蔗糖產業區域性經濟基礎數據管理模型設計與實現
2021-09-26 03:13:16方欣
甘蔗糖業 2021年4期
關鍵詞:模型
方 欣
(中共陜西省委黨校,陜西西安710061)
0 引言
甘蔗和甜菜是我國重要的糖料作物,其中甘蔗種植面積常年占據我國年糖料面積的85%左右,是我國主要的糖料作物[1]。當前,我國甘蔗種植主要分布于廣西、云南、海南和廣東湛江等省區,云南省是我國第2大甘蔗種植省區和第2大食糖生產省區[2-3]。據云南省工信廳統計數據顯示,2019/20年榨季云南入榨甘蔗1679.81萬t,比上榨季增長3.4%,產糖211.92萬t,比上榨季增長4.3%,產酒精7.65萬t,同比上年增長2倍左右,云南省蔗糖產業全行業實現了扭虧為盈,全省平均食糖銷售價格達到5364元/t,含稅成本5240元,截至2020年10月末實現利潤4.15億元[2]。隨著云南省蔗糖產業的飛速發展,針對產業區域性經濟基礎數據進行統計、計算、分析、決策等的需求越來越多,對數據管理的要求逐漸向智能化轉移。傳統的數據統計、數據管理系統在面對海量廣義數據處理時逐漸暴露出無法處理分散存儲、關鍵詞檢索效率低下以及數據回饋結果精準度不夠等問題,開展新式數據管理模型建設成為蔗糖產業區域性經濟基礎數據管理工作的研究重點。
1 數據管理模型概述
數據管理又稱為數據資產管理,是對數據的組織、編目、定位等,是數據處理的核心環節[4]。20世紀80年代,第一代數據管理模型的雛形——數據倉庫概念首次出現,隨著數據倉庫理念的發展和多種應用軟件落地,數據管理理念逐漸成型。至2004年,國際數據治理協會DGI首次發布了DGI數據管理框架,從該框架模型初步提出了RPP(人員/流程/規則)框架。經過十幾年的發展,數據管理模型逐漸發展成熟,按照組織架構、規則、流程等3大原則構建了面向廣義數據的管理模型(圖1)。
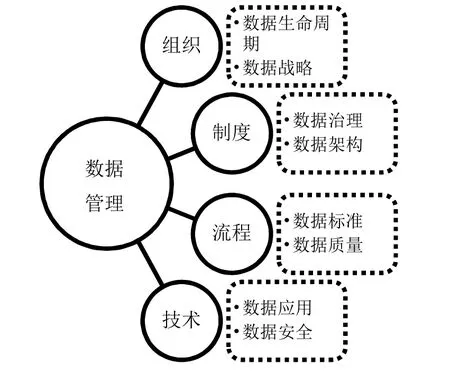
圖1 傳統數據管理模型
2 管理模型設計與實現
2.1 需求分析
2.1.1 數據相關
模型數據相關功能將主要實現:①數據資源對接,模型需實現數據庫與各類型糖類有關公開、非公開數據資源的對接,如與《中國糖業年報》、各市區縣甘蔗產業統計信息、各數據資源類網站以及部分糖企公開信息高效對接;②數據分類與檢索,模型需實現操作人員根據糖業關鍵詞完成數據詞條分類檢索,按照“區域”“類型”“年份”等邏輯進行數據集構建;③數據分析與決策指導,模型需能夠根據省級蔗糖產業統計數據,對云南省內各市區縣蔗糖生產情況進行對比,并根據數據分析結果為各區域蔗糖產業發展提供一定的決策指導[5]。
