深度學習模型在超聲影像特征診斷乳腺病變性質中的應用*
2021-10-09 08:20:40歐陽濤
中國衛生統計 2021年4期
譚 垚 霍 苓 歐陽濤△ 姚 晨△
【提 要】 目的 探究并比較深度神經網絡模型與傳統學習淺層模型在基于超聲影像特征診斷乳腺病變性質的應用價值。方法 將建模數據集以75%:25%比例拆分為訓練集和測試集,同時構建6種淺層學習模型和深度神經網絡模型,比較其在測試集和驗證集的性能,以ROC曲線下面積(AUC)作為模型主要評估指標。結果 在淺層學習模型中,logistic回歸的AUC最大,除多層感知器外,其他差異均有統計學意義;深度神經網絡模型的ROC曲線下面積(AUC)高于logistic回歸,差異具有統計學意義。結論 深度神經網絡模型相比于傳統淺層學習模型在基于超聲影像特征診斷乳腺病變性質中有更大的診斷價值,但需要進一步探索并優化DNN模型,從而最終使臨床醫師能從深度學習模型的輔助診斷中獲益。
乳腺癌是中國女性發病率最高的惡性腫瘤,嚴重危害女性的身心健康[1]。對乳腺癌疾病進行有效的篩查可以早期發現疾病,降低疾病死亡率。目前用于乳腺癌篩查的主要方法是基于常規超聲設備的乳腺超聲檢查,但醫生尤其是基層醫生的操作水平有限和經驗不足嚴重影響篩查的效果,如何進一步提高篩查能力是研究者的共同目標。因此基于大樣本超聲影像特征建立診斷乳腺病變性質的模型可以有效輔助基層醫生提高篩查能力,從而做出更及時、更準確的診斷。
目前國內外針對于乳腺癌超聲影像建立模型的研究多數采用淺層學習模型,本文利用深度學習進行進一步探索。深度學習是一種基于人工神經網絡的研究,通過模擬人腦神經元將數據從低層傳遞到高層,最終解釋數據和信息的一種機械學習技術[2]。深度學習目前在醫學影像領域上取得較大的成功,因其構架具有靈活性、特征提取能力強、性能潛力大和可擴展性強等優勢,通常優于淺層機器學習方法,并且可以在很少或沒有預處理的情況下從原始數據中自動提取特征[3],從而輔助醫生提高診斷效能[4]。
