深度強化學習及在路徑規劃中的研究進展
2021-10-14 06:33:58張榮霞武長旭孫同超趙增順
計算機工程與應用 2021年19期
張榮霞,武長旭,孫同超,趙增順
山東科技大學 電子信息工程學院,山東 青島 266590
隨著機器人技術以及電子信息技術的發展,移動機器人的應用越來越智能化,智能移動機器人的一個重要特征是在復雜動態環境下可以進行良好的路徑規劃[1]。智能機器人路徑規劃是指在搜索區域內給出合理的目標函數,并在一定范圍內找到目標函數的最優解,使機器人找到一條從起點到目標點的安全無障礙路徑[2]。路徑規劃在許多領域有著廣泛的應用,如機器人機械手臂的路徑規劃[3]、無人機的路徑規劃[4]等。
傳統的路徑規劃方法,如人工勢場法[5]、A*算法[6-7]、蟻群算法[8-9]、遺傳算法[10]等,在復雜環境中無法處理復雜高維環境信息,或者容易陷入局部最優。
路徑規劃方法根據訓練方法的不同,可分為監督學習、無監督學習和強化學習[11]、監督學習和無監督學習在進行路徑規劃時都需要大量的先驗知識,否則無法進行良好的路徑規劃。強化學習(Reinforcement Learning,RL)是一種不需先驗知識并且與環境直接進行試錯迭代獲取反饋信息來優化策略的人工智能算法,并且能夠自主學習和在線學習,逐漸成為機器人在未知環境下路徑規劃的研究熱點[12-13]。傳統的強化學習方法受到動作空間和樣本空間維數的限制,難以適應更接近實際情況的復雜問題情況,而深度學習(Deep Learning,DL)具有較強的感知能力,能夠更加適應復雜的問題,但是缺乏一定的決策能力。因此,谷歌大腦將DL 和RL 結合起來,得到深度強化學習(Deep Reinforcement Learning,DRL),取長補短,為移動機器人復雜環境中的運動規劃問題提供了新的思路和方向。
深度強化學習具有深度學習強大的感知能力和強化學習智能的決策能力,在面對復雜環境和任務時表現突出,這有助于機器人的自主學習和避障規劃。2013年,Google DeepMind 提出深度Q 網絡[14](Deep Q-learning Network,DQN),是深度強化學習發展過程中的里程碑,它突破了傳統RL方法中基于淺層結構的價值函數逼近和策略搜索的學習機制[15],通過多層深度卷積神經網絡,實現了從高維輸入空間到Q值空間的端到端映射,以模擬人腦的活動。由于Agent 需要不斷與周圍環境進行交互,所以深度Q網絡(DQN)不可避免地面臨著學習大量網絡參數的需求,導致學習效率低下。針對這些問題,研究人員對DQN 算法從訓練算法、神經網絡結構、學習機制、基于AC 框架的DRL 算法等方面進行深入研究并提出了許多改進策略。
本文主要通過研究DQN及其改進算法在移動機器人路徑規劃中的研究進展,來闡述DRL 算法在路徑規劃中的演化過程。首先介紹DQN算法的工作原理及不足,然后根據DQN 算法的原理,從訓練算法、神經網絡結構、學習機制、AC框架多種變形這四類進行深入研究并歸納整理當前的改進策略,介紹移動機器人進行路徑規劃的其他強化學習算法,旨在為DRL算法在移動機器人路徑規劃的進一步研究提供依據,最后對DRL 算法在移動機器人路徑規劃的未來研究與發展進行了展望。
1 DQN算法的工作原理及不足分析
1.1 DQN算法的工作原理
傳統的Q-learning 算法在進行路徑規劃時用Q 表存儲數據,但當路徑規劃的環境過于復雜和數據過多時,Q 表不僅難以存儲而且難以搜索,容易出現維數爆炸,為解決這個問題,可以利用函數逼近來代替Q值表對值函數進行計算,但容易出現算法的不穩定。DQN算法結合了深度神經網絡和傳統強化學習算法Q-learning的優點[16],一定程度上解決了用非線性函數逼近器近似表示值函數時算法的不穩定性問題。DQN算法利用深度神經網絡作為函數逼近來代替Q值表,并對值函數進行計算,以神經網絡作為狀態-動作值函數的載體,用參數為ω的f網絡近似代替值函數,公式為:

f(s,a,ω)為函數的近似替代,用神經網絡的輸出代替Q值,具體如圖1[11]所示。s為輸入狀態,F(s,ai,ω)(i=1,2,3,4)表示狀態s下動作ai的Q值。DQN 在與環境互相迭代過程中,狀態st與狀態st+1具有高度相關性,導致神經網絡過擬合而無法收斂。為打破數據相關性,提升神經網絡更新效率和算法收斂效果,DQN 算法采用經驗庫[17](Experience Replay Buffer)將環境探索得到的數據以記憶單元的形式儲存起來,然后利用隨機樣本采樣的方法更新和訓練神經網絡參數。另外DQN算法還引入雙網絡結構,即同時使用Q估計網絡和Q目標網絡來進行模型訓練,不是直接使用預更新的當前Q 網絡,以此來減少目標值與當前值的相關性。估計網絡和目標網絡的結構完全相同,但是網絡參數不同。其中Q網絡的輸出為Q(s,a,θ),用來估計當前狀態動作的值函數;目標網絡的輸出表示為Q(s,a,θ′)。

圖1 DQN代替模型Fig.1 DQN instead model
DQN 網絡更新是利用TD 誤差進行參數更新。公式如式(2)所示:

