基于神經(jīng)網(wǎng)絡的汽車側(cè)面造型評價方法
2021-09-19 13:56:06王歡歡初勝男顧經(jīng)緯
圖學學報 2021年4期
王歡歡,初勝男,顧經(jīng)緯
(1.天津科技大學機械工程學院,天津 300222;2.天津市輕工與食品工程機械裝備集成設計與在線監(jiān)控重點實驗室,天津 300222)
隨著汽車技術(shù)的不斷成熟與完善,汽車已經(jīng)不再是技術(shù)導向型產(chǎn)品,更多的是需求導向型產(chǎn)品,汽車造型成為用戶選購時的重要考量點[1-2]。對于汽車這種形態(tài)復雜,且非規(guī)則幾何形狀的產(chǎn)品而言,用戶往往無法清晰地表達自己的視覺感受,受試者通常會使用較為模糊的表達方式。對于經(jīng)驗不足的設計者,很容易出現(xiàn)主觀性的設計誤判,難以獲得準確的造型意象。反向傳播(back propagation,BP)神經(jīng)網(wǎng)絡作為一種非線性運算方法,能夠建立用戶意象與造型設計參數(shù)之間的映射關(guān)系,從而把握產(chǎn)品形態(tài)設計方向[3-7]。通過研究面部表情有助于客觀地評估產(chǎn)品的可用性[8-9],表情識別技術(shù)能夠連續(xù)識別用戶在觀察汽車造型時的感受,分析造型風格與用戶好感度的相關(guān)性,幫助設計師了解用戶對產(chǎn)品造型的需求,更客觀地判斷造型優(yōu)化方向的有效性。因此,本文通過量化意象,并將表情識別技術(shù)運用在方案評價階段,通過識別測試者面部表情的變化和情緒傾向性,獲取用戶情感需求,以數(shù)據(jù)形式得出結(jié)論,來以指導汽車的側(cè)面造型設計。
1 用戶意象與造型特征的關(guān)系模型
1.1 選取樣本和感性意象詞匯
汽車樣本圖像主要來自于“汽車之家”網(wǎng)站上提供的側(cè)面視圖,包括歐洲系、日系、美系和國產(chǎn)品牌4 個大類共80 輛車型,基本涵蓋了目前市場上絕大多數(shù)的中型車的造型。對圖像進行初步處理,利用邊緣檢測算法[10]得到汽車的側(cè)面線框圖,隨后對圖像進行黑白處理,使其成為二值圖像。因車輪屬于附加特征,實驗只針對主要特征和過渡特征,因此去除了車輪。預處理后將相似的車型剔除,保留了62 輛。這些車型涵蓋種類豐富,不同車型之間的造型語言具有一定區(qū)分度,以保證神經(jīng)網(wǎng)絡訓練的有效性,處理后的圖像如圖1 所示。

圖1 處理后的樣本 Fig.1 Processed sample images
對二值圖像進行參數(shù)化處理,為后續(xù)BP 神經(jīng)網(wǎng)絡的造型分類做準備。在平面繪圖軟件中利用關(guān)鍵控制點,繪制樣本車側(cè)面造型的輪廓圖和側(cè)面腰線。外輪廓造型有36 個控制點,分別由C1~C36控制;腰線與外輪廓線分開,且為非閉合線,由9個控制點Q1~Q9 控制,樣本控制點分布如圖2 所示。之后使用網(wǎng)格工具,對樣本造型的關(guān)鍵控制點進行定位。以圖2 為例,最左端C1 點建立Y軸,以最下端C35 點建立X軸,由此建立坐標系以獲取每個控制點的二維坐標,樣本的關(guān)鍵控制點坐標值見表1。

圖2 樣本控制點分布 Fig.2 The distribution of sample control point

表1 關(guān)鍵點坐標值 Table 1 The key point coordinate value of sample
