基于膠囊網絡與深度置信網絡融合模型的手寫漢字識別
2021-10-09 07:31:41管小衛丁琳
軟件工程 2021年10期
關鍵詞:深度學習
管小衛 丁琳
摘? 要:針對離線手寫漢字的特征提取困難、不能準確識別等問題,提出了一種膠囊網絡與深度置信網絡的融合模型。首先從CASIA-HWDB1數據集中隨機選擇了一些文本分別訓練膠囊網絡和深度置信網絡,然后采用膠囊網絡和深度置信網絡的融合策略進行了手寫漢字識別實驗。實驗結果表明,在不確定方向上使用漢字融合模型的錯誤率降低了5.2%,與單獨使用膠囊網絡和深度置信網絡相比,具有更好的識別效果。
關鍵詞:手寫漢字;深度學習;膠囊網絡;深度置信網絡
中圖分類號:TP399? ? ?文獻標識碼:A
Handwritten Chinese Character Recognition based on the Fusion
Model of Capsule Network and Deep Belief Network
GUAN Xiaowei, DING Lin
(Jiangsu Vocational and Technical College of Finance & Economics, Huai'an 223003, China)
56491644@qq.com; 372369299@qq.com
Abstract: Aiming at the difficulties in feature extraction of offline handwritten Chinese characters and inaccurate recognition, this paper proposes a fusion model of Capsule Network (CapsNet) and Deep Belief Network (DBN). First, some texts from CASIA-HWDB1 data set are randomly selected to train CapsNet and DBN respectively. Then, handwritten Chinese character recognition experiments are conducted using the fusion strategy of CapsNet and DBN. The experimental results show that the error rate of fusion model is reduced by 5.2% for Chinese characters in uncertain direction, and it has better recognition effect than using CapsNet and DBN alone.
