基于貝葉斯優化的SWDAE-LSTM滾動軸承早期故障預測方法研究
2021-10-11 09:50:08石懷濤尚亞俊白曉天
振動與沖擊 2021年18期
石懷濤,尚亞俊,白曉天,郭 磊,馬 輝
(1.沈陽建筑大學 機械工程學院,沈陽 110168;2.東北大學 機械工程與自動化學院,沈陽 110819)
旋轉機械是現代工業、民用和軍事應用中最常見的機械類型[1-2],而滾動軸承是其核心部件之一,極易在長期運行中由于安裝、溫度、潤滑等因素受到損傷[3]。若早期故障未得到有效識別與及時解除,旋轉機械的精度將不斷降低,直至系統完全損壞,甚至引起不可挽回的后果。
很多有效的傳統滾動軸承故障診斷方法依靠旋轉機械的運行振動信號對其進行故障診斷[4-6],對其時域、頻域及時頻域進行分析,如振動分析、溫度分析以及油液分析等。其中振動分析是最具說服力的方法,從振動信號中提取大量的特征參數作為傳統故障診斷的標準。時域特征(均方差根、峭度)被廣泛應用于軸承性能評估[7-9]。Chen等[10]提出基于均方差根值(root mean square,RMS)的時域統計指標用在滾動軸承狀態識別中,RMS反映的是信號能量,振幅值隨時間變化的越緩慢,其效果越明顯,很明顯對早期故障不敏感。袁云龍等[11]基于峭度(Kurtosis)的時域統計指標來進行滾動軸承狀態識別,峭度對沖擊信號的有較大的反應,所以對早期異常故障信號有較高的敏感性,但對于微小波動的情況,可能出現敏感度過高造成評估滾動軸承故障的可靠性產生影響。而滾動軸承振動信號隱含的特征信息非常多,特征信息的提取是滾動軸承的關鍵。采用多種時域特征,研究滾動軸承運行狀態與振動信號之間的關系。其中,RMS和Kurtosis是最常見的時域特征方法,因為它們能有效地反映滾動軸承運行振動的實時變化。但是,滾動軸承運行過程中振動的不確定性引起的波動對軸承運行狀態的預測有很大的影響。時域特征分析不再利于滾動軸承的早期故障預測。
深度學習能自動學習豐富而有區別的特征,具有強大的特征提取能力,使其在故障診斷領域的應用成為了可能。李恒等[12]提出將滾動軸承振動信號進行短時傅里葉變換,使用得到的時頻譜樣本訓練卷積神經網絡(convolutional neural networks,CNN),對不同類型的故障有較高的識別精度。Zhang等[13]提出的單類支持向量機(support vector machine,SVM)方法雖然能夠向高維空間中進行映射,對于大規模的訓練數據比較困難,尤其是進行超參數的智能調優的過程時,會投入大量的時間和精力。以上神經網絡模型訓練的樣本之間是相互獨立的,數據之間具有的時序相關性被忽略。長短時記憶[14](long short-term memory network,LSTM)網絡是一種特殊的循環神經網絡(recurrent neural network,RNN),在涉及序列數據廣泛的機器學習問題中是有效的[15]。杜小磊等[16]提出了一種基于深層小波卷積自編碼器和LSTM的軸承故障診斷模型,利用小波自編碼提取故障特征進行LSTM網絡訓練,進行故障診斷。趙建鵬等[17]使用經驗模態分解數據進行特征參量的提取,并輸入到LSTM網絡中預測下一刻旋轉機械的工作狀態。但這些方法都存在網絡模型使用簡單,提取數據的時序關聯特性機理不確切等問題。
越深的網絡和越多的節點個數往往會使學習效果和擬合效果越好,但也會增加超參數的個數。超參數是模型訓練開始前設置的一系列參數,例如隱藏層的數量、每層的節點個數、迭代次數和學習率等,模型的超參數具有選取困難、沒有規律性的特點,而且不同超參數之間存在無法預知的影響,每個超參組合的評估需要進行大量的迭代計算。不同的超參數組合會影響模型的最終準確率和平穩性,通常需要大量的超參數試驗來確定模型最終的超參數組合,耗費大量的時間和精力。
網絡模型的超參數優化策略[18-19]對模型的精度影響很大,網格搜索方法[20-21]是最早的自動搜索超參數的方法,網格搜索是一種帶有步長的窮舉方法,通過不斷縮小網格的步長增大搜索空間最大程度上找到模型的最優解,但是網格搜索只適合數據集較小的模型,一旦數據規模增大,就會很難得到最優解,甚至會出現“指數爆炸”的問題。Bergstra等[22]提出隨機搜索方法,將超參數選擇問題轉變成函數優化問題,按照概率分布抽取初始值,進行計算得到最優解或者近似最優解,適用于數據集較大的情況,但隨即搜索得到的結果之間差異較大。網格搜索和隨機搜索均為目標函數可導的優化方法,對于目標函數表達式未知等復雜的優化問題,提出了智能優化方法與深度學習模型相結合的方式,如Yan等[23]用遺傳算法來優化人工神經網絡模型的超參數,Li等[24]用量子遺傳算法優化神經網絡,李甜甜[25]用粒子群算法和模擬退火算法來優化SVM中超參數等。但遺傳算法和粒子群算法均屬于群體優化算法,需要足夠多的初始點來進行訓練才能有效地搜索到最優解,訓練效率不高。本文使用貝葉斯優化(Bayesian optimization,BO)[26]方法,因BO網絡只需對目標函數進行次數很少的評估就能獲得最優解,非常適用于求解目標函數表達式未知以及評估代價高昂的復雜優化問題,且不需要大量的采樣點便可以得到最優解,適合深度學習模型的超參數調優問題[27]。
