基于社會蜘蛛群優化的粒子濾波算法研究
2021-10-11 05:54:32谷旭平唐大全
自動化儀表 2021年8期
關鍵詞:優化
谷旭平,唐大全
(海軍航空大學航空作戰勤務學院,山東 煙臺 264001)
0 引言
解決非線性問題,一般采用擴展卡爾曼濾波的方法,并且其隨機量須符合高斯分布。但粒子濾波(particle filter,PF)的出現打破了解決非線性問題的桎梏[1]。粒子濾波在解決非線性、非高斯問題上的突破,使其應用范圍異常廣泛。粒子濾波在視覺跟蹤領域,目標定位、導航、跟蹤領域以及通信與信號處理領域都發揮著重要作用[2-5]。
粒子退化是標準粒子濾波器的主要缺陷[6-7],解決方法之一就是重采樣。但重采樣會降低粒子多樣性,難以保證估計精度。文獻[8]在重采樣之后加入馬爾科夫鏈蒙特卡洛(Markov chain Monte Carlo,MCMC)移動處理,減少了粒子相關性,使粒子分布與狀態概率密度函數一致,保證了粒子分布的合理性;但算法的收斂性很難保證,且計算量大。文獻[9]利用正規則方法計算粒子的后驗概率密度,有效地緩解了重采樣帶來的樣本枯竭與粒子退化問題,但高維的正規則難以實現。文獻[10]在重采樣前,依據似然值的大小對原粒子權值進行修正,保證重采樣后粒子向高似然區域移動。該算法在重采樣后,更接近狀態真值,但每個粒子需要計算兩次權值以及似然值。這就伴隨著大計算量的問題,難以保證算法的實時性。文獻[11]~文獻[17]依據自然界生物種群的尋優特性,對粒子濾波的重采樣過程進行改進,在一定程度上改善了算法的濾波精度,提高了粒子多樣性。
本文將社會蜘蛛群的尋優特性[18-19]引入粒子濾波的重采樣過程中。一方面,依據有效粒子數判斷是否進行重采樣;另一方面,在復制大權重粒子時,在其期望值附近添加隨機粒子以保證粒子多樣性。同時,利用群體突變、動態自適應權重調節,以及將遺傳算法中的交叉概率[20]引入蜘蛛群繁殖的過程中,保證了算法的全局以及局部收斂能力。