DQN 算法流程如圖2所示[18],將環境狀態s傳入到當前值網絡,以ε概率隨機選擇一個動作at,執行動作a得到新的狀態st+1和獎勵值r,并將(st,at,rt,st+1)存儲到經驗池D中,然后從經驗池D中選取隨機采集樣本進行訓練,最后根據TD損失函數進行target網絡參數更新,更新參數的方法為隨機梯度下降,每隔N次迭代拷貝參數到目標值網絡進行參數更新并訓練。

圖2 DQN更新流程Fig.2 DQN update process
基于DQN算法的路徑規劃流程如下所示:
算法1DQN路徑規劃算法
1.初始化經驗池D,初始化Q-target 網絡參數和當前網絡參數容量為N,初始化折扣因子γ
2.forepisode=1,2,…,d0
3.初始化環境狀態,將移動機器人獲取的環境特征信息(s,a,r,s′)保存于記憶矩陣D中,并計算網絡輸出
4.根據概率ε機器人選擇一個隨機的動作或者根據當前的狀態輸入到目前的網絡中,計算出每個動作的Q值,選擇Q值的最優動作
5.得到機器人執行動作at后的獎勵rt和下一個網絡的輸入
6.將得到的數據作為機器人的狀態一起存入到記憶矩陣D中(記憶矩陣還保存著前N個時刻的狀態),設置合理的獎勵函數
7.隨機從記憶矩陣D中取出一批樣本
8.將按照公式(2)更新過后的Q值作為目標值,計算每一個狀態的目標值
9.通過隨機快速下降法更新權重,利用TD更新網絡參數
10.每C次迭代后更新目標網絡θ-=θ
11.end for
12.end for
近年來,將DRL算法應用于移動機器人路徑規劃的方面的工作已經做了很多,DQN 算法的提出對移動機器人路徑規劃的發展起著重要作用,2016年,文獻[19]最先利用DQN 算法實現了虛擬環境中的機器人路徑規劃;文獻[20]提出一種改進深度強化學習算法(NDQN),加入了差值增長概念,利用改正函數對DQN 算法進行改進并運用到機器人三維路徑規劃中。圖3 為使用基于DRL算法的移動機器人路徑規劃方法的總體框架[21],該框架由智能體和環境組成,后續很多方法都是從該框架的基礎上進行改進,更多詳細介紹請見第3章。DQN算法實現了DL 和RL 的結合,對DRL 的發展有重要意義。但DQN 算法在實際應用中存在不足,無法處理連續動作控制任務。
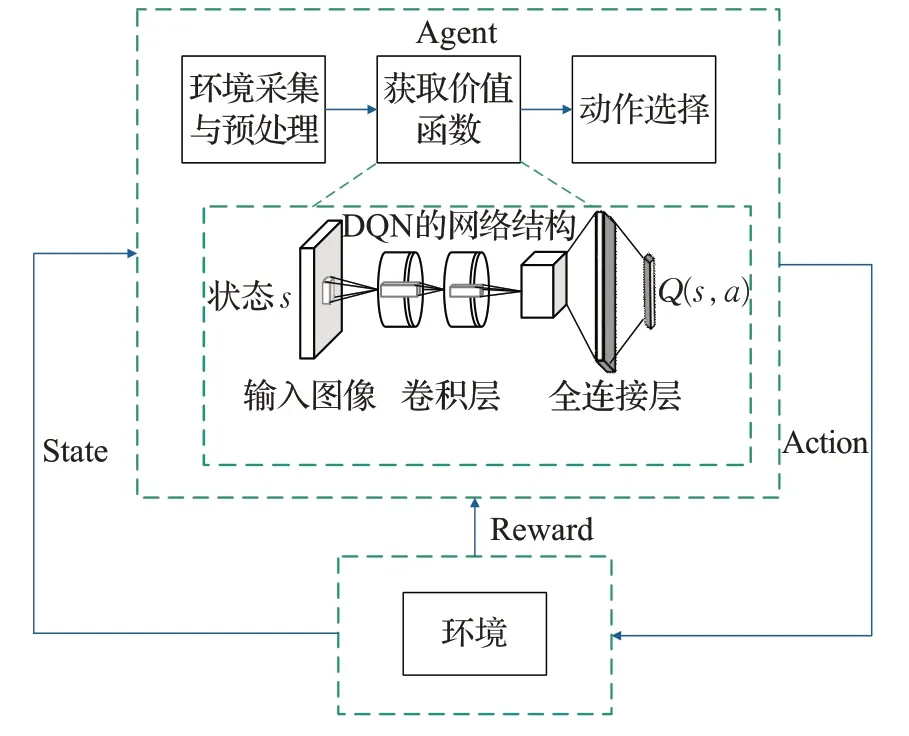
圖3 基于DRL的機器人路徑規劃框架Fig.3 Robot path planning framework based on DRL
1.2 DQN算法的不足分析
DQN 算法在路徑規劃等領域得到了廣泛的應用,但是仍然存在許多問題,比如過估計問題、容易陷入局部最優、學習效率低、不能滿足高維動作的輸入、算法穩定性差、探索過程中目標丟失、數據探索效率低下等問題,另外DQN算法只能處理短期記憶問題,無法處理長期記憶的問題。分析存在以上問題的原因如下:
(1)過估計問題
機器人運用DQN 算法進行路徑規劃時,神經網絡以狀態-動作對作為輸入,以Q函數值為輸出,實現環境端對端的控制,每一次網絡更新時機器人都會對目標Q 網絡采取最大化操作,這樣容易高估動作值,導致算法將次優行為價值認定為最優行為價值[22],移動機器人容易陷入局部最優。
(2)學習效率低
機器人進行路徑規劃的時候需要不停地與環境進行交互,這就導致DQN 算法會面臨學習大量參數的局面,導致機器人學習效率低下。另外DQN 算法在與環境互相迭代過程中,所采集的運動樣本具有較大的關聯性,導致神經網絡過擬合而無法收斂,降低了神經網絡更新效率,影響了算法收斂效果。傳統DQN 算法只使用單個機器人進行訓練,在進行路徑規劃時,機器人的數量也會影響機器人的學習效率。
(3)算法穩定性差
DQN算法一般都是使用傳統卷積網絡處理原始輸入,比如機器人上安裝的傳感器獲得的外部環境圖像,將處理后的數據分流到兩個全連接網絡中,分別為動作值和目標值,數值之間具有相關性,導致算法穩定性差,所以必須打破數據相關性,提高算法穩定性。另外,用神經網絡的非線性函數逼近器來表示Q值函數容易產生誤差。
(4)數據探索效率低下
在路徑規劃問題中,機器人為了獲得最短路徑,在運用DQN 算法進行路徑規劃時,只為獲得最大的獎勵值,忽略探索過程,陷入死循環,導致機器人探索環境效率低下。所以在機器人在運用DQN算法進行路徑規劃時,需要設置合理的獎懲函數,提高機器人的性能。
(5)長短期記憶
運用DQN 算法進行路徑規劃時,需要不斷更新經驗池,將當前的記憶數據存儲到經驗池中,將卷積神經網絡當前得到的Q函數與之前的數據進行比較;隨后將兩者的誤差通過梯度下降法反向傳播回卷積神經網絡中,從而實現Q-Network的訓練與更新,但是卷積神經網絡只能存儲短期記憶,這就導致神經網絡的更新具有延遲性,降低了機器人路徑規劃算法的性能。將只能實現短期記憶的卷積神經網絡更換成具有長期記憶的神經網絡是十分必要的,比如LSTM(Long Short-Term Memory)。
2 DQN算法的改進研究
針對上述問題,Hasselt等人[23]、Wang等人[24]、Foerster等人[25]對DQN 算法進行深入研究,改進算法主要從訓練方法、神經網絡結構、學習機制、基于AC 框架的RL算法等方面提高算法的優化能力,為后續移動機器人路徑規劃算法提供理論基礎。
