
一種輕量級文本蘊含模型
2021-10-18 08:39:38孫成勝伍少梅李小俊
四川大學學報(自然科學版) 2021年5期
王 偉, 孫成勝, 伍少梅, 張 芮, 康 睿, 李小俊
(1.中國電子科技網絡信息安全有限公司, 成都 610041; 2.四川大學計算機學院, 成都 610065;3. 衛士通信息產業股份有限公司, 成都 610041)
1 引 言
文本蘊含識別(Recognizing Textual Entailment, RTE)是自然語言理解研究中一項基本任務,對問答對話,閱讀理解,文本摘要等任務有輔助作用.文本蘊含任務定義為給定一對文本,分別稱為前提(Premise)和假設(Hypothesis),模型需要推理出這兩段文本之間的關系,文本關系主要包括蘊含、中立和矛盾.
基于神經網絡的文本蘊含模型取得較高的識別準確率.現有主流文本蘊含模型[1-2]通常使用雙向LSTM網絡編碼文本,并采用注意力機制對兩段文本交互,再用循環神經網絡分析并推理交互特征從而判斷文本關系.這些模型一個共同特點是采用多次循環神經網絡編碼和推理文本,并且近年來部分文本蘊含模型[3-4]為了進一步提升精度,模型整體趨勢構建得越來越復雜,花費更多的參數,模型也需要花費更長的訓練和推理時間.更高的訓練代價使得模型難以快速微調和迭代,更長的推理時間使得模型不適于線上實際應用.
本文致力于探索高效的文本蘊含模型,采用并行架構,在保證模型精度情況下盡量精簡模型結構,提高模型運行速度.本文提出輕量級文本蘊含模型(Lightweight Textual Entailment Model, LwTEM),模型采用改進的自注意力編碼器分別編碼前提和假設文本向量,捕捉文本長距離依賴,采用點積注意力機制深入比較兩段文本語義,然后用卷積神經網絡分別提取兩段文本局部交互特征,模型可堆疊多個模塊進一步強化推理效果,凝練高層語義信息.
2 相關工作
基于神經網絡方法是文本蘊含任務的主流方法,主要分為兩類.一類通過構建更好的文本編碼器來獨立編碼兩段文本,再采用神經網絡分類器對兩個文本向量分類.編碼器主要包括循環神經網絡[5],卷積神經網絡[6],自注意力網絡[7].一個好的文本編碼器可適用于其他文本任務,但由于該方法沒有兩段文本的交互過程,分類器難以捕捉復雜的文本關系.另一類方法采用交互聚合框架來建模文本關系,在文本編碼后采用注意力機制從語義上比較兩段文本,再將文本交互特征聚合后進行推理.Chen等人[2]采用詞級別注意力矩陣對齊交互文本,并使用雙向LSTM網絡編碼和聚合文本特征.
在這種框架基礎上,主要有4種方式被用于進一步提升文本蘊含性能.(1) 是采用手工提取文本特征來作為模型輸入,Chen等[2]采用句法解析樹得到句法特征,Tay等[1]和Gong等[8]使用詞性特征,Kim等[4]和Gong等[8]手動提取字符匹配特征(2) 是采用復雜的文本對齊過程,Wang等[9]采用多視角匹配操作,Tan等[10]采用多種交互對齊方式;(3) 是構建復雜的后處理過程來處理文本交互結果,Tay等[1]使用因子分解層增強文本交互表示,Gong等[8]采用密集連接操作構建深度卷積網絡從交互結果中抽取文本信息. Xiong等[11]使用門控機制處理句子級交互信息,結合單詞級細粒度推理機制捕獲全局語義;(4) 通過多次迭代推理或多層編碼器來提取文本深層語義信息.Liu等[3]使用循環神經網絡多次迭代推理文本交互特征.Kim等[4]堆疊編碼層和交互對齊層,采用自動編碼器處理大量特征空間.Tay等[12]采用多種層級的注意力強化推理結果,并用密集連接加強多層級注意力傳播.
這些模型大多數都采用循環神經網絡進行編碼和推理,許多基于循環神經網絡的文本任務[13-14]取得了成功, RNN網絡的結構和串行數據處理方式,非常適用于文本數據,但該網絡運行時間通常較慢,再加上近年來文本蘊含模型各種復雜的特征和組件的堆疊使得模型結構越來越復雜,參數越來越多,訓練和推理時間也越來越長.