對于語義差分調(diào)查問卷而言,62 款車型數(shù)量太多,過長的問卷時間可導致測試者疲勞,且看到更多相似的圖像后也可能影響或失去評價判斷的標準,因此要選擇差異性大的車型。問卷調(diào)查共選擇被試者30 人,男女比例為1∶1。被試者可自由對62 輛汽車側(cè)面造型進行分類,將主觀認為相似的車型分到一組。把車型的坐標參數(shù)導入SPSS 統(tǒng)計軟件進行聚類分析,以確定汽車造型的分類數(shù)量,并剔除相似度高的圖像樣本,最終分為38 類,并在每類中各選擇一個車型圖像作為進行語義差分調(diào)查問卷的樣本以及BP 神經(jīng)網(wǎng)絡的訓練樣本庫。
在產(chǎn)品外觀設計過程中,設計師主要考慮產(chǎn)品形態(tài)、材質(zhì)、色彩、圖案等。本文意象詞匯的選擇結(jié)合了汽車產(chǎn)品本身的特點,從形態(tài)、配色、材質(zhì)、比例、裝飾5 個要素出發(fā)來表達汽車造型意象。通過相關(guān)文獻資料、互聯(lián)網(wǎng)新聞等渠道,收集了32 個與汽車側(cè)面造型相關(guān)的意象詞匯見表2。選取的意象詞匯按照這5 個要素進行分類,并經(jīng)過對比和分析,去除冗余詞匯、意義相近的詞匯,以及一些主觀性過強而易于對用戶的情緒產(chǎn)生過多干擾的詞匯。同時,在咨詢了汽車設計方面的專家以及對實驗對象進行問卷調(diào)查后,通過數(shù)據(jù)處理、聚類分析對意象詞匯進行篩選,確立了最終的4 個意象詞匯,即“流線”、“穩(wěn)重”、“大氣”和“優(yōu)雅”。

表2 初選意象詞 Table 2 Primary imagery
利用意象詞匯和38 個樣本汽車側(cè)面輪廓造型制作語義差分調(diào)查問卷,以獲取用戶對于不同車輛造型的評價數(shù)據(jù)。將用戶對于造型語言的感知程度分為5 級。以流線為例,5 分為流線程度很高;3 分為一般;1 分為很差。調(diào)查一共收到73 份問卷,其中有效問卷62 份。并計算有效問卷中每種車型的意象評價值的均值。
1.2 網(wǎng)絡模型的訓練與驗證
利用3 層、單隱含層的BP 神經(jīng)網(wǎng)絡,在MATLAB 中搭建造型風格與用戶意象之間的關(guān)系模型。由于BP 神經(jīng)網(wǎng)絡采用的是非線性變換函數(shù)Sigmoid 函數(shù),該函數(shù)只能識別[0,1]的數(shù)據(jù),因此利用mapminmax 函數(shù)對樣本數(shù)據(jù)集進行歸一化(Normalizing)處理。根據(jù)經(jīng)驗公式以及試算,設置隱含層節(jié)點為11,并將網(wǎng)絡最大迭代次數(shù)設置為500,訓練目標設置為0.000 06,學習率設置為0.08。基于此訓練BP 神經(jīng)網(wǎng)絡用于快速判斷汽車側(cè)面造型風格。
為了驗證用戶意象與汽車造型特征的關(guān)系模型的可行性,從剩余的24 個汽車側(cè)面造型中選擇5組數(shù)據(jù),輸入網(wǎng)絡模型中進行驗證,將神經(jīng)網(wǎng)絡得到的預測值與調(diào)查問卷得到的實際值進行比較,結(jié)果見表3,結(jié)果顯示,兩者的誤差值很小。為了驗證該BP 神經(jīng)網(wǎng)絡的有效性,將原本因為車型相似度較高而剔除的10 款車型造型數(shù)據(jù)輸入網(wǎng)絡,并對該10 款車型進行感性工學問卷調(diào)查,分析比較2組數(shù)據(jù)的差異性。使用SPSS 軟件對2 組數(shù)據(jù)的平均值進行T 檢驗,得到顯著性水平p=0.186>0.05,說明該BP 神經(jīng)網(wǎng)絡是有效的。

表3 神經(jīng)網(wǎng)絡預測值誤差 Table 3 Neural network predictive error
