一種融合集成思想的不平衡數(shù)據(jù)分類方法
2021-09-28 11:23:38強冰冰
軟件導刊 2021年9期
強冰冰,尹 紅,王 瑞
(昆明理工大學機電工程學院,云南昆明 650550)
0 引言
在實際生產和生活中,廣泛存在數(shù)據(jù)類分布不均衡現(xiàn)象,單一的傳統(tǒng)分類器,如神經網絡、SVM 等在處理不平衡數(shù)據(jù)時,往往傾向于多數(shù)類,使得少數(shù)類的分類效果較差。而在實際應用場景中,如醫(yī)學診斷[1]、信用卡欺詐檢測[2]等,少數(shù)類的正確分類具有重要意義,因此,國內外學者從數(shù)據(jù)和算法的角度對不平衡數(shù)據(jù)分類進行了研究。
針對不平衡數(shù)據(jù)在數(shù)據(jù)層面的處理,以過采樣和欠采樣方法為代表,通過調節(jié)樣本類別的比例以達到類平衡;在算法層面,其思路是基于現(xiàn)有算法進行改進,使其能夠更好地區(qū)分少數(shù)類,主要有單類學習[3-4]、代價敏感學習[5-6]和集成學習等。
在數(shù)據(jù)層面,過采樣方法是通過增加少數(shù)類的數(shù)量以達到樣本均衡。傳統(tǒng)的隨機過采樣,在合成樣本時具有較大的隨機性和盲目性,容易使模型過擬合,于是Chawla[7]提出SMOTE 過采樣技術,有效降低了過擬合的風險;SMOTE雖然簡單有效,但同時也存在樣本合成質量低、邊界模糊和類分布不均勻問題[8-9]。為了解決上述問題,文獻[10]提出基于K 均值聚類和SMOTE 相結合的K-means SMOTE過采樣方法,提高了樣本合成質量,克服了類分布不均勻問題,但尋找超參數(shù)的最優(yōu)值往往依賴于經驗;文獻[11]基于CNN(Condensed Nearest Neighbor)和Tomek-link,提出了一種改進的過采樣方法,可以較好地檢測出離群點、噪聲和冗余樣本;文獻[12]根據(jù)學習困難程度對少數(shù)類使用加權分布,考慮到少數(shù)類樣本的分布特點,提出自適應的合成少數(shù)類樣本的ADASYN 采樣方法;文獻[13]利用邊界樣本的最近鄰密度剔除噪聲點和確定合成樣本數(shù)量,對SMOTE 方法的新樣本合成規(guī)則進行了優(yōu)化;文獻[14]針對少數(shù)類的分布問題,采用cGAN(conditional Generative Ad?versarial Networks)進行過采樣,這種方法雖然較好地擬合了真實數(shù)據(jù)分布,但是cGAN 具有一定的時間復雜度,并且訓練一個性能較好的cGAN 需要相當?shù)臄?shù)據(jù)量;文獻[15]提出將樣本劃分成3 個區(qū)域:正域、邊界域和負域,分別對邊界域和負域中的小類樣本進行不同的過采樣處理,提出了一種基于三支決策的不平衡數(shù)據(jù)過采樣方法,但時間復雜性較大。