Vaswani等[15]提出Transformer結構,摒棄了串行編碼結構,采用自注意力和全連接網絡作為基本架構,在多個文本任務上取得了較好的結果.自注意力可跨距離捕捉文本遠距離依賴,良好的并行能力使得該結構在速度上很有優勢,便于堆疊多層,可提取更準確的高層語義信息.Zhang等[16]把語義角色融合到自注意力機制應用于RTE任務.卷積神經網絡擅長于局部特征建模,也被廣泛使用文本任務中.Xu等[17]將上下文相關的概念特征整合到卷積神經網絡中應用于短文本分類任務.卷積核及參數共享特點使得該網絡在運行速度和參數數量上也要優于循環神經網絡.
3 模 型
輕量級模型LwTEM包括嵌入層,編碼層,交互層,特征提取層和輸出層,整體架構如圖1所示.其中編碼層、交互層和特征提取層共同構成一個模塊,如圖1藍色虛線部分,模型針對不同數據集特點可疊加多個模塊,達到不同的推理效果.

圖1 LwTEM模型架構Fig.1 Model architecture of LwTEM
3.1 嵌入層
由于編碼層的自注意力網絡無法捕捉文本的位置信息,因此本文在嵌入層將預訓練詞向量和位置編碼拼接作為模型輸入.位置編碼采用Vaswani等[15]提出的相對位置編碼.
PE(pos,2l)=sin(pos/10002l/dmodel)
(1)
PE(pos,2l+1)=cos(pos/10002l/dmodel)
(2)
式中,pos表示文本序列中當前詞的位置;l表示位置向量中第l維;sin和cos分別表示奇數維度和偶數維度用的數學函數.該位置函數可以根據sin和cos函數的數學特性捕捉單詞之間的相對位置關系.
3.2 編碼層
本文編碼層和Transformer編碼器結構相似,由兩個子模塊組成:多頭注意力和兩層前饋神經網絡,每個子模塊通過殘差和層歸一化相連.
自注意力可無視距離交互遠距離文本,但同時也會忽略文本序列信息.對于一句話,中心詞附近的文本詞的作用應該是高于遠距離文本的,比如:“The man in a black shirt is standing next to black box”,句子中第一個“black”和第二個“black”對于“man”這個中心詞來說重要程度是不一樣的,而原始自注意力計算方式將這兩個“black”同等對待.本文模型對自注意力結果增加參數約束,用于學習不同距離的詞對中心詞產生的不同效果.雖然嵌入層的位置編碼也可緩解該問題,但實驗顯示增加參數約束后效果更好.改進后自注意力計算方式如圖2所示.
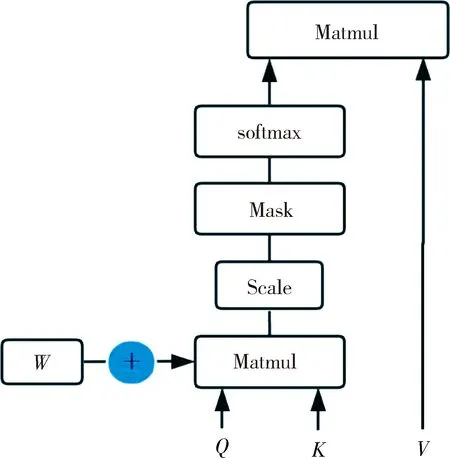
圖2 模型自注意力方式Fig.2 Structure of self attention
計算方式如式(3)所示。
(3)
式中,Q,K,V為輸入文本分別采用不同參數的線性映射得到;dk為多頭自注意力的隱層.本文模型在原本的自注意力計算方式下增加參數W,W和自注意力矩陣大小相同,為可訓練參數,用于改善不同距離詞的自注意力效果.
多頭自注意力計算結果通過拼接送入兩層前饋神經網絡中,如式(4)所示.
F(p)=W2(Relu(W1p+b1))+b2
(4)
式中,W1、W2和b1、b2分別為兩層的前饋神經網絡的權重和偏置;p為經過多頭自注意力計算的前提文本向量,假設文本向量計算方式也同上.前饋神經網絡將自注意力編碼后的信息映射到高維空間,通過非線性激活函數Relu進一步選擇有效的特征.