1.3 汽車造型風格
本文的最終目的是研究同一車型在迭代優(yōu)化中的造型風格是否符合用戶市場的需求,并研究何種風格的設計趨勢更易獲得市場的喜愛。因此選取了3 種具有代表性的車型,這3 種車型迭代次數(shù)較長,分別以車型A,B 和C 命名,每種車型各12種迭代款式,編號1~12。并將3 種車型每一代的側(cè)面造型特征輸入到用戶意象與汽車造型特征的關(guān)系模型,得到模型反饋的結(jié)果,即車的意象分值曲線如圖3 所示。
圖3 的結(jié)果顯示,隨著不斷迭代,B 車模型反饋的分值最高的意象為優(yōu)雅,穩(wěn)重的分值處于第二位,流線意象在2.5 分附近波動,大氣的意象概率一直保持較低的概率,在近幾代的車型中大氣意象有小幅上升。通過對比原圖可知,這種情況的出現(xiàn)是由于近幾代車型尺寸有所增大及局部比例變化,因此把B 車型作為優(yōu)雅和穩(wěn)重意象的代表。同理,A 車型作為流線和優(yōu)雅的代表;C 車型作為大氣和穩(wěn)重意象的代表。
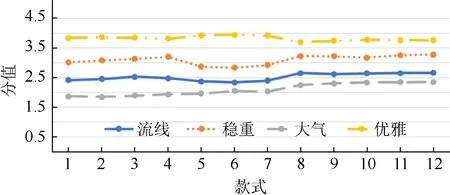
圖3 B 車意象分值曲線 Fig.3 Model B image value curve
2 汽車造型評價系統(tǒng)
2.1 表情識別模型的訓練與驗證
本文表情識別的網(wǎng)絡結(jié)構(gòu)選擇了VGG 結(jié)構(gòu)[11-14],VGG 結(jié)構(gòu)的泛化能力非常好,在不同的圖像數(shù)據(jù)集上都有良好的表現(xiàn)。其采用了AlexNet[15]的思想,網(wǎng)絡架構(gòu)是卷積層-池化層-全連接層的結(jié)構(gòu)。本文中表情識別實驗的重點是需要能夠準確判斷受試者情緒的正負向傾向,對于7 種情感的少量分類,VGG 結(jié)構(gòu)下的VGG13 網(wǎng)絡模型更加輕巧、層數(shù)適中,不易出現(xiàn)冗余,且降低了整個模型的訓練效率。
表情識別模型[16]的初步訓練階段選取了Fer2013,JAFFE 和CK+3 個公開的數(shù)據(jù)庫,并按照9∶1 的比例分為訓練集和測試集,最終訓練集包含32 782 張圖像,測試集包含3 643 張圖像。在訓練網(wǎng)絡模型過程中,通過不斷測試將學習率設置為0.000 1,批大小(Batch-size)設置為32,丟失概率(Dropout)設置為0.7。為了方便數(shù)據(jù)和標簽的統(tǒng)一讀取,將3 種數(shù)據(jù)庫的圖像都處理為CK+圖像的形式,并分為高興(Happy)、憤怒(Angry)、厭惡(Disgust)、悲傷(Sad)、恐懼(Fear)、驚訝(Surprise)和平靜(Neutral)7 類。實驗采用在每個epoch 后評估測試集的準確率,當準確率提高時,存儲模型當前的權(quán)重。在多個epoch 后,得到對測試集識別準確率最高的結(jié)果,首次訓練后模型對各數(shù)據(jù)庫識別準確率如圖4 所示。橫軸分別代表模型對JAFFE 原數(shù)據(jù)集、JAFFE 數(shù)據(jù)集中人的面部區(qū)域(說明能從圖像中提取有效的面部信息,不會因為圖像中人臉的面積大小影響測試的結(jié)果,證明模型的魯棒性)、Fer2013 數(shù)據(jù)集及CK+數(shù)據(jù)集的識別率。
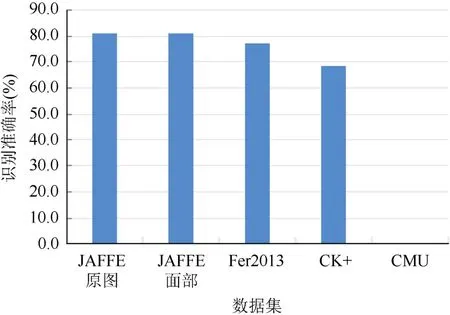
圖4 首次訓練后的識別準確率 Fig.4 The recognition accuracy of the first training