基于以上分析,本文提出了一種基于貝葉斯優化的滑動窗堆疊去噪自編碼器(sliding window stacked denoising auto encoder,SWDAE)和LSTM網絡的早期故障預測模型(SWDAE-LSTM)的研究方法。在離線建模階段,為了保證堆疊去噪自編碼(stacked denoising auto encoder,SDAE)提取特征的精確性,使用滑動窗算法對數據進行預處理,之后將數據輸入到SDAE網絡進行滾動軸承故障特征的提取,并固定訓練好的SDAE,將經過SDAE重構的數據集作為LSTM的輸入,進行LSTM網絡的訓練,進一步學習數據之間的時序特征。之后將訓練好的SDAE-LSTM模型用于在線監測,去掉LSTM最后一層分類層,實時在線數據輸入到SDAE-LSTM網絡,訓練得到下一時刻的預測值,而這一時刻的真實值來源于實際的運行數據,數據實時輸入到模型中,與訓練得到的預測值進行殘差計算來重構誤差,來判斷滾動軸承的運行狀態。對于SDAE和LSTM的精度與其超參數組合的關系,我們在貝葉斯優化階段使用貝葉斯優化算法對模型的超參數進行智能調參,BO可以在迭代中尋求最優解,在節省了大量的時間和精力的同時,使模型的精確度和平穩性達到最優,從而使模型能夠更全面地學習滾動軸承數據的特征。利用辛辛那提大學智能維護中心提供的數據進行了實驗仿真,仿真結果表明,基于貝葉斯優化的SWDAE-LSTM模型可以很好地描述滾動軸承的運行狀態,更早更穩定的預測出滾動軸承的早期故障,這對于滾動軸承運行狀態的退化監測非常重要。同時,利用旋轉機械綜合模擬實驗臺證明了本文提出方法的有效性和可靠性。
得益于SDAE模型的特征提取能力與LSTM模型的數據特征提取能力,本文對滾動軸承早期故障預測的主要貢獻如下:
(1)利用貝葉斯優化算法對模型的超參數進行智能調參,使模型的超參數得出最優解,在節省了大量時間和精力的同時,使模型的精確度和平穩性達到最優。
(2)利用滑動窗算法對滾動軸承的數據進行預處理,使輸入到網絡模型中的數據長度保持一致,使SDAE能更好的提取滾動軸承的數據特征,同時保證了數據之間的時序相關性,使模型能更好的對滾動軸承早期故障的出現進行預測。
(3)將無監督的SDAE網絡對滾動軸承振動信號的特征進行提取,去掉LSTM網絡最后一層分類層,提取數據之間的時序關聯特性,并利用滾動軸承序列數據的完整歷史軌跡對滾動軸承的運行狀態進行監測,進一步預測滾動軸承早期故障的出現。
1 優化的SWDAE-LSTM理論
1.1 堆疊去噪自動編碼器
自動編碼器(auto encoder,AE)是一個無監督的特征表達網絡,由輸入層(x)、隱藏層(h)和輸出層(r)組成。AE的目的是通過編碼和解碼的過程重構數據,使輸出數據與輸入數據之間的誤差最小。去噪自編碼器(denoising auto encoder,DAE)是AE的一種改進方法,DAE從被損壞或加入噪聲的數據樣本中重建數據。AE從輸入層到隱藏層的編碼公式為
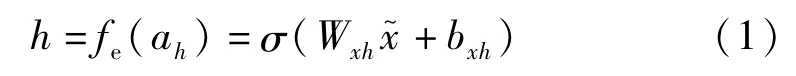
式中:fe()為輸入層到輸出層的編碼函數;σ()為Sigmoid激活函數;Wxh為其權重值;bxh為其偏移值。
AE從隱藏層到輸出層的解碼公式為
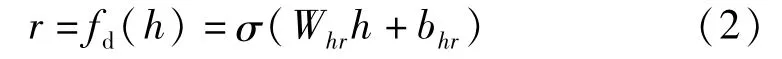
式中:fd()為隱藏層到輸出層的解碼函數;Whr為其的權重值;bhr為其偏移值。
AE的中心思想是通過編碼和解碼,使輸入數據和輸出數據保持一致,因此AE的損失函數為
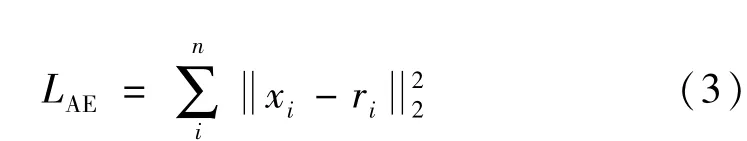
未處理的振動信號含有大量的噪聲,初始故障的信號特征較弱,需要通過DAE處理去除了信號中的大部分噪聲,以及隱藏層從信號中提取魯棒特征。
將多個DAE堆疊便得到SDAE,在訓練模型時,上一個DAE的輸出作為下一個DAE的輸入,以此類推,直到所有的DAE訓練結束,得到一個堆疊而成的深層網絡。經堆疊而成的SDAE網絡在高維度、非線性輸入數據特征的提取上具有很強的魯棒性。
1.2 長短時記憶網絡