3.3 交互層
模型的交互方式采用簡單高效的點積注意力,得到兩段文本的詞級相似度結果.
Inter(pi,hj)=piT·hj
(5)
(6)
(7)
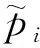
將交互特征向量和原編碼向量通過以下方式進行融合.
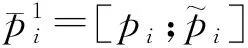
(8)
(9)
(10)
(11)
式中,[;]表示連接符號;°表示元素相乘,可表示原文本向量和交互向量之間的相似度,相減操作可表示找到向量之間的差異.假設文本的特征融合方式也同上.
3.4 特征提取層
特征提取層采用卷積神經網絡提取融合的特征.由于編碼層的自注意力網絡可充分編碼遠距離文本信息,而卷積神經網絡更關注局部特征,結合CNN網絡的局部感知和自注意力編碼的全局信息,可全面獲取文本高層語義和蘊含特征.卷積計算方式如式(12)所示.
(12)

3.5 輸出層
輸出層采用最大池化操作將文本特征轉為固定長度的向量.最后將前提和假設文本向量連接,采用兩層前饋神經網絡連接用于最后關系分類.

(13)
fk=xWk+bk,k∈{1,2}
(14)

4 實驗結果
4.1 數據集
本文LwTEM模型采用SNLI,SCITAIL, MultiNLI三個數據集進行驗證.其中SNLI數據集[18]是由斯坦福在2015年發布的大型文本蘊含數據集,SCITAIL數據集[19]是根據科學類多選問答任務構造的科學類文本蘊含數據集.MultiNLI數據集[20]為SNLI擴展的文本蘊含數據集,在語料范圍覆蓋度和推理難度上都有一定加強.表1 展示了三個實驗數據集詳細信息.
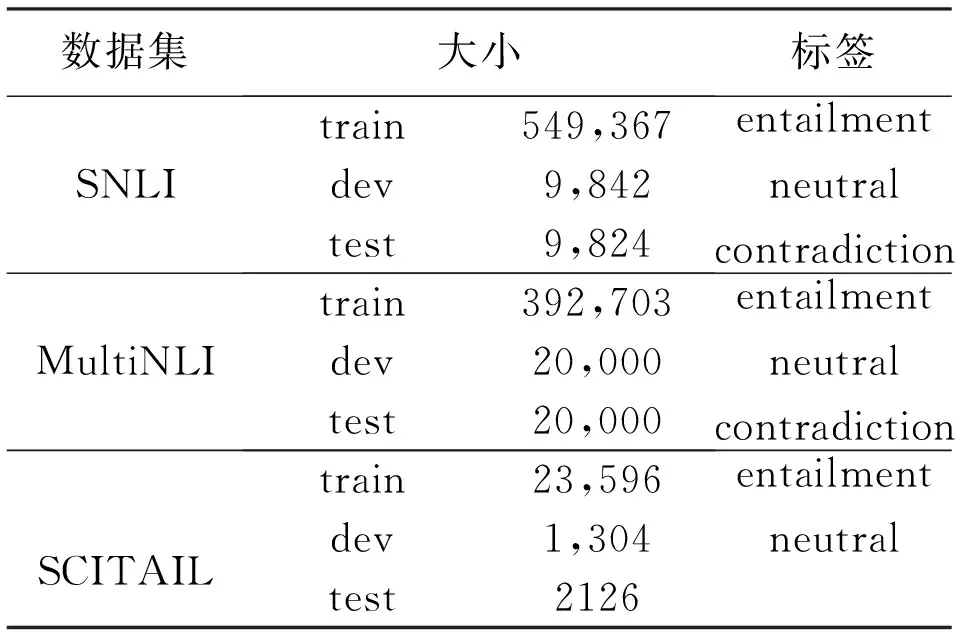
表1 3個實驗數據集分布
表1中,Entailment表示蘊含;neutral表示中立;contradiction表示矛盾類別;文本蘊含評價指標為準確率(Accuracy,ACC).