1 粒子濾波原理
粒子濾波的基本思想是:根據系統狀態的經驗分布在狀態空間產生的粒子集,不斷調整粒子的權重和位置,通過調整的粒子信息修正最初的經驗分布。
狀態空間的狀態轉移模型以及量測模型為:
xk=f(xk-1,vk-1)
(1)
zk=h(xk,nk)
(2)
式中:xk∈Rnx為k時刻的狀態向量;zk∈Rnz為k時刻的量測值;vk∈Rnv和nk∈Rnn為過程和量測噪聲,f:Rnx→Rnx,h:Rnz→Rnz為有界非線性映射。
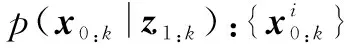
(3)
式中:權值由重采樣選擇。
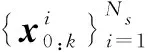
(4)
重要性密度函數分解為:
q(x0:k|z1:k)=q(xk|x0:k-1,z1:k)q(x0:k-1|z1:k-1)
(5)
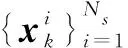
后驗概率密度函數可表示為:
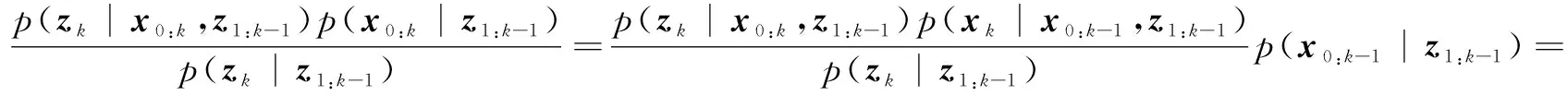
(6)
將式(4)、式(5)代入式(6),即可得到重要性權重的計算公式:
(7)
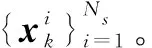
(8)
選擇易于實現的先驗概率密度作為重要性密度函數。將式(8)代入式(7),則重要性權重簡化為:
(9)
權重歸一化,即:
(10)
后驗概率密度p(xk|z1:k)為:
(11)
則k時刻狀態的估計值為:
(12)
2 社會蜘蛛群優化算法
蜘蛛群優化(social spider optimization,SSO)算法將優化空間抽象為一張信息交流網,蜘蛛通過身體接觸以及網的振動來傳遞信息。
2.1 蜘蛛群分工
在社會蜘蛛群體中,雌雄蜘蛛比重不同,一般雌蜘蛛占整個種群數量N的65%~90%。雌、雄蜘蛛種群數量Nf、Nm分別為:
Nf=floor[(0.9-r×0.25)×N]
(13)
Nm=N-Nf
(14)
式中:r為[0,1]之間的隨機數;floor()為向下取整函數。
雌、雄蜘蛛的初始位置fi,j、mg,j分別為:
(15)
(16)
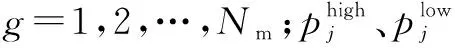
蜘蛛個體權重為:
(17)
式中:J(si)為第i只蜘蛛的適應度。
bs、ws分別為適應度的極大值與極小值:
(18)
(19)
2.2 蜘蛛的移動
2.2.1 移動的誘因
社會蜘蛛在信息交流網中通過彼此之間的振動,感知對方位置。蜘蛛個體的權重以及彼此的距離是影響振動的關鍵因素。振動表達式為:
(20)
式中:di,j=‖si-sj‖為蜘蛛個體i、j的歐式距離。
蜘蛛個體接收到的振動來源有3種:
①權重較大,距離較近的雌蜘蛛個體為:
(21)
②權重最大的蜘蛛個體為:
(22)
③權重較大,距離最近的雄蜘蛛個體為:
(23)
2.2.2 雌雄蜘蛛位置移動
蜘蛛個體位置的移動主要體現在對同性和異性的排斥上,其位置移動算式為:

(24)
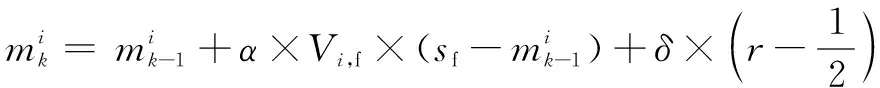
(25)
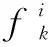
2.3 蜘蛛種群的更新
在交配半徑范圍內的雌雄蜘蛛個體,通過交配產生新蜘蛛個體。新個體的權重受到上一代個體權重影響。新個體與種群質量較輕的個體進行比較,淘汰其中權重較輕的個體來保持種群數量不變。交配半徑R以及蜘蛛影響概率pi為:
(26)
(27)
3 社會蜘蛛群優化的粒子濾波算法
蜘蛛群的尋優過程就是粒子濾波的重采樣過程,通過對SSO進行改進,來保持粒子多樣性以及算法的收斂能力。
3.1 粒子多樣性的改進