長短時記憶網絡是一種特殊的RNN網絡,既有RNN網絡所具備的時序關聯特性,并且通過門控循環單元 來控制網絡中神經元間的歷史信息傳輸,解決了傳統RNN網絡梯度消失和梯度爆炸的問題。
圖1為LSTM網絡的基本結構,由輸入門、遺忘門和輸出門來完成LSTM每個神經單元工作狀態的修改和輸出,并由GRU在內部控制有效信息的記憶和傳遞。其中,遺忘門決定(t-1)時刻的單元狀態有多少被保留到t時刻。輸入門決定單元狀態的更新。在遺忘門和輸入門更新了單元狀態之后,由σ()非線性激活函數和輸出門來決定LSTM神經單元狀態的輸出。一個LSTM細胞的計算過程如下:
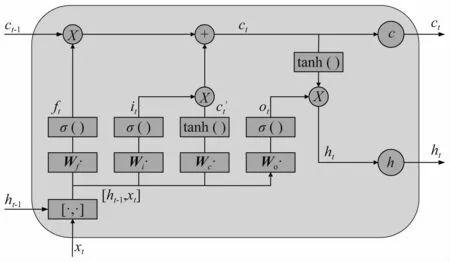
圖1 LSTM細胞圖Fig.1 LSTM structure
遺忘門
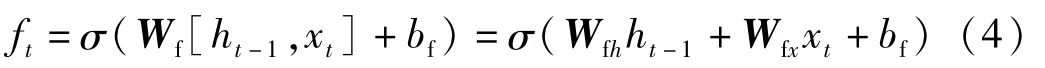
式中:ft為遺忘門;Wf為遺忘門的權重矩陣;bf為遺忘門偏置項。
輸入門
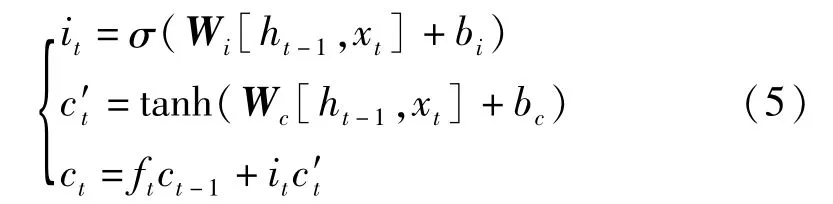
式中:it為輸入門;c′t為當前輸入的單元狀態,最后計算出當前時刻的單元狀態ct。
輸出門
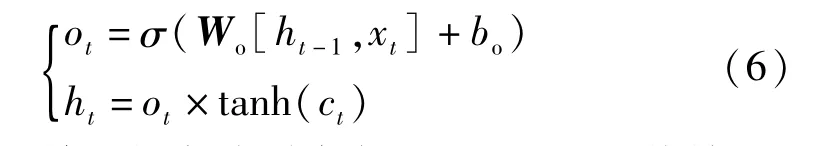
輸出門和單元狀態共同決定了LSTM的最終輸出。
1.3 SWDAE-LSTM網絡
綜上所述,我們將SDAE網絡和LSTM網絡組合來構建神經網絡模型。如圖2所示,為SWDAE-LSTM網絡框架。
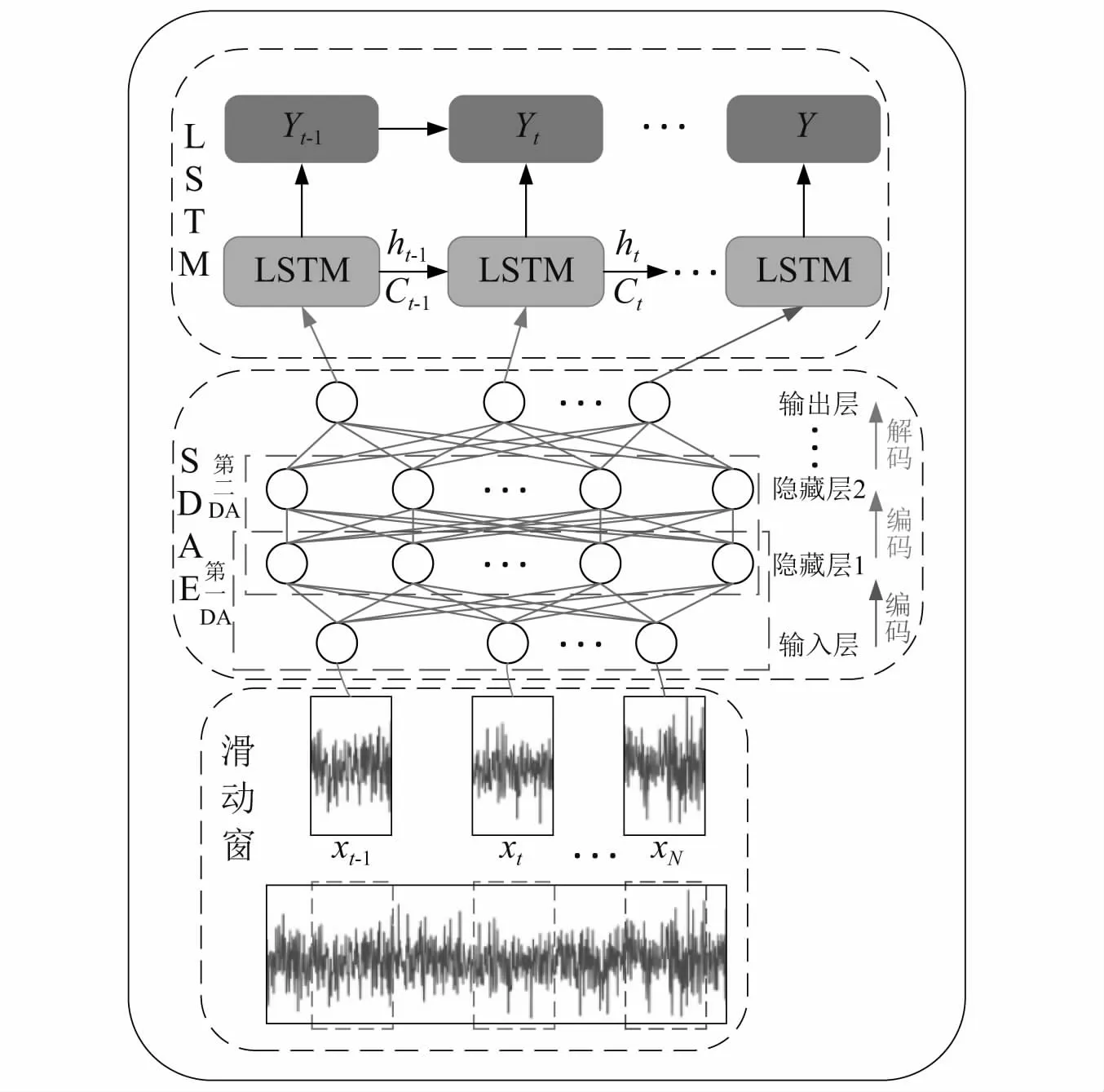
圖2 SWDAE-LSTM網絡結構Fig.2 SWDAE-LSTM network structure
該模型主要由輸入層、特征提取層和預測層組成。滑動窗按照一定的步長和移動速度將數據進行堆疊劃分,產生X={X1,X2,…,Xt-1,Xt,…,XN}輸入數據集,將處理好的數據集輸入到SDAE網絡當中,按照式(1)~式(3)訓練SDAE網絡,利用SDAE網絡捕獲數據更多有用的隱藏模式,并從原始數據中獲得更強的魯棒性以及數據之間的時序依賴特性。將訓練好的數據作為LSTM網絡的輸入,按照式(4)~式(6)進行LSTM網絡訓練,生成序列數據,對數據進行預測。
1.4 貝葉斯優化算法
貝葉斯優化針對深度學習模型超參數目標函數表達式未知、搜索代價高昂的復雜優化問題,使用一個不斷更新的概率模型,通過少數次的目標函數評估來更新優化函數的后驗概率,得到最優的模型超參數組合。模型的超參數組合選擇可表示為
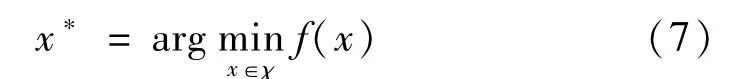
式中:f(x)為最小化的目標函數,用于評估目標函數的最優性能;x*為最后獲得的最優超參數組合。
貝葉斯優化源于貝葉斯定理,利用BO公式建立優化過程的概率分布
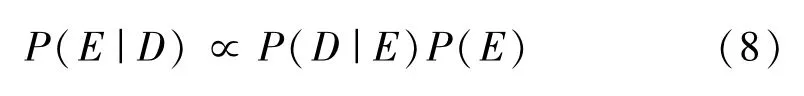
式中:P(E)為高斯分布;P(D|E)為一個高斯回歸過程。可由核矩陣∑來確定,∑由核函數定義,其表達式為
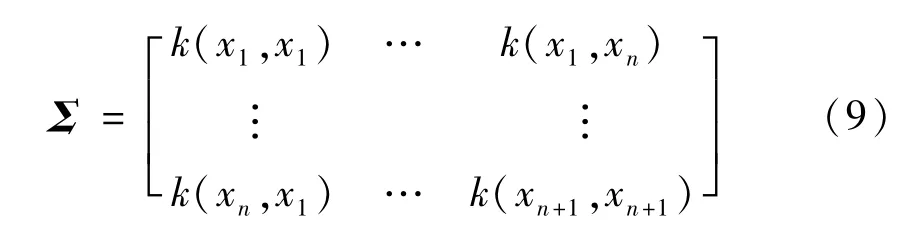
BO超參數的目的就是通過不斷地迭代得到一個最優的超參數組合,即x*=xn+1使模型的精度達到最優。
2 BO的SWDAE-LSTM滾動軸承早期故障預測
2.1 基于BO的SWDAE-LSTM
基于以上研究,SDAE網絡在故障特征提取方面具有很強的魯棒性,LSTM網絡能夠學習數據之間的時序關聯特性,將SDAE與LSTM網絡組合為一個網絡模型,來描述滾動軸的運行狀態,正確的狀態描述是解決滾動軸承早期故障預測的最優方式。為了保證SDAE網絡特征提取的有效性,本文引入了滑動窗算法對數據進行預處理,保證了SDAE網絡對提取特征的魯棒性。貝葉斯優化可以不斷更新超參數,只需經過少次目標函數評估即可獲得理想解,適合深度學習模型的超參數調優問題。因此本文選用BO算法優化模型的超參數,滑動窗算法進行數據預處理,LSTM與SDAE組合來構建深度神經網絡模型。
2.2 BO的SWDAE-LSTM模型流程
基于BO的SWDAE-LSTM模型的構建包括貝葉斯優化階段、離線建模階段和在線監測階段,貝葉斯優化階段由超參數初始點開始進行模型訓練,并不斷更新超參數組合,直到模型的精度滿足要求。離線建模階段利用經滑動窗預處理的歷史正常數據進行SDAE迭代訓練,保存訓練好的SDAE之后訓練LSTM,去除LSTM的分類層將LSTM網絡作為序列生成器,可以輸出數據變成與輸入數據維度相同的序列數據。在線監測階段,將實時在線數據輸入到訓練好的SWDAE-LSTM模型中,進行滾動軸承下一時刻運行狀態的預測并輸出其預測值,將其預測值和在線數據進行殘差計算使誤差重構,當前的運行狀態是否在正常范圍之內通過支持向量數據描述(support vector data description,SVDD)來判斷,若正常則繼續監測,否則報警。如圖3所示,為滾動軸承早期故障預測流程圖(3個階段:貝葉斯優化調參、離線建模和在線監測)。