本研究將利用logistic回歸(LR)、隨機森林(random forest,RF)、極端隨機樹(extra trees)、多層感知器(multilayer perceptron,MLP)、支持向量機(support vector,SVC)和極端梯度提升(XGBoost)六種淺層學習模型和深度神經網絡模型(deep neural network,DNN)分別基于超聲影像特征診斷乳腺病變性質建立相關模型,比較兩類模型的預測能力。
資料與方法
1.資料來源
本研究基于前期研究數據[14],建模數據集為北京腫瘤醫院2010年11月至2016年5月收集的具有全自動超聲影像檢查資料、病灶超聲影像最大徑2cm以下且有組織病理學確診的1345例病例,經過北京人民醫院醫生再次讀取影像特征數據,最后納入兩醫院復判一致的建模數據為1125例,其中惡性腫瘤為732例(占65.07%)。將建模數據集劃分為75%訓練樣本(training set)和25%測試樣本(test set),訓練樣本用于模型構建,測試樣本進行模型測試。
外部驗證數據集(external validation set)為北京腫瘤醫院、北京人民醫院、河北醫科大學第四醫院、北京市順義區婦幼保健院和北京市海淀區婦幼保健院5個中心2017年8月到2019年12月收集的全自動超聲影像檢查資料,并且有活檢病例病理結果(1094例)或隨訪病例隨訪結果(890例)共計1981例,經過數據清理最后納入1965例。用包括基層醫院在內收集的1965例臨床數據作為外部驗證數據集對模型進行驗證。
模型結局指標是具有病理活檢分型的活檢病例或隨訪結果有疾病分型的隨訪病例的診斷結果(良性或惡性)。自變量是根據超聲影像特征性術語,在前期研究中確定納入模型的相關變量,變量編碼如表1。
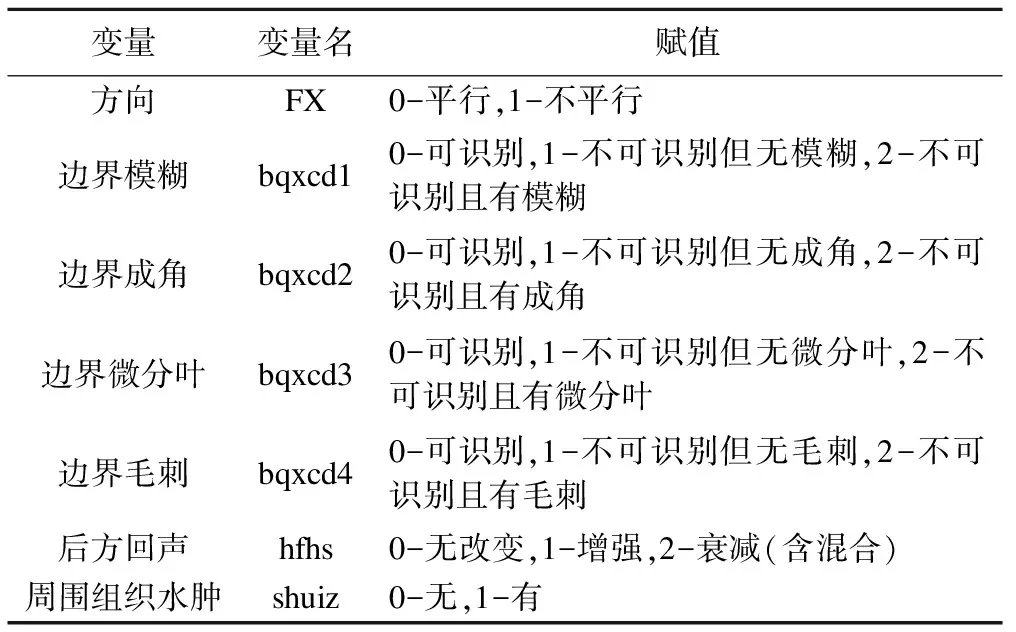
表1 變量賦值情況
2.研究方法
(1)淺層學習模型
將變量選擇、獨熱編碼和基本模型組裝成pipeline(管道或流水線),將pipeline放入網格搜索,設置10折交叉驗證,進行超參數的搜索以調優,輸出最優模型。為了防止模型過擬合,對模型進一步校準,使用校準后的模型對測試集和外部驗證集進行預測,并輸出預測性能指標。將上述全部流程定義為一個函數模塊以供重復調用。輸入所有自變量,對每個模型分別定義參數搜索范圍,調用上述函數并執行結果。