為了檢驗該模型對于非數(shù)據(jù)庫中圖像的識別準確率,采用了由卡內(nèi)基梅隆大學采集的The CMU Multi-PIE Face 數(shù)據(jù)庫(CMU),將CMU 數(shù)據(jù)庫中6 152 張標記的圖像輸入模型,并用圖像增強的方法來提高模型的準確率和魯棒性,最終訓練后模型對各數(shù)據(jù)集的準確率如圖5 所示。
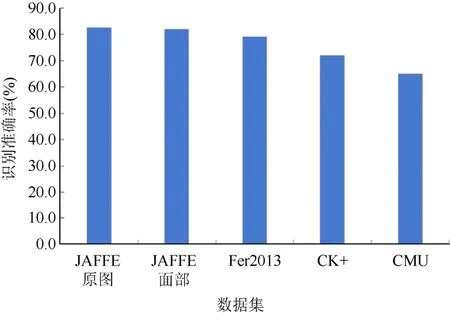
圖5 模型改進后的識別準確率 Fig.5 The recognition accuracy after model improvement
與此同時,查看CMU 數(shù)據(jù)庫識別各表情分類的準確率如圖6 所示,發(fā)現(xiàn)并不是所有表情的識別率都高。對于高興、驚訝和平靜這3 種表情識別準確率較高,而其余的表情識別率較低。由于之后的實驗只需要研究用戶情緒的正負向傾向,憤怒、厭惡、恐懼和悲傷都屬于偏負向的情緒,雖然這4 種表情之間識別率存在不均衡的問題,但不會對實驗準確性造成過大的影響。經(jīng)過訓練和改進,該神經(jīng)網(wǎng)絡綜合準確率可達76%以上,能夠有效地區(qū)分測試圖像中人臉情緒的正負向傾向,滿足了之后實驗和評價體系建立的要求。

圖6 CMU 數(shù)據(jù)庫各表情識別正確率 Fig.6 The recognition accuracy of each expression in CMU
2.2 實驗
2.2.1 實驗過程
36 名受試者參加表情識別實驗,圖像采集所采用的設備為工業(yè)相機,配套的軟件為官方提供的“MV Viewer”。在正式實驗之前,通過預實驗剔除因環(huán)境、眼鏡反光等因素造成的表情識別準確率不佳的受試者。首先使用被標記的表情誘導圖像識別受試者表情并將這些表情的原始圖像輸入到預實驗程序中,運行后自動顯示識別結(jié)果,識別后在圖像上標定情緒標簽如圖7 所示,若識別表情的準確率達到80%以上,則受試者通過預實驗。實驗最終剔除了7 名受試者,29 名(男18 名,女11 名)參與了實驗。

圖7 預實驗識別結(jié)果 Fig.7 Pre-experimental identification result
在正式實驗中,每秒采集圖像20 幀,將圖像保存為表情識別模型可讀取的圖像格式。并通過幻燈片的形式將A,B 和C 3 款車的側(cè)面造型按汽車發(fā)布的時間順序展示給受試者,每幅圖像在屏幕上停留10 s,同一款車型的12 張圖像放映結(jié)束后,休息1 min,再展示下一組;采集受試者面部圖像的同時同步錄制屏幕上的幻燈片內(nèi)容。并將攝像頭錄制到的連續(xù)圖像與受試者觀看幻燈片的錄像時間軸同步,保證采集到的受試者表情與看到的圖像內(nèi)容在時間上的一致性。
2.2.2 數(shù)據(jù)處理
受試者的表情數(shù)據(jù)用搭建的 VGG13 CNN 表情識別模型進行處理,最后輸出代表7 種表情的預測結(jié)果。
由于只需要分析受試者對于所看到造型的喜好程度,憤怒和恐懼過于極端,在實際觀察一個沒有強烈主觀色彩的中性圖像時,出現(xiàn)這3 種情緒的可能性極低,因此作為誤差將其剔除。對于剩下的5 種表情,將厭惡和悲傷作為負向情緒;將高興作為正向情緒;將平靜認為無情緒波動。對于驚訝這種表情,比較難以直接界定這個表情的正負向情緒,采取該表情出現(xiàn)時其前一張與后一張圖像的表情來界定。這里分2 種情況,若前后2 張圖像的表情識別情緒一致,均為正向、負向或無情緒波動,則認為中間這張驚訝的表情與前后的表情一致;若前后2 張圖像的表情識別情緒不一致,則認為驚訝為用戶的情緒正在發(fā)生轉(zhuǎn)變,為了平滑情緒波動曲線,將這一時間點的情緒判定為無情緒波動。分析整理各個受試者的正負向情緒后,以1 s 為一個單位,每個單位20 個表情數(shù)據(jù),將3 種情緒歸一化處理,然后繪制隨時間變化的用戶群情緒變化曲線圖(B 車為例)如圖8 所示。