2.1 改進訓練方法
(1)分布式深度Q網絡
在訓練過程中,傳統DQN 算法只使用單個機器進行訓練,這就會導致較長的訓練時間,學習效率低。針對此類問題,Nair 等人[26]提出了分布式深度Q 網絡算法,可以多個機器同時進行訓練,用分布式重放存儲器和分布式神經網絡并行工作和學習,與單個機器訓練相比,有效地提供了增大容量的分布式經驗回放內存,不僅可以生成更多的訓練數據,分布式參與者還可以更加有效地探索空間,因為每個這樣的參與者都可以存儲其自己的過去經驗記錄,根據一定差異性策略進行操作,使機器人的訓練時間大大減少,提高了學習效率。分布式深度Q網絡算法主要由四部分組成,分別為并行參與者、平行學習者、參數服務器、經驗回放存儲機制,算法框架圖如圖4所示[26]。
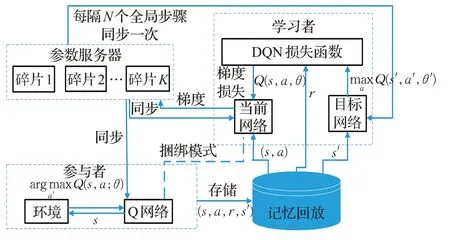
圖4 分布式DQN算法框架Fig.4 Distributed DQN algorithm framework
參與者用于產生新行為;從儲存的經驗中訓練出平行學習者;參數服務器用以表示價值函數或者行為策略的分布式神經網絡;經驗回放存儲制用以儲存分布式經驗存儲。分布式DQN算法能夠利用大量的計算資源來擴大DQN 算法的規模,但是也對計算機本身的計算能力和內存有了更高的要求。
(2)平均DQN算法
DQN算法的不穩定性和可變性可能會對機器人路徑規劃的效率產生影響,針對這個問題,Anschel等人[27]提出平均DQN(Averaged-DQN,ADQN)算法。ADQN算法是傳統DQN算法新的擴展,ADQN算法與DQN算法的主要差異是目標值的不同選擇,ADQN算法通過使用之前學習的Q值進行平均估計,產生當前的行動價值估計來減少目標近似誤差的方差,可以使得學習進度更加穩定,價值估計也更加保守,實現更穩定的訓練過程。ADQN算法能夠對學習曲線產生方差減少效應,該算法解決了由Q學習和函數逼近相結合而產生的問題,表明了平均DQN 算法在理論上比DQN 算法在降低方差方面更有效。文獻[28]表明ADQN 算法在玩具問題和街機學習環境中的幾個Atari 2600游戲中表現良好,但同時也使得訓練時間變長,資源消耗增加。
2.2 改進神經網絡結構
DQN 算法是通過神經網絡來估計Q 函數,網絡結構決定了網絡的學習效率和表達能力[29],神經網絡結構的選擇對DQN算法的性能的高低非常重要。
(1)Double DQN算法
DQN算法每一次更新時都會對目標Q網絡采取最大化操作,這樣會導致Q值受到了嚴重的高估,即網絡輸出的Q值高于真實的Q值。為有效解決過估計問題,Hasselt等人[23]提出深度雙Q網絡(Double DQN,DDQN)算法,對DQN 的優化目標進行優化改進。DDQN 算法將目標中的最大運算分解為動作選擇和動作評估來減少高估問題,通過隨機分配每個經驗來更新兩個值函數中的一個來學習兩個值函數,這樣就有了兩組權重,對于每次更新,一組權重用于確定貪婪策略,另一組用于確定其值,有效解決了DQN算法中存在的過估計問題,使得智能體能夠選擇相對較優的動作。實驗表明DDQN算法在價值準確性和策略質量方面都優于DQN,不僅產生更準確的價值估計,而且產生更好的策略,使機器人的學習更加穩定。
但DDQN算法在選擇相對較優的動作時,是利用當前估計網絡參數,而不是已經更新的先驗知識庫,所以解決價值高估問題的同時,也會帶來價值低估問題。董永峰等人[30]提出動態目標雙深Q網絡(DTDDQN)算法,將DDQN算法與平均DQN算法相結合,取長補短,對網絡參數進行培訓,使網絡輸出的Q值更接近實際Q值,解決了路徑規劃中的估計值誤差大的問題。
(2)基于決斗架構的DQN算法
決斗網絡是一種新的無模型強化學習神經網絡結構,Wang等人[24]提出基于決斗架構的DQN(Dueling DQN)算法,從神經網絡結構方面對DQN 算法進行改進。基于決斗網絡的DQN算法采用卷積神經網絡處理原始輸入,將處理過的原始輸入分流到兩個全連接網絡中,分別為狀態值和優勢函數。這種分流的優點是在動作之間推廣學習,而不對底層的強化學習算法進行任何改變,結構如圖5所示[24]。
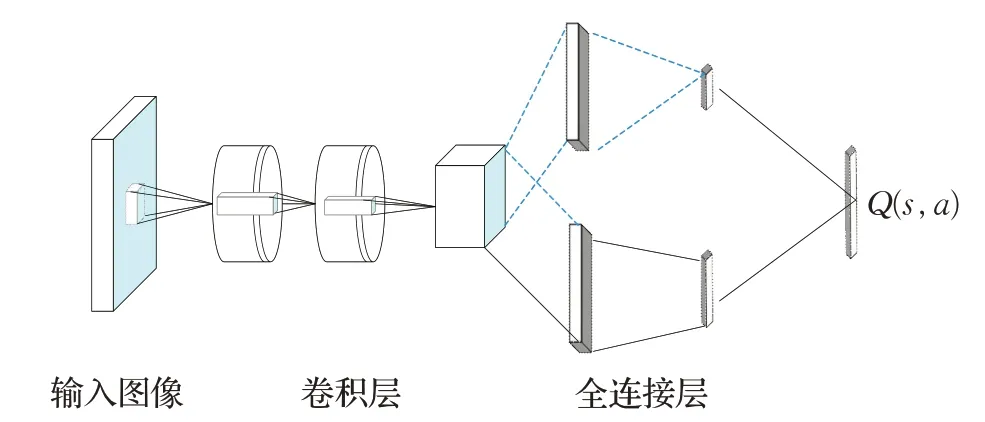
圖5 決斗架構的DQN網絡結構Fig.5 Dueling DQN network structure
基于決斗架構的DQN算法的優勢部分在于它能夠有效地學習狀態值函數。當決斗架構中的Q值每次更新時,價值流也會更新,這與傳統DQN算法結構中的更新方式形成鮮明對比,在DQN結構中,只更新一個動作的值,所有其他動作的值保持不變。在基于決斗架構的DQN 算法中,更頻繁的價值流更新將更多的資源分配給價值函數,從而允許更好地逼近狀態值,這對于基于時間差異的方法來說是非常必要的和準確的[31]。實驗表明,當動作數較大時,決斗結構比單流Q 網絡的優勢更大,可以獲得更高的平均獎勵,以及更快的早期訓練速度,提高算法的穩定性。