Keywords: handwritten Chinese characters; deep learning; capsule network; deep belief network
1? ?引言(Introduction)
漢字識別的研究涉及人工智能、模式識別、圖像處理、統計決策理論等學科,在辦公、銀行、郵政等自動分類領域具有重要的理論意義和實踐價值[1]。漢字識別可分為印刷漢字識別和手寫漢字識別兩大類。手寫漢字識別可分為在線手寫漢字識別和離線手寫漢字識別。在線漢字識別是指在通過觸摸屏等輸入設備手寫漢字過程中,計算機根據書寫漢字的筆畫走向、筆畫順序、書寫速度等多種信息進行識別,由于信息量多且具有連續性,因此識別難度較小,識別準確率也較高[2]。離線漢字識別提供的信息量少,僅僅通過識別一個漢字的二維圖像來提取漢字特征,所以識別難度較大,識別準確率也較低[3]。各大高校和研究所致力于漢字識別的研究,由于漢字具有類別多、字形復雜、相似等特點,因此每個人手寫漢字千差萬別,導致手寫漢字識別困難,故手寫漢字識別一直是研究的熱點和難點[4-5]。
手寫漢字識別是一個極具挑戰性的模式識別與機器學習問題,特征如下:一是漢字類別中的漢字數量很多。二是字體結構復雜。三是字形變化很大。離線手寫漢字主要用在日常生活中。手寫字是任意的,缺乏規范性,水平、垂直、點等筆觸容易變形,例如筆直變彎,筆觸成圓弧,短橫、短豎成點等。四是有很多類似的詞。漢字集合中有很多相似詞,如:“已—己—巳,盲—肓,兔—免”等,可能由于預處理不當從而導致字符錯誤。
總之,諸多研究人員已經做了大量的離線手寫漢字識別工作。針對離線手寫漢字識別的難點,文獻[6]提出了一種CNN-DBN手寫漢字融合模型,比單獨分別使用CNN和DBN的識別效果好。文獻[7]從GoogLeNet網絡構建了卷積神經網絡,并使用隨機彈性變換算法擴展了訓練數據。文獻[8]結合ResNet網絡,通過使用作業圖像中漢字筆跡測試結果中的每個有效檢測區域作為輸入,實現基于深度學習模型的漢字筆跡識別。文獻[9]提出了一種基于PCCG-GAN的手寫漢字歸一化方法,實現了從手寫到打印的漢字生成任務。利用對稱網絡提取手寫漢字多尺度信息并進行特征融合,減少了輸入輸出之間共享的底層信息量,減少了欠采樣過程中信息的丟失。文獻[10]由于卷積神經網絡對手寫漢字的識別速度較慢,二維主成分分析(2DPCA)和卷積神經網絡相結合來識別手寫漢字與基于Alexnet的CNN模型相比,時間減少了78%,與基于ACNN的模型相比,時間減少了80%。文獻[11]針對傳統手寫漢字識別特征提取過程復雜、識別率低、分類模型能力弱的問題,設計了一種多通道交叉融合的深度殘差網絡模型,并設計了中心損失函數,比之前的算法提高了2.3%識別率。
近年來,隨著深度學習的興起和不斷發展,各種智能算法在計算機視覺領域取得了突破性的成果,使得手寫漢字的識別率也越來越高。為了進一步探索線下手寫漢字的識別方法,本文擬提出一種膠囊網絡與深度置信網絡融合的識別模型,以提高手寫漢字的識別能力。