4.2 實驗結果
本文的模型是基于Tensorflow框架搭建,采用ADAM優化器[21]作為整個模型的優化函數.SCITAIL數據集的學習率為0.001,batch size大小為32,隱層維度為256,SNLI和MultiNLI數據集的學習率采用warm up策略,初始學習率為0.000 1,分別逐步上升到0.001和0.002之后開始下降,batch size為256,網絡隱層維度為200.為防止過擬合,采用dropout[22]比率為0.2,CNN網絡過濾器大小為3.輸入為300維的Glove詞嵌入[23]和50維的位置向量,對于詞表外的單詞,采用高斯分布隨機初始化一個300維的向量,所有詞向量在整個訓練過程中不更新.
表2至表4分別顯示了三個數據集的準確率結果,由于僅SNLI數據集中部分對比模型列出了模型參數數量,因此僅在SNLI數據集上對比模型參數數量結果,表5對比了部分模型的推理速度.
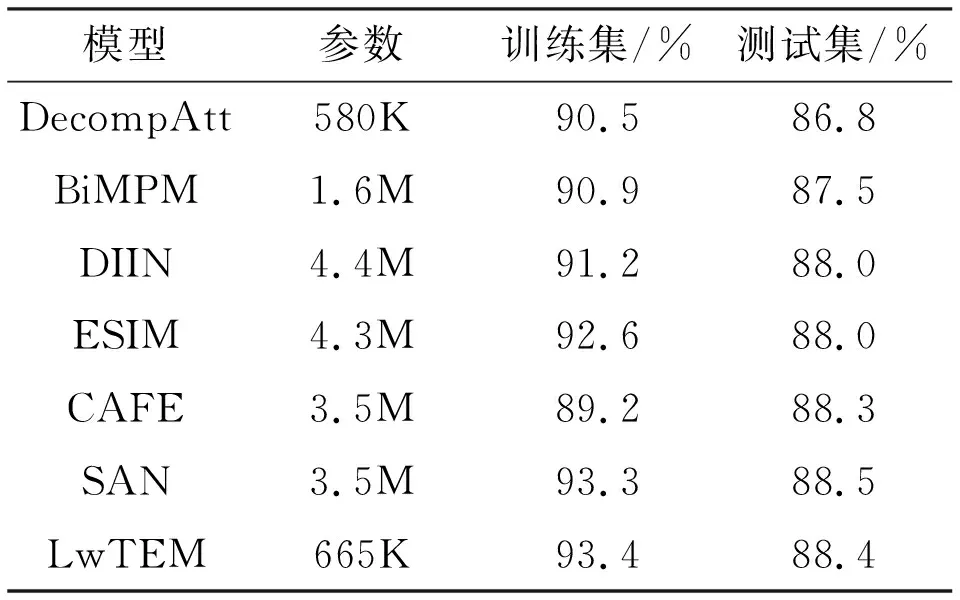
表2 SNLI數據集結果

表3 SCITAIL數據集結果

表4 MultiNLI數據集結果
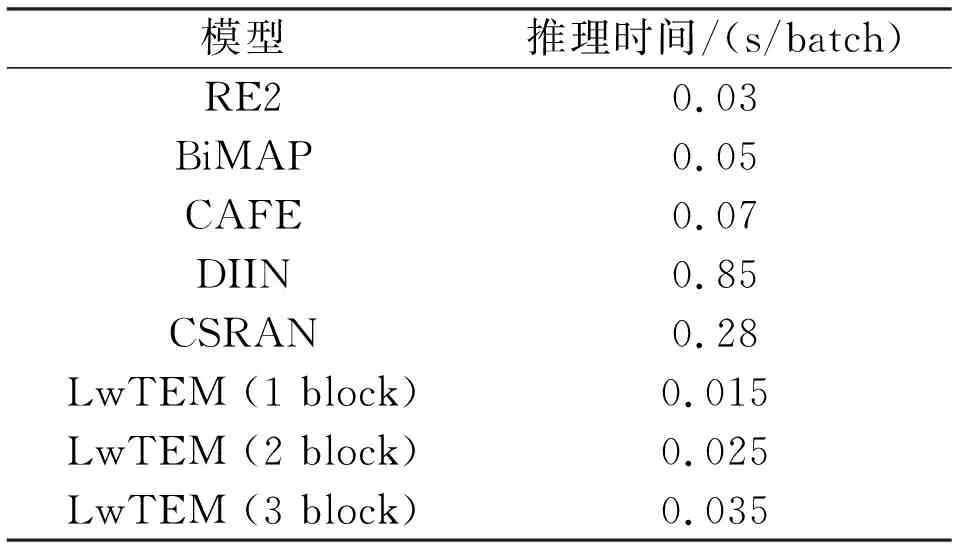
表5 模型推理速度對比
表2為SNLI數據集的結果,LwTEM模型在SNLI測試集上達到了88.4%的準確率,模型參數數量卻只有665 K,遠低于其他主流模型參數量.