基于決斗架構的DQN算法通過兩個決斗數據流來估計Q值,但是它只專注于Q函數內的決斗,影響了算法的性能,而且決斗網絡只適用于那些基于Q值的算法,使得算法有局限性。為了解決這些問題,Qiu等人[32]提出用一個創新的狀態表示決斗網絡來提高強化學習算法的性能,將狀態表示決斗網絡與決斗DQN相結合,形成了一種新的算法——SR 決斗DQN(State Representation Dueling DQN)算法,結果表明,與決斗DQN相比,SR決斗DQN算法更有利于解決高維環境下的任務,提高了決斗DQN 算法在CartPole 環境下的訓練速度和性能。
(3)深度循環Q網絡算法
長短期記憶網絡(LSTM)是循環神經網絡的升級版,具有長期記憶的特點,最早由Hochreiter 等人[33]在1997 年提出。傳統的DQN 算法進行路徑規劃時,機器人在與環境進行交互傳遞信息的過程中,神經網絡只能傳遞當前的信息,而忽視了后面的影響,而且數據之間是有聯系的。為了解決這個問題,Hausknecht 等人[34]提出了一種基于LSTM 的DQN 算法,深度循環Q 網絡算法(Deep Recurrent Q-Network,DRQN),將遞歸LSTM替換第一個后卷積全連接層來增加深度Q 網絡(DQN)的遞歸性的效果,并對DQN濾波進行改進,降低對較遠信息的權重,增加關系強的信息權重。在Atari2600 游戲平臺驗證了其性能,在相同的歷史長度下,LSTM 是在DQN的輸入層中儲存歷史記憶的一種可行的替代方案,可以更好地適應評估時間。
單層LSTM記憶歷史信息能力有限,在一些連續性不強的環境中進行路徑規劃時,機器人不能取得滿意的結果。2017年,翟建偉[35]在DRQN算法的基礎上加入自注意力機制,提出一種具有視覺注意機制的深層循環Q網絡(Deep Recurrent Q-Network with Visual Attention Mechanism,VAM-DRQN),能夠聚焦圖像中的關鍵信息,使得機器人獲得的環境圖像更加清楚。2019年,劉全等人[36]提出一種帶探索噪音的深度循環Q 網絡模型(EN-DRQN),引入改進的簡單循環單元,解決了單層LSTM記憶力能力有限的問題,既保留了狀態序列之間的相關性,又可以在序列之間有效的探索出新狀態,同時在歷史信息的指引下做出有效決策,進一步加快了網絡的運算。實驗證明EN-DRQN 加快了機器人的訓練速度,減少了訓練時間。
2.3 改進學習機制
(1)基于優先經驗回放的DQN算法
機器人連續運動時所采集的樣本本身之間存在較強的相關性,將導致機器人價值網絡更新梯度消失,機器人無法繼續學習,容易陷入局部最優,使得算法穩定性差。為打破數據相關性,提高算法穩定性,Schaul等人[37]提出了基于優先經驗回放的DQN(Prioritized Replay DQN)算法,使用基于優先級的經驗回放機制替代等概率的抽樣方式,解決了經驗回放中的采樣問題。該算法使機器人能夠在更多數量級的數據中有效地學習,并且將行動與學習結合。行動者根據共享的神經網絡選擇行動,與之前的環境實例進行交互,并在共享的經驗重放存儲器中積累所得經驗,學習者回放經驗樣本并更新神經網絡[38],提高有價值樣本的利用率。但經驗回放就意味著每個真實交互中的環境信息將使用更多的內存和計算,機器人需要很多探索行為才能得到積極的反饋,這就使得基于優先經驗回放的DQN算法進行路徑規劃時需要耗費大量的時間和資源,導致算法很難收斂。
(2)示范DQN算法
DQN 算法進行路徑規劃時需要大量的訓練數據,嚴重地限制了深度學習在許多真實世界任務的適用性,學習過程中的表現非常差。Hester 等人[39]提出示范DQN(Deep Q-learning from Demonstrations,DQFD)算法,該算法利用少量演示數據,可以訪問來自系統先前控制的數據,即使是從相對少量的演示數據中,也能大大加快學習過程。DQFD 算法利用少量的演示數據對機器人進行預培訓,使其能夠從學習開始就很好地完成任務,然后從自己生成的數據中繼續改進,而且優先重放機制能夠在學習時自動評估演示數據的必要比例,將時間差異更新與演示者行為的監督分類相結合來工作,減少了和環境交互次數,提高了學習效率。DQFD算法使逆向學習應用于許多現實問題成為可能,但不能對示范者的行為進行準確的分類,示范和代理數據之間存在差異,無法應用于連續動作域。
(3)策略與網絡深度Q學習算法
DQN算法能通過模仿人類學習技能的過程從經驗中學習,當機器人學習過去的經驗時,全面多樣的經驗有助于提高算法的性能。基于不同學習階段對經驗深度和廣度的不同需求,LV 等人[40]提出了一種快速學習策略,策略與網絡深度Q學習算法(Policy and Network Deep Q-Network,PN-DQN),該算法計算Q值采用密集網絡架構,在學習的初始階段創建經驗值評估網絡,增加深度經驗的比例,從而更快地理解環境,改變了技能學習過程中經驗的概率分布,使得模型可以在學習的不同階段獲得更多所需的經驗,從而提高學習效率。在路徑規劃應用中,只需要輸入地圖圖像,不需要對地圖進行建模,旨在提高路徑規劃的速度和精度。仿真實驗表明,PN-DQN 算法在學習速度、路徑規劃成功率和路徑精度方面都優于傳統的DQN 算法,但該算法只適用于離散狀態空間,對于連續動作控制的效果并不好。