重采樣不僅使粒子多樣性下降,也增加了計算量,影響粒子濾波的實時性能。采用有效粒子數Neff來衡量粒子多樣性。有效粒子數的計算式為:
(28)
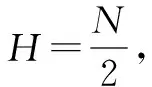
由于噪聲干擾和其他原因,全局最優粒子權重可能不是最大的。重采樣可能導致丟棄全局最優粒子,不能收斂到真實狀態。因此在復制大權重粒子時,根據復制數量在期望值附近添加少量隨機粒子。在粒子不發散的情況下,增加大權重粒子周圍的粒子以保持多樣性,以避免出現次優結果。
重采樣時,記錄刪除的小權重粒子Ndel的數量,從大權重粒子中選擇Nx個粒子,并使用式(29),獲得可復制粒子數M。將大權重粒子的權重作為平均值,并使其成為標準的高斯分布。從高斯分布中隨機選擇M個粒子作為重采樣結果。
(29)
3.2 收斂性能的改進
3.2.1 群體突變
在迭代前期,為避免算法陷入局部最優解,在保證最優粒子的前提下,對其余粒子進行群體突變。引入動態的次數因子temp。因為每個計算周期中,粒子收斂的迭代次數之和是不一樣的,當迭代次數累計到預先規定的數值temp時,就初始化粒子。這可使粒子持續地在較大的空間內尋優,避免算法陷入局部最優。
(30)
3.2.2 動態自適應權重調節
①尋優速度因子。
在粒子尋優的過程中,全局最優值取決于個體最優值的變化,也反映了粒子運動效果。在優化過程中,當前迭代的全局最優值大于或等于上一輪迭代的全局最優值。
定義尋優速度因子Mspeed:
(31)
式中:Nbest為當前迭代最優值;pbest為上一輪迭代最優值。
Mspeed值越小,表示尋優速度越快。經過一定迭代次數,該值會保持在1,表示算法找到最優解。
②尋優程度因子。
定義尋優程度因子Gather:
(32)
XP=exp{min[(Nbest×N-Nsum),(Nsum-
Nbest×N)]}
(33)
式中:Nsum為當前迭代次數粒子的適應度之和;Gather為粒子的尋優程度,0≤Gather≤1。