BiMAP網絡[9]采用全匹配,最大匹配,平均匹配和注意力匹配多種對齊過程豐富文本匹配特征,CAFE網絡[1],DIIN網絡[8]在輸入層構建多種文本輸入特征,SAN網絡[3]采用多次迭代推理凝練深層語義信息.這些網絡除了DIIN模型外都是采用循環神經網絡用于文本編碼和推理,其中,SAN模型準確率高于本文模型0.1%,但參數數量卻遠多于本文模型.DecompAtt[24]采用自注意力和全連接網絡為模型主要框架,沒有復雜的推理過程和額外的特征,其參數數量略少于本文模型,但本文模型準確率高于該模型1.6%.通過分析可知,在綜合考慮準確率和參數數量指標后,LwTEM模型性能要優于主流文本蘊含模型.
表3為SCITAIL數據集實驗結果,由表2和3結合可知,LwTEM模型參數數量遠少于上述大多數模型,并且在SCITAIL數據集上準確率也達到最好的效果.
表4顯示了在MultiNLI數據集的實驗結果.MultiNLI測試集分為Matched和Mismatched兩個部分.LwTEM模型在Matched數據部分達到了78.7%的準確率,分別高于ESIM模型1.9%,MwAN模型0.2%,并且和DIIN,CAFE模型結果相當,在Mismatch數據上準確率為78.1%,優于表4中大部分模型結果.
表5顯示了模型不同block的推理速度結果,推理過程中一個batch標準大小為8,最大句子長度設為20,Yang等[25]模型中設定完全相同,模型運行的處理器也相同,均為Inter Core i7,唯一的不同在于操作系統,本文模型運行操作系統為Windows10,表中其他模型運行系統為MacOS.CAFé[1],BiMAP[9],CSRAN[12]模型均是由單層或多層LSTM網絡作為文本編碼,并采用各種注意力匹配推理文本關系.RE2[25]結合CNN網絡和注意力以及殘差連接構建模型,DIIN[8]采用CNN網絡,空間注意力以及密集連接構建的文本蘊含模型,但由于其復雜的交互特征處理過程,使得模型速度較慢.由表5中可知,本文模型1個模塊的推理時間僅為0.015 s,優于其他所有模型推理速度,疊加到2個模塊的模型推理時間為0.025 s,仍然好于其他模型,在疊加到3個模塊后,模型推理速度為0.035 s.表5推理結果表明了本文模型LwTEM在推理速度上要比其他主流文本蘊含模型至少快1倍以上.
4.3 模型性能分析
4.3.1 結構消融分析 圖3為LwTEM模型在SCITAIL驗證集上模型結構消融結果,直觀反應了不同模塊的結果變化[26-27].由圖3可知,本文輕量級模型(a)在SCITAIL驗證集上最好效果為89.4%,在(b)去掉編碼層注意力中參數w后準確率下降了0.3%,表明了改善后的自注意力優于原自注意力效果;在(c)去掉卷積結構后模型準確率大幅降低了2%,表明了在本文模型中CNN網絡提取文本局部特征對文本對關系判斷的重要性;在(d)去掉原特征融合方式而采用簡單的拼接方式代替原本特征融合后,模型準確率也降低了1.5%.在這三個不同模塊中,其作用最大的是CNN模塊,其次是特征融合方式.圖3表明了本章模型中各個模塊的有效性和不可替代性.