2.4 基于Actor-Critic框架的DRL算法
基于強化學習的運動規劃是一種基于數據的非監督式機器學習方法,將感知、規劃集成于一體,通過策略學習實現端到端的運動規劃[41],基于強化學習的DQN算法對移動機器人路徑規劃的發展具有深遠意義。除了從訓練方法、神經網絡結構、學習機制等方面研究DQN算法,通過其他角度對DQN算法的研究也取得了一些進展。
根據機器人路徑規劃是否存在價值函數的指導,分為基于值函數算法和策略梯度算法兩種運動規劃算法[42]。以價值函數為基礎的強化學習方法常被應用于機器人離散動作空間的運動規劃,但對連續動作的處理能力不足,無法解決隨機策略問題;基于策略的強化學習算法直接通過給定的策略評價函數在策略空間內搜索得到最優控制策略[43],能夠處理連續動作問題,但學習效率較低,缺乏隨機探索能力。將值函數算法和策略梯度算法結合得到新的一種結構:行動者-評論家(Actor-Critic,AC),融合了值函數算法和策略梯度算法的優點,在進行訓練時,Actor和Critic的交替更新參數,優化了算法的性能。
(1)DDPG
無模型、脫離策略的行動者-評論家算法,使用深度函數逼近器,可以在高維、連續的行動空間中學習策略,Lillicrap 等人[44]將行動者-評論家方法與DQN 算法相結合,得到一種無模型的深度確定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG),用來自重放緩沖器的樣本對網絡進行離線訓練,以最小化樣本之間的相關性,同時通過雙網絡結構和優先經驗回放機制,解決了Actor-Critic難收斂的問題,提高了算法的效率。但DDPG進行路徑規劃時存在訓練時間過長、訓練數據需求大、訓練初期的學習策略不穩定等問題,而且由于環境的復雜性和隨機性,DDPG往往受到低效的探索和不穩定的訓練的影響。
眾多研究者對DDPG 算法進行了改進,Hou 等人[45]提出基于知識驅動的DDPG算法,在策略搜索階段應用混合探索策略來驅動有效的探索,使機器人能夠從經驗中高效、穩定地學習多孔裝配技能。Zheng 等人[46]提出自適應雙自舉DDPG算法,該算法將DDPG擴展到自舉演員-評論家體系結構,通過多個Actor捕捉更多潛在的行動和多個Critic協作評估更合理的Q值,提高了機器人探索效率和算法性能。武曲等人[47]將LSTM 算法與DDPG 算法相結合,以環境圖像作為輸入,通過預先訓練的自動編碼器進行圖像降維,方便準確提取環境特征信息,利用LSTM 處理數據時的預測特性,實現了有預測的機器人動態路徑規劃。
(2)TRPO
在DDPG策略梯度的優化過程中,得到合適的步長對移動機器人路徑規劃學習效率和訓練效率至關重要。為確定合適的步長,Schulman等人[48]提出了一種基于信賴域策略優化的強化學習算法(Trust Region Policy Optimization,TRPO)。實驗表明,最小化某個替代損失函數可以保證策略在非平凡步長下的改進,使策略始終朝著好的方向持續更新,但計算過程復雜、對策略與環境的交互依賴大、容易出現較大誤差的問題。
Jha等人[49]提出了一種擬牛頓信賴域策略優化(QNTRPO)方法,將計算步長作為搜索方向計算的一部分,而且步長能夠根據目標的精度而變化,使得該算法的學習速度比TRPO 要快。Zhang 等人[50]對TRPO 算法進行了從不同目標中學習信息能力的擴展,解決了獎賞稀少、算法誤差大的問題,進一步優化了算法的性能。Shani等人[51-52]對TPRO算法進行改進,使得改進后的TPRO有更強的學習能力。
(3)PPO
針對TRPO算法計算過程繁雜,過于依賴策略和環境的交互,從而導致機動機器人運動規劃路徑與最優路徑產生偏差的問題,Schulman等人[53]在TRPO算法基礎上提出了近端策略優化算法(Proximal Policy Optimization,PPO)。它通過與環境的交互作用來采樣數據,使用隨機梯度代替標準策略梯度優化目標函數交替,使得機器人路徑規劃算法具有較好的數據效率和魯棒性。PPO 和TRPO 算法最大的區別是PPO 支持多個時段的小批量更新,實施起來更簡單、更通用,并且具有更好的樣本復雜性。
PPO 算法可以在各種具有挑戰性的任務中實現最先進的性能,但是,PPO 算法不能嚴格限制似然比和強制執行定義明確的命令與約束,這就導致PPO算法的性能不穩定。為了解決這個問題,Wang 等人[54]提出了一種增強型PPO 算法,真實PPO 算法(Truly PPO,TPPO)采用新的函數來支持回滾行為,限制新舊策略的差異,優化目標函數,改善最終策略性能,通過將策略限制在信任域內,TPPO 算法在樣本效率和性能上都有了很大的提高。
(4)A3C