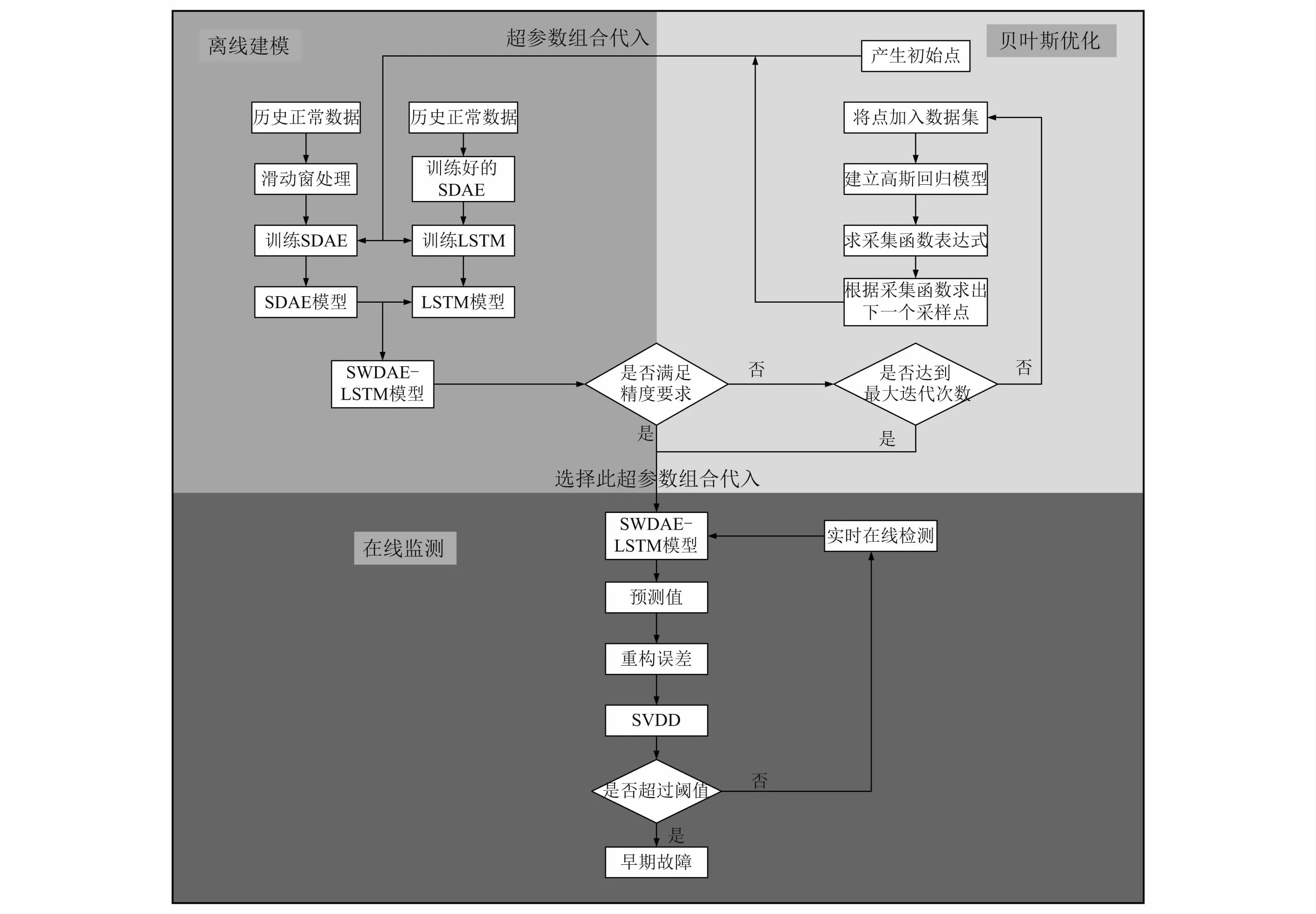
圖3 滾動軸承早期故障預測流程圖Fig.3 Rolling bearing early fault prediction flow chart
(1)貝葉斯優化階段:
步驟1根據要優化的超參數,設置n個初始點Xn=[X1,X2,…,Xn],作為模型的初始化超參數,并代入SWDAE-LSTM模型中進行訓練。并計算Xn在目標函數上的響應值Yn=[Y1,Y2,…,Yn],構建數據集D={(X1,Y1)…(Xn,Yn)}。
步驟2在模型的驗證集上判斷模型是否滿足精度要求,若滿足則模型超參數為Xn,否則判斷模型是否達到最大迭代次數,若滿足則該模型超參數為Xn,否則循環執行貝葉斯優化迭代。
步驟3利用D數據集,建立高斯回歸模型GP。
步驟4基于GP,通過采集函數u(X),進行采樣點Xn+1的計算。
步驟5使用新得到的采樣點Xn+1作為模型超參數,進行模型訓練,并得到模型的響應值Yn+1。
步驟6判斷是否滿足精度要求。若不滿足循環執行步驟2~步驟6;滿足則確定超參數為Xn+1,停止迭代。
(2)離線建模階段:
步驟1采集滾動軸承正常狀態下的振動信號,作為歷史正常數據x。
步驟2在歷史正常數據上運行長度為ω的重疊滑動窗口,得到一個新的擴展時間序列數據Y。
步驟3將新的數據集Y作為SDAE輸入數據,將初始化參數作為模型的超參數。根據第2章式(1)~式(5)對SDAE進行訓練。
步驟4固定訓練好的SDAE,并將重構的數據作為LSTM的輸入數據ej,進行LSTM訓練。
步驟5訓練LSTM時,輸出與輸入數據維度相同的預測序列,并不斷更新SWDAE-LSTM模型的超參數以及參數。
步驟6判斷模型的精度是否滿足要求。若不滿足,循環執行步驟1~步驟5;滿足則停止訓練。
(3)在線監測階段:
步驟1將實時數據輸入到訓練好的SWDAE-LSTM模型中,輸出下一時刻的預測數據nt。
步驟2將輸出的預測值nt與實時數據的真實值進行殘差計算,產生重構誤差J(θ)。
步驟3將重構誤差經過SVDD,判斷重構誤差是否超過SVDD設置的閾值,若超過,則滾動軸承出現早期故障,進行報警,否則繼續循環步驟1~步驟5。
3 滾動軸承早期故障仿真實驗與分析
為驗證基于貝葉斯優化的SWDAE-LSTM模型對滾動軸承早期故障預測的診斷效果,分別利用來自美國辛辛那提大學智能維護中心(IMSCenter)的軸承全生命周期數據以及機械故障綜合模擬實驗裝置獲取的數據進行仿真實驗及分析。如圖4所示,為滾動軸承全壽命試驗臺,軸承測試臺在一個由交流電動機驅動的軸上承載4個軸承(1#、2#、3#、4#),軸的轉速保持為2 000 r/min。為加速軸承老化,在徑向方向上,彈簧機構向軸和軸承施加了2 721.6 kg的載荷,油液循環系統可測量潤滑油的流量和溫度。此每個軸承箱上均安裝了振動加速度傳感器,數據采樣率為20 kHz,每隔10 min采樣一次并記錄。本文使用1#軸承的數據進行仿真試驗。
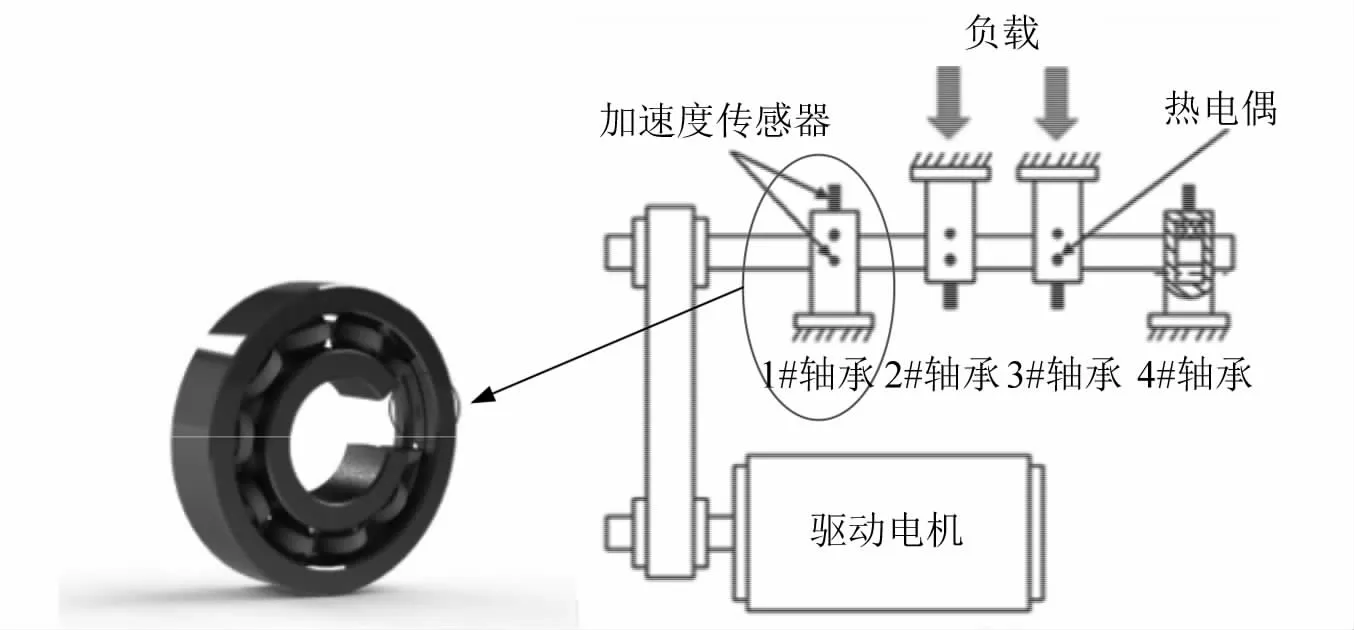
圖4 滾動軸承全壽命試驗臺Fig.4 Rolling bearing full life test stand
如圖5所示,為機械故障綜合模擬試驗臺,實驗臺主要由調速電機,加速度傳感器等構成。實驗中設置不同轉速下不同故障尺寸的滾動軸承實驗,分別在轉速為1 200 r/min,2 400 r/min,3 600 r/min,選取故障直徑為0.2 mm,0.3 mm,0.5 mm的滾動軸承,故障的位置包括滾動軸承的外圈、內圈和滾動體,在信號采樣頻率為12 kHz下采集振動信號。

圖5 旋轉機械故障綜合模擬實驗臺Fig.5 Rotating machinery fault comprehensive simulation test bench
3.1 實驗數據
由美國辛辛那提大學智能維護中心提供的軸承全生命周期數據可知,共包含3個試驗,在轉速相同的條件下每個實驗出現明顯故障時停止實驗,最后整理試驗數據集如表1所示。
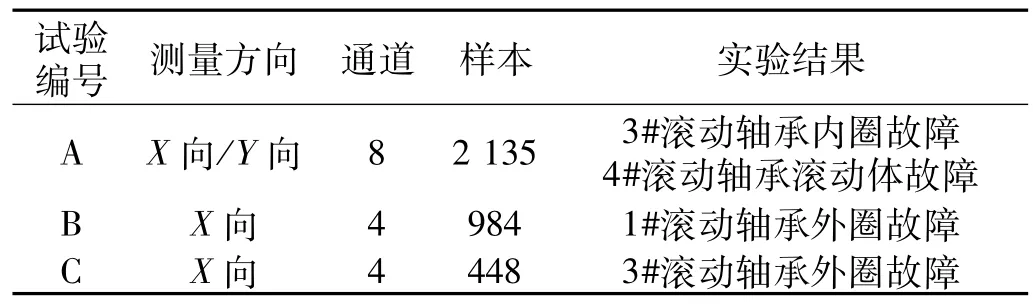
表1 滾動軸承全生命周期數據集Tab.1 Rolling bearing full life cycle data set