2? ?相關工作研究(Related Work Research)
2.1? ?膠囊網絡
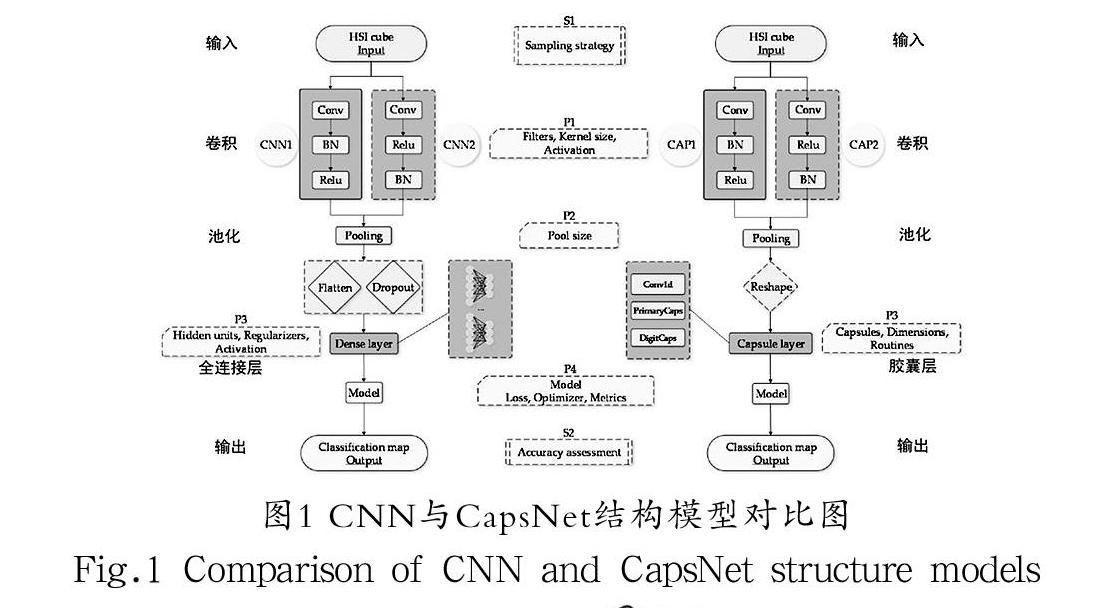
Hinton等人在2017 年提出了膠囊網絡(Capsule Network, CapsNet)。CapsNet是建立在卷積神經網絡(Convolutional Neural Networks, CNN)基礎上的圖像分類識別技術,CNN的缺陷是對于物體間的空間識別能力及物體旋轉后的識別能力不強,而CapsNet能很好地解決這兩個問題,如圖1所示。CapsNet結構層次淺,由卷積層、主膠囊層、數字膠囊層構成,其結構如圖2所示。
傳統的神經網絡是由神經元組成的,神經元表示對象中的各種屬性。膠囊(Capsule)稱為向量神經元,向量長度表示對象存在的概率,向量方向表示對象的屬性,它包含多個神經元。CapsNet用膠囊代替傳統神經元,它的輸入輸出都是一個向量。低層封裝需要將輸出傳遞給該輸出的高層封裝。具體地說,路由數據的傳輸是通過低層膠囊的輸入與高層膠囊的輸出的相似性來確定的。如果低層膠囊的預測矢量與高層膠囊的有效矢量具有高度相似性,則表明這兩個膠囊高度相關。
CapsNet中使用了迭代動態路由算法,以與輸出向量相似的方向在膠囊中獲取向量,并且與向量的數量和模塊的長度呈正相關。為了避免將內部乘積用作無上限情況的度量,將矢量壓縮到輸出之前。
2.2? ?深度置信網絡
深度置信網絡(DBN)由多層有限Boltzmann機器(RBM)和一層分類器組成,經典的DBN網絡結構是由多層RBM和一層BP組成的深度神經網絡。該深度模型廣泛應用于圖像分類識別、語音識別等領域。
DBN是基于生物神經網絡的研究和淺層神經網絡的發展而來的,并且從聯合概率分布中推斷出概率樣本模型的數據樣本分布。DBN生成模型通過訓練網絡結構中神經元之間的權重,整個神經網絡根據最大概率生成訓練數據,形成高級抽象特征,并提高了模型的分類性能。
DBN使用自下而上的傳輸,底層神經元接收原始特征向量,不斷抽象到更高的水平,頂層神經網絡形成易于組合的特征向量。通過添加層,可以抽象出更大的特征向量,并且網絡的每一層都會削弱前一層的錯誤信息和輔助信息,以確保深度網絡的準確性。DBN結構如圖3所示。受限的Boltzmann機器由兩個神經元節點組成,即隱藏層和可見層。
2.2.1? ?受限玻耳茲曼機(RBM)
首先,DBN模型是基于人工神經網絡的,由接收輸入數據的顯性神經元和特征提取的隱性神經元組成。DBN的關鍵組件是RBM,它通過將多層RBM與最終分類器結合在一起來檢測、識別和分類輸入數據。RBM組成結構包含兩層神經元,每一層都可以由一個向量表示,向量的維數由每一層中神經元的數量確定,如圖4所示。