Mnih 等人[55]基于異步強化學習(Asynchronous Reinforcement Learning,ARL)的思想,提出一種概念簡單、輕量級的深度強化學習框架——異步優勢的演員評論家算法(Asynchronous Advantage Actor-Critic,A3C)。基于A3C的移動機器人路徑規劃算法主要是將異步梯度下降算法和DQN 算法以及多種強化學習算法相結合,讓不同的機器人在相同的環境進行不同步的交互學習,訓練時間和數據效率隨著并行參與者學習者的數量而變化,當使用更多的平行參與者學習者時,并行應用在線更新的多個參與者學習者對參數進行的總體改變在時間上的相關性可能較小。因此,A3C算法不再依賴經驗回放來穩定學習,能夠使用基于策略的強化學習方法,使得訓練時間更短,效率更高。
在實際問題中,當并行參與訓練的機器人過多時,就會導致訓練數據過大,應用成本增加,而且存在收斂于局部最優策略和樣本探索效率低下等問題。Kartal等人[56]將終端預測(Terminal Prediction,TP)任務集成到A3C 中,并進行了最小程度的細化,通過讓機器人預測其終端狀態的距離來學習控制策略。實驗表明,A3C-TP算法在大多數測試領域的性能都優于標準的A3C算法,在針對不同對手的策略方面學習效率和收斂性都有顯著提高。Labao 等人[57]提出了一種基于異步梯度共享(Gradient Sharing,GS)機制的A3C 算法(A3C-GS),用于改進A3C算法探索數據的效率。該算法具有在短期內自動使策略多樣化以供探索的特性,從而減少了對熵損失項的需求,而且在需要探索的高維環境中表現良好。
(5)SAC
一般基于強化學習的移動機器人路徑規劃算法樣本學習效率都比較差,是因為基于梯度策略的算法學習有效策略所需的梯度步驟和每個步驟的樣本數量隨著任務的復雜性而增加。針對這個問題,Haarnoja 等人[58]提出了一種基于最大熵的離線學習強化學習方法:軟行動者-批評者(Soft Actor-Critic,SAC)算法。SAC 算法將非策略更新與穩定的隨機Actor-Critic公式相結合,在最大化熵的同時,最大化預期回報,即在盡可能隨機行動的同時成功完成任務。實驗證明,SAC算法提高了樣本的學習效率和算法穩定性,很容易擴展到非常復雜的高維任務[59],更加適應于真實環境。
Fu 等人[60]提出了一種基于最大熵框架的SAC 算法,并成功應用到車載互聯網中的實時流媒體服務控制中。Cheng等人[61]將無人機的決策問題建模為馬爾可夫決策過程(MDP),構建強化學習框架,并將SAC算法與仿真環境相連接,訓練模型使得無人機學習任務的決策,生成基于SAC算法的自主決策能力,使無人機在與環境交互的過程中不斷總結經驗,做出最佳的戰略選擇。Tang 等人[62]提出了一種層次化的SAC 算法來解決多物流機器人分配任務問題,通過引入子目標在不同的時間尺度上對模型進行了訓練,其中頂層學習了策略,底層學習了實現子目標的策略,與原本SAC算法相比,該方法能夠使多物流AGV 機器人協同工作,在稀疏環境下的獎勵提高了約2.61倍。
3 DQN算法在路徑規劃方面的改進總結
DQN 算法在移動機器人路徑規劃中得到廣泛應用,為了進一步提升DQN算法的學習效率,許多學者提出了許多富有成效的改進措施,將上述的主要內容進行總結,如表1所示。

表1 DQN算法的改進總結Table 1 Summary of improvements in DQN algorithms
單一的DQN 改進算法的都能實現顯著的性能改進,因為它們的改進都是為了解決單一的問題,把DQN改進算法相互融合,取長補短,它們很大程度上可以更好地提高算法性能。Xie等人[63]提出了一種基于決斗結構的深度雙Q 網絡避障算法(Dueling Double Deep-Q Network,D3QN)。D3QN 算法可以有效地學習如何在模擬器中避開障礙物,實驗表明,D3QN 與傳統的DQN算法相比,能夠實現雙倍的學習速度,而且可以將在虛擬環境中訓練的模型直接應用到復雜未知的路徑規劃環境中。基于優先經驗的DDQN和決斗DDQN都使用雙Q 學習,決斗DDQN 也可以與優先經驗重放相結合。Hessel等人[64]提出了Rainbow的概念,將DQN算法的六個擴展集成到單個集成代理中,將Rainbow的表現與A3C、DQN、DDQN、優先DDQN、決斗DDQN、分布式DQN和噪音DQN的相應曲線進行比較,Rainbow的性能明顯優于任何基線,數據效率和最終性能都表現良好。
除了對DQN 算法進行以上改進外,還從其他角度對DQN 算法及模型架構進行了研究。Kulkarni 等人[65]提出一種分層DQN算法(hierarchical-DQN,h-DQN),將控制任務分成若干層次,從多層策略中學習,每一層都負責在不同的時間和行為抽象層面進行控制,提高了學習效率。徐志雄等人[66]將Sarsa與DQN 算法相融合,提出了基于動態融合目標的深度強化學習算法(Dynamic Target Deep Q-Network,DTDQN),有效地減少了值函數過估計,提高學習性能和訓練穩定性。張俊杰等人[67]提出了狀態值再利用的決斗深度Q 學習網絡(Reuse of State Value-Dueling Deep Q-learning Network,RSVDueling DQN),將機器人訓練樣本時得到的獎勵值標準化后與Dueling-DQN算法中的Q網絡值進行結合,加強狀態-動作對的內在聯系,使得機器人能夠得到更加準確的獎勵值,不僅使算法的穩定性大大提高,更加加快了算法的收斂速度。Avrachenkov等人[68]、Hui 等人[69]也對DQN 算法從不同的角度進行改進,并取得了良好的效果。