其中,每個樣本中有20 480點,通過表1可以看出,在相同的實驗設備、實驗環境以及滾動軸承等條件下,實驗中的每組滾動軸承發生故障的位置是不同的,并且故障出現的時間也是不一樣的。因此說明滾動軸承的故障具有不確定性,人為的歷史經驗很難做出準確的判斷。
以實驗B(1#滾動軸承)的數據作為本文實驗仿真使用的數據,共包含984個樣本,其中每個樣本中包含20 480點。選擇樣本文件的前400個1#滾動軸承的正常運行數據作為模型的訓練數據,后584個1#滾動軸承的退化過程數據用于測試模型的性能。為了保證實驗結果的有效性和準確性,通過計算采樣頻率和電機轉速可以得出,滾動軸承在實驗中旋轉一周可以采集600個采樣點,將數據按照其周期性將數據輸入到模型進行訓練和測試。
由機械故障綜合模擬實驗臺可得數據集,為了進一步驗證SWDAE-LSTM方法的有效性和可靠性,我們使用采樣頻率為12 kHz,故障直徑為0.2 mm的條件下,3種不同的轉速的滾動軸承故障數據,數據類型共10組,最后整理實驗數據如表2所示。
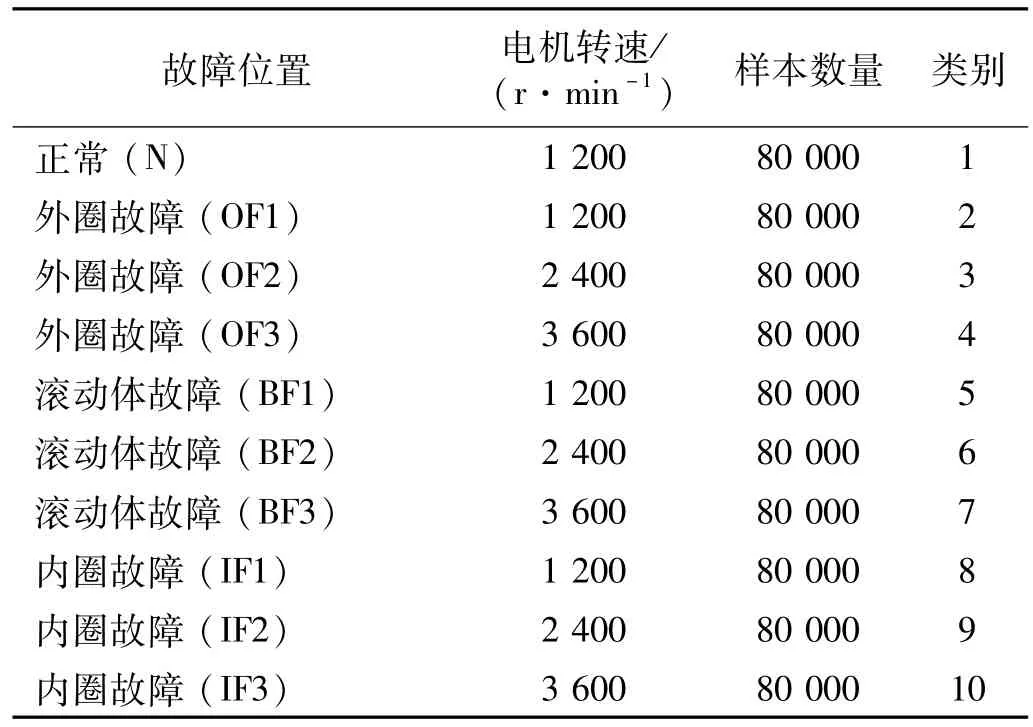
表2 滾動軸承故障數據Tab.2 Rolling bearing fault data
數據集中共有80 000個采樣點,將每200個采樣點劃分為一個樣本,每個故障包含400個樣本,使用前300個樣本作為訓練集,后100個樣本作為測試集。
3.2 實驗方案
3.2.1 貝葉斯優化模型驗證
為了保證模型能更準確識別出滾動軸承早期故障,本文使用了貝葉斯優化算法進行智能調參。
根據訓練集的大小將隱藏層的個數設置為整數范圍3~5個,隱藏層神經元個數設置為300~600,并且每次按整百來調整搜索空間。LSTM的收斂速度和訓練精度對批量大小(Batchsize)的設置大小十分敏感,所以在待優化超參數選擇中,同樣需要對Batchsize進行優化,Batchsize的搜索范圍設置為90~200,并且每次按整百來調整搜索空間。目前神經網絡的主要優化函數有Adam、RMSProp、Nadam,經BO算法優化出最適合模型的優化函數。在激活函數sigmoid、tanh、relu中經迭代搜索出適合模型的激活函數。訓練一個大型的神經網絡時,為防止過擬合的發生,需引入Dropout歸一化。Dropout的大小決定了在訓練過程中神經元暫時被丟棄的概率,因此設置其搜索區間為0~0.9。由于本文提出的模型使用貝葉斯優化方法確定模型超參數,圖6顯示了貝葉斯優化算法優化模型中超參數的過程。
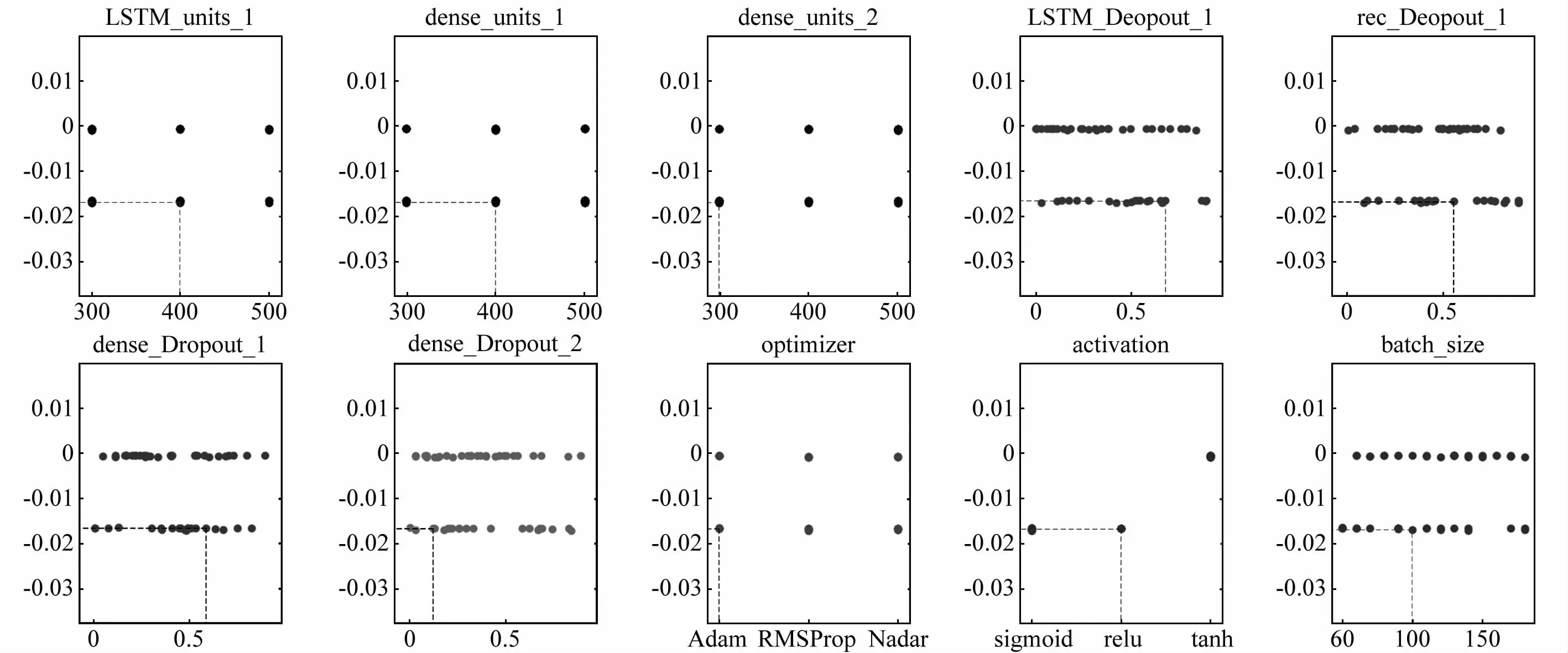
圖6 貝葉斯優化超參數過程可視化Fig.6 Visualization of Bayesian optimization hyperparameter process
圖6的橫坐標表示的是各待優化參數的選擇區間,分別為LSTM隱藏層神經元個數、SDAE第一層隱藏層神經元個數、SDAE第二層隱藏層個數、LSTM的Dropout歸一化大小、SDAE第一層隱藏層Dropout歸一化大小、SDAE第二層隱藏層Dropout歸一化大小、優化函數、激活函數、Batchsize的大小,縱坐標表示模型在驗證集上的均方誤差(mean-square error,MSE),通過參數估計值與參數真值之差平方的期望值的公式MSE=,來評價數據的變化程度,當MSE的值越小時,超參數預測值具有更高的精度。貝葉斯在優化參數的過程中使用高斯函數代替黑箱函數,并通過一致連續的局部平滑性弱假設,來得到最優解。平滑性弱假設使BO算法有效的利用區間鄰近信息進行更準確的推斷,從而選擇更具有“潛力”的點。圖6中的每個小框圖為每個超參數由BO算法在區間的搜索過程,即通過主動選擇策略來確定搜索區間當中最具“潛力”的點,圖6中的選中的點表示在設定好的區間內最具“潛力”的點,即超參數組合的最優解,可見,每個待優化超參數都會影響模型的最后精度。
在貝葉斯智能調參的過程中,為了顯示任意一組超參數對模型的影響及其調參過程的平穩性,添加可視化程序,圖中的曲線代表了在BO的過程中,經過多次迭代(如20次迭代)之后更新學習的超參數組合對SWDAE-LSTM模型的訓練損失率即平均損失誤差,如圖7所示,為模型的訓練損失和在驗證集的平均損失誤差。
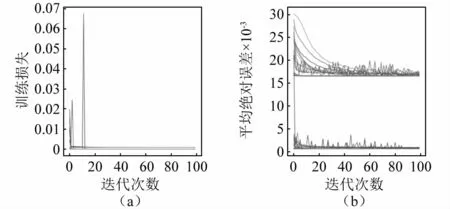
圖7 貝葉斯優化超參數訓練過程Fig.7 BO of the hyperparameter training process