在算法層面,集成學習通過組合多個基分類器提高少數(shù)類樣本識別率。Boosting 算法在每一輪的迭代中,會根據(jù)樣本分布對訓練集進行重新采樣,如果樣本被錯誤分類,權重會增加。在不平衡數(shù)據(jù)集中,少數(shù)類更容易被分錯,在每次迭代時,少數(shù)類的權值會逐漸增加,在一定程度上保證了少數(shù)類能夠被識別。由于Boosting 算法族在識別少數(shù)類上具有優(yōu)勢,因此很多研究者提出了基于Boosting算法族的改進方法以解決不平衡數(shù)據(jù)分類問題。文獻[16]將欠采樣和集成學習相結合,提出了Easy Ensemble 和Balance Cascade;文獻[17]通過對大類中分類困難樣本的權重和標簽進行處理,提出基于AdaBoost 的改進算法,但存在著如何確定閾值和處理權重問題;文獻[18]提出PC?Boost,該算法利用數(shù)據(jù)合成方法添加合成的少數(shù)類以平衡訓練信息;文獻[19]提出多類別不平衡學習算法,利用混合的集成技術充分挖掘被隨機欠采樣方法忽略的潛在有用的大類樣本信息;文獻[20]基于集成學習架構,將欠采樣技術、Real Adaboost、代價敏感權值修正和自適應邊界決策策略相結合,提出自適應的EUSBoost。
綜上所述,過采樣方法雖然能夠在一定程度上解決不平衡數(shù)據(jù)分類問題,但是可能會引入無用的信息和噪聲,導致分類算法效果下降;基于集成學習的boosting 算法族雖然在解決不平衡分類上有著較好效果,但沒有考慮到樣本數(shù)據(jù)分布的先驗信息。針對以上問題,考慮到少數(shù)類樣本較少并結合集成的思想,針對不平衡數(shù)據(jù),本文從數(shù)據(jù)層面和算法層面出發(fā)進行研究,通過改變數(shù)據(jù)分布,使得少數(shù)類和多數(shù)類的邊界更清晰,從而讓算法在少數(shù)類上的表現(xiàn)更好。
1 基于集成思想的不平衡數(shù)據(jù)分類算法
針對不平衡數(shù)據(jù)處理,本文所提出的算法分為3 個階段:數(shù)據(jù)處理階段、基分類器訓練階段和原始算法訓練階段,如圖1 所示。
