面向GPU Cache的訪存請求處理技術
2021-09-27 16:15:07李炳超
電腦知識與技術 2021年19期
李炳超

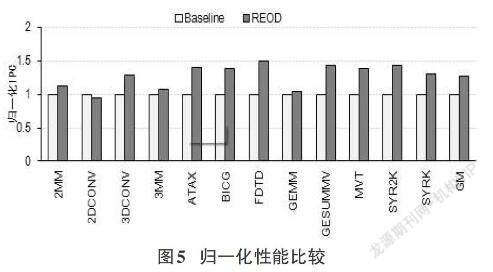
摘要:GPU內部大量線程的同時運行會生成大量的訪存請求,當訪問同一L1 Cache組的訪存請求所涉及的空間超過L1 Cache一組的容量時,由于沒有Cache行可以分配而導致當前訪存請求及后續所有訪存請求發生停頓,影響了GPU的性能。該文設計了一種訪存請求緩沖隊列結構,訪存請求被發送到不同的隊列中,并通過調度策略來選擇不會發生停頓的訪存請求訪問L1 Cache。實驗表明,該方法能夠有效地減少停頓次數,使得GPU的性能平均提高了26%。
關鍵詞:圖形處理器;高速緩沖存儲器;線程;訪存請求;單指令多線程
中圖分類號:TP33? ? ? ?文獻標識碼:A
文章編號:1009-3044(2021)19-0128-03
1引言
近十多年來,GPU受到越來越多的應用程序的青睞。它不僅可以處理高分辨率的3D圖形應用,還能為一些具有數據并行特征的應用程序加速,如圖算法、天氣預報、加密算法、生物信息處理等等。特別是對于深度神經網絡的迅速發展,GPU的硬件支撐起到了積極的推動作用。
GPU由多個可執行相同程序的流多處理器構成,每個流多處理器內部具有數十個用于并行計算的計算核心。另外,為了減少訪存操作的開銷,GPU還為每個流多處理器配備了高帶寬、低延遲的L1 Cache。用戶將應用程序的任務以線程為單位進行細分,進而將多個線程組成一個線程塊。應用程序以線程塊為單位被派遣到各個流多處理器上。每個流多處理器能夠同時運行上千個線程,32個線程會被硬件組織成一個線程束。GPU采用單指令多線程的執行模式,一個線程束內的線程以并行的方式執行同一條指令。另外,為了服務計算核心的并行計算需求,GPU在每個流多處理器內部配備了高帶寬、低延遲的L1 Cache。GPU在執行訪存指令時,線程束內的每個線程都能夠生成一個訪存請求。GPU的讀寫單元對訪問同一數據塊(例如128字節)的訪存請求進行合并來減少訪存請求個數,從而能夠減少訪存指令的處理延遲和存儲系統的擁堵。對于一些具有不規則數據結構的應用程序,線程束生成的訪存請求并不能被讀寫單元全部合并,從而導致一條訪存指令產生多個訪存請求,線程束需要串行處理各個訪存請求并且等待所有訪存請求的數據準備就緒才能繼續執行。如果訪存請求在L1 Cache中發生命中,則直接從L1 Cache中獲取數據;如果發生缺失,根據替換策略,L1 Cache需要為當前缺失的訪存請求分配一個Cache行,并向下一級存儲器發送訪存請求來為該Cache行獲取數據。在缺失的數據未取回之前,該Cache行處于“預留”狀態,表示該Cache行已經被占用并且不能被替換。
然而,GPU的L1 Cache需要為流多處理器內部的所有線程服務,過多的訪存請求將會在L1 Cache發生資源競爭[7]。當訪存請求所需的資源全部被占用時,所有的訪存請求都不得不發生停頓,從而影響了GPU的性能。文章對由L1 Cache資源競爭引起停頓進行了具體的分析,設計了一種處理訪存請求的方法REOD。REOD包含一個多緩存隊列結構,并結合相應的調度策略,能夠有效地緩解訪存請求的停頓現象,最終提高GPU的性能。
2訪存請求停頓
由于流多處理器內部能同時運行上千個線程,并且每個線程束又能夠產生多個訪存請求,因此流多處理器內部會存在大量的訪存請求對L1 Cache進行訪問。頻繁的訪問L1 Cache不僅會造成Cache行局部性的丟失,甚至會造成L1 Cache的暫停。圖1描述了造成訪存請求停頓的三種現象:(1)對于采用組相聯映射的Cache架構,訪存請求只能訪問其訪存地址所映射的Cache組。由于大量線程的同時運行,并且每個線程束又能夠產生多個訪存請求,從而導致訪存請求對某一Cache組的集中訪問。若一個Cache組的所有Cache行都已經處于“預留(R)”狀態,則意味著當前Cache組中沒有可以被替換的Cache行,表示該Cache組已滿(例如圖1中的Cache組set-0)。若繼續有訪存請求訪問該組并發生缺失,該訪存請求只能停頓并等待數據返回該Cache組才能繼續被處理。對于這種停頓現象,文章將其命名為“CSF”;(2)若缺失的訪存請求沒有發生CSF,那么缺失信息會暫存在缺失狀態保持寄存器MSHR中。MSHR由多個條目構成,每個條目保存一個Cache行的塊地址,每個條目可容納若干訪問該Cache行的訪存請求。當訪存請求發生缺失時,若MSHR所有的條目都已經被占用或將要訪問的Cache行所容納的訪存請求個數已滿,該訪存請求也會發生停頓,文章將這種停頓現象命名為“MSHRF”;(3)若MSHR能夠保存缺失信息,則訪存請求會被發送到片內互聯網絡的缺失隊列中。如果缺失隊列已滿,則訪存請求依然會發生停頓直到缺失隊列中的一個訪存請求被片內互聯網絡發送出去,文章將這種停頓現象命名為“MQF”。在以上三種情況中,訪存請求發生停頓之后,后續訪問其他未滿Cache組的訪存請求也必須停頓等待,從而造成訪存指令處理延遲的增加,嚴重影響GPU的性能。
文章對一些應用程序運行過程中發生的停頓次數進行了統計并進行了歸一化,如圖2所示。三種停頓現象中,CSF的平均比例為92%,MSHRF的平均比例為1%,MQF的平均比例為7%。因此,訪存請求發生停頓的主要瓶頸是一個訪存請求由于所要訪問的Cache組沒有可分配的Cache行而造成所有的訪存請求都發生停頓。
3 REOD架構
3.1多緩存隊列結構
REOD的主要目標是減少CSF次數,使得訪存請求出現CSF時不會影響后續訪存請求的處理。為此,文章在REOD中設計了一種新的訪存請求緩存隊列結構,并結合訪存請求調度策略,有效地減少訪存請求的停頓現象。如圖3所示,REOD包含若干個容量較小的隊列,每個隊列可與一個(或多個)Cache組對應。線程束的訪存請求在訪問L1 Cache之前,首先要根據訪存請求的訪問地址計算其將要訪問的Cache組索引,然后根據Cache組索引通過隊列選擇器將訪存請求發送到相應的緩存隊列中。訪存請求選擇器在每個周期根據輪詢調度器的調度結果從所有的緩存隊列中選取一個有效的訪存請求發送到L1 Cache進行訪問。若新的訪存請求所對應的緩存隊列已滿,則該訪存請求暫定等待。