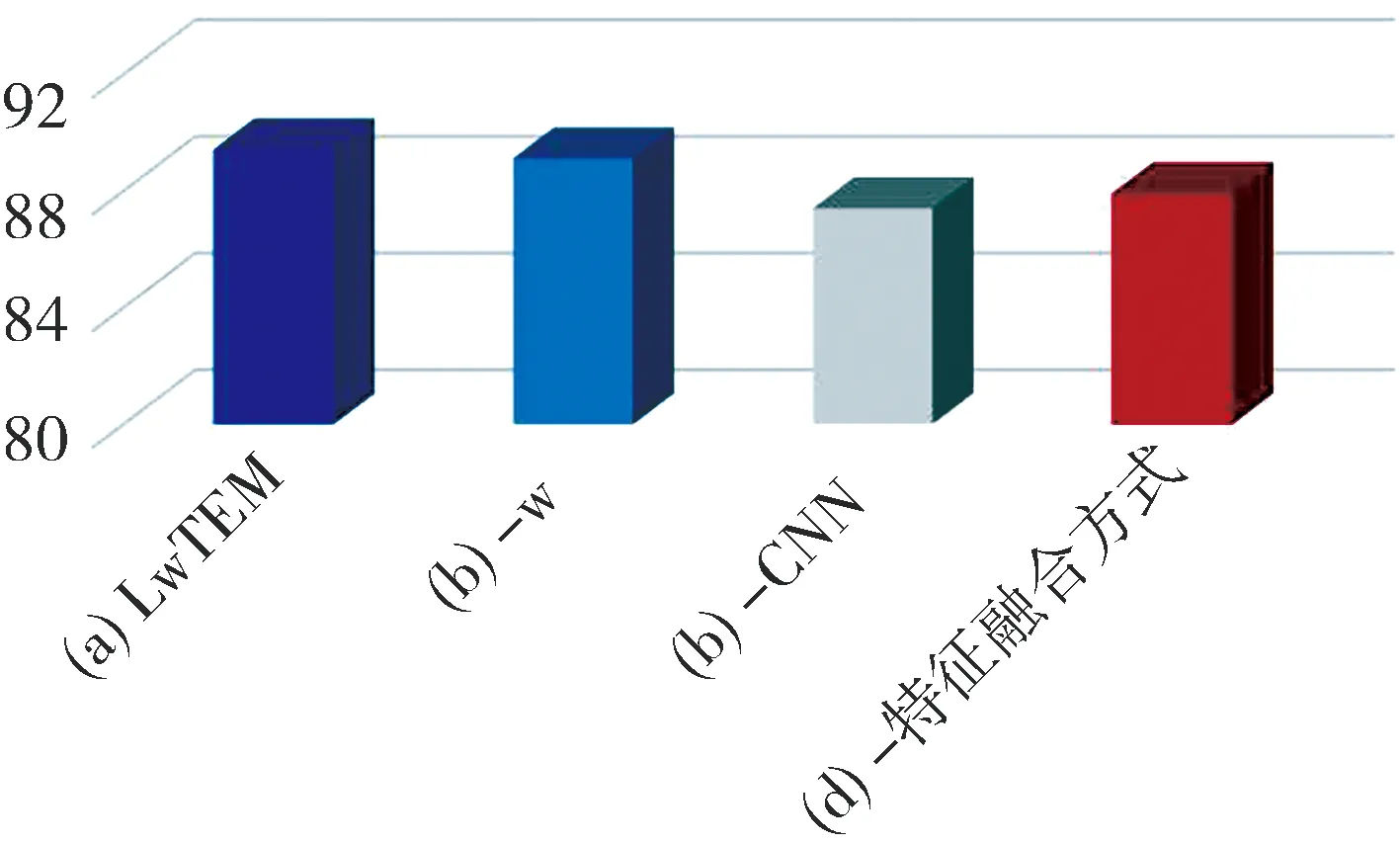
圖3 模型結構消融結果柱狀圖
4.3.2 不同block實驗結果 表6為LwTEM模型在疊加不同模塊后在各個數據集的驗證集上的準確率.在SNLI驗證集上疊加2個模塊比1個模塊準確率提升了0.2%,當繼續疊加到3個模塊后,并沒有發現明顯的效果提升,說明本章模型在SNLI數據集上用2個模塊堆疊的即可.而在MultiNLI數據集上疊加兩個模塊后,模型結果均提升了0.6%,而繼續增加到3個模塊,準確率進一步提升0.7%和0.4%.受硬件限制和模型復雜度影響,本文僅測試到三個模塊.由表6結果可知,針對不同數據集的特點,疊加不同的模塊有不同的效果.對于MultiNLI數據集,文本對較長,句式復雜,疊加多個模塊模擬多次推理效果更好,而對于簡單句的SNLI數據集,本章模型的1個模塊即可達到較高的文本關系識別率.