由圖4可知,為了保證層中神經元的獨立性,RBM各層中的神經元之間無連接,層間神經元雙向連接,即與給定元素相對應的隱藏元素的值無關,并且當該元素被賦予隱藏元素值時,將保留相同的特性。
2.2.2? ?DBN模型的構建
DBN就是一些堆疊在一起的RBM,前一個RBM的輸出就是后一個RBM的輸入。本文以兩層RBM和Softmax分類層為例構建DBN模型。如圖3所示,v代表顯示層神經元,h代表隱藏層神經元,y代表標簽已知的樣本,o代表分類結果輸出。DBN模型的構造如下:固定第一個訓練后的RBM的權重和偏差,將其隱藏元素的狀態作為第二個RBM的輸入;訓練后將第二個RBM堆疊在第一個RBM上;重復上述過程進行多次逐層學習。如果訓練數據集包含標記的樣本,則需要在第二次RBM訓練期間將其添加,最后使用Softmax對數據進行分類。
深度置信網絡在檢測識別領域的應用效果分析,如表1所示。樣本數據主要是手寫數字、頻譜圖像和語音。
2.3? ?CapsNet與DBN融合模型
CapsNet模型和DBN模型都可以應用于線下手寫漢字識別任務,CapsNet解決了CNN的缺點,能捕捉特征位置、相對大小、特征方向等屬性間的關系。DBN通過采用逐層訓練的方式為整個網絡賦予了較好的初始權值,以重構數據為目標,使網絡只要微調就可以達到最優解,這在無監督的環境中是非常有用的。
由于CapsNet和DBN網絡結構不同,因此提取特征的優勢不同,如字形特征不明顯,或與其他字形相似,那么不同的人識別的結果可能也不一樣。本文提出的CapsNet和DBN融合模型結合了兩者的優勢,比單獨使用CapsNet和DBN識別漢字具有更高的識別能力,這種模型稱為CapsNet-DBN融合模型,包括訓練和識別過程,如圖5所示。
3? ?仿真與測試(Simulation and Test)
3.1? ?實驗準備
使用數據集CASIA-HWDB 1.1進行訓練和測試,該數據集于2010 年5 月公布,為手寫單字,分別由300 人書寫,包含171 個英文數字符號,3,755 個GB2312一級漢字,共300 套,總計1,172,907 個有效樣本。表2列出了CapsNet-DBN模型中的各層參數。
3.2? ?實驗結果與分析
本文實驗環境:Windows 10 64位操作系統,處理器為Intel(R) Core(TM)i7-6500U CPU,主頻為2.5 GHz,內存為16 GB,實驗平臺為Python 3.8版本。實驗數據來自http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html。
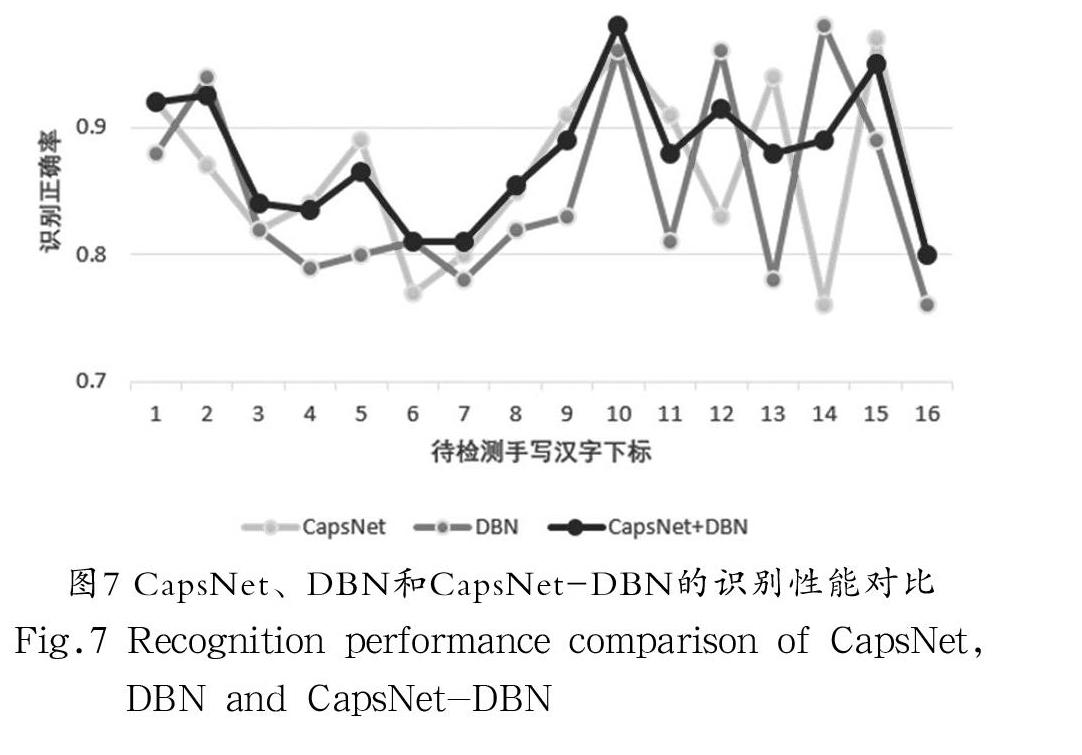
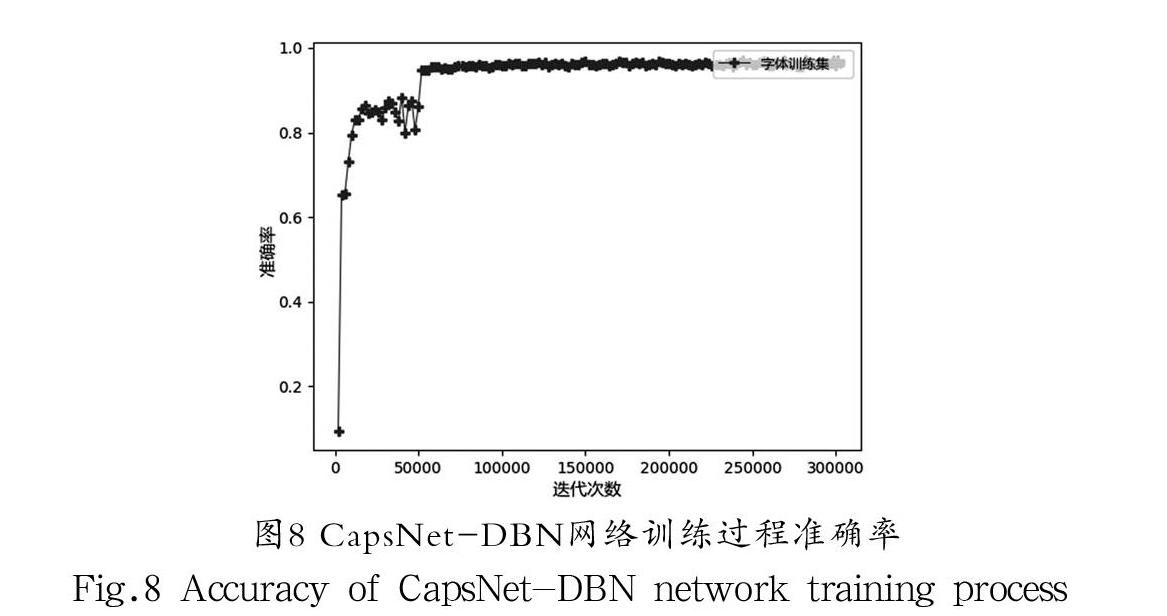