圖7中的曲線代表了網絡模型使用貝葉斯算法在超參數空間選擇的一組超參數進行訓練的過程。在訓練損失圖中,圖中的任意一條曲線都代表了當前超參數組合進行迭代時的模型訓練損失,隨著貝葉斯的優化搜索,模型的訓練過程逐漸穩定其損失也降到最低。BO算法從過去的結果中進行推理來更新優化函數的后驗概率(參考式(7)~式(9)),不斷搜索到最優的超參數組合。從平均絕對誤差圖中可以看出,模型在驗證集的平均絕對誤差從0.017左右下降到0.002左右,迭代訓練過程也趨于平穩,可以證明BO算法選擇出了可以使模型精度顯著提高和泛化能力顯著增強的一組最優超參數,避免了手動調節超參數造成的大量時間損耗以及超參數組合的不平穩性。
為了驗證BO算法選擇出來的最優超參數組合的精度是否滿足要求,將優化出的超參數組合代入本文提出的模型中,得到振動信號訓練模型的損失下降圖,如圖8所示。
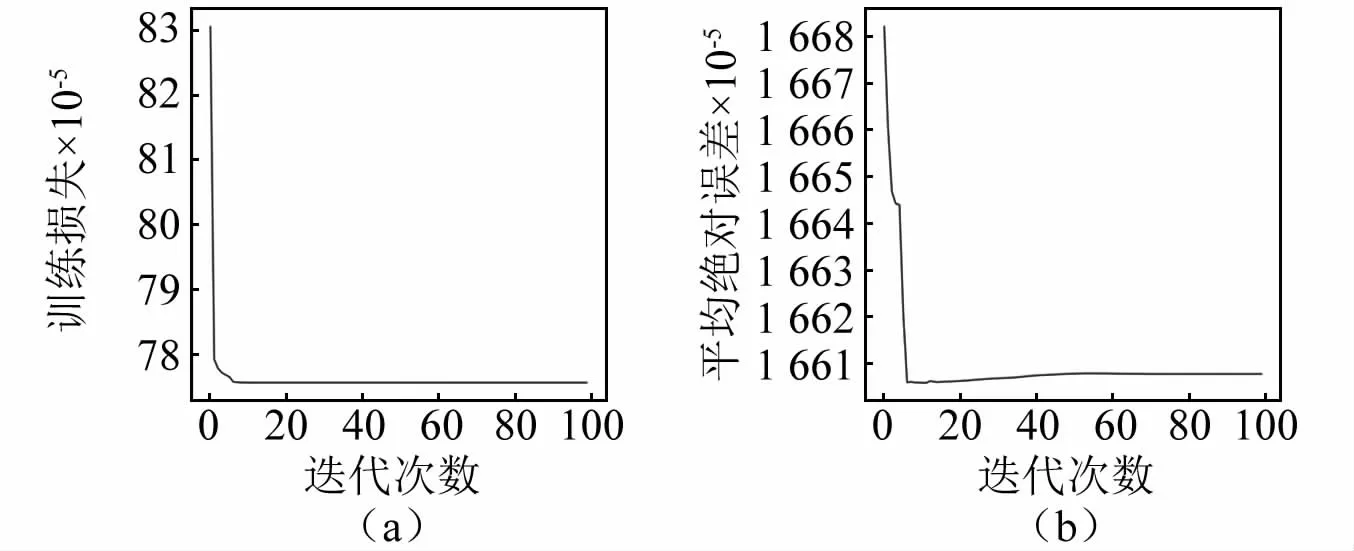
圖8 最優超參數模型訓練過程Fig.8 The training process of the optimal hyperparameter model
從圖8中可以看出,經過貝葉斯優化選擇出的超參數組合,在模型訓練過程中,模型的收斂速度更快且在收斂過程中波動較小。隨著迭代的完成,模型的訓練損失降到0.000 751,損失率為0.075 1%,準確率達到了99.91%,模型的平均絕對誤差降到0.016 59,此時模型提取數據的特征較為充分,精度高并且穩定。
驗證模型滿足精度要求后,在模型訓練超參數過程中添加顯示程序,訓練結束時顯示優化好的超參數組合,得到本文模型超參數組合如表3所示。

表3 經過優化的模型超參數Tab.3 Optimized model hyperparameters
3.2.2 滾動軸承早期故障預測
選擇實驗B的1#滾動軸承的運行數據進行仿真,如圖9為實驗B中1#滾動軸承全生命周期的原始時域振動信號圖。由圖中可以看出,滾動軸承在大約750個樣本(約125 h)前的時域信號是比較平穩的,在大約750個數據樣本之后時域信號出現了非常明顯的異常,即滾動軸承發生了較為明顯的損傷,并且之后時域信號出現了波谷現象,即滾動軸承外圈故障中典型的“治愈現象”,由于損傷出現后在循環力的作用下,損傷位置被短暫的磨合至光滑,之后出現重度損傷之后,滾動軸承不再被“治愈”直至失效。
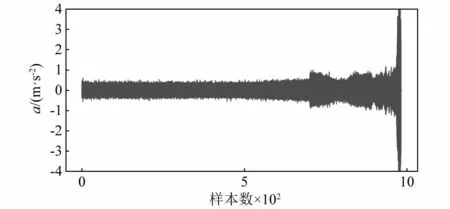
圖9 1#滾動軸承全生命周期振動信號Fig.9 1#rolling bearing full life cycle vibration signal
基于時域統計指標經常被用在滾動軸承狀態識別中,常用的時域統計指標有平均值,均方差根值和峭度。圖10分別為1#滾動軸承的這幾種時域統計指標值。
從圖10可以看出,圖10(a)平均值基本上不能有效反映滾動軸承的退化趨勢和故障狀態。從圖10(b)RMS值可以看出,大約從500個樣本(約83 h)左右開始有上升趨勢,反映了軸承退化的早期,信號幅值較正常狀態有了相對明顯的增加,但是加速度相對平穩增加,隨著損傷的加深,RMS值出現波動并逐漸增大。但是RMS沒有較大的變化峰值,曲線變化相對緩慢。圖10(c)Kurtosis值對沖擊信號較為敏感,在故障樣本出現時其信號幅值也產生了相對的突變,但不同于RMS,隨著故障的加深,其信號幅值波動較大,在退化末期更為敏感,軸承接近失效,而在退化早期沖擊信號并不明顯,所以相比較于RMS值,從Kurtosis值圖中沒有有效反映出滾動軸承的退化早期,并且在退化末期出現了下降的趨勢。

圖10 時域統計指標識別滾動軸承狀態Fig.10 1#rolling bearing full life cycle vibration signal
基于時域的統計指標雖然可以在一定程度下反映滾動軸承的退化趨勢,但是不能很好的反映滾動軸承早期故障的變化和退化后期的各個階段。將BO算法選擇出的最優超參數組合代入模型中進行訓練,如圖11所示,為本文提出的基于貝葉斯優化的SWDAELSTM模型對滾動軸承運行狀態的描述。

圖11 1#滾動軸承全生命周期描述曲線Fig.11 Full life cycle description curve of 1#rolling bearing
從圖11可以看出,經過BO算法優化的模型可以檢測到在第10 070個周期左右首先出現異常的測試數據較正常狀態信號幅值明顯增加(軸承運行90 h左右)。與圖8相比,提前了將近30 h發現軸承故障。然后數據趨于正常,直到第14 500周期左右異常信號出現之后異常的測試數據出現的時間間隔逐漸變短,且每次異常信號的幅值也逐漸增大,直至滾動軸承完全失效。這符合滾動軸承的生命周期(從正常到完全失效的過程)。與均方差根值和峭度統計指標的方法相比,經過BO算法優化的SWDAE-LSTM的模型可以很好的反映滾動軸承的早期故障的變化和退化的各個階段。即當滾動軸承的外圈出現初始異常時,隨著滾動軸承的繼續運行,外圈損傷將被滾動體不斷磨合,滾動軸承的異常信號會出現短期的相對正常的數據。隨著滾動軸承的繼續運行,并且重復損傷與磨合的過程,但是相對正常數據產生的時間間隔被縮短,直至不會再出現類似正常數據。