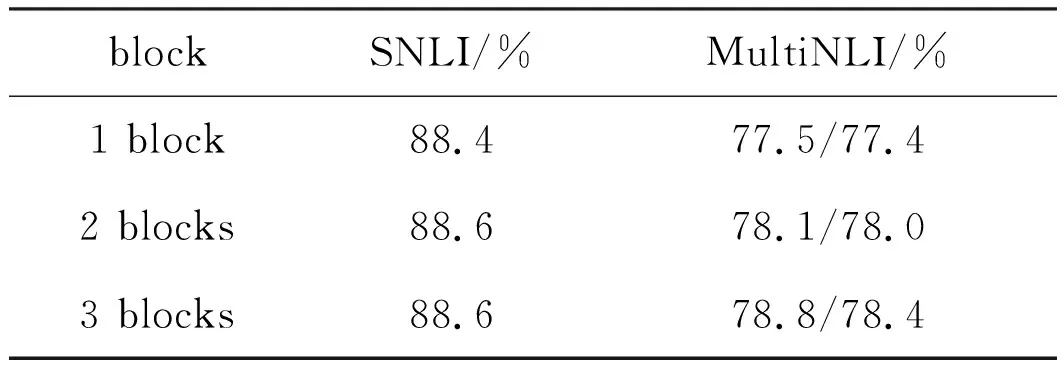
表6 模塊不同block結果
4.3.3 注意力可視化和案例分析 本節通過可視化注意力結果分析模型內部學到的信息.LwTEM模型注意力模塊得到的注意力熱力圖如4所示,縱軸表示前提文本,橫軸表示假設文本,每個方塊表示前提和假設文本中詞兩兩對應的注意力可視化結果,顏色越深表示注意力值越大.
圖4共包含4個樣例,樣例1為SNLI數據集中矛盾樣例,樣例2為SNLI數據集中蘊含樣例,樣例3為SCITAIL數據集的蘊含樣例,樣例4為SCITAIL數據集的中立樣例.以下為4個樣例詳細分析結果.
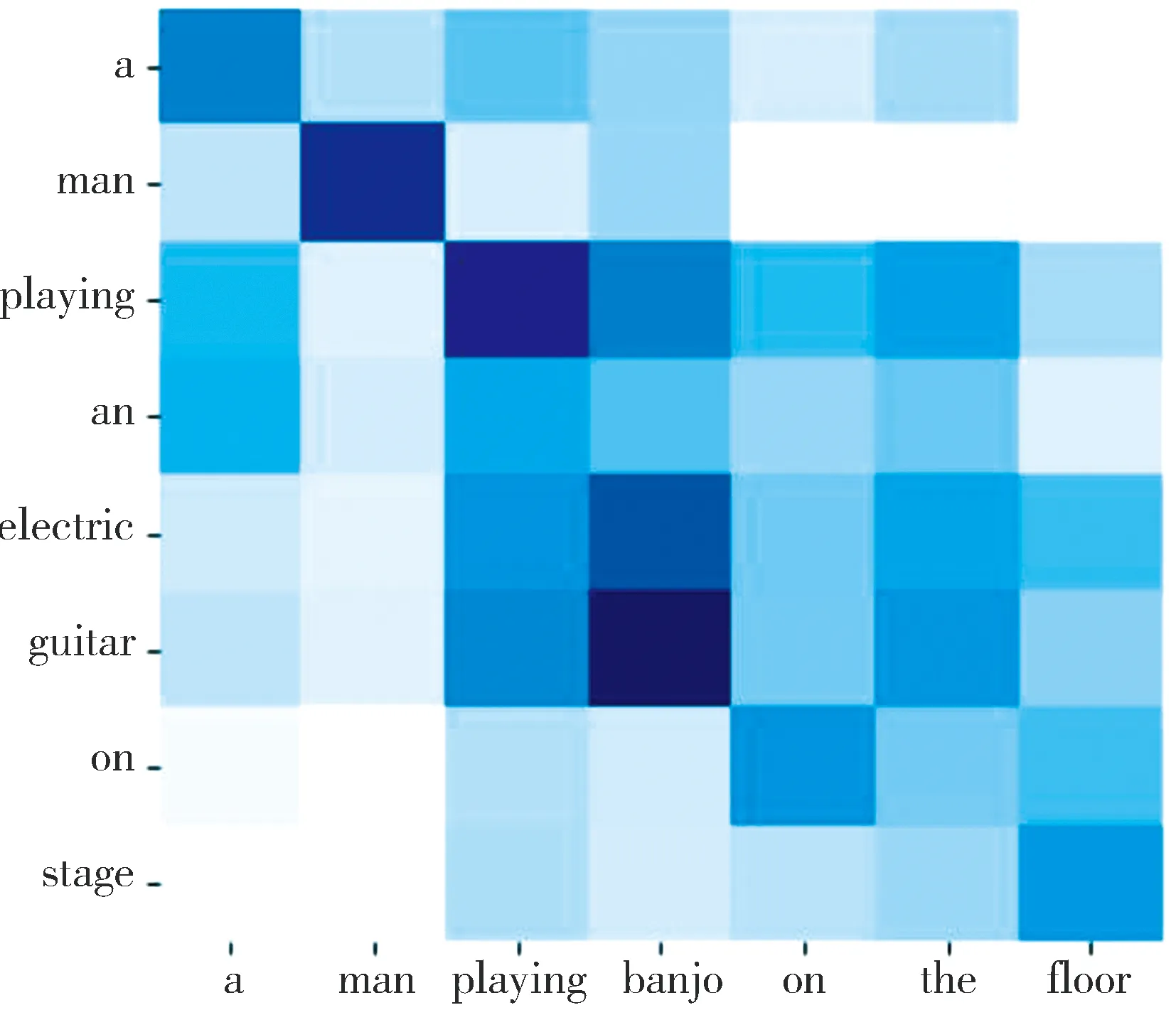
(a) 樣例1
前提1:a man playing an electric guitar on stage.
假設1:a man playing banjo on the floor.
標簽1:矛盾
在樣例1中,模型可準確找到“guitar”和“banjo”這一對關鍵詞,在主語“a man”,動詞“playing”一一對應的情況下,模型定位到“guitar”和“banjo”的語義差異,從而識別出文本的矛盾關系.
前提2:a woman with a green headscarf blue shirt and a very big grin.
假設2:the women is very happy.
標簽2:蘊含
對于樣例2文本對,模型注意力對齊了“very big grin”和“very happy”這一對關鍵詞,可以推測出前提蘊含假設文本語義,從而找到文本對的蘊含關系.