圖8 B 車用戶群情緒變化曲線 Fig.8 Model B Users’ emotional change curve
2.3 實驗結(jié)果分析及驗證
對意象分值和情緒傾向性相關(guān)性的分析,在雙側(cè)檢驗,置信度為0.01 上使用SPPS 對雙變量進行了Pearson 相關(guān)系數(shù)分析。結(jié)果顯示,4 個意象詞之間呈現(xiàn)不同程度的負相關(guān)性,“流線”與正向情緒具有顯著性差異,2 變量呈較強正相關(guān)(0.767),“穩(wěn)重”和“優(yōu)雅”與情緒之間呈較低相關(guān)性,則說明這2個造型意象與用戶好感度關(guān)聯(lián)性較低。結(jié)合相關(guān)性分析,從圖8 與圖3 中可以看到,最初用戶對該車表現(xiàn)以平靜為主,情緒傾向性較低,隨著車型的迭代,用戶的好感度逐漸上升。在之前對B 車的造型風格進行預測時,從第五到第七代,這3 款車型正好處在一次大的換代階段,整車造型變得十分圓潤,因此穩(wěn)重的意象顯著下跌,與此同時優(yōu)雅的意象有所增加。然而在情緒變化曲線中,造型意象的顯著改變并未對用戶的評價造成顯著的影響,因此初步認為這2 個造型意象與用戶好感度關(guān)聯(lián)性較低。同理,分析A 和C 的意象分值曲線和情緒變化曲線(圖9~10)。隨著A 車型的迭代,流線分值大幅上升,超過了20%,其余的意象得分變化不大。與之對應的情緒變化曲線顯示,正向情緒也取得了大幅上升,負向情緒大幅下降;C 車型的4 種意象,分值均有不同程度的提高。從第七代車型開始,流線的得分開始大幅增加。對應的情緒變化曲線可以看出,在第七代車型,負向情緒就有了大幅下降,從第八代車型開始,用戶對于C 車型基本已經(jīng)沒有負向情緒。

圖9 A 車的意象分值曲線和情緒變化曲線 ((a)意象分值曲線;(b)情緒變化曲線) Fig.9 Model A image value curve and emotional change curve ((a) Image value curve;(b) Emotional change curve)
通過對3 款車型的風格演變進行分析和評價,得出了用戶目前更傾向于流線和大氣造型的結(jié)論,增加“流線”意象的分值能顯著提高用戶好感度。由于本文中的A,B 和C 3 款車型年代跨度長、造型變化多,用戶好感度的提升可能是多種造型意象綜合的結(jié)果。所以本文選取D 車型的3 款車,驗證是否單一流線意象的提升能夠?qū)τ脩艉酶卸绕鸬秸嚓P(guān)作用。
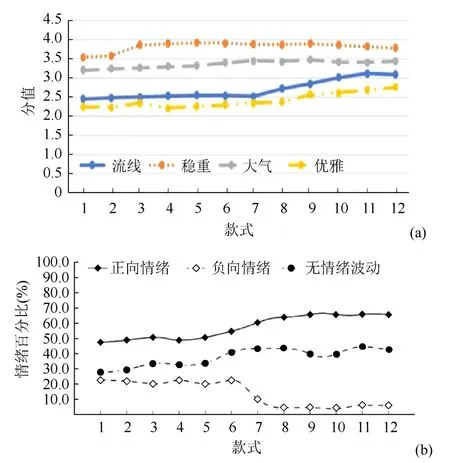
圖10 C 車的意象分值曲線和情緒變化曲線((a)意象分值曲線;(b)情緒變化曲線) Fig.10 Model C image value curve and emotional change curve ((a) Image value curve;(b) Emotional change curve)