交叉驗證是防止過度擬合的有力預防措施。在標準的k倍交叉驗證中,我們將數據劃分為k個子集,稱為folds(折)。然后,我們將(k-1)倍的迭代算法迭代訓練,同時將其余倍數用作測試集(稱為“holdout fold”,即“留出來一部分”)。交叉驗證使模型可以僅使用原始訓練集來調整超參數。這樣,就可以將測試集保留為一個真正看不見的數據集,以選擇最終模型。對于具備正則化超參數的模型,我們對logistic回歸模型使用正則化,決策樹類型的random forest、extra trees進行了剪枝,support vector和multilayer perceptron選用具有懲罰功能的超參數,XGBoost使用了控制模型復雜性的參數。
機器學習所用軟件為Python。淺層學習模型構建所使用的庫為“sklearn”庫。
(2)深度學習模型
構建DNN模型,并以logistic回歸模型作為基線進行比較。DNN模型所用的3個數據集(訓練集,測試集和外部驗證集)都同上述淺層學習模型,使用相同的自變量作為輸入。依次進行獨熱編碼,模型架構設計,模型編譯,借助于網格搜索的超參數調整等流程確定最佳模型,最后進行模型預測,性能結果輸出。將DNN模型和logistic回歸模型在測試集和外部驗證集的預測結果,以ROC曲線形式繪制到同一個圖中進行兩者性能的對比。DNN模型使用的Python庫為:“keras”庫;“keras”的后端引擎庫為“tensorflow”。
①DNN架構設計
DNN模型共包含4層的網絡架構,見圖1。Dense層使用“relu”激活函數,內核初始化器(kernel_initializer)使用“glorot_uniform”。模型編譯時,使用損失函數為“binary_crossentropy”,優化器為具有學習率為1e-4的“RMSprop”,評估指標為準確率(accuracy)。
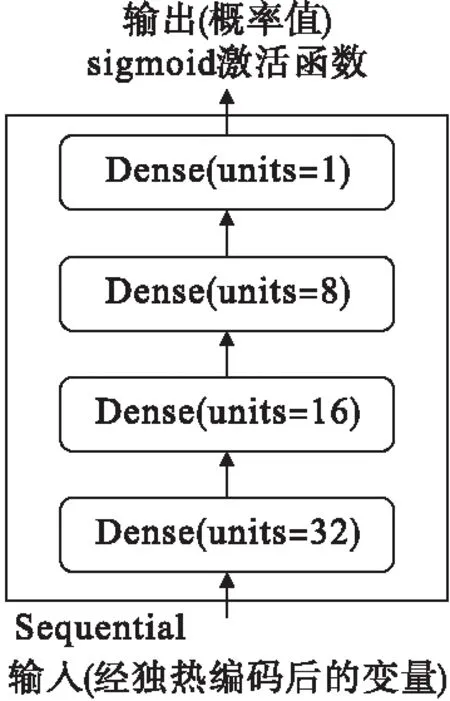
圖1 DNN模型架構
②DNN調優
將DNN模型包裝在KerasClassifier類實例中,使用sklearn模塊中的GridSearchCV類進行網格搜索超參數。最終使用的輪次(epochs,向前和向后傳播中所有批次的單次訓練迭代),批處理(batch_size,即一次訓練所選取的樣本數)的取值分別為:epochs=100,batch_size=10。