前提3:This causes gases to become liquids and liquids to become solids as the temperature decreases
前提4:At high temperatures, the solid dye converts into a gas without ever becoming a liquid
假設3&4:Gases and liquids become solids at low temperatures
樣例3和樣例4的假設文本相同.前提3和假設為蘊含關系,前提4和假設為中立關系.通過注意力可視化分析,在樣例3中,“gases”“become”liquids”和“liquids”“become”“solids”均有一一對應關系,“decrease”和“low”也可通過注意力推理出詞義相同,在句子中謂語,賓語和多個不同主語均能一一對應情況下,可推斷出文本為蘊含關系.對于樣例4,為非蘊含關系,卻有很多相同詞,模型可對齊這些相同詞的注意力,但是假設中關鍵詞“liquids”到“solids”的關系,在前提中沒有與之相應的關系,所以模型將其判斷為非蘊含關系.
5 結 論
本文構建輕量級文本蘊含模型LwTEM,主要由自注意力編碼,注意力交互,特征融合和CNN網絡構成,堆疊多個模塊可根據不同數據集特點得到相應的推理效果.本文在三個文本蘊含數據集上均做了實驗,結果表明LwTEM模型在準確率和現主流模型相當情況下,參數數量和推理速度明顯優于其他模型.未來可嘗試將LwTEM模型應用于其他文本匹配任務.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