殘差是基于實時在線運行數據對滾動軸承的運行狀態進行監測的方法之一,訓練之后的SWDAE-LSTM網絡能夠預測下一時刻的振動數據,預測的振動數據與實時在線的輸入數據進行殘差計算,之后利用重構誤差來識別滾動軸承運行過程中的異常振動情況,如圖11可知,能夠提前30 h時監測出滾動軸承的異常振動信號。因此有理由相信殘差能夠為滾動軸承早期故障預測提供健康監測指標。
3.2.3 滾動軸承故障試驗
為了驗證SWDAE-LSTM網絡的有效性,我們使用故障程度最小的故障軸承數據集,數據集共包含了10組實驗數據,共4種滾動軸承的運行狀態:正常狀態、內圈故障、外圈故障、滾動體故障。為了保證模型的魯棒新和準確性,我們使用歷史正常數據對網絡進行訓練,之后將4種故障數據輸入到訓練好的模型中,使用重構誤差來判斷滾動軸承的運行狀態。
圖12中可以看出,4種故障中,外圈故障最為明顯,而其余兩種故障與滾動軸承正常狀態相差較小,較難區分。
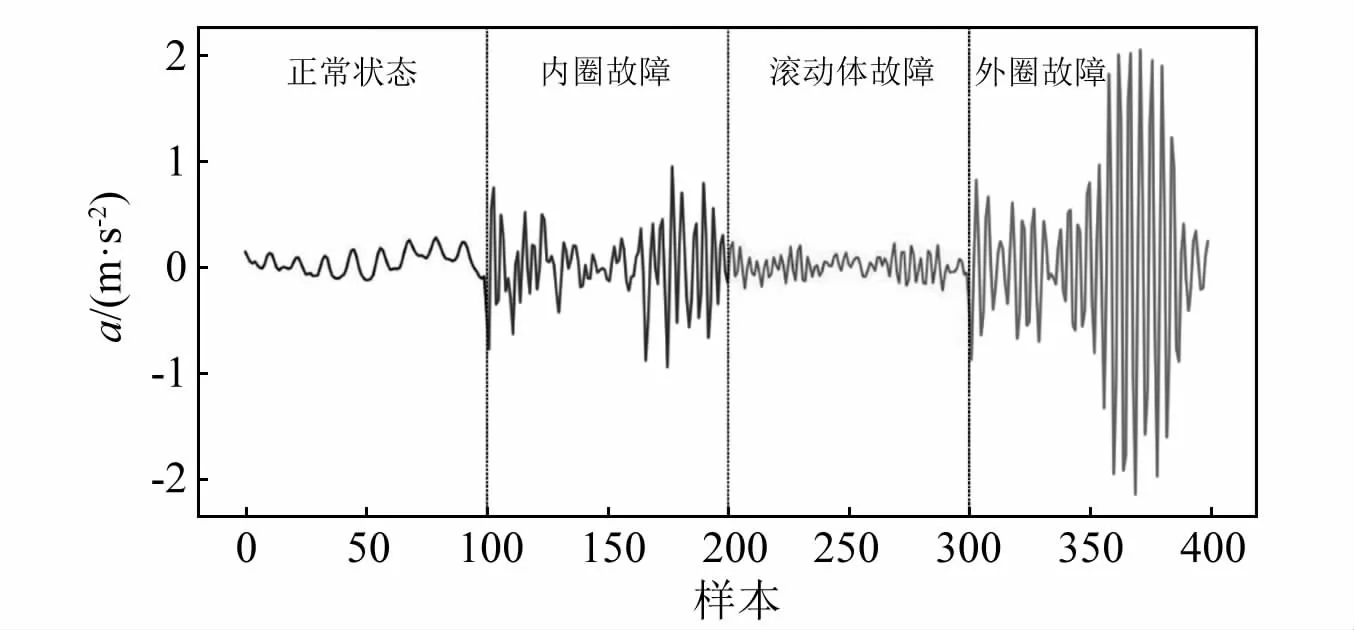
圖12 4種故障數據時域圖Fig.12 Four fault data time domain diagrams
圖13顯示了滾動軸承震動數據,經SWDAELSTM網絡重構誤差之后的結果圖。
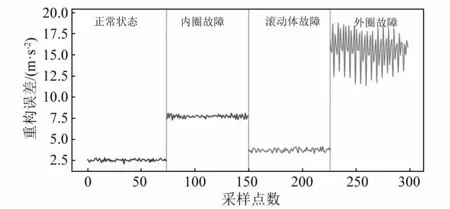
圖13 4種故障診斷的重構誤差Fig.13 Reconstruction errors of four fault diagnoses
如圖13所示,顯示了經過BO算法優化的SWDAE-LSTM網絡對滾動軸承進行故障診斷的結果,可以看出,正常狀態的重構誤差在2.5左右波動,而故障狀態的重構誤差大于正常狀態,在3.7~17.5波動,正常狀態的重構誤差與故障狀態的重構誤差具有明顯的差異,說明經過BO算法優化的SWDAE-LSTM網絡能夠將滾動軸承的正常狀態和故障狀態很好的分隔開來,同時,內圈故障的重構誤差在7.5左右波動,滾動體故障的重構誤差在3.5左右波動,外圈故障的重構誤差在12.5~17.5波動,每個故障的重構誤差都不存在重疊部分,可以證明本文提出的方法能夠有效的對滾動軸承的故障進行診斷。
3.3 仿真實驗結果對比
為了驗證本文提出的基于貝葉斯優化的SWDAELSTM(以下簡稱SDLSTM)方法的穩定性和先進性,將BO之后的SWDAE-LSTM算法與Kurtosis、RMS、SDAE+RMS、SDAE+Kurtosis進行了比較。
3.3.1 全生命周期數據仿真實驗分析
為了驗證本文提出的基于BO的SWDAE-LSTM模型的有效性,使用IMS數據集,將本文提出的模型與常用的是與特征提取的方法進行了比較。圖14中,①號線代表本文提出的經BO的SWDAE-LSTM算法,②號線代表Kurtosis統計指標,③號線代表RMS統計指標,④號線代表SDAE和RMS提取的特征,⑤號線代表特征由SDAE和Kurtosis提取。
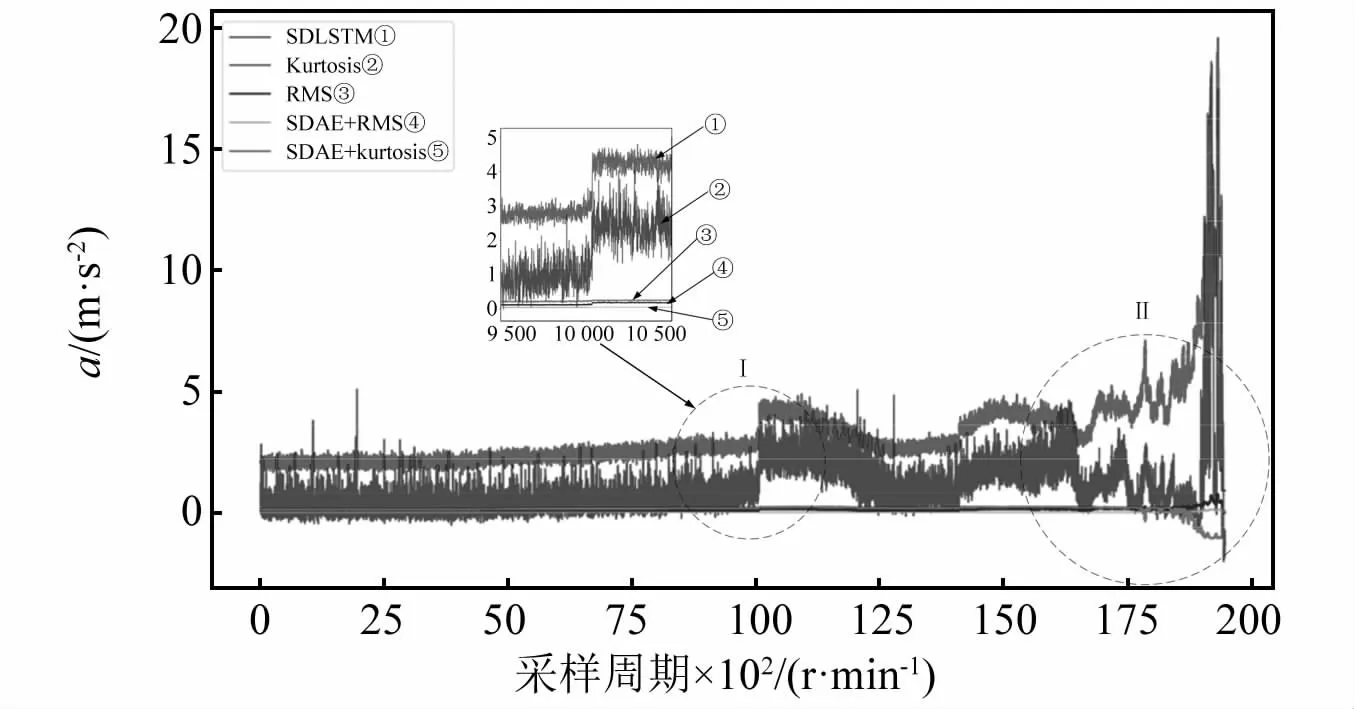
圖14 故障預測算法提取特征結果比較Fig.14 Fault prediction algorithm to extract feature results comparison
圖14描述了故障的發展,圖中Ⅰ、Ⅱ分別是早期故障階段和重度故障階段。從Ⅰ中可以看出,Kurtosis和本文提出的方法對初始異常的診斷有相似的效果,對于Kurtosis來說,它對信號的異常變化非常敏感,當滾動軸承運行異常時,振動信號會有一個瞬態尖峰,因此Kurtosis會有明顯的變化,但是會造成診斷結果不穩定,造成誤判的機率會增大。且從Ⅱ中可以看出,Kurtosis并不能很好地反映滾動軸承從早期故障到退化末期的逐步失效趨勢,對維修指導意義不大。所以不能為評估滾動軸承的狀況提供非常有價值的診斷特征。而對于RMS,在滾動軸承早期故障產生時其振動信號并沒有產生異常,在Ⅱ中看出,RMS只在故障產生的后期出現了波動,且波動幅度很小,所以不能作為評估指標來很好的反映滾動軸承的運行狀態。另外兩種方法(SDAE+RMS、SDAE+Kurtosis),由Ⅰ可以看出,雖然通過SDAE訓練,學習到了穩定的特性,但是對狀態變化并不敏感。而經過BO的SWDAE-LSTM算法不僅可以對滾動軸承早期異常非常敏感,并且可以反映滾動軸承后期的退化趨勢,在診斷過程中滾動軸承的信號穩定,因此能夠對滾動軸承早期故障進行預測。