直到一定數量的迭代,新的迭代才能改善模型,但是此后該模型的泛化能力可能會因為過度擬合訓練數據而減弱。提前停止是指當模型通過該點前停止。為了防止過擬合,我們開始時選擇相對較少的層和參數,然后逐漸增加層的大小或增加新層,直到這種增加對驗證損失的影響變得很小。根據模型的損失曲線,選擇適合的輪次,及時終止模型的迭代。
(3)ROC曲線比較
ROC曲線下面積用于評估模型的區分度,以此驗證模型的鑒別能力。將各個模型ROC曲線下面積作為主要的評價指標,運用Medcal軟件,將各個模型的預測值作為檢驗變量,金標準結果設為分類變量,得出各個模型的ROC曲線下面積(AUC)并采用Z檢驗對結果進行兩兩比較,比較ROC曲線下面積有無統計學差異,P<0.05表示有統計學差異。
結 果
1.一般情況
建模數據集惡性腫瘤732例(65.07%),良性腫瘤393例(34.93%);驗證數據集中惡性腫瘤498例(25.34%),良性腫瘤1467例(74.66%),兩者經檢驗差異具有統計學意義(χ2=471.132,P<0.0001)。
2.淺層學習模型結果
分別用logistic回歸、random forest、extra trees、multilayer perceptron、support vector和XGBoost對測試集和驗證集進行分析。
在測試集中,multilayer perceptron模型AUC最大,為0.775(95%CI:0.719~0.832);logistic回歸模型AUC為0.771(95%CI:0.715~0.826)。在驗證集中logistic回歸模型AUC最大,為0.906(95%CI:0.892~0.921)。其他模型在測試集和驗證集的評價指標詳見表2。
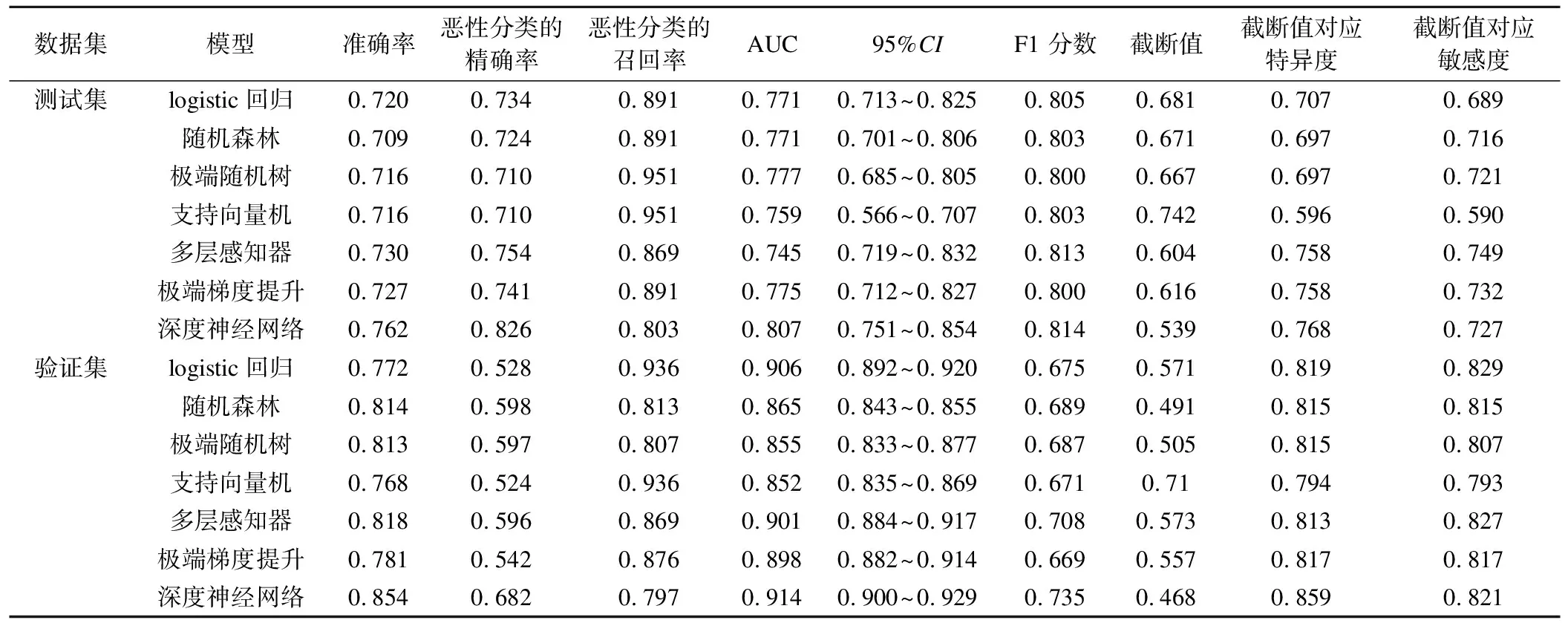
表2 不同模型在測試和驗證集的評價指標比較