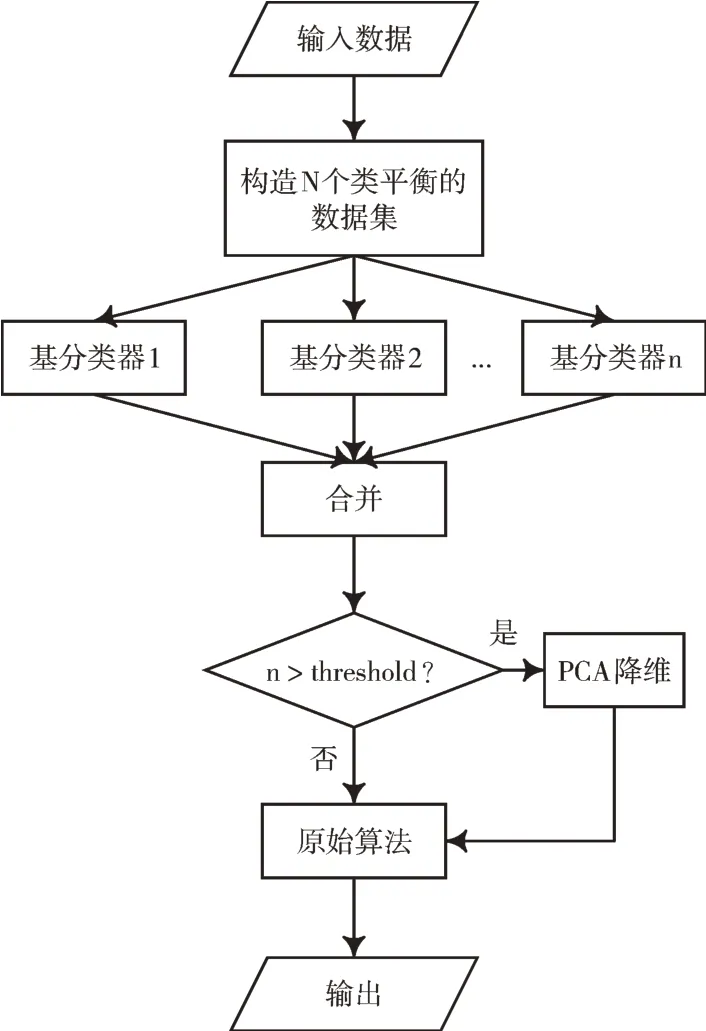
Fig.1 Imbalanced data classification model incorporating ensemble ideas圖1 融合集成思想的不平衡數(shù)據(jù)分類模型
采用過采樣方法合成的樣本并不能夠完全替代真實的樣本,會引入一定的噪聲;而降采樣方法刪除的樣本可能包含有用信息,從而丟失了部分信息。避免過多引入噪聲和丟失信息,在數(shù)據(jù)處理階段利用現(xiàn)有數(shù)據(jù)集和Kmeans SMOTE 合成少量樣本以構造多個類平衡的數(shù)據(jù)集。
相關研究表明,基分類器的差異性能夠提高集成性能[21-22],因此,在基分類器訓練階段從數(shù)據(jù)和算法的角度構造具有差異性的基分類器,以提高集成效果。
通過前兩個階段得到基分類器的輸出后將其合并,為了提高算法運行效率,可以設置閾值ρ,當合并后數(shù)據(jù)的維度大于某個閾值,使用PCA 降維,再將處理后的數(shù)據(jù)作為原始算法輸入。詳細算法流程如圖1 所示。
輸入:樣本D=(xi,yi),i=1,2,…,n,xi是n維特征空間的樣本,yi是類標簽。基學習器L={l1,l2,…,lk},lk為不同種類的基學習器。
輸出:預測結果y_predi,i=1,2,…,n
(1)初始化ρ;
(2)計算少數(shù)類數(shù)量Ns,多數(shù)類數(shù)量Nl;
(3)計算需要合成的樣本數(shù):
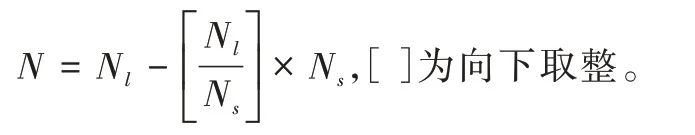
(4)使用K-means 進行聚類,將特征空間劃分為K 個聚類,根據(jù)每個聚類的不平衡度選定過采樣的聚類f。
(5)對于每個選定的聚類,用歐式距離計算每個少數(shù)類樣本點到其他少數(shù)類樣本點的距離,存放到矩陣;將矩陣的所有非對角元素相加,除以非對角元素的數(shù)量得到每個聚類的平均距離averageDistance(f)。
(6)計算每個選定聚類的密度:
density(f)=即少數(shù)類的數(shù)量除以平均距離的m的冪次方,m為特征個數(shù)。
(7)計算每個選定聚類的稀疏因子:
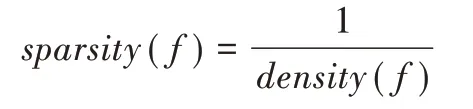
(8)每個聚類的采樣權重為該聚類稀疏因子除以所有聚類稀疏因子之和。根據(jù)需要合成的樣本數(shù)N和采樣權重確定每個聚類合成的樣本數(shù)量,再利用SMOTE 合成樣本,并添加到D中。