表3為CapsNet網絡、DBN網絡及其融合網絡的準確率。CapsNet、DBN、CapsNet-DBN對不同寫法的漢字識別能力的比較如圖6所示。圖7表明三種算法對不同漢字的識別能力,CapsNet-DBN在大部分情況下都比CapsNet和DBN對不同漢字的識別能力要高。圖8和圖9分別顯示了CapsNet-DBN網絡訓練過程準確率和訓練損失。
使用相同數據集驗證并比較表1中的各種模型算法和本文所述的融合模型的識別準確率,從表4中可知,ResNet-BLSTM+DBN方法對手寫漢字的識別效果良好,本文提出的CapsNet-DBN融合模型也可以獲得較高的精度。
本文在CapsNet-DBN模型的基礎上嘗試增加隱藏層和隱藏單元數目及在不同的迭代次數中進行測試,分別增加了隱藏層個數及隱藏單元數。圖10(a)隱藏層參數為(32*3*3)-(16*2*2)-(2*2)-(2*2)-(64*2*2)-(2*2)-(512),圖10(b)隱藏層參數為(32*3*3)-(2*2)-(16*2*2)-(2*2)-(32*2*2)-(2*2)-(64*2*2)-(2*2)-(512),圖10(b)比圖10(a)增加了2 個隱藏層。圖11(a)隱藏層參數為(32*3*3)-(2*2)-(32*2*2)-(2*2)-(96*2*2)-(2*2)-(128*2*2)-(2*2)-(512),圖11(b)隱藏層參數為 (32*3*3)-(2*2)-(64*2*2)-(2*2)-(96*2*2)-(2*2)-(128*2*2)-(2*2)-(512),圖11(b)其中一個隱藏層單元數為圖11(a)的2 倍。實驗結果說明了隱藏層個數和隱藏單元數目的增加可以將大量信息擴展到維度較大的中間空間,這樣會將模型的驗證精度提高7.2%。當然,隱藏層個數和隱藏單元數目也不是越多越好,需要根據具體問題進行調整。
4? ?結論(Conclusion)
本文針對離線手寫漢字的特征提取困難、不能準確識別等問題,提出了一種膠囊網絡與深度置信網絡的融合模型,從CASIA-HWDB 1.1數據集中隨機選擇了一些文本進行手寫漢字識別實驗。實驗結果表明,與單獨的CapsNet和DBN及傳統的機器學習方法相比,CapsNet-DBN融合模型在數據集上獲得了更好的識別結果。
參考文獻(References)
[1] SHEN X, MESSINA R. A method of synthesizing handwritten Chinese images for data augmentation[C]// International Conference on Frontiers in Handwriting Recognition(ICFHR). 2016 15th International Conference on Frontiers in Handwriting Recognition. Shenzhen, China: IEEE, 2016:114-119.