4 DRL算法在其他方面的實際應用
4.1 計算機博弈
深度強化學習(Deep Reinforcement Learning,DRL)綜合利用了強化學習的心理和神經機制以及深層神經網絡強大的特征表示能力,在人工智能的發展中發揮著重要作用[70]。計算機博弈是人工智能領域最具挑戰性的研究方向之一,已經研究出了很多重要的理論和方法,并應用到實際問題中。2016 年,DeepMind 團隊根據深度學習和策略搜索的方法研制出了圍棋博弈系統AlphaGo,并以4∶1的戰績打敗了圍棋冠軍李世石[71],之后AlphaGo 的升級版Master 在與世界頂尖圍棋大師柯潔的對戰中以3∶0 的成績取得了勝利。2017 年,Deep-Mind 團隊在此基礎上研制出完全基于DRL 的系統AlphaGo Zero,完全不需要人類的經驗數據,在短時間內并且自己訓練自己的情況下以100∶0 的成績打敗了AlphaGo[72]。計算機博弈分為完備信息博弈和非完備信息博弈,破解完備信息博弈游戲相對來說比較容易,但非完備信息博弈更加復雜,破解更加困難,具有更大的挑戰性。對于人工智能的研究者來說,對非完備信息博弈游戲的研究仍是一個充滿挑戰性的方向。
4.2 視頻游戲
由于DRL 的訓練需要大量的采樣和試錯訓練,而游戲環境能夠提供充足的樣本,并且避免了試錯的成本[73],所以DRL適用于視頻游戲領域。游戲環境具有多樣性,但DQN算法較早應用于Atari 2600的算法,在跨越49 場比賽的專業人類游戲測試儀的水平上進行,計算機能夠在超過一半的比賽中實現超過75%的人類分數的成績[74]。之后,Nair[26]、Hasselt[23]、Wang[24]、Schaul 等人[37]對DQN算法進行改進,分別在Atari 2600游戲中取得了成績,并得到不同程度的提升,Atari 2600 的游戲數據集已經達到了人類級的控制精度。2020 年,Badia等人[75]提出Agent57 算法,在Atari 2600 游戲中取得了良好的成績,超越了人類的平均水平。除了Atari平臺,人們也基于其他游戲平臺對DRL進行了研究。Kempka等人[76]、Vinyals 等人[77]通過研究DRL 算法,提出了將ViZDoom 和StarCraftII 為DRL 的測試平臺,ViZDoom基于監督學習的方法,StarCraftII 基于實時策略(RTS)的方法,大大提高了算法的訓練速度,顯著地提高了智能體在游戲中的表現性能。RTS游戲被視為AI研究的大挑戰,MOBA(Multi-player Online Battle Arena)是一種RTS游戲。騰訊的AI Lab利用DRL研究MOBA中的王者榮耀(Honor of Kings)游戲,其中重點研究1V1 模式[78],經過訓練后,在2 100 場的1v1 競賽中的獲勝率為99.81%。目前,視頻游戲是DRL 算法最好的訓練方法之一,人們對視頻游戲的研究對未來人工智能的發展具有重要意義。
4.3 導航
導航是指移動機器人在復雜環境下在一個地方運動到一個指定的目的地,在運動過程中要避開障礙物、找到最優路徑。近年來,利用DRL在迷宮導航、室內導航、視覺導航等方面的研究取得了一定進展。在迷宮導航方面,Jaderberg等人[79]提出采用無監督的輔助任務的強化學習,在沒有外在獎勵的情況下也能繼續迷宮導航,使得迷宮學習的平均速度提高10 倍。在室內環境中,Zhu等人[80]利用遷移強化學習方法,以深度圖像作為神經網絡輸入提取環境特征,訓練后的移動機器人經過參數微調可以被直接應用到現實環境中的導航控制。基于視覺的導航對機器人的應用至關重要,Kulhanek等人[81]提出一種基于視覺的端到端的DRL導航策略,設計了視覺輔助任務、定制的獎勵方案和新的強大模擬器,能夠在真實的機器人上直接部署訓練好的策略。在30次導航實驗中,機器人在超過86.7%的情況下到達目標的0.3 m 鄰域,該方法直接適用于移動操作這樣的任務。導航技術的發展對于機器人路徑規劃技術的發展是非常重要的,導航技術的應用也越來越廣泛。
4.4 多機器人協作
多機器人協作是指機器人之間通過相互合作完成任務,從而得到聯合的獎勵值,通過并行計算提升算法的效率或者可以通過博弈互相學習對手的策略。單個機器人在一個復雜的環境中進行路徑規劃發揮的作用總是有限的,多機器人與單機器人相比,通常能夠完成更加復雜的任務[82]。基于DRL 的多機器人協作問題是機器學習領域的一個重要的研究熱點和應用方向,因此研究多機器人路徑規劃具有極高的價值和意義[16]。