2.1.2 技術相關
模型技術相關功能將主要考慮未來云南省蔗糖產業發展滿足:①模型的高度兼容性,需要能夠容納和兼容多種格式的數據來源,需要提供多類型單位、部門對蔗糖產業數據的需求,同時還要能夠與原有的農業、蔗糖產業相關系統實現對接;②模型的高拓展性,模型在接入新的數據時,應能充分保證模型內數據在時間領域的前后延伸問題,對于蔗糖產業生產區域、制糖企業數量、規模等的變化應能及時進行字段調整,對于未來需要重新接入的功能、數據處理算法等應能夠及時進行拓展和補充;③模型的安全性,模型應具備多用戶、多形式用戶訪問時的權限認證手段,充分保證蔗糖產業區域性經濟基礎數據的安全性。
2.2 模型框架設計
2.2.1 模型構建要素
根據產業經濟基礎數據能力成熟度評價模型相關理論[6-8],本文認為,數據風險與合規、價值創造等業務目標或成果是云南蔗糖產業區域性經濟基礎數據管理的核心命題,影響這些數據管理目標達成的核心根源在于組織結構和認知度、政策、數據相關責任者3個促成要素,數據質量管理、信息生命周期管理、信息安全和隱私等3個核心要素,數據架構、分類與元數據、審計日志和報告等3個支撐要素(圖2)。

圖2 數據管理模型3要素
2.2.2 數據管理維度
根據數據管理模型3要素,構建蔗糖產業區域性經濟基礎數據管理統一模式,如圖3所示。
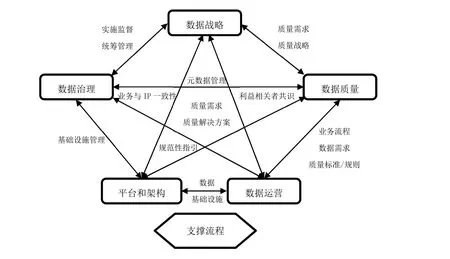
圖3 數據管理維度
數據戰略模塊通過3大促成要素,實現對數據治理、數據質量、平臺和架構以及數據運營等模塊的監督、管理、規范性指引等功能;數據治理模塊則主要基于3大核心要素,實現對平臺和架構、數據運營以及數據質量的基礎設施與管理、業務與IP一致性以及元數據管理;平臺和架構模塊則主要基于模型軟硬件系統,為模型數據治理、數據戰略策劃、數據質量評價以及數據運營等提供基礎設施;數據運營模塊負責具體的蔗糖產業區域性經濟基礎數據增刪改查工作;數據質量模塊則主要負責監督數據管理模型中的數據準確性、及時性以及安全性等。
2.2.3 數據管理模型實現