3.3.2 定量對比分析
為了進一步定量驗證本文提出的基于貝葉斯優化的SWDAE-LSTM方法的有效性,利用SVDD來表示故障發生時的信號位置。同樣的,我們將SVDD與表4中的其他幾種方法結合起來,顯示每種方法的預測周期通過比較故障報警發生時的運行時間來評估不同方法的有效性。對實驗B中1#滾動軸承進行早期異常的預測,為了說明使用深度學習方法的先進性和有效性,使用單類的SVM方法和本文方法進行對比。預測的結果如圖15所示。
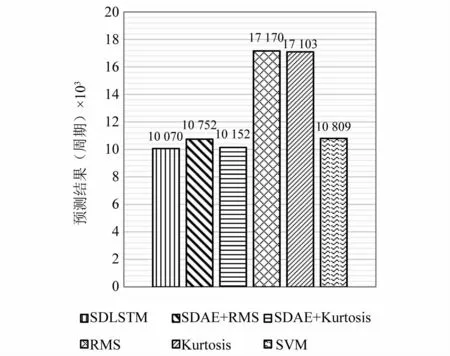
圖15 1#滾動軸承故障預測結果定量比較Fig.15 Quantitative comparison of failure prediction results of 1#rolling bearing
由圖15可以看出,經BO的SWDAE-LSTM模型可以在10 070個周期內進行故障報警。相比其他方法,BO算法優化的網絡的精度更高,能夠更早的發現滾動軸承的早期故障,效果優于其他方法。在RMS、Kurtosis這兩種方法結合了SDAE后,相對于直接使用統計指標RMS、Kurtosis的早期故障預測時間,雖然提前了約600個周期,提高了滾動軸承早期故障預測的效果,但仍滯后于本文所提方法。因此,經BO的SWDAE-LSTM模型可以更早的預測到滾動軸承早期故障的出現,能夠對滾動軸承早期故障進行預測,末期退化過程也得到良好反映,同時也表明SDAE提取的數據特征更加穩定。
3.3.3 滾動軸承故障診斷實驗分析
為了驗證經過BO算法優化的SWDAE-LSTM網絡的有效性和可靠性,將本文提出的方法與支持向量機自編碼、堆棧降噪自編碼、循環神經網絡、SDAE-RNN這幾種常見的故障診斷方法的結果分別進行對比。其中SVM的輸入維滾動軸承振動信號的16個時域統計特征和13個頻域特征,并且選擇SVM常用的損失函數L2,對于RNN、AE、SDAE、SDAE-RNN的輸入與本文提出的方法使用同一個輸入數據。同理,為了保證實驗的可比較性,我們將要對比的網絡的超參數有BO算法驚醒優化得出,如表4所示,為模型的部分超參數。
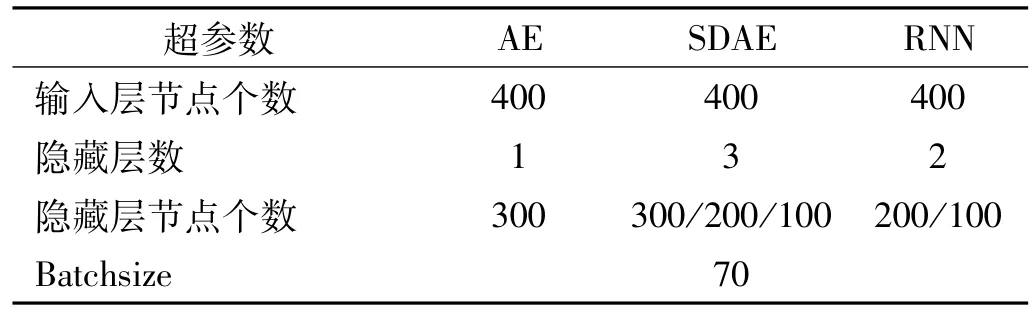
表4 不同方法超參數設置Tab.4 Different methods for hyperparameter setting
上述方法均使用Adam自適應學習率的方法對模型進行訓練,經過迭代訓練之后,得出每個方法所對應的準確率,如表5及圖16所示。
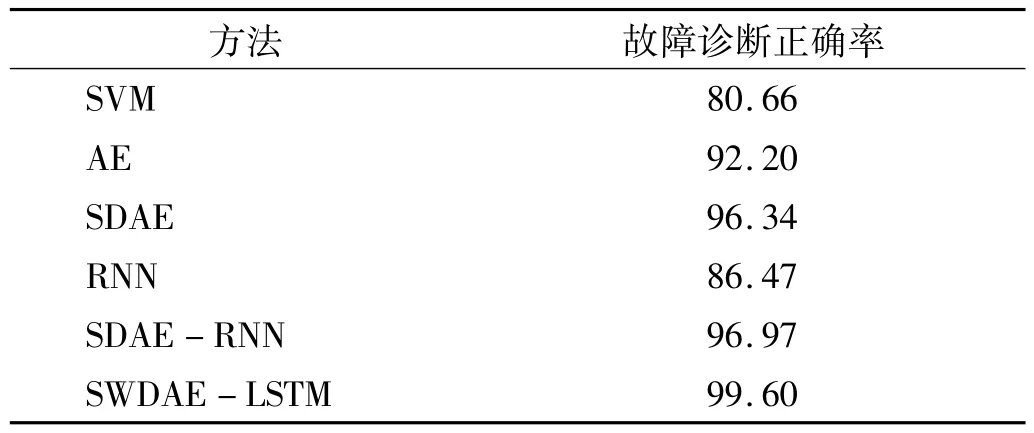
表5 不同方法診斷精度Tab.5 Different diagnostic accuracy methods %
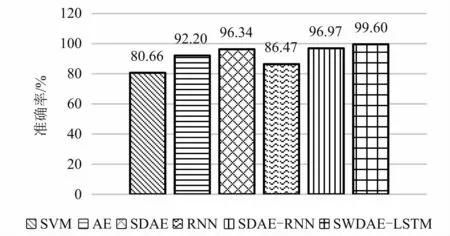
圖16 模型診斷結果Fig.16 Model diagnosis results
如圖16所示,為每種方法的故障診斷精度,SVM相比于其他深度學習其準確率較低,說明人工擬合特征結合模式識別并不能對故障進行準確識別,具有一定的局限性。AE與SDAE在特征提取方面其準確率由于RNN,SDAE經過多層非線性映射,相比于AE來說,其非線性特征提取能力較強。由于采用的輸入數據一致,但SDAE-RNN網絡的故障診斷準確率相比于SDAE-LSTM較低,在經過滑動窗之算法預處理的數據,保留了數據之間的時序關聯特性,LSTM能夠提取數據之間的時序關聯特性。綜上,SWDAE-LSTM網絡在故障診斷方面也具有很高的精度,證明經過BO算法優化的SWDAE-LSTM網絡的有效性和可靠性。
4 結 論
(1)簡述了滾動軸承早期故障診斷的重要性,指出傳統時域特征提取方法的不足,以及超參數組合對模型精度的影響,提出一種基于貝葉斯優化的SWDAELSTM網絡模型。
(2)提出的模型不僅可以學習數據的分布,保留數據之間的時序相關性,而且在超參數選擇方面,避免了手動調參費時和參數不確定性的問題,保證了模型的精度和準確率,能更好的監測滾動軸承運行狀態。
(3)經貝葉斯優化的模型與其他特征提取模型結合SVDD和單類別SVM方法相比,可以更早有效的預測出滾動軸承的早期故障,且具有很強的魯棒性,對于預測滾動軸承的早期故障和生命周期計算具有重要意義。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2018年11期)2018-08-04 03:25:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