Gather在一定程度上反映了粒子的多樣性。Gather值越大,粒子的尋優程度越好,粒子多樣性越差。經過一定的迭代次數后,Gather值會保持在1。如果此時算法陷入局部最優,那么不容易跳出局部最優。
③權重調節。
根據重采樣的特點,蜘蛛群優化算法中的粒子權重w應依據粒子的尋優速度以及程度的變化而變化。粒子的尋優速度越快,粒子越可保持大范圍尋優,其全局尋優能力越強。當粒子尋優速度變慢時,通過調整w的大小,可保證粒子在小范圍空間內搜索,從而提高其局部收斂能力。
粒子越分散,算法就不易陷入局部最優。但是隨粒子的尋優程度的不斷提高,算法易陷入局部最優。此時可增大粒子的搜索范圍,從而提高粒子的全局收斂能力。
綜上,粒子的權重w為:
w=1-wa×Mspeed+ws×Gather
(34)
式中:wm和wg為常數,wm∈[0.4,0.6],wg∈[0.05,0.20]。
3.2.3 新粒子生成速度
為了進一步保證算法的收斂能力,將遺傳算法[21]中改進的交叉操作引入SSO。交叉操作的作用主要是限制子蜘蛛的誕生速度。在算法迭代初期,為了提高SSO全局尋優效率,一般交叉概率選取較大值;隨著迭代次數的逐漸增加,為了保證SSO局部尋優能力,選取較小的交叉概率。交叉操作的計算式為:
(35)
式中:PS為自適應交叉概率;PSO為自適應參數;γ為迭代次數;kmax為設置度量。
本文取PSO=0.85、kmax=20。
3.3 改進的粒子濾波算法步驟
改進的社會蜘蛛群粒子濾波算法步驟如下。
(1)初始化。在k=0時刻,依據先驗概率分布p(x0)進行采樣,選取N個初始樣本,并根據式(13)、式(14)初始化雌、雄蜘蛛粒子數目Nf、Nm。然后,根據式(15)、式(16)初始化雌、雄蜘蛛的位置fi,j、mg,j,設定temp。
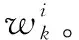