(9)D 中少數(shù)類的樣本集合為S,多數(shù)類樣本集合為L。從L中隨機抽取Ns個樣本與S構成類平衡的集合di,i=1,2,…,k,k=
(10)集成k個種類的基學習器,得到基學習器E;
(11)forj=1:k
(12)用dj訓練學習器E 得到輸出fj,k
(13)end for
(14)合并L的輸出得到D″=(fi,k,yi),i=1,2,…,n;
(15)ifk>ρ
(16)使用PCA 將D″降維;
(17)end if
(18)使用D″訓練原始算法得到輸出y_predi。
2 實驗與分析
2.1 評價方法
對于二分類問題,根據(jù)真實值和算法預測值,可以得到混淆矩陣,如表1 所示。
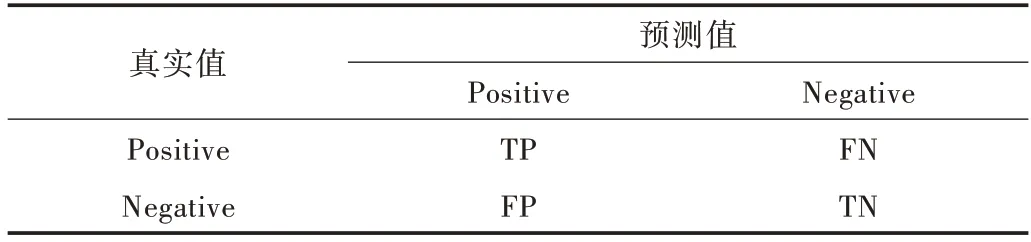
Table 1 Confusion matrix表1 混淆矩陣
為了能夠評價學習器在不平衡數(shù)據(jù)上的性能,本文使用F-measure、G-mean 和AUC 指標評價學習器的表現(xiàn),將少數(shù)類定義為Positive,多數(shù)類定為Negative,計算公式如下:

為了評估算法性能,利用Friedman 檢驗進行統(tǒng)計意義上的比較。Friedman 檢驗是利用秩實現(xiàn)對總體分布是否存在顯著差異的非參數(shù)檢驗方法,步驟如下:
(1)原假設H0:每個算法性能相同;備擇假設H1:至少有兩個算法性能存在差異。
(2)首先使用交叉驗證得到每個算法在每個測試集上的結果;然后在每個數(shù)據(jù)集上根據(jù)測試性能由好到壞進行排序,若相同,則取平均序值。
(3)假設在N個數(shù)據(jù)集上比較k個算法,令ri表示第i個算法的平均序值,則檢驗統(tǒng)計量Fr為:
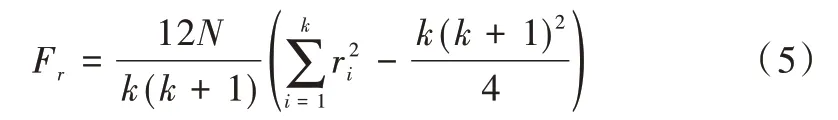
(5)由于原始的Friedman 要求k較大,過于保守,因此通常使用以下公式計算檢驗統(tǒng)計量。
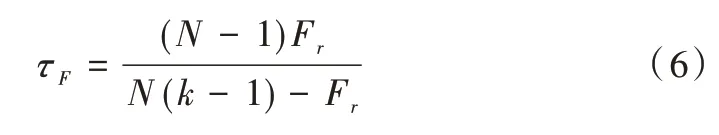
(6)如果原假設H0被拒絕,則需要進行后續(xù)檢驗進一步區(qū)分各算法性能。本文利用Nemenyi 進行后續(xù)檢驗,其臨界值域的計算公式如式(7),其中qα查表可得。
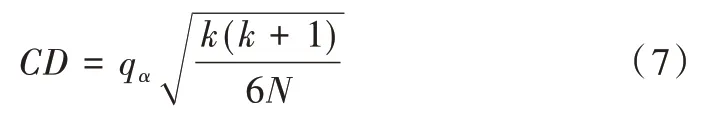
2.2 數(shù)據(jù)集描述