用AUC作為模型的主要評價指標,對各個模型的AUC進行統計學檢驗,在驗證集上,logistic回歸模型AUC高于其他模型,logistic回歸模型與extra trees,random forest和support vector的AUC差異具有統計學意義(Z值分別為5.746,4.981,8.079,P<0.0001);logistic回歸模型與XGBoost的AUC差異具有統計學意義(Z=2.081,P=0.0374);logistic回歸模型與multilayer perceptron的AUC差異無統計學意義。其他模型之間AUC比較見表3。
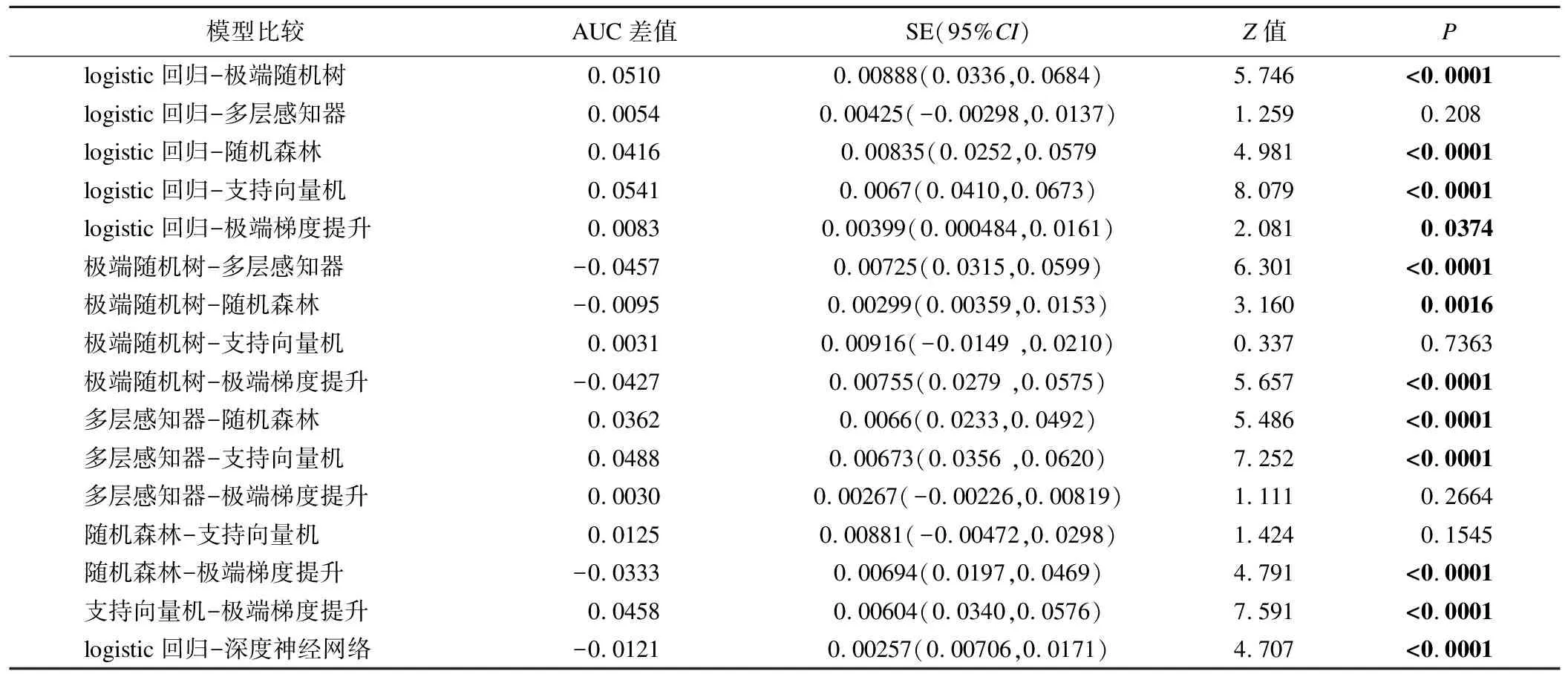
表3 不同模型在驗證數據集上ROC曲線下面積比較
3.深度學習模型結果
以logistic回歸作為淺層學習基線模型,建立DNN深度學習模型與之進行比較。DNN模型loss(損失)曲線和accuracy(準確率)曲線見圖2,未出現過擬合的現象。根據表1,在測試集上DNN模型各個參數表現都優于淺層學習模型,其準確度為0.762,AUC為0.807(95%CI:0.751~0.854)。在驗證集中DNN模型準確度為0.854,在選取的截斷值為0.468時,靈敏度為0.821,特異度為0.859,AUC為0.914(95%CI:0.900~0.929),與logistic回歸比較,兩模型AUC相差0.0121,Z統計量為4.707,P<0.0001,兩模型預測價值差異具有統計學意義,DNN模型高于logistic回歸,兩者在測試集和驗證集的ROC曲線見圖3。
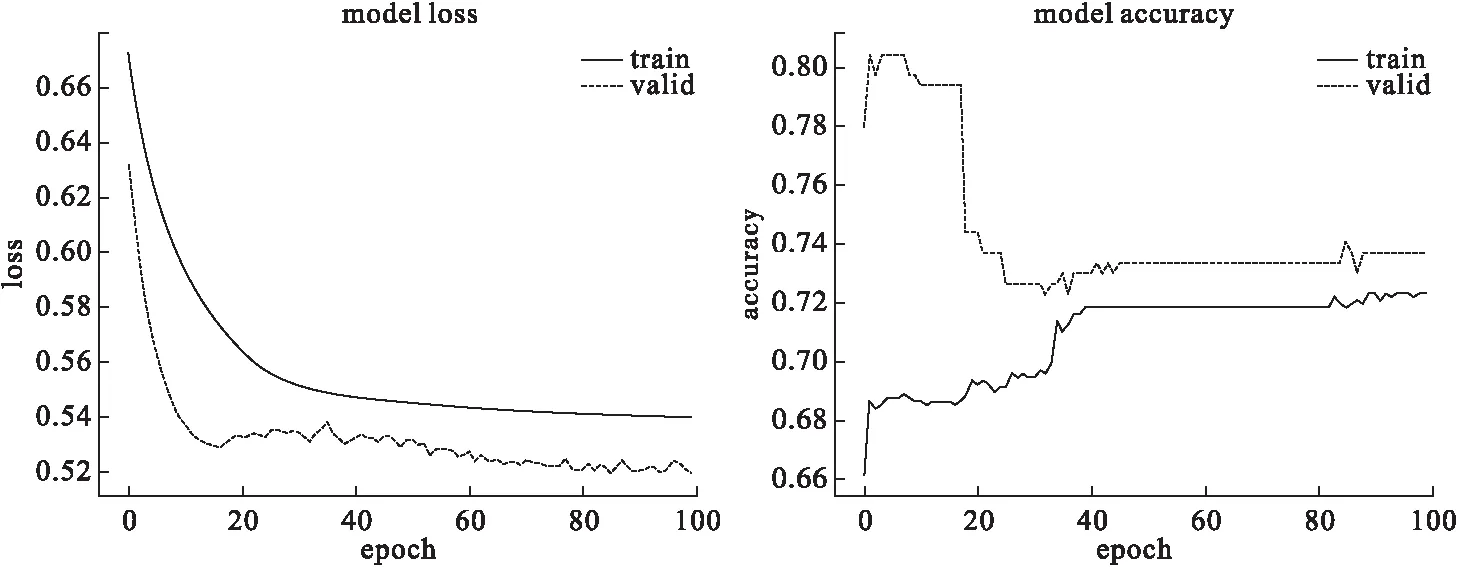
圖2 DNN模型每輪(epoch)訓練損失/準確率和驗證損失/準確率
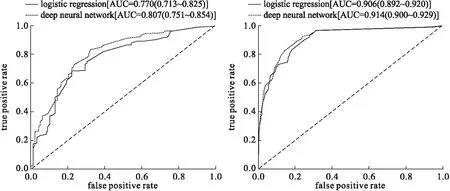
圖3 logistic模型和DNN模型在測試集(左)和驗證集(右)的ROC曲線
討 論
本研究通過建立不同的淺層學習模型和深度學習模型探究基于超聲影像特征診斷乳腺病變性質的價值。目前國內臨床上利用超聲影像特征建立診斷模型大部分采用logistic 回歸[5-7],建模方式較為單一。logistic回歸作為一種常見的模型,構建過程簡單且易于解釋,但是由于它對參數進行線性結合計算,對于復雜的變量適應程度較低[8]。本研究所有變量均為分類變量,可以有效避免由于變量之間存在線性關系假設導致logistic 回歸建模的局限性[9]。