(3)采用改進的SSO算法來優化粒子的重采樣過程。
①依據式(28)判斷是否進行重采樣。
②根據式(17)、式(20)~式(23)計算每個蜘蛛的振動強度。
③若當前迭代次數大于temp,在保持最優粒子位置不變的情況下,依據式(30)進行小權重粒子位置移動;否則,依據式(24)、式(25)移動雌、雄蜘蛛的位置。
④根據式(26)、式(27),雌、雄蜘蛛在給定交配半徑內產生新的粒子,并依據式(35)維持不同時期新粒子產生的速率,保證不同時期的收斂速度。
⑤依據式(31)~式(34),動態調整粒子權重。
(4)計算迭代截止時粒子的權重,并用式(10)進行歸一化處理。
(5)根據式(12),輸出狀態估計值。
3.4 改進粒子濾波算法收斂性驗證
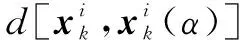
(36)
式中:t為蜘蛛粒子個體到達局部最優位置的時間;若E(t)存在且有界,則該算法是全局收斂的。

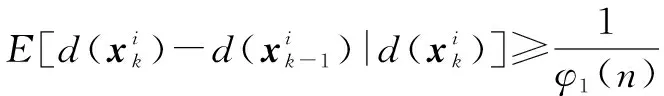
條件1說明了蜘蛛粒子個體與最優位置之間的距離在一個多項式的范圍內。條件2說明蜘蛛粒子個體不斷趨于最優位置時,蜘蛛粒子群的移動在一個多項式倒數的范圍內。
當滿足上述兩個條件時,E(t)存在且有界,蜘蛛群算法的時間估計為:
(37)
本文對SSO進行改進,但在每一次迭代后,蜘蛛粒子群體必將進入最優狀態,因此優化后算法依然滿足上述條件;采用遺傳算法的交叉概率,動態自適應調整權重,群體突變,蜘蛛粒子群整體的移動并沒有改變,因此依然滿足上述條件。綜上所述,改進的SSO依然保持著全局收斂能力,且該算法是收斂的。
4 仿真分析