選擇的驗證車型D 的迭代次數(shù)較少,每代造型風格都有明顯地改變。最新一代的D-3 側(cè)面造型擁有更流暢的造型比例,整車主要提升了流線的意象,比較適合對流線感這項單一變量進行實驗,因此選取這款車型來驗證評價系統(tǒng)結(jié)論的有效性。首先對D 車側(cè)面外輪廓造型參數(shù)化,隨后將3 輛車的參數(shù)值輸入到預測模型中,得出意象分值曲線。由預測曲線可以看出,D 車的造型意象提升較為單一,主要的提升在“流線”這一造型意象中。同時,結(jié)合用戶的表情識別數(shù)據(jù),驗證了流線造型意象與用戶好感度具有顯著相關(guān)性的結(jié)論,即單一的流線意象提升也能夠提升用戶好感度。新一代D-3 對比前兩代車型,該車在流線意象得分中有一定的提高,與之對應的,用戶對于新款車型的評價也較上兩代車型更好,由此驗證了之前的分析判斷。由此得出,在汽車造型設計優(yōu)化中,提升流線型意象,更符合未來一段時間用戶對于汽車造型語言的需求趨勢。
此外,通過量化意象得到具體的側(cè)面造型,進一步幫助設計師在眾多的“流線型”設計方案中選擇最接近用戶好感度的車型。首先對比D 車型3 款車的關(guān)鍵點坐標,分析得到C6~C17 的關(guān)鍵點在汽車迭代過程中變化較大、具有顯著相關(guān)性。其次以C10,C12 和C14 折點為分界點,在Excel 中根據(jù)散點圖的走勢,選擇擬合結(jié)果的R 平方值最接近于1 的擬合函數(shù)(R 平方值越接近1,擬合效果越好),由此得到C6~C10,C10~C12,C12~C14 和C14~C17的函數(shù)表達式。最后利用MATLAB 軟件計算3 款車對應曲線的曲率,推斷出流線型汽車大致的曲率范圍見表4。
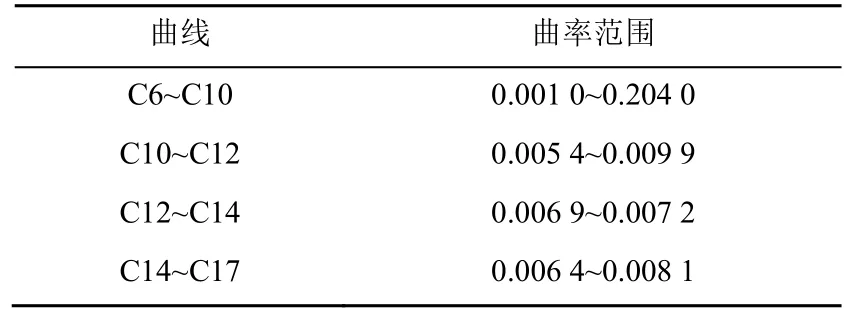
表4 “流線型”汽車曲率范圍 Table 4 The curvature range of“Streamlined”
3 結(jié)束語
本文是通過神經(jīng)網(wǎng)絡的學習能力,搭建用戶意象與造型風格的關(guān)系模型,使計算機獲得識別車輛造型風格的能力,取代傳統(tǒng)的調(diào)查問卷,提高風格評價的效率。其次,使用表情識別技術(shù)來量化地分析產(chǎn)品造型意象和用戶好感度之間的關(guān)系,對造型風格趨勢進行分析和評價,由此獲得滿足用戶情感需求的設計方案。并利用Excel 和MATLAB 軟件快速計算的能力,得到流線型汽車最佳的曲率范圍。此方法的優(yōu)勢在于:
(1) 快速識別汽車造型風格。為了研究造型風格變化趨勢,需要用戶觀察同一款車型的不同年代的改款,這些車型之間變化較小。將汽車圖像二值化后,用戶也難以區(qū)分車款之間的細微差異,容易造成用戶判斷力的缺失。通過用戶意象與造型風格神經(jīng)網(wǎng)絡關(guān)系模型的建立,獲得對輸入車型風格的判斷能力,能夠?qū)τ械脑煨惋L格進行快速識別,而不需要每一次都重復調(diào)查問卷并人工分析。
(2) 識別用戶潛意識情緒。應用表情識別技術(shù)可以發(fā)現(xiàn)設計師容易忽略的被試者的細微情緒變化,可以分析設計中某些細節(jié)對被試者產(chǎn)生的心理作用。幫助設計師更客觀、更理性地了解用戶的真實感受,分析用戶行為,從而設計出更符合用戶心理預期的設計。
(3) 以數(shù)據(jù)形式得到具體意象的側(cè)面造型。通過量化意象,以數(shù)據(jù)形式得出具體結(jié)論,來指導汽車研發(fā)流程中的側(cè)面造型設計,做到以用戶為導向判斷造型優(yōu)化方向的優(yōu)劣,幫助設計師在造型優(yōu)化時有跡可循。
猜你喜歡
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
作文大王·低年級(2016年4期)2016-04-18 00:24:37
商業(yè)評論(2014年6期)2015-02-28 04:44:25
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