目前解決多機器人的路徑規劃問題取得了一定進展,梁宸[83]提出一種基于改進的DDPG多機器人DRL算法。該算法將DDPG算法中的AC網絡加入了帶注意力神經元的雙向循環神經網絡,用于多機器人之間的通訊,改進后的算法不僅提高了算法的收斂速度,任務的完成度也有顯著提升。Foerster等人[84]提出了一種多機器人行為-批評方法,采取分散的政策,即每個主體只根據其局部行動觀察歷史來選擇自己的行動,同時提高所有智能體共同的獎勵值,顯著提高了機器人路徑規劃的平均性能。Mao等人[85]提出了一種基于深度多主體強化學習的算法:學習-交流的ACC(Actor-Coordinator-Critic)網絡,解決多機器人之間的“學習-交流”問題。ACC網絡有兩種模式:一種是在Coordinator 的幫助下學習Actor 之間的通信協議,并保持Critic 的獨立性;另一種是在Coordinator 的幫助下學習Critic 之間的通信協議,并保持Actor 的獨立性,由于Actor 是獨立的,在訓練完成后,機器人之間即使沒有交流也可以相互配合。Sunehag等人[86]、Iqbal等人[87]也對多機器人之間的協作進行了研究,并取得了一定成果,促進了多機器人協作的發展。
DRL訓練通常需要大量樣本進行訓練,多機器人協作可以使得多個機器人并發產生大量樣本,增加了樣本數量,提高了學習速率,但多機器人環境下的學習任務仍然面臨著諸多挑戰,因為人類社會中很多問題都可以抽象為復雜的多機器人協作問題,所以還需要進一步探索研究該領域[88]。
5 結論
本文主要通過研究DQN 算法的原理、改進算法以及實際應用等,體現了DRL的演化過程。如今,雖然基于改進DQN 算法的深度強化學習模型已經較為完善,在機械臂、電動汽車實時調度策略[89]、室內外路徑規劃、無人機等方面得到了廣泛應用,但對DQN 算法的研究主要集中在虛擬環境中,算法的實際應用現仍處于發展階段。DRL算法的自主學習應用需要大量的學習樣本,但在實際環境中獲取大量樣本是不實際的,樣本收集成本高,但少量樣本使得機器人學習到的經驗準確性不足。探索過程中目標的丟失也是路徑規劃研究中的一個重要問題,計算機本身的計算能力也限制了移動機器人路徑規劃算法性能。另外,DRL算法在進行路徑規劃時,需要時刻與環境進行交互,機器人依靠傳感器和圖像信息完成復雜環境中的避障任務,所以從傳感器獲取信息的準確性,對算法的性能有重要影響。DQN 及其改進算法都是首先在模擬環境中進行的,模擬環境的成功應用才可以推廣到現實環境中,但是模擬與現實環境總是存在差距的。據此,未來對DQN 算法的研究可以從以下方面展開:
(1)建立精準環境預測模型。建立準確的環境模型,Agent就可以減少與真實環境的交互,通過學到的環境模型預測未來狀態[90],這不僅有助于提供一個潛在的無限數據源,還可以緩解真實機器人的安全問題。然而面對復雜多變的環境,在有限樣本的情況下,建立精準的環境模型是十分困難的。
(2)避免在探索過程中失去目標。在路徑規劃問題中,機器人可能過于專注于探索路徑以避開障礙物而忽略學習目標。獎勵函數是移動機器人的訓練的支撐,設計合理有效的獎勵函數,對過度專注于探索路徑的機器人進行懲罰是至關重要的。另外可以進行模仿學習,使智能體模仿人類思考,與給定觀察環境進行交互,使其最終獲得最大的累積獎勵。
(3)提高勘探數據的有效性。利用遞歸神經網絡模塊在機器人的學習過程中加入記憶單元。機器人的輸出動作可以由多個狀態控制,可以解決信息丟失導致的低效探索問題。但在實際問題中,環境往往都是復雜且未知的,機器人探索得到的數據龐大且復雜,無法快速篩選得到有效的樣本,導致算法學習效率差。
(4)提高計算機的計算能力。計算機的計算能力對于算法性能,就像大腦的思考能力對于人類生命,無論多么優秀的算法,都需要以計算機為載體進行實驗仿真,然后運用到實際環境中,所以提高計算機本身的計算能力,對于算法性能的提升至關重要。
(5)增強處理傳感器信息技術的發展。DRL算法可以完成各種傳感器信息的融合,做出合理決策,但是不同類型的傳感器具有不同的信息冗余性,處理不同渠道的傳感器信息[91],獲取準確的環境信息是亟待解決的問題,一些傳統的規劃方法可以作為輔助決策,來提高算法決策的可靠性。
(6)縮小模擬環境與真實環境的差距。虛擬模型被轉換到真實環境中會降低策略的性能[92],提高模擬環境的真實性能更好地為現實世界做準備,但縮小虛擬和現實的差距需要更廣泛的理論和經驗,以便更好地理解DRL算法在學習過程中的效果。
就目前發展現狀而言,基于DRL 路徑規劃算法大多還處于實驗室階段,與應用到現實世界中的運動規劃算法還具有較大的差距。未來對DRL算法的應用研究不能僅僅局限于算法本身的改進,可以多學科合作,將人機交互知識領域的經驗融于DRL算法,提高Agent應對環境的不確定性和突發性情況的能力;將DRL 算法與自動控制理論相聯系,兩者相互借鑒,讓Agent 向著更加智能化的方向發展。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
中國生殖健康(2020年6期)2020-02-01 06:28:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
中國生殖健康(2019年11期)2019-01-07 01:28:02
數學大世界(2018年1期)2018-04-12 05:39:14
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