本研究主要是基于前期研究[14]依據三種自變量篩選的方法,考慮模型的使用條件(如:共線性等)從最初27個自變量確定的7個模型預測自變量的進一步驗證研究。本研究不將重點放在自變量的篩選上,在基于前者研究確定的自變量上通過建立包括logistic 回歸在內的6個淺層學習模型比較,綜合模型參數和模型操作便捷性,解釋容易性等方面,最終確定使用logistic 回歸作為淺層學習基線模型與深度模型比較。
當前基于超聲影像特征建立乳腺病變性質診斷模型多數使用的是淺層結構算法模型,其局限性在于有限樣本和計算單元情況下對復雜函數的表示能力有限,針對復雜分類問題其泛化能力受到一定制約[10]。深度學習可通過學習一種深層非線性網絡結構,實現復雜函數逼近,表征輸入數據分布式表示,并展現了強大的從少數樣本集中學習數據集本質特征的能力[11]。DNN模型是一種深度神經學習網絡模型,是深度學習的基礎[12]。其內部的神經網絡層可以分為三類,輸入層、隱藏層和輸出層,一般來說第一層是輸入層,最后一層是輸出層,而中間的層數都是隱藏層。相比于淺層學習模型,DNN由于有更多的層次,對事物的建模或者抽象表現的能力更突出,因此也更能準確模擬出更復雜的模型。
本研究構建4層網絡架構的深度學習模型,利用較少層數的DNN模型結構處理數據結果,與傳統淺層學習模型相比模型得到明顯提升,具有更佳的診斷效果,尤其在準確率上有較大的提升[13-14],說明利用深度學習模型能更充分地探索人工判讀的超聲影像特征變量的診斷價值,得到預測能力更強的預測模型。本研究的不足之處在于DNN模型建立過程中層數無法自動設置,需要一層一層手動添加構建,本研究只探究了4層網絡構架的DNN模型,未必達到最優層數的設置,需要再嘗試更深層數的模型建立。同時,在構建DNN模型時涉及的每層參數設置采用的是默認參數,沒有嘗試調整相關參數以獲得更優模型。
綜上所述,DNN模型相比于傳統淺層學習模型在基于超聲影像特征診斷乳腺病變性質有更大的診斷價值,但需要進一步探索并優化DNN模型,從而最終使臨床醫師能從深度學習模型的輔助診斷中獲益。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