本試驗選用一維系統來仿真基本粒子濾波,鴿群優化粒子濾波(pigeon-inspired optimization-PF,PIO-PF),改進的磷蝦優化粒子濾波(improved krill herd optimization-PF,IKH-PF),布谷鳥群優化粒子濾波(cuckoo search optimization-PF,CS-PF),改進的社會蜘蛛優化粒子濾波(improved social-spider optimization-PF,ISSO-PF)在狀態估計精度、實時性等方面的綜合指標。
選用的一維非線性系統方程與觀測方程為:
x(k)=0.9+cos(0.04πk)+0.4x(k-1)+w(k)
(38)
(39)
式中:w為服從伽馬分布Λ~Γ(3,2)的過程噪聲;v為符合均值為0、方差為R的高斯分布的噪聲。
系統的初始狀態為x(0)=0.1,仿真步長T=100。
4.1 算法精度測試
(1)在粒子數不同的情況下,濾波狀態估計和估計誤差絕對值分別如圖1、圖2所示。
①粒子數N=50、方差R=1時,仿真結果與估計誤差絕對值如圖1、圖2(a)所示。
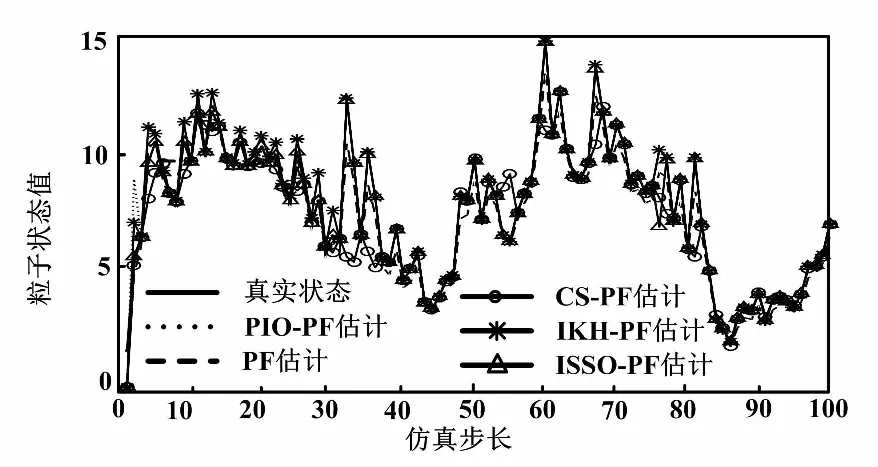
圖1 濾波狀態估計(N=50,R=1)
②粒子數N=100、方差R=1時,估計誤差絕對值如圖2(b)所示。
③粒子數N=150、方差R=1時,估計誤差絕對值如圖2(c)所示。
④粒子數N=200、方差R=1時,估計誤差絕對值如圖2(d)所示。
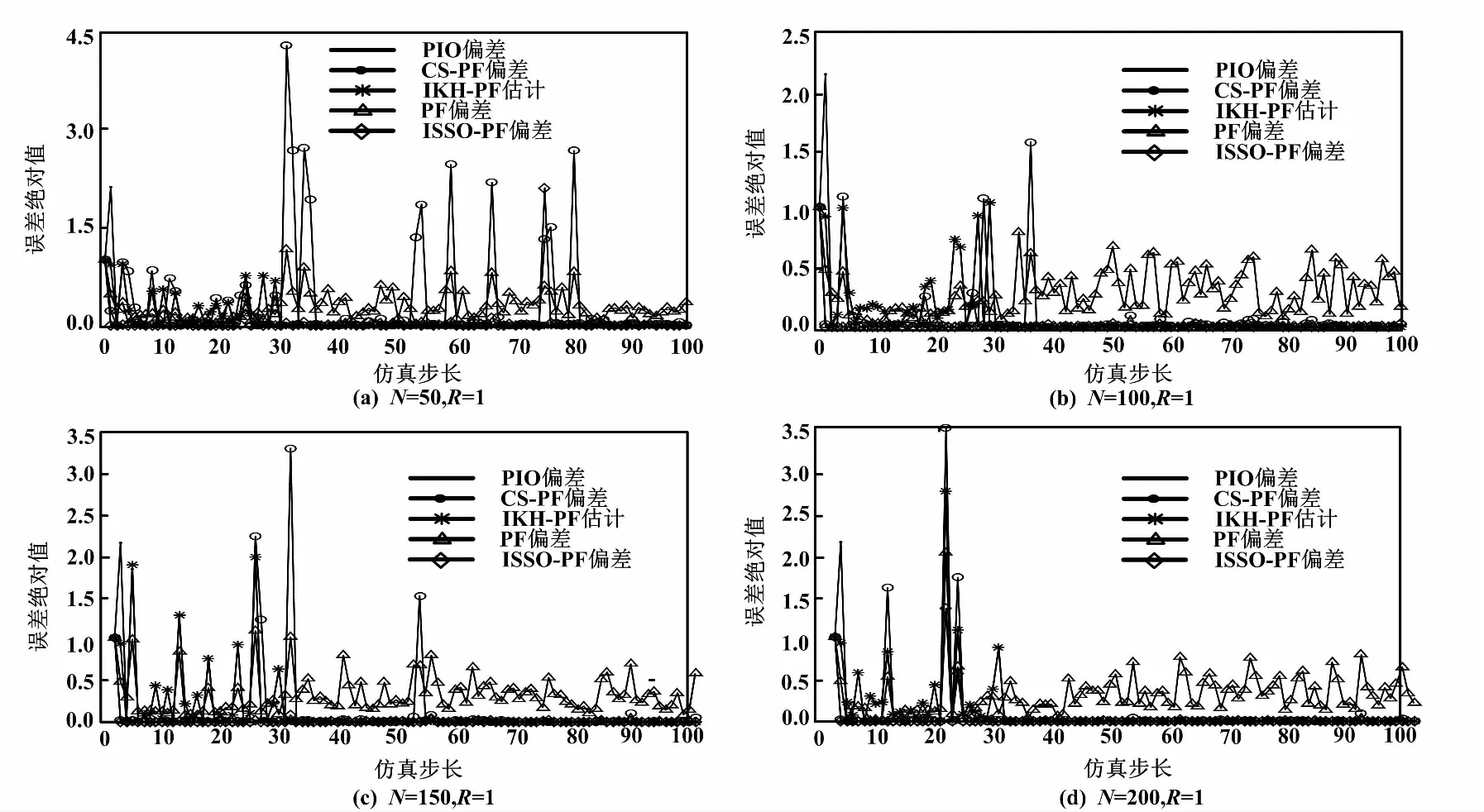
圖2 估計誤差絕對值
(2)在R=5的條件下,再進行一組試驗,整體誤差對比如表1所示。
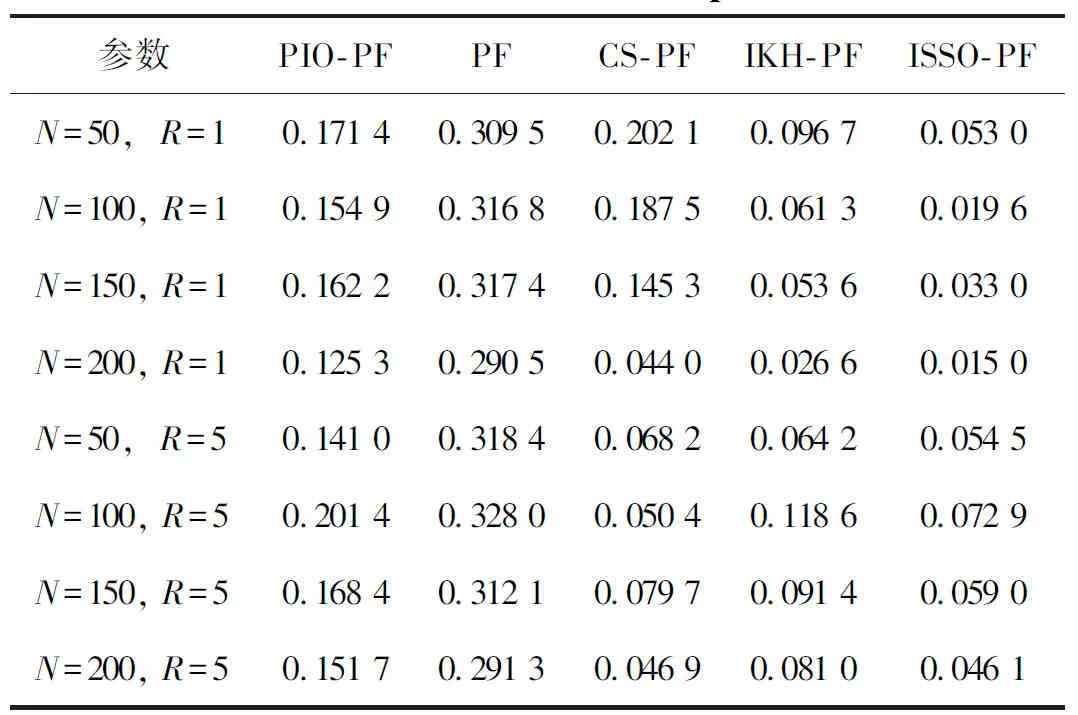
表1 整體誤差對比
4.2 粒子空間分布
R=1時,選取不同的粒子總數,粒子的狀態空間分布如圖3所示。
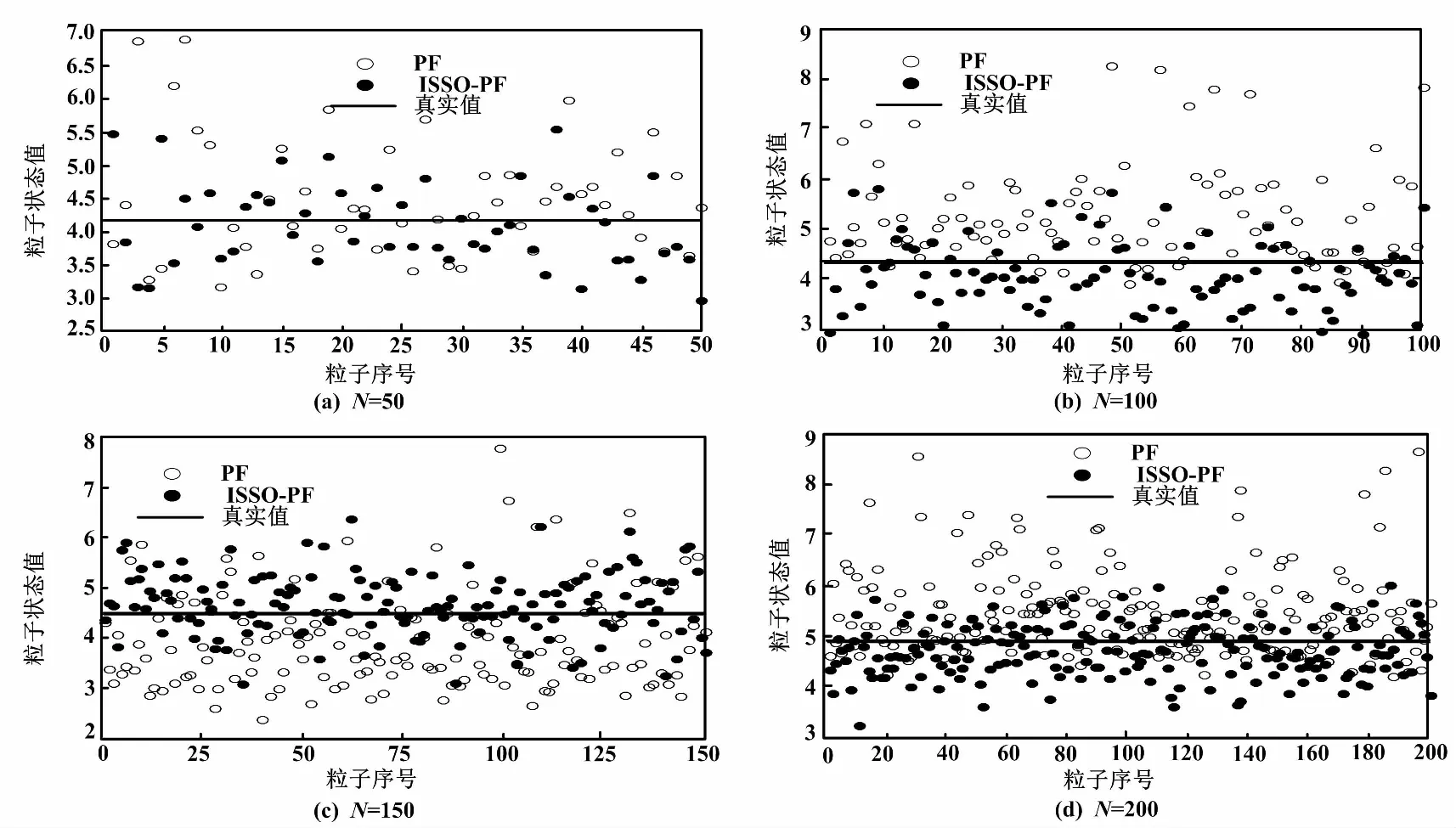
圖3 粒子的狀態空間分布
4.3 運行時間對比
針對上述不同的仿真情況,對各算法的運行時間進行統計。
運行時間對比如表2所示。
