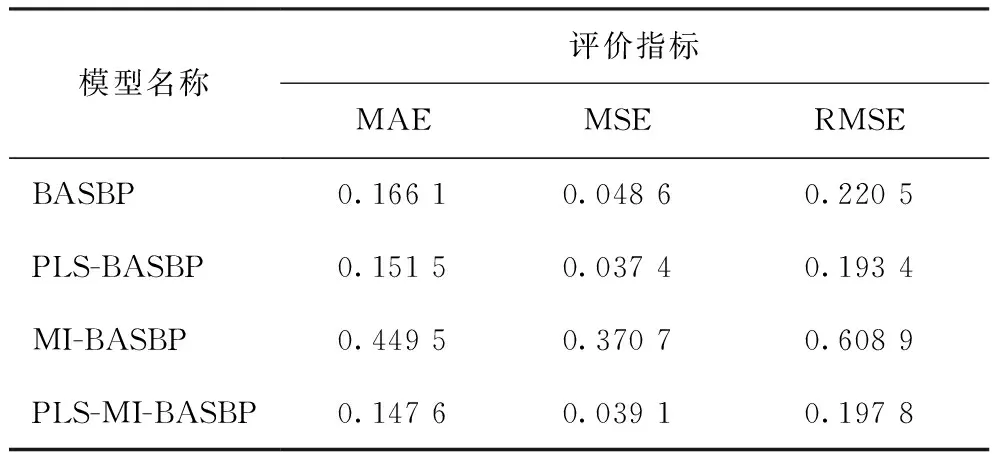
表4 不同特征變量選擇方法的BASBP網絡模型的仿真結果
綜合比較采用PLS-MI組合方法優化后PLS-MI-BP,PLS-MI-GABP,PLS-MI-BASBP,PLS-MI-RSBASBP模型的預測值與工業真實值間的誤差,結果如表6所示。從表6可以看出,4種模型預測結果中,PLS-MI-RSBASBP模型預測值與工業真實值的MAE,MSE,RMSE都是最小的。因此,PLS-MI-RSBASBP模型對汽油RON的預測性能最好。
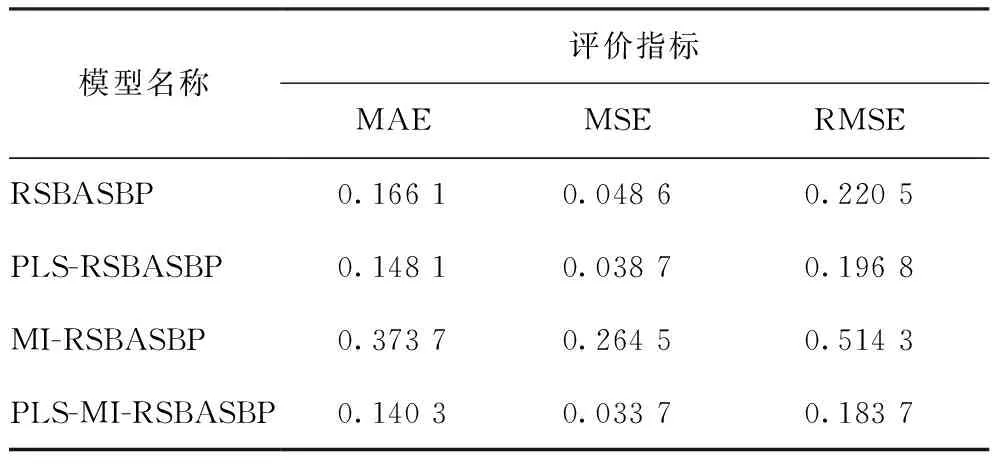
表5 不同特征變量選擇方法的RSBASBP網絡模型的仿真結果
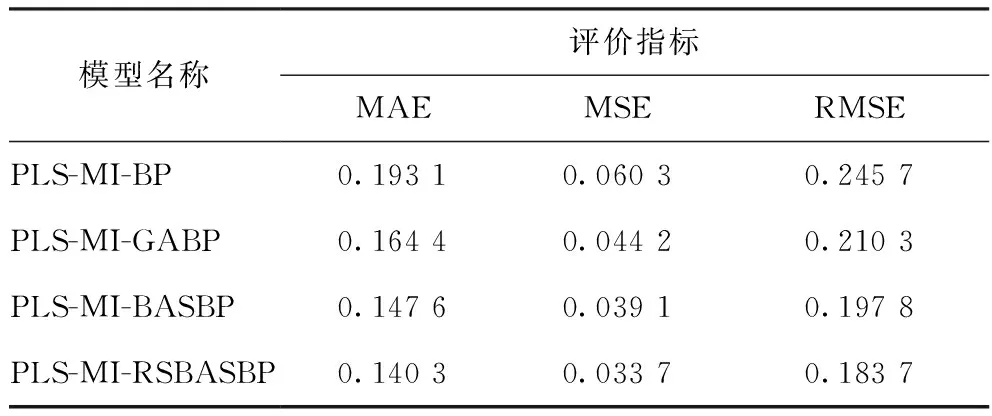
表6 4種PLS-MI組合模型的預測誤差
4 結 論
對于催化裂化汽油精制脫硫S Zorb裝置,基于偏最小二乘法和互信息組合的改進天牛須搜索算法優化BP神經網絡的模型(PLS-MI-RSBASBP)可以大幅降低特征變量維度,對汽油RON的預測性能好。
該模型通過計算特征變量與目標變量投影重要性(VIP)和互信息(MI)值,篩選出與目標變量汽油RON強相關、低冗余的19個變量作為模型的輸入特征變量,PLS-MI結合方法由于單一的PLS和MI方法,有效避免了模擬過程的“過擬合”現象,特征變量降維后的模型預測精確度提高。
與其他預測模型相比,PLS-MI-RABASBP模型對汽油辛烷值的預測值與裝置真實值間的擬合度最高,預測誤差最低,性能最好。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
光學精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