為了驗證本文算法的適用性,按照不平衡度從小到大,選取15 個數(shù)據(jù)集,分別來源于KEEL 和UCI,數(shù)據(jù)集的詳細信息如表2 所示,其中不平衡度由多數(shù)類個數(shù)除以少數(shù)類個數(shù)得到。
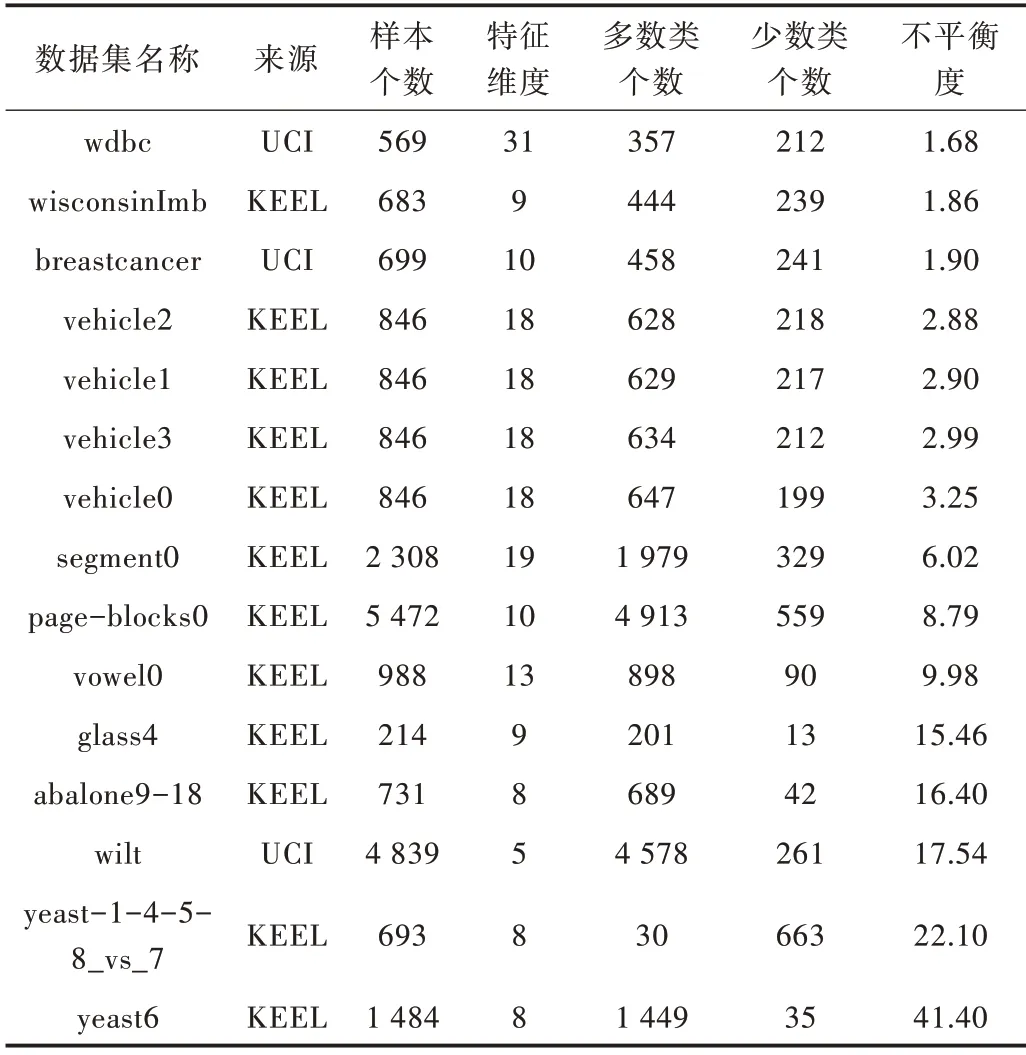
Table 2 Data set description表2 數(shù)據(jù)集描述
2.3 參數(shù)設置
為了驗證本文所提出方法的有效性,選取Adaboost、AdaCost、EUSboost 和Xgboost 進行對比實驗,采取5 折交叉驗證取平均值作為算法表現(xiàn)性能的度量;選擇BP 神經網絡、SVM 和Xgboost 作為本文算法的基分類器。鑒于Boost?ing 的算法在迭代次數(shù)為10 時表現(xiàn)較好[23],本文將Ada?boost 和EUSboost 的迭代次數(shù)設為10。具體算法參數(shù)設置如下:
(1)Adaboost:迭代次數(shù)為10 次,CART 作為弱分類器。
(2)AdaCost:多數(shù)類代價設為0.25,少數(shù)類代價設為1.00。
(3)EUSboost:迭代次數(shù)為10 次,其他參數(shù)為默認參數(shù)。
(4)XGBoost:弱分類器為gbtree,葉子節(jié)點劃分時所需損失函數(shù)減少的最小值為0.1,正則化權重為2,收縮步長為0.1,迭代次數(shù)400,其他參數(shù)為默認值。
2.4 結果分析
本文利用AUC、G-mean 和F-measure 3 個指標作為評價指標,分別比較在使用本文方法前后的性能。為了更簡潔地展示實驗結果,將Adaboost 簡寫為Ada,Adacost 簡寫為Adac,EUSboost 簡寫為EUS,XGBoost 簡寫為Xgb。將本文方法改進后的算法后加上符號+,如Ada+表示使用本文方法改進后的Adaboost 算法,其中加粗表示效果最好。
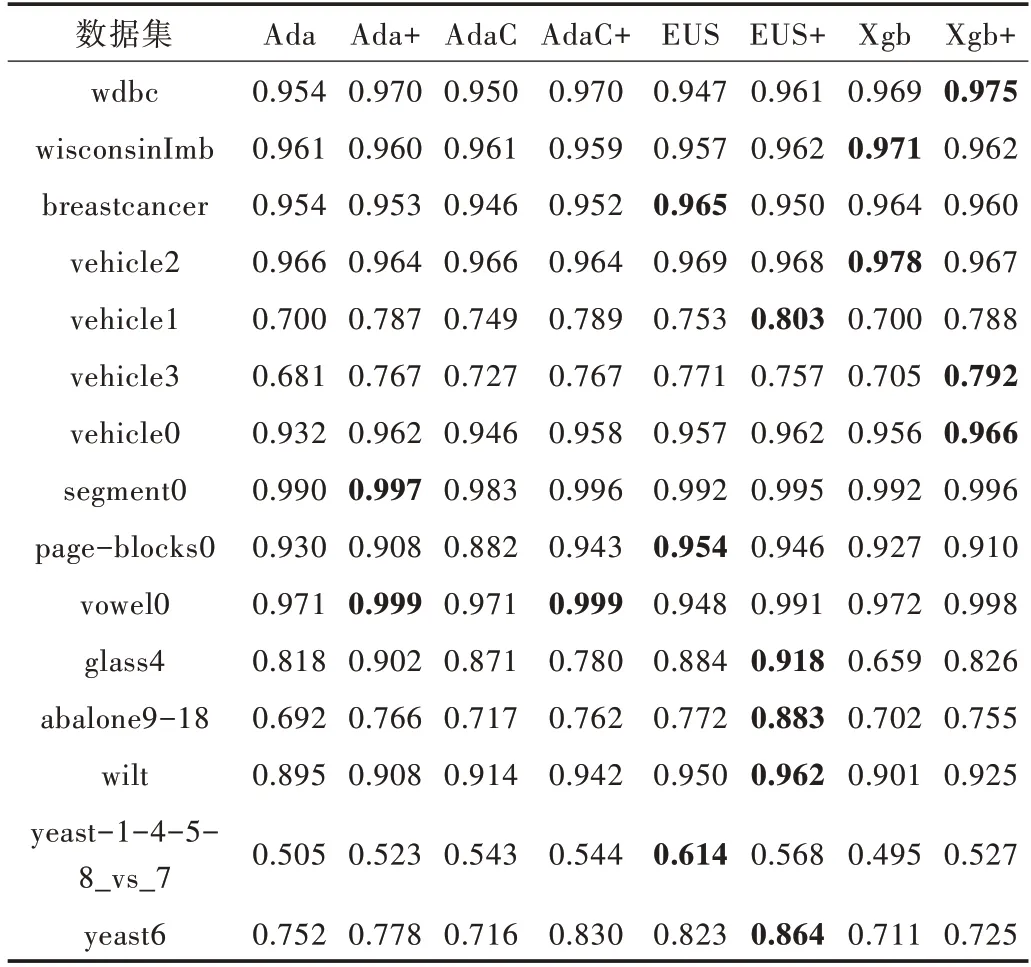
Table 3 Comparison of AUC values of various algorithms表3 各算法的AUC 值比較
通過表3 可以看出,Adaboost、AdaCost、EUSboost 和Xg?boost 在使用本文所提出的方法后,其AUC 值在大部分數(shù)據(jù)集上有了一定提升。在vowel0 上,改進后各算法的AUC 值均接近于1;在glass4 上,Xgboost 的AUC 值上升得最快,為16.7%。