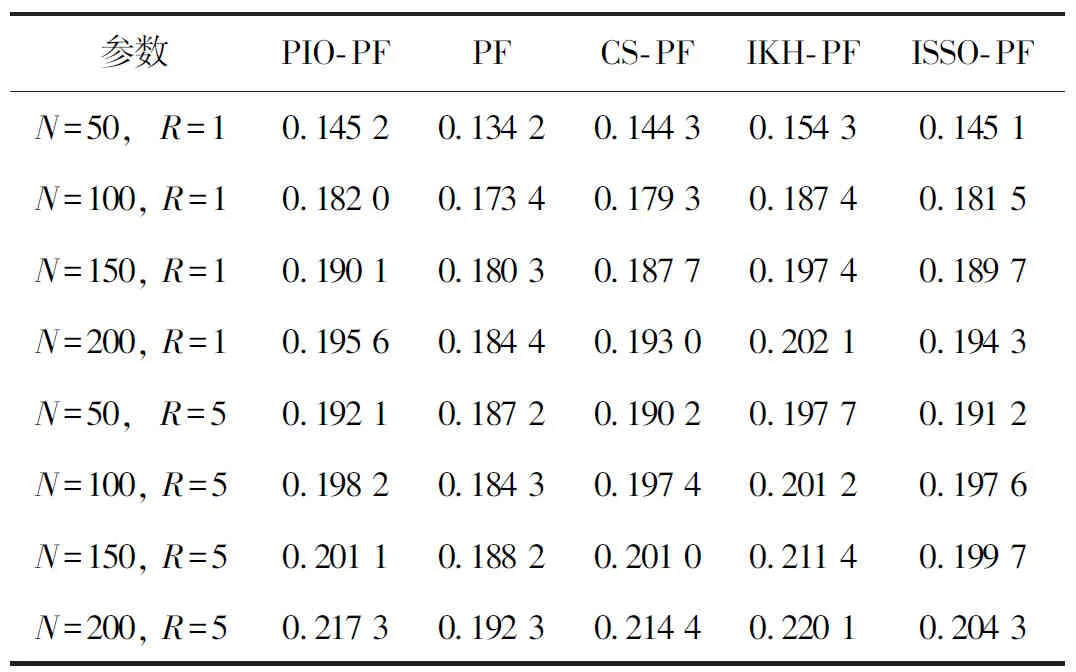
表2 運行時間對比
4.4 試驗結果分析
從圖1可以看出,5種算法都很好地跟蹤了系統的真實狀態。從圖2可以看出,對比5種濾波算法的誤差絕對值,ISSO-PF算法的誤差一直處于較低的水平,其他濾波算法均存在不同程度的誤差起伏。從表1可以看出,整體的改進濾波算法要比普通的粒子濾波算法的誤差更小,精度更高。算法誤差從低到高依次為ISSO-PF、IKH-PF、PIO-PF、CS-PF、PF。
從粒子的狀態空間分布可以直觀地看出粒子的狀態估計情況,從圖3可以看出,ISSO-PF可以很好地跟蹤真實值,而且隨著粒子數的增加,粒子的分布越廣,在真實值附近分布的粒子數越多。所以ISSO-PF算法在提高濾波精度、改善粒子貧化、增加粒子多樣性方面,均有很好的效果。
算法的運行時間能夠很好地體現算法的開銷問題。在算法實時性要求較高的情況下,該指標尤為重要。從表2可以看出,整體的計算時間消耗最低的是PF,然后依次是ISSO-PF、PIO-PF、CS-PF、IKH-PF。由此可知,濾波精度的提高是以運算時間為代價的,但是ISSO-PF的實時性能較其他改進算法,還是有較大改善的。
5 結論
為了改善粒子濾波的粒子退化、增強粒子多樣性,本文結合了SSO與粒子濾波算法的特點,采用改進的SSO優化粒子濾波的重采樣過程。為了改善粒子退化:一方面,依據有效粒子數,選擇是否進行重采樣;另一方面,在重采樣復制大權重粒子的過程中,在大權重粒子附近添加隨機粒子,保證粒子的多樣性。同時,利用群體突變、動態自適應權重調節,以及將遺傳算法中的交叉概率引入蜘蛛群繁殖的過程中,保證了算法的全局以及局部收斂能力。試驗結果表明,ISSO-PF算法提高了濾波精度,改善了粒子退化,增加了粒子多樣性。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