[2] WU P L, WANG F Y, LIU J Y. An integrated multi-classifier method for handwritten Chinese medicine prescription recognition[C]// International Conference on Software Engineering and Service Science (ICSESS). 2018 IEEE 9th International Conference on Software Engineering and Service Science. Beijing, China: IEEE, 2018:1-4.
[3] WANG Z R, DU J. Writer code based adaptation of deep neural network for offline handwritten Chinese text recognition[C]// International Conference on Frontiers in Handwriting Recognition(ICFHR). 2016 15th International Conference on Frontiers in Handwriting Recognition. Shenzhen, China: IEEE, 2016:548-553.
[4] 閆喜亮,王黎明.卷積深度神經網絡的手寫漢字識別系統[J].計算機工程與應用,2017(10):246-250.
[5] 金連文,鐘卓耀,楊釗,等.深度學習在手寫漢字識別中的應用綜述[J].自動化學報,2016,42(8):1125-1141.
[6] 李蘭英,周志剛,陳德運.DBN和CNN融合的脫機手寫漢字識別[J].哈爾濱理工大學學報,2020,25(3):137-143.
[7] 林恒青,鄭曉斌,王麟珠,等.基于深度卷積神經網絡和隨機彈性變換的脫機手寫形近漢字識別[J].蘭州工業學院學報,2020,27(3):62-67.
[8] 徐穩越.面向作業智能評閱的漢字手寫體檢測與識別[D].石家莊:河北師范大學,2020.
[9] 張紅蕊.基于生成式對抗網絡的漢字生成方法研究[D].天津:天津師范大學,2020.
[10] 鄭延斌,韓夢云,樊文鑫.基于二維主成分分析與卷積神經網絡的手寫體漢字識別[J].計算機應用,2020,40(8):2465-2471.
[11] 張秀玲,周凱旋,魏其珺,等.多通道交叉融合的深度殘差網絡脫機手寫漢字識別[J].小型微型計算機系統,2019,40(10):
2232-2235.
[12] 張緒冰,王賢敏,王凱,等.基于深度置信網絡的CRISM影像火星表面礦物識別方法[J].地質科技通報,2020,39(4):189-200.
[13] 鄭益勤,楊曉峰,李紫薇.深度學習的靜止衛星圖像海上強對流云團識別[J].遙感學報,2020,24(1):97-106.
[14] 何群,杜碩,王煜文,等.基于變分模態分解與深度置信網絡的運動想象分類識別研究[J].計量學報,2020,41(1):90-99.
[15] 徐宇恒,程嗣怡,董曉璇,等.基于DBN特征提取的雷達輻射源個體識別[J].空軍工程大學學報(自然科學版),2019,20(6):
91-96,108.
[16] 陳亮,吳攀,劉韻婷.面向類內差距表情的深度學習識別[J].中國圖象圖形學報,2020,25(4):679-687.
[17] 張華麗,康曉東,冉華,等.用于肺結節影像分類識別的DBN與CNN的比較研究[J].計算機科學,2020,47(z1):254-259.
[18] 宋文豪.基于深度學習的說話人識別技術應用[D].成都:電子科技大學,2020.
[19] 陳海霞.基于神經網絡的多維說話人信息識別研究[D].南京:南京郵電大學,2019.
作者簡介:
管小衛(1981-),男,碩士,講師.研究領域:圖像處理,軟件工程.
丁? ?琳(1980-),女,碩士,講師.研究領域:物聯網技術.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