為了更好地評價算法性能,使用Friedman 檢驗對表3各算法的AUC 值進行排序得到表4。
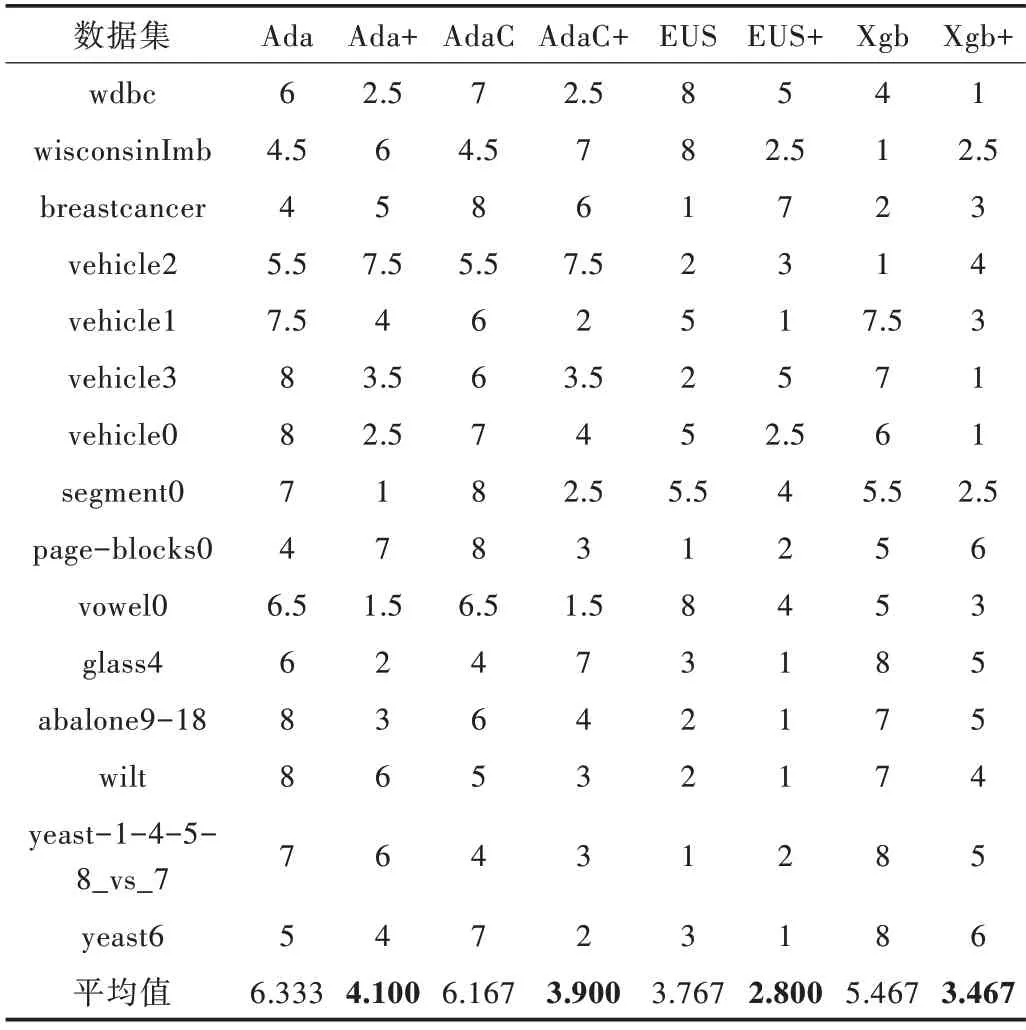
Table 4 Aligned-ranks of algorithms under AUC表4 AUC 下算法的序值
序值越小意味著算法性能越好,從表4 中可以看出,使用本文方法進行改進后,各算法平均序值都小于原始算法。
取顯著性水α 平為0.05,由表4、式(5)和式(6)可得檢驗統(tǒng)計量τF=5.628,查表可知F 檢驗的臨界值為2.104,小于τF,因此各算法性能相同這一假設被拒絕,則意味著各算法性能不相同,因此用Nemenyi 檢驗作進一步區(qū)分。由式(7)可計算得臨界值域CD 為2.711,由臨界值域和表4 可得到檢驗結果,用圖2 表示。
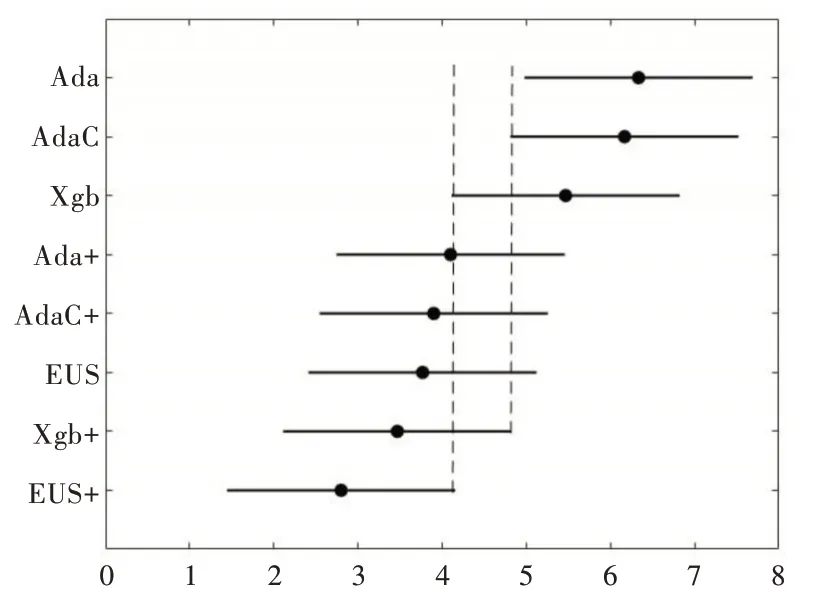
Fig.2 Friedman test chart under AUC圖2 AUC 下Friedman 檢驗 圖
由圖1 可以直觀地看出,經過本文方法改進后,在AUC上EUSboost 的性能優(yōu)于Xgboost,顯著優(yōu)于AdaCost 和Ada?boost;改進后的Xgboost 優(yōu)于AdaCost 和Adaboost。
由表5 可以看出,經過本文方法改進后的算法在大部分數(shù)據(jù)集上G-mean 有了一定提升。在yeast6 上AdaCost 的G-mean 提高了21.9%,在vowel0 上各改進后算法的Gmean 均接近于1,Xgboost 在yeast-1-4-5-8_vs_7 上 由0 提升至16.2%。
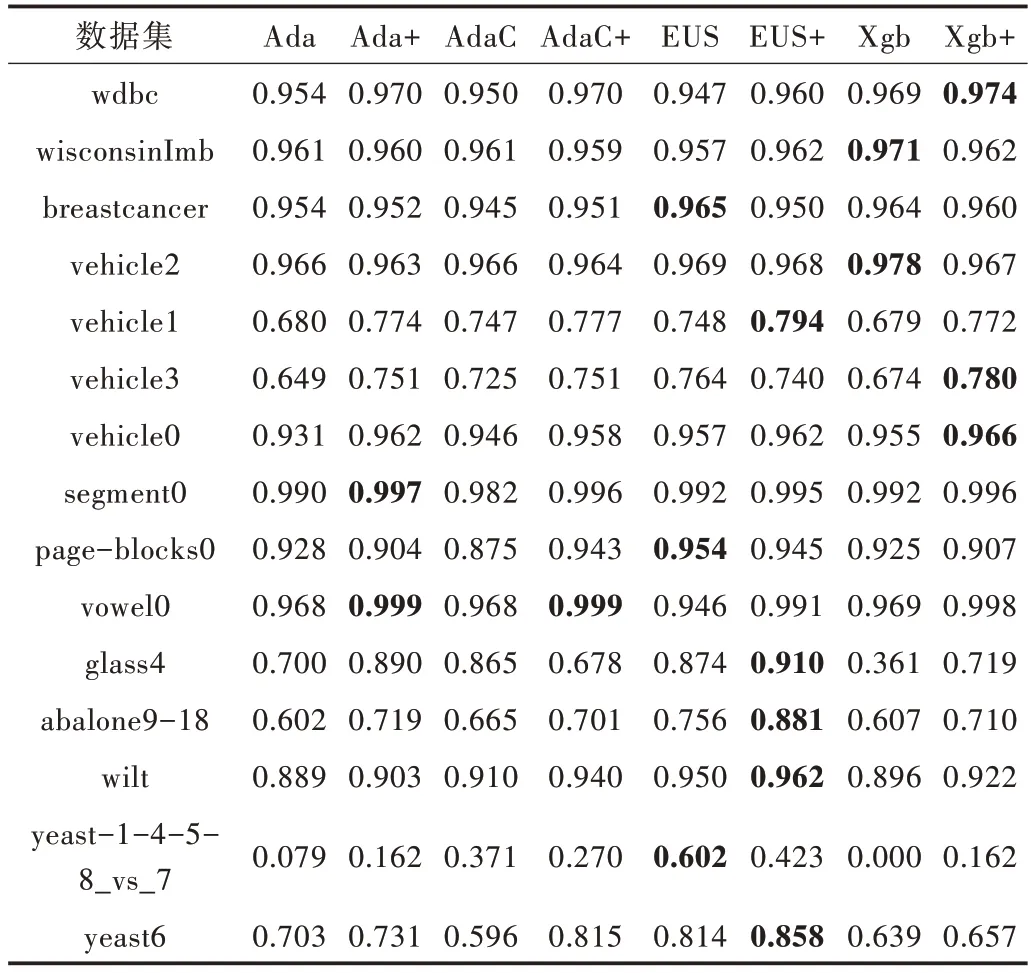
Table 5 Comparison of G-mean values of various algorithms表5 各算法的G-mean 值比較
同上,利用Friedman 檢驗對表5 中算法的G-mean 進行排序可以得到表6。從表6 可以看出,改進后算法的平均序值均小于原始算法。同理可以計算得檢驗統(tǒng)計量τF=5.460,大于F 檢驗的臨界值,因此說明各算法性能不相同,存在差異,進一步使用Nemenyi 檢驗,各算法檢驗結果用圖3 表示。
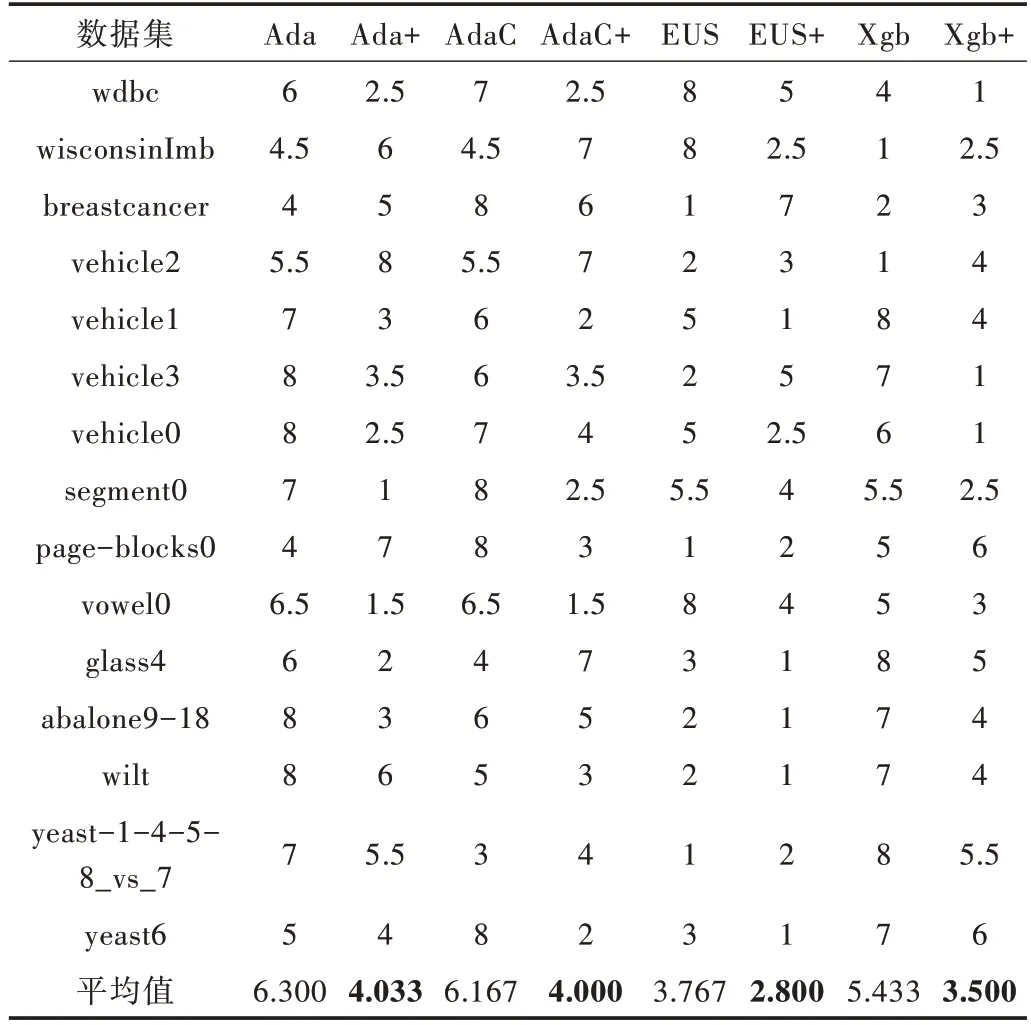