通過對云南省蔗糖產業區域性經濟基礎數據管理模型需求分析可知,該系統主要將承擔用戶對產業數據的上傳、檢索以及下載等服務,因此系統結構本身并不復雜,系統的搭建將主要針對如何保證數據交換的效率、用戶的低成本接入以及降低系統整體維護升級成本等。因此,本文結合2.2.1、2.2.2等部分分析,將圖3所示數據管理維度進行充分簡化,得到圖4所示基于云南省蔗糖產業區域性經濟基礎數據管理模型需求的數據管理模型。
本文基于傳統數據管理模型,結合我國云南省蔗糖產業區域經濟基礎數據特征,構建針對性較強的蔗糖產業區域性經濟基礎數據管理模型。該數據管理框架更加傾向于對數據管理開展實踐操作,通過①~⑩組件回答了數據管理中why-what-who-when-how等經典問題。①~⑥組件中,組件①回答了某一產業或項目為什么開展或實施數據管理的問題;組建②~⑥則分別從重點區域(目標、評估標準、資金戰略)、數據規則與定義、決策權、職責和控制等角度對數據管理工作的具體規則進行描述;⑦~⑨則將數據管理系統中所涉及的主體人員按照利益相關、數據主管部門以及數據管理具體操作人員等原則進行劃分,對應的是誰參與數據管理等問題;最后的組件⑩則具體設定了數據管理模型中的價值聲明,制定數據管理的實施路徑,數據管理應用于計劃投資的過程以及設計、部署、實施數據管理的具體流程[9-10]。
將圖4與圖1傳統數據管理模型進行融合,得到圖5所示蔗糖產業區域性經濟基礎數據管理核心能力與核心管理過程域。
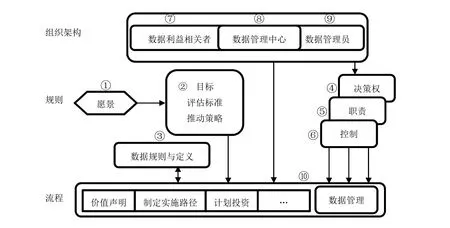
圖4 蔗糖產業區域性經濟基礎數據管理模型
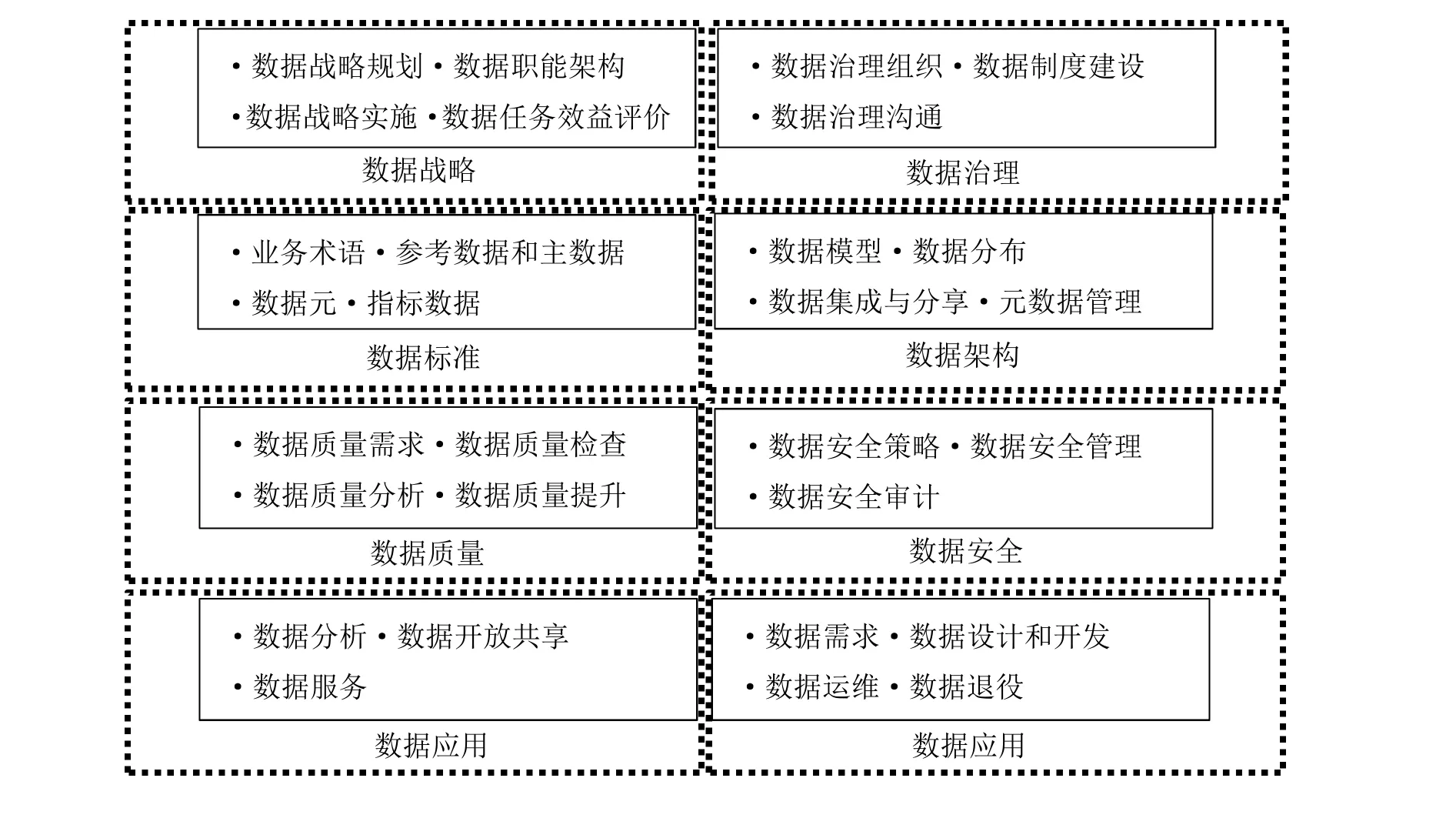
圖5 數據管理核心能力與核心管理過程域
3 結語
本文設計并實現了一種基于蔗糖產業區域性經濟基礎數據的數據管理模型,該模型以傳統數據管理模型中的8大核心能力域為基礎,開發出適用于蔗糖產業的28項核心管理過程域,理論上能夠實現蔗糖產業區域性經濟基礎數據的智能化管理。較為可惜的是,由于本數字模型處于初步開發階段,尚未能實現與云南蔗糖產業的實際對接,因而,系統的數據管理效率、開放共享、數據分析等功能尚未能進行驗證,需在以后的工作中逐漸完善。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