Table 6 Aligned-ranks of algorithms under G-mean表6 G-mean 下算法的序值
由圖3 可以直觀地看出,在G-mean 上改進后的EUS?boost 優(yōu)于Xgboost,顯著優(yōu)于AdaCost 和AdaBoost;改進后的Xgboost 優(yōu)于AdaCost 和AdaBoost。
在F-measure 上,由表7 可以看出,各改進后的算法在大部分數(shù)據(jù)集上均有一定提升。特別是在abalone9-18 上各算法提升較快,其中AdaCost 和EUSboost 提升效果最好,為20%左右。由表8 可知,改進后各算法平均序值均小于原始算法。

Fig.3 Friedman test chart under G-mean圖3 G-mean 下Friedman 檢驗圖
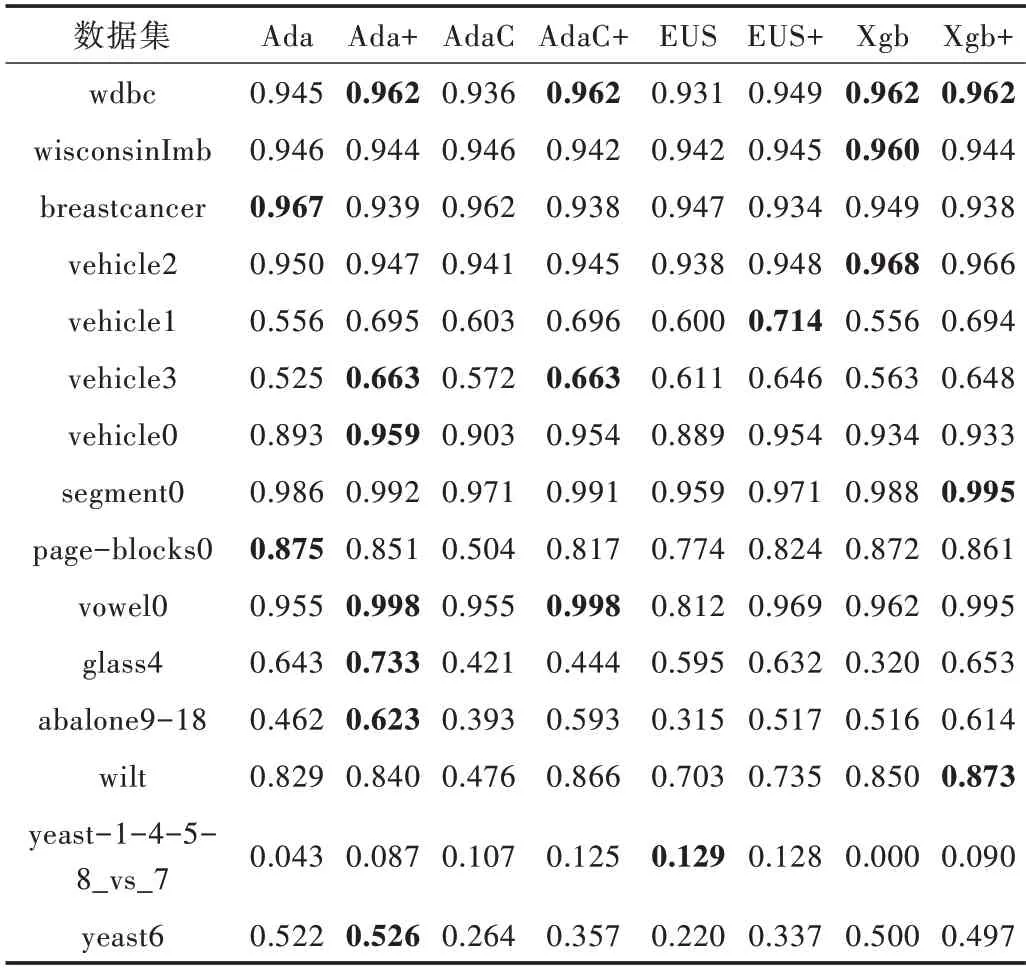
Table 7 Comparison of F-measure values of various algorithms表7 各算法的F-measure 值比較
同理計算可得檢驗統(tǒng)計量τF=4.661,大于F 檢驗的臨界值,因此拒絕各算法性能相同這一假設,然后利用Neme?nyi 后續(xù)檢驗,其檢驗結果用圖4 表示。
由圖4 可知,在F-measure 上,改進后的Adaboos 性能顯著優(yōu)于AdaCost 和EUSboost;改進后的Xgboost 性能略優(yōu)于AdaCost,顯著優(yōu)于EUSboost;改進后的AdaCost 優(yōu)于EU?Sboost。
以上分析說明,本文所提出的方法具有一定的有效性和適用性。以vowel0 數(shù)據(jù)集為例,說明本文方法如何提高算法性能。
利用PCA 對vowel0 進行降維,取前3 個成分,累計貢獻率為90.067;同樣將經過本文方法改進后的vowel0 降成三維,取前3 個成分,累計貢獻率為77.359。將降維后的數(shù)據(jù)繪制成散點圖,其中圖5 為原始數(shù)據(jù)散點圖,圖6 為經過本文方法改進后的數(shù)據(jù)散點圖。為了更加直觀地看出類與類之間的邊界,將圖5 的點沿著X 軸正方向和Z 軸所組成的平面進行投影,將圖6 的點沿著Y 軸正方向和Z 軸所組成的平面進行投影,分別得到圖7 和圖8,從圖8 中直觀地看出類邊界變得更為明顯。雖然經過PCA 降成二維后,失去了部分信息,但從累計貢獻率中可以看出,仍然保留了相當部分的信息,經過本文方法改進后,使得vowel0 的少數(shù)類與多數(shù)類之間的界限更加明顯,從而使得改進后的算法在AUC、G-mean 和F-measure 上均接近于1。
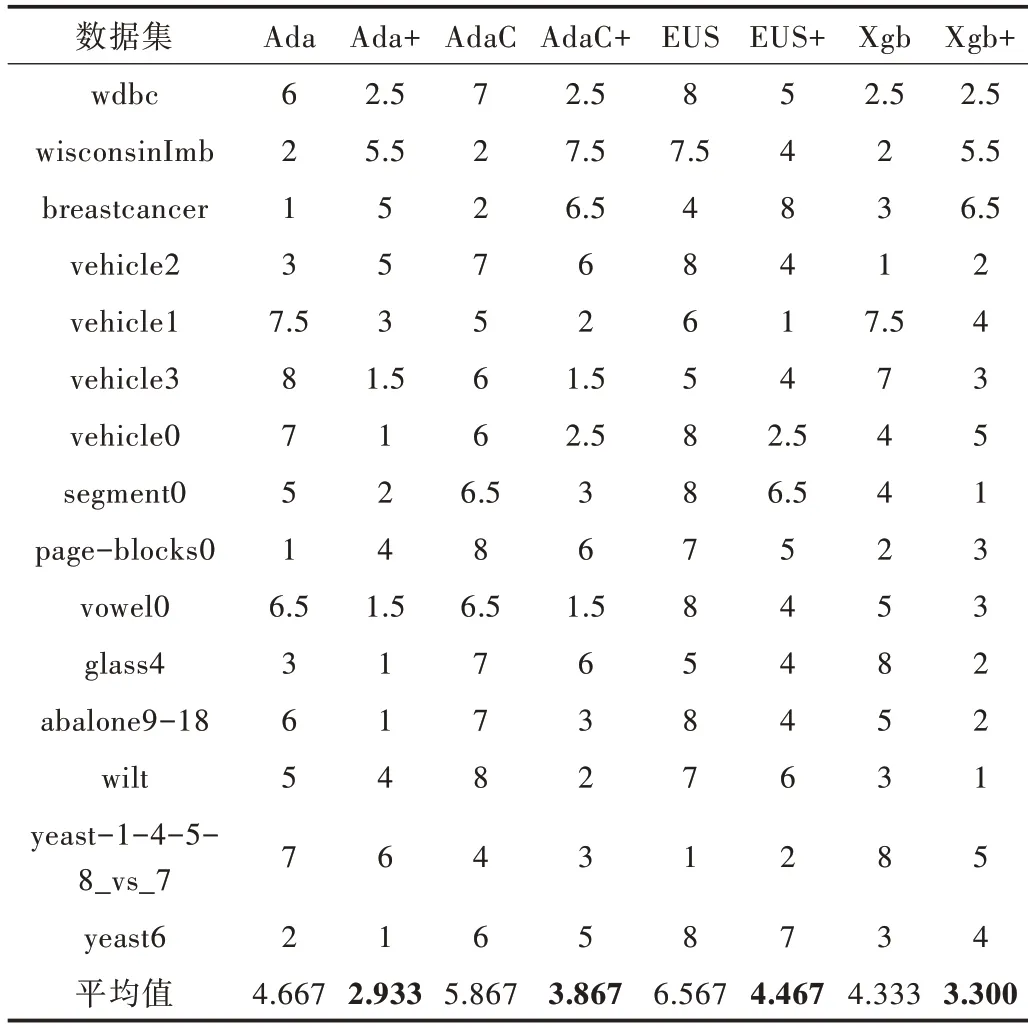
Table 8 Aligned-ranks of algorithms under F-measure表8 F-measure 下算法的序值
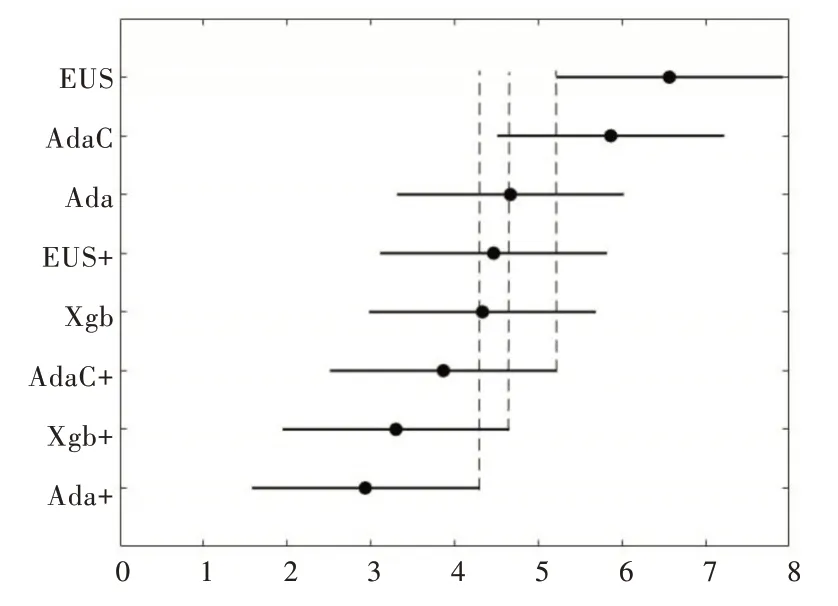
Fig.4 Friedman test chart under F-measure圖4 F-measure 下Friedman 檢驗圖
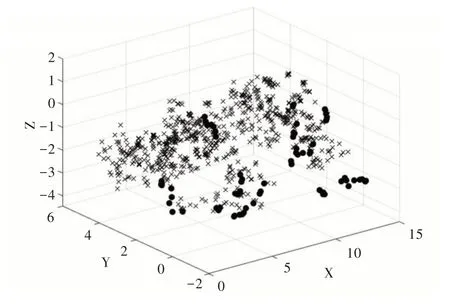
Fig.5 vowel0 three-dimensional scatter plot圖5 vowel0 三維散點圖
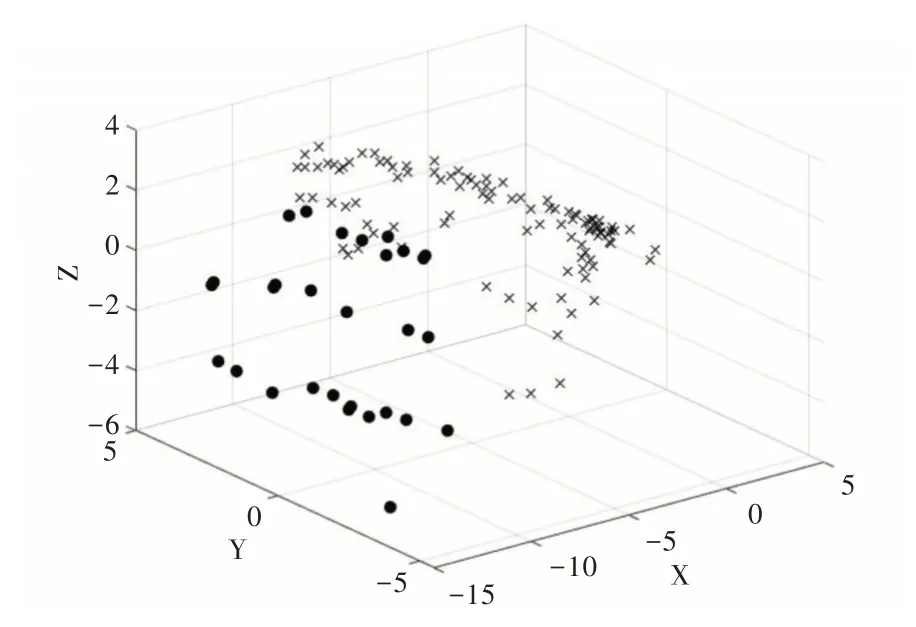
Fig.6 Improved vowel0 three-dimensional scatter plot圖6 改進后的vowel0 三維維散點圖
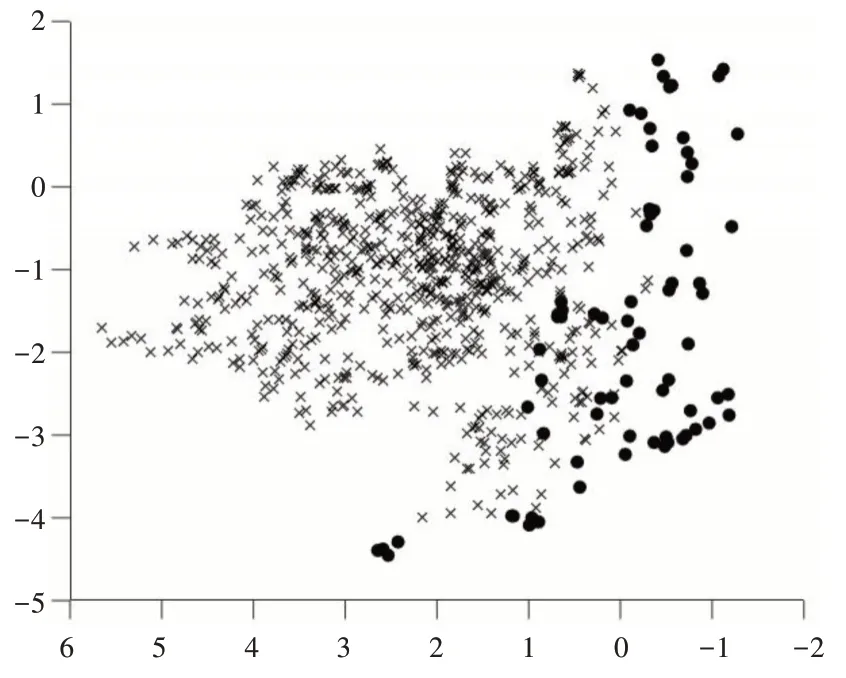
Fig.7 vowel0 two-dimensional scatter plot圖7 vowel0 二維散點圖
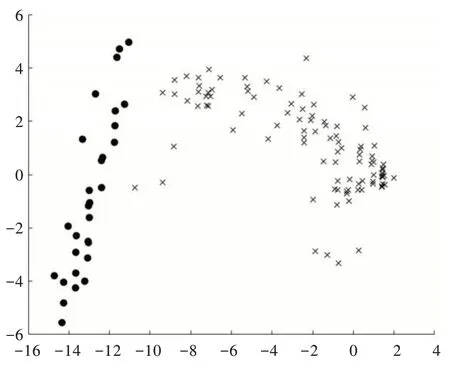
Fig.8 Improved vowel0 two-dimensional scatter plot圖8 改進后的vowel0 二維散點圖
3 結語
針對傳統(tǒng)分類器不能較好地處理類不平衡問題,本文從數(shù)據(jù)和算法角度提出了融合集成思想的改進方法。該方法首先從數(shù)據(jù)層面出發(fā),利用現(xiàn)有的數(shù)據(jù)集和K-means SMOTE 過采樣方法構造多個類平衡的數(shù)據(jù)集;其次,從算法層面出發(fā),集成了多個基分類器。通過對比實驗分析,說明了本文方法的有效性和可行性,并且從類邊界的角度分析了本文方法能夠提高算法性能的原因。但是,當特征維度很高或者類極度不平衡時,訓練模型的時間開銷較大。同時,本文僅針對二分類問題展開了研究,存在局限性。降低時間復雜度和推廣到多分類問題是后續(xù)重點研究的問題。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